
基于改进强化学习的移动机器人动态避障方法
2023-02-16 01:22徐建华邵康康王佳惠刘学聪
中国惯性技术学报 2023年1期
徐建华,邵康康,王佳惠,刘学聪
(北京理工大学 自动化学院,北京 100081)
移动机器人由于具备环境感知、行为决策及运动控制等能力,被广泛用于智能清洁、农田作业、军事探测等领域。动态避障是移动机器人领域研究的热点和难点,是指移动机器人能够根据传感器信息,按照一定的方法有效地避开动态障碍物并到达终点[1]。动态避障方法主要有模型驱动和数据驱动两大类。模型驱动类型包括Bug 算法[2]、A*算法、动态窗口法[3](Dynamic Window Approach,DWA)和速度障碍法[4](Velocity Obstacles,VO),它们的特点是通过确定性规则解算避障策略,难以适用于复杂环境下的移动机器人动态避障任务[5]。
强化学习方法属于数据驱动类型,通过移动机器人不断与环境交互获得最优避障策略,避免对确定性规则的依赖[6]。智能体通过与环境进行交互来获取状态和奖赏,并执行动作,环境再将新的状态和此动作的奖赏反馈于智能体,如图1 所示。2013 年DeepMind公司发表了深度Q 网络算法(Deep Q-Network,DQN)以来,强化学习方法取得了非常快速的发展。
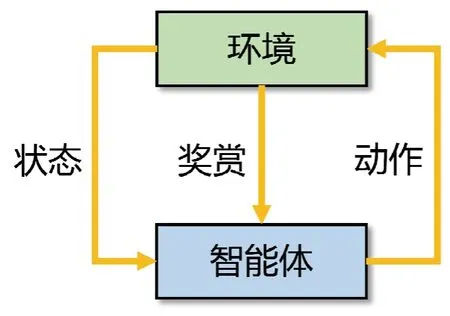
图1 强化学习结构图Fig.1 Structure chart of reinforcement learning
Jiang 等[7]提出一种具有经验回放和启发式搜索的深度Q 网络,解决了强化学习中Q 表的“维度灾难”问题,但未考虑动态障碍物对避障策略的影响。Xie等[8]提出了一个新的框架,结合启发式学习,可以有效克服深度强化学习中的高方差问题,但未考虑稀疏奖赏对训练的影响,导致算法收敛速度较慢。Wu 等[9]提出了一种以深度图像为输入的端到端模型,便于从仿真环境部署到更复杂的现实世界场景中,但是以深度像为输入的算法对计算性能要求较高。
为解决移动机器人在复杂动态环境的避障问题,本文提出一种改进的强化学习算法。移动机器人根据自身速度、目标位置和激光雷达信息直接得到动作信号,实现端到端的控制。首先,对观测空间和动作空间进行优化,增强在动态障碍物环境中的行驶能力;其次,基于距离梯度引导和角度梯度引导促使移动机器人向终点方向优化,加快算法的收敛速度;再次,利用柔性演员评论家算法[10](Soft Actor-Critic,SAC)结合卷积神经网络从多维观测数据中提取高质量特征,提升策略训练效果;最后,设计多种仿真试验验证本文方法的有效性和优越性。
1 传统SAC 算法
SAC 算法是一种适合连续动作空间的强化学习算法,其最大的特点是具有带熵累计奖赏J′(π):
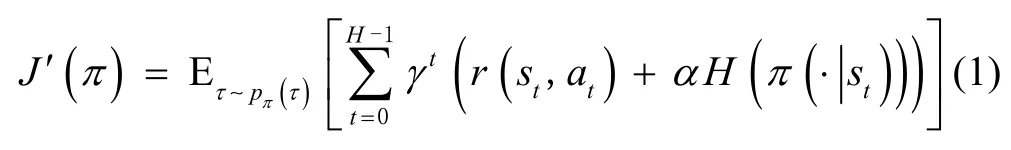
式中,τ表示一条轨迹,π表示策略,pπ(τ)为执行策略π时采样到的轨迹分布。H为轨迹时间,γt为t时刻折扣因子,at为t时刻动作,r(st,at)为t时刻奖赏函数。即为添加的熵项,α为熵项的权重即温度系数,根据信息熵的定义,状态st下选择的动作分布越分散,熵项越大。因此加入信息熵可以促使算法同时探索多种最优的策略,避免了反复选择同一个动作而陷入次优[11]。同时通过最大化奖赏,放弃明显没有前途的策略。
SAC 算法的网络结构如图2 所示,由1 个演员网络、2 个评论家网络和2 个目标评论家网络组成。SAC算法的具体流程如下:
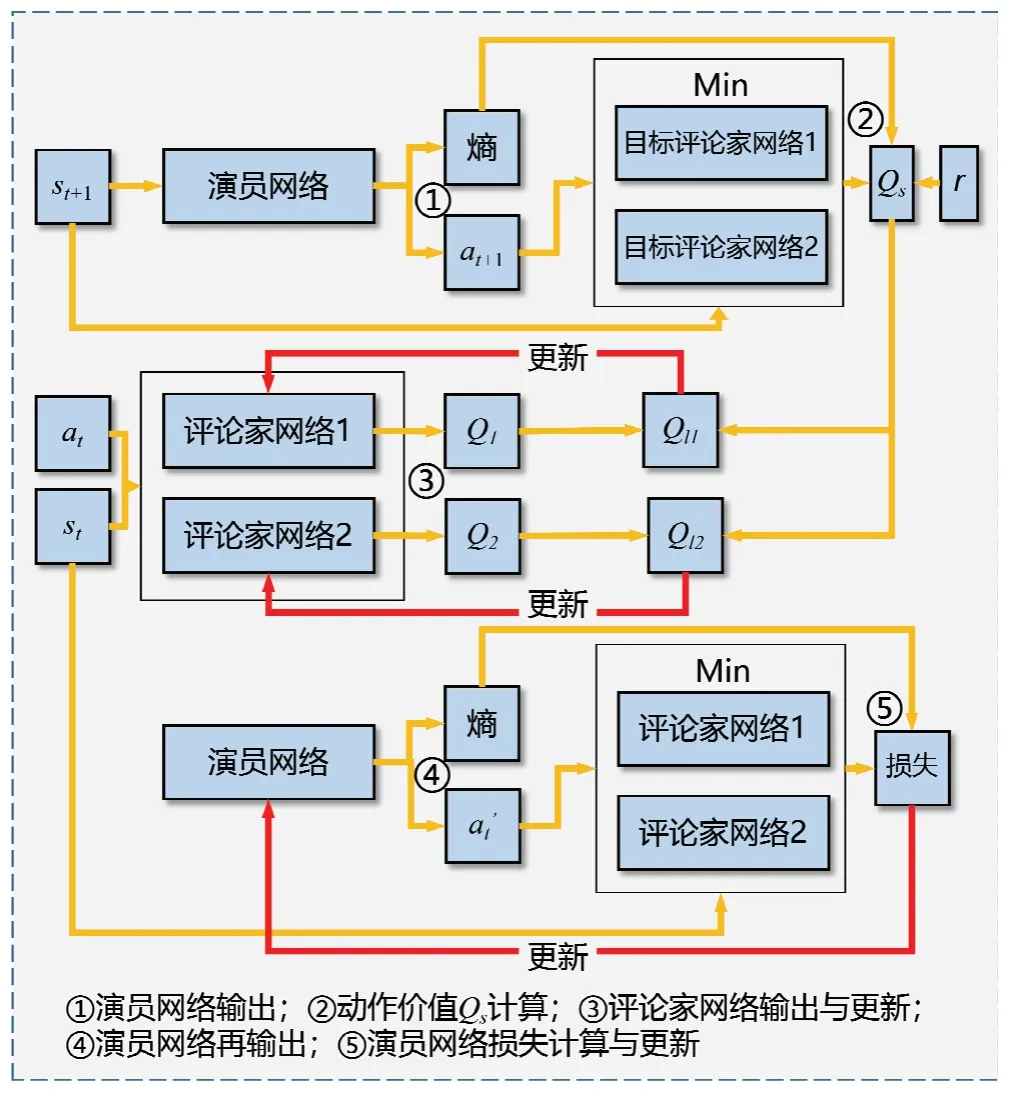
图2 SAC 算法网络结构Fig.2 Network structure of SAC
步骤1:进行参数初始化,包括评论家网络权重θi、演员网络权重Φ、目标评论家网络权重和记忆池D初始化。
步骤2:观测当前状态st,依据策略选择并执行动作αt,接着把状态st+1、奖赏值r(st,αt)和是否到达终点标志d存入记忆池D。
步骤3:从记忆池抽样一定数据[12],依次更新评论家网络权重θi、演员网络权重Φ、温度系数α和目标评论家网络权重。更新评论家网络权重θi,评论家网络输出的Q1和Q2代表其对当前状态st下动作at的价值评估,Qs由目标评论家网络的输出、演员网络的熵项输出和奖励r共同计算得出,Ql1和Ql2为更新的依据;演员网络权重Φ通过损失来进行更新;温度系数α通过带约束的优化问题进行更新;目标评论家网络权重通过滑动平均值进行更新。
步骤4:输出更新后的评论家网络权重θi、演员网络权重Φ。
2 改进SAC 算法
2.1 观测空间和动作空间设计
传统的强化学习算法对环境无先验信息,这使得移动机器人只依据当前状态对动作进行选择,缺少对动态障碍物轨迹的预测。本文算法的观测空间由连续3 帧的激光雷达数据、目标点相对于机器人的位置坐标和机器人的当前速度构成。每一帧激光雷达数据为长度为512 的一维数组,用lt表示,其中每个元素对应于单束激光的距离测量值。目标点相对于机器人的位置坐标为长度为2 的一维数组,用gt表示,其中第一个元素是横坐标,第二个元素是纵坐标。机器人的当前速度为长度为2 的一维数组,用zt表示,其中第一个元素是线速度,第二个元素是角速度。设置激光雷达的扫描角度为180 °,最大探测距离为6 m。设置连续3 帧的激光雷达数据,可以充分利用环境的先验信息,增强对动态障碍物轨迹的预测。
传统的强化学习算法输出的是有限的特定机器人运动,例如直行、左转、右转,无法连续控制机器人线速度和角速度,存在收敛速度慢和轨迹平滑度差的问题。本文算法的动作空间直接由连续的线速度和角速度构成。设置线速度的取值vt∈(0,1)m/s,角速度的取值wt∈(-1,1)rad/s。算法直接把观测数据映射到移动机器人的动作信号,实现一种端到端的避障方法。
2.2 带有梯度引导的奖赏函数设计
强化学习的目标是学习从环境状态到动作的映射模型,使得外部环境对学习系统在某种意义下的评价为最佳。本文的评价标准是移动机器人能否规避障碍物且平稳到达终点。传统的奖赏函数相对简单,当到达终点时,给予正奖赏;当撞上障碍物时,给予负奖赏。虽然这种稀疏奖赏函数符合直觉,但是由于产生的奖赏过于稀疏,不利于算法学习收敛[13]。为解决稀疏奖赏问题,本文设计了带有梯度引导的奖赏函数:

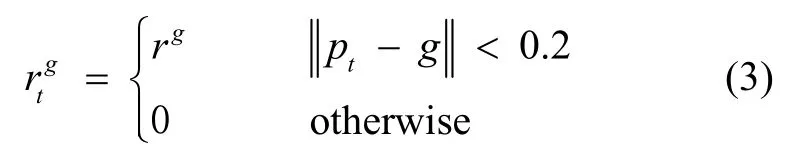



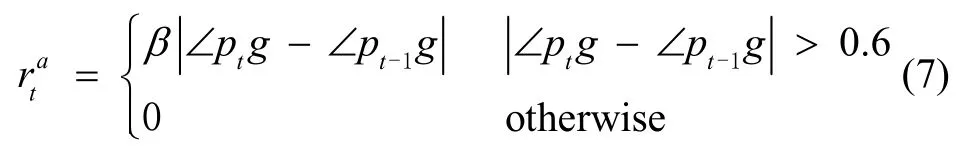
其中,pt表示移动机器人当前时刻坐标,g为机器人终点坐标,η为距离梯度引导系数,β为角度梯度引导系数,依据仿真环境设置rg=15,rc=-15,rt=-0.01,η=-1,β=-0.1,终点区域半径为0.2,角度梯度引导添加界限为0.6。式(7)中的角度为弧度制,∠ptg是机器人当前线速度方向与机器人及终点连线夹角。从式(6)-(7)可以看出,距离梯度引导和角度梯度引导通过在行驶途中给予机器人相对于终点的距离梯度负值和角度梯度负值,以促使移动机器人朝着距终点距离更小的方向优化,加快算法的收敛速度。
2.3 网络结构设计
传统的强化学习算法采用全连接层作为网络结构,存在高状态维数时收敛速度慢的问题。卷积神经网络对输入数据进行卷积操作,提取高质量特征。卷积层由大量不同类型的卷积核组成,卷积核的个数越多,特征提取能力越强[14]。SAC 算法中包含演员和评论家两种神经网络。演员网络以观测信息ot为输入,输出动作at,控制移动机器人的速度和方向。评论家网络以观测信息ot和动作at为输入,输出当前状态下动作的价值Q,对演员网络输出的动作进行评价,使其能够不断优化。由于激光雷达信息维数较大,通过卷积层进行特征提取,提升策略训练效果。
演员网络结构由图3(a)所示,3 帧激光雷达信息lt、lt-1、lt-2输入第一个卷积层,其使用32 个大小为5,步长为2,激活函数为ReLu 的一维卷积核。第二个卷积层使用32 个大小为3,步长为2,激活函数为ReLu 的一维卷积核,进行进一步的特征提取。把提取的激光雷达的信息特征输入到有256 个单元,激活函数为ReLu 的全连接层。本层的输出连同终点相对位置和移动机器人速度一起输入有256 个单元,激活函数为ReLu 的全连接层,其结果输入到两个有2 个单元,激活函数为Liner 的全连接层,分别得到动作均值和动作方差。移动机器人的动作取值空间是连续的,因此可以使用一个高斯分布采样来获得仿真环境中移动机器人的动作,即其运动指令。
评论家网络结构由图3(b)所示,其与演员网络主体类似,不同之处在于,激光雷达信息全连接层的输出连同终点相对位置、移动机器人速度和移动机器人动作一起输入有256 个单元,激活函数为ReLu 的全连接层。其结果输入到有1 个单元,激活函数为Liner的全连接层,得到动作价值Q。
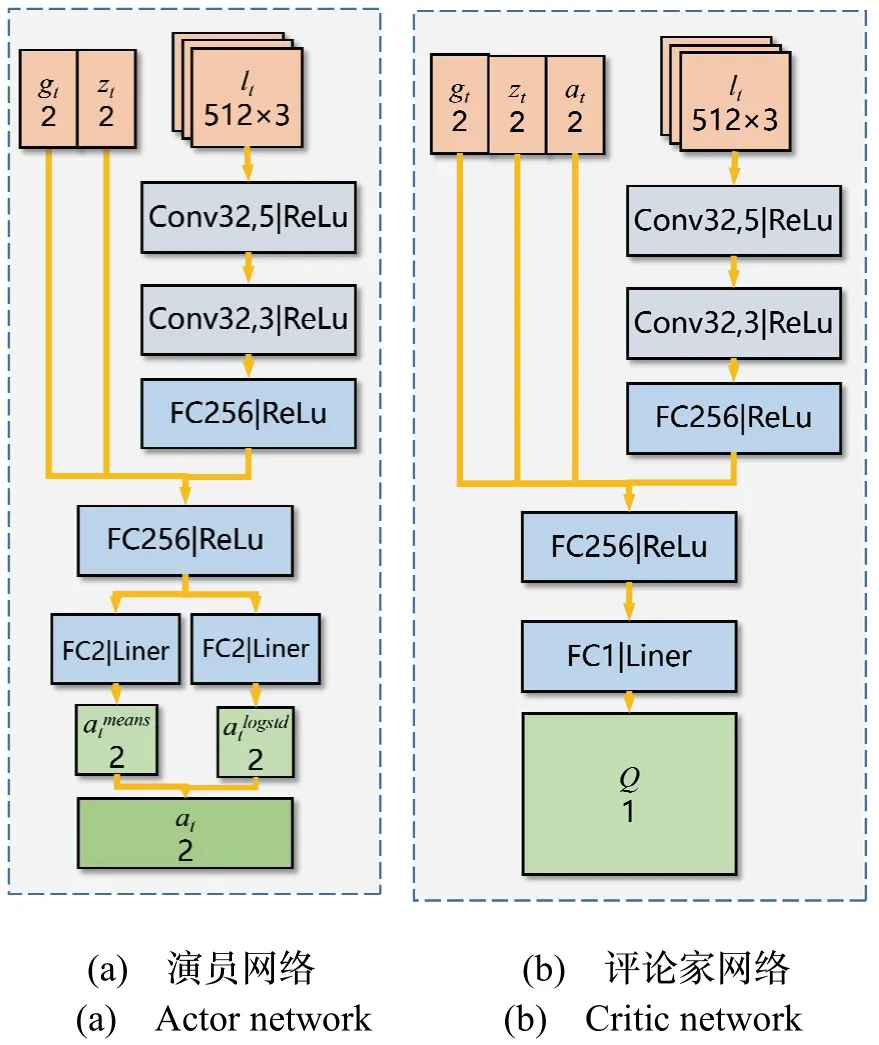
图3 网络结构Fig.3 Network structure
3 仿真试验与分析
3.1 避障策略训练
本文硬件配置为Intel i7-4780K 处理器、8 GB 运行内存和GTX1070 显卡。软件使用ubuntu18.04 系统和Pytorch1.2.0 编写算法,使用Stage 联合机器人操作系统(Robot Operating System,ROS)进行避障策略训练,实现机器人运动模拟、雷达感知、碰撞检测等功能。
图4 为本文构造的仿真环境,黑色圆形表示静态障碍物,红色长方形表示移动机器人,周围条纹为可视化的激光束。在训练避障策略时,每个回合随机设置移动机器人的初始位置、终点位置和静态障碍位置。依据计算机的性能和仿真环境大小,设置8 个移动机器人同时运行,移动机器人相互作为动态障碍物,同时并行生成多组数据加快避障策略训练。
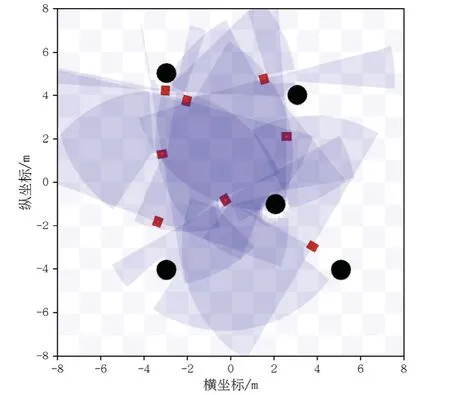
图4 训练环境Fig.4 Training environment
算法的参数如表1 所示,REPLAY_SIZE是记忆容量;BATCH_SIZE是批次大小;MAX_STEPS是每回合训练的最大步数;UPDATE_INTERVAL表示在每次触发更新的条件时,对网络进行梯度更新的次数。LEARNING_RATE是学习率;γ是折扣因子;α是温度系数的初始值。

表1 算法参数Tab.1 Algorithm parameters
训练过程中奖赏变化如图5 所示,为了使结果更加直观,对奖赏变化曲线进行了平滑处理(图中用SAC*表示改进SAC 算法,SAC 表示传统SAC 算法)。从图中可以看出,改进SAC 算法比传统SAC 算法的训练速度提升40%,表明梯度引导可以加快训练收敛速度。算法收敛时,改进SAC 算法比传统SAC 算法的平均奖赏增加10 左右,表明改进SAC 算法具有更高的成功率。

图5 奖赏变化曲线Fig.5 Reward curve
3.2 二维仿真试验
二维仿真试验环境如图6 所示,黑色圆形表示静态障碍物,长方形表示移动机器人,不同移动机器人使用不同颜色标出,从开始避障到结束,轨迹的颜色由浅变深,轨迹对应的时间在轨迹旁用数字标出,单位为s,且每3 s 或4 s 标注一次。为验证避障策略的有效性,设计三种评价指标对避障效果进行评价,其中成功率表示成功回合数占总试验回合数的比例,平均线速度和轨迹长度表示在成功回合中机器人平均线速度大小和轨迹长度。

图6 二维仿真试验环境Fig.6 2D simulation test environment
无障碍物试验环境如图6(a)所示,用以对照避障效果。1 个静态障碍物试验环境如图6(b)所示,终点在起点正前方,障碍物在起点和终点之间。依据试验环境大小随机设置7 个静态障碍物,其试验环境如图6(c)所示。当机器人之间的路径重合或者交叉时即有碰撞风险,本文设计其他移动机器人作为动态障碍物,不同移动机器人使用不同颜色标出。1 个动态障碍物试验环境如图6(d)所示,2 个移动机器人起点在“十”字2 个相邻端点,终点在相对端点。3 个动态障碍物试验环境如图6(e)所示,4 个移动机器人起点在“十”字4 个端点,终点在相对端点。7 个动态障碍物试验环境如图6(f)所示,8 个移动机器人起点在“米”字8个端点,终点在相对端点。分别进行100 回合的试验,试验结果如表2 所示。

表2 二维仿真试验结果Tab.2 2D simulation test results
仿真试验结果表明,在1 个静态障碍物环境中,改进SAC 算法可以完成移动机器人的无碰撞运行,成功率达到100%。与传统SAC 算法相比,轨迹长度缩短7.15%,平均线速度增加9.09%。
在7 个静态障碍物环境中,改进SAC 算法可以完成移动机器人的无碰撞运行,成功率达到100%。与传统SAC 算法相比,轨迹长度缩短8.09%,平均线速度增加23.25%。
在1 个动态障碍物环境中,改进SAC 算法可以完成移动机器人的无碰撞运行,成功率达到100%。与传统SAC 算法相比,轨迹长度缩短8.69%,平均线速度增加17.35%。
在3 个动态障碍物环境中,改进SAC 算法可以完成移动机器人的无碰撞运行,成功率达到100%。与传统SAC 算法相比,轨迹长度缩短2.69%,平均线速度增加11.88%。
在7 个动态障碍物环境中,改进SAC 算法可以完成移动机器人的无碰撞运行,成功率达到100%。与传统SAC 算法相比,轨迹长度缩短25.36%,平均线速度增加11.87%。
综合上述仿真试验,本文所提出的改进SAC 算法能够完成移动机器人的无碰撞运行,平稳从起点到达终点。与传统SAC 算法相比,成功率更高、轨迹长度更短、平均线速度更大、效率更高。
3.3 三维仿真试验
采用如图7 所示的Turtlebot3-Burger 移动机器人进行三维仿真试验,对改进SAC 算法的有效性进行验证。该机器人为二轮差速驱动,搭载惯性测量单元(Inertial Measurement Unit,IMU)和激光雷达等设备,其中IMU 传感器用于获取移动机器人的速度信息、激光雷达用于获取外界环境信息。移动机器人的参数:最大线速度0.22 m/s,最大角速度2.84 rad/s,尺寸长宽高138×178×192 mm,重量1 kg。

图7 Turtlebot3-Burger 移动机器人Fig.7 Turtlebot3-Burger mobile robot
三维仿真试验环境使用Gazebo 搭建,Gazebo 是一款机器人仿真软件,其提供高保真度的物理模拟和传感器模型,能够在复杂环境中准确高效地模拟机器人工作。动态障碍物仿真试验环境如图8 所示,尺寸为10×10×2.5 m,灰色球形表示动态障碍物,直径为1 m,动态障碍物1 沿机器人前方3 m 平行线从右向左以0.20 m/s 匀速运动,动态障碍物2 沿机器人前方6 m 平行线从左向右以0.20 m/s 匀速运动。移动机器人起点在试验环境下方的中间,终点在机器人的正前方。本文将所提方法与多个现有方法进行比较,具体为:1) A*:利用搜索的方式进行反应式避障;2) RRT*:变种快速探索随机树方法(Rapidly-exploring Random Tree,RRT),在传统RRT 算法中引入重连接操作;3)PPO:近端策略优化(Proximal Policy Optimization,PPO)算法,也是一种强化学习算法,仿真试验结果如表3所示。
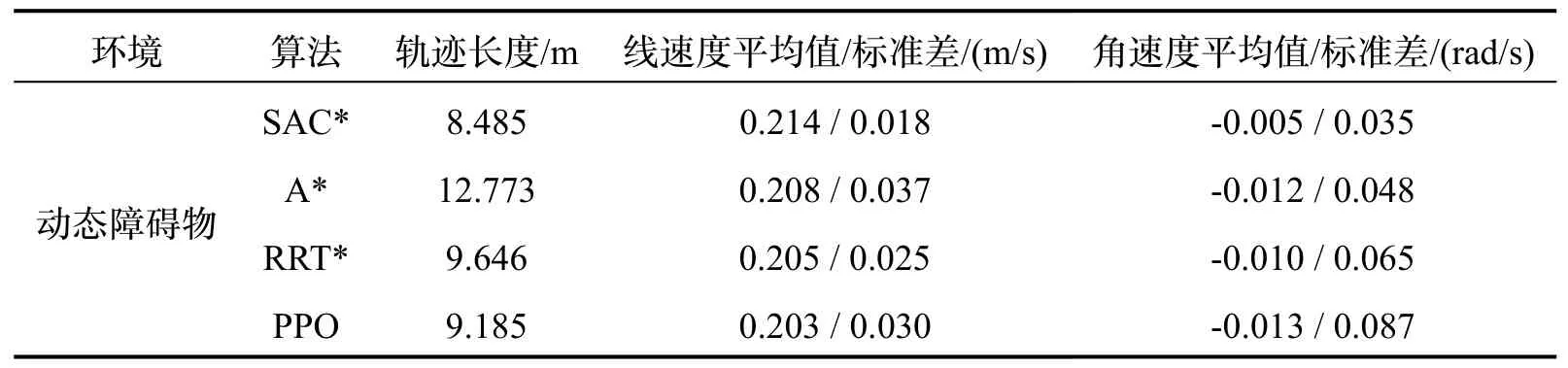
表3 三维仿真试验结果Tab.3 3D simulation test results

图8 三维仿真试验环境Fig.8 3D simulation test environment
仿真试验结果表明,在动态障碍物环境中,改进SAC 算法可以完成移动机器人无碰撞到达终点。与A*算法、RRT*算法和PPO 算法相比,线速度平均值分别增加2.88%、4.39%、5.42%,线速度标准差分别降低51.35%、28.00%、40.00%,角速度标准差分别降低27.08%、46.15%、18.60%。
效果差别最大的改进SAC 算法和A*算法在动态障碍物试验的轨迹、距离变化、速度变化和角速度变化分别如图9-12 所示,轨迹对应的时间在轨迹旁用数字标出,单位为s,且每10 s 标注一次。当遇到障碍物2 时,改进SAC 算法具有对障碍物运动方向的预测能力,可以通过改变自身运动方向和降低行驶速度进行避障,轨迹更短;A*算法主要通过改变自身运动方向进行避障,只进行反应式避障轨迹规划,缺少对障碍物运动方向的预测,轨迹更长。
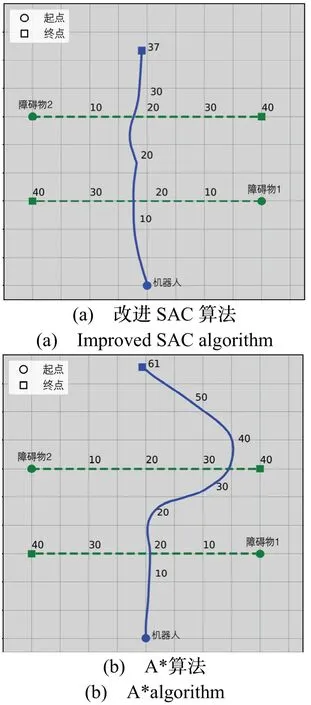
图9 动态障碍物试验轨迹Fig.9 Dynamic obstacles test track

图10 动态障碍物试验距离变化曲线Fig.10 Dynamic obstacles test distance curve

图11 动态障碍物试验线速度变化曲线Fig.11 Dynamic obstacles test linear velocity curve

图12 动态障碍物试验角速度变化曲线Fig.12 Dynamic obstacles test angular velocity curve
综合上述三维动态障碍物仿真,本文所提出的改进SAC 算法能够完成移动机器人的无碰撞运行,平稳从起点到达终点。与现有方法相比,避障效果更好。当遇到动态障碍物时,改进SAC 算法可以对障碍物的运动方向进行预测,轨迹更短。
4 结论
本文提出的改进SAC 算法能够使移动机器人在复杂环境下躲避多动态障碍,平稳从起点到达终点。利用Stage 和Gazebo 联合ROS 系统分别设计二维和三维仿真试验。仿真试验结果表明,带有梯度引导的奖赏函数可以促使移动机器人向终点方向优化,加快算法收敛速度;卷积神经网络可以提取高维信息特征,提升策略效果。与传统的SAC 算法相比,改进SAC算法能使移动机器人避障成功率更高、平均线速度更大、轨迹长度更短、线速度和角速度波动更小。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
动漫界·幼教365(中班)(2020年3期)2020-04-20
铁道通信信号(2020年9期)2020-02-06
创新作文(1-2年级)(2019年4期)2019-10-15
考试周刊(2018年95期)2018-11-14
山东工业技术(2018年5期)2018-03-10
制造技术与机床(2017年3期)2017-06-23
科技创新与应用(2016年34期)2016-12-23
新高考·高一物理(2016年3期)2016-05-18
中国海洋大学学报(自然科学版)(2014年8期)2014-02-28
