
融入篇章信息的文学作品命名实体识别
2023-02-04 06:08:56贾玉祥昝红英窦华溢
中文信息学报 2023年11期
贾玉祥,晁 睿,昝红英,窦华溢,曹 帅,2,徐 硕,2
(1. 郑州大学 计算机与人工智能学院,河南 郑州 450000;2. 郑州中业科技股份有限公司,河南 郑州 450000)
0 引言
命名实体识别[1]是信息抽取的基础任务之一,其主要目标是将文本中的人名、地名、机构名等实体名识别出来,以服务于自动问答、机器翻译、文本分析等下游任务。使用命名实体识别技术,识别出文学作品中人物等实体,对文学作品的智能分析和数据挖掘具有重要意义,如人物建模[2]、社会网络构建[3]、事件抽取[4]等任务都使用了实体信息。文学领域的命名实体识别,目前还是一个具有挑战性的任务[5]。主要原因有: ①文学作品语料与通用领域语料的差异大,不同作者写作风格不同,模型难以泛化;②作品中人物等实体复杂多变,模型难以学习特征;③文学领域的命名实体识别研究较少,缺乏大规模、高质量的标注语料。
通用的命名实体识别方法大多是针对句子级的数据,这些方法能够捕捉到句子内部的依赖关系,但是忽略了句间的长距离依赖,而篇幅长正是小说等文学作品的一大特点。文学作品中的人物、地点等实体通常不是孤立存在的,同一篇章中的实体相互交织形成一个整体的网络[6]。以往的命名实体识别方法只关注实体本身,忽略了篇章中实体之间的联系。本文模型将篇章中的实体进行一致性把控和识别,能够有效提升文学作品命名实体识别的效果。
本文的主要研究贡献包括以下两个方面: 构建了基于两部金庸武侠小说的命名实体识别数据集,并将其开放共享;针对文学作品特性,提出一种融入篇章信息的命名实体识别模型,实验表明该方法能够有效提升文学作品命名实体识别的效果。
1 相关工作
近些年深度学习模型在自然语言处理领域取得了广泛应用和良好的效果[7]。Collobert等人[8]首次提出基于深度学习神经网络的命名实体识别模型,该模型能够在大规模的真实数据上获得较好的命名实体识别效果,但该模型无法捕捉长距离的依赖关系。Kuru等人[9]使用LSTM提取全局特征,在多种不同语言上均取得了良好的命名实体识别效果。柏兵等人[10]将双向LSTM模型和CRF模型进行结合,在1998年《人民日报》语料库上取得了较好识别效果。Zhang等人[11]在序列标注模型基础上融入潜在的词汇信息,提出了Lattice LSTM模型。Liu等人[12]提出一种LM-LSTM-CRF任务感知型模型,在CoNLL-03命名实体识别数据集上F1值达到了91.71%。王月等人[13]提出一种BERT-Bi-LSTM-Attention-CRF模型,在警情文本命名实体识别上准确率达91%。陈茹等人[14]充分考虑到文本层次化结构对实体识别的重要性,提出了IDC-HSAN模型。Gui等人[15]通过对篇章级数据中的标签进行一致性把控,提出一种篇章级命名实体识别方法,在多个英文数据集上达到最优结果。
以往命名实体识别研究大都聚焦在通用领域语料,针对文学作品领域的尝试较少。Vala等人[16]提出一种基于图的Pipeline模型来识别文学作品中的人物,在多个数据集上获得很好的结果。同时提出一个衡量人物识别性能的评价框架,为以后相关工作提供了评价标准。Brooke等人[17]提出一种LitNER模型来进行小说命名实体识别,该模型基于Bootstrap方法,使用无监督方式进行训练,实验表明在给定文本全部上下文的条件下,该模型优于有监督方法。Xu等人[18]为解决中文文学文本命名实体识别数据匮乏的问题,基于700余篇文学领域的文章构建了一个面向中文文学作品的命名实体识别和关系抽取数据集。谢韬[19]通过对宋词和史记等古文语料进行研究,首先基于Apriori算法和LSTM模型对语料进行分词处理,再通过LSTM和CRF模型对数据进行命名实体识别,实验表明,该方法能够有效识别古文中的重要实体。Bamman等人[20]依照ACE标注规范,对100部英文小说进行命名实体标注,标注范围为每一部小说的前1 000个词,在该数据集上训练能够有效提升文学领域命名实体识别的效果。
2 中文小说NER数据集
2.1 人物/PER
人物主要指具体角色的人名,是文学作品中的核心实体。如在表1中“郭靖心想不错”中包含的人物“郭靖”,“丘处机和她在终南山上比邻而居”中的“丘处机”均为人物实体。需要注意的是,文学作品中通常包含非主要人物的集合、亲属称谓、人名指代,这些不在人物实体的标注范围内。如“两株大松树下围着一堆村民”中的“村民”,“却不提父亲已自刎身死之事”中的“父亲”,均不做标注。
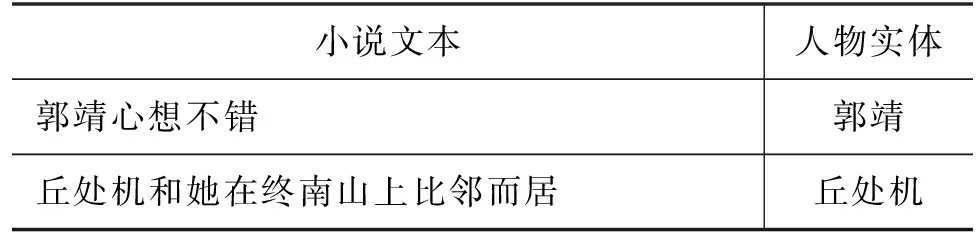
表1 人物实体示例
2.2 地点/LOC
地点主要指故事情节发生的地点或者对话中提及的地点,地点实体包括的范围较广。如在表2中,“从西域带来了这八盆兰花”中的“西域”为范围较大的地点实体,“临安府牛家村村民郭啸天、杨铁心二犯”中的“临安府”“牛家村”为范围较小的地点实体,“临安府”“牛家村”应分开标注。

表2 地点实体示例
2.3 组织/ORG
组织主要指门派或者帮会,主要特点: 成员们的武功都是一脉相传的,常以“派”“门”“教”“帮”“会”结尾。如在表3中,“要讲武功,终究全真教是正宗”中的“全真教”“丐帮却号称江湖上第一大帮”中的“丐帮”均为组织实体。

表3 组织实体
2.4 武器/WEP
武器主要包括兵器和武功。兵器指的是某人所使用的特定武器,如在表4中,“丐帮中规矩,见了打狗棒如见帮主本人”中的“打狗棒”为武器中的兵器实体。需注意,单字的兵器实体不做标注。武功指的是某个人所使用的特定武功,如表4中,“贫道就以太极拳中的招数和他拆几手”中的“太极拳”为武器中的武功实体。

表4 武器实体
2.5 数据集统计
数据集总体统计如表5所示,人物实体占比最大。 高频人物实体如图1所示,可以看出两部小说的主要人物“郭靖”“杨过”“黄蓉”“小龙女”出现频次最高,符合小说的主要人物特性。高频地点实体如图2所示,其中“蒙古”和“襄阳”为主要故事情节发生地点。高频组织实体如图3所示,其中“桃花岛”为组织实体,而并非一个地点,“全真教”“全真派”和“全真”为同一组织的不同称呼,后续将进行共指消解的标注。高频武器实体如图4所示,其中“长剑”为多数人使用兵器,故出现频次最多,“九阴真经”为两部小说中重要武功,出现频次为第二。

图1 高频人物实体
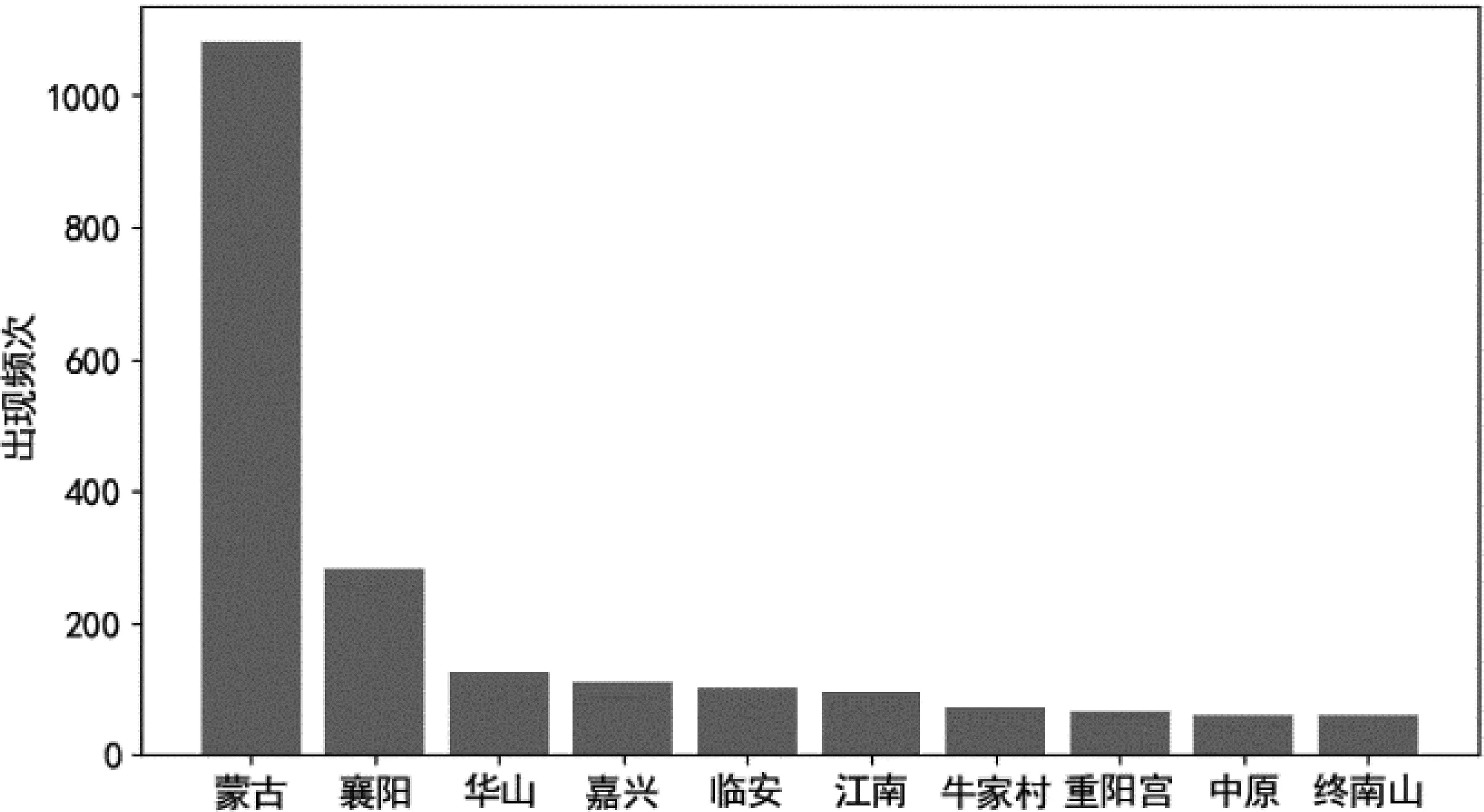
图2 高频地点实体

图3 高频组织实体
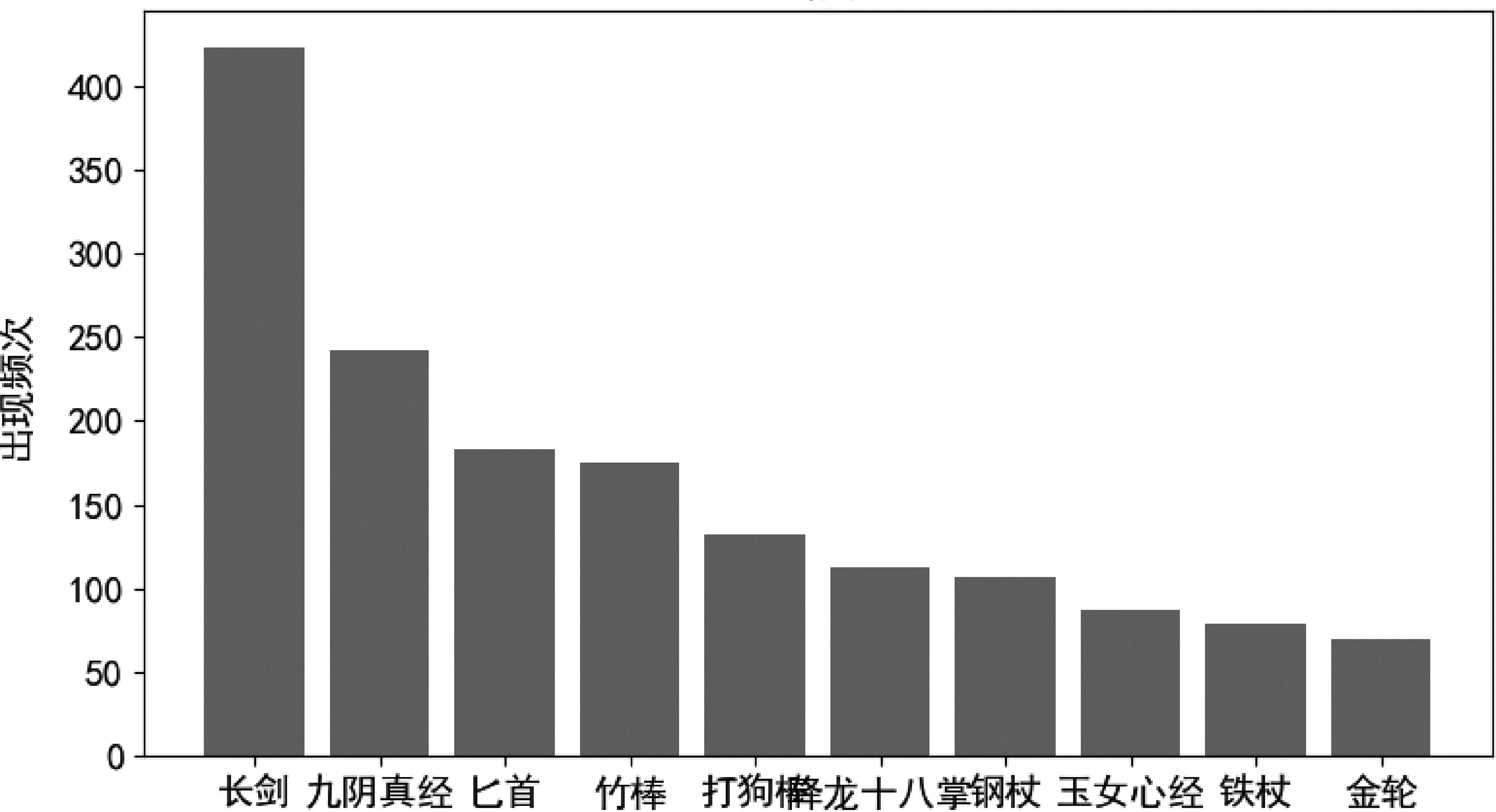
图4 高频武器实体

表5 数据集总体统计
2.6 标注一致性分析
为保证标注质量,本文采用多轮迭代修正的模式进行标注规范的修订和标注工作,每一篇小说文本同时有两名标注人员进行标注。首先由一标负责人对小说文本进行初步标注,得到一标结果;然后由二标负责人对一标的标注结果进行检查验证,得到二标结果。如有一标、二标标注不一致的地方,二人进行讨论并给出解决方案,最后再由一标负责人对标注结果进行确认,得到三标结果。对于标注过程分歧较多的情况,本文经过反复讨论后确定。
本次标注使用F1值[21]作为一致性评价标准,分别对四种实体进行标注一致性检验。表6中Mac-F1为宏平均F1值,宏平均F1值对每个实体类别单独计算F1值,然后将所有实体类别的F1值取平均;Mic-F1为微平均F1值,微平均F1值将所有类别的预测结果汇总后,再计算F1值。由表6可以看出,不同实体的标注一致性存在差异,其中人物和组织实体标注一致性较高,武器和地点实体标注一致性较低。总体标注一致性微平均达到0.938 1,宏平均达到0.893 3,表明该数据集是可信赖的[22]。

表6 标注一致性分析
3 融入篇章信息的命名实体识别模型
本文通过融合两个模型来进行文学作品的命名实体识别,模型整体结构如图5所示。首先使用BiGRU-CRF[23]模型来预测数据的初步标签,同时将隐藏状态和初步标签存入篇章信息字典,然后将篇章信息字典融入Transformer模型[24]中得到新的预测标签, 最后通过比较新的预测标签和初步标签的可信度,得到最终模型预测的结果。模型充分考虑篇章中不同行数据之间的远距离依赖关系,两个数据集上的多个实验表明了该模型的有效性。

图5 模型整体结构图
3.1 篇章信息字典
篇章信息篇章信息是通过对数据集进行人为划分来构建的,篇章大小定义为ch个连续的句子。篇章信息字典保存该篇章中所有字符和字符对应的所有的隐藏向量信息,字符i可能在该篇章不同上下文中对应多个隐藏向量(hi:1,…,hi:n),模型在进行标签预测时会同时考虑字符i的所有隐藏向量,从而可以捕捉篇章中不同行数据之间的远程依赖和同行数据之间的近程依赖。
篇章信息字典的构建模型通过BiGRU+CRF来进行初步预测和篇章信息字典的构建,篇章信息字典表示为D={ENTRYc1,…,ENTRYcN},ENTRYci中包含字符i的隐藏状态向量hi和对应标签的嵌入li,整个字典中包含篇章中所有字符的隐藏状态向量和标签嵌入。由于同一字符i上下文可能不同,因此字符i可以在篇章字典中出现多次(hi:1,li:1),…,(hi:n,li:n),即同一字符i的隐藏状态向量hi和对应标签的嵌入li可能不同。但是对于给定的隐藏状态向量hi:j,只有唯一的标签嵌入li:j与其对应。
篇章信息字典的应用在第二阶段Transformer模型中,首先对输入的字符i进行篇章字典查找,得到隐藏状态向量(hi:1,…,hi:n),然后通过Softmax计算出所有隐藏状态向量的概率分布phi:j,如式(1)所示。
其中,xi为字符i的字向量,W为线性运算矩阵,hi:j为对应的隐藏状态向量。然后通过计算每个隐藏状态向量hi:j与该向量的概率phi:j的乘积得到该隐藏状态向量对字符i的贡献,最后将所有贡献相加得到字符i的整体隐藏状态向量hi,hi包含了整个篇章中字符i的信息,hi计算方式如式(2)所示。
3.2 BiGRU-CRF模型
GRU全称为Gated Recurrent Unit,即门限循环单元,是一种改进的循环神经网络RNN[25],能够有效解决RNN网络梯度消失和爆炸的问题,同时相较于LSTM模型更为简化。其中,zt为更新门,rt为重置门,xt为输入文本的向量,ht是第t步隐藏状态。
CRF全称为Conditional Random Field,即条件随机场,是一种无向图模型[26]。该模型能够将随机变量的输入转换为条件概率分布,能够有效学习到训练数据中与标签有关的约束条件,能够保证得到结果的合法性。对于给定数据W=(w1,…,wn),其预测标签序列y=(y1,…,yn)。 计算方式如式(7)所示。
其中,M为条件转移矩阵,Myi,yi+1为从yi标签转移到yi+1标签的概率,Ni,yi表示第i个字被标记为标签yi的概率。
3.3 Transformer模型
Transformer模型首先通过多头自注意力机制对融入篇章信息的隐藏状态向量h进行注意力计算,第一步先对Q矩阵和K矩阵进行相似度计算,得到相似度f如式(8)所示。
相似度f通过Softmax函数归一化后与相应的V矩阵加权求和得到最后的注意力如式(9)所示。

MultiHead=Concat(head1,…,headm)WO
(10)

(11)
3.4 可信度计算
模型最终的输出结果通过计算标签预测可信度来确定,标签可信度计算过程如下: 首先使用相同的方法分别计算两个模型预测标签的错误率ri如式(12)所示。

4 实验结果
4.1 实验设置
实验使用哈工大LTP工具[27]、BiLSTM-CRF、BiGRU-CRF、Lattice-LSTM-CRF和BERT-LSTM-CRF模型作为基线模型,其中LTP工具不训练直接用于识别。主要进行了以下四个实验:
实验一整体数据集划分训练集: 验证集: 测试集为2∶1∶1进行实验。
实验二对训练数据中未出现的新实体(OOV)召回率单独进行测评。
实验三针对不同篇章篇幅设置进行实验,篇章篇幅设置为ch个连续的句子,实验得到最佳篇章篇幅设置。
实验四由于1998年《人民日报》1月命名实体识别数据集具有天然的篇章信息(每一篇新闻为一个篇章),对该数据集划分训练集: 验证集: 测试集3∶1∶1,分别进行保留原有新闻篇章和去除篇章的实验,进一步验证篇章信息的有效性。实验超参数设置如表7所示。

表7 超参数设置
4.2 实验结果及分析
实验一结果如表8所示,其中BiLSTM-CRF、BiGRU-CRF、Lattice-LSTM-CRF和本文提出的模型使用同一个字向量表,可以看到本文提出的模型明显优于这三种模型。LTP工具由于其训练数据为通用领域,在文学领域数据集上结果较差,Lattice-LSTM-CRF效果低于BiLSTM-CRF的原因可能是因为Lattice-LSTM模型中的词向量表与本数据集领域差异较大。BERT-LSTM-CRF模型由于引入外部预训练数据,宏平均Mac-F1高于本文提出模型,但其微平均Mic-F1值低于本文提出模型。由此可知本文所提出的模型在不引入外部资源的情况下,效果达到了最好。
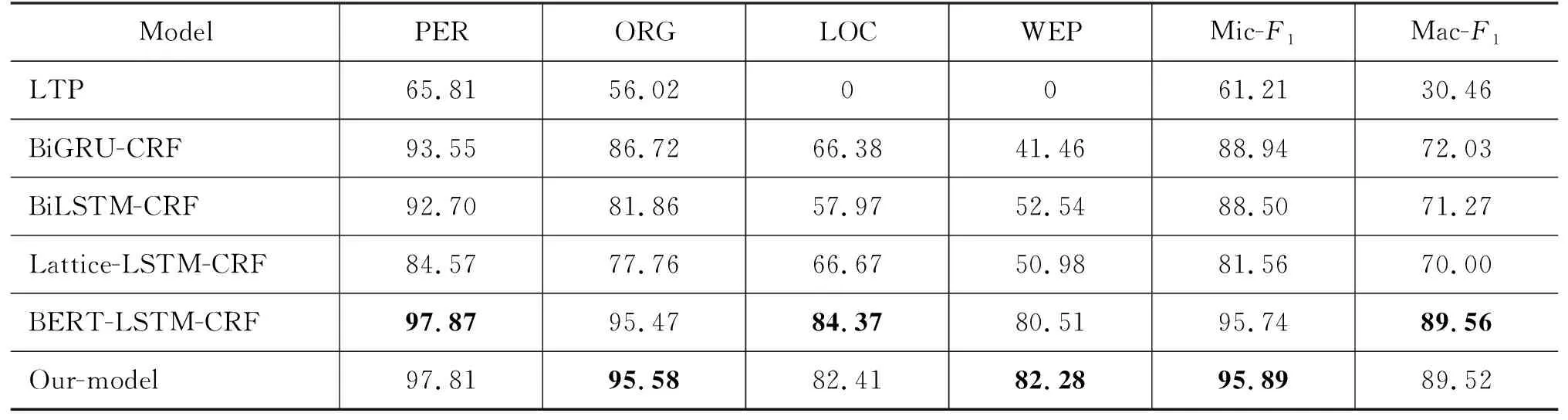
表8 整体实验结果 (单位: %)
实验二结果如表9所示,模型对于OOV实体的识别效果均低于实验一。Lattice-LSTM在实验二中的识别OOV的能力优于BiLSTM-CRF和BiGRU-CRF。BERT-LSTM-CRF模型Mac-Recall高于本文提出模型,但由于其人物实体识别率较低且人物实体占比较大,故Mic-Recall远低于本文提出模型。

表9 OOV实体识别效果 (单位: %)
实验三结果如图6和图7所示,X轴上的值表示一个篇章中包含的句子数。通过图片可以看到,随着篇章篇幅的增大,模型识别效果表现出先提升再下降的趋势,并在篇章篇幅为20的时候达到最好。原因可能是在篇章篇幅过小时,篇章信息过少,模型只能学到有限的篇章信息;而在篇章篇幅过大时,篇章内数据之间关联性下降,模型可能学到有偏误的篇章信息。以上分析证明了篇章信息在模型中进行命名实体识别是有效的。

图6 不同篇章篇幅Mac-F1值

图7 不同篇章篇幅Mic-F1值
实验四结果如表10所示,《人民日报》数据集具有天然的篇章信息,同一篇新闻报道往往主题相同,实体之间联系较为紧密,模型能够学习到的篇章信息较多。实验结果也证明了这一点,保存篇章信息比去除篇章信息的平均F1值提高了3个百分点以上。

表10 《人民日报》数据集实验结果
4.3 案例分析
案例分析如图8所示,第一句话中“靖哥哥”的“靖”和后面同一篇章中另一句话中“郭靖”的“靖”形成篇章级依赖关系,二者均被预测为人物标签。而后面一句话中“郭靖”的“靖”和“靖康之耻”中的“靖”属于本地句子级依赖关系,但二者的标签并不相同。由此可知,如果只考虑句子级的依赖关系,有可能导致模型预测错误,而加入篇章信息之后,可以有效避免这一问题发生。
错误分析如图9所示,第一句话和第二句话中出现的“孙婆婆”实体均被错误识别为“孙婆”。原因可能为“孙婆婆”实体出现较少且篇章内出现大量“老太婆”“老婆婆”等不是命名实体的字符串,“孙婆婆”中的第二个“婆”错误依赖了“老太婆”“老婆婆”中的“婆”,从而导致“孙婆婆”中的第二个“婆”被标注为标签O。
5 文学作品命名实体识别的应用
从小说中识别出命名实体之后,就可以进行后续的实体关系的研究。以人物之间的关系为例,根据人物实体在篇章中的共现情况可以构造社会网络,进而可以利用复杂网络技术来分析人物之间的关联关系。
使用模型在《射雕英雄传》上的NER识别结果,篇章大小设置为20句,即20句以内共同出现的人物具有共现关系,构造的社会网络(部分)如图10所示,也可以获取以个人为中心的网络,图11为主要人物“杨康”的人物关系网络。为了获取更精确的社会网络,后续可以在NER基础上进一步做指代消解,以获得实体层面的共现关系。另一方面,也可以考虑用对话关系代替共现关系,探索更加多样性的社会网络[28]。

图10 《射雕英雄传》中的人物社会网络
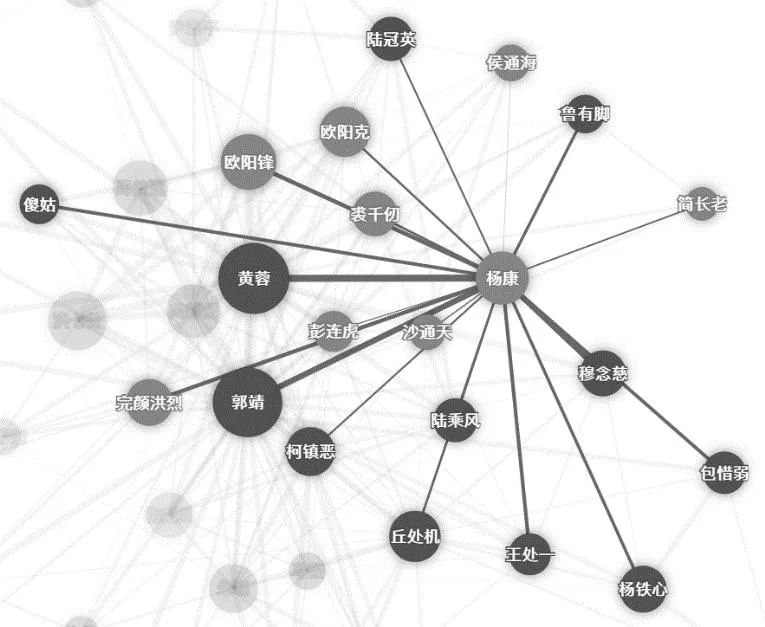
图11 《射雕英雄传》杨康的社会网络
6 总结与展望
本文基于两部金庸武侠小说构建了命名实体识别数据集,同时提出一种融入篇章信息的命名实体识别模型,通过多角度实验证明了该模型的有效性。最后本文构建了《射雕英雄传》的人物社会网络,体现了文学领域NER的应用价值。
本文构造的数据集还存在规模较小、来源单一的问题,下一步工作将继续加大文学作品数据标注规模,丰富文本来源;优化命名实体识别模型,并探索人物实体之间的关系以及不同实体之间的关系。
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
中国外汇(2019年18期)2019-11-25 01:41:54
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
公民与法治(2016年10期)2016-05-17 04:12:58
