
结合标签转移关系的多任务笑点识别方法
2023-02-04 06:09:02张童越张绍武林鸿飞
中文信息学报 2023年11期
张童越,张绍武,林鸿飞,徐 博,杨 亮
(大连理工大学 计算机科学与技术学院, 辽宁 大连 116024)
0 引言
幽默是人类交流的重要组成部分,情景喜剧作为一种大量包含幽默元素的艺术形式深受人们的青睐,在情景喜剧中,笑点(punchline)是幽默的载体,它是对白中使人发笑的一个或多个句子,是情景喜剧具有幽默性的关键之一。情景喜剧的对白具有复杂的语境,识别对白中的笑点对于提高计算机识别人类幽默的能力有着重要作用,但是从大量的对白中识别出少量的笑点是一项有挑战性的任务。 情景喜剧的对白由大量的笑话组成,Bright等[1]指出笑话一般是由笑点和笑点的上文铺垫(setup)所组成的,Raskin等[2]认为“铺垫”的作用是为笑点提供上下文信息,笑点的作用是通过表达与铺垫相违背的语义来产生幽默的效果,这在幽默理论中被称为不一致性[3]。在情景喜剧笑点识别任务中,笑点和非笑点在对白中的分布情况直观反映在句子标签的分布规律上,但是现有的笑点识别方法通常只通过建模铺垫和笑点之间的上下文语义关系分析不一致性并识别笑点,对标签的利用并不充分。为了弥补这一不足,本文引入了在标签层面的分析,将相邻标签之间的转移关系看作是不一致性的一种体现。相邻标签之间的转移关系存在于单词级别和句子级别两个粒度上,例如,句子A为“You fell Asleep !!”,句子A的下一句句子B为“There was no kangroo !”,句子A为铺垫,标签值为0,句子B为笑点,标签值为1,句子B能够产生和句子A的不一致性。在单词级别,将组成句子的字符(包括单词和标点符号)分为两类,正类代表该字符所在的句子能产生与铺垫的不一致性,标签值为1,其中字符的生成方式将在2.2节做详细介绍,因此句子A中所有字符均为负类,句子B中所有字符均为正类,即每个句子中相邻先后两个字符的标签不会是“1,0”或“0,1”,即标签不会在0和1之间发生转移。在句子级别,句子A和B之间的不一致性直观体现在句子的标签由0变为1的标签转移现象。为了挖掘在单词级别和句子级别同时存在的两种标签转移关系,考虑到条件随机场能够计算相邻标签的转移可能性大小,使用线性链条件随机场(Linear Chain Conditional Random Field,CRF)[4]学习上述两种转移关系。最后,由于学习相邻标签之间的转移关系以及上下文语义关系均能够学习到铺垫和笑点之间的不一致性,两者之间存在相关性,为了利用这种相关性提高模型的性能,本文采用多任务学习方法并定义了四个子任务,如表1所示,将子任务一作为主任务,其他作为副任务,子任务一和子任务三为仅学习词义或句义而不使用条件随机场挖掘标签序列中的信息,子任务二和子任务四为学习词义或句义的同时使用条件随机场挖掘标签序列中的信息,并同时对四个子任务进行学习。

表1 子任务描述
本文的贡献分为以下两点: (1)提出了结合条件随机场的单词-句子级多任务学习方法。在情景喜剧笑点识别任务中,该方法将标签序列中相邻两个标签之间的转移看作是幽默理论中不一致性理论的一种体现,为了学习相邻标签之间的转移关系,本文结合了神经网络与条件随机场。(2)使用多任务学习方法同时学习四个子任务,并通过实验证明了多任务学习的有效性。
1 相关工作
幽默是人们日常交流的重要组成部分,随着机器学习和深度学习技术的发展,幽默识别受到了较多的关注。在以往的工作中,为了识别幽默,Mihalcea和Strapparava[5]提出了四种特征,分别为头韵(西方诗歌的一种押韵形式)、反义词组,同义词组以及上下文特征,并使用这些特征识别文本是否幽默。Yang等[6]设计了一种用于识别幽默的分类器,该分类器从不协调性、歧义、说话者和倾听者之间的影响以及发音特征四个层面挖掘幽默背后的语义结构。Morales和Zhai[7]利用了文本的背景信息,如维基百科的词条描述,并构建多种特征识别互联网上的幽默评论。以上都是基于特征工程的幽默识别方法,随着深度学习技术的发展,基于神经网络的方法同样取得了好的效果,Chen和Soo[8]使用卷积神经网络进行幽默识别。Zhou[9]等指出双关语是实现幽默效果的方式之一,包括谐音相关和语义相关,并使用一种基于BERT和注意力机制的方法同时对单词的音素(根据语音的自然属性划分出来的最小语音单位)和语义进行建模。Fan等[10]提出的模型结合了卷积神经网络、门控循环神经网络和注意力机制,该模型通过学习语音结构和语义表征的方法进行幽默识别。 笑点是幽默的重要表现形式之一,并广泛存在于对白中,为了识别笑点,以往的工作大多从铺垫和笑点组成的句子对这一角度解决问题。在以往的工作中,Xie等[11]为了区分笑话和非笑话,使用预训练语言模型学习铺垫和笑点之间的语义关系,并将不一致性扩展到不 确定度和惊喜度两个方面,从这两个方面对铺垫和笑点之间的语义关系进行评估;受到不一致性理论的启发,Mihalcea等[12]提出了一种通过计算铺垫和笑点之间语义关系来识别笑点的方法。Andrew 和Cattle[13]使用了五种不同的度量方法计算铺垫和笑点之间的语义相关度;Bertero和Fung[14]使用长短时记忆网络建模铺垫和笑点之间的关系;Choube等[15]通过融合来自文本、音频和视频三个模态的信息,提高了语义识别的准确性,同时使用门控循环单元进行上下文建模,进一步提高了笑点识别的效果。
综上所述,铺垫和笑点这一概念常被用于笑点识别工作中,但是以往的笑点识别工作通常只通过建模铺垫和笑点之间的上下文语义关系分析不一致性并识别笑点,忽视了标签序列中的信息,导致对标签信息的利用并不充分。
2 模型
2.1 模型概述


图1 结合标签转移关系的多任务笑点识别模型图
2.2 词嵌入层
为了将输入文本转换为模型可接受的向量形式,需要对输入文本进行词嵌入。模型的输入为一个由对白中N个句子拼接成的序列S=[s1;s2;…;sN],使用预训练语言模型对输入序列进行词嵌入,现有的预训练模型包括BERT[16],XLNet[17],RoBERTA[18]等,本框架使用RoBERTA作为词嵌入层,同时规定:
其中,len(·)是计算一个句子经过Roberta的分词处理后生成的字符总数的操作,max为超参数,si代表输入序列中第i个句子,并且将si包含的所有字符表示为:W={wi,1,wi,2,…,wi,len(si)},其中i∈RN,wi,j为si的第j个字符,N表示一个batch包含的句子数量。将输入序列送入入嵌入层,得到每个字符的词向量,将词嵌入层的输出定义为:
其中,Ri={vi,1,…,vi,len(si)},vi,j∈Rb×l×d,i∈RN,vi,j表示第si的j个字符对应的词向量,b为输入的batch数量,l为si中包含的字符数量之和,d为Roberta隐藏层大小。
2.3 标签层面
本文将相邻标签之间的转移关系看作幽默理论中的不一致性理论的一种体现,为了在标签层面分析铺垫和笑点之间的不一致性,模型在单词级别和句子级别同时挖掘相邻标签之间的转移关系,本节详细介绍如何在单词级别和句子级别上挖掘相邻标签之间的转移关系,以及如何设置共享层。
2.3.1 单词级别
在单词级别,标签层面和单纯词义层面共享一部分隐藏层,定义为shareword,被共享隐藏层的参数同时受到两个层面的影响,使模型学习到更多的信息。词嵌入层中的Transformers能够忽略字符之间的距离,并学习句子中全部字符之间的特征依赖关系,为了学习部分字符之间的局部特征依赖关系,考虑到卷积运算只对卷积核大小范围内的输入进行处理[19],我们使用卷积神经网络处理输入字符序列的词嵌入向量,即图1中的“CNN”,并使用一个特征组合层将CNN的输出向量和词嵌入层的输出相加,如式(3)、式(4)所示。


(5)
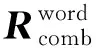
其中,Linear1(·)为一层用于二分类的全连接层,即fc1。为了学习相邻字符的标签之间的转移关系,将输出Pcrf1定义为:
其中,CRF1(·)为一个线性链条件随机场,Pcrf1为条件随机场对每个字符预测得到的标签。

其中,yi为输入序列中第i个字符的标签,n为输入序列的长度,得分函数值越大,对输入序列的标签预测的合理性越高。
2.3.2 句子级别

在句子级别上,为了学习相邻句子的标签之间的转移关系,将输出定义为:

其中,yi为输入序列中第i个字符的标签,n为输入序列的长度,得分函数值越大,对输入序列的标签预测的合理性越高。
2.4 单纯语义层面
模型在单词级别和句子级别同时挖掘铺垫和笑点在单纯语义层面的关系,本节详细介绍如何在单词级别挖掘词义和在句子级别挖掘句义,以及如何设置共享层。
2.4.1 单词级别
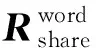
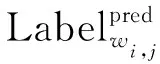
2.4.2 句子级别

由于数据集中正样本数量远少于负样本数量,因此将二分类问题转化为异常检测问题进行处理[21],其中,Linear2(·)代表用于异常检测的全连接层,即图1中的fc2。
2.5 训练和预测
为了使模型同时学习标签层面和单纯语义层面的信息,使用多任务学习方法,将任务一作为主任务,将其他任务作为副任务,同时对四个任务进行学习,提高主任务的泛化性。
任务一为学习字符的词义,损失函数采用交叉熵损失函数,并将损失函数定义为lossword,由于数据集中只有每个句子的标签,因此将一个句子中所有字符的真实标签定义为该句的真实标签,标签为1代表该字符所处的句子能够产生和上文的不一致性,否则相反。
任务二为学习不同类别字符的转移关系,损失函数为线性链条件随机场产生的损失函数,将损失函数定义为:

任务三为学习句子的句义,由于数据集中存在正负样本数量不均衡问题,因此使用GHM损失函数[22],并将损失函数定义为lossutt,GHM损失函数通过衡量一定梯度范围内的正负样本数量,使数量较多的类别对应的样本权重下降,让模型能够更多地关注数量较少的样本。
任务四为学习相邻句子的标签转移关系,损失函数定义为:
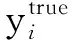
其中,λ是权重衰减系数,θ是所有可训练参数。
3 实验
3.1 数据集
本文在CCL2020“小牛杯”幽默计算——情景喜剧笑点识别评测任务的英文数据集上进行实验,该数据集来自电视剧《老友记》。根据场景的变换,将情景剧的对话结构分为对白(Dialogue)和句子(Utterance)两个层级,对白层级以一段独立的对白为单位,每段对白包含不同数量的样本,句子层级以一条样本为单位,每条样本为一个句子,如表2所示,对白A来自该数据集,包含7条样本,每条样本为一条句子。数据集中每条样本带有一个标签,标签为“0”表示该样本不是笑点,为“1”表示该样本是笑点,训练集包含7 472条样本,550段对白, 其中包括1 773条笑点和5 699条非笑点,测试集包含2 096条样本,157段对白,如表3所示。

表2 对白结构样例
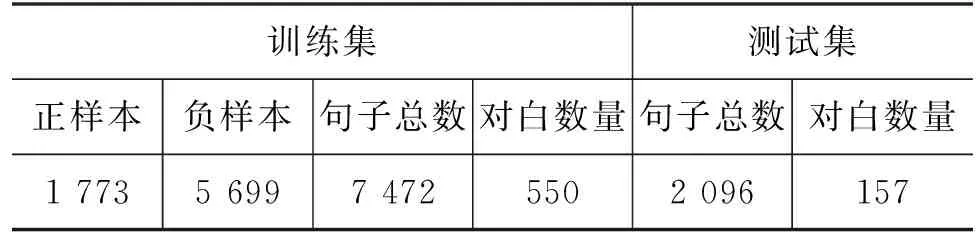
表3 数据集规模
3.2 评价指标
情景喜剧被划分成若干段对白(Dialogue),每段对白由不同数量的句子(Utterance)组成,考虑到每段对白包含的句子数量不同,评测官方将F1+Acc的值作为最终评价指标,该值的大小代表笑点识别效果的好坏(1)http://cips-cl.org/static/CCL2020/humorcomputation.html,其中F1为句子层级的F1分数,F1分数为所有正类样本的召回率(Recall)和准确率(Precision)的调和平均数;Acc为对白层级的精确率,精确率的计算方法为首先得到每段对白的精确率,再对所有对白的精确率取平均。
3.3 基线模型
基线模型如表4所示,第一类是自设计的基线模型,BERT代表使用预训练BERT模型对输入序列进行词嵌入,并使用全连接层和Softmax函数为每个句子进行分类,TextCNN[23]和LSTM[24]被用于提取句向量中的幽默特征,BiLSTM使用双向LSTM从前到后和从后到前对输入句子序列的句向量进行编码;最后,所有自设计基线模型均使用预训练BERT作为词嵌入层。第二类是CCL2020任务三参赛队伍中在英文数据集上取得前六名的队伍所采用的方案(2)https://github.com/DUTIR-Emotion-Group/CCL2020-Humor-Computation,第六名使用门控循环单元对句子进行上下文建模。第五名构建了四个基于长短时记忆网络,卷积神经网络和多头注意力机制的不同模型,并对四个模型进行模型融合。第四名使用了多种数据增强方法,并使用模型融合方法融合由不同数据训练得到的模型。第三名使用多任务学习方法同时对句子是否为笑点以及当前句子的说话者进行预测。第二名将命名实体识别的思想应用于笑点识别任务,通过判断一句话中所有预测标签为1的字符总数和该句长度的比例判断该句是否为笑点,本文的模型是在该方法上做出的改进。第一名使用预测下一句的方法对句子进行分类,在将数据输入到预训练模型时,输入策略为将待分类句的前十句和后两句作为输入的第一个序列,待分类句作为第二个序列。

表4 CCL2021英文数据集实验结果
3.4 实验细节
实验在Pytorch环境下进行。优化器为AdamW。为了减少过拟合现象的发生,采用权重衰减策略,权重衰减系数为0.01。学习率为5×10-6,同时采用学习率衰减策略,模型每处理300个batch学习率变为当前值的0.8倍。Dropout设置为0.1。Batchsize为1,即每次向模型输入由NF条句子组成的单个序列,并规定输入序列经过预训练模型分词后的字符总数必须小于256。在词嵌入层使用的预训练模型为含24个Transformer[25]的RoBERTA(large),RoBERTA(large)的隐藏层大小为1 024,并将最后一层Transformer的输出向量作为词嵌入层的输出。卷积神经网络的卷积层层数为1,同时为了保证输出向量的维度与输入向量保持一致,卷积层的卷积核大小设置为3,步长设置为1,卷积核数量与词嵌入层的隐藏层大小相同。当阈值设置为0.3时模型的性能相对最佳。
3.5 实验结果
表4展示了本文提出的方法和基线模型的比较结果。在自设计的基线模型中,使用TextCNN挖掘句向量之间的短距离上下文语义关系,以及使用LSTM和双向LSTM(BiLSTM)捕捉句向量之间的长距离上下文语义关系,虽然LSTM可弥补TextCNN只能提取短距离特征这一不足,但是会更多地关注后输入的信息从而导致丢失部分信息,双向LSTM通过对输入序列进行从前到后和从后到前的编码解决了丢失信息的问题,但是由于挖掘幽默特征较为困难,而且数据集中正负样本数量差别大,使用传统神经网络作为分类器无法取得理想的识别效果。在参赛队伍使用的六种模型中,为了弥补传统神经网络在笑点识别工作中的不足,使用了BERT或基于BERT改进的预训练语言模型获得单词或句子向量,使用传统或人工设计的分类器提取语义特征并对句子进行分类,同时为了进一步提高笑点识别性能,第一名、第四名和第五名使用模型融合方法中的投票法提高输出结果的准确性,第三名使用多任务学习方法提高模型的泛化性。与所有基线模型相比,本文提出的结合条件随机场的单词-句子级多任务学习模型将在标签层面的分析引入到笑点识别任务中,并使用多任务学习方法融合来自标签层面和单纯语义层面的信息,不同的子任务为模型训练提供了不同的噪声,噪声的存在能够提高模型拟合真实数据分布的能力,使模型从训练数据中学习到更具一般性的表征,提高模型的泛化性,超过了所有基线模型中的最好模型的性能。与所有基线模型相比,本文提出的模型在F1分数(F1)上比基线模型中最好的方法提高了4.1%;在精确率(Acc)上比基线模型中的“第一名”低0.9%,原因是模型虽然提高了将正样本正确识别的概率,因此使正类的召回率(Recall)比第一名高12.7%,但是将更多的负样本错误识别为正样本,因此正类的查准率(Precision)比第一名低3.2%,导致精确率(Acc)低于第一名。由于数据集由大量独立的对白组成,且每段对白包含的句子数量不同,只在句子层级或对白层级分析笑点识别效果无法准确判断模型的性能,因此遵循评测官方的规定,将F1分数和精确率之和“F1+Acc”作为最终评价指标,本文提出的模型在“F1+Acc”上比基线模型中最好的方法提高了3.2%,证明使用多任务学习方法将在标签层面的分析融入到情景喜剧笑点识别任务中能够有效提高笑点识别的性能。
为了更好地证明模型中各部分的作用,本文进行了消融实验研究,结果如表5所示。可以看出,只删除任务二、任务三或任务四会使模型的性能分别下降2.3%、1.4%和0.8%,证明任务二对提高模型性能的贡献最大,删除任务四和任务二以及删除任务四、任务二和任务三同样会导致模型的性能分别下降3.4%和3.7%,证明在情景喜剧笑点识别任务中,使用线性链条件随机场在单词级别学习相邻字符的标签转移关系以及在句子级别学习相邻句子的标签转移关系能使模型获得对提高笑点识别效果有用的信息,同时随着子任务数量的减少,模型的性能随之下降,证明多任务学习方法在笑点识别任务中的有效性以及学习标签序列中的信息和学习语义信息之间具有相关性。

表5 消融实验结果
4 结论
为了识别情景喜剧对白中的笑点,本文提出了结合条件随机场的单词级-句子级多任务学习模型,该模型将标签序列中相邻两个标签之间的转移看作幽默理论中的不一致性理论的一种体现,并使用多任务学习方法同时在标签层面和单纯语义层面进行分析,通过和六个基线模型的对比实验以及消融实验证明了该模型在情景喜剧笑点识别工作中是有效的。今后的工作中, 将考虑通过将外部知识引入到情景喜剧笑点识别任务中以提高模型的性能。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
时代邮刊(2019年24期)2020-01-02 11:04:44
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
意林·少年版(2019年18期)2019-11-13 15:56:52
意林绘阅读(2019年7期)2019-08-19 18:00:56
中国生物医学工程学报(2019年6期)2019-07-16 07:52:40
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
自动化学报(2016年3期)2016-08-23 12:02:56
电测与仪表(2016年5期)2016-04-22 01:13:46
