
基于自纠错伪标签的无监督域自适应
2023-02-06 07:48:36林磊,孙涵
计算机技术与发展 2023年1期
林 磊,孙 涵
(南京航空航天大学 计算机科学与技术学院/人工智能学院,江苏 南京 211106)
0 引 言
随着深度学习的飞速发展,现实世界中也存在越来越多的域自适应问题,这些问题大部分是由于数据标注成本昂贵和深度模型对于不同任务的欠迁移性所导致的[1]。无监督域自适应旨在解决有标记的训练样本和无标记的测试样本来自于不同领域(分别称为源域和目标域)的问题。若用源域的标记样本进行训练学习到的模型,在不进行域自适应的情况下直接应用于目标域样本,则模型会出现明显的性能下降。这种性能的降低主要是由于两个领域之间存在因为数据分布差异而导致的域偏移所造成。不少域自适应方法采用伪标签[2]的思想,利用源域数据训练出的模型为目标域生成伪标签。但是现存的伪标签方法存在两个不足之处:伪标签由源域数据训练的模型生成,这会导致伪标签受限于源域数据,因为域迁移现象,该伪标签无法完全适配目标域数据;在训练的早期,网络可能生成错误的伪标签,不进行修正继续训练则会导致网络学习的分布与目标域分布差异越来越大。根据目前基于伪标签域自适应方法的不足之处,该文从伪标签的选择和更新两个方面提出了改进方案。
受到半监督学习中元伪标签[3]的启发,提出了基于自纠错伪标签的无监督域自适应方法(Self-correcting Pseudo Label for unsupervised domain adaptation,SPL)。首先,在伪标签生成阶段,主要使用源域子空间对齐和目标域聚类对齐结合的方法选择更优的初始伪标签。然后,在训练过程中,利用学生教师双网络模型进行伪标签的更新。具体而言,教师网络使用源域和目标域数据一起训练,生成最优伪标签,学生网络则使用目标域数据和伪标签进行有监督训练。接着,根据学生网络在伪标签目标域数据集上的表现,同步优化教师网络的参数,并且相应地调整伪标签,以进一步提高学生网络的表现。在多个标准域自适应数据集上的实验结果证明了该方法在域自适应问题的有效性。
1 相关工作
在无监督域自适应问题中,因为源域的标记样本和目标域的无标记样本在训练阶段都是可用的,所以它是一个可以进行归纳学习的过渡性学习问题。早期的方法试图通过学习一个联合子空间来调整源域和目标域,从而使任何一个域的样本都能被投射到这个共同的子空间中,然后采用不同的算法来促进目标域样本在这个子空间中的可分离性[4]。然后,使用在大规模ImageNet数据集上预训练的深度模型提取特征的方法进一步促进了这些基于特征转换的方法。随后,梯度反转[5]和对抗学习[6]的方法被用于深度域自适应,以学习端到端方式学习域不变特征。另一种有效的方式则是为目标域样本生成伪标签[7-8]。
尽管伪标签方法的性能很好,但是它们都有两大不足之处。首先,伪标签主要由有标记的源域数据训练的分类器生成,这样生成的伪标签会过度依赖于源域数据,而源域和目标域之间存在域偏移,所以这种伪标签就可能携带噪声信息,导致最后训练出来的网络在目标域上出现性能下降的情况。此外,目前伪标签主要分为硬伪标签和软伪标签。硬伪标签的策略是为每一个未标记的目标域样本都分配一个伪标签,然后将有伪标签的目标域样本和源域样本一起进行学习来改进分类模型。这种硬伪标签的问题是,在训练初期,弱分类器误标的样本可能会对后续学习过程造成严重伤害。弱伪标签则是为目标域样本分配每个类的条件概率,从而得到一个伪标签向量,并且在每次迭代训练的过程中都更新这个伪标签向量。虽然弱伪标签优于硬伪标签,但是如果弱伪标签更新方法的不佳同样会导致出现硬伪标签的问题。所以,针对目前伪标签方法存在的问题,该文提出了一种更加稳定的可以进行自纠错的伪标签域自适应方法。
2 自纠错伪标签网络
2.1 总体框架
提出的网络主要由学生网络S和教师网络T组成,它们对应的参数分别为θS和θT。教师网络的作用是利用有标记源域数据和无标记目标域数据训练,然后进行子空间对齐,将源域和目标域数据映射到易于区分特征的子空间内。接着,在该子空间内进行双重伪标签生成,分别从源域和目标域两个角度生成伪标签,综合考虑源域中可迁移知识和目标域内的结构信息。然后,从候选伪标签中选择最优伪标签加入伪标签集。接着,学生网络利用目标域数据集和伪标签集进行训练。但是,这个时候的伪标签集与真实的目标域标签集还存在一定的差异,需要进行自纠错更新。具体而言,设置一个反馈信号,用于反馈学生网络在伪标签集上的表现,然后将这一信号传递给教师网络更新教师网络的参数。学生网络和教师网络是并行训练的:学生网络从教师网络生成的伪标签数据中进行学习;教师网络从反馈信号中学习学生网络在伪标签数据上的表现,从而更新伪标签。经过这样的自纠错过程,网络可以学习到越来越贴合目标域的伪标签,成功实现从源域到目标域的迁移。
2.2 子空间对齐

(1)
XHXTa=φa
(2)
所以,降维矩阵A=[a1,a2,…,am1]∈m×m1可以由协方差矩阵XHXT的前k个特征值对应的特征向量构成。应用主成分分析降维后的数据m1×n为:
(3)
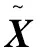
在这个子空间S,目的是拉近源域和目标域之间的分布,但是因为域偏移,想要整体匹配源域和目标域是不现实的,但是源域和目标域的标签空间是一致的。在一致的标签空间内,可以将源域和目标域数据一起进行类别的对齐。因为对于同一类别的样本,无论其来自于哪个域,在子空间S中投影应该是相近的。所以投影矩阵B的优化方式如下:
(4)
其中,W表示源域和目标域样本数据之间的相似矩阵。因为源域数据是有标注的,所以这里利用标注数据对相似矩阵进行优化,即同一类别的样本在映射空间内的距离应该是相近的,所以它们之间的权重可以设为1。
(5)
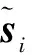
然后,利用MMD的优化方式,投影变换可以优化为:
(6)
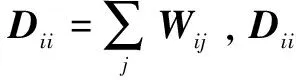
(7)
2.3 双重伪标签生成

(8)
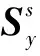
(9)
其中,d(Sy,T)表示目标域特征st与类别为y的源域类原型特征的距离。所以,可以利用目标域特征st与每一个类的源域原型特征之间的差异表示目标域特征st的条件概率:
根据源域的标签信息,获得了基于源域原型的条件概率ps(y|xt)。这一概率主要依赖于源域的类内分布,但是目标域的类内分布和源域之间还是存在一定差异的,所以只是使用源域类别信息的条件概率是不完善的,并且忽略了目标域自身的类别结构。为了获取目标域样本的内在结构,该文基于目标域类别空间生成新的伪标签。
具体而言,使用K-means聚类算法在所有目标样本的投影向量st生成|Y|个聚类族群,聚类的中心位置使用源域原型进行初始化。假设存在一个目标域映射和源域映射一对一的相关矩阵C∈|Y|×|Y|,并且对于任意的cij∈C存在以下关系:
(11)
其中,cij表示目标域中的第i个族群与类别j的相关性。该相关矩阵的优化方式如下:
(12)
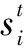
(13)
借此,可以得到基于目标域类别结构信息的条件概率:
(14)
使用迭代学习策略,交替学习用于域对齐的投影矩阵P和用于目标样本的双伪标签。尽管上述两种伪标签方法中的任何一种都能够为下一次迭代中的投影学习提供有用的伪标签,但它们在本质上是不同的。通过最近的源域类原型进行的伪标签倾向于向靠近源数据的样本输出高概率,而基于目标域结构化预测则对靠近目标域的聚类中心的样本具有高置信度,无论它们离源域有多远。所以,该文主张通过公式10和公式14的简单组合来利用这两种方法的互补性:
p(y|xt)=max{ps(y|xt),pt(y|xt)}
(15)
(16)
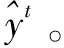
2.4 自纠错伪标签更新
在半监督学习领域中,学生教师模型的方法已经被广泛应用到伪标签生成中,但是大部分的方法都是学生和教师之间无反馈的训练。受到元伪标签的启发,该文在域自适应学生教师模型中引入自纠错的伪标签更新方式。具体而言,存在一批源域数据xs及其标签ys,目标域数据xt,对于学生网络S和教师网络T,可以获得相应的软预测值S(xt;θS),T(xs;θT)和T(xt;θT)。其中,学生网络只使用目标域数据,教师网络则同时使用源域和目标域数据。所以在有监督训练中,可以使用CE(ys,S(xt;θS))作为典型的交叉熵损失。在伪标签训练过程中,往往通过最小化目标域数据的交叉熵损失来优化学生网络的参数:
(17)
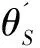
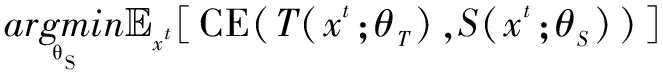
(18)
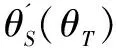
∇θSExt[CE(T(xt;θT),S(xt;θS))]
(19)
其中,ηS表示学习率。所以,可以获得最终的学生网络优化目标:
∇θSExt[CE(T(xt;θT),S(xt;θS))]}
(20)
(21)
LT,s=CE(ys,S(xs;θT))
(22)
(23)
3 实验与分析
主要使用三组域自适应任务中通用的数据集对上述方法进行了对比实验,分别是Office-31[10]数据集、Office-Home[11]数据集以及VisDA-2017[12]数据集。为了验证提出的基于自纠错伪标签算法的有效性,选择与多个无监督域自适应的方法相比较,这些方法中有的使用了对抗学习的方法,有的则使用了伪标签的思想。
该文主要使用Pytorch深度学习框架来实现基于自纠错伪标签的无监督域自适应方法。为了公平比较,每次实验都用相同的网络结构。利用不包含最后全连接层的,在ImageNet上进行预训练的ResNet50作为特征提取器。使用了源域中所有的标签数据和目标域中所有的无标签数据,最终在目标域数据集上比较算法的图像分类的准确率。主要使用的GPU为Nvidia Titan Xp显卡,主要环境是在Ubuntu16.04操作系统下。
根据表1的实验结果,提出的SPL算法在六种迁移任务上的平均准确率都优于其他对比算法。SPL算法相较于不进行域自适应的ResNet-50,在平均准确率上提高了近13.9百分点。相较于同样使用聚类伪标签但是伪标签没有更新的CAT方法也有不错的提升,平均准确率比CAT高了2.4百分点。具体到每一个迁移任务,SPL的方法虽然在A→W、D→W和A→D任务上稍低于REN,但是在迁移任务更加困难的D→A和W→A上,SPL的方法明显优于REN,分别提升3.1和1.1百分点。
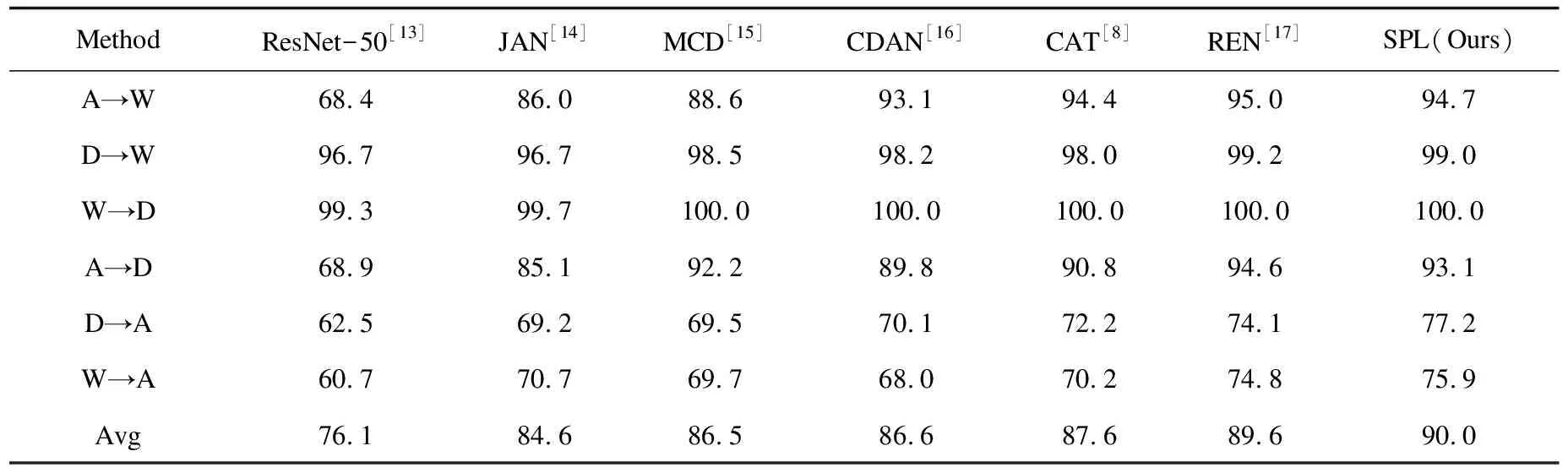
表1 Office-31实验结果 %
Office-Home数据集的实验结果如表2所示。Office-Home数据集相较于Office-31数据集更加困难。不过基于自纠错伪标签的SPL在面临这类困难情况时,发挥出了伪标签自纠错的优势,最终平均准确率比ResNet-50高了22.6百分点,证明该算法具有不错的泛化能力。对于12个不同的迁移任务,SPL在多个迁移任务上都表现最佳,尤其是Ar→Cl、Cl→Ar和Pr→Cl任务上,相较于第二名提升了2~3百分点。这是因为在这些难度较大的任务上,源域和目标域之间的差异过大,之前的方法大部分都过分依赖于源域的标签信息,而SPL充分考虑到了目标域的结构信息,根据源域和目标域的结合提取出了更优的伪标签,并且在后续更新中一直优化伪标签,从而迁移能力更强。

表2 Office-Home实验结果 %

续表2
对于VisDA-2017数据集,只使用了其中的合成数据集到真实数据集的迁移任务。因为VisDA-2017数据集比较复杂,所以采用ResNet-101作为主干网络。因为该数据集的复杂性,大部分对比算法都无法在所有类别上表现良好,比如MSTN虽然在类别aero和mcycl上取得了最好的效果,但是其在truck的准确率只有18.5%。文中方法虽然只在类别horse和person上表现最佳,但是基本上在其他类别上效果也不错,所以最终的平均准确率要优于其他的对比算法。
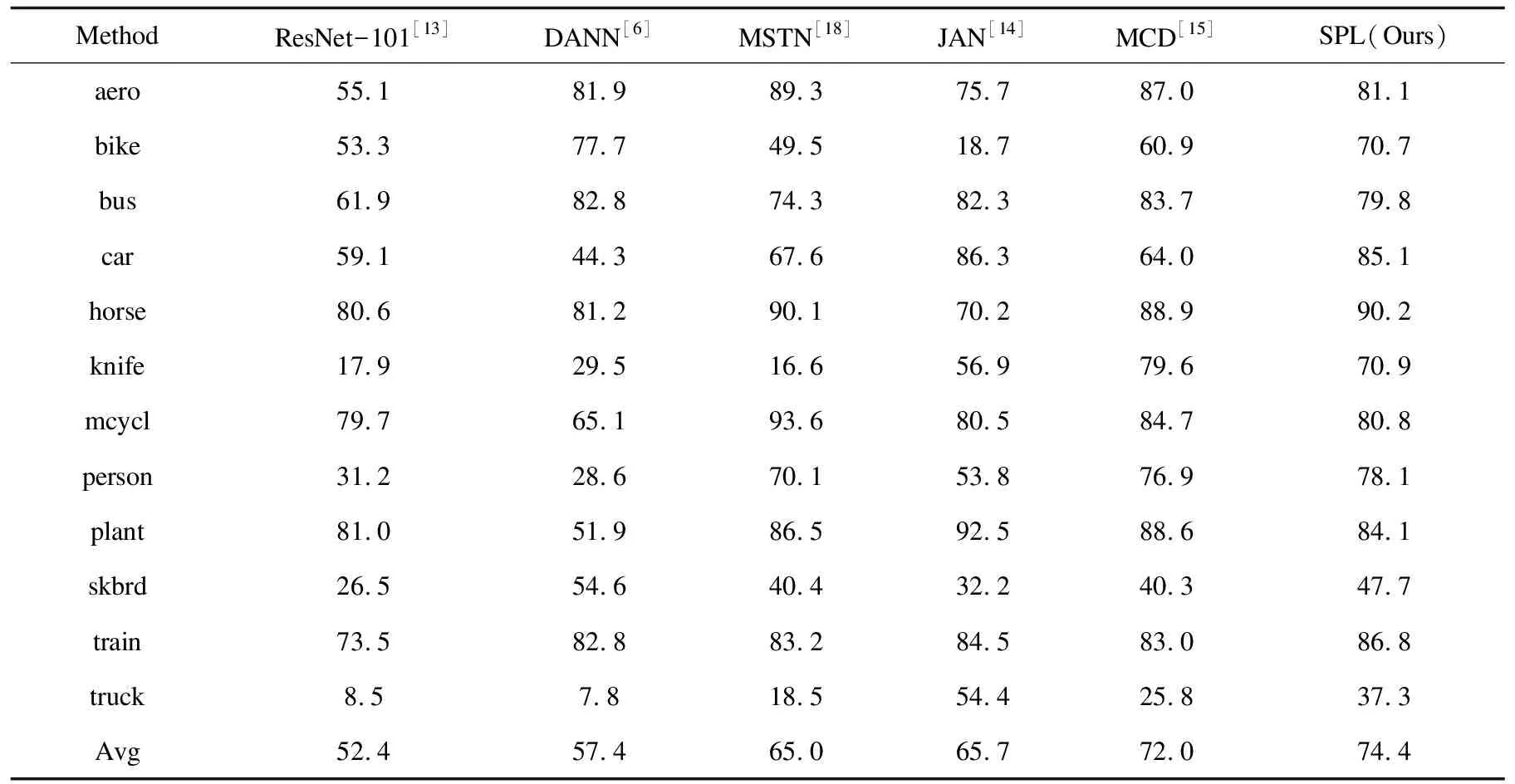
表3 VisDA-2017实验结果 %
4 结束语
探讨了域自适应问题中如何有效地使用伪标签方法,提出了基于自纠错伪标签的无监督域自适应方法,不仅提出了更优的伪标签选择方案,而且使用了可以自动纠错的伪标签更新方案。在伪标签选择阶段,充分考虑了源域的类别信息和目标域的内在结构信息,从这两方面出发提出了双重伪标签,使生成的伪标签避免受限于源域知识,并且更符合目标域的特征分布。鉴于单网络生成的伪标签可能无法完全监督该网络的训练,使用了学生教师模型,利用教师网络同时训练源域和目标域特征,然后为学生网络生成伪标签,使伪标签的生成与使用分离。但是只有教师到学生网络的单向反馈是不足的,该文使用元伪标签的思想,通过学生网络在利用伪标签进行训练时的反馈,反向优化教师网络,使其形成一个循环优化的过程。提出的SPL方法在Office-31、Office-Home和VisDA-2017数据集上进行了大量的实验,并且与多个不同无监督域自适应方法进行了比较,验证了SPL方法的有效性以及迁移能力。
猜你喜欢
计算机技术与发展(2024年3期)2024-03-25 02:10:02
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
计算机技术与发展(2020年11期)2020-12-04 07:50:46
车迷(2018年11期)2018-08-30 03:20:32
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
海峡姐妹(2018年3期)2018-05-09 08:21:02
数学学习与研究(2017年3期)2017-03-09 18:12:42
公民与法治(2016年10期)2016-05-17 04:12:58
中国老区建设(2016年1期)2016-02-28 09:32:00
电子与信息学报(2015年12期)2015-08-17 11:14:42
