
实时以太网总线控制器设计
2023-02-06 14:07陈凌宇杨立志赵东林朱文亮
光学精密工程 2023年1期
陈凌宇, 杨立志, 赵东林, 朱文亮
(1.国防科技大学 智能科学学院,湖南 长沙 410073;2.华中科技大学 机械科学与工程学院,湖北 武汉 430074)
1 引 言
现场总线作为可编程控制系统的“神经”,是实现系统主从站及末端设备数据信息传递的重要介质。在数控机床、机器人、医疗设备等对控制系统性能要求较高的领域中,现场总线的数据传输实时性和同步性是保证系统控制速度和精度的关键[1-2]。以太网总线是现场总线的一种,凭借其数据传输率高、数据吞吐量大等优势成为工业现场总线的发展趋势[3-4]。目前,国内大多数可编程控制系统采用EtherCAT,POWERLINK,PROFINET等国外实时以太网总线,对工业控制系统的信息安全造成了较大的隐患。因此,设计和开发具有高精度同步性能的自主可控实时以太网现场总线成为我国制造业发展的迫切需求。
以IEEE802.3有线以太网物理层和链路层标准为基础,设计并集成符合工业自动化控制过程中数据传输特点的链路层协议(以下简称协议),是实现以太网总线通信的有效方法。以EtherCAT,PROFINET IRT,SERCOS 等为代表的实时以太网总线,通过对以太网数据链路层的MAC子层数据传输方法的定义,实现了数据传输的实时性[5-6]。国内实时以太网总线多采用FPGA+PHY的硬件结构,将协议以IP核的形式集成在FPGA中实现链路数据的传输控制。如NCUC-bus (GB/T29001)实时以太网总线[7]。链路层数据传输方法是协议的重要内容,大量研究对系统周期数据[8]、非周期数据[9]的实时传输调度问题进行优化,以提高通信效率。此外,在协议中集成以太网时钟同步策略是保证系统进行高速协同控制的关键。多数研究基于IEEE1588精确时钟同步协议,主要思想是通过时间戳计算传播延时和时间偏移[10-11]。PARK等提出了一种通过估计总线上每个节点时间漂移的大小和符号并进行补偿的方式,显著降低了EtherCAT总线的同步误差[12]。CHOI等提出了一种分布式异步时钟同步协议,利用网络中各节点的相对时间信息对时间误差进行补偿,提高了时间收敛速度[13]。EXEL等针对分布式时钟中线路传输不对称的问题,提出了基于线交换和高精度时间戳的方法,可将时钟偏移减小到120 ps[14],但是这种方法较为复杂且需要硬件支持。
本文以NCUC线型级联网络拓扑架构为基础,对NCUC总线的系统构成及原理进行了全面的分析。在此基础上,对工业控制系统时间敏感与非敏感数据传输机制进行分析与设计,形成了各类数据的通道传输机制,并提出了一种通道映射方法,提升了数据传输效率。针对系统时钟同步问题,分析了以太网总线通信延时的原因。通过建立时钟补偿模型,采用时间戳的方式对总线各节点时钟进行测量和补偿,形成了基于分布式时钟的以太网总线同步方法。最后,以国产FPGA为平台构建实验平台,对总线通信性能进行了测试,验证了所提出的实时以太网控制器的实时性与同步性。
2 系统构成及原理
2.1 NCUC网络拓扑结构
在总线式可编程控制系统中,主站与各功能从站通过现场总线相连以实现主从设备之间的数据交换。由于线型总线的同步性能优于其他以太网总线,集成NCUC协议的控制器芯片(以下简称NCUC控制器)采用线型级联的方式嵌入各从站控制器中。通过对以太网物理层数据流的读写控制和链路层数据处理,实现了在线型级联网络拓扑结构下主站与各从站的高速、同步通信功能[15]。拓扑结构如图1所示,主站通过以太网接口将网络数据发送至从站1的端口1,NCUC控制器对数据进行处理后由端口2发出;从站2的端口1接收到从站1发出的数据后,通过端口2发送至下一从站;直到最后一个从站N接收到数据后,直接通过端口2返回至主站。
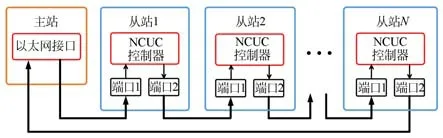
图1 NCUC线型级联网络拓扑架构原理Fig.1 Schematic diagram of NCUC linear cascade network topology
2.2 NCUC控制器硬件结构
在可编程控制系统中,主站多采用高性能工业计算机。通过改造网口协议,可灵活地管理整个实时通信网络。而从站需要将NCUC控制器集成在嵌入式电路板中,通过搭建以太网相关的物理层、链路层相关电路来实现网络通信。
从站的硬件结构原理如图2所示。网络数据传输以工业以太网5类双绞线为介质,通过从站M12工业连接器1进入从站。网络变压器采用普斯电子的HX_1188_NL,用于实现信号隔离,保护内部电路安全。隔离后的网络信号采用微芯公司百兆以太网收发器LAN8710Ai进行收发处理,与NCUC控制器通过MII(Medium Independent Interface)接口相连。NCUC控制器采用国产京微齐力公司的HME-P1P060N0TF784C(以下简称P1)大容量FPGA,对PHY接收数据进行协议栈处理。信息处理结束后,NCUC控制器将待发送数据通过PHY收发器2、隔离变压器2、M12工业连接器2发送至以太网总线。此外,从站应用MCU为京微齐力SoC芯片HMEM7A12N0F484I7(以下简称M7)。其中,集成了不同的应用层功能,主要实现数字量IO、模拟量IO、伺服控制和通信转换等。NCUC控制器与应用MCU之间通过片上高速PDI接口实现数据传输。

图2 从站硬件结构原理Fig.2 Schematic diagram of slave hardware
2.3 NCUC控制器功能结构
NCUC控制器中集成链路层数据通信传输、协议解析、网络冗余和时钟同步等功能,是实现总线传输协议的核心器件。此外,NCUC控制器还提供片间PDI异步通信接口,便于实现应用层功能的MCU访问。图3显示了集成NCUC控制器的内部功能结构。
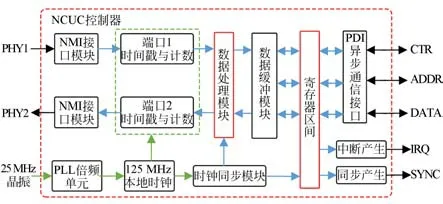
图3 NCUC控制器功能结构原理Fig.3 Schematic diagram of functional structure of NCUC controller
NCUC控制器中,两个独立的NMI接口模块对物理层PHY收发器进行读写操作。NMI接口模块分别与两个具有时间戳与计数功能的端口相连,各端口在网络数据读写时,将时间戳信息写入网络帧,这对同步控制算法的实现起到了重要的作用。接收到的网络帧信息根据帧类型的不同,由数据处理模块进行透传、读取数据、写入数据和协议栈等操作。NCUC协议相关的配置以及收发数据存放在寄存器区间内。为提高数据处理速度,在数据处理模块和寄存器区间设置数据缓冲模块。设计并行异步通信接口,以满足外部MCU控制器对内部寄存器中NCUC配置区、接收数据区和发送数据区的操作。在NCUC控制器接收到有效的通信数据后,中断产生模块将立刻产生IRQ跳沿信号,表明通信数据接收成功。同步产生模块则会根据各从站同步时间补偿的不同进行延时,当所有从站都接收到数据后同步产生SYNC跳沿。MCU可根据SYNC信号进行精准的同步控制。
在NCUC控制器中,寄存器是实现NCUC通信管理、同步设置及数据交换的重要模块。主站通过网络对从站寄存器进行操作,从站则通过PDI数据接口对寄存器进行访问。所以,寄存器是连接主站与从站的数据存储桥梁。寄存器模块由64 kB空间的双口RAM构成,其中2 kB为管理空间,用于通信和同步相关配置、管理和监控;另外62 kB为数据空间,用于存放接收的网络数据和需要发送的数据。寄存器的空间结构如表1所示。
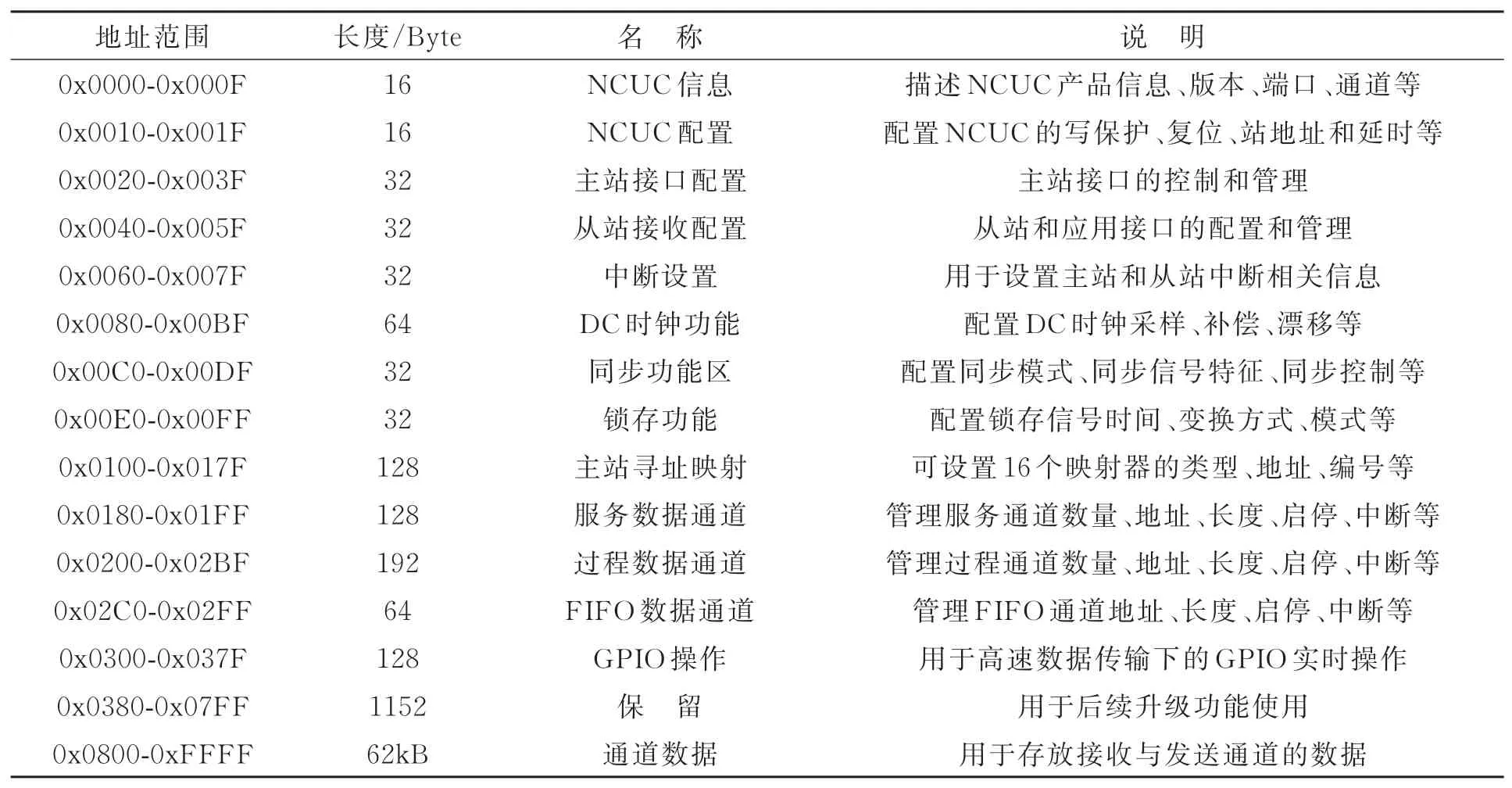
表1 NCUC控制器内部寄存器存储空间说明Tab.1 Description of internal memory storage space of NCUC controller
3 网络数据传输
3.1 帧结构定义
实时以太网数据以标准IEEE802.3以太网帧为传输载体,通过对标准以太网帧结构的重定义形成了一种高效传输的帧结构。NCUC网络帧结构如图4所示。保留长度为14字节的IEEE802.3标准以太网帧头中目标的MAC地址和源MAC地址信息,将2字节的帧类型写入固定值0x8888,该帧为NCUC网络帧。将标准以太网帧46-1500字节的数据区分为2字节的NCUC帧头区和44-1498字节的数据区。其中,NCUC帧头由索引值、版本号、循环圈数和循环标志位构成。此外,NCUC数据区可根据定义分为若干个报文区间,每个NCUC报文对应总线上某个从站的下发数据或是上传数据。报文数据区间可根据传输数据大小自由定义数据长度。如果NCUC帧头与报文总长度小于46字节,则需要在报文之后补0~46字节。最后,将标准以太网帧4字节的FCS校验作为帧尾。
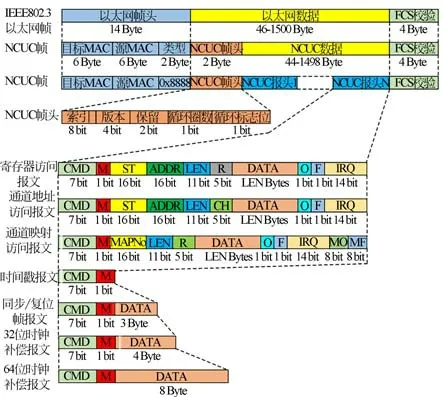
图4 NCUC网络帧结构定义Fig.4 Definition of NCUC network frame structure
网络帧提供了寄存器访问、通道地址访问、通道映射、产生时间戳、同步/复位帧、32位时钟补偿,以及64位时钟补偿7种类型的报文。主站可通过网络帧的功能灵活地将所需的报文组帧,形成不同功能的网络帧。各报文功能如下:
(1)寄存器访问报文:用于读写寄存器单元。
(2)通道地址访问报文:按通道地址的方式读写数据传输通道。
(3)通道映射访问报文:采用通道映射的方式对所映射的通道进行读写。
(4)产生时间戳报文:使各从站NCUC控制器产生收发帧的时间戳。
(5)同步/复位帧报文:用于启动或复位同步帧命令。
(6)32位时钟补偿报文:进行精度为32位的分布式时钟补偿。
(7)64位时钟补偿报文:进行精度为64位的分布式时钟补偿。
3.2 通道数据传输机制
数据通道是网络数据传输的重要方式,通过对传输数据结构、类型和长度等条件的设置,可实现通信数据块的高速传输。在实际应用中,通信数据根据其用途可分为多种,这些数据对通信传输的要求也存在差异[9]。针对可编程控制系统的数据传输需求,在NCUC实时以太网控制器中设计服务数据、过程数据和FIFO数据通道。
服务数据通道主要用于传输协议或非实时数据。协议数据除了所传输的数据内容外,还集成了握手、应答等协议内容。在数据传输过程中,对主从站数据问答的有效性提出很高的要求,但对时间并不敏感。通过操作寄存器中服务数据通道区(0x0180-0x01FF),可在寄存器62 kB的通道数据区中开辟一个RAM块,作为服务数据通道。为保证服务通道中协议数据传输的可靠性,设计如图5所示的状态转移模型。在处于状态0时,通道中无可读的最新数据,产生写中断信号等待数据写入。主站/从站根据写中断信号发送协议数据,向通道中写入第一字节数据后,通道状态切换至状态1,表示主站/从站正在写入。此时,写中断标志位复位,不再接收其他写操作。当主站/从站协议数据依次写入通道后,通道状态跳转至状态2并产生读中断信号,表示此时数据已经完全写入,从站/主站可以进行数据读取。从站/主站读取第一字节后,通道状切换至状态3并清除读中断标志,不再允许其他读操作读取通道数据。从站/主站逐字节读完通道中所有数据后,通道跳转至状态0,产生写中断信号并等待下一次写入。这种依次读写的通道操作模式,虽然占用了通道数据传输的时间资源,但可保证协议数据在主从站之间有效、可靠的传递。

图5 服务数据通道状态转移模型Fig. 5 Service data channel state transition model
过程数据通道主要用于实时数据传输。实时数据是自动控制过程中产生的指令及反馈信息,这些数据会随时间周期不断的更新。通信数据使用方主要关心的是数据实时性。因此,数据的周期性更新是保证实时性的重点。通过配置寄存器的过程数据通道区(0x0200-0x02BF),可在通道数据区中开辟相同的3个连续的RAM块,作为过程数据通道。过程数据通道状态转移模型如图6所示。通道的写操作和读操作分别针对待写区和读出区进行,中间的缓存区用于缓存数据。这种读写区域分离的方式,使通道永远处于写入状态,保证了周期性数据写入的有效性。待写区数据写入完成后,产生读中断信号。此时,读出区由缓存区数据填充,保证读出的数据为最新写入的数据。如果上次数据尚未读出完成就写入了新的数据,则会导致上次数据被本次数据覆盖。这种读写区域分离的过程通道操作模式,能够保证实时数据的高效传输,但需要对读写操作时序进行一定的约束。
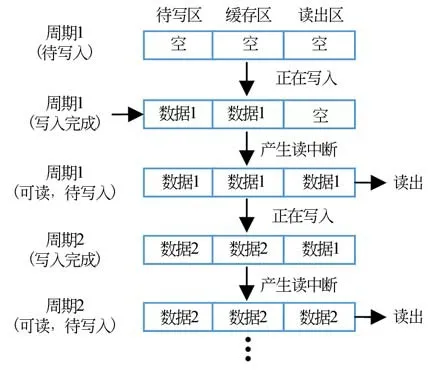
图6 过程数据通道状态转移模型Fig.6 Transition model of process data channel state
制造装备智能化对图像、视频等大容量数据的实时传输提出了要求。由于数据容量极大,一般的总线数据传输通道可能无法进行完整存储。设计FIFO数据通道,允许设备同时对其进行读写,极大地节省了数据的缓存空间。配置寄存器FIFO数据通道区(0x02C0-0x02FF),可在通道数据区中开辟1个尽可能长的RAM块(大于1 kB),作为FIFO通道。其状态转移模型如图7所示。状态0表示当前通道为空状态,仅允许数据写入。只要通道被写入数据,则通道状态跳转到状态1并置位读中断,表示通道为非空非满状态,可读可写。在状态1时,如果通道数据被读空则通道状态回到状态0并复位读中断;若通道被写满,则跳转至状态2并复位写中断,表示通道已满不可写入。此时,只要存在数据读出,则置位写中断并跳转至状态1,可读可写。
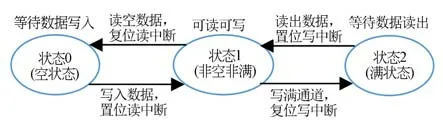
图7 FIFO通道状态转移模型Fig.7 Transition model of FIFO channel state
3.3 通道映射
通道机制有效地保证了实际系统中各类型数据传输的可靠性,同时,也降低了通信时有效数据的传输效率。在总线系统中,主站与从站都存在数据通信需求,这表明每个从站至少需要开辟1个通道进行数据读取或数据发送。而每开辟1个通道,主站需要增加一个报文,从而增加了报头和应答这类无效数据,如图4所示。无效数据加重了网络传输的数据量,降低了有效数据的传输效率。
本文采用通道映射的方式,将同类型的报文进行合并,共用一个报头和一个应答中断。主站将各从站的通道数据在整个报文中的映射信息,如映射编号、起始地址、通道号、数据长度、通道内起始地址等信息保存。每个从站则将自身相关的映射信息保存在NCUC控制器中。如此,主从站可以根据已有的映射信息,读写合并报文的网络帧数据。

图8 通道映射工作原理Fig.8 Working principle of channel mapping
图8显示了通道映射的工作原理。在一主多从的总线式系统中,每一网络帧需要装载主站对各个从站的发送数据以及各个从站返回至主站的状态信息。将主站下发到N个从站的N个报文合并为一个读映射报文,从站所有上传报文合并为一个写映射报文,读写映射报文按图4中通道映射报文结构进行组合。在收发网络数据帧时,通过映射编号、映射启停控制、读写控制、报文内起始地址、通道号、数据长度、通道内起始地址,使映射过程有效。具体操作过程如下:
(1)从站根据映射编号在网络帧中寻找符合此编号的报文,在映射器启动的情况下进行读写控制判断。若读写操作为读,则从网络帧中读取数据至通道;若为写,则需要将对应通道的内容写入报文相应位置。
(2)在读写控制为读时,从站根据报文内起始地址、数据长度参数找到报文中具体的待读数据区域,读出后顺序写入相应通道号中以通道内起始地址开始的区域。
(3)在读写控制为写时,从站根据通道号、通道内起始地址、数据长度参数将对应通道中的数据取出,并写入与映射编号、报文内起始地址相应的报文区域。
通道映射的方式,可在多类数据同时传输时极大地提高通信效率。假设系统中有N个从站,每个从站读通道和写通道数据长度为R_len和S_len字节。根据NCUC以太网帧结构,采用通道地址访问时通信效率ηc为:

由式(1)和式(2)可知,无论从站个数多少,ηm始终大于ηc,且从站数量越多,则通道映射机制的通信效率越高。例如,采用CANopen应用层协议,每个从站开辟4组PDO,其读写通道数据长度各为40字节。当网络帧数据长度达到规定极限时,通道地址访问通信效率为67.7%,而映射通信效率为96.2%。
4 以太网时钟同步
4.1 通信传输延迟分析
在线型级联的网络拓扑结构中,主站发送的通信数据帧需要依次经过各从站,导致各从站接收同一通信数据帧存在延时[10]。图9显示了两个相邻的从站通信延时原理。数据帧传输到达从站A的端口0接收端P0_RX,NCUC控制器对数据帧进行读取并由端口1发送端P1_TX发出。由于通信线缆长度对通信数据传输的延时,经过线间延时后从站B的P0_RX接收到数据帧。因此,从站A与从站B的端口0接收到数据帧的时间延时为delayLAB。其中,包括从站A开始处理P0_RX数据到P1_TX发送时间delayCA01,以及从站AB之间通信线缆的线间传输延时delay-LAB。另外,数据帧由系统最后一个从站返回后由从站B的P1_RX接收,经过从站B的站内处理延时delayCB10和线间传输延时delayLBA后至从站A的P1_RX接口。
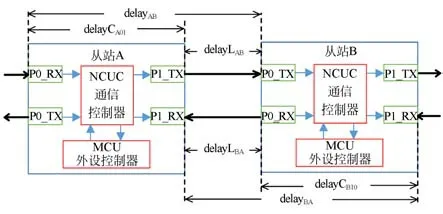
图9 相邻的两个从站间通信延时示意图Fig. 9 Schematic diagram of communication delay between two adjacent slave stations
以上分析表明,通信延时原因包括数据帧在通信介质中的传输时间造成的线间传输延时,以及各从站对数据帧的处理转发造成的站内处理延时。
4.2 通信延迟补偿
准确的测量线间传输延时和站内处理延时时间并进行补偿是实现从站同步的基本思想。但在总线式系统中,由于各从站上电时间、时钟源都存在偏差,无法直接地测量通信延时[16]。这里以主站相连的第一地从站为参考从站,测量各从站与参考从站的通信时间延时,作为各从站延时的补偿值。具体测量形式是通过在数据帧中加入时间戳报文的方式,记录数据帧在各从站端口接收与发送的本地时间,以及数据帧在从站内部处理时间,对通信延时进行测量。
建立线型级联网络传输延时模型如图10所示。时间戳报文在抵达从站后以该从站本地时钟为基准,记录抵达接收端口的时间和离开发送端口的时间,为通信延时测量提供重要依据。因此,定义变量tNR0,tNR1分别为包含时间戳报文的通信帧抵达从站N接收端口0和端口1的时间,tNT1,tNT0分别为通信帧离开端口T1和T0的时间。通信帧在从站N内正向传输的站内处理延时为D_CNP,反向站内延时为D_CNR。通信帧由从站A端口发出,到从站B端口接收的线间传输延时为D_LAB。通过模型分析,分别对各从站时钟的线间传输延时和站内处理延时进行计算和补偿。
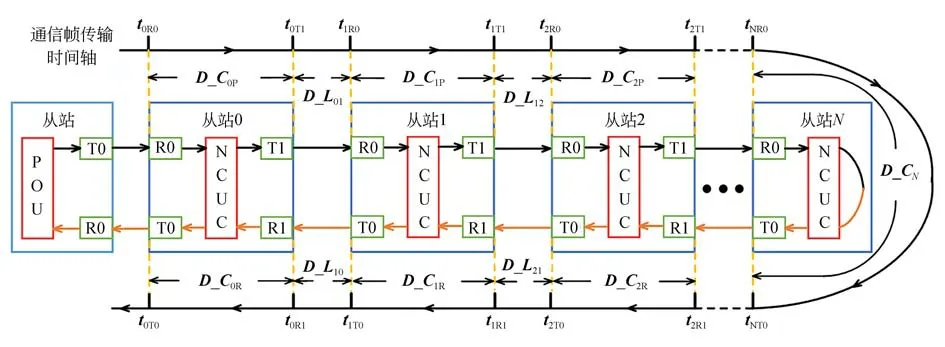
图10 线型级联网络的传输延时模型Fig.10 Transmission delay model of linear concatenated network
4.2.1 线间传输延时计算
从站之间通信双绞线的长度和环境条件一致,因此可假设通信线缆上往返传输延时相等。则对于相邻的从站0和从站1,有如下关系:
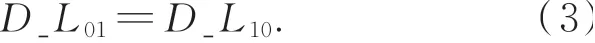
由于时间戳报文在各从站之间记录的时间参考时钟不同,假设从站1与从站0的时间偏差为offset10,则从站0和从站1的线间传输延时可表示为:
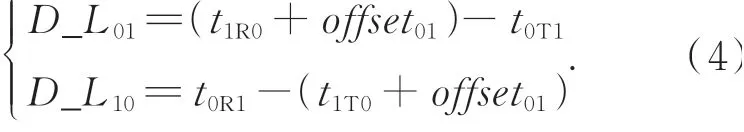
将式(3)代入式(4),则可得到从站0与从站1的线间传输延时为:
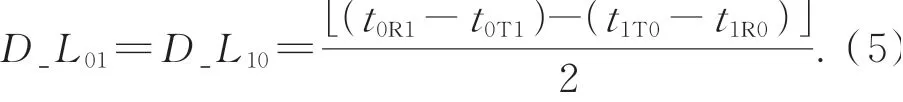
一般地,对于一个有N+1个从站的系统,从站i到参考从站(从站0)的线间延时可以通过计算从站0到从站i的所有线间传输延时总和,即:
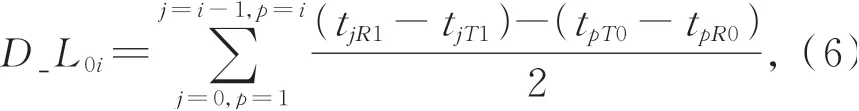
其中:i为大于或等于1的正整数,j=i-1。
4.2.2 站内处理延时计算
当通信帧抵达从站时,接收端PHY的读信号有效时,NCUC控制器以本地时钟开始计数,直到发送端PHY的写信号有效为止。根据通信帧延时处理模型,任意从站i的站内处理延时可计算为:

一般来说,通信帧由从站N返回至主站的过程,各从站采用转发的处理方式并不进行有效的数据处理,故进行补偿时仅考虑D_CiP。在一个有N+1个从站的系统中,从站i到参考从站的所有站内延时D_C0i为:
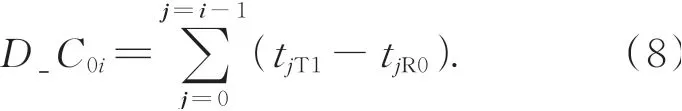
根据式(6)、式(8)的计算结果,容易得到从站i与参考从站的通信延时。主站则可以通过寄存器访问报文将各从站的线间传输延时和站内处理延时写入各从站寄存器中,用于补偿通信帧延时。
4.3 分布式时钟同步
前文以参考从站时钟为基准,采用时间戳报文对各从站通信延时进行了测量和补偿。但是,这种基于各从站本地时钟的测量结果会因各从站时钟源的偏差导致误差。要达到各从站的高精度同步,必须对各从站时钟进行同步处理。
由于各从站上电时间和时钟源的差异,各从站的实际时间变化如图11所示[12]。在任意时间t0时刻,本地时钟和参考时钟的差异为Coffset。显然,Coffset是随时间变化的函数,本文所提出的分布式时钟同步方法则是以较短的周期实时测量Coffset,并对本地时钟进行补偿,使所有从站的时钟向参考时钟看齐。

图11 时钟模型Fig.11 Clock model
将图11中的时钟模型分为若干个相等的Δt区间,如果区间足够小,则可将时钟模型的本地时钟与参考时钟变换曲线近似为直线。根据直线的函数表达式可知,造成两条直线差异的影响因素为变化率和偏移值,在时钟模型中分别成为时钟漂移和时钟偏移。因此,建立图12所示的时钟补偿模型,周期性地对本地时钟进行漂移补偿和偏移补偿,使本地时钟与参考时钟曲线重合,从而达到时钟同步的目的。
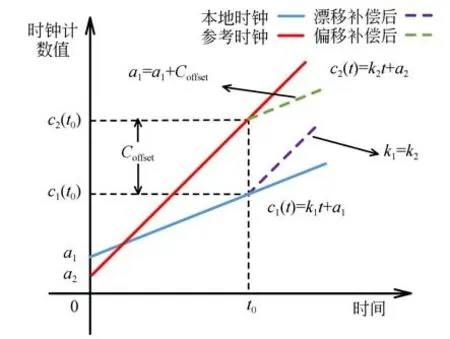
图12 时钟补偿模型Fig.12 Clock compensation model
4.3.1 时钟偏移补偿
根据式(4),从站1与从站0的时钟时间偏差Coffset10可以通过时间戳的方式进行测量得到:
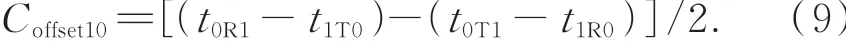
将式(9)扩展到任意相邻的两个从站,即从站i和从站j的时间偏差Coffsetij为:
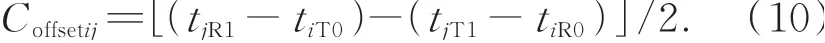
由于从站0为参考从站,则从站1的本地时钟与参考时钟的偏差为Coffset10。一般地,在N+1个从站系统中,从站i的本地时钟与参考时钟偏差可表示如下:

4.3.2 时钟漂移补偿
在线型级联网络中,本地时钟与参考时钟的变化率无法直接测量,但通过二者的时钟偏移值Coffset的变化率可以间接地补偿时钟漂移[10]。
假设在图12的时钟补偿模型中,本地时钟c1(t)和参考时钟c2(t)的表达式如下:
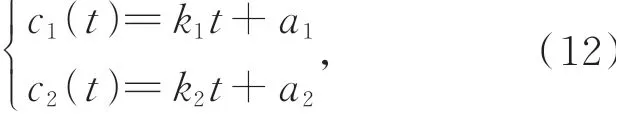
其中:k1和k2分别为本地时钟和参考时钟曲线的变化率,a1和a2分别为两时钟曲线在t=0时刻的初值。
根据时钟偏移值定义容易得到:
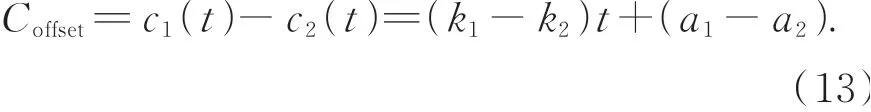
对式(13)求导,得到的时钟偏移值变化率Roffset是本地时钟曲线和参考时钟曲线变化率的差值,如下:

设置漂移补偿因子fd。当Roffset>0时,表明本地时钟相比参考时钟向正向漂移,需要将k1减小fd;反之,则表明本地时钟相比参考时钟向负向漂移,将k1增加fd。具体补偿方法如下:
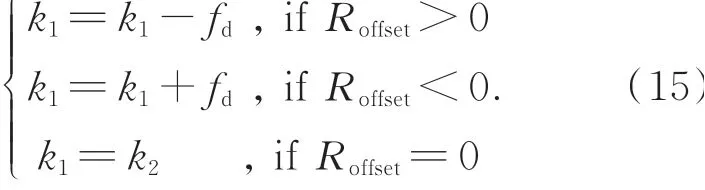
在正常的网络通信过程中,各从站接收到通信帧后利用式(11)、式(15)对各自本地时钟进行偏移和漂移补偿,使各从站时钟与参考从站时钟一致。然后,利用式(6)、式(8)对通信传输过程中的线间延时和站内延时进行补偿,实现基于分布式时钟的以太网通信同步。
5 实 验
本节搭建总线式控制系统,通过几组实验对实时以太网总线的通信性能进行测试。
5.1 系统构建
构建典型的总线式控制系统如图13所示。为保证系统处理能力,主站采用ATOM处理器,利用通用的以太网接口将3个数字量IO从站相连,形成典型的工业现场末端设备的控制网络。在集成开发环境中编写符合IEC61131-3的逻辑代码,编译后通过标准以太网接口下载到主站中,作为主站逻辑控制的程序组织单元(POU)。主站采用Modbus协议与组态设备相连,通过组态监控终端实现控制系统的人机交互。此外,从站采用P1+M7的硬件结构,P1中集成NCUC控制器IP核实现网络数据收发,M7中集成CANopen设备控制及操作子协议,并通过P1的异步数据接口实现控制指令接收与设备状态发送。
5.2 通信性能测试
采用图13所示的总线式控制系统,在自研的软件集成开发环境FX_PLC Developer中编写IEC61131-3逻辑代码并下载到主站,对NCUC总线上各从站数字量输出接口进行操作。

图13 典型的总线式控制系统架构Fig.13 Typical fieldbus control system architecture
5.2.1 通信数据传输实时性测试
考虑到百兆以太网链路的传输极限以及CANopen应用层协议的数据传输机制对通信周期的约束。分别设置主站通信周期为1 000,500,250 μs,并按通信周期向各从站发送数字量输出口电平翻转指令。通过示波器观察各从站数字量输出口电平的变化。在图14中,各从站电平翻转呈现周期性,且与主站通信周期一致。测试结果表明,以CANopen作为系统应用层协议时,NCUC总线对系统的最小控制周期可达250 μs。
5.2.2 总线同步精度测试
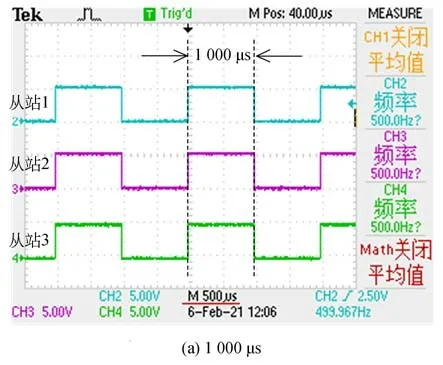
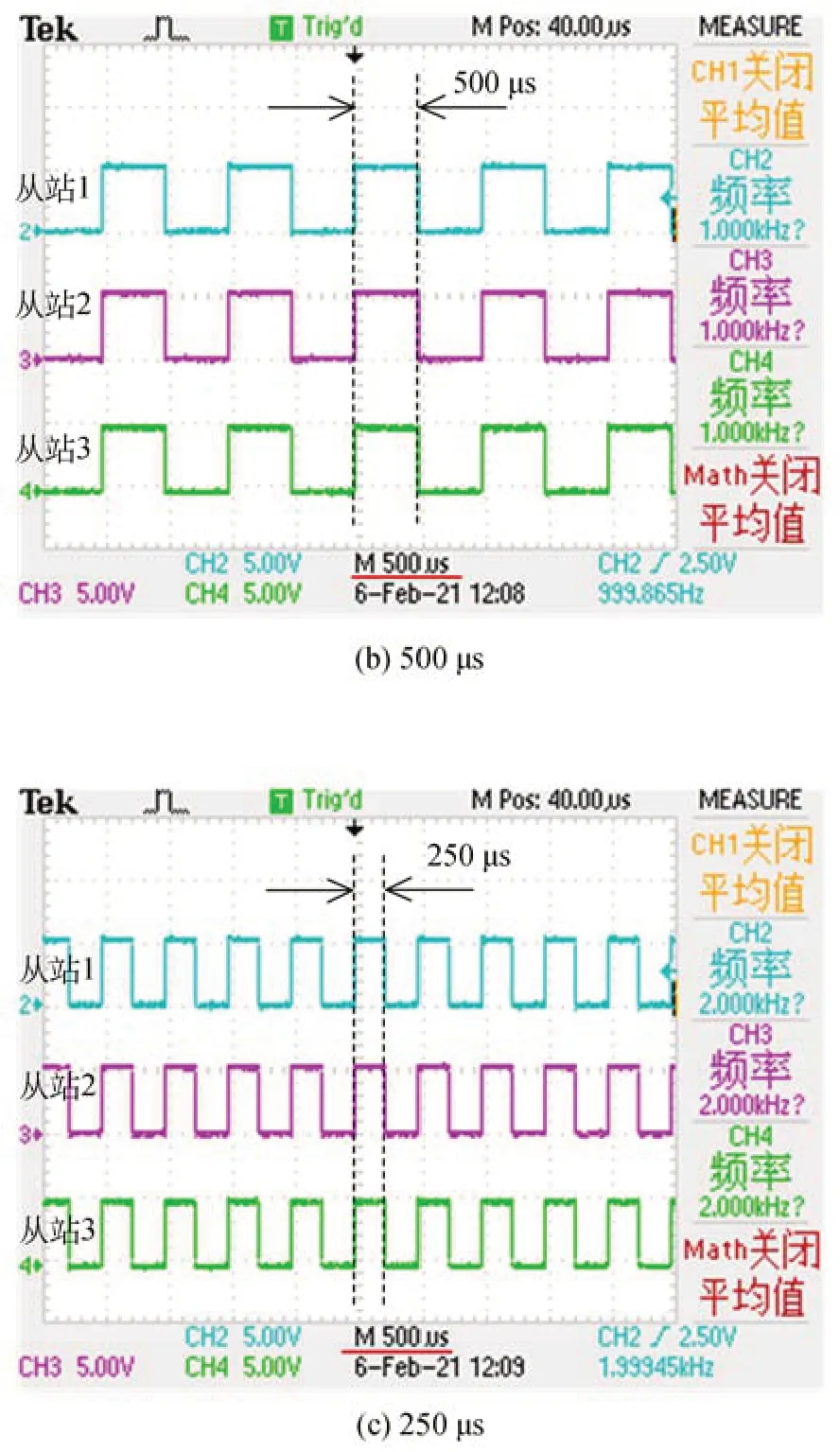
图14 NCUC以太网总线通信周期测试结果Fig.14 Test results of NCUC ethernet bus communication cycle
NCUC控制器SYNC信号是通过时钟同步补偿后的基准信号,各从站SYNC信号的时间误差反映了NCUC控制器同步性能的优劣。将系统各从站SYNC信号引入示波器,在系统正常建立通信后观察SYNC信号的变化。图15中,从站2和从站3与参考从站的SYNC信号分别相差27,32 ns。这表明在三从站系统中,NCUC实时以太网同步时间误差在50 ns量级。
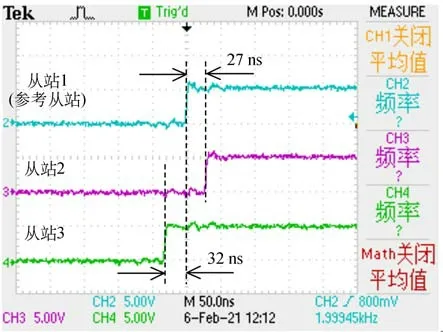
图15 NCUC以太网总线同步精度测试结果Fig.15 Test result of NCUC ethernet bus synchronization accuracy
6 结 论
本文针对可编程控制系统中高性能现场总线的自主可控问题,以NCUC实时以太网总线为基础,利用国产大容量FPGA芯片为平台搭建了FPGA+PHY的通用以太网硬件架构,针对网络数据传输特点设计了以太网控制器的内部功能结构。为了提高网络数据的传输效率,对网络帧结构及通道数据传输方法进行了研究,提出了一种通道映射的方法,使多节点系统中网络数据的传输效率得到极大提升。通过分析实时以太网的传输原理,总结了各从站节点通信帧传输不同步的原因。建立了线型级联网络数据帧传输延迟模型,提出了各从站通信延时补偿方法。此外,采用分布式时钟同步的方法,对各从站本地时钟相对参考时钟的漂移和偏移进行了补偿,使系统各从站时钟达到同步。最后,通过实验对总线通信速率和同步精度进行测试。结果表明,本文设计的实时以太网总线的最小通信周期为250 μs,同步精度小于50 ns,达到国际先进水平。
猜你喜欢
汽车电器(2022年9期)2022-11-07
装备制造技术(2020年1期)2020-12-25
自动化仪表(2020年10期)2020-11-13
铁道通信信号(2020年4期)2020-09-21
中国外汇(2019年11期)2019-08-27
电子制作(2019年14期)2019-08-20
电子制作(2017年24期)2017-02-02
铁道通信信号(2016年8期)2016-06-01
船舶力学(2015年6期)2015-12-12
中国交通信息化(2015年11期)2015-06-06
