
一种用于心电图分类的改进神经网络算法
2023-02-06 07:48:32尘昌华乔风娟
计算机技术与发展 2023年1期
尘昌华,乔风娟,李 彬
(1.上海开放大学奉贤分校,上海 201499;2.齐鲁工业大学(山东省科学院) 数学与统计学院,山东 济南 250353)
0 引 言
据统计,心血管疾病的死亡率在所有疾病中居于首位,远高于恶性肿瘤、呼吸系统疾病等。心电图(Electrocardiogram,ECG)能够反映人体的电信号活动情况,是医生用来诊断心血管疾病的重要依据。由于ECG中包含各种噪声,如基线漂移、肌电干扰和工频干扰等,医生在诊断时往往需要先忽略干扰较多的波形再进行判断。
近年来,计算机辅助ECG诊断技术有了较大发展。现有的诊断技术主要包括三个步骤:去噪、特征提取和分类。常用的去噪方法主要有:基于小波变换的方法[1]、基于数字滤波器的方法[2]以及基于阈值的方法[3]等。Singh[4]将经验小波变换(Empirical Wavelet Transform,EWT)用于ECG信号的去噪,证明了该算法的有效性;Sai[5]证明了在ECG信号的去噪过程中,提升小波变换(Lifting Wavelet Transform,LWT)的去噪性能优于中值滤波。
深度学习方法能够同时实现ECG信号的特征提取和分类,近年来在ECG辅助诊断方面取得了令人满意的成果。Acharya等[6]设计了一种九层的卷积神经网络结构,在MIT-BIH数据集上实现了94.03%的识别准确率;Chauhan等[7]采用LSTM网络对正常心跳和异常心跳进行分类,准确率为96.45%;Shu等[8]将LSTM与CNN相结合,开发了一种新的处理变长心电信号的混合结构,在MIT-BIH数据集上的识别准确率为98.10%。但是,现有的大多数算法都是仅基于MIT-BIH这一个数据集得出的结论,该数据集仅采集了47个人的心电图,算法的泛化性和实用性难以得到验证。
为了较好地提高ECG信号的分类识别率和处理效率,该文提出了基于EWT的提升小波阈值去噪方法:对含噪信号进行经验小波分解,得到多频率的模态分量IMFs;对IMFs作提升小波阈值去噪处理;用经过提升小波阈值去噪技术处理过的模态分量进行重构,得到最终去噪后的信号。然后,设计了LRF-BLSTM-Attention模型,利用三个交替的随机卷积层和最大池化层提取ECG信号的空间特征,利用BLSTM获得ECG信号的时间特征,在BLSTM隐藏层的输出中引入注意力机制,给重要的特征分配更多的注意力,进一步挖掘序列信息的相关性,提高ECG识别的准确率。最后,基于CCDD和MIT-BIH数据集进行仿真实验,验证该所提出模型算法结构的实用性。
针对心电信号的自动分类工作进行研究,首先,现有的算法大多都是基于MIT-BIH数据集,该数据集的心电信号来自于少数个体,代表性不强。这造成有些算法在该数据集上能够取得很好的识别准确率,在临床应用上的识别效果很差。该文不仅采用了MIT-BIH Arrhythmia数据集,还采用了CCDD数据库,该数据库数据量大,且背景噪声较多,共有17万条来自不同病人的心电信号,更具有临床代表性。同时,现有的心电信号自动分类方法多是针对单导联数据进行分类,不能考虑其他导联的特征信息。该文考虑了导联之间的相关性,提出了多通道模型,能够实现多导联心电信号的分类。
1 基于EWT的提升小波阈值去噪方法
经验小波变换[9]是Gilles结合经验模态分解和小波分析而提出的信号处理方法。
首先,将信号频谱范围规范化到[0,π],并将其分割为连续的N段,每段为Λn,即:
(1)
假设为以ωn为中心,即Λn=[ωn-1,ωn],则宽度为Tn=2τn。


(2)
(3)
其中,β(x)=x4(35-84x+70x2-20x3)。

(4)
(5)

提升小波法[10]是Swelden在小波变换的基础上提出的第二代小波算法,继承了第一代小波算法的多分辨率特性,且不依赖于傅里叶变换,大大降低了算法复杂度和内存需求,是目前对离散信号进行分析的重要方法。
提升小波法主要分为分裂、预测、更新三个步骤:首先,根据原始信号x(n)的奇偶性分解为两个互不重叠的奇序列{xo(k)=x(2k+1)}和偶序列{xe(k)=x(2k)};根据相关性原则,利用偶序列来预测奇序列,产生细节信号d(k):d(k)=xo(k)-P(xe(k));根据完整性原则,对偶序列进行更新,得到信号的逼近序列c(k),更新公式为c(k)=xe(k)+U(d(k)),U为更新算子。
文中所使用的阈值去噪方法是Donoho等人提出的软阈值去噪法,软阈值函数为:
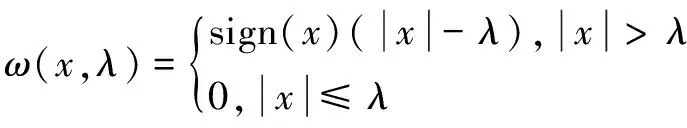
(6)
其中,λ为阈值,x为高频小波系数。
在上文所述基础上,提出了EWT的提升小波阈值去噪方法[11],该方法的主要操作过程如下:首先,对含噪的原始信号进行经验小波分解,得到多频率的模态分量IMFs;然后,对IMFs作提升小波阈值去噪处理;最后,重构经过提升小波阈值去噪技术处理过的模态分量,即可得到最终去噪后的信号。
2 相关模型
2.1 基于局部感受野的极限学习机
基于局部感受野的极限学习机(Local Receptive Fields Based Extreme Learning Machine,ELM-LRF)是在极限学习机的基础上引入局部感受野的概念而提出的一种网络模型,能够实现特征的自动提取和分类,具有模型复杂度低、速度快的优点[12]。
ELM-LRF模型的网络结构主要包括随机卷积层、池化层和输出层三个部分,如图1所示。

图1 ELM-LRF模型的网络结构
(1)随机卷积层。随机卷积的概念借鉴于卷积神经网络中的卷积操作。不同点在于:随机卷积过程中,卷积核中的每一个元素都根据概率分布随机生成并确定,不需要进行迭代、微调。假设模型的输入是大小为d×1的向量,卷积核的大小为r×1,第k个特征图的权重表示为ak∈Rr×1,输出节点(i,1)处的值ci,1,k(x)为:

i=1,2,…,(d-r+1)
(7)
(2)最大池化层。利用最大池化去除冗余信息,减少特征维数。设池化大小为s×1,第k个特征图在节点(p,1)处的值hp,1,k为:
hp,1,k=max(ci,1),i=p-s/2,…,p+s/2
(8)
其中,p,q=1,2,…,(d-r+1)。
(3)输出层。通过最后一个隐藏层的输出H求解输出权重β,计算公式为:

(9)
2.2 BLSTM
LSTM是循环神经网络[13](Recurrent Neural Network,RNN)的一种变型,能够避免RNN训练过程中出现的梯度消失或梯度爆炸问题,目前已广泛应用于文本分类[14]、电力预测[15]等多个领域。
一般的LSTM记忆单元结构如图2所示。LSTM网络由输入层、隐藏层和输出层组成,与传统RNN不同的是,LSTM网络的隐藏神经元由LSTM记忆单元构成,每个记忆单元包括遗忘门(Forget Gate)、输入门(Input Gate)、输出门(Output Gate)三个部分,遗忘门确定当前的细胞状态中的舍弃信息,输入门确定更新当前细胞状态的信息,输出门确定隐藏层的输出状态。

图2 一般的LSTM记忆单元结构
LSTM的计算过程如下:
ft=σ(Wf[xt,ht-1]+bf)
(10)
it=σ(Wi[xt,ht-1]+bi)
(11)
gt=tanh(Wg[xt,ht-1]+bg)
(12)
ot=σ(Wo[xt,ht-1]+bo)
(13)
ct=ft⊙ct-1+it
(14)
ht=ot⊙tanh(ct)
(15)
其中,ft、it、ot、ct分别表示遗忘门、输入门和输出门和细胞状态在t时刻的输出,Wf、Wi和Wo分别表示各个门结构的权重,bf、bi和bo分别表示它们的偏置。xt表示t时刻的输入,ct表示t时刻的细胞状态,ht表示隐藏层在时刻t的输出,σ表示sigmoid函数,tanh表示双曲正切激活函数,⊙表示Hadamard乘积。
心电图信号的分类识别依赖于过去和未来的时间特征信息,而LSTM只能考虑过去的信息,不能考虑未来的信息,在一定程度上影响了心电图的识别效果。BLSTM模型是在LSTM的基础上提出的[13],能够弥补LSTM模型的不足,通过正向LSTM传播和反向LSTM传播能够分别学习心电信号的前向特征和后向特征。二者结合,就能得到心电信号的总体特征。
2.3 注意力机制
注意力机制(Attention Mechanism)于2014年由Bahdanau提出[15],模仿了人类大脑中特有的图像处理机制。该方法能够根据需要有选择地分配注意力,提高计算机进行信息处理的效率。注意力机制目前广泛应用于各种深度学习领域,如机器翻译[16]、图像处理[17]、文本分类[18]等。注意力机制在BLSTM中的计算过程如下:
首先,根据当前时刻信号过去和未来信号的依赖关系,对BLSTM网络隐藏层输出的信号特征ht赋予注意力权重at。其计算公式为:
at=tan(ht)
(16)
接着,通过softmax函数对注意力权重at进行归一化处理。计算公式表示为:
(17)
最后,分配注意力权重。根据注意力权重的大小给特征向量ht分配注意力资源,增强信号的特征表达能力。计算公式表示为:
(18)
在心电图识别任务中,通过随机卷积层和池化层能够获得心电信号的局部空间特征,通过BLSTM网络能够进一步得到心电信号的时间特征表示。然而,这两部分都没有突出心电信号当前采样点与之前、之后采样点之间的关联性,不利于长时间的心电信号识别任务。为了增强距离较远采样点之间的相关性,该文引入了注意力机制,即有选择地给与不同重要程度的采样点不同的注意力资源。在模型中引入注意力机制,不仅能够获得心电信号的空间特征和时间特征,还能够考虑当前采样点和上下文时刻采样点的关联性,使得模型在具有重要信息的区域获得更多的注意力资源,提高心电图分类识别的准确率。
3 文中方法
3.1 模 型
结合ELM-LRF、BLSTM和注意力机制,该文提出了一种新的网络结构,记为LRF-BLSTM- Attention模型。下面以多导联数据的心电信号自动分类任务为例,介绍该模型的网络结构。如图3所示,该模型由输入层、ELM-LRF特征提取器、BLSTM网络层和注意力层四大部分组成。
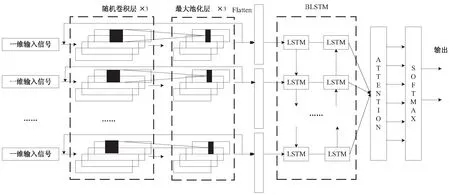
图3 LRF-BLSTM-Attention模型结构
(1)输入层。
该模型的输入是去噪后的心电信号,以每一个导联分别作为输入,训练多个ELM-LRF特征提取器。设一段心电信号共有m个导联,n个采样点,则该信号可以表示为:

(19)
共训练m个ELM-LRF特征提取器,第i个特征提取器的输入是xi=(xi1,xi2,…,xin)。
(2)ELM-LRF特征提取器。
ELM-LRF特征提取器通过三个堆叠的随机卷积层和最大池化层对输入的心电信号进行深层特征提取,随机卷积层和池化层交替出现。首先,利用第一个随机卷积层对心电信号特征提取,并将输出作为第一个最大池化层的输入,该层的输出为第二个随机卷积层的输入,依此循环,共有三个随机卷积层和三个最大池化层。将最后一个最大池化层的所有特征子图合并,传送到BLSTM部分。
卷积核大小的不同代表局部感受野的不同,能够提取到不同层次的特征。在实际任务中,随机卷积层中卷积核的大小和池化大小根据经验确定大致范围,并通过试凑法确定。
(3)BLSTM网络层。
ELM-LRF特征提取器的输出表示为(s1,s2,…,sn),以此作为BLSTM网络层的输入。BLSTM网络可以看作一个正向LSTM和一个反向LSTM,隐层输出分别表示为hf=(hf1,hf2,…,hfn)和hb=(hb1,hb2,…,hbn),将hf和hb进行拼接,得到h=(hf;hb),即为BLSTM网络层所提取的特征向量,反映了输入序列的时间信息和依赖关系。
(4)注意力层。
为了进一步凸显心电信号的主要特征,引入注意力机制。将BLSTM网络层所提取的特征向量h=(hf;hb)进行整合,得到注意力层的输入,表示为H:(h1,h2,…,hn)。由式(16)、(17)、(18),得到最终的特征向量,并利用softmax函数得到分类结果。
3.2 模型训练
所提出模型算法中,随机卷积层的参数是根据概率分布随机确定的,不需要通过迭代调整。因此,仅需要训练BLSTM和注意力机制中的参数。本模型在最后一个Dense层利用softmax进行分类,计算公式如下:
(20)
其中,j为类别,xi表示输入的第i个样本,P(yi=j|xi)为获得第i个样本的类标签的概率函数。N表示样本数目,w表示模型中的参数。
在训练过程中,优化器选择Nadam[19],损失函数为交叉熵损失函数,计算公式为:
(21)
其中,yi为第i个样本的类标签,m为类别总数。
为了防止过拟合,在训练时引入Dropout,以一定的概率丢弃一些隐层神经元。为了提高运行速度,降低对内存的要求,实验采用分批次训练方法,批次大小设为128。
4 仿真实验
4.1 实验环境及评价指标
实验所利用的处理器是3.70 GHz Intel(R) Core(TM) i7-8700K,内存为32 GB,使用的编程语言为MATLAB R2018a和Python 3.5,调用的库主要有:Keras、Numpy、wfdb、matplotlib、pandas、scipy、math等。
为了验证所提出方法的有效性,以特异性、灵敏度和准确率作为模型性能的评价指标。
4.2 数据集描述
(1)中国心血管疾病数据集。
中国心血管疾病数据集(Chinese Cardiovascular Disease Database,CCDD)是针对中国的心血管疾病患者而建立的[20],数据库的所有数据均来自于医院的临床数据。该数据库中共包含17万多条数据,每条数据都来自不同的患者,共包含十二导联数据,采样时间为10 s左右,采样频率为500 Hz。
(2)MIT-BIH Arrhythmia数据集。
MIT-BIH心律失常数据集[21]包含了来自Beth Israel Hospital (BIH)住院患者的48条心电图信号记录。每一个心电信号都超过30分钟,并由心血管疾病专家进行注释。在该数据集上,以单个的心拍为单位进行分类。首先,对数据下采样到250 Hz[22]并去噪,通过pan-tompkin算法检测R峰[23],并取R峰前100、后149个采样点组成一个完整的心拍。本实验中,共使用四种心拍类型,分别是正常窦性心律(Normal Sinus Rhythm,NSR)、左束支传导阻滞(Left Bundle Branch Block,LBBB)、右束支传导阻滞(Right Bundle Branch Block,RBBB)、室性早缩(Ventricular Premature Contraction,VPC)。
4.3 CCDD的预处理
(1)读取数据。由于导联数据的正交性,实验中读取八个导联的数据,分别是Ⅱ、Ⅲ、Ⅴ1、Ⅴ2、Ⅴ3、Ⅴ4、Ⅴ5、Ⅴ6导联,其他导联的数据可由这八个导联推导得出。
(2)剔除标签为“0x00”(无效)和采样时间不足9 s的心电记录。由于操作失误等原因可能会导致心电信号一直为0,将这类记录也剔除。
(3)考虑到内存需求和数据平衡性要求,在剩下的数据中选择前5万正常数据和前5万异常数据作为本次实验的数据集,共计10万数据。将实验数据集随机打乱,并按照7∶3的比例分为训练集和测试集。
(4)为了降低模型训练的复杂度,根据文献[22],实验中将CCDD的数据下采样到250 Hz。
(5)去噪。对CCDD数据库中的心电记录进行基于EWT的提升小波阈值去噪实验。
4.4 实验设计和结果
(1)CCDD。
LRF-BLSTM-Attention模型用于CCDD数据集时的结构设计如表1所示。第一至六层为特征提取器,随机卷积层和最大池化层交替出现,随机卷积层中分别采用4、8、16个大小为7×1、6×1、5×1的卷积核;第七层和第八层分别为BLSTM层和Attention层,第九层为Dense层,利用softmax函数输出心电信号的类别概率。
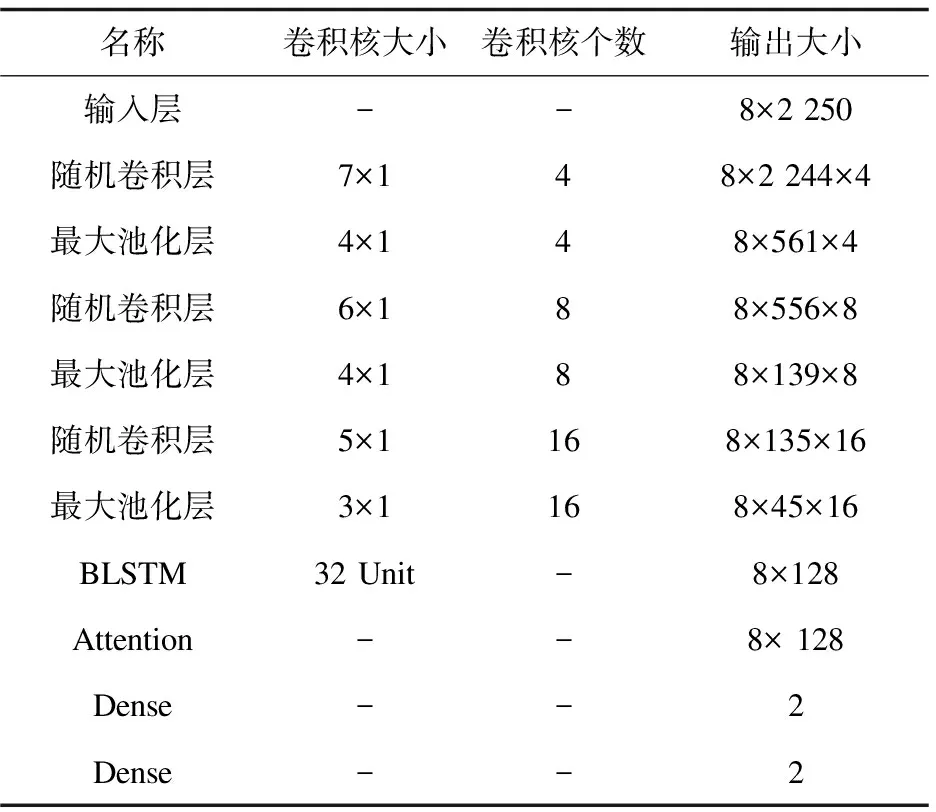
表1 CCDD的LRF-BLSTM-Attention结构设计
利用Dropout防止过拟合处理中,选择合适的丢弃概率对网络模型的训练至关重要,如果丢弃概率太小,可能难以达到消除过拟合的作用,如果丢弃概率太大,则可能会丢失数据中的重要信息。实验中分别选择不同的Dropout值进行多次实验,结果如图4所示。当Dropout取值为0.3时,测试集的准确率达到最高,为86.12%,因此,最终Dropout的取值为0.3。

图4 不同Dropout值下的测试集准确率
为了进一步评估所提出的LRF- BLSTM-Attention模型在心电图信号识别领域的性能,将该模型与LSTM、BLSTM、LRF-BLSTM(未引入注意力机制)、LRF-BGRU-Attention (Bidirectional Gated Recurrent Unit)和LRF-BLSTM- Attention模型进行对比,结果如图5所示。
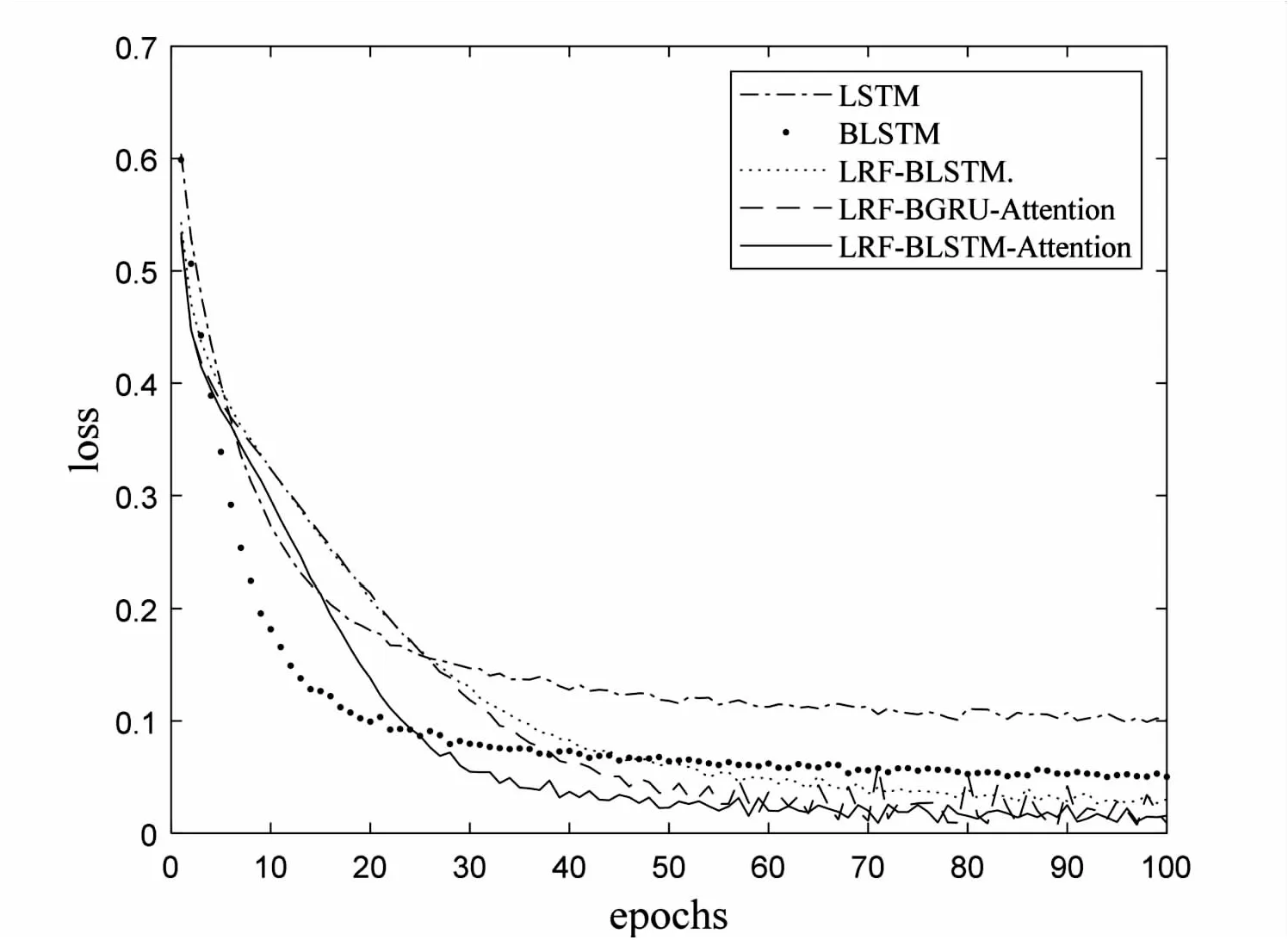
图5 各模型的loss变化曲线
由图5可以看出,随着迭代次数的增加,所有模型的损失值逐渐下降并最终收敛趋于稳定。LSTM模型和BLSTM模型收敛较快,但loss函数最终收敛的值偏大,说明这两种模型的学习能力较差。而LRF-BLSTM模型、LRF-BGRU-Attention模型、LRF-BLSTM-Attention模型的loss函数最终收敛的值较小,说明ELM-LRF与BLSTM模型的结合提高了模型的学习能力。
在这三种模型中,LRF-BLSTM模型在训练约90轮后loss曲线趋于平稳,而LRF-BGRU-Attention模型和LRF-BLSTM- Attention模型的loss函数达到最终收敛大约需要经过50轮迭代训练。这说明注意力机制的引入加强了序列信息之间的关联性,进一步优化了模型的特征表达能力,从而使得loss函数达到收敛所需的迭代次数降低。
各模型在CCDD上的识别结果如表2所示。可以看出,LSTM模型的识别准确率为75.43%,BLSTM模型的识别准确率为75.91%,这是因为单项LSTM模型只能学习时间序列的历史信息,而BLSTM模型能够同时学习历史和未来的信息,优化了模型的特征表达能力,因此接下来的实验中均采用BLSTM层LRF-BLSTM-Attention模型的loss值比LRF-BGRU-Attention模型低,说明LRF-BLSTM- Attention模型具有更好的特征表达能力。相较于其他对比模型,所提出的LRF-BLSTM-Attention模型的灵敏度和识别准确率均最高,分别为89.32%和86.12%。同时,可以发现使用未去噪数据的LRF-BLSTM-Attention模型(No Denoising)准确率为84.26%,相较于使用去噪数据的LRF-BLSTM- Attention模型准确率较低,证明了所提出的去噪算法(基于EWT的提升小波阈值去噪方法)的实用性。

表2 不同算法在CCDD上的识别结果 %
表3列出了不同算法训练一轮的时间。可以看出,LSTM在CCDD数据上训练一轮所需要的时间是41 s,BLSTM需要61 s。对比LSTM模型和BLSTM模型,LRF-BLST模型训练一轮仅需要29 s,这是因为LRF模型能够通过卷积和池化操作减少输入特征的维数,进而减少训练时间。LRF-BGRU-Attention模型训练一轮的时间为27 s,比LRF-BLSTM模型的时间少,这是因为BGRU模型比BLSTM模型的复杂度更低,但是BGRU模型的震荡幅度较大,说明该模型的稳定性较差。LRF-BLSTM-Attention模型训练一轮的时间为45 s,比LRF-BLSTM所需的时间多,说明进入注意力机制的LRF-BLSTM-Attention模型复杂度更高,所需的训练时间更长。由图5和表3,相比于其他对比模型,LRF-BLSTM-Attention模型达到最小loss值所需要训练的轮数更少,loss值也最小,因此,认为增加模型复杂度是有必要的。

表3 不同算法训练一轮的时间对比
为了进一步评估所提出算法的性能,表4给出了在CCDD上多种模型的识别结果比较。Wang L P等[24]提出了ECG-MTHC(Multi-way Tree Based Hybrid Classifier,MTHC)模型,以牺牲特异性为代价,达到了较高的灵敏度,最终识别准确率为77.70%。Jin L P[25]针对多导联心电图,设计了多导联卷积神经网络,达到了83.66%的识别准确率。Li H H[26]首先筛选异常数据,然后使用导联卷积神经网络进行分类,识别准确率达到了84.77%。与其他的识别算法比,LRF-BLSTM-Attention模型的识别准确率最高,为86.12%,特异性和灵敏度分别为82.94%和89.32%。该实验证明了LRF-BLSTM-Attention模型在计算机辅助心血管疾病诊断领域的实用性和高效性。

表4 在CCDD上多种模型的识别结果比较 %
(2)MIT-BIH数据集。
由于目前大多数心电识别算法的评估都是基于MIT-BIH数据集进行的,为了进一步验证所提出的LRF-BLSTM-Attention模型的性能,实验中也将该模型用于MIT-BIH数据集的识别。在MIT-BIH数据库的识别任务中,一条心拍的长度为250,因此模型的输入为250×1,相比于CCDD数据集中一条记录的长度为2 250少了很多。为了防止在训练过程中丢失过多信息,实验中减小了池化层中的核的大小,其具体设计如表5所示。
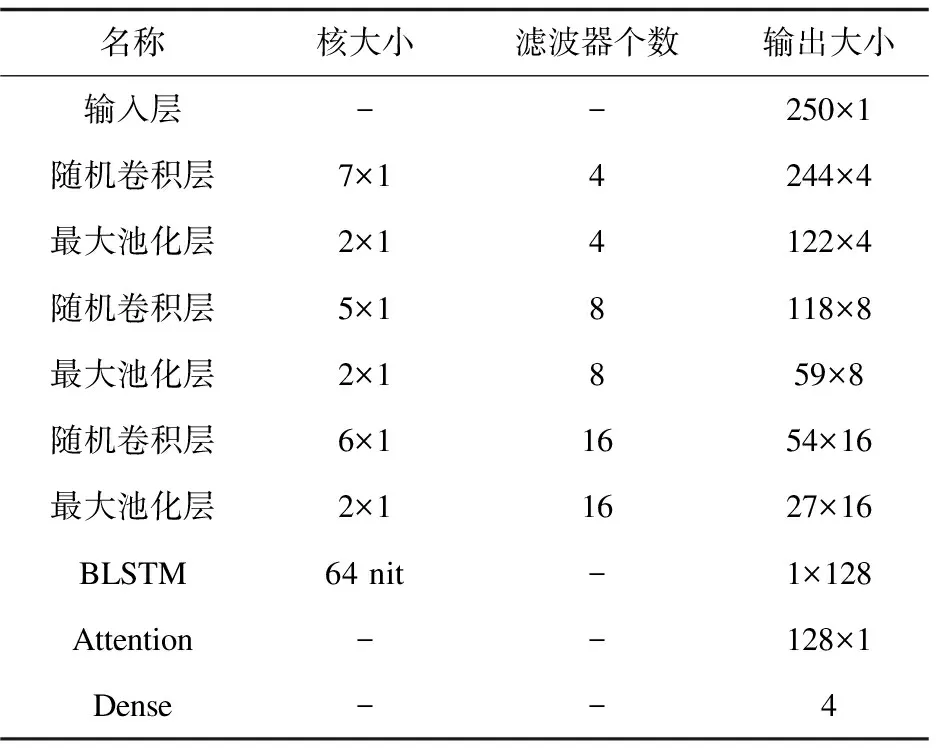
表5 MIT-BIH数据库的LRF-BLSTM-Attention
各模型的loss曲线如图6所示。对比其他模型,LRF-BLSTM-Attention模型的loss曲线达到稳定状态所需的训练论数最少,并且达到的loss值最小,说明了所提出模型的优越性。

图6 各模型的loss变化曲线
与大多数现有的心电图分类模型相比,所提出的算法具有优势。不同模型的识别结果如表6所示。Elhaj[27]通过多种特征提取方式进行特征提取并融合,利用SVM进行分类,得到98.91%的识别准确率;Acharya[6]通过9层的CNN实现心电信号的自动分类,识别准确率为94.03%;Yang[28]利用PCANet提取特征,并利用SVM分类,实现97.08%的识别准确率;Yang[29]结合ICA和PCANet对心电信号进行识别,识别准确率达到98.63%;在之前的文章中,利用LRF-BLSTM模型分别实现了99.32%,97.15%的准确率和灵敏度[30]。与对比模型相比,所提出的算法在MIT-BIH数据集上达到较高的识别准确率,为99.87%。

表6 MIT-BIH上不同模型识别结果
4.5 结果分析
ELM-LRF能够学习心电信号的空间信息。卷积操作通过构建随机滤波器平滑时间序列,学习其特征表示;池化操作能够去掉冗余特征,减小输入的特征维数,具有平移不变性、旋转不变性和尺度不变性等特点。BLSTM模型能够充分学习历史和未来的时间信息,获得序列的时间特征表示。LRF-BLSTM模型结合ELM-LRF模型和BLSTM模型的优点,使得模型的识别效率提高。在LRF-BLSTM中引入注意力机制,能够加强当前时间信息与历史、未来信息的关联性,利用分配注意力权重的大小凸显特征向量的重要程度,从而进一步优化模型的特征提取和表达能力。因此,所提出的LRF-BLSTM-Attention模型能够强化心电信号的特征表示,实现较高的识别准确率,在CCDD和MIT-BIH数据集上分别达到了86.12%和99.87%。
在时间复杂度方面,由于ELM-LRF模型能够降低输入特征的维数,减少训练时间,因此LRF-BLSTM模型训练一轮所需的时间比单一的BLSTM模型少。LRF-BLSTM-Attention模型由于引入了注意力机制,使得模型复杂度增加,但loss曲线收敛速度加快,总体训练时间减少。
实验结果表明,LRF-BLSTM-Attention模型在心血管疾病的计算机临床辅助诊断中具有较好的实用性和计算效率。
5 结束语
针对心电图识别问题,提出了一种基于EWT的提升小波阈值去噪方法,并设计了LRF-BLSTM- Attention模型。ELM-LRF、BLSTM和注意力机制的结合能够提高模型的特征提取能力,进而提高识别准确率。分别在CCDD和MIT-BIH数据集上进行实验,识别准确率分别为86.12%和99.87%,验证了LRF-BLSTM-Attention模型在心电图识别问题上的优势。注意力机制的引入增加了模型复杂度,在未来的心电图识别中,将进一步改进该模型,降低时间复杂度,处理更多、更复杂的心电图数据。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
成都信息工程大学学报(2021年4期)2021-11-22 07:44:40
科技传播(2019年24期)2019-06-15 09:29:28
电子制作(2018年19期)2018-11-14 02:37:08
北京航空航天大学学报(2017年9期)2017-12-18 07:12:22
传媒评论(2017年3期)2017-06-13 09:18:10
自动化学报(2017年11期)2017-04-04 02:52:58
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
噪声与振动控制(2015年4期)2015-01-01 07:08:21
汽车电器(2014年8期)2014-02-28 12:14:29
