
高分辨率可见光图像引导红外图像超分辨率的Transformer网络
2023-02-18 03:06邱德粉江俊君胡星宇刘贤明马佳义
中国图象图形学报 2023年1期
邱德粉,江俊君*,胡星宇,刘贤明,马佳义
1.哈尔滨工业大学计算机科学与技术学院,哈尔滨 150001; 2.武汉大学电子信息学院,武汉 430072
0 引 言
与传统的可见光范围成像相比,红外成像具有许多优势,因为它在极低可见度条件下仍然可以很好地工作,如图1(a)所示。红外的环境适应性优于可见光,尤其在夜间和恶劣气候下的工作能力。由于依靠目标和背景之间的温差和辐射率差进行探测,所以红外成像可以克服部分视觉上的障碍而探测到目标,抗干扰能力强,如图1(b)所示。因此,红外图像具有广泛的军事和民间应用,例如,夜视、安防监控和机器人技术。为了实现高分辨率的红外成像,需要把红外传感器封装在单独的真空包装中,这是一个耗时且高成本的过程。因此,红外传感器要比相同分辨率的可见光传感器贵得多,这极大地限制了红外传感器的实际应用范围。对于低分辨率的红外图像,可以考虑开发有效的算法来恢复热辐射细节,这对于使用高分辨率红外图像进行目标检测和目标识别的任务至关重要。在计算机视觉中,根据低分辨率图像预测高分辨率图像的过程定义为图像超分辨率重建。红外图像超分辨率技术可以通过从相当便宜的低分辨率红外传感器捕获的图像预测准确的高分辨率红外图像。

图1 红外图像和可见光图像示例
深度学习技术取得了显著发展,已经成功应用于图像超分辨率问题。SRCNN(super-resolution convolutional neural network)(Dong 等,2014)首次使用卷积神经网络学习从低分辨率输入到高分辨率输出的映射函数来解决超分辨率问题,被认为是基于深度学习的超分辨率的开创性工作。VDSR(image super-resolution using very deep convolutional networks)(Kim等,2016a)和DRCN(deeply-recursive convolutional network)(Kim 等,2016b)使用残差学习来构建具有更深架构和更高准确性的超分辨率网络。SRGAN(super-resolution generative adversarial network)(Ledig 等,2017)使用生成对抗网络(generative adversarial network, GAN),通过引入包括均方误差(mean squared error, MSE)损失、感知损失和对抗损失的多种损失函数来预测高分辨率输出。SRNTT(image super-resolution by neural texture transfer)(Zhang 等,2019)根据纹理相似性进一步从参考图像中转移纹理信息以增强纹理。徐雯捷等人(2021)针对实际应用场景提出了轻量级注意力特征选择循环网络来重建超分辨率图像。吴瀚霖等人(2022)实现了连续比例因子的图像超分辨率方法。但是这些技术大多集中在可见光图像领域,红外图像得到的关注较少。
随着红外图像的应用范围越来越广泛,迫切需要可以在红外图像域进行图像超分辨率的方法。PBVS(perception beyond the visible spectrum)研讨会举办了热图像超分辨率挑战赛(thermal image super-resolution challenge, TISR)旨在为红外图像超分辨率问题引入更多优秀的方法,并鼓励在该领域进行研究。由于该比赛只提供了红外图像进行训练和测试,因此参赛队伍的方法都是针对红外图像进行的单图超分辨率。高分辨率纹理在退化过程中被过度破坏,无法正常恢复,就会在超分辨率图像中产生模糊,单图超分辨率就变得非常具有挑战性。
许多低分辨率热像仪都和高分辨率可见光传感器搭配使用,一种可行的思路是利用可见光传感器捕获的高分辨率图像,辅助红外图像进行超分辨率。Lee等人(2017)使用可见光图像的亮度域作为增强红外图像的训练域。Han等人(2017)提出了一种基于卷积神经网络的引导图像超分辨率算法,通过使用在弱光环境下同时获取的低分辨率红外图像和高分辨率可见光图像来提高近红外图像的分辨率。该方法从红外图像和可见光图像中提取特征,并使用卷积层将它们组合起来。跨模态图像超分辨率重建的关键是将相关细节从引导高分辨率图像转移融合到待超分辨率重建的低分辨率图像中,并保持对红外模态的忠实,避免转移仅存在于可见光模态中的冗余伪影或纹理细节,例如图1(c)书封面上的文字和图画。由于上述工作直接将提取的红外图像特征和可见光图像特征串联起来,然后经过卷积层进行超分辨率,因此没有很好地解决相关细节转移这个问题。Gupta和Mitra(2020)提出了一种基于从可见光图像中提取的金字塔边缘图的引导超分辨率算法,称为PAGSR(pyramidal edge-maps and attention based guided thermal super-resolution)。PAGSR通过使用不同感知尺度的边缘图和基于空间注意力的融合模块,可以将相关细节从可见光图像转移并融合到红外图像中,由此可以保持对红外模态的忠诚,避免转移只存在于可见光模态中的冗余伪影。PAGSR假设可见光和红外图像对是对齐的,然而,实际情况中图像对一般都是不对齐的。UGSR(unaligned guided thermal image super-resolution)(Gupta和Mitra,2022)是第1个尝试针对未对齐的红外与可见光图像对进行引导超分辨率的工作,但是UGSR直接将对齐的红外特征和可见光特征逐像素相加,然后进行超分辨率,没有从可见光图像中有针对性地转移相关细节到红外图像中,同时抑制不相关细节的转移。
目前许多方法将深度网络用于图像超分辨率重建任务中,由于其深度架构,它们提取的特征高度冗余。具有多个卷积层的深度神经网络在每个卷积层中都使用很多特征进行超分辨率任务,这会占用更大的空间,带来更多的计算量,但是超分辨率图像的质量不一定好,因此需要优化深度模型的这种行为以提高模型性能。
为解决以上问题,本文提出了一种使用高分辨率可见光图像来引导红外图像进行超分辨率的神经网络模型,可以从给定高分辨率可见光图像中汲取高分辨率纹理为重建红外图像提供高频细节信息,同时使用通道拆分策略消除图像超分辨率网络中的冗余特征。
受人类视觉注意力机制的启发,红外图像和可见光图像都共同包含的纹理特征目标区域需要重点关注。然后从目标区域的可见光图像中转移相关的细节信息到红外图像中,同时抑制非目标区域无用信息的转移,并根据相似程度为转移的信息赋予权重。注意力机制极大地提高了信息处理的效率和准确度。Transformer的自注意力机制可以将注意力集中在两种模态图像的相似位置,快速获得相关的纹理信息,同时抑制不相关的纹理信息。因此为了处理图像之间光谱范围的差异,减少超分辨率图像中因此产生的模糊、重影和伪影,本文提出一种基于引导Transformer的信息引导与融合方法,从高分辨率可见光图像中搜索和传输相关纹理信息来指导红外图像的超分辨率恢复。
本文贡献主要有3点:1)提出了一种新型的基于引导Transformer的网络结构来从高分辨率可见光图像中搜索相关的纹理信息,并用于之后的低分辨率红外图像的超分重建;2)使用基于通道拆分策略来进行超分辨率重建的网络结构,可以有效消除模型中的冗余特征,减少计算量的同时提升模型性能;3)在FLIR-aligned数据集上的实验结果验证了方法的有效性,相比最近提出的红外图像引导超分辨率方法在峰值信噪比(peak signal to noise ratio,PSNR)上提升了0.75 dB。
1 模型结构设计与分析
1.1 网络结构
本文提出的高分辨率可见光图像引导低分辨率红外图像超分辨率网络是一个端到端的网络,其结构如图2所示,共包含两部分,分别为引导Transformer模块和超分辨率重建模块。首先ILR,ILR↑,IVS,IVS↓↑经过第1部分的引导Transformer子网络得到包含高分辨率可见光图像和低分辨率红外图像信息的合成特征,然后将这个合成特征输入到后面的超分辨率重建子网络,最终得到超分辨率的红外图像。超分辨率重建子网络参考HAN(holistic attention network)网络。ILR,ILR↑,IVS分别代表输入低分辨率红外图像、上采样之后的低分辨率红外图像和高分辨率的可见光图像。在可见光图像上依次进行下采样和上采样获得与ILR↑具有域一致性的IVS↓↑。

图2 红外图像超分辨率网络结构
1.1.1 引导Transformer子网络介绍
超分辨率任务的关键是正确预测高频细节。可见光引导图像包含独属于可见光谱的精细纹理细节,例如图1(c)中书封面上的文字和图画,台灯的装饰图案仅存在于可见光图像。当使用引导超分辨率时,这种仅存在于可见光图像的纹理细节可能会导致伪影。因此,本文提出了引导Transformer模块,从可见光图像中搜索和传输超分辨率重建任务需要的纹理信息。此外,考虑到红外图像和可见光图像之间存在一定的视差,本文方法不做输入图像对完全对齐的严格假设。不完全对齐的图像经过引导Transformer子网络提取纹理信息和相关性的计算,可以将相关的纹理信息从高分辨率可见光图像转移到低分辨率红外图像中,从而缓解视差带来的影响。
具体做法是首先从两种图像中提取纹理特征,然后通过Transformer的自注意力机制融合两种图像的特征,来获得可见光图像特征中与红外图像相关的信息。引导Transformer模块包含4部分:纹理提取、相关性计算、硬注意力和软注意力。
1)纹理提取。与红外图像相比,可见光图像的分辨率更高,并且包含有用的高频细节,有助于提升红外图像超分辨率的性能。纹理信息应该根据输入的低分辨率红外图像自适应地提取和整合。因此,本文没有使用类似VGG(Visual Geometry Group)等预训练分类模型的纹理提取器,而是使用了一个可以学习的纹理提取器,其参数将在端到端训练期间进行更新。这样的设计鼓励在红外图像和可见光图像之间进行联合特征学习,可以捕获更准确的纹理特征。纹理信息的提取过程可以表示为
Q=LTE(ILR↑)
(1)
K=LTE(IVS↓↑)
(2)
V=LTE(IVS)
(3)
式中,LTE(·)代表可学习的纹理提取器。提取的纹理特征Q,K,V表示Transformer内部注意力机制的3个基本元素,并将在接下来的部分中进一步使用。
2)相关性计算。相关性计算旨在通过估计Q和K之间的相似性来计算ILR和IVS图像之间的相关性。目的是将相关的纹理信息从高分辨率可见光图像转移到低分辨率红外图像,同时抑制不相关纹理信息的转移。通过计算相关性以及后续硬注意力和软注意力的使用,本文基本可以实现只转移相关纹理信息同时忽略不相关纹理信息。
将Q和K展开,表示为qi(i∈[1,HLR×WLR])和kj(j∈[1,HVS×WVS]),然后计算它们之间的相似性
(4)
式中,〈〉表示计算向量内积。
3)硬注意力。使用硬注意力模块转移高分辨率纹理特征V。在硬注意力模块中,只为每个qi从V中最相关的位置转移特征。具体地,首先计算一个硬注意力图H,其中第i个元素hi(i∈[1,HLR×WLR])是从相关性ri,j中计算得到的
(5)
hi的值可以看做是一个硬索引,它表示在可见光图像中与低分辨率红外图像中第i个位置最相关的位置。为了从高分辨率图像中获得转移的高分辨率纹理特征T,使用硬注意力图作为索引对V的展开块进行索引选择操作
ti=vhi
(6)
式中,ti代表T中第i个位置的值,这个值是从V中第hi个位置选择的。
4)软注意力。使用一个软注意力块来融合高分辨率特征T和从低分辨率图像中提取到的低分辨率特征F。在融合的过程中应该增强相关的纹理转移,抑制不太相关的纹理转移。为了实现这一点,从ri,j中计算出一个软注意力图S,来表示T中每个位置的传输纹理特征的置信度
(7)
式中,si表示软注意力图中的第i个位置。没有直接将注意力图S应用于T,而是首先将高分辨率纹理特征T与低分辨率特征F融合,以此利用来自低分辨率图像的更多信息。融合的特征进一步与软注意力S逐元素相乘,并加上F来获得Transformer的最终输出。这个操作可以表示为
Fo=F+Conv(Concat(F,T))⊙S
(8)
式中,Fo表示合成的输出特征。Conv和Concat分别表示卷积操作和串联操作。运算符⊙表示特征图之间的逐元素相乘。
1.1.2 超分辨率子网络介绍
在超分辨率部分,包含引导信息的合成特征进行超分辨率重建得到高分辨率图像。但是由于网络比较深以及多个网络层会提取相似的特征这一性质,大多数深度网络会提取高度冗余的特征。本文使用通道拆分策略解决这一限制并同时提供更好的超分辨率结果。在所提网络中使用通道拆分来区分通道维度中的特征,可以在拆分的特征图上执行不同的操作,从而降低冗余并提高超分辨率性能。
来自残差组的特征分成两个流Fi和Fs,每个流的特征都是C通道。Fi特征经过后续的残差组去提取丰富的特征,剩下的Fs特征直接与其他残差组的Fs特征连接。
1.2 损失函数
在本文方法中包括两个损失函数项:重构损失和感知损失,损失函数表达为
L=λrLr+λpLp
(9)
重构损失Lr可以实现更高的PSNR,通常使用均方误差(MSE)来计算。本文采用L1范数,与MSE相比,L1范数可以让重建图像更锐化,网络更容易收敛。
(10)
感知损失Lp已被证明可以提高重建图像的视觉质量,已有的图像超分辨率工作(Johnson 等,2016;Ledig 等,2017;Sajjadi 等,2017)使用感知损失并获得了更好的视觉效果。感知损失的关键思想是增强重建图像和目标图像之间在特征空间上的相似性。
(11)
式中,φi(·)代表VGG19网络的第i层的特征图,(Ci,Hi,Wi)代表当前层的特征的形状。ISR是重建图像,IHR为高分辨率图像。
2 实验与性能评估
2.1 实验设置
FLIR-ADAS数据集提供了未校正的带注释的红外图像和不带注释的可见光图像。由于原始的数据集不包含任何校正的图像,需要通过识别对应关系和估计相对变换矩阵来手动校正每对图像。因此在本文实验使用FLIR-aligned(Fang 等,2022),此版本数据集只保留了3个比较常见的类型数据,分别是“自行车”、“汽车”和“人”,手动移除了没有对应关系的图像对,4 890对图像用于训练,126对图像作为验证集,126对图像作为测试集。需要注意的是,FLIR-aligned中的图像对存在一定的视差,因此并不是完全对齐的。
纹理提取器由卷积层和池化层组成,输出与低分辨率图像相同尺寸的纹理特征。为了减少时间和GPU内存的消耗,相关性计算在低分辨率图像同尺寸的纹理特征上进行。在二倍超分辨率实验中,由于低分辨率图像尺寸在计算相关性时显存占用仍然太大,将测试图像统一裁剪成512×512像素进行实验。在超分辨率模块本文使用了10个残差组,每个残差组中有20个残差块。本文方法使用ADAM(adaptive moment estimation)算法进行优化,其中超参数β1=0.9,β2=0.999,ε=10-8,学习率是10-4,共训练400个周期。所有实验都是在Pytorch框架下使用NVIDIA 2080Ti的GPU显卡完成的。
2.2 与其他方法对比
将本文方法与可见光图像单图超分辨率方法、红外图像单图超分辨率方法和可见光图像引导红外图像超分辨率方法进行比较。与单图超分辨率方法的比较可以很好地说明可见光图像中的纹理信息对于红外图像超分的指导作用;与可见光图像引导红外图像超分辨率方法进行比较可以展示本文方法在性能上的优越性。
在引导超分辨率方法中,选取了两个目前最先进的(state-of-the-art,SOTA)基于深度学习的方法进行比较:针对未对齐的红外与可见光图像对进行引导超分辨率的工作UGSR(Gupta和Mitra,2022)以及基于多尺度边缘图和空间注意力融合模块的引导超分辨率工作PAGSR(Gupta和Mitra,2020)。在单图超分方法中,将本文方法与热成像图像超分SOTA方法——采用深度通道拆分网络来减少冗余特征的方法ChasNet(channel split convolutional neural network)(Zhao 等,2019)和可见光图像超分SOTA方法——基于ResNet的改进增强深度超分辨率网络EDSR(enhanced deep super-resolution network)(Lim 等,2017)、残差通道注意力网络RCAN(residual channel attention network)(Zhang 等,2018b)、轻量化的信息多重蒸馏网络IMDN(information multi-distillation network)(Hui 等,2019)、基于层注意力和通道空间注意力的整体注意网络HAN(Niu 等,2020)、基于窗口移位注意力Transformer的超分网络SwinIR(image restoration using swin transformer)(Liang 等,2021)进行了比较。在测试之前,所有方法都根据公开的代码和论文在FLIR-aligned数据集上进行了训练。
2.2.1 客观实验结果
为了定量评估本文方法的超分辨率效果并与其他方法进行比较,本文采用峰值信噪比(PSNR)和结构相似性(structural similarity,SSIM)(Wang 等,2004)作为评价指标。表1—表3分别展示了这些方法在FLIR-aligned测试集126幅图像上进行不同倍率超分辨率实验获得的平均PSNR和SSIM值。平均而言,本文方法大大优于其他最先进的图像超分辨率方法。本文方法在4倍超分辨率和8倍超分辨率实验上产生了最好的客观结果。在4倍超分辨率实验中,本文方法与2021年提出的引导超分辨率方法UGSR相比,在PSNR上高出0.75 dB,在SSIM上高出0.041。与2021年提出的红外图像超分辨率方法ChasNet相比,在PSNR和SSIM上分别高1.106 dB和0.06。与使用Swin Transformer的SwinIR方法相比,PSNR提升了0.743 dB,SSIM提升了0.048。在8倍超分辨率实验中,本文方法与UGSR相比,PSNR提高了0.458 dB。与单图超分辨率方法HAN相比,PSNR提升了0.804 dB,SSIM提升了0.027。在2倍超分辨率实验中,由于引导超分辨率方法UGSR和PAGSR不支持2倍超分辨率,因此只与单图超分辨率方法进行了比较。本文方法相比SwinIR,SSIM提升了0.06,说明本文方法从可见光图像中学习到了相关的图像结构特征。而PSNR相比SwinIR有所降低可能是因为本文方法在较低尺度上从可见光图像中提取的纹理特征包含了对红外超分图像造成影响的底层特征(如亮度等),因此本文方法更适用于较高尺度的引导红外图像超分辨率任务。

表1 不同模型的2倍超分辨率客观结果比较
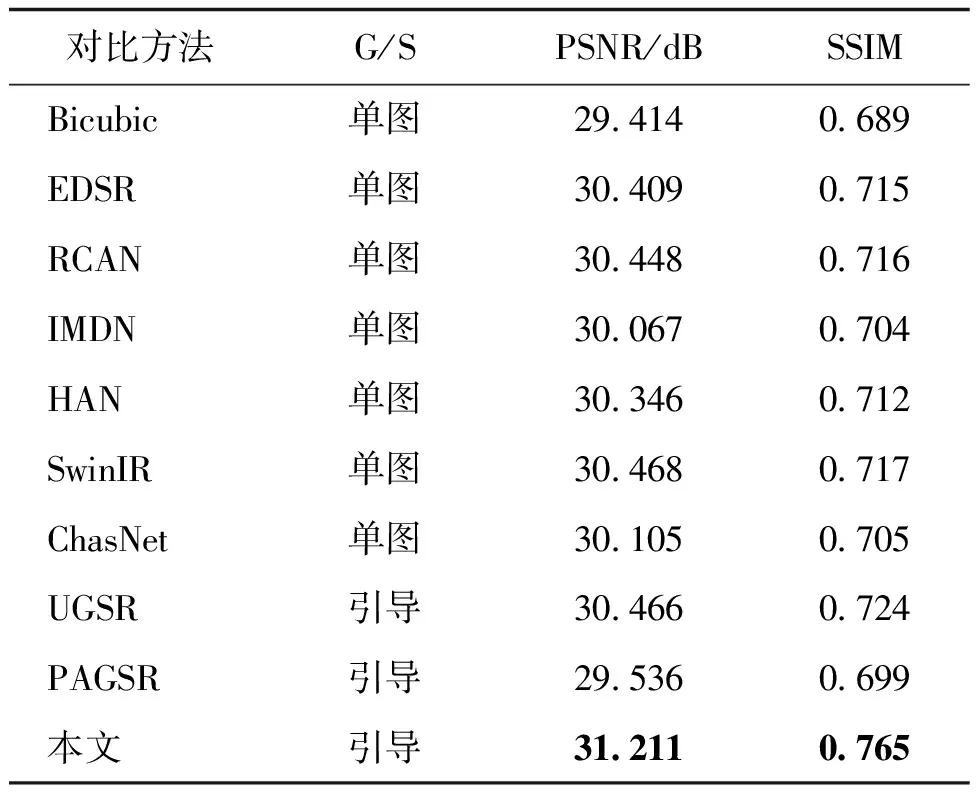
表2 不同模型的4倍超分辨率客观结果比较

表3 不同模型的8倍超分辨率客观结果比较
2.2.2 主观实验结果
在图3和图4中,将本文方法与其他图像超分辨率方法进行了比较。大多数其他图像超分辨率方法都具有模糊的边缘,如图3所示,这可能是因为输入的红外图像的分辨率比较低或纹理不匹配以及引导信息的转移和融合不准确。在现有方法中,针对不对齐的红外图像对进行引导超分辨率的方法UGSR表现不错,但是本文方法更忠实地重建了高频细节,边缘更清晰。
在图4中,与其他方法相比,本文方法在可见光图像高频信息的引导下较好地重建了纹理细节,如图中红色方框标注的放大部分所示。在图3和图4的结果中,引导超分辨率方法PAGSR显示出较多的模糊,这主要是由于红外图像和可见光图像的错位导致的纹理失配,从而在超分辨率结果中显示出模糊。本文的超分辨率结果比其他方法清晰得多,这表明对不对齐的图像对的鲁棒性相对较高。总之,本文方法能够更好地重建高频细节,并且没有出现伪影。

图4 样本FLIR_05847的4倍超分辨率结果
2.3 消融实验
在本节中,验证了本文方法不同模块的有效性,包括引导Transformer和通道拆分策略。
2.3.1 引导Transformer有效性验证
引导Transformer主要包含4部分:纹理提取、相关性计算、用于特征转移的硬注意力、用于特征合成的软注意力。引导Transformer消融实验的结果如表2所示。本文将使用通道拆分策略的HAN网络作为基础模型,在基础模型之上逐步添加硬注意力(hard attention,HA)和软注意力(soft attention,SA)。值得注意的是,在基础模型上添加硬注意力时,包括添加纹理提取和相关性计算。如表4所示,当在基础模型上添加硬注意力时,PSNR提升了0.426 dB,SSIM从0.712提升到0.764。这些数据证明了硬注意力模块可以有效地从可见光图像中转移相关纹理信息到红外图像中。软注意力的主要作用是根据两个图像的特征之间的相关性计算出一个注意力图,在特征转移融合的过程中增强相关的纹理特征,即赋予相关纹理特征一个较大的权重;抑制不相关纹理特征的转移和融合,即赋予该纹理特征一个较小的权重。当模型加上软注意力时,如表4第3行,进一步将PSNR提高到31.211 dB,SSIM也有小幅提升。图5的主观结果也进一步验证了引导Transformer的有效性。如图5(d)(j)所示,在基础模型上添加硬注意力时,超分辨率结果的清晰度明显上升,且包含更多的高频信息。如图5(e)(k)所示,当模型加上软注意力时,超分辨率结果的视觉质量也有所提升。因此,引导Transformer模块可以从给定高分辨率可见光图像中汲取高分辨率纹理为重建红外图像提供高频细节信息,从而提升红外图像超分辨率方法的性能。

图5 引导Transformer消融实验结果
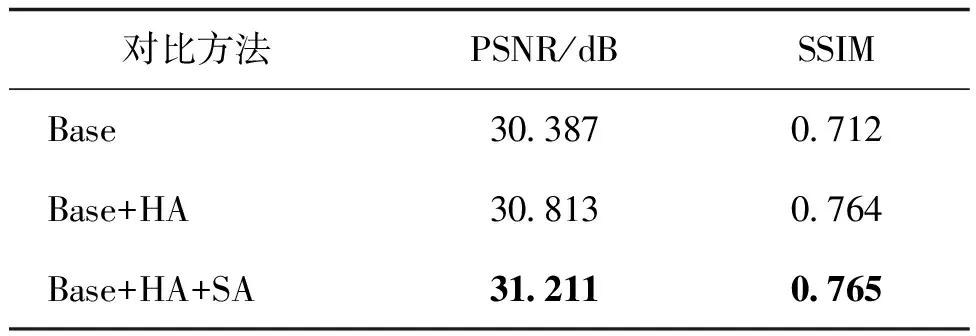
表4 引导Transformer 消融实验结果
2.3.2 通道拆分策略有效性验证
为了验证通道拆分策略的有效性,本文进行了消融实验,一个网络保持原始网络结构;另一个网络不使用通道拆分策略,来自残差组的特征不再分成两个流,而是通过复制,一份经过后续的残差组,另一份与其他残差输出的特征进行串联,然后经过层注意力模块。如表5所示,当在本文使用的网络结构中去除通道拆分策略后,PSNR和SSIM均有不同程度的降低。通过表5数据可以发现,通道拆分策略对于红外图像超分辨率任务具有促进作用,证明了通道拆分策略在本文网络中的有效性。

表5 通道拆分消融实验的结果
3 结 论
面向引导超分辨率任务,本文提出了一种基于引导Transformer 的信息引导与融合方法,根据红外图像特征和可见光图像特征之间的相似度,从高分辨率可见光图像中转移相关纹理信息到红外图像中,同时抑制不相关纹理信息的转移。针对深度网络中存在的特征冗余问题和计算效率问题,本文在超分辨率模块使用通道拆分策略。
引导Transformer有效地减少了超分辨率图像中因为图像之间光谱范围差异而产生的模糊、重影和伪影。在 FLIR-aligned 数据集上的实验结果表明,本文方法重建的红外图像具有较多细节信息、较少的伪影和模糊;在客观结果方面,本文方法在 PSNR 和 SSIM 两种常用的客观评价指标上能够取得优于其他对比方法的性能。
值得指出的是,由于使用Transformer 和多种注意力机制,以及网络具有较深的结构(超分辨率模块包含10个残差组,每个残差组包含20个残差块),网络的计算量和参数量较大。未来拟对本文方法进行轻量化处理,进一步优化方法。
猜你喜欢
红外技术(2022年11期)2022-11-25
计算机应用(2020年7期)2020-08-06
雷达学报(2020年3期)2020-07-13
软件(2020年3期)2020-04-20
摄影之友(影像视觉)(2018年12期)2019-01-28
艺术科技(2018年2期)2018-07-23
Coco薇(2017年8期)2017-08-03
Coco薇(2015年5期)2016-03-29
太空探索(2015年8期)2015-07-18
浙江大学学报(工学版)(2015年1期)2015-03-01
