
基于强化学习的异构超密度网络资源分配算法
2023-02-06 07:48任正国
计算机技术与发展 2023年1期
吴 锡,任正国,孙 君
(南京邮电大学 江苏省无线通信重点实验室,江苏 南京 210003)
0 引 言
随着无线设备的急剧增加,现有的蜂窝网络已经无法满足爆炸式增长的无线业务需求。异构超密度网络使用具有不同传输功率和覆盖范围的微小区和毫微小区来增强现有的蜂窝网络,这些异构网络(HetNet)可以将用户设备(User Equipment,UE)从宏基站(Macro Base Station,MBS)转移到微基站(Pico BS,PBS)和毫微基站(Femto BS,FBS)。此外,PBS和FBS可以重复使用MBS并与MBS共享相同的信道,实现异构网络的高频谱效率。因此,异构超密度网络被认为是增加未来无线通信系统容量的方案之一。此类异构网络中存在一些问题亟待优化,例如小区间干扰,资源浪费以及能源消耗大的问题。设计节能高效的无线通信系统已成为一种新趋势[1-3],合理的频谱分配和功率分配策略能显著地提升能源效率和系统容量。文献[4]提出了异构网络中用户关联和资源分配的联合优化方案,但是,考虑到非凸性和组合性,获得联合优化问题的全局最优策略是具有挑战性的。为了提升异构小区的能源效率,满足用户的服务质量,文献[5]研究了基于凸优化的方法分配传输功率以及带宽。文献[6-7]分别研究了博弈论方法、线性规划方法解决联合用户关联和资源分配问题。但是,这些方法需要几乎完整的信道状态信息,而完整的信道状态信息通常很难得到。近年来深度强化学习成为人工智能应用中一种新的研究趋势,并且正在成为解决无线通信系统动态资源分配问题的可行工具。该文专注于利用强化学习方法来解决这一难题。
在强化学习算法中,强化学习代理考虑最大化长期奖励,而不是简单地获得当前的最佳奖励,这对于解决动态的资源分配问题十分有效。在提升系统吞吐量方面,文献[8]研究了一种基于强化学习的媒体访问控制协议,用以学习最佳的信道访问策略。文献[9]考虑了一种多信道无线网络中网络效用最大化的动态频谱访问问题,用户能够从他们的确认字符(Acknowledge character,ACK)信号中学习频谱接入策略;文献[10]提出了基于生成对抗网络(Generative Adversarial Networks,GAN)的深度强化学习方法,用以找到一个最优的带宽共享解决方案。但是上述文献仅考虑频谱资源的分配,并没有涉及功率控制,不够完善。文献[11]研究了多智能体的强化学习方法用以解决无线网络中的功率分配问题,用户根据相邻用户的信道状态信息和QoS来调整自己的发射功率,文章虽然以功率控制为出发点,但是并没有考虑系统的能源效率问题,有些欠妥。文献[12]考虑超密集异构网络中的同层干扰和跨层干扰问题,提出了基于强化学习的资源分配方案。文献[13]结合深度学习和强化学习构建神经网络,根据环境状态动态调整信道和功率分配。但是文献[12-13]均未对信道信息有较高的要求。文献[14]研究了REINFORCE、DQL(Deep Q Learning)和DDPG(Deep Deterministic Policy Gradient)等方法在多小区功率分配上的性能表现,但是也只是从系统总容量出发,对于用户QoS要求、能源效率等方面欠考虑,同时对于信道状态信息要求较高。文献[15-16]研究了超密度蜂窝小区的资源分配问题,提出了基于模型的深度强化学习方法,但是在集中式结构下分析的资源分配问题,同样需要完整的信道状态信息;文献[17]以能源效率为目标,通过与环境的交互来学习混合能源驱动的异构网络中用户调度和资源分配的最优策略,但是算法收敛速度较慢,且不稳定。文献[18]提出了基于强化学习的方法来解决联合用户关联基站和频谱分配问题。虽然考虑到用户的QoS要求,但仅从最大化系统容量的角度出发,并没有分析系统的频谱效率。
上述基于文献资源分配主要存在以下问题:(1)全局信道状态信息难以得到;(2)维度问题:由于上述文献中通常需要全局或整个小区内的信道状态信息,导致其神经网络输入输出维度与小区数量、信道数量、用户数成正比,且状态空间随着输入输出维度呈指数增长。此外,在高维空间中的探索效率低下,因此学习可能不切实际。
综上所述,为了在有限的信道状态信息下解决异构超密度网络的下行链路中的频谱和功率联合分配问题,由于联合优化问题的非凸性和组合性,且是一个NP-hard问题,提出了一种新的基于多智能体强化学习的分布式优化算法。该算法以满足用户QoS为基本要求,提升系统的频谱利用率和能源效率为主要目标。通过强化学习算法训练神经网络,得到接近最优的联合频谱和功率分配策略。现有的工作大多将基站作为资源分配的决策者,在一定情况下增加基站的负担,且全局的信道状态信息的要求较高,该文将资源分配的决策放在用户侧,在算法收敛较快的情况下所造成的计算负担和能耗是可以接受的。
1 系统模型
考虑一个具有Mm个宏基站(MBS),Mp个微基站(PBS)以及Mf个毫微基站Mm+Mp+Mf=M和N个移动用户的异构超密度网络的下行链路,每个小区BS位于每个小区的中心,其授权移动用户随机分布在小区。每两个相邻的小区之间有重叠的区域。为了最大程度地利用无线电资源,将频率复用因子设置为1,为了避免小区内干扰,假设每个小区中的每个用户仅分配一个子信道,因此所有用户信号在同一小区中子信道是正交的。小区中使用的K个正交子信道可以在每个相邻小区中重复使用。然而,重叠区域中的用户由最近的小区BS服务,由于可能使用相同的频谱资源,他们可能遭受严重的小区间干扰(Inter Carrier Interference,ICI)。网络模型结构如图1所示。
令dm,n表示基站m∈M={1,2,…,M}与用户n∈N={1,2,…,N}之间的关联关系,dm,n=1表示基站m与用户n关联,假设用户与具有最高边际效用的基站相关联,则有以下资源分配:
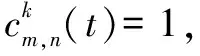
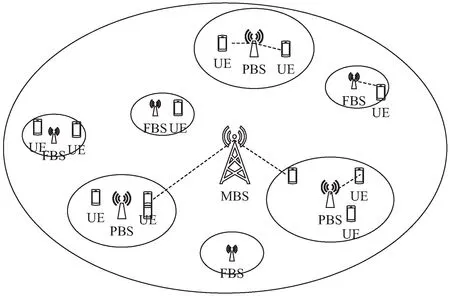
图1 网络模型结构
(1)
考虑具有平坦衰落的单个频带,采用块衰落模型来表示在时隙t中用户n到基站m的下行链路信道增益gm,n,k(t)为:
(2)

(3)
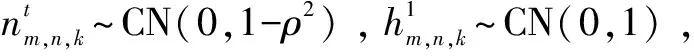
ρ=J0(2πfdTs)
(4)
其中,J0(•)是第一类零阶贝塞尔函数;fd是最大多普勒频率;Ts是相邻时刻之间的时间间隔。
不同小区中的用户分配相同的子信道,例如,基站m在子信道k上服务的用户n的ICI可以表示为:
(5)


(6)
(7)
其中,W为子信道的带宽。
定义能源效率函数EE为:
(8)
定义频谱效率函数SE为:
(9)
考虑所有用户想要满足其各自最小的QoS要求Ω,因此,假设用户n下行速率Γn(t)不小于最小QoS要求Ωn,即:
Γn(t)≥Ωn
(10)
为了联合单个用户优化频谱效率和网络能源效率,效用函数可以定义为:
(11)
参数β是为了考虑频谱效率和能源效率的折中,该文的目标是在保证用户QoS前提下,提升频谱效率和能源效率,则联合优化问题表示为:

(12)
2 基于强化学习的联合资源分配
上述异构场景下的联合资源分配问题可以表示为马尔可夫决策过程(Markov Decision Processes,MDP)。Q学习算法是解决MDP问题的最有效的算法之一。然而,异构超密度网络规模庞大,拓扑结构复杂,使得算法的计算复杂度难以控制,DRL能够很好地解决此类复杂的问题,网络实体经过不断与环境交互,通过学习可以进行自主决策,同时DNN(Deep Neural Networks)的引入能够在具有大的状态空间和动作空间的问题求解上具有显著优势。为了解决在全局信道状态信息不可知的问题,引入了多智能体的方法,每个智能体只根据自己的信道状态信息以及极小的信息传递便可做出决策。因此,提出了基于多智能体强化学习的联合资源分配框架。本节分别定义了联合资源分配的状态空间、动作空间和奖励函数,然后提出了基于多智能体的强化学习算法解决联合资源分配问题。
2.1 强化学习三要素定义
在强化学习中,智能体(代理)基于策略做出决策,选择动作对环境造成影响,得到反馈。状态空间、动作空间和奖励函数是强化学习的三要素。对于该文所考虑的异构超密度网络,将用户作为智能体,定义状态空间、动作空间和奖励函数如下:
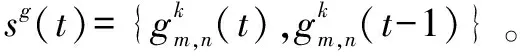

(13)
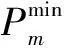

奖励:在采取行动后,代理可以计算环境的回报rn(t)。智能体的唯一目标是最大化总回报。因为an(t)的行为对奖励rn(t)有直接影响,所以发送给代理的奖励定义了对代理而言是好是坏的行为。在这种情况下,利用效用函数ηn(t)得到奖励函数rn(t),达到系统最大化频谱效率和能源效率的近似最优解。
(14)
其中,ψ为频谱效率和能源效率的折中因子,ζ为未到达QoS要求的用户数目。
2.2 多智能体联合资源分配策略
在t时刻,每个智能体通过观测状态s(t)∈S,按照既定的策略π选择相应的动作a(t)∈A,并和环境产生交互,然后得到即时奖励r(t),进入下一个状态s(t+1)。智能体的目标是学习策略π:s(t)∈S→a(t)∈A,根据其当前状态s(t)来选择下一个动作a(t+1),该策略会产生最大可能的预期累积奖励。
智能体和环境交互,以寻求最大化奖励,使用值函数来评估当前环境的状态和策略,方程式为:
(15)
其中,γ∈[0,1)是确定未来奖励权重的折现率。若折现因子为0,则只考虑当前奖励,意味着采取短视的策略,若γ∈(0,1),表示将长远的未来收益考虑到了当前行为产生的价值中。
状态值函数,用以描述遵循策略π时一个状态的值。
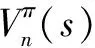
Eπ[r(t+1)+γVπ(s(t+1))|s(t)=sn]
(16)
类似的得到状态行为对的价值函数:
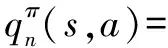
sn,a(t)=an]
(17)
对于任何MDP问题,总存在一个确定性的最优策略;同时如果知道最优行为价值函数,则表明找到了最优策略。
最优状态价值函数是所有状态价值函数中的最大值,为:
(18)
针对V*(s),一个状态的最优价值等于从该状态出发采取的所有行为产生的行为价值中最大的那个行为价值:
(19)
于是可以通过找到最优行为价值函数来寻找最佳策略π*。根据Q学习算法,通过以下公式更新Q值Qn(sn,an):
Qn(sn,an)←Qn(sn,an)+αk[r(t+1)+
(20)
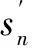
在DQN中,DNN用来表示动作和状态空间,DNN输入是当前的状态,输出是当前可执行状态的动作的Q值表的近似,具有权重θ的NN(Neural Networks)函数逼近器Qn(sn,an;θ)≈Qn(sn,an)。DQN使用目标网络和在线网络来稳定整体网络性能,目标网络是在线网络Qn(sn,an;θ)的副本,但其权重在数次迭代中固定不变。目标网络的权重每经过一定次数的迭代,更新为在线网络中的权重。损失函数定义为:
(21)




(22)
为了实现更好的策略估计,引入对决神经网络[20]获得优势函数An(sn,an)=Qn(sn,an)-Vn(sn),动作an对比其他动作的优势可用An(sn,an)表示。因此,在决斗架构中,DDQN的最后一层由Vn(sn)和An(sn,an)两个子网络组成。通过组合Vn(sn)和An(sn,an),可以估计动作价值函数Qn(sn,an)。
该文所用的强化学习模型如图2所示。每一个用户拥有一个代理,每一个代理拥有两个DQN网络,一个是在线网络,一个是目标网络。在线网络的主要作用是根据用户得到的状态信息,包括用户的当前功率分配和信道选择策略是否满足预先设置的下行速率,以及自身的信道状态信息,输出功率分配和信道分配的决策,然后用户将此策略发送给基站,请求基站根据此策略分配资源,基站根据自身可用的资源拒绝或同意用户的请求。目标网络的作用是辅助在线网络的权重参数更新。

图2 强化学习模型
算法1描述了联合优化问题的多智能体强化学习方法。在每个训练情节开始时,初始化状态信息,每个用户向其关联的基站报告其自身的当前状态(仅为sq(t)),通过消息回程通信链路在基站间传递,获得所有用户的QoS信息。然后,基站将该信息发送给所有用户。每个情节持续T步。例如,在每个情节的步骤中,用户n使用ε贪婪策略从估计的Q值Qn(sn,an)中选择执行动作。然后,每个用户将其子信道分配和功率分配请求发送到该用户已经选择与其关联的基站。该请求包含所需子信道的索引和下行发射功率。然后,基站根据其可用资源来接受或拒绝来自用户n的请求。如果基站接受用户n的请求,基站将以用户请求的功率向用户n发送反馈信号。此时用户可以根据得到的反馈计算下行链路速率,进而计算出奖励函数。反之基站拒绝用户请求,不向用户的请求做出反馈,此时用户得到奖励为负。然后,在获得立即奖励rn(sn,an)和更新下一状态之后,每个用户更新Q值。当满足所有用户的QoS或达到最大步长T时,当前情节结束。
算法1
1.初始化重现存储D,以及目标网络替换步长N-。

3.重复500个情节,每一个情节重复500步,对于每一步进行以下操作:

(b)所有的UE更新环境s(t+1),得到奖励r(t+1)。
(d)所有的UE从各自的记忆回放单元D中随机抽取样本,计算损失函数Ln(θ),并更新权重。
4.每隔N-步,所有的UE将各自的目标网络参数θ-替换为在线网络权重θ。
5.当所有的UE满足QoS条件,或者达到最大迭代步骤,结束当前情节。
3 仿真分析
在这一节中,给出了所提多智能体强化学习资源分配算法在异构超密度网络中的下行链路中的性能表现,并给出了该算法与其他RL算法[13]以及贪婪算法的对比。采用tensorflow平台实验仿真,仿真设置宏基站的数量为2,微基站的数量为8,毫微基站的数量为12,以及用户数N∈{20,25,30,35,40},且用户随机分布在各个小区的范围内。宏基站和微基站的覆盖半径分别500 m、100 m,最大传输功率分别为38 dbm、30 dbm,二者的路径损耗模型均为34+40*log10(d),毫微基站的覆盖半径为30 m,最大传输功率为20 dbm,其路径损耗模型为37+30*log10(d)。信道带宽为180 kHz,噪声功率密度N0为-174 dBm/Hz。重现存储D的大小为500,抽样批次的长度为32,学习率参数为0.000 05。网络布置如图3所示。
图4给出了该算法在不同学习率收敛的回合数训练效率的表现,在学习过程开始时,训练步骤都非常大,这是因为经过初始化,代理没有之前学习的经历,很难找到令所有用户满足QoS要求的策略,需要经过很长的迭代步骤才能收敛,甚至达到预设的最大回合数都不能收敛。但随着情节数目的增加,代理经过学习,收敛速度加快,对比不同的学习率,当学习率为0.000 05时,在40回合后,不到10步就能够收敛,而学习率为0.001时,收敛较慢。这是因为学习率对于网络来说太大了,只有合适的学习率才能使收敛更快。
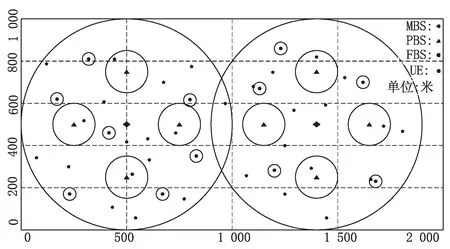
图3 网络布置
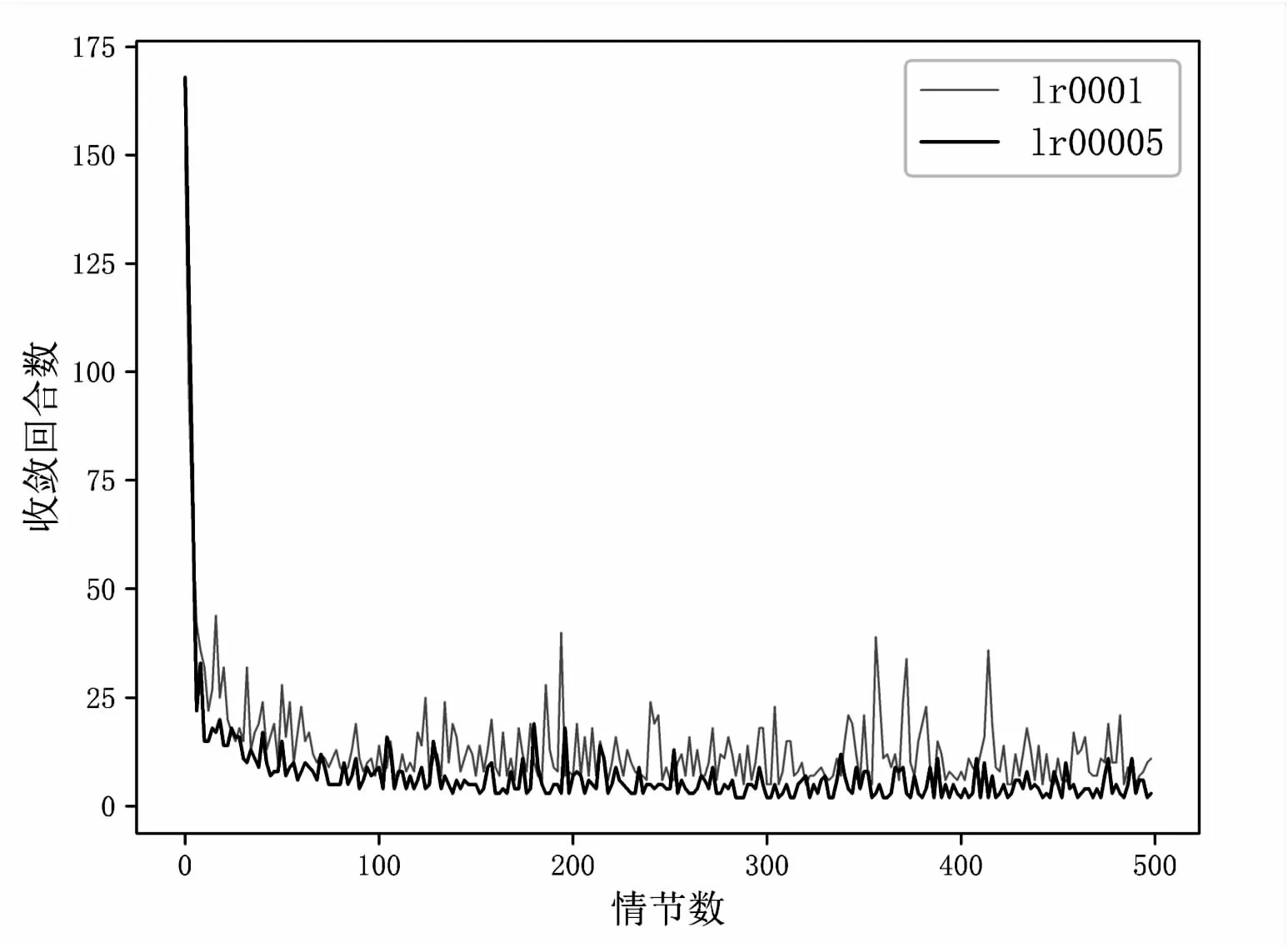
图4 训练步骤与回合数曲线
图5给出了不同算法在不同功率分配等级条件下系统能源效率的表现。相较于贪婪算法和文献[13]中算法,该文得到的能源效率分别提升了26.43%~43.47%和22.68%~33.25%。随着功率分级数量的提升,在一定区间内会提升能源效率,但过高的分级数量会增加计算复杂度,且提升的能量效率有限。
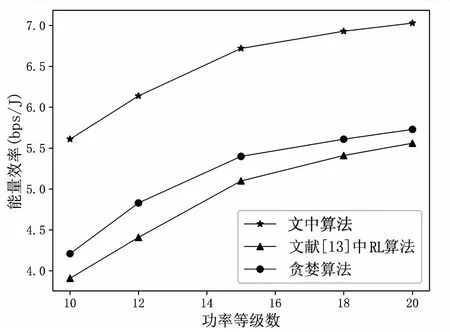
图5 能源效率与功率分配等级关系曲线
图6给出了三种不同算法在不同子信道数的条件下系统频谱效率的表现,随着子信道数量的增加,三种算法的频谱利用率均有下降。这是因为随着子信道数量的增加,在相同的用户数量下,信道的复用效率降低。对比文献[13]中的算法和贪婪算法,该算法的频谱利用率均有所提升。

图6 频谱效率与信道数量关系曲线
在图7中,比较了三种算法在不同用户数量条件下系统吞吐量的变化。可以看出随着用户数量的增加,系统总的吞吐量增大,但是增长的趋势有所减缓,在用户数与信道数相等时,多个用户共用同一条信道的情况较少,干扰较小,这时所提方案平均每个用户的下行速率最大值位于初始点,达到2 Mpbs/s,此时系统总容量为40.21 Mbps/s,随着用户数量增加,干扰增大,平均每个用户的下行速率减少。相比文献[13]中的算法和贪婪算法,文中算法系统速率提升最大达到14.11%和25.65%。

图7 系统容量与用户数量关系曲线
4 结束语
在异构超密度网络,为了满足用户最小QoS要求,提升系统频谱利用率以及能源效率,提出了基于多智能体强化学习框架的分布式资源管理算法。将能源效率和频谱效率作为奖惩值,并通过有限的消息传递得到状态信息,再根据状态信息分配频谱和功率策略,然后反复训练更新神经网络,使得到的策略趋向于最优策略。仿真结果表明,该算法可以满足用户需求,提升网络能效,有效解决复杂动态网络下的资源分配问题。
猜你喜欢
小学教学研究(2022年5期)2022-04-28
空间科学学报(2021年6期)2021-03-09
英语文摘(2020年10期)2020-11-26
计算机系统应用(2018年7期)2018-07-18
智富时代(2018年3期)2018-06-11
智富时代(2018年3期)2018-06-11
计算机应用(2016年10期)2017-05-12
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
人民音乐(2016年3期)2016-11-07
