
基于UIE的情感可解释分析
2023-02-04 05:46刘苏文李军辉郭立帆曾海峰
中文信息学报 2023年11期
朱 杰, 刘苏文, 李军辉,郭立帆, 曾海峰, 陈 风
(1. 阿里巴巴集团,浙江 杭州 311100;2. 苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
互联网的迅速发展和社交平台的进一步扩张,为人们提供了可以快速便捷发表和分享个人言论的广阔平台,越来越多的人喜欢在网络平台上对事物发表评价和意见,这些观点对于无法接触到真实事物的潜在用户具有很高的参考价值,他们可以通过这些具有主观色彩的评论来了解舆论对于某一事物或者产品的看法。因此,挖掘这些评价中包含的情感倾向具有广泛的实际应用价值。
文本情感分析任务旨在判断一句话或者一段较长篇幅文本的情感倾向,如对商品评论[1]、电影影评[2]、店面点评等。目前情感分析的主流模型为循环神经网络[3]和预训练模型[4]等。但深度学习模型所采用的神经网络往往都被当作“黑盒”使用,其内部决策机制对用户是不透明的。即模型只给出最终的决策结果,并没有对模型的结果给出可以理解的解释。这种不透明性,导致用户对其结果不信任,增加了其落地难度,尤其是在医疗、法律等特殊领域。例如,一个医疗诊断系统,如果只给出病例的判断结果而没有给出诊断的依据,用户便很难被说服。由此可见,在追求情感分析准确性的同时,对模型预测的结果给出合理的解释已经成为了情感分析任务所需解决的一个重要问题。
本文致力于研究一个可解释的情感分析任务——情感可解释分析,该任务在判断文本情感极性的同时,还要抽取出所对应的证据。例如,图1给定一个文本“陈老师人非常好,做事很细心”,模型在判断出情感倾向为“积极”的同时,还需要抽取出其决策所依据的证据“人好”和“做事细心”。

图1 情感可解释分析任务样例
除此之外,本文面临的另一个挑战是缺乏标注数据。训练一个高性能的情感分析模型,往往需要大量的标注语料,但由于人工标注会耗费大量的时间和成本,现有的情感可解释分析评测任务(1)https://aistudio.baidu.com/aistudio/competition/detail/159/0/introduction只存在评测数据,并没有训练数据。
因此,本文设计了一个基于预训练模型 UIE[5]的情感可解释分析方法,通过小样本(Few-shot)学习和文本聚类等技术,极大地提高了模型的合理性和忠诚性,最终取得了“2022语言与智能技术竞赛: 情感可解释评测”任务的第一名。
1 相关工作
1.1 情感分析方法
传统的情感分析方法往往需要人工定义特征,然后使用机器学习方法来进行文本的情感分类。常用的机器学习方法有支持向量机(Support Vector Machine, SVM)[6]、朴素贝叶斯(Naïve Bayes, NB)[7]、深度森林(Deep Forest, DF)[8]等。但这些方法都需要针对不同的应用领域手动定义不同的特征提取规则,需要专家参与。
近年来,神经网络的方法被证明了有效性,渐渐成为了主流。 Kim[9]首先将卷积神经网络(Convolutional Neural Network, CNN)应用于情感分类任务。Socher等人[10]则提出了使用递归神经网络(Recurrent Neural Network, RNN)进行情感分析,取得了进一步的性能提升。随后,长短时记忆网络(Long-short Term Memory, LSTM)[11]也被于该任务。为了解决 LSTM 门控机制计算复杂度高的问题,Cho等人[12]又提出了使用门控循环单元网络(Gated Recurrent Unit, GRU)。基于多头自注意力机制的Transformer[13]问世以来,几乎席卷了所有任务榜单,情感分析也不例外。赵等人[14]提出用基于 Transformer 的混合模型建模方法进行短文本情感分析,性能高于其他主流方法。
1.2 信息抽取
信息抽取(Information Extraction,IE),即从自然语言文本中抽取出特定的事件或事实信息,帮助人们将海量内容自动分类、提取和重构。 这些信息通常包括实体(Entity)、关系(Relation)、事件(Event)。信息抽取主要包括三个子任务: 关系抽取(RE)、命名实体识别(NER)、事件抽取(EE)。
目前主流的方法依然是基于深度神经网络的方法。Liu 等人[15]首次使用卷积神经网络来做关系抽取任务。Zeng 等人[16]引入位置特征,并使用预训练的词向量进行关系抽取。随后,Xu 等人[17]首次使用 LSTM 网络捕捉句子信息来进行关系抽取。针对单向 LSTM 网络无法完全抽取上下文信息的问题,Zhang 等人[18]提出 Bi-LSTM 模型抽取句子双向的隐状态输出。Transformer 问世之后,Lee 等人[19]使用多头自注意力对句子的每个单词上下文信息进行编码,随后使用双向 LSTM 网络对句子进行编码,并叠加词语级别的注意力机制来获取向量表示。
1.3 预训练语言模型
现今,从 ELMo[20]到 BERT[21],预训练语言模型在多项自然语言处理任务上展现了其优势。预训练模型,利用了大规模文本,通过掩码预测、上下句判断等任务进行预训练,随后根据不同的下游任务进行微调,在包括命名实体识别、阅读理解问答和自然语言推理等多项自然语言处理任务上取得了当时最优结果。预训练、微调的两阶段模式逐渐成为众多自然语言处理任务的主流方法。
2 基于 UIE 的情感可解释分析
UIE(Universal Information Extraction),为Lu等人[5]在 ACL-2022 中提出的一种通用信息抽取统一框架。该框架实现了实体抽取、关系抽取、事件抽取、情感分析等任务的统一建模,并使得不同任务之间具备着良好的迁移和泛化能力。
本文的基准模型使用的是PaddleNLP 借鉴UIE的框架,基于ERNIE 3.0知识增强预训练模型训练并开源的首个中文通用信息抽取模型 UIE(2)https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie,整体模型框架如图2所示。该模型可以支持不限定行业领域和抽取目标的关键信息抽取,实现零样本(Zero-shot)快速冷启动,并具备优秀的少样本(Few-shot)微调能力,快速适配特定的抽取目标。

图2 UIE 模型框架
2.1 基于 UIE 的情感分类
情感分类任务是给定一句话,让模型判断出该句话的整体情感倾向。具体的,本文的情感分类任务是需要判断出文本是“正向”或“负向”两类。为了将情感分类任务适用于 UIE 框架,首先需要定义出如式(1)所示的Prompt 模板。
定义Prompt模板完成之后,将其与原始文本按式(2)拼接作为模型的输入,即可实现 zero-shot 情感分类。
为了提高情感分类的准确性,本文使用了公开数据集 ChnSentiCorp(3)https://www.luge.ai/ - /luge/dataDetail?id=25作为训练集对 UIE 模型进行微调。
2.2 基于 UIE 的情感可解释证据抽取
情感可解释分析是指模型在判断出文本情感倾向的同时,还需要给出模型决策所依赖的证据。如图1中给定文本“陈老师人非常好,做事很细心”,模型需要判断出该评论属于“正向”情感,并且“正向”情感的证据为“人好”和“做事细心”。证据需要满足两个要求: 合理性和忠诚性。
对于合理性,针对每一条输入文本t和其标准情感极性I,需要预测出极性I预测所依赖的证据。证据应满足充分、简洁、完备等3个特性。充分性,表明证据包含预测所需要的足够信息;简洁性,表明证据中每个词都是预测必需的;完备性,表明证据包含了所有有用信息。
对于忠诚性,以扰动下证据的一致性来评估模型的忠诚性。为此,针对每一个原始输入文本t,依照不重要词增删改、重要词同义替换、句式修改等方式构建了扰动文本t′。然后,评估原始文本和扰动文本证据词排序的一致性。扰动样例数据如表1所示。

表1 扰动样例数据
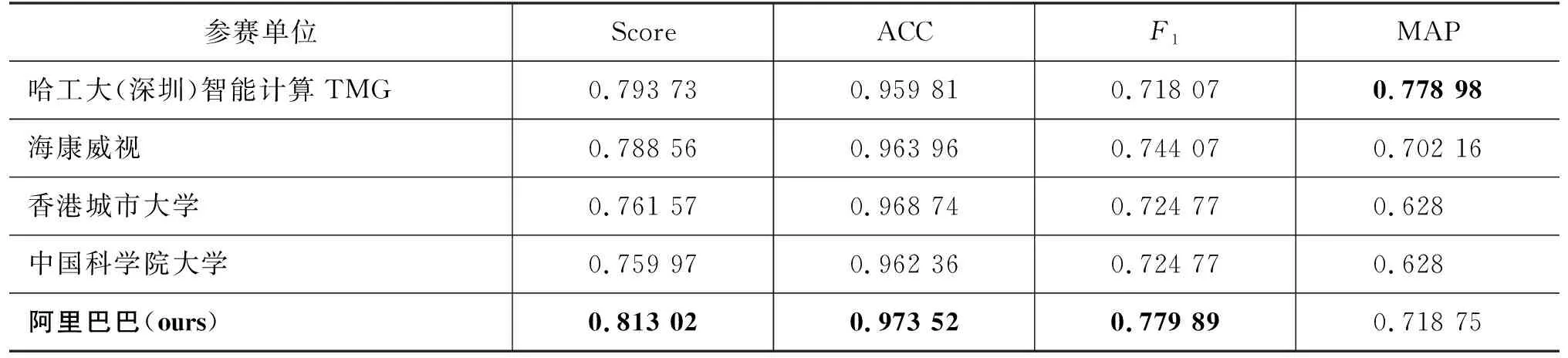
表2 实验结果
针对本次LIC-2022 评测任务的要求,则需要模型在正确判断文本的情感极性的同时,给出判断所依赖的证据之一, 并且要保证原始文本和扰动文本抽取出的证据一致性。即在如表1所示的示例中,原句中存在着两个证据“垃圾店”和“态度差”,模型需要在两个证据中选择其一给出即可, 并且要保证与扰动数据的证据选择一致。
根据如上要求,本文定义了如式(3)所示的Prompt 模板。其中,该模板分为两部分,第一部分为“评价维度: 观点词”对应着“店垃圾”的证据抽取,“店”指“评价维度”,“垃圾”指的是观点词;第二部分,“观点词”则是为了抽取泛化类的扰动数据证据,如表1 中的“不会再来”。
Schema= [{' 评价维度' : ' 观点词' }, ' 观点词' ]
(3)
本文从ChnSentiCorp数据集中抽取出少量评价样本,通过同样的扰动方法构造类似扰动数据,并使用 doccano(4)https://github.com/doccano/doccano平台按照式(3)描述的 Schema对其进行标注,然后对 UIE 模型进行小样本训练调优。
2.3 基于文本聚类的一致性调优
根据一致性的要求,让模型对原始文本和扰动文本抽取出排序一致的证据。例如,证据“店垃圾”和“垃圾店”就是不符合一致性的要求。
为了提高模型一致性分数,本文首先采用了文本聚类(5)https://github.com/MachineLP/TextMatch的方法识别出每一类文本集A=[A1,A2,…,Ai],每一类文本集合A都代表着一个原始样本和其对应的扰动样本组合。本文通过文本聚类的方法,在整个测试集对所有样本进行聚类,并且为了针对竞赛提高性能,本文会加入一些先验知识规则。例如,每一类聚类结果中,“id” 值最靠前的一个默认为原始样本,后面则为扰动样本,且扰动样本的“id”必须是连续的,在很大程度上提高了聚类的准确率。
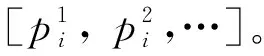
最终,通过比较该类别里面文本之间的证据集合,挑选出“字”重合率最高的证据pi作为该文本的证据,并且调整证据里面“字”之间的相对顺序,使其保持一致。
3 实验
3.1 实验设置
本文采用PaddleNLP 开源的基于 ERNIE-3.0 的中文 UIE 模型作为基准模型。情感分类和观点证据抽取在两个不同的 UIE-base基础上分别进行微调得到两个不同的模型。 UIE-base 模型是基于 Transformer 层的预训练模型,其一共包含了 12 层,隐向量维度为 768,自注意力头为 12 个。
在具体的实验过程中,各参数设置如下: 学习率为1e-5,批处理大小batch_size为 32,最大句子长度为 512,在 NVIDIA V100 GPU 上微调了10 个 epochs。
为了验证模型的准确性、合理性、忠诚性,本文采用了3 种评价指标,分别是ACC、Macro-F1和 MAP分数。
ACC用来评估模型对情感分类的准确率,计算如式(4)所示。
Macro-F1分数用来评估抽取出的证据合理性,计算如式(5)所示。

MAP用来评价模型的忠诚性,具体计算方法如式(8)所示。最终,根据准确率、合理性、忠诚性3个指标的加权分数得到总分数 Score,对应的权重分别是0.25,0.5,0.25。

3.2 实验数据
本文使用“2022语言与智能技术竞赛: 情感可解释”赛道的评测数据集作为测试集,其包含3 135条评测数据,由1 496条原始输入和1 639条扰动输入构成。其中,所有原始输入均来自真实用户数据,覆盖了单情感、多情感和隐晦情感3类情感描述。
ChnSentiCorp作为经典的句子级情感分类数据集,包含酒店、笔记本电脑和数据相关的网络评论数据,共包含积极、消极两个类别,其中训练集9 600个样本,开发集1 200 个样本,测试集 1 200 个样本。因为该评测任务仅提供测试集,并没有提供训练集可供使用,所以本文将ChnSentiCorp作为文本情感分类的训练数据集,并且从中挑选出少量典型样本使用Doccano 平台进行证据抽取模型的数据标注。
3.3 实验结果
实验结果如表 2 所示,本文方法在情感分类准确率 ACC和证据抽取的F1上都取得了大幅的领先地位,MAP 分数也保持着很强的竞争力,最终,总分数Score取得了81.302分,排名位居榜单第一的位置。证据抽取F1值相比于第二名,高出了6个百分点。MAP分数相比于第二名,低了6个百分点,因为F1和MAP分数在一定程度上是成反比的。例如,“特别垃圾的摄影店,服务态度差”“特别垃圾的摄影店,服务态度含含糊糊”和“这个摄影店,我不会再来”三个样本,前者是原始样本,后两者则是根据泛化方法构建的扰动样本。它们的证据分别是“垃圾店态度差”“不会再来”和“垃圾店态度含含糊糊”。所以,若想保证MAP分数的性能,对于前两者则都应该抽取出“垃圾店”作为证据,而不能分别抽取出“态度差”和“态度含含糊糊”作为证据。但是,对于“这个摄影店,我不会再来”这个样本,它与原始样本的证据并无“字”的重合,所以只能尽可能地保证证据抽取的F1值。
综上所述,在理想情况下,模型应该在保证F1值最优的前提下,尽可能地选择MAP分数最高的那个证据。
3.4 实验分析
为了进一步评估本文提出方法的有效性,本文对情感分类和证据抽取两个任务分别做了消融实验(Ablation Experiment)。
3.4.1 样本数量对情感分类ACC性能的影响
为了更好地比较训练样本数量和情感分类准确率之间的关系,本文添加了以样本数量为变量的对比实验。分别以数量0、100、300为基准进行实验,实验过程中,基准模型使用同样的 UIE-base模型,各参数初始化一致。
从表3的实验结果可以看出: ①使用 UIE-base 模型直接进行预测,ACC 的性能为 60.223%;②当使用100个训练样本对基准模型进行 fine-tuning 之后,ACC 性能可以达到 80.399%,相比于基准性能大幅提升了20.116个百分点;③当样本数量增加至300之后,ACC性能相比于基准性能提升了32.919%,相比于数量100提升了12.803%,可以看到,当样本数量持续增加时,性能增幅也在持续收窄。

表3 样本数量对ACC性能的影响
针对上述实验结果,本文对测试集样本结果进行了分析,主要原因是测试集中包含了大量转折情感,并且最终的情感倾向往往是以转折之后的情感为主,本文最终的实验结果也针对该种情况进行了特定的调优。本文在微调的过程中,特地选取了存在转折的样本进行训练,例如,文本中包含“但是”“却”等转折词的样本,本文会将其样本情感明确标注为转折词后的文本情感。
3.4.2 样本数量对证据抽取F1性能的影响
为了得到样本数量对证据抽取F1值性能的影响,本文同样以数量0、100、300为基准在 UIE-base上进行了对比实验,实验结果如表4所示。

表4 样本数量对F1性能的影响
从实验结果中可以看出,直接使用UIE-base模型可以得到51.338%的F1值;当增加100个训练样本之后,性能取得了大幅度提升,达到了 71.282%; 当使用 300 个训练样本之后,模型性能可以提升至 74.894%。
3.4.2 文本聚类调优算法对MAP值的影响
为了表明基于文本聚类调优算法的有效性,本文对最终的模型进行了文本聚类调优操作。实验结果如表5所示。

表5 文本聚类调优算法对MAP的影响
从实验结果中可以看出,当在最终的模型上进行基于文本聚类调优算法的优化,其MAP值从58.753%大幅提升至71.875%。同时,也可以看到,当使用调优算法之后,其F1值也同样有着较大提升,从75.919%提升至77.989%。
4 结论
本文介绍了在“2022语言与智能技术竞赛: 情感可解释评测”赛道上的冠军解决方案,通过基于 UIE 的基准模型、少样本学习、文本聚类等方法,提高了情感分类准确性,证据抽取的合理性和忠诚性,进而达到了模型可解释的目的。
未来工作中,我们将尝试联合情感分类和证据抽取,让两个任务互相促进,从而获得更好的效果。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2019年4期)2019-10-10
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
红土地(2016年3期)2017-01-15
贵州师范学院学报(2016年3期)2016-12-01
幼儿智力世界(2016年6期)2016-05-14
发明与创新(2016年33期)2016-04-16
小雪花·初中高分作文(2015年10期)2015-10-24
电源技术(2015年11期)2015-08-22
