
基于自适应特征融合的小样本细粒度图像分类
2023-02-14 10:31解耀华章为川景军锋
计算机工程与应用 2023年3期
解耀华,章为川,任 劼,景军锋,2
1.西安工程大学 电子信息学院,西安 710600
2.陕西省人工智能联合实验室 西安工程大学分部,西安 710600
近年来,大多数基于深度学习的图像分类需要大量的具有人工标注的训练样本对神经网络的参数进行优化。细粒度图像分类(fine-grained image classification,FGIC)是图像分类领域的一个重要分支。FGIC需在区分出基本类别的基础上,对基本类别下的子类进行进一步分类,例如对鸟类或者犬类的品种分类。但是训练网络模型需要鸟类或者犬类专家对样本预先标注,这会耗费大量的人力和时间。而人类仅通过一个或几个样本就可以学习到一个新概念,受此启发,2006年,Li等人[1]提出了小样本学习(few shot learning,FSL)的概念,即用少量的样本训练网络模型对测试图像进行分类。Li等人[2]利用贝叶斯框架,从先前无关类别中学习到可转移的模型,并迁移到新的类别进行分类。
受上述两个研究方向的影响,不少学者开始研究如何在样本数量极少的情况下进行细粒度的图像分类,即小样本细粒度图像分类(few shot fine-grained image classification,FSFGIC)。由于同一子类别中的图像拍摄的角度差异以及属于不同子类中的图像的高相似度,造成的高类内方差和低类间波动是FSFGIC的核心挑战[3-5]。如何仅仅使用少量的被标注的细粒度图像训练模型对查询集样本进行分类是现阶段FSFGIC的研究重点。现有的FSFGIC方法主要可以分为两类:基于元学习的FSFGIC方法和基于度量的FSFGIC方法。
基于元学习的FSFGIC方法旨在学习一些和模型参数无关的元知识,包括模型的初始值、超参数等。当模型遇到新的类别时,可以快速对模型优化去适应新任务。Meta-learner[6]提供了一些关于如何设计和训练基于长短期记忆网络(long short-term memory,LSTM)元学习器的思想。与传统的监督学习的分类不同,Finn等人[7]与Tian等人[8]对网络模型的初始值进行优化,对于简单的数据集可以达到很好的效果,然而在样本量极少的情况下,对于纹理结构复杂的数据集在高维参数空间上运行时,并不能有效限制过拟合。为此,LEO[9]通过从模型的高维参数空间中学习一个低维嵌入,并在低维空间实施优化来解决模型在超高维参数空间下易过拟合的问题。虽然基于元学习的FSFGIC方法泛化性强,但其增加了大量优化的参数,导致计算量非常庞大。
基于度量的FSFGIC方法是对样本在特征空间的分布进行建模。该方法首先使用特征提取器将支持集(support sets)和查询集(query sets)的样本映射到公共的特征空间中,然后利用不同的度量函数(例如欧氏距离[10-12]或余弦距离[13-14])计算查询集样本和支持集样本特征向量的相似度,并对查询集样本进行分类。由于局部特征描述符可以比全局特征更有效地表示每个类别的分布,最近的一些工作CovaMNet[10]、ATL-Net[11]和DN4[12]使用了局部特征描述符来表示样本不同区域,然后利用相应的相似度函数来计算查询集样本到每类之间的相似度度量关系。匹配网络(M-Net)[13]经过特征提取后,使用双向LSTM和注意力机制创建上下文嵌入并使用余弦度量对测试样本分类。原型网络(P-Net)[14]通过计算查询集的每个样本到不同支持类中心的距离,实现对查询集的样本分类。GNN[15]建立输入数据和图表示之间的映射关系执行FSFGIC任务。最近,Deep-EMD[16]通过计算各图像最佳匹配代价计算相似度。Wang等人[17]和Cao等人[18]通过增强图像局部特征突出图像级的相似度。
现有的基于度量的FSFGIC算法存在以下问题:(1)现有的特征提取网络仅仅使用深层的特征,忽视了网络的浅层的位置结构特征;(2)现有的FSFGIC所使用的训练方法在细粒度图像上只注重单个样本的特征,忽视了样本之间的联系;(3)由于细粒度图像具有高类内方差和低类间波动,特征提取网络得到的特征向量未进行有效处理,导致鲁棒性差。
本文针对上述三个现有的FSFGIC问题提出的主要创新点如下:(1)设计了一种特征提取网络:自适应特征融合嵌入网络(adaptive feature fusion embedding network,AffeNet),将深层强语义信息和浅层位置结构信息结合,并通过自适应算法和压缩与激励层(squeezeand-excitation,SE)进一步提取关键特征;(2)采用单图训练(single image training,SIT)和多图训练(multi-image training,MIT)结合的方法训练特征提取网络,同时关注单样本的特征和样本之间的联系,使得训练过的网络更好地适应新类;(3)为了使得同一类的特征向量在特征空间中的距离更加接近,不同类的特征向量的距离更大,减小细粒度图像的类内方差。本文对提取到的特征向量进行特征分布转换、正交三角(quadrature right trigonometric,QR)分解、归一化处理。
1 研究方法
本文的FSFGIC算法流程如图1所示。在训练阶段,本文使用SIT和MIT方法根据Cb个类的样本和对应的标签利用交叉熵损失训练(cross entropy,CE)特征提取网络AffeNet和分类器。在测试阶段使去掉分类器,首先用AffeNet作为特征提取器fϕ将所有样本映射到公共的特征空间表示为特征向量,然后对提取到的特征向量做特征处理(feature processing,FP),最后用相似度度量算法来预测查询集属于每个类别的概率(Probability,P)。
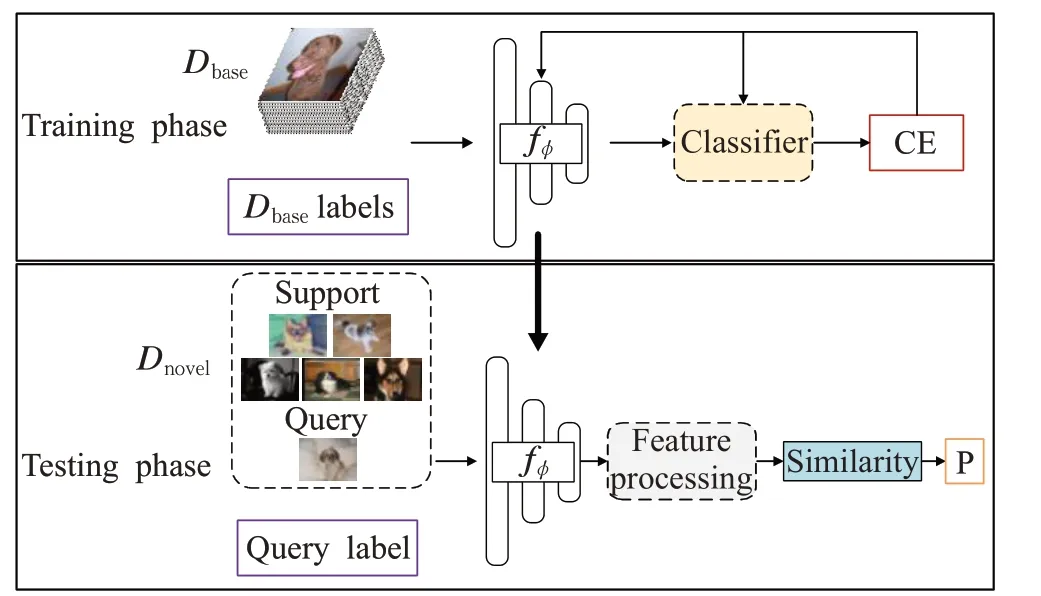
图1 本文的小样本细粒度图像分类算法流程Fig.1 FSFGIC algorithm flow in this paper
1.1 问题定义
现有的FSFGIC中,所有数据集可划分为一个有Cb个类的基类集,一个有Cv个类的验证集和一个有Cn个类的新类集指的是基类集、验证集和新类集的样本数量。其中,Cbase、Cval、Cnovel中的类别是不相交的,表示为Cbase∩Cval∩Cnovel=∅。
本文使用Dbase训练特征提取网络AffeNet,Dval搜索模型的最优参数,Dnovel用来测试FSFGIC性能。在FSFGIC中包含大量的子任务,每个子任务随机从Dnovel中采样N个类,每个类有K个含标签的样本和Q个无标签的样本,通过含标签的N×K个样本预测N×Q个样本的类别。上述任务称为NwayKshot任务。
1.2 训练阶段
为了提升训练阶段的特征提取网络的特征提取能力,本文提出了一种基于自适应特征融合嵌入网络AffeNet,采用单图训练方法和多图训练方法先后对AffeNet训练。
1.2.1 特征提取网络
现有的FSFGIC中使用的特征提取网络[10-12]大多为Conv-64F[12]、ResNet12[19]或WRN[20],并只使用了最后一个卷积层的输出作为提取到的特征,忽略了浅层的位置结构信息。文献[12,19-20]都是自上而下连接网络体系结构,从最深的卷积层中获得了具有强语义信息特征描述符,如图2(a)所示。
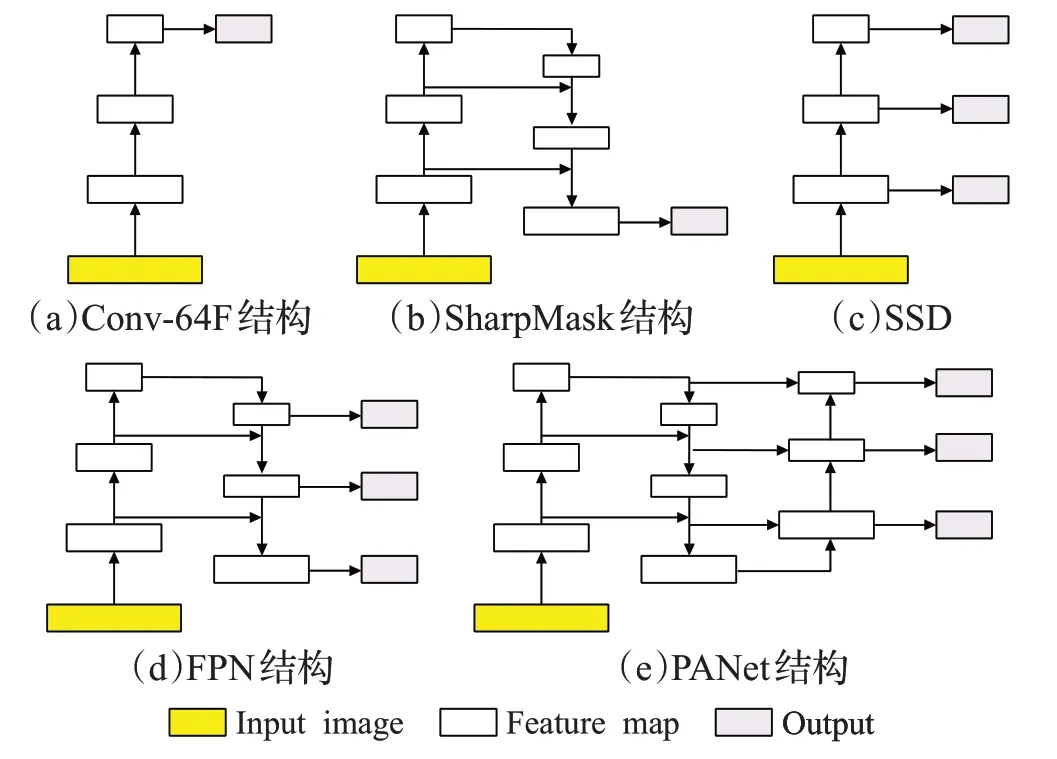
图2 现有的特征提取网络的架构Fig.2 Existing architectures of feature extraction networks
在目标检测和图像分割[21-24]任务中,不少学者对特征提取网络进行了改进,在使用强语义特征的基础上加入了位置结构特征,取得了良好的效果。Pinheiro等人[21]设计了一种自上而下、跳跃连接网络体系结构(SharpMask),从最深的卷积层中获得了具有强语义信息和强位置结构特征描述符,如图2(b)。Liu等人[22]提出了single shot multibox detector(SSD),从不同的卷积层获得多尺度特征描述符,如图2(c)。Lin等人[23]提出了特征金字塔网络(FPN),如图2(d),从自上而下和跳跃连接的网络体系结构[21]中获得具有强语义信息的多尺度特征描述符。Liu等人[24]设计了path aggregation network(PANet),利用FPN[23]获取多尺度特征图,然后采用自下而上的融合架构得到的多尺度特征信息,如图2(e)所示。
在图2(a)中,随着卷积和下采样的次数不断增加,特征图中的每一个像素值对应了图像中一个区域的特征。因此,特征提取网络的深层特征图具有强语义信息。然而,Conv-64F网络丢失了特征提取网络中的浅层特征图包含更多的像素点的信息,不能够有效地反映出细粒度图像的空间和结构信息。本文受到文献[21-24]启发,利用浅层的位置结构特征和深层的语义特征,减少细粒度图像的类内方差,提取出适合FSLGIC的特征。在文献[22-24]中,通过融合特征提取网络的深层和浅层的特征,有助于提高FSFGIC的准确率,但是采用多尺度输出,深层特征和浅层特征的权重相同,不同层的特征没有分配到适合的权值。因此,本文提出了一种自适应特征融合嵌入网络AffeNet,网络结构详见图3,包含两种不同的卷积块。其中block0、block1和block4均由卷积、批次归一化、ReLu激活函数、最大池化和SE组成。block2、block3、block5和block6均由卷积、批次归一化、ReLu激活函数和SE组成。

图3 自适应融合嵌入网络Fig.3 Adaptive feature fusion embedding network
为了进一步提取特征中的关键信息,本文在每个block的最后添加了基于压缩与激励层[25]的注意力模块。首先平均池化层对输入特征图池化,即用每张特征图的平均值来表示每个通道的特征。假设输入的通道数为m,特征图平均池化为一个特征向量,表示为c=[c1,c2,…,cm];其次,线性压缩层将原来的特征向量压缩为原来通道数的1/4,得到压缩特征向量s=[s1,s2,…,sm4];然后线性激励层将s激励为m维的特征向量e=[e1,e2,…,em];最后,将得到的特征向量和原输入特征相乘作为SE模块的输出的特征图。其中,线性压缩层输出s=wc+b,如公式(1):

线性激励层输出e=αs+ϑ,如公式(2):
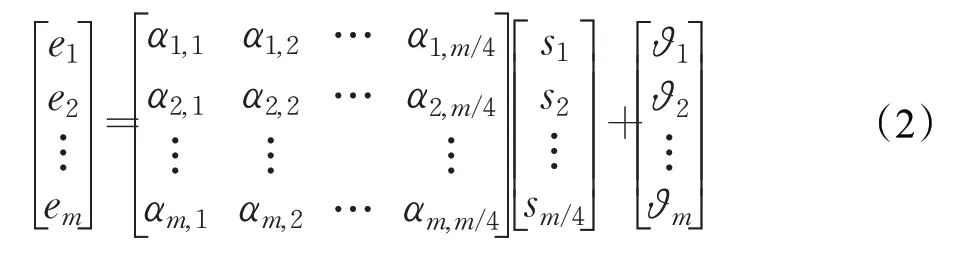
其中,w和α分别表示压缩与激励层的权值,b和ϑ是压缩与激励层的偏置值。经过一定次数的训练,[e1,e2,…,em]演变为每个通道的权值,给有助于提高分类性能的通道赋予更大的权值。
AffeNet包括三个步骤:首先,通过自上而下的多个卷积块构建高层次的语义特征图t3。其次,对下采样得到的特征图与相应大小的特征图按位相加,并进行双线性插值上采样,得到浅层特征图u3。最后,将合并后每层的特征图和上一步的特征图通过按位相加进行合并,并使用多个卷积块进一步提取出结合浅层的位置结构信息和深层的语义信息的特征图a4,将融合后的特征图a4和第一步下采样的特征图t3进行自适应加权求和得到最终的特征向量。
AffeNet的算法流程具体如下:输入一张通道数为3,大小为H×W的图片样本xi∈Dbase,首先,通过第一个卷积块block0,得到64个H/2×H/2大小的特征图。block1、bock2、block3使用64个卷积核将输入样本处理为H/4×W/4大小的特征图t3,表示为:

其次,对从t3开始自下而上进行同层的特征图融合,并进行上采样,得到u3,计算过程见公式(4):

其中,↑指的是双线性插值上采样。
然后,使用block4、block5、block6进一步提取出结合位置结构信息特征和语义特征的特征图,并和上一步得到的特征图进行特征融合,计算过程见公式(5):
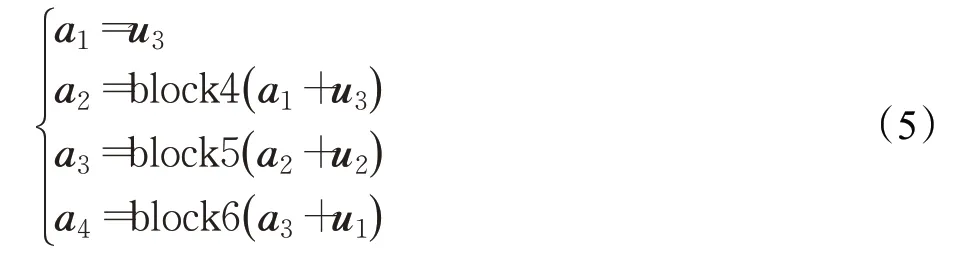
最后,将融合后的特征a4和原来的下采样输出t3自适应加权融合,表示为公式(6):

其中,γ和ξ表示自适应融合的权重,初始值均为1,通过训练得到最终权值。feature是一个64维的特征向量。
1.2.2 单图训练方法(SIT)
输入单样本xa∈Dbase经过特征提取网络得到64维的特征向量之后。使用线性分类器将特征向量转化为Cb个类的预测概率,然后用ŷSIT与样本xa的标签ya的交叉熵损失作为损失函数对特征提取网络进行优化。SIT的损失函数可表达为公式(7):

其中,l(·)指的是交叉熵损失函数,SIT训练过程位于图4的左上方,classifier表示线性分类器,l(·)表示交叉熵损失函数。
1.2.3 多图训练方法(MIT)
当使用SIT方法训练了一定的次数后,将训练的权重使用多图训练方法继续训练AffeNet。样本xa和样本xb,{xi,yi}∈Dbase(i=a,b)需要进行特征图混合(feature map mixing,FMM)处理,FMM见图4的右上方部分。本文对第一阶段的下采样过程的任意一层特征图做特征图混合,即对不同样本的同一层的特征图做特征图混合处理,计算过程见公式(8):

其中,0≤r≤3是个随机数,ra指的是样本xa的第r层特征图,rb指的是样本xb的第r层特征图,λ是符合β分布的任意值,将融合后的特征图再使用第r+1层之后的模块处理,MIT具体过程见图4的下方。分类的预测结果记为ŷMIT,样本xa的标签记作ya,样本xb的标签记作yb,分别计算ŷMIT和ya的交叉熵损失与ŷMIT和yb的交叉熵损失。最后将两个损失函数分别使用λ和1-λ加权求和,进行反向传播和梯度下降。MIT训练方法的损失函数可表达为公式(9),其中l1和l2分别是交叉熵损失函数:
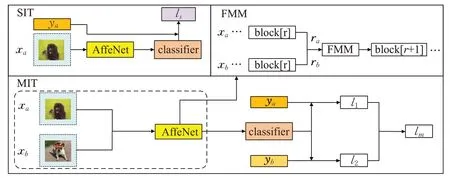
图4 训练阶段的训练方法Fig.4 Training methods in training phase
1.3 测试阶段
在训练阶段得到了可转移的知识后,此时训练好的AffeNet可作为测试阶段的特征提取器对新类Dnovel进行特征提取。用fϕ表示特征提取器,其中ϕ是训练过的架构参数。对于样本xj在特征空间中的特征向量表达为vj=fϕ(xj)=[vj1,vj2,…,vj64]。其中1≤j≤N×(K+Q)。为了使得同一类的特征向量在特征空间中的距离更加接近,不同类的特征向量的距离更大,本文使用了特征分布转换、QR分解和归一化对AffeNet提取到的特征进行特征处理(feature processing,FP)。
1.3.1 特征分布转换
为了使得特征空间的特征向量的分布均匀,通常需要每个样本的特征向量符合类高斯分布[26]。公式(10)能够将从Dnovel的样本的特征向量从随机分布转化为类高斯分布δj=[δj1,δj2,…,δj64]。

其中,vj指的是NwayKshot任务中第j个样本的特征向量,1≤j≤N×(K+Q),k指的是特征向量vj的维度索引,ε是防止异常值的极小值。
1.3.2 QR分解
将N×(K+Q)个样本组成一个新的矩阵H∈R(N(K+Q))×64。H的每一行表示一个NwayKshot任务的每个样本的特征向量。已知样本的特征矩阵H和样本标签,求分类器参数X,即根据方程HX=L求解X。具体步骤为,首先对H进行QR分解[27],得QRX=L。其中Q是正交阵,R是上三角阵(R的主对角线下面的元素全为0)。其次,两边左乘QT得到RX=QTL,令QTL=L′,得到RX=L′。此时的R阵为新的特征矩阵,L′为Dnovel的标签,R矩阵和H都是一个任务里的所有样本在特征空间中的特征向量,不同的是R矩阵为上三角阵,用ρ表示QR分解函数,R=[ρ(δ1),ρ(δ2),…,ρ(δN×(K+Q))],表示为N×(K+Q)个样本的特征向量。QR分解的优势有两点:(1)由于R是上三角矩阵,求解X较简便;(2)R阵使得同一类的特征向量距离更加接近,使得不同类的特征向量的距离更大,这对分类有很大提升。
1.3.3 归一化
特征向量归一化,即支持集和查询集的样本的特征向量分别按照比例缩放,使得NwayKshot任务的所有样本落在相近的空间,提高分类性能。将R分为支持集Rsup=[R1,R2,…,RN×K]和查询集Rq=[R1,R2,…,RN×Q]。公式(11)和公式(12)是对支持集和查询集分别归一化。

其中,μ指的是查询集或支持集所有样本的平均特征向量,下标τ和υ指的是支持集和查询集样本的索引,上标sup和q表示支持集和查询集。
1.3.4 相似度度量算法
初始化类中心zj,即求出支持集的每个类的平均特征向量记为zj=[zj1,zj2,…,zj64],表达为:

其中,τ指的是第j类支持集的样本索引,zj指的是第j类的类中心。计算查询集的样本的特征向量到每个类zj的欧式距离L∈RNQ×N,具体表达为:

样本到该类的类中心的距离越小,则该样本属于这个类的概率越大。因此,查询集样本的类别概率可以近似为:
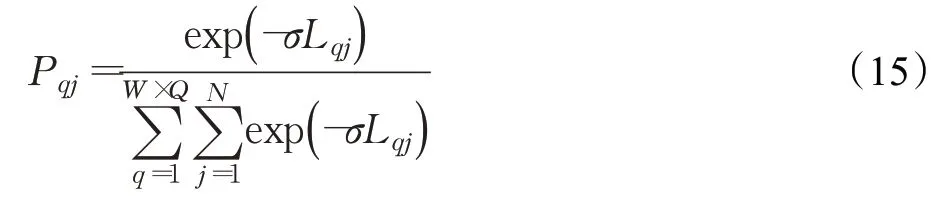
其中,σ为常数,实验中设置为10。所有的Pqj组成概率矩阵P∈RNQ×N,P每一行的最大值所在的类作为预测的类别的结果。
2 实验
2.1 数据集
本文使用标准的公开细粒度数据集Stanford Dogs[28]、Stanford Cars[29]、CUB-200[30]对该方法进行评估。Stanford Dogs数据集包含来自世界各地的120种犬类共20 580张图片。Stanford Cars包含196种汽车共16 185张图片。CUB-200共包含200种鸟类共11 788张图片。
本文使用上述数据集做FSFGIC时,需要将图像分为基类集Dbase、验证集Dval和新类集Dnovel。其中Dbase、Dval和Dnovel的类别不含交集,对于3个数据集的类别分割结果见表1。

表1 基类、验证、新类数据集分割Table 1 Base,Val and Novel dataset segmentation
2.2 实验设置
在训练过程中,本实验中采用随机裁剪、颜色抖动、随机翻转等数据增强手段来防止过拟合。使用SIT训练方法和MIT训练方法先后训练Dbase至一定次数。使用Adam优化器[31]对AffeNet进行训练,初始学习率为0.000 1,动量为0.95,输入图像分辨率为84×84。一旦在训练阶段学习到可转移的模型,那么该模型就会转变为特征提取器。在测试阶段,随机采样10 000个任务测试该方法的性能。
本文的全部实验使用NVIDIA GTX1080Ti显卡,在Windows10、CUDA10.0、Python3.7和PyTorch1.5.0环境下运行。
2.3 实验结果与分析
为了验证本文所提出的FSFGIC算法的性能,将本文的FSFGIC算法在3个细粒度数据集Stanford Dogs、Stanford Cars和CUB-200上进行了测试,并和MAML[7]、M-Net[13]、P-Net[14]、GNN[15]、CovaMNet[10]、DN4[12]、ATLNet[11]、DeepEMD[16]、DLG[18]小样本细粒度图像分类方法进行比较。其分类准确率相比于其他9个FSFGIC算法更高,实验结果如表2所示。

表2 细粒度数据集小样本分类准确率Table 2 Acuracy of few shot fine-grained image classification datasets 单位:%
在Stanford Dogs数据集上,本文所提的算法比ATL-Net的5 way 1 shot准确率提升了5.27个百分点,5 way 5 shot准确率提升了2.90个百分点。在Stanford Cars上相比于ATL-Net的5 way 1 shot提升了3.29个百分点,5 way 5 shot上提升了4.67个百分点。在CUB-200上比DLG方法5 way 1 shot仅仅落后0.82个百分点,但是在5 way 5 shot上提升了1.55个百分点。实验结果表明本文提出的FSFGIC方法在细粒度数据上的小样本分类准确率优于其他方法。
2.4 N和K对分类结果的影响
本文在CUB-200数据集上分析了对于支持集的样本的类别数(N)和每一类的样本数(K)对分类结果的影响,实验结果见表3和表4。实验结果表明,随着N的增大,小样本分类的准确率减小,这是因为需要把查询集的样本分为更多的类,增加了分类的难度。反之,随着K的增大,由于每个类别的样本数量增加,求取的类中心也越接近期望的类中心,因此,小样本分类的准确率会提升。

表3 当N=5,K对分类结果的影响Table 3 When N=5,influence of K on classification results

表4 当K=1,N对分类结果的影响Table 4 When K=1,influence of N on classification results
2.5 网络复杂度分析
为了证明AffeNet的实用性,本文使用torchsummary工具计算了网络模型的结构计算量和模型的参数量。其中,网络结构计算量指的是推理一张图片的浮点计算量(giga floating-point operations per image,GFLOPI)。通过精简公式[32]计算GFLOPI。

其中,G指的是卷积的GFLOPI,C1和C2指的是卷积的输入通道和输出通道,W1和H1指的是卷积核的宽和高,W2和H2指的是输出通道的宽和高。
AffeNet和其他FSFGIC算法的主干网络比较,包括Conv-64F、ResNet12、ResNet18、WRN做比较。实验结果如表5。实验表明,AffeNet的复杂度低于ResNet12、ResNet18、WRN,有效提高了实际应用的实时性。另外AffeNet和Conv-64F复杂度相差不大,但是精度却远高于Conv-64F,在2.7节的消融实验2中,AffeNet的准确率相对于Conv-64F分别提升了2.21和3.05个百分点。

表5 主干网络的复杂度对比Table 5 Complexity comparison of backbone networks
2.6 可视化
为了对比不同算法下,每个类别的样本所提取的特征在特征空间的分布的远近程度,本文随机取一个5 way 5 shot任务的所有样本,用不同颜色的阿拉伯数字来表示每个类别的样本在特征空间的特征向量。本文在Stanford Cars数据集上用主成分分析(principal component analysis,PCA)[33]和t-分布邻域嵌入算法(tdistributed stochastic neighbor embedding,T-SNE)[34]的方法将特征向量降维并进行了可视化实验,并与DN4、ATL-Net比较。可视化的结果见图5。
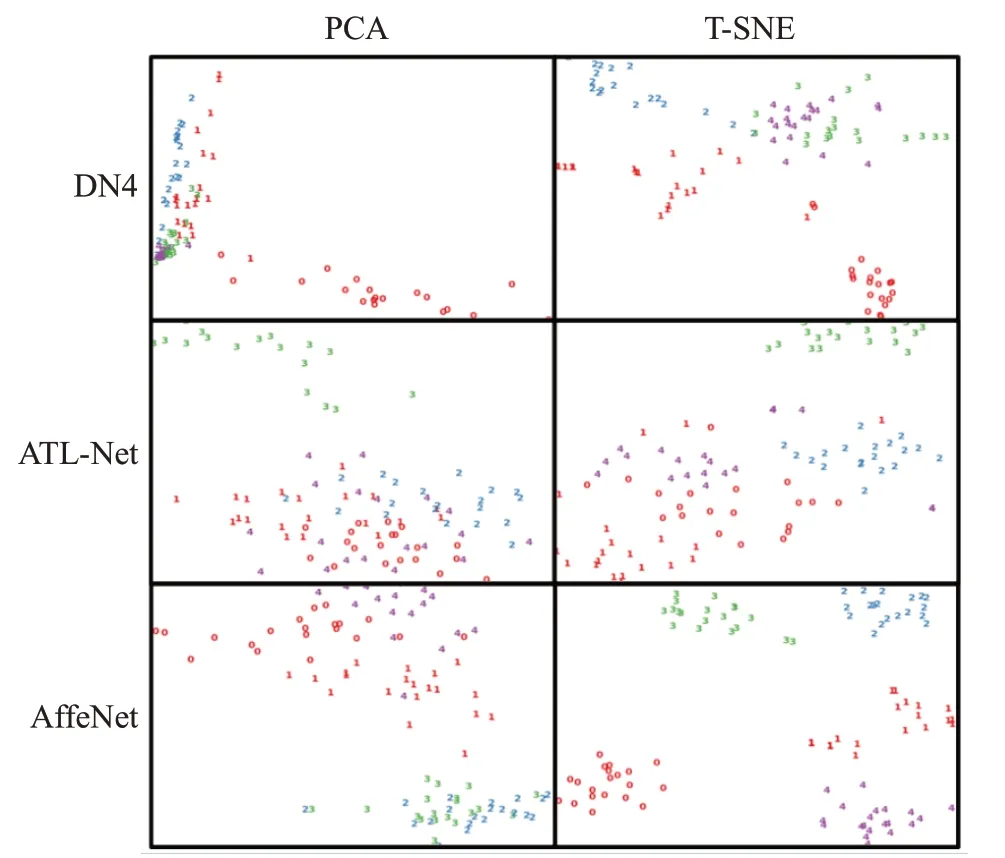
图5 特征分布可视化Fig.5 Feature distributed visualization
在图5中,第一列表示PCA可视化的结果,第二列表示T-SNE的可视化结果。第一行的图表示DN4的特征向量分布。第二行的图表示ATL-Net的特征向量分布。第三行的图表示本文方法的特征向量的分布。实验结果表明本文中的FSFGIC方法对于不同类别的图片在特征空间的分布上的距离较远,并且在同一类别的图片的分布的距离相近。
2.7 消融研究
为了更加精确地验证自适应特征融合、注意力模块和trainval对分类准确率的影响,本文在CUB-200上做了消融实验,消融实验1的结果见表6。
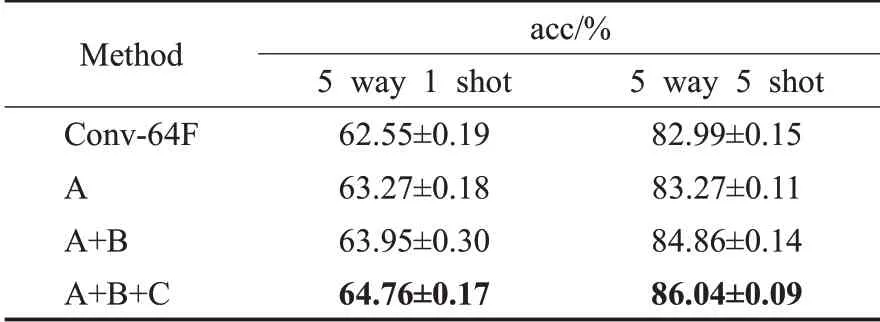
表6 在CUB-200上做的消融实验1Table 6 Ablation experiment 1 on CUB-200
本文进行了四组实验,其中Conv-64F指的是只有4层卷积作为特征提取网络,即图3的t3作为样本的输出特征向量。表6中A表示仅使用自适应特征融合嵌入网络;B表示使用AffeNet加SE作为特征提取网络;C表示把基类集和验证集组合为Dbase在训练AffeNet。实验表明使用不同层的特征融合和注意力模块可以提升细粒度图像的分类准确率,AffeNet在CUB-200上的5 way 1 shot和5 way 5 shot准确率分别达到了63.95%和84.86%。另外。把基类集和验证类集合并为新的基类集,可以有效防止过拟合,其准确率达到了64.76%和86.04%。
为了证明SIT和MIT训练方法的泛化性和特征处理的有效性,本文新增了消融实验2,实验结果见表7。第一组实验仅使用SIT训练方法,第二组实验为使用SIT和MIT先后训练的方法,第三组实验为SIT和MIT的基础上加上FP。实验结果证明本文的训练方法相比于单独使用SIT准确率提升了2.37和4.65个百分点。
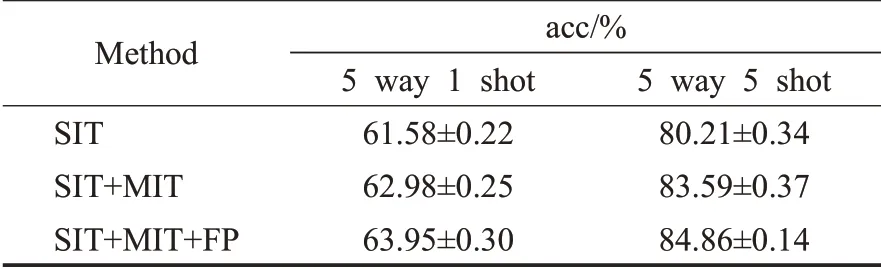
表7 在CUB-200上做的消融实验2Table 7 Ablation experiment 2 on CUB-200
2.8 其他实验细节
本文的AffeNet是端到端的网络结构,可以从零开始训练,因此对初始值的依赖程度很低,鲁棒性强。本文对三个数据集训练后的最佳自适应权值记录下来。γ和ξ的初始值为1,均为可训练的参数,其结果见表8。

表8 自适应权值γ和ξ的最佳取值Table 8 The best value for adaptive weights γ and ξ
3 结束语
本文提出了一个小样本细粒度图像分类方法。该方法使用自适应特征融合提取具有强语义信息的深层信息和位置结构信息的浅层信息,并且使用注意力进一步提取关键信息。为了使得特征提取网络在提取特征的同时,关注到样本之间的联系,能够适应到新类,本文使用SIT和MIT联合训练方法先后对AffeNet进行训练。在测试阶段,特征提取网络AffeNet提取每个样本的特征向量,并对特征向量做特征分布转换、QR分解、归一化处理,使得相同类别的特征向量分布在同一区域的特征空间。
本文在3个细粒度数据集Stanford Dogs、Stanford Cars、CUB-200对本文的方法进行评估。实验结果表明本文FSFGIC方法优于其他方法,有效地解决了现有的小样本细粒度图像分类问题。但是,小样本细粒度图像分类需要学习的任务量很大,因此训练较复杂的模型需要耗费大量的时间,在网络模型轻量化和训练方式简单化等方面还需要进一步研究。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
红外技术(2022年11期)2022-11-25
保定学院学报(2022年2期)2022-04-07
安阳工学院学报(2020年2期)2020-06-05
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
许昌学院学报(2018年4期)2018-05-02
电脑知识与技术(2017年26期)2017-11-20
中华建设(2017年1期)2017-06-07
自动化学报(2017年11期)2017-04-04
