
深度学习多聚焦图像融合方法综述
2023-02-18 06:33王磊齐争争刘羽
中国图象图形学报 2023年1期
王磊,齐争争,刘羽,2*
1.合肥工业大学生物医学工程系,合肥 230009;2.合肥工业大学测量理论与精密仪器安徽省重点实验室,合肥 230009
0 引 言
受限于光学镜头的有限景深,成像装置有时无法实现同一场景中所有物体或区域的清晰聚焦成像,导致景深范围外的场景内容出现散焦模糊现象(Liu等,2020)。为解决上述问题,多聚焦图像融合(multi-focus image fusion,MFIF)技术提供了一种有效途径,通过综合同一场景下多幅部分聚焦图像包含的互补信息,生成一幅全聚焦(all-in-focus)融合图像,以更加适合人类观察或计算机处理,在数码摄影、显微成像、全息成像和集成成像等领域具有广泛的应用价值。多聚焦图像融合的研究可以追溯到20世纪80年代,近40年来提出了数以百计的融合方法。传统MFIF方法一般分为基于变换域的方法和基于空间域的方法两类(Liu等,2020)。
基于变换域的方法主要包括3个步骤,即图像分解(变换)、系数融合和图像重构(逆变换)。首先,利用某种图像表示模型将源图像转换到变换域,得到变换系数;然后,通过设计的融合策略对变换系数进行融合处理;最后,对融合后的系数进行相应的逆变换重构得到融合图像。根据图像表示模型的不同,变换域方法可以进一步分为基于多尺度变换的方法(Burt和Adelson,1985;Li等,1995,2013a;Lewis等,2007;Yang等,2007;Zhang和Guo,2009;殷明等,2016)、基于稀疏表示的方法(Yang和Li,2010;Jiang和Wang,2014;Liu和Wang,2015;Liu等,2016)、基于梯度域的方法(Sun等,2013;Zhou等,2014)、基于其他变换的方法(Mitianoudis和Stathaki,2007;Liang等,2012)以及基于混合变换的方法(Li和Yang,2008a;Liu等,2015a;Zhu等,2018;杨培 等,2021)等。
基于空间域的方法直接在图像空间域中对源图像进行处理和融合。在该类方法中,通常首先在空间域中提取相关特征来度量源图像的活跃程度(activity level),然后根据计算出的活跃程度使用某种融合规则(fusion rule)对源图像进行融合。在MFIF方法中,最常用的融合规则是取极大(maximum selection)。在很多空间域方法中,最后还会使用一些一致性验证(consistency verification)技术(Piella,2003)对得到的决策图或融合图像进行优化,进一步提升融合质量。根据融合算法针对的基本处理单元,空间域方法可以进一步分为基于分块的方法(Li等,2001;Aslantas和Kurban,2010;Bai等,2015;Guo等,2015;Zhang和Levine,2016)、基于区域的方法(Li等,2006;Li和Yang,2008b;Duan等,2018)和基于像素的方法(Li等,2013b;Liu等,2015b;Nejati等,2015;Ma等,2019b;Qiu等,2019;Xiao等,2020)。
得益于强大的特征学习能力,深度学习在众多图像与视觉任务中获得了极为成功的应用。在MFIF问题研究中,基于深度学习的方法自2017年首次提出以来(Liu等,2017),迅速成为该问题的热点研究方向,陆续提出了近百种方法。卷积神经网络(convolutional neural network,CNN)和生成对抗网络(generative adversarial network,GAN)等深度学习模型成功应用于MFIF方法研究。对上述研究工作进行全面系统的回顾与总结有助于研究人员了解该方向的研究进展,对该方向的未来发展也能起到一定的启示作用,具有较强的实际意义。
随着多源图像融合的发展,国际上出现了一些优秀的综述论文,其中一些涉及多聚焦图像融合问题。Li等人(2017)对多源图像融合方向的研究现状进行了全面综述,内容涵盖遥感、医学、红外与可见光、多聚焦等多种图像融合问题,但所述方法均为传统融合方法。Liu等人(2018)与Zhang(2022b)分别对基于深度学习的图像融合方法进行回顾,同样不限于多聚焦图像融合问题。Liu等人(2020)针对MFIF问题开展系统综述工作,所述方法涉及传统方法和基于深度学习的方法。Zhang(2022b)对基于深度学习的MFIF方法进行全面综述和性能对比实验。然而上述工作距今期间又有数十种基于深度学习的MFIF方法陆续提出。此外,上述综述工作均发表于国际英文期刊,国内期刊上目前还鲜有相关的综述工作。
鉴于上述背景,本文对基于深度学习的MFIF方法进行系统回顾,将这些方法进行归纳分类,更清晰地展现该方向的最新研究进展。此外,本文对25种代表性MFIF方法(包括10种传统方法和15种深度学习方法)在3个常用MFIF数据集上的性能进行实验对比与分析。最后,对MFIF存在的挑战性问题及未来发展趋势进行讨论与展望。
1 基于深度学习的多聚焦图像融合方法
根据采用的深度学习模型类型,基于深度学习的多聚焦图像融合方法可以进一步分为基于分类模型的方法和基于回归模型的方法。基于分类模型的方法将多聚焦图像融合建模为像素聚焦属性的判别问题,使用分类型卷积网络实现该目标。与此不同,基于回归模型的方法学习从源图像到融合图像的直接映射,使用端到端网络模型预测输出融合图像。
1.1 基于分类模型的方法
基于分类模型的方法与很多传统空间域方法具有类似的框架。具体而言,使用深度神经网络提取图像特征以及对图像像素的聚焦属性进行分类,即判断像素处于聚焦区域还是散焦区域。根据像素处理方式不同,基于分类模型的方法进一步分为基于图像分块的方法和基于图像分割的方法两类。表1列出了基于深度分类模型的主要融合方法。

表1 基于深度分类模型的多聚焦图像融合方法概述
1.1.1 基于图像分块的方法
Liu等人(2017)首次将卷积神经网络引入到多聚焦图像融合方法研究中,设计了一个面向分类任务的孪生型卷积神经网络,用于学习从源图像到聚焦图(focus map)的直接映射,将传统方法中活跃程度度量和融合规则这两个关键步骤以网络学习的方式一体化实现,加强了两者之间的关联性,同时避免了传统启发式设计的困难。为了解决网络训练的问题,采用多个尺度的高斯模糊来模拟散焦,人工创建了一个由清晰图像块和模糊图像块组成的大规模数据集,用于监督学习。在具体实现中,通过将网络中的全连接层等效转换为卷积层,使网络能够接受任意大小的源图像作为输入,保证了算法的实用性。该方法的流程图如图1所示。

图1 Liu等人(2017)提出的基于CNN的MFIF方法流程图
在得到聚焦图后,还需对其进行二值分割和一致性验证处理,生成最终决策图用于融合。为了提高图像块分类的精度,Tang等人(2018)将图像块分为聚焦、散焦和未知3类,对3类图像像素进行加权求和,得到源图像的得分图以生成决策图。Zhao等人(2021)为了提高边界区域的融合质量,解决边界像素属性难以判别的困难,提出了一种基于区域和像素的融合方法。首先对源图像进行分块,利用三分类网络将图像块分为聚焦、散焦和边界3类。然后利用边界网络对边界区域进行微调,得到二值决策图。Amin-Naji等人(2019)将集成学习的思想应用于多聚焦图像融合,利用多个CNN分别对源图像及其梯度图像进行分类,以进一步提高分类精度,该方法示意图如图2所示。Zhou等人(2021)基于梯度信息能直观反映图像边缘信息这一思想,将原始图像和其对应的4种梯度图像输入到5个CNN中,得到5个初始聚焦图,然后合并它们得到最终聚焦图。Guo等人(2018a)基于拉普拉斯能量对源图像进行聚焦度量得到聚焦信息图,然后利用深层神经网络对图像块进行分类得到决策图。Yang等人(2019)提出了一种基于多层特征卷积神经网络的方法,组合不同卷积层的特征图以提高分类精度。

图2 Amin-Naji等人(2019)提出的基于集成CNN的MFIF方法示意图
1.1.2 基于图像分割的方法
上述基于图像分块的方法由于分块操作往往忽略了图像的全局上下文信息,且相邻图像块的预测通常是相互独立的,导致得到的聚焦图或决策图存在空间不一致(连续)性,影响融合质量,尤其是聚焦区域和散焦区域之间边界区域的融合质量。为了解决这一问题,研究人员提出了一些基于图像(语义)分割的方法,将融合任务建模为聚焦区域的分割问题。Guo等人(2018b)提出了一种基于全卷积网络的融合方法,将整幅图像用于网络训练,输出与源图像大小相同的聚焦图。为此,设计了一种基于高斯滤波的方法,使用原始图像和聚焦/散焦分割图合成用于监督学习的训练图像。此外,该方法通过全连接条件随机场对决策图进行细化。Deshmukh等人(2018)将深度置信网络(deep belief network)应用于聚焦像素的检测,利用该网络判断像素类别,得到权重图,以进行加权融合生成融合结果。Xu等人(2020a)利用从源图像获得的梯度关系图构造损失函数,帮助网络快速收敛,提高决策图精度。
为了进一步提高聚焦边界区域的分割精度,研究人员提出了一些对边界进行优化的多聚焦图像融合方法。Ma等人(2019a)提出了一种级联的边界感知卷积神经网络用于多聚焦图像融合,如图3所示。该方法首先使用初始融合网络获得初始聚焦图,将像素分为聚焦、散焦和边界像素,并加权求和得到初始融合图;然后使用边界融合网络生成边界融合图像;最后二者相加得到最终融合结果。Xu等人(2020c)提出了一种边界优化算法对融合图像的边界进行优化。该方法首先对源图像进行聚焦图检测得到二分类聚焦图,根据聚焦图确定边界,最后使用边界优化算法优化融合结果中的边界。

图3 Ma等人(2019a)提出的基于边界感知CNN的MFIF方法示意图
除了直接对边界进行优化,一些学者提出了利用多尺度特征和注意力机制等技术提升边界分割精度的方法。Zhou等人(2019)提出一种基于金字塔场景解析网络(pyramid scene parsing network)的多聚焦图像融合方法,利用金字塔池化模块提取图像最后的多尺度特征,从而提高聚焦图预测的准确度。Xiao等人(2021)提出一种基于全局特征编码的U-Net模型,用于多聚焦图像融合,该网络引入了全局特征金字塔提取模块和全局注意力连接上采样模块,能有效提取和利用图像的全局语义信息。Liu等人(2021)提出一种基于多尺度特征交互网络的融合方法,网络结构如图4所示,通过对卷积神经网络提取的多尺度特征进行融合,并引入坐标注意力机制增强多尺度特征交互力度,提高聚焦图的分割精度。

图4 Liu等人(2021)提出的基于多尺度特征交互网络的MFIF方法示意图
除了利用卷积神经网络提取多尺度特征,一些方法通过多尺度分解提取多尺度特征。Wang等人(2019b)提出一种在离散小波变换域进行分割的方法,首先将源图像进行多尺度分解得到4个不同频率子带图像,然后将这些子带图像输入到不同网络,输出4个决策图以融合各个子带图像。Guo等人(2020)在卷积神经网络中引入了位置自注意力机制和通道自注意力机制,帮助卷积神经网络捕获更多的图像特征。此外,一些方法采用增强网络输入的方式来提高边界精度。Gao等人(2022)将一对源图像和对应的经拉普拉斯算子检测的特征图像一起输入到网络中,以准确区分聚焦区域和散焦区域的边界。
上述方法在网络训练时通常只是基于聚焦图的分割结果,为了进一步提升融合性能,一些方法将融合图像直接输出,并用于帮助网络训练。Lai等人(2019)将多尺度特征提取单元和视觉注意力单元作为网络的基本单元,然后网络输出聚焦图,利用聚焦图与源图像进行加权求和得到融合图像,方法示意图如图5所示。该方法在训练过程中计算融合图像与真实值(ground truth)之间的结构相似性(structural similarity, SSIM)作为损失函数,使融合图像直接参与到网络训练中。Li等人(2020)将融合图像与ground truth之间的结构相似性和梯度差异作为损失函数项,以进一步提高融合性能。Ma等人(2022)使用基于梯度的融合评价度量指标作为训练过程中的损失函数,并且设计了一种决策图校准策略以提高边界融合质量。Ma等人(2021b)提出一种自监督掩膜优化模型用于多聚焦图像融合。该方法设计了带引导滤波的引导块生成初始二值掩膜加快网络收敛,并且最小化融合图像与源图像间的梯度差异以迫使模型学习更精确的二值掩膜。

图5 Lai等人(2019)提出的基于多尺度视觉注意力深度CNN(MADCNN)的MFIF方法示意图
由于深度学习优越的特征表示能力,一些方法利用网络模型提取或增强源图像特征,然后度量这些特征的活跃程度得到决策图。Ma等人(2021a)提出一种基于无监督编码器—解码器网络的方法,采用网络中的编码器来获取源图像的深层特征,然后使用空间频率(spatial frequency,SF)度量活跃程度,得到决策图,最后对决策图进行一致性验证,得到融合结果。Song和Wu(2019)采用PCANet(principal component analysis network)提取图像特征,利用核范数生成源图像的活跃程度度量,得到决策图,最后使用加权融合得到融合图像。Liu等人(2022)提出一种基于超分辨重建网络的方法,首先利用深度残差网络对源图像进行超分辨重建,然后通过滚动引导滤波进行噪声平滑和边缘保持,最后利用基于结构梯度的聚焦区域检测算法生成决策图。
除了CNN模型,GAN也用于多聚焦图像融合领域。Guo等人(2019)最早提出了基于GAN的MFIF方法,示意图如图6所示。在该方法中,生成器的输出是一个聚焦决策图,除了与真实决策图计算二值交叉熵损失外,还设计了一个鉴别器模型,用于提高输出与真实决策图之间的相似性。Wang等人(2021b)针对多聚焦图像中的散焦扩散效应(defocus spread effect,DSE)(Xu等,2020d)提出一种基于GAN的多聚焦图像融合方法,该网络采用了挤压和激励残差模块,并在损失函数中添加了重构和梯度正则化以增强边界细节,提升融合质量。

图6 Guo等人(2019)提出的基于GAN的MFIF方法示意图
1.2 基于回归模型的方法
与上述基于分类模型的方法输出像素聚焦属性图不同,基于回归模型的方法使用网络模型预测输出融合图像,学习从源图像到融合图像的端到端映射。在此类方法中,网络框架通常包括特征提取、融合与重建3部分,类似于传统变换域方法的框架。根据网络模型学习方式的不同,本文将其进一步分为基于监督学习的方法和基于无监督学习的方法两类。表2列出了基于深度分类模型的主要融合方法。

表2 基于深度回归模型的多聚焦图像融合方法概述
1.2.1 基于监督学习的方法
Xu等人(2018)提出一种用于多聚焦图像融合的全卷积双路径网络,并采用高斯滤波来合成训练数据集。Zhang等人(2020b)提出一种包括特征提取、融合和重建3个阶段的端到端网络模型用于多聚焦图像融合,如图7所示。该方法利用深度信息和高斯模糊生成训练数据集,并采用感知损失进行网络训练。Zhao等人(2019)提出一种基于卷积神经网络的多层特征处理机制用于多聚焦图像融合,在不同层上进行特征提取、融合和重建。Yu等人(2022)提出一种双路径融合网络,在网络的特征提取模块中添加了大量的注意力机制。Zang等人(2021)设计了一种基于统一融合注意力的融合策略以获得更多信息,该融合策略由通道注意力和空间注意力构成。Deng和Dragotti(2021)提出一种用于图像融合的公共和唯一信息分离网络,该网络能提取源图像的公共特征和唯一特征。Wang等人(2022)提出一种两阶段渐进残差学习网络,该网络由初始融合块网络和增强融合块网络构成,初始融合块网络用于融合源图像中的颜色信息,增强融合块网络进一步融合细节特征。
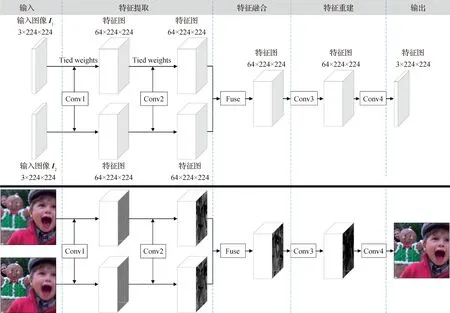
图7 Zhang等人(2020b)提出的基于CNN的通用图像融合框架
此外,GAN也用于基于深度回归模型的融合方法研究中。Huang等人(2020)提出一种基于GAN的端到端多聚焦图像融合方法,在网络模型中设计了一种自适应权重块,引导生成器自适应学习聚焦像素的分布,如图8所示。

图8 Huang等人(2020)提出的基于GAN的MFIF方法示意图
上述方法主要采用两分支输入方式,将源图像分别输入到对应的分支网络中,再通过一定的融合规则融合特征。此外,还有一些方法将源图像进行通道连接后再输入到网络。Li等人(2019a)提出一种U形端到端卷积网络,以提高多聚焦图像融合的特征提取能力,并设计了基于结构相似性的损失函数来训练网络。Pea等人(2019)提出一种基于沙漏网络(hourglass network)的多聚焦图像融合方法。
针对网络中特征融合策略存在的单一性问题,一些方法首先将源图像分解为多个尺度,为不同尺度设计不同的融合策略。Li等人(2019b)提出一种基于小波域的CNN用于多聚焦图像融合。在该方法中,源图像首先被小波变换分解为高频和低频图像,然后用两个网络对它们进行融合,最后逆变换得到融合图像。Cheng等人(2021)使用引导滤波将源图像分解为基础层和细节层,为两个层的特征设计了不同的融合策略。
1.2.2 基于无监督学习的方法
除了基于监督学习的融合方法,也有基于无监督学习的多聚焦图像融合方法,此类方法不需要人工构造融合图像的ground truth。Yan等人(2020)通过在融合图像与源图像之间设计基于结构相似性的损失函数,提出一种基于无监督卷积神经网络的多聚焦图像融合方法,如图9所示。Mustafa等人(2019b)将多尺度架构引入到端到端卷积神经网络模型中,用于无监督的多聚焦图像融合,并提出一种同时考虑像素差异和结构相似性的损失函数用于网络训练。Jung等人(2020)利用多通道图像对比度的结构张量表示,提出一种无监督损失函数。Xu等人(2022)通过持续学习(continual learning)技术提出一种无监督图像融合框架,用统一的网络解决多种类型的图像融合问题。Zhang等人(2021)提出一种基于无监督GAN模型的多聚焦图像融合方法,设计了一个自适应决策块来丰富融合图像的纹理细节。

图9 Yan等人(2020)提出的基于无监督CNN的MFIF方法示意图
2 实 验
实验对多种代表性多聚焦图像融合方法的性能进行比较与分析。在3个多聚焦图像数据集上,使用8个常用的客观评价指标对25种代表性融合方法(包括5种传统空间域方法、5种传统变换域方法和15种基于深度学习的方法)的性能进行对比。
2.1 数据集
使用3个多聚焦图像融合数据集进行实验,分别是Lytro数据集(Nejati等,2015)(https://www.researchgate.net/publication/291522937_Lytro_Multi-focus_Image_Dataset)、MFFW(multi-focus image fusion in the wild)数据集(Xu等,2020d)(https://www.researchgate.net/publication/350965471_MFFW)和Classic数据集(自行收集)(https://www.researchgate.net/publication/361556764_Classic-MFIF-dataset)。其中,Lytro和MFFW数据集分别包含20对彩色图像和13对彩色图像,Classic数据集包含多聚焦图像融合领域非常经典的20对灰度图像(与前两个数据集不重复)。图10展示了3个数据集中的源图像。

图10 实验中使用的3个多聚焦图像融合数据集
2.2 客观评价指标
2.3 对比方法
在实验中,选择了25种多聚焦图像融合方法进行性能比较,选取原则主要包括:1)方法具有较高的领域影响力或是最近提出的;2)方法的源代码在网上公开;3)所选方法尽可能全面地涵盖多聚焦图像融合方法的各个类别。表4列出了所选方法的详细信息,包括方法类型、简称和源代码链接。所选方法中包括5种传统变换域方法、5种传统空间域方法和15种基于深度学习的方法。更具体地,传统变换域方法中包括2种基于多尺度分解的方法:NSCT(nonsubsampled contourlet transform)(Yang等,2007)和GFF(guided filtering fusion)(Li等,2013a)、1种基于稀疏表示的方法:CSR(convolutional sparse representation)(Liu等,2016)、1种基于梯度域的方法:MWGF(multi-scale weighted gradient-based fusion)(Zhou等,2014)、1种基于不同变换组合的方法:NSCT-SR(nonsubsampled contourlet transform and sparse representation)(Liu等,2015a);传统空间域方法中包括1种基于分块的方法:QUADTREE(Bai等,2015)、4种基于像素的方法:DSIFT(dense scale invariant feature transform)(Liu等,2015b)、SRCF(sparse representation corresponding features)(Nejati等,2015)、GFDF(guided filter-based focus region detection for fusion)(Qiu等,2019)和BRW(boosted random walks)(Ma等,2019b);深度学习方法中包括10种基于分类模型的方法,其中CNN(Liu等,2017)和ECNN(ensemble of CNN)(Amin-Naji等,2019b)是基于图像分块的方法,GCF(gradients and connected regions based fusion)(Xu等,2020a)、MFF-SSIM(multi-focus image fusion based on structural similarity)(Xu等,2020c)、MSFIN(multiscale feature interactive network)(Liu等,2021)、MADCNN(multi-scale visual attention deep convolutional neural network)(Lai等,2019)、DRPL(deep regression pair learning)(Li等,2020)、GACN(gradient aware cascade network)(Ma等,2022)、SESF(squeeze excitation and spatial frequency)(Ma等,2020a)和SMFuse(self-supervised mask-optimization fuse)(Ma等,2021)是基于图像分割的方法,以及5种基于回归模型的方法,其中IFCNN(image fusion with convolutional neural network)(Zhang等,2020b)和R-PSNN(residual atrous pyramid pseudo-siamese neural network)(Jiang等,2021b)是基于监督学习的方法,FusionDN(densely connected network for fusion)(Xu等,2020b)、PMGI(proportional maintenance of gradient and intensity)(Zhang等,2020a)和U2Fusion(unified unsupervised image fusion)(Xu等,2022)是基于无监督学习的方法。所有方法均使用默认参数设置和作者提供的训练模型。

表3 实验中选择的25种方法
2.4 结果与讨论
表4—表6列出了不同融合方法在3个数据集上的客观评价结果,给出了每个数据集中所有测试图像的平均得分。可以发现,3个数据集上的结果在整体上具有较强的相似性,变换域方法在QE上更有优势,而空间域方法在其他指标上更具优势。5种变换域方法中并不存在具有明显优势的方法,整体定量性能差异不大。对于空间域方法,在大部分指标上都能获得非常有竞争力的性能。因此,综合来看,空间域方法的融合性能优于变换域方法,这是由于空间域法可以更好地保持源图像的原始聚焦信息,而变换域方法每个阶段都可能引入像素误差,导致融合性能的降低。

表4 不同融合方法在Lytro数据集上的客观性能
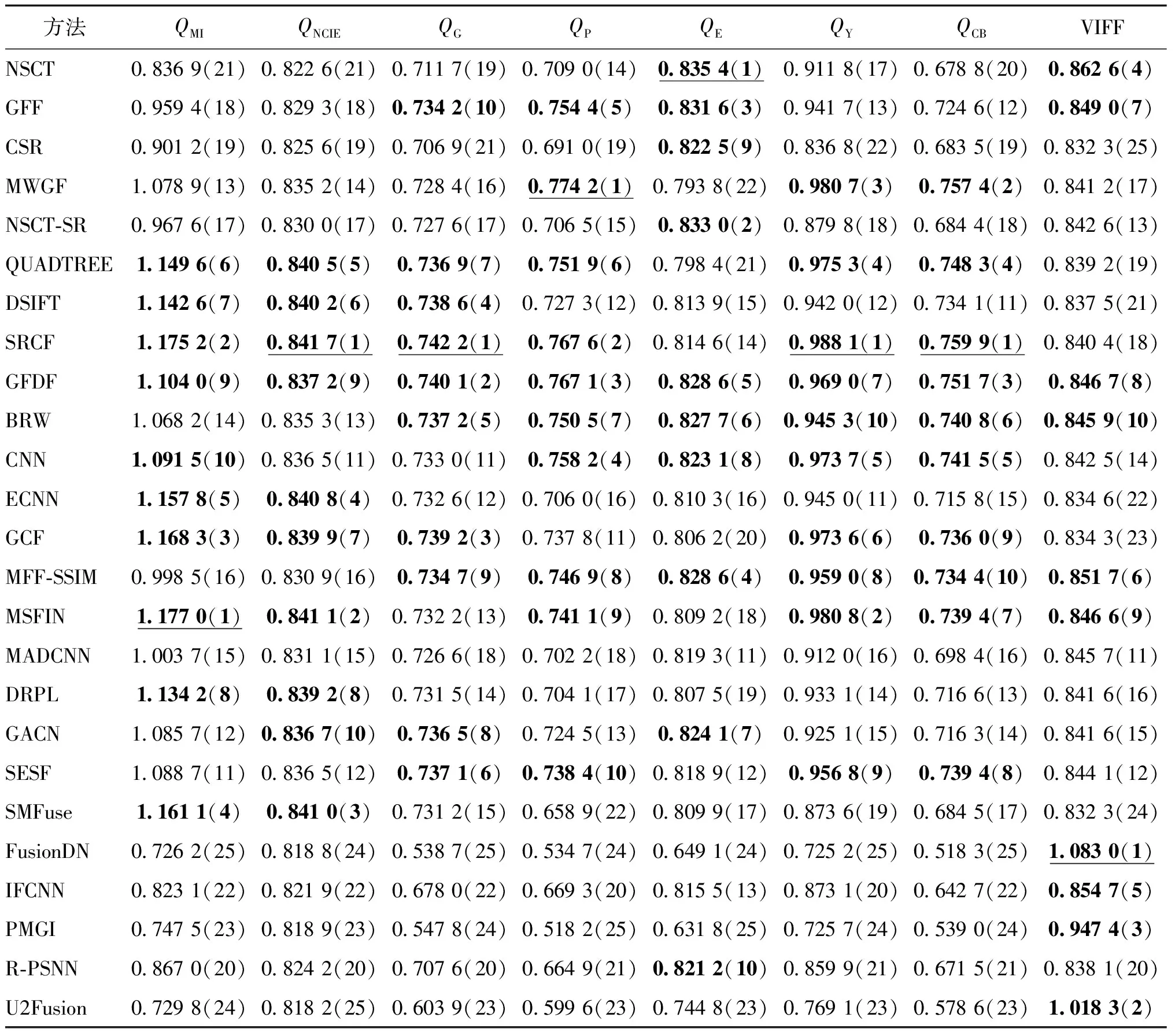
表5 不同融合方法在MFFW数据集上的客观性能

表6 不同融合方法在Classic数据集上的客观性能
在基于深度学习的方法中,基于回归模型的方法在指标VIFF上取得不错的结果,而基于分类模型的方法通常能在其他大多数指标上获得比基于回归模型的方法更好的性能。这是因为利用回归模型直接生成融合图像的过程可分为特征提取、融合和重建3个阶段,与变换域方法框架较为相似,受限于模型的预测精度,容易引入像素误差,而基于分类模型的方法与空间域方法框架类似,整体性能更好。在基于回归模型的方法中,有监督的方法(即IFCNN和R-PSNN)的结果普遍优于无监督的方法(即FusionDN、PMGI和U2Fusion),由此可见,监督学习的方式可以有效提升融合网络的性能。此外,从排名来看,将源图像由RGB转到YCbCr颜色空间的方法(即FusionDN、PMGI和U2Fusion)在VIFF指标上的结果明显优于其他使用RGB源图像作为网络输入的方法(即IFCNN和R-PSNN),这表明对源图像的Y分量进行融合能有效提高融合结果的视觉信息保真度。而在基于分类模型的方法中,有一致性验证等后处理操作的方法(如CNN、GCF、MFF-SSIM、MSFIN和SESF)一般能取得比没有后处理的方法(如ECNN、MADCNN、DRPL、GACN和SMFuse)更好的融合性能。但是,所有方法都无法在3个数据集中排名前10。例如,MSFIN在Lytro数据集中所有指标都排名前10,但是在MFFW和Classic数据集中所有指标都未排进前10。这表明多聚焦图像融合方法研究仍有较大的提升空间。通过比较各方法每个指标的值可以发现,深度学习方法的整体性能与优秀的传统方法相当甚至略低,并未展现明显优势,主要原因之一是多聚焦图像融合领域缺乏大规模可用于训练的真实数据集,通常采用的人工合成训练数据的方式与真实多聚焦图像之间存在差异,导致训练得到的深度学习模型泛化能力不足,在真实多聚焦图像数据集上的性能受限。
图11—图13展示了不同融合方法在3个数据集中一组测试图像上的融合结果。由图11可以看出,对于较为简单的Lytro数据集而言,几乎所有融合方法获得的融合图像都具有良好的视觉效果,不同方法之间的差异相对较小。由图12可以看出,在MFFW数据集中,源图像存在明显的散焦扩散效应(DSE)(Xu等,2020d),聚焦边界像素的处理难度较高,几乎所有方法在边界区域都未能获得令人满意的结果,存在较为严重的伪边缘现象,影响了视觉质量。MFF-SSIM方法的结果相对较好,这是因为该方法对边界区域进行了特别的优化。由图13可以看出,在Classic数据集给出的示例中,源图像之前没有进行精确的配准,导致大多数传统变换域方法和基于深度回归模型的方法融合质量不够理想,在一些区域存在明显的细节模糊现象,空间域法和基于深度分类模型的方法相对而言融合效果较好。

图11 不同方法在Lytro数据集中示例图像瓶子上的融合结果

图12 不同方法在MFFW数据集中示例图像咖啡杯上的融合结果

图13 不同方法在Classic数据集中示例图像石狮子上的融合结果
表7列出了不同方法融合一对520 × 520像素的彩色图像消耗的平均运行时间。使用Lytro数据集中20对520 × 520像素的图像进行统计,计算平均运行时间。实验使用的计算机硬件配置是Intel CoreTMi9-10900X CPU,NVIDIA GeForce RTX 2080Ti GPU,128 MB RAM。在25种方法中,NSCT、GFF、CSR、MWGF、NSCT-SR、QUADYREE、DSIFT、SRCF、GFDF、BRW和CNN在MATLAB环境下仅以CPU串行方式运行,ECNN、GCF、MFF-SSIM、MSFIN、MADCNN、DRPL、GACN、SESF、SMFuse、FusionDN、IFCNN、PMGI、R-PSNN和U2Fusion在Python环境下使用GPU并行加速方式运行。
由表7可以看出,得益于GPU加速,大多数深度学习方法的计算效率较高,而个别方法由于分块融合方式(如ECNN)或在CPU下实现(如CNN),运行时间较长。在传统方法中,使用到稀疏表示模型的相关方法运行效率一般较低,如NSCT-SR和CSR。
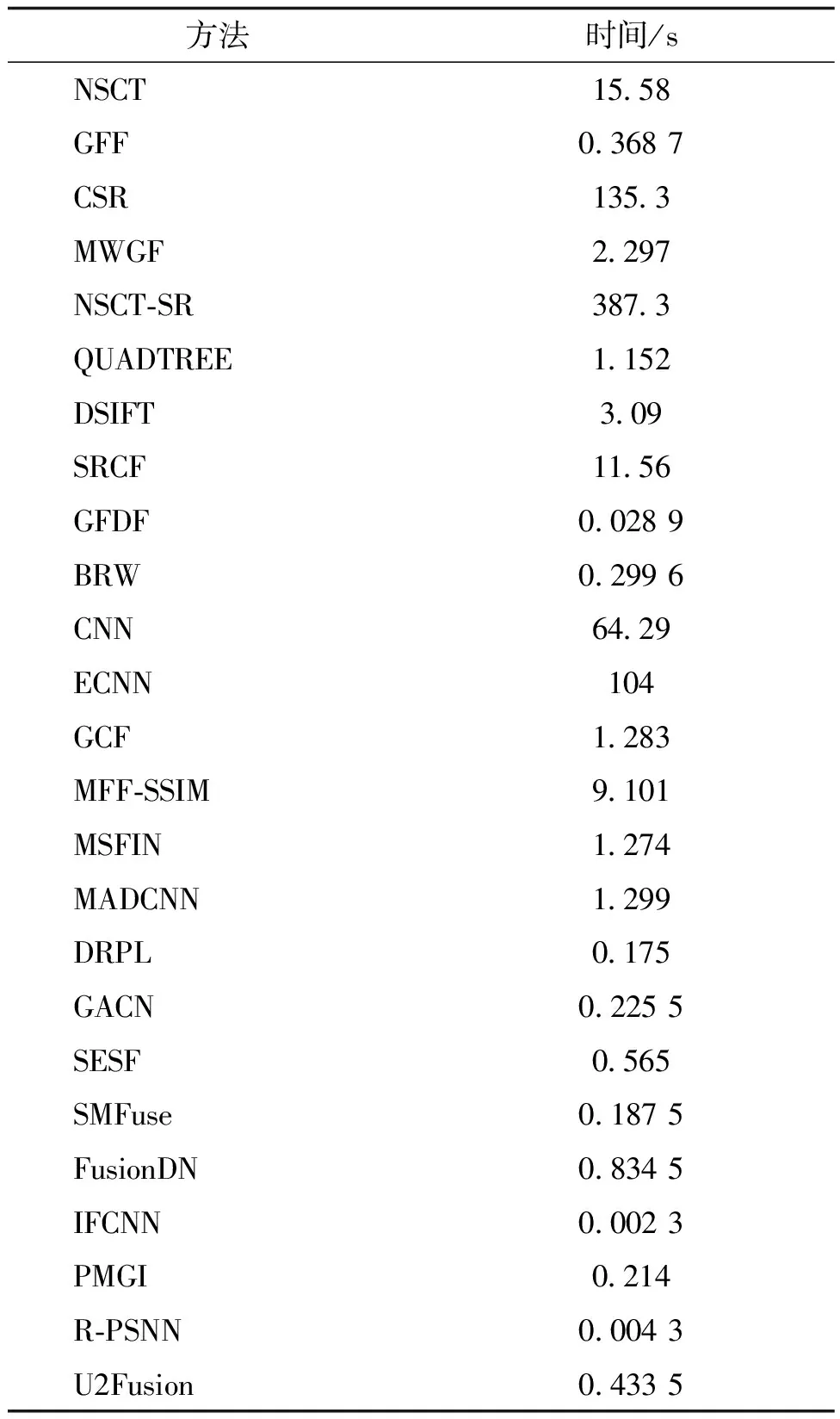
表7 不同方法融合一对520×520像素彩色图像的平均运行时间
3 结 语
本文对基于深度学习的多聚焦图像融合方法进行了全面综述,将现有方法分为基于深度分类模型的方法和基于深度回归模型的方法,并介绍了相关的代表性方法。此外,对25种具有代表性的多聚焦图像融合方法进行了实验性能验证与对比,实验中使用了3个多聚焦图像融合数据集和8个常用的客观质量评价指标。尽管近年来基于深度学习的多聚焦图像融合方法研究取得了很大进展,但实验结果表明这些新方法与传统融合方法相比并未表现出明显优势,该方向仍存在一些挑战性问题需要解决,未来工作可以从以下几个方面开展:
1)聚焦边界区域的融合。边界区域表示源图像中聚焦区域与散焦区域之间的区域,通常位于景深突变的区域。边界区域的聚焦特性很复杂,因为在源图像中一些像素可能会聚焦,而一些像素可能会散焦,并且边界形状总是不规则的。此外,在不同的源图像中,边界周围的像素通常具有不同的清晰度,存在所谓的散焦扩散效应(DSE)(Xu等,2020d),给边界像素的处理带来了很大挑战。因此,边界区域的融合是多聚焦图像融合中的一个难点,对融合图像的视觉质量有着至关重要的影响,提升边界区域的融合质量是未来一个值得深入研究的方向。
2)未精确配准情况下的融合方法。现有绝大多数多聚焦图像融合方法研究均假设源图像之间已经进行了精确的空间配准,对于低配准精度情况下的研究还十分有限,很多方法在融合未精确配准的源图像时性能显著下降。因此,在设计融合方法时,如何提升对未精确配准情况的鲁棒性,获得高质量的融合效果,也是该领域未来一个值得深入研究的方向。
3)具有真实标签的大规模训练数据集的构造。目前多聚焦图像融合领域缺乏大规模的真实训练数据集,大部分基于深度学习的方法往往只能通过人工模糊的方式合成数据集,然而这种方式忽略了真实多聚焦图像中的散焦扩散效应等很多特点,导致深度模型性能无法充分发挥,这一点从上述实验结果中可以明显看出。因此,构造大规模的真实训练数据集对于未来基于深度学习的多聚焦图像融合研究也具有重要意义。
4)网络模型以及网络的学习方式的改进。目前基于深度学习的多聚焦图像融合方法中使用的网络结构和损失函数相对比较简单,特别是对于聚焦边界区域缺乏精细化的处理,训练方式也较为单一。在未来研究中,网络结构、损失函数和训练方式等方面仍具有很大的改进空间。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
儿童时代·幸福宝宝(2021年11期)2021-12-21
北京航空航天大学学报(2021年9期)2021-11-02
小学科学(学生版)(2021年4期)2021-07-23
现代装饰(2020年4期)2020-05-20
电子制作(2019年13期)2020-01-14
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
证券法律评论(2018年0期)2018-08-31
北京航空航天大学学报(2018年1期)2018-04-20
