
结合VMD符号熵与SVDD的滚动轴承性能退化评估
2023-02-16 12:39:02周建民熊文豪尹文豪李家辉高森
机械科学与技术 2023年1期
周建民, 熊文豪, 尹文豪, 李家辉, 高森
(1. 华东交通大学 机电与车辆工程学院,南昌 330013;2. 载运工具与装备教育部重点实验室,南昌 330013)
滚动轴承是机械设备中的重要组成部分,机械设备的工作状态与轴承运行状态直接相关,若能准确并且及时诊断出轴承运行过程中故障与状态,对保障机械系统安全运行,减少或者避免重大灾难事故的发生具有重大意义[1]。同时,如果可以对设备性能退化的过程中监测到该设备所退化的程度,那么就能够制定合理的计划对设备进行维修。滚动轴承的性能退化评估正是基于此所提出的一种方法,它侧重对设备全寿命周期中退化程度的度量,而不是过多集中关注某一时间点的故障类型[2]。通过采集滚动轴承全寿命数据,并对数据进行分析与处理,评估设备退化的程度,便能够对设备制定合理的维修方案。
经验模态分解(Empirical mode decomposition, EMD)是信号特征提取常用的一种方法[3],但是其存在的模态混叠[4]等不足之处很大程度上限制了其发展。变分模态分解(Variational mode decomposition, VMD)[5]在2014年由Konstantin Dragomiretskiy提出,是一种非递归的自适应信号分析方法。它的分解方法是提前设定好模态分量个数,并且假设每个模态分量都存在着一个中心频率,并利用中心频率来确定每个模态分量,该方法有坚实的理论基础,可以有效抑制EMD中模态混叠的问题。目前基于此方法在机械故障领域中有着不错的效果[6-8]。
由于轴承振动信号的非线性、非平稳性等特点,许多非线性信号方法,如近似熵[9]、样本熵[10]、排列熵[11]等在机械故障领域中有着广泛的应用。将时间序列符号化是从符号动力学理论[12]发展起来的一种分析方法,同样是一种有效的复杂性分析方法,其具有计算速度快,同时可以捕捉信号中非线性特性,陈晓平[13]等已将符号熵运用于机械的故障诊断中。
支持向量数据描述(Support vector data description, SVDD)[14-15]常用于滚动轴承的性能退化评估方面,是由Tax等提出的一种有效的单值分类(One-class Classification)方法。该模型的训练只需一种类型目标样本,通过该训练样本建立超球体模型,轴承正常数据则在球体内部,非正常轴承样本数据则在球体外[16],通过检测未知样本与超球体球心的距离,便可得到性能退化评估曲线。该模型解决了机械故障数据缺乏的问题,同时还有较好的鲁棒性。
综上所述,本文提出了结合VMD符号熵和SVDD的滚动轴承性能退化评估。将原始信号经过VMD方法分解得到若干模态分量,计算各模态分量的符号熵,并采用双样本Z值对各个分量符号熵进行评价,最后选取双样本Z值最大的分量符号熵作为特征向量,再从其中选择正常样本数据作为SVDD模型的训练,通过全寿命数据进行验证,从而实现了滚动轴承的性能退化评估。验证结果表明,本文所提方法可以准确描述轴承的性能退化状态,与其它方法比较,具有一定优越性。
1 变分模态分解原理
变分模态分解的核心思想是通过构造变分问题,依据提前设定的模态分量个数,在其变分框架中不断更新各个模态分量的中心频率以及带宽,最后将原始信号自适应地分解成K个IMF函数。求解步骤如下:
步骤1 构造变分问题
1) 根据提前设定好的K值,将原始信号f(t)分解成K个IMF分量uk(t),并对以上每个模态分量进行Hilbert变换得其解析信号
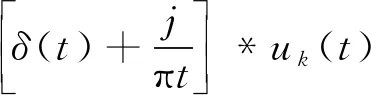
(1)
2) 对以上所得解析信号与预估的中心频率ωk进行混合,将各IMF函数的频谱调制到相应的基频带上
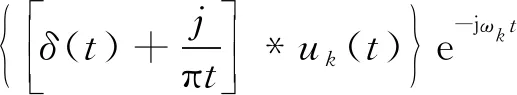
(2)
3) 在使得各个IMF分量相加之和等于原始信号f(t)的约束条件下,计算上述公式中解调信号的梯度平方L2的范数,构造的变分问题如下:
(3)
式中:{uk},{ωk}分别为各个固有模态函数及其中心频率。
步骤2 求解变分问题
1) 为求出式(3)约束变分问题的最优解,需要引入拉格朗日乘子λ(t)和二次惩罚因子α,将式(3)转化为无约束变分问题:
L({uk(t)},{ωk},λ(t))=
(4)
2) 采用乘法算子交替方向法,通过多次迭代更新求解出式(4)的鞍点,具体步骤如下:
(2) 迭代更新参数
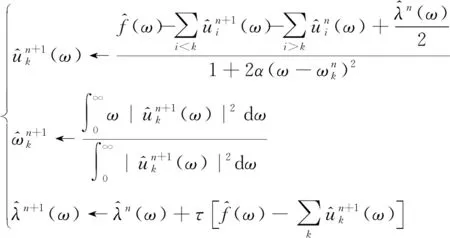
(5)
(3) 重复步骤二,直至满足以下迭代条件

(6)
(4) 将得到的uk(ω)经傅里叶逆变换得uk(t),便可得到K个IMF分量uk(t)。
2 符号熵原理
符号动力学分析可以更好把握序列的整体趋势。为进一步了解时间序列的总体结构,将其二进制化,可以得到符号序列{sn}
(7)
式中m0为IMF均值。
符号熵计算示例图如图1所示。
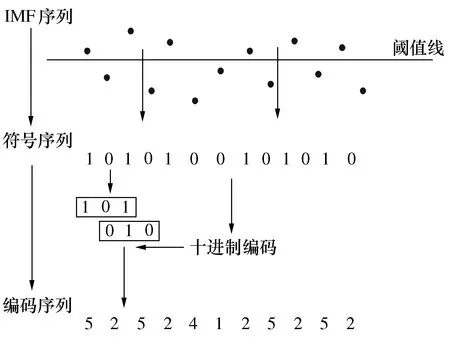
图1 符号熵计算示例图
由图1所示可知:当时间序列超过了阈值线,便会符号化为1,反之符号化为0。
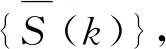

k=1,2,…,N-(L-1)τ
(8)
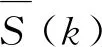
由此,引入反映时间序列总体特征的信息熵-Shannon熵,其改进后的熵值公式为
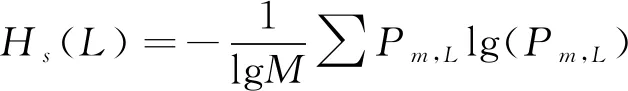
(9)
式中:Hs(L)为短符号序列长度为L的符号熵;Pm,L表示编码序列中,各个符号编码所对应的概率;M为符号序列序列中出现不同编码的总数。可以看出,当且仅当某个编码出现概率为1时,Hs(L)=0;当编码序列中各个编码出现的概率相等时,Hs(L)=1。由此可以看出,Hs(L)越大,原始时间序列的不稳定性也就越大;反之Hs(L)越小,可以确定时间序列的某种编码出现概率越大,则说明时间序列越稳定。基于此,说明符号熵大小可以来度量时间序列的不确定程度大小。
3 支持向量数据描述
SVDD是一种有效解决单值分类问题的方法。其核心思想是对目标样本进行训练,将目标样本通过非线性映射φ,使其在高维特征空间中寻找一个包含全部或者大部分目标样本的最小超球体,尽量使得目标样本尽量在该最小超球体内,而非目标样本则位于超球体外。其具体数学模型如下:
对于目标样本,将其映射到高维空间中,寻找一个包含全部或者几乎全部上述目标样本的超球体,定义该超球体半径为R,球心为a。为了减少目标样本中的野点对超球体的影响,在这里引入松弛因子ξ和惩罚参数C,允许目标样本中部分样点分布于超球体之外。因此,SVDD优化问题如下:

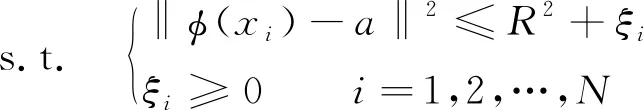
(10)
为解决上述最小优化问题,构造朗格朗日方程
(αi,γi≥0)
(11)
式中:αi,γi均为拉格朗日系数。
对式(11)中的R,a和ξi分别求其偏导并令其等于零,再代入式(10)中,则式(10)的最小化问题转化成如下形式:
s.t. ∑αi=1 0≤αi≤C
(12)
式中:K(xi,xj)为核函数,通常在SVDD方法中,选用高斯核函数
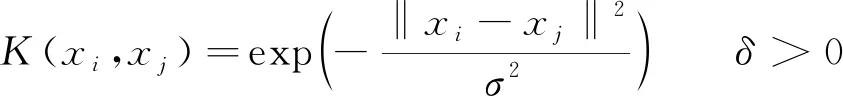
(13)
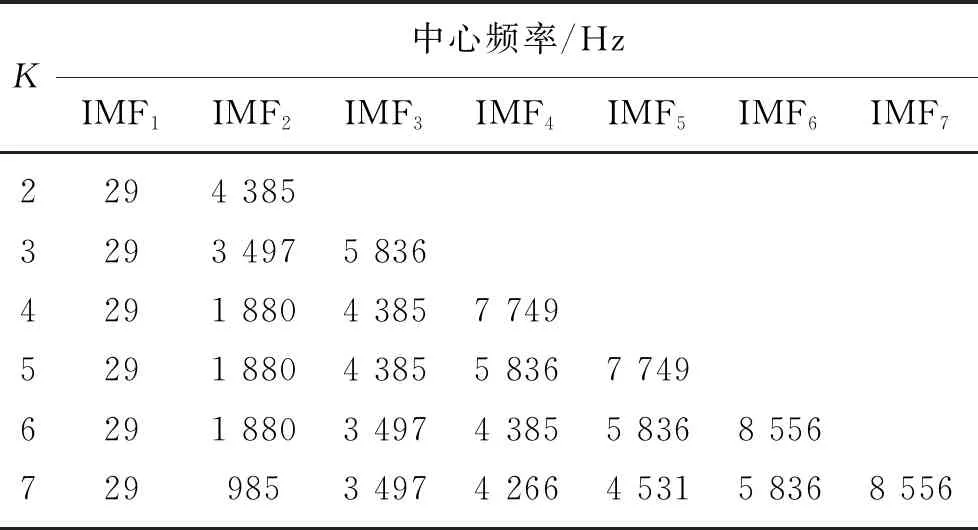
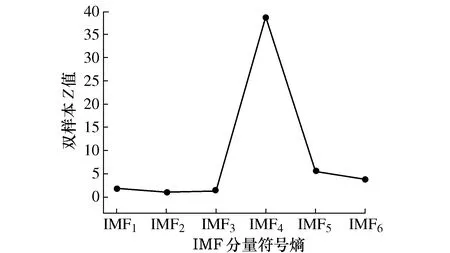
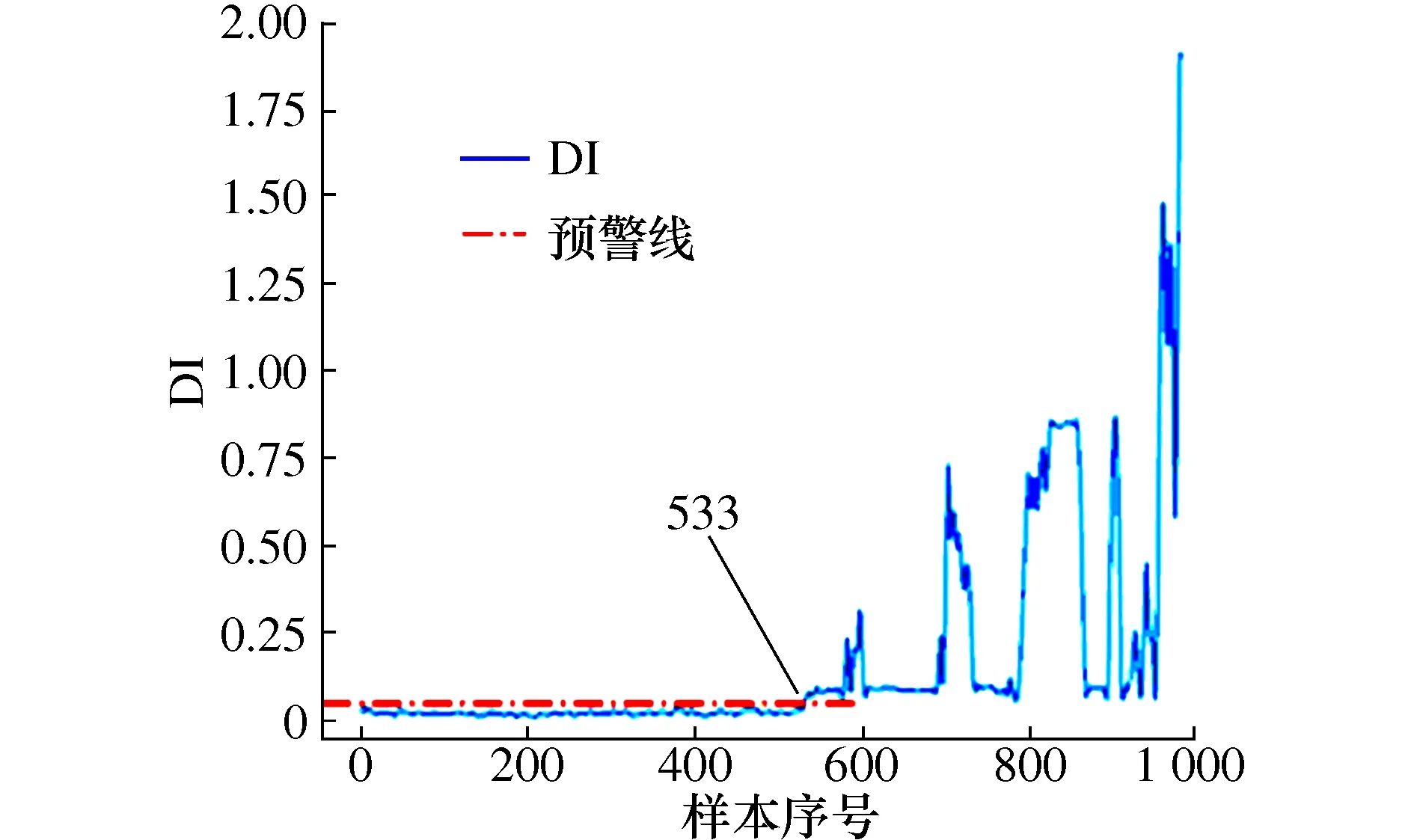
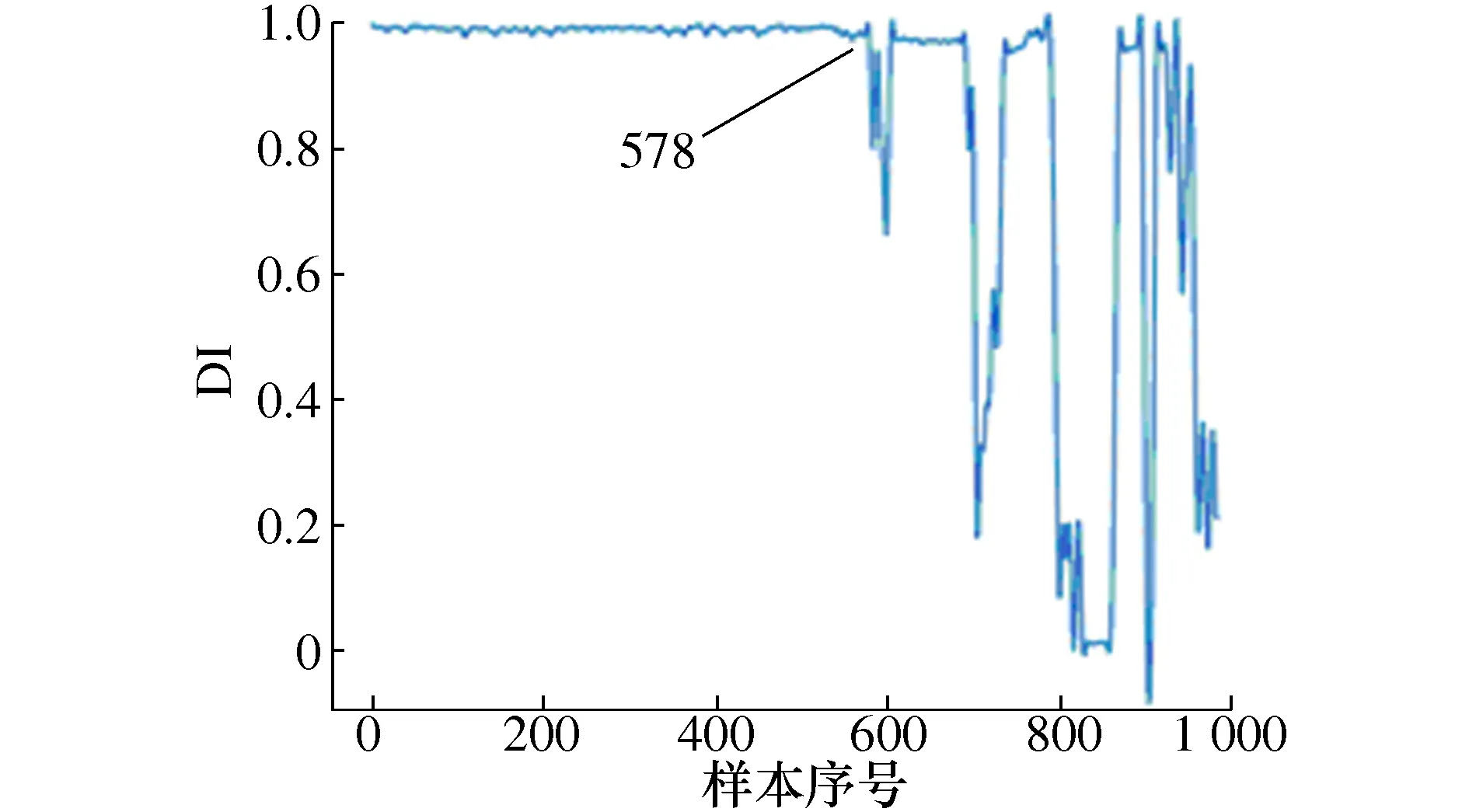
当=0时,样本位于超球体内;当0<αi R2=‖φ(xsv)-a‖2=K(xsv,xsv)- (14) 对于任意样本z,它与超球体球心的距离D的计算公式为 (15) 此时,比较D与R值的大小,能够分析出任意样本是否位于超球体内、边界或者外。 在对轴承进行性能退化评估时,先将一部分正常样本作为SVDD的目标样本进行训练,此时,可以得到超球体的半径R和球心a。然后将剩余轴承数据样本输入到该确定的超球体模型中,可以得到每个样本与超球体球心的距离D,通过判断D与R的差值,可以分析出轴承的工作状态。当D小于等于R时,说明轴承正常工作;当D大于R时,说明该轴承出现了故障,D越大说明轴承的故障程度越深。因此,该方法可以有效地判断出轴承当前的工作状态。 对滚动轴承全寿命进行VMD分解之前,需要确定IMF分量的个数K。如果K过小,则信号中的信息不能被完全提取出来;若K过大,则会产生模态混叠现象。因此,K的取值异常关键。本文将通过观察不同K值下的各IMF分量的中心频率来确定K的取值。K依次增大,各IMF分量的中心频率将会越来越接近,通过此来判断分解是否合理,便可确定K的取值。任意选取全寿命数据中的一组,这里以第200组数据为例,对该组数据进行VMD分解,随着K的增大,各个IMF分量的中心频率也在改变,如表1所示。当K=7时,IMF4与IMF5的中心频率分别为4 266 Hz、4 531 Hz,可以看出这两者的中心频率十分接近,存在着信号被过分解的风险。因此,当K值大于7时,信号都有被过分解的风险。但若K值过小,分解出来的信号又不足以表征原始信号中的成分。综上所述,选取K值为6作为本文VMD分解的模态个数。 表1 不同K值下的IMF分量中心频率 为了更好比较出各个分量符号熵的优劣程度,以及更早提前发现早期故障,本文采用双样本Z值[18]评估特征的差异。特征值的Z值越大,说明区分正常样本与故障样本的能力越强,反之亦然。双样本Z值定义为 (16) 采集故障轴承正常样本与早期故障各50个,计算其IMF分量符号熵的双样本Z值,如图2所示。 图2 IMF分量符号熵双样本Z值大小 从图2可以看出,IMF分量符号熵的双样本Z值位于IMF4处有最大值,其余IMF分量双样本Z值相比之下都比较小,即意味着其对正常样本与早期故障样本的区分并不明显,因此,本文选用IMF4分量符号熵作为特征指标。 对于滚动轴承从开始正常运行到完全失效全寿命样本,为了更好获取该轴承的性能退化程度,本文提出了基于VMD符号熵和SVDD结合的性能退化评估方法,流程图如图3所示。 图3 性能退化评估流程图 其具体步骤如下: 步骤1 对轴承全寿命数据进行6层分解,提取双样本Z值大小最高的IMF分量符号熵作为特征指标。 步骤2 利用全寿命数据中正常信号的综合特征指标作为目标样本训练,经SVDD可得出最小超球体模型,以及球心a和球半径R。 步骤3 计算全寿命样本特征综合指标Vt,将其作为SVDD的输入,计算特征综合指标与超球体球心之间的距离d,即可得到性能退化指标(Degradation index,DI)。并将此作为性能退化评估的依据。 本文使用的滚动轴承全寿命周期试验数据来自于Cincinnati大学IMS(智能维护系统),疲劳寿命试验台以及传感器布置图如图4和图5所示。实验中,轴的转速为2 000 r/min,轴承振动信号由加速度传感器每隔10 min采集一次,数据采样频率为20 kHz,采集时长约达164 h。最终,以轴承1出现外圈故障导致轴承失效而停止采集,共采集到轴承全寿命周期984组样本。经计算,该轴承外圈故障特征频率约为236 Hz。 图4 试验台传感器布置图 图5 试验台示意图 根据所选取的IMF分量符号熵,大致可以分析出前一段时间的符号熵基本不变,因此,选取全寿命轴承信号的前300组样本进行SVDD训练,训练后所得超球体半径R=0.133。将全寿命984组样本数据输入训练所得的超球体模型中,得到的每个样本到球心的距离D的变化趋势,如图6所示。 图6 基于VMD符号熵性能退化评估曲线图 从图6可以看出,在运行的前5 320 min期间,样本DI值均在预警线以下,说明滚动轴承处于正常工作状态。在第5 330 min时,第一次超过预警线,此时说明轴承发生了早期及其轻微的故障,直到第7 000 min时,轴承的DI值发生了急剧的变化,说明轴承已经出现了反复磨损和破坏加深,随后的DI值变化毫无规律,基本已经处于严重故障状态,直至第9 670 min,轴承已完全失效。 为了验证上述结果,对上述所说关键时间点信号进行包络谱分析,分别对第5 320 min、5 330 min、7 000 min的振动信号做包络谱分析。如图7和图8所示,在第5 330 min时,可以检测到故障频率为230 Hz及其倍频461 Hz,但在第5 320 min时,并无显现出故障频率。因此,可以认为在第5 330 min时发生了第一次外圈故障。 图7 第5 320 min包络谱 图8 第5 330 min包络谱 为了验证本文所提符号熵与排列熵特征优劣,使用式(16)中特征评价指标进行评估,分别计算不同IMF分量下熵的双样本Z值。选取双样本Z值最大作为特征提取的依据,经计算可得,IMF分量排列熵的双样本Z值最大值为31.34,与符号熵的双样本Z值相差有7.22左右,由此可以看出符号熵区分能力优于排列熵。 为了进一步说明符号熵与排列熵的特征差异,将排列熵中双样本Z值最大的作为输入特征向量,得到性能退化评估曲线图,如图9所示。可以看出,排列熵与符号熵都可以准确早期故障样本点,而且有着类似的变化趋势,但是排列熵区分早期故障的能力明显不如符号熵,只有在轴承恶化阶段DI值才急剧变化,这样不利于及时做出维修的策略。 图9 基于VMD排列熵性能退化评估曲线图 为进一步证明本文所提方法的优越性,将评估模型替换成FCM模型。具体流程如下:选取全寿命周期的正常运行状态和故障状态的VMD符号熵作为训练样本,得到两个聚类中心,再将全寿命周期的所有数据作为测试样本,得到与正常样本特征的隶属度,将其作为性能退化评估指标DI,DI属于[0, 1],得到性能退化评估曲线,见图10。 图10 基于FCM排列熵性能退化评估曲线图 图10的评估曲线变化与图6大致相同,表示轴承在开始运行的一段时间内,都趋于平稳;之后曲线开始缓慢抖动,表明发生了轻微故障;当进入某一个时间点时,曲线晃动剧烈,说明已经发生了重度故障,直至失效。由图10可分看出,轴承发生早期故障的时间点在第5 780 min,与图5中5 330 min足足晚了450 min,在实际故障维修中有着重大意义。因此,本文所提方法对发现轴承的早期故障明显优于FCM评估模型。 1) 对振动信号进行VMD分解,计算各IMF分量的符号熵,引用双样本Z值进行筛选,可以得到较好的轴承性能退化情况。 2) 分别使用排列熵特征提取方法、FCM退化模型与本文所提出的VMD符号熵特征提取方法做对比,进一步验证了本文方法的优越性。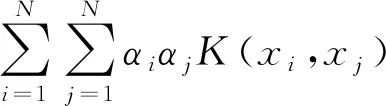
4 结合VMD符号熵和SVDD结合的性能退化评估方法
4.1 特征指标的选择
4.2 特征评价

4.3 性能退化评估流程
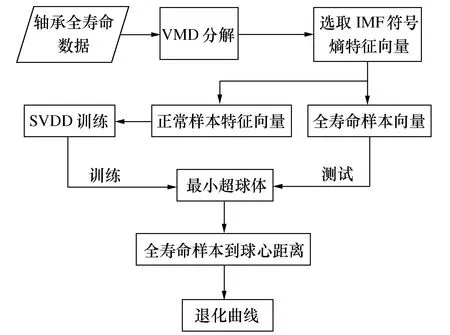
5 实验验证与分析
5.1 试验台介绍

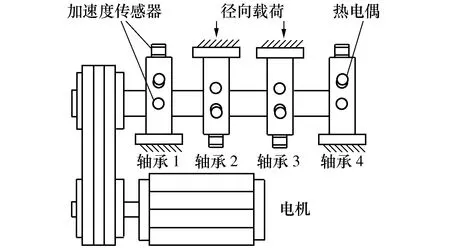
5.2 结合VMD符号熵和SVDD的滚动轴承性能退化评估

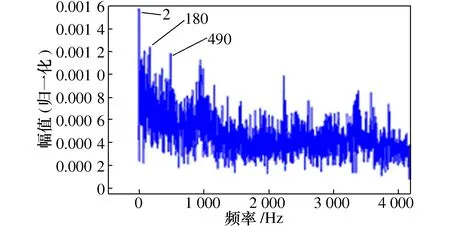
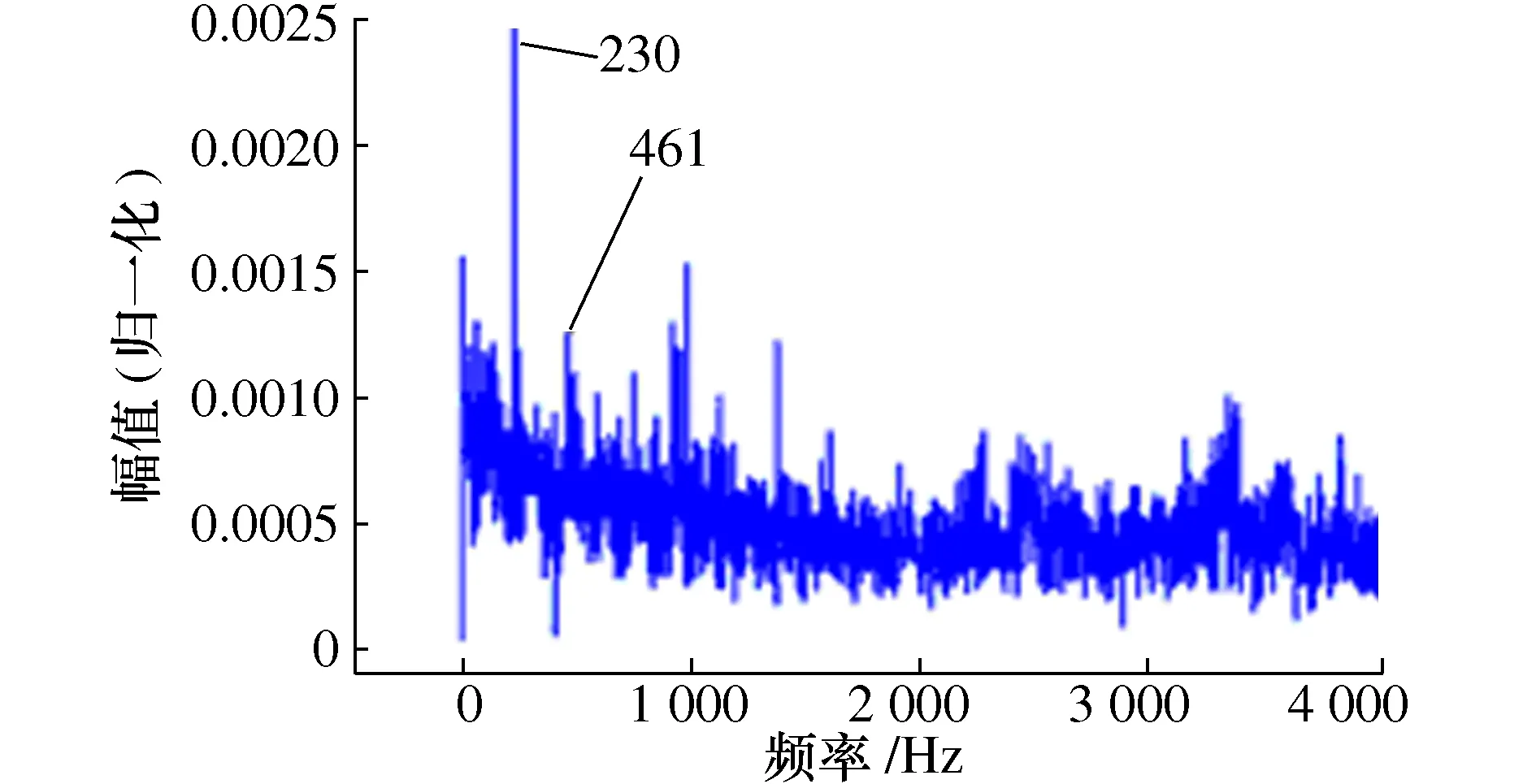
5.3 结合VMD排列熵和SVDD的滚动轴承性能退化评估
5.4 结合VMD符号熵和FCM的滚动轴承性能退化评估
6 结论
猜你喜欢
哈尔滨轴承(2022年2期)2022-07-22 06:39:32
哈尔滨轴承(2022年1期)2022-05-23 13:13:24
哈尔滨轴承(2021年2期)2021-08-12 06:11:46
哈尔滨轴承(2021年1期)2021-07-21 05:43:16
基层中医药(2021年12期)2021-06-05 06:56:26
消费电子(2020年5期)2020-12-28 06:58:27
智族GQ(2019年9期)2019-10-28 08:16:21
英美文学研究论丛(2018年1期)2018-08-16 03:00:06
池州学院学报(2017年5期)2018-01-23 02:54:31
纺织科学研究(2017年6期)2017-07-03 12:14:15
