
一种引入结构化知识的常识问答模型
2023-02-04 08:23罗琨皓曹擎星梁小丹
中文信息学报 2023年12期
罗琨皓,曹擎星,梁小丹
(中山大学 智能工程学院,广东 广州 510006)
0 引言
在大规模文本语料库上训练的预训练模型,无需人工标签,通过自监督学习的方式即可学习到通用的文本表示。BERT[1]、Elmo[2]等语言模型,利用自注意力机制和多层堆叠等机制提高模型容量,增强了模型的泛化效果。研究表明,通过自监督的方式预训练得到的大容量的预训练语言模型,不仅能够对语言知识进行编码,而且还能学习到蕴含在大型文本语料库中的某些结构信息。例如,BERT和Elmo可提取到句子中的语法依赖结构[3-4]。除此之外,在事实类完形填空问题中,BERT还可通过预测文本的空白词汇学习到关系知识[5]。在自然语言理解领域和信息抽取领域,大量的研究工作致力于从自由形式的文本中解析出不同类型的结构化信息,例如,语法分析[6]、实体链接[7]和知识提取[8]。在多种自然语言理解任务上,例如,文本蕴含[9]、情感分类[10]和机器问答[11-12],相关研究工作已经证明结构化信息的效果。
近年来,多个研究工作致力于在语言模型之外引入知识。例如,谭等人[13]在阅读理解任务中,引入现代汉语词典和HowNet[14]等词义知识,在中文阅读理解任务上取得显著的性能提升。张等人[15]从知识库中提取出高信息量的实体信息,通过特殊的语义融合模块来增强文本中对应的表示。因此,针对某种特定的NLP任务,如常识问答,动态选择和利用不同的结构信息非常重要;否则,仅通过预训练任务将大量人类提出的结构化信息融入数据驱动的模型中,需要极大规模的文本数据和超大容量的模型。
本文探索如何利用文本中的底层结构关系信息,从而扩展语言模型的表征能力。在训练时,我们并非直接为词向量添加额外的结构化约束,而是探索如何将结构化的先验知识信息融入模型结构中。朱等人[16]将Transformer网络[17]应用在AMR图转文本任务,曹等人[18]将Transformer模型中引入语法纠错任务,这类方法体现了Transformer网络在编码结构信息上具有天然的优势。因此,本文将尝试在Transformer网络中动态融入多种结构化信息,提出PDT(Prior-Driven Transformer) 模型,该模型能够动态融合多种结构化信息。给定一个文本序列,首先利用现有的工具,如Spacy[19]等,提取四种不同层级的结构化信息,包括依赖关系解析树、实体检测链接、情感词连接,以及常识知识图。这四种结构信息反映了人类理解语言时的不同角度。然后,对于每种结构关系,通过构建不同的邻接关系矩阵,来表示两个单词是否能够通过某种特定的结构信息建立链接。最后,根据具体输入的文本,PDT模型进一步融合和选择合适的结构信息。通过给定关系矩阵,隐式建立了四种不同的关系语义图,语义图可看是作在两个单词之间是否有相关联系的标志。在模型中,每个单词只能通过特征矩阵,将特征转发给语义图中相连的单词,并最终将模型内部的结构信息与人类的先验结构信息结合。
本文的贡献总结如下: 在常识问答任务中,利用文本中蕴含的常识信息,为文本建立常识关系图,利用现有工具抽取多种有助于理解语言的结构化信息,并将其融入到深度模型中,来辅助常识问答任务。实验结果证明,本文提出的动态融合模型,还可针对某个特定的任务或者样本,对不同的结构信息加权以辅助常识问答。在多种结构化信息的指导下,我们提出的PDT模型能显著提升多个常识问答数据集的效果。
1 相关研究
1.1 结构融合
近年来,多种几何结构(如序列、树和图等)已经被广泛应用到深度模型中。基于人类知识先验构建的结构,不仅融入了人类的结构化知识,同时降低了模型的计算复杂度。例如,RNN[20]和LSTM[21]之类的序列模型,前提假设是步骤t的状态仅仅取决于其上一个步骤t-1的状态;树型LSTM[22]之类的树模型,前提假设是父节点的特征组成仅仅取决于其子节点的特征组成;条件随机场CRF[23]和图卷积神经网络GCN[24]之类的图模型,前提假设是样本中的输入可转化为多个相邻节点的联系。在多种NLP任务上的相关研究工作,已经证实这些结构在深度模型的有效性。
除了手动设计的结构化信息之外,近期提出的深度模型还学会了在词向量编码中融入几何结构信息。Hewitt等人[3]提出了一种结构探测方法,应用全局线性变换和平方L2距离来构建最小生成树,并将得到的最小生成树与标准的语法解析树进行比较。结果表明基于神经网络编码的词向量表示可以融入语法树信息。RFeif等人[4]还发现,在词向量的表示空间中,头部词汇和从属词之间的L2距离与二者之间的依赖类型相关。Petroni等人[5]通过在完形填空的事实句子中预测三元组中被替换掉的宾语对象,恢复出深层语言模型中蕴藏的知识三元组。鉴于上述的研究成果,最近有多个模型试图利用语言自身的结构信息来改进深度模型在NLP下游任务中的效果。SG-Net[25]利用掩盖语法依赖关系之间的权重,将依赖关系树融入语言模型中。StructBert[26]引入了两个辅助任务来预测被打乱单词和句子的正确顺序,从而学习到文本的上下文结构信息。
1.2 机器问答
随着深度神经网络模型[1,27]在大型问答数据集[28-30]上的成功应用,机器问答相关任务上的模型效果近年来取得显著的提升。Cui等人[31]提出了Attention-over-Attention模型,用于计算问题和文档中每对单词之间的注意力权值。Seo等人[32]提出了BiDAF网络,分层建立基于问题感知的文章表征注意力和基于文章感知的问题表征注意力,以捕获问题和文章不同粒度的特征。Yu等人[33]提出了QANet网络,利用卷积神经网络和自注意力机制,开辟了机器问答研究的新方向。Chen等人[34]利用Wikipedia额外引入知识来回答事实问题。本文同样利用乘性注意力机制,并考虑了文章和问题之间包括常识在内的多种结构联系。
在常识问答任务中,通常将常识作为语义图联系的形式。由于图神经网络在处理图结构信息方面具有天然的优势,近年来,多篇研究工作[35-36]尝试利用图神经网络来改进深度神经网络语言模型,并显著提升CosmosQA[37]、CommonsenseQA[38]等常识问答任务上的效果。KagNet[36]网络在CommonsenseQA[38]常识问答任务中,提出在ConceptNet[39]中抽取4跳内的三元组建立常识语义图,利用图卷积神经网络GCN[24]对图进行编码,利用LSTM[21]对图中的路径进行编码,利用基于路径的注意力机制计算出语义图和QA文本对之间的联系,但该方法引入太多的无关常识信息。Lv等人[40]将ConceptNet[39]中蕴含的三元组信息看作结构化知识,将Wikipedia中囊括关键词的句子看作非结构化知识,分别抽取出三元组,利用图卷积神经网络GCN编码图信息,并利用图注意力网络GAT[41]来聚合两种结构信息。但该方法同样存在大量的信息冗余,使得模型容易关注无关的信息上。
鉴于上述研究工作忽视了底层语法结构在常识问答中的作用,本文同样基于ConceptNet构建常识联系图,并结合多种类型的语法结构信息。但本文在构建常识联系图时,并非利用路径上的所有信息,而是将起始节点连边,并映射到二者之间的注意力联系上,增强常识连接词之间的特征。
2 方法
针对常识问答任务,本文提出知识驱动的编码器模型——Prior-Driven Transformer模型,简称为PDT模型,模型结构如图1所示。其将多种人类理解语言需要的结构知识,整合到基于Transformer网络的改进模型中,从而扩展了Transformer网络的表征能力。

图1 PDT(Prior-Driven Transformer)模型结构图
具体来说,本文考虑了4种先验结构信息: 语法依赖关系、实体链接关系、情感词连接关系以及常识连接关系。给定一个包含N个单词的序列,首先利用现有的工具包Spacy 来提取这些结构信息,然后将结构关系转化为4个N×N维的二进制关系矩阵M=[M1,M2,M3,M4]。这些矩阵可表示在对应类型的结构关系中两个单词之间是否存在边的连接。例如,如果两个单词wi和wj之间具有语法依赖关系,则M1[i;j]=M1[j;i]=1,否则M1[i;j]=M1[j;i]=0。


2.1 结构关系抽取
为抽取文本中的结构信息,首先将样本中的文章、问题和答案拼接为整个序列,然后利用Spacy等工具提取单词之间的结构关系。图2给出了CommonsenseQA数据集中某个样本的多种结构关系。

图2 CommonsenseQA数据集的不同结构关系实例
2.1.1 依赖关系
依赖关系反映了文本序列中头部词汇和其从属词之间的句法联系,从而得到序列的句法结构。在问答任务中,语义相关联的单词之间通常存在语法依赖联系,从而可定位出问答所需要的关键信息,因而考虑额外引入依赖关系来辅助问答。
本文利用现有的Spacy工具将给定的序列解析为语法依赖树,并进一步确定每个节点的所有祖先节点,节点与祖先节点采用无向图的方式连接,生成依赖关系矩阵M1。
如果在语法解析树中,某个单词wj是单词wi的祖先,则M1[i;j]=M1[j;i]=1,否则M1[i;j]=M1[j;i]=0。如在图2(b)中,为问题序列构建出语法依赖树,中心词为thought和meant,问题中的其他词都为中心词的子节点。通过将依赖树中的所有节点与其对应的祖先节点建立双向连接,得到一个对称的关系矩阵。
2.1.2 实体关系
在长文本序列中,时间、地点和人名等特定实体有助于定位序列中的关键信息,从而构建出特定对象之间的语义联系。在常识问答任务中,实体间的联系可看作显式的常识关联,因而考虑将实体关系引入该任务。
本文利用Spacy工具包中现成的实体检测和短语解析方法,识别文本中的命名实体和实体短语,并将所有实体以无向边的方式连接,从而构建实体关系矩阵M2。
在序列中,如果其中两个单词wi和wj均属于命名实体或实体短语,则建立连接M2[i;j]=M2[j;i]=1,否则M2[i;j]=M2[j;i]=0。在图2(c)中,序列中包括5个实体,在实体之间分别建立连接,从而得到对称的实体关系矩阵M2。
2.1.3 情绪关系
文本序列中的情绪词反映了文本中的观点态度。在问答任务中,情绪词之间的联系可视为隐式的常识关联,有助于在特定语境下更深层次地理解文本,因而考虑在常识问答任务中引入情绪联系来辅助问答。
本文利用SentiWordNet情绪词表[42]来提取给定文本中的情感词,并建立情感关系矩阵M3。首先利用Spacy工具中的词性识别方法,识别每个单词的词性;然后根据单词内容及其词性,从SentiWordNet中检索出单词对应的积极情绪和消极情绪得分。如果检索到的某类得分包括多个值,则将多个得分取平均值。如果某个词wi的积极情绪得分大于消极情绪得分,则将这个词视为积极情绪词;如果某个词的积极情绪得分小于消极情绪得分,则将其视为消极情绪词;否则视为中性词。
最终,若两个单词wi和wj同为积极情绪词,或同为消极情绪词,则建立连接,得到M3[i;j]=M3[j;i]=1,否则M3[i;j]=M3[j;i]=0。例如,在 图2(d)中,问题中的home、time和答案中的early均为积极情绪词,在问题和答案之间建立情绪词连接,进而得到情绪词关系矩阵。
2.1.4 常识关系
在常识问答任务中,不仅需要考虑文本自身蕴藏的语义信息,还需要考虑文本内隐藏的常识联系。通过构建显式的常识关系图,在图结构上可定位问答所需要的关键信息,从而完成常识推理。因而考虑在常识问答任务中,引入常识关系结构。
本文利用常识概念图谱ConceptNet[39]来提取文本中单词之间的常识联系。具体来说,在CosmosQA数据集中,给定文章、问题和答案组成的序列,如果序列中的单词wi和wj在ConceptNet中都存在具有相同词干的节点与之对应,则视为在单词之间建立常识连接。同理,在CommonsenseQA数据集中,给定问题和答案组成的序列,如果两个词wi和wj在ConceptNet中存在2跳之内(包括2跳)的联系,则视为单词之间存在常识连接。
假设单词wi和wj分别与ConceptNet中的节点ni和nj具有相同的词干,且节点ni和节点nj在ConceptNet中具有2跳以内(包括2跳)的连接,则在常识关系图中,可在单词wi和wj之间建立连接,即M4[i;j]=M4[j;i]=1,否则M4[i;j]=M4[j;i]=0。在图2(a)中,问题中的home、evening、time和leave与答案中的early和morning均存在常识联系,可构建出对称的常识关系矩阵M4。
2.1.5 动态结构融合

其中,t∈[1,4],N是文章、问题和候选答案所组成的序列中的单词数。Wl∈R4×D,αl∈R4是学习到的不同矩阵间的权值,D为隐藏层h中词向量表示的维度。
2.2 模型结构层
在PDT模型中,我们改进了原始Transformer模型[17]中的多头自注意力机制,将提取到的四种结构信息通过改进的注意力计算,动态融合到Transformer模型结构中。
2.2.1 Transformer模型层
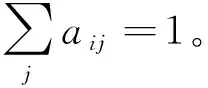

2.2.2 PDT模型层

(4)

(5)

在训练阶段,在所有的候选答案上执行交叉熵损失函数,在测试阶段,将选择通过Softmax计算后,概率最高的候选答案作为预测的输出。
3 实验
3.1 数据集
本文在热门的常识问答数据集CosmosQA[37]和CommonsenseQA上进行了实验。该数据集主要专注于常识推理,适用于评测融入模型中的不同结构,从而判断哪些信息对于常识问答更为有效。
CosmosQA数据集中包含35 000个样本,每个样本包括文章、问题和候选答案三部分。要回答这类问题,需要考虑文本之外的多种常识信息。数据集中的文章来自Spinn3r Blog数据集。在数据标注阶段,标注者仅保留存在常识推理过程的样本,并给出1个正确答案和3个错误答案,将顺序打乱后作为候选答案。
CommonsenseQA数据集中包含12 102个样本,每个样本中包含问题和候选答案两部分。要想回答问题,需要充分利用样本中涉及的常识知识,并筛选出重要的常识连接。数据集中的问答对基于Conceptnet常识库标注。在数据标注阶段,标注者针对每个问题给出1个正确答案,并选择四个与问题相关的错误答案,将顺序打乱后作为候选答案。
3.2 实验设置
在词向量编码阶段,选择RoBERTa-base模型[27]作为模型骨架网络,之后加入随机初始化后的PDT模型,以评估融合结构化信息后PDT模型的有效性。为了使自定义的模型与RoBERTa-base模型的输出保持一致,PDT模型将隐藏层维度设置为768,多头注意力机制中包含12个自注意力头,并堆叠了三层嵌入结构知识的Transformer层。
3.3 实验结果
表1和表2中展示了本文提出的PDT模型在CosmosQA和CommonsenseQA两个常识问答数据集上的效果。其中, Dev代表模型在验证集上的准确率,Test代表模型在测试集上的准确率,所有数值均分百分数。
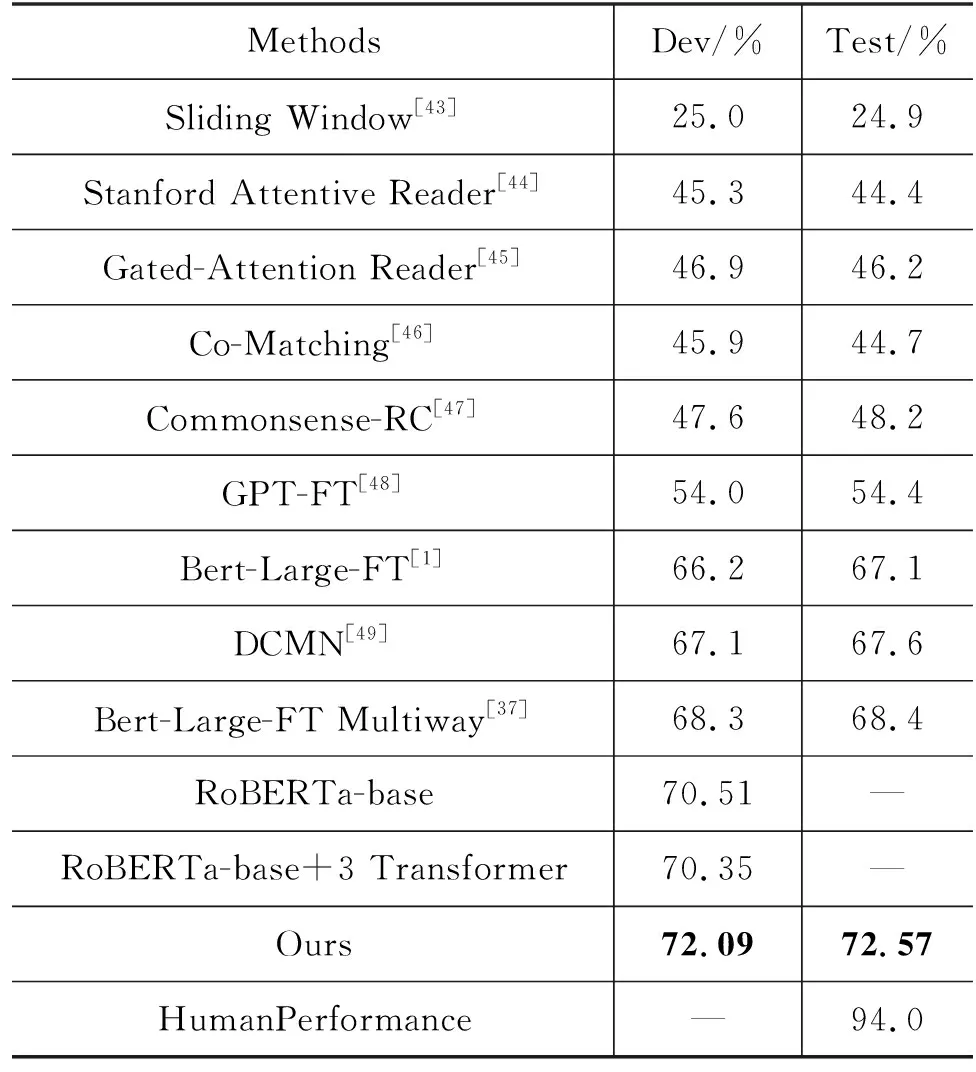
表1 不同模型在CosmosQA数据集上的准确率

表2 不同模型在CommonsenseQA数据集上的准确率
表1中的实验结果表明,在以RoBERTa-base[27]作为骨架网络的模型中, 在CosmosQA数据集上,本文提出的PDT模型的效果已经超过其他模型,成为当前效果最好的方法。PDT模型在RoBERTa-base基线模型的基础上,通过较小的模型改进,在CosmosQA数据集的验证集上,准确率较基线模型提高了1.58个百分点。
表2中的实验结果也表明,在以RoBERTa-base为骨架模型的模型中,PDT模型在CommonsenseQA常识问答数据集上,相较于基线模型也取得明显的性能提升。在CommonsenseQA数据集上中,PDT模型在验证集上的准确率相较于基线模型提升了1.27个百分点。
上述结果一方面证明了PDT模型在多个常识问答任务上的有效性;另一方面PDT模型在常识问答任务中的准确率与人类的表现存在显著的差异,这也表明大容量的预训练语言模型,即使基于大量的训练数据来训练,其理解语言的方式同人类仍然存在一个语义的鸿沟。当前预训练模型还不能有效利用文本中蕴含的常识信息,模型与人类相比,在理解结构知识的能力上仍存在较大的差异。
3.4 对比试验
为进一步评估在PDT模型中融入模型的不同结构信息的作用,我们进行了一组对比实验。通过比较不同的结构信息在模型上的实验结果,评估出不同结构关系对模型的影响。
除此之外,为验证不同的动态结构融合方式的效果,我们也进行了一组对比实验,比较了不同的特征融合方式的效果。
3.4.1 结构信息对比
表3列出了在CosmosQA和CommonsenseQA数据集中,使用融入不同的结构信息之后模型的效果。基线模型以RoBERTa-base模型作为骨架模型,并在后面堆叠了额外的3层Transformer层。RoBERTa网络和Transformer网络输出的第一个单词的特征将被用于分类。
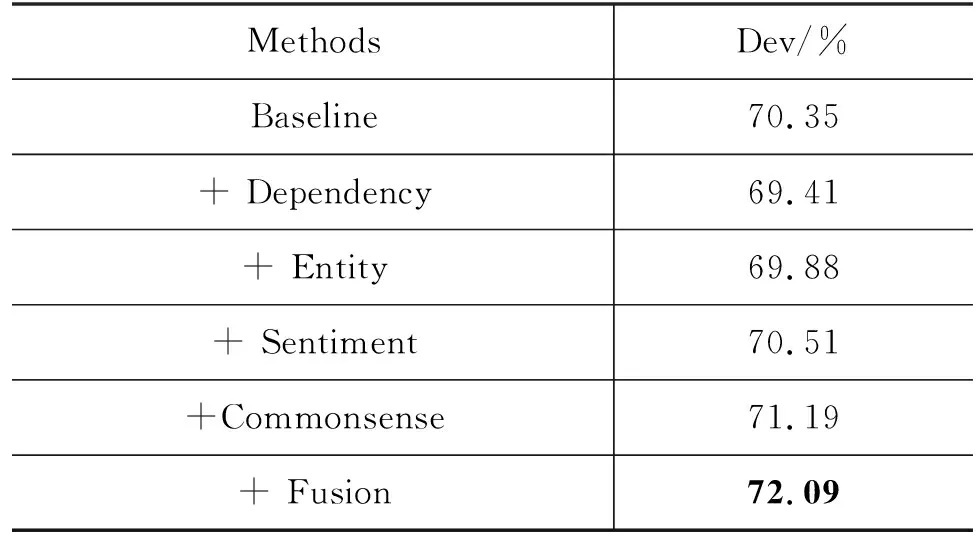
表3 不同的结构信息在CosmosQA验证集上的准确率
表3中的其余每一行,代表在CosmosQA数据集中引入不同的结构关系信息之后,模型在验证集上的效果。
表4中的其余每一行,代表在CommonsenseQA数据集中,引入多种结构关系后模型在验证集上的效果。
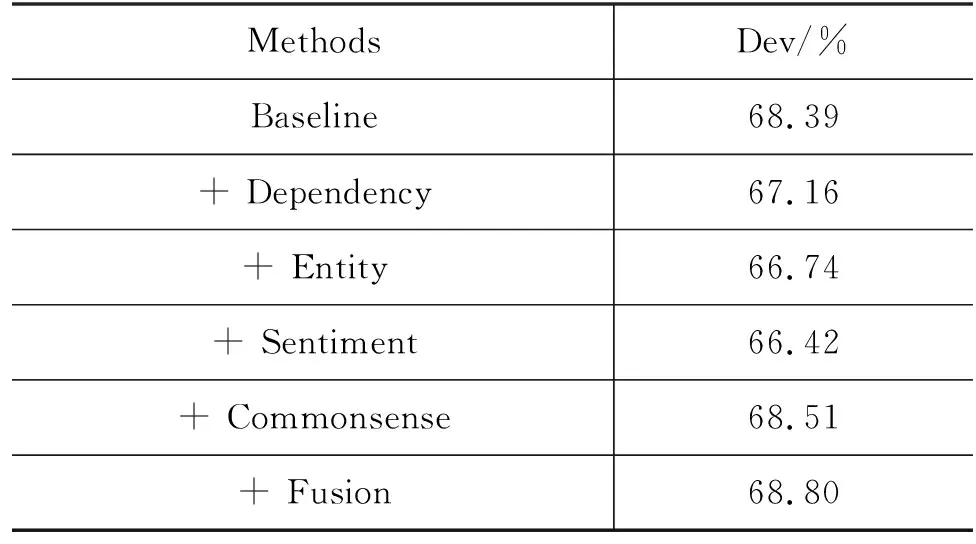
表4 不同的结构信息在CommonsenseQA验证集上的准确率
(1) 语法依赖关系
在两种数据集的实验中,语法依赖关系均会损害模型在验证集上的性能。在CosmosQA数据集上添加语法依赖结构信息后,PDT模型在验证集上的准确率降为69.41%,相较于基线模型下降了0.94个百分点。在CommonsenseQA数据集上,添加语法依赖关系后,PDT模型在验证集上的准确率降为67.16%,相较于基线模型准确率下降了1.23个百分点。
上述结果表明,在常识问答任务中,仅仅依赖文本内部的句法结构无法提供完全有效的常识信息。句法结构与常识问答中需要的常识信息存在较大差异,因而模型未取得明显性能提升。
(2) 实体链接关系
实体链接关系同样会降低模型在数据集上的性能。在CosmosQA数据集中,融入实体信息后,PDT模型在验证集上预测的准确率下降到69.88%,相较于基线模型下降了0.47个百分点。在CommonsenseQA数据集上,添加实体联系后,PDT模型在验证集上的准确率下降到66.74%,相较于基线模型,准确率下降了1.65个百分点。
上述结果表明,仅仅依赖特定实体间的联系,同样无法构建出有效的常识信息。实体间联系仅仅反映出特定类型的单词之间的关联,无法反映序列整体的语义信息。
(3) 情绪词关系
情绪词关系在两个数据集上取得相反的效果。在CosmosQA数据集上,添加情绪词关系后,PDT模型在验证集上的准确率提升到70.51%,相较于基线模型准确率提升了0.16个百分点。但在CommonsenseQA数据集上,融入情绪词关系后,PDT模型准确率下降到66.42%,相较于基线模型准确率下降了1.97个百分点。
该结果表明,在CommonsenseQA数据集上,由于序列长度较短,且答案与情绪词基本不相关,因而准确率明显下降。但在CosmosQA数据集中,序列中包含大量有效的情绪词,在某些样本中,可利用情绪词作为额外的常识信息来辅助问答,因而模型准确率取得小幅度提升。
(4) 常识关系
单种结构关系提升最大的是常识关系,其在两种数据集上相较于基线模型均取得明显性能提升。在CosmosQA数据集上,PDT模型在验证集上的准确率提升到71.19%,相较于基线模型提升了0.84个百分点。而在CosmosQA数据集中,相较于基线模型,PDT模型在验证集中的准确率提升到68.51%,整体提升了0.12个百分点。
上述结果表明,在常识问答任务中引入额外的常识关系,能够增强文本信息之间的语义特征。在理解复杂长文本时,常识信息为问答提供了清晰的推理路径,对于辅助常识问答起到了至关重要的作用。
不同结构关系的实验结果对比也说明,并非所有的结构信息在单独应用时都适用于特定的问答任务。在不同的数据集或不同样本上,不同类型的结构信息的作用存在明显差异。为充分利用不同的结构知识,需要将多种结构知识动态融合,从而为每个样本筛选出重要的结构信息。
3.4.2 结构融合方式对比
本文比较了基于不同的思路提出的3种动态结构融合机制: 基于输入的、基于任务的以及固定注意力头的,并列出了不同模型的实验对比结果,结果如表5、表6所示。

表5 不同结构融合方式在CosmosQA验证集上的准确率

表6 不同结构融合方式在CommonsenseQA验证集上的准确率
(1) 基于输入的动态融合
预训练语言模型在提取序列特征时,能有效融合上下文信息,得到考虑上下文的特征向量。在动态融合时,由于文本特征向量融合整个文本序列的语义特征,因而选择对特征向量进行线性变换,来生成融合多种结构关系矩阵的权值。
基于输入的结构融合,通过对RoBERTa层输出的词向量表示进行平均池化后,经过线性层后得到动态融合的权重。其中,Layer-wise代表对于每一层Transformer网络使用不同的动态融合参数;Head-wise代表对于同一层Transformer网络中的不同自注意力头使用不同的动态融合权重;Layer &Head wise代表对每一层Transformer网络中的不同自注意力头,使用不同的动态融合参数。
在CosmosQA数据集上,Layer-wise方法将PDT模型在验证集上的准确率提高到72.09%,在基线模型的基础上准确率提升了1.74个百分点;Head-wise方法使PDT模型在验证集上的准确率提升到70.75%,相较于基线模型提高了0.4个百分点; Layer &Head-wise方法使PDT模型在验证集上的准确率下降到69.41%,整体下降了0.94个百分点。
在CommonsenseQA数据集上,Head-wise方法使得PDT模型在验证集上的准确率提升到68.80%,相较于基线模型提升了0.41个百分点;Head-wise方法使PDT模型在验证集上的准确率下降到67.98%,在基线模型的基础上下降了0.41个百分点;Layer &Head-ise方法使PDT模型在验证集上的准确率下降到68.06%,整体下降了0.33个百分点。
上述结果表明,在两种数据集中,Layer-wise方法通过在不同层上为不同的结构关系设置不同的权值,从而动态融合多种结构关系,模型效果提升较为显著。其中的权值反映了在每一层中区分出每种结构的重要性。Head-wise方法在两种数据集上取得不一样的效果,也表明在不同的注意力头上应用不同的结构关系,模型在不同数据集上效果不稳定。Layer &Head-wise在两种数据集上准确率都明显下降,这也表明使用更多的参数来学习动态融合权重,并不能提高模型的性能。
该结果也表明,基于不同层的结构融合方式,在构建文本中常识关系时,可针对特定的样本提取出更有效的常识信息。
(2) 基于任务的动态融合
为验证动态融合权值的重要性,本文尝试随机生成权值来融合多种结构关系矩阵,利用标准正态分布来随机生成权值。该权值与文本序列特征无关,从而对比基于输入向量特征生成动态融合权值的有效性。
基于任务的动态融合,在整个数据集上自定义动态融合权重,而非在每个样本上定义权重。具体来说,动态融合权重α是一个维度为4的需要学习的参数,并且有∑tαt=1。基于任务的动态融合权重α不依赖于某个具体的样本输入。因此注意力过程仅仅与任务相关。
在CosmosQA数据集中,基于任务的动态融合模型,在验证集上的准确率相对于基线模型都存在不同程度的下降,该结果也表明,随机生成的自定义参数并不能为所有的样本选择出合适的权值,来融合多种结构知识。
(3) 固定自注意力头的结构融合
为对比选择性地利用不同结构知识的重要性,本文还尝试在注意力机制中应用固定的结构关系矩阵,而非动态融合多种结构关系矩阵,所有样本都采用固定的注意力矩阵。
具体来说,固定自注意力头的结构融合,在结构融合过程中,模型不需要额外生成动态融合权重α。相反,该方法为每一层Transformer层中不同的注意力头分配不同类型的结构关系矩阵。给定邻接矩阵M,M中包含四种不同的矩阵{M1,M2,M3,M4},我们在每一层Transformer网络中的不同的自注意力头上分配不同的结构信息。即将结构关系矩阵M1应用到第1~3个自注意力头{H1,H2,H3}上,将矩阵M2应用到第4~6个自注意力头{H4,H5,H6}上,将矩阵M3的应用到第7~9个自注意力头{H7,H8,H9}上,将矩阵M4的应用到第10~12个自注意力头{H10,H11,H12}上。
在固定自注意力头的模型实验中,两个数据集上模型的准确率相对于最优结果都存在不同程度的下降。该结果也表明将所有结构知识若不加区别地施加到所有的注意力头上,模型并不能够充分利用不同的结构信息。由于该模型的准确率还低于仅仅依赖常识结构关系的准确率,即该结构并未考虑到每种结构关系之间的重要性,从而模型准确率显著降低。
3.5 可视化分析
3.5.1 结构可视化
为衡量不同结构知识在常识问答中的作用,尝试将PDT模型的常识推理模块中的某些注意力可视化,以图2实例的情绪词关系和常识关系为例来证明PDT模型的效果。
(1) 情绪词关系
为验证情绪词关系在常识问答中的效果,将图2实例的情绪词关系矩阵输入到RoBERTa-base+3 Transformer基线模型中,并挑选Transformer结构中的最后一层的第5个自注意力头的注意力权值进行可视化,可视化结果如图3所示。其中图3(a)表示未引入情绪词关系时的注意力可视化结果,图3(b)表示引入情绪词关系后的注意力可视化结果。
图3(b)的结果也表明,引入情绪词结构知识后,PDT模型能够捕捉到home、time和early等单词之间的情绪词关系,从而引导模型选择正确的答案,辅助常识问答。
(2) 常识关系
为证明常识关系在常识问答中的重要性,也将图2中实例的常识关系输入到基线模型中,并挑选Transformer结构中最后一层的第11个注意力头的注意力权值进行可视化,可视化结果如图4所示,图4(a)表示未引入常识关系的注意力可视化结果,图4(b)表示引入常识关系的可视化结果。

图4 常识关系的注意力可视化结果
图4(b)中的结果也反映出,引入常识关系,PDT模型能够捕捉到问题中的home、evening等四个单词与答案中的单词之间的常识关系,并通过常识关系图进行常识推理,进而辅助模型选择正确的答案。
3.5.2 动态融合可视化
在常识问答任务中,为验证PDT模型中的动态融合方式的影响,尝试在基于输入的动态融合方式中,将图2中的实例输入到PDT模型中,不同结构知识的关系矩阵和动态融合的权值如图5所示。动态融合后,Transformer最后一层的动态掩码矩阵如图6(a)所示,第9个注意力头的注意力权值如图6(b)所示。

图5 不同结构关系矩阵的权值对比

图6 动态融合后的掩码矩阵和注意力权值
图中结果表明,不同的结构知识对于某个问答样本的重要性不同。在该实例中,常识关系和情绪词联系更有助于辅助回答该问题,模型亦为其分配较大了的权值,而其余结构关系的权值相对较低。通过不同的动态融合权值,PDT模型可为不同的样本分配最有效的结构知识信息。
4 结论
在本文工作中,我们提出了PDT模型,将语言学中被广泛研究的结构化信息,视为额外知识融入到语言模型中。对于常识问答任务,诸如语法依赖树和常识知识图等结构信息,可以提供辅助问答的有效信息。通过动态融合这些结构信息,PDT模型可充分利用结构知识,使得当前的深度语言模型有稳定的提升。本文还证实了将传统的语言学结构信息与当前的深度神经网络结合的重要性,为以后的研究提供了参考思路。未来工作中,我们还将探索引入更多元化的结构信息,训练深度神经网络来动态融合这些结构,并研究大量结构信息如何改善当前的深度模型性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
文苑(2020年11期)2020-11-19
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
数学物理学报(2017年5期)2017-11-23
中国眼镜科技杂志(2017年10期)2017-07-10
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
河南电力(2015年5期)2015-06-08
新课程学习·中(2013年3期)2013-06-14
