
词性信息在神经机器翻译中的作用分析
2023-02-04 09:26郑一雄朱俊国余正涛
中文信息学报 2023年12期
郑一雄,朱俊国,余正涛
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650000;2. 昆明理工大学 云南省人工智能重点实验室,云南 昆明 650000)
0 引言
随着深度学习的发展,神经机器翻译模型在各种翻译任务上都取得了卓越的成效。其中,Transformer模型[1]是目前使用最广泛的神经翻译模型。Transformer模型与其他神经机器翻译模型的最大区别在于它完全基于注意力机制。但由于注意力机制的工作原理尚不明确,Transformer模型仍是一个“黑箱”,无法直观理解它的工作机制,难以在原有模型的基础上进一步提升翻译质量。因此,本文主要针对Transformer模型中注意力节点在机器翻译过程中的作用进行可解释性研究。
2015年由Bahdanau等人[2]首次将注意力机制应用在神经机器翻译领域,2017年由Vaswani等人[1]提出了完全基于注意力机制的Transformer模型。虽然基于注意力机制的翻译模型已经取得了很好的翻译性能,但研究者难以用人类可理解的方式解释其工作机制。针对这一问题,目前已有研究者对注意力机制的可解释性开展了相关研究,如Bahdanau[2]、Serrano[3]等人研究了注意力权重相对于源语言单词和目标语单词之间的关系,Vig[4]、Raganato[5]等人分析了Transformer模型中编码器自注意力节点关注的源语言的语言学信息,Michel[6]、Wang[7]等人分析了注意力节点与译文质量的关系。与过去的解释工作不同的是,本文的方法可以分析Transformer模型中各类型注意力节点关注的目标语的语言学信息,并通过屏蔽负作用节点的方法来提升模型的翻译性能。
本文利用屏蔽节点的方法,对已经训练好的翻译模型进行分析。主要方法是保持模型参数不变,分析屏蔽节点前后模型输出译文的变化情况,通过这种方法分别对Transformer模型内部的单节点和节点组合与译文中不同词性的词的关系进行分析。屏蔽注意力节点会导致模型输出的译文发生变化,根据这种变化就可以定量计算出注意力节点对各词性单词正确翻译的贡献程度,在此基础上就可以分析不同节点的重要程度,对节点进行针对性的选择和屏蔽,从而优化模型,在原有模型基础上进一步提高翻译质量。
本文分析了德语到英语和俄语到英语的Transformer翻译模型。实验结果表明,根据本文提出的方法计算得到的节点词性贡献度,可以选出各词性相关的负作用节点。通过屏蔽模型中负作用节点,相比原始模型,能够在newstest2020-deen测试集上提升机器翻译模型的BLEU值1.13,在newstest2020-ruen测试集上提升BLEU值0.89。
1 相关工作
目前,对注意力机制进行解释分析的方法主要有三类,分别是注意力权重法、探针法和节点屏蔽法。注意力权重法主要用注意力权重的大小来分析各注意力节点所关注的单词。Bahdanau等人[2]认为注意力权重的大小反映了各源语言单词对各目标语单词的联系程度。Serrano等人[3]也通过实验发现注意力权重可以反映各源语言单词对目标语单词的贡献程度。由于自注意力机制的作用是提取句子内各单词间的关系,Vig[4]、Manning[8]等人研究了Transformer模型的编码器的自注意力机制,用注意力权重来分析节点对源语言单词的关注情况,从而分析节点所关注的语言学现象。探针法的主要方法是保持Transformer模型编码器训练好的参数不变,在其后连接一个简单解码器进行各项语言学任务,通过语言学任务上的表现来衡量编码器各部分对源语言的语言学信息的学习情况。Raganato等人[5]使用探针法分析了Transformer模型中各编码层对于源语言句法信息和语义信息的学习情况。节点屏蔽法主要是根据屏蔽节点后BLEU值的变化情况来对节点进行分析。Michel等人[6]通过分析屏蔽注意力节点前后BLEU值的变化情况,发现有些注意力节点在翻译中的贡献程度较小,可以通过屏蔽这类节点来压缩模型和提升模型速度。
注意力权重法和探针法主要对Transformer模型的编码器自注意力节点和源语言的语言学现象进行分析,不能将解释工作和译文质量联系起来。节点屏蔽法主要研究屏蔽节点对BLEU值的影响,没有从语言学角度分析各节点的作用。本文提出的方法可以对Transformer模型中所有类型的注意力节点进行研究,分析各节点所关注的词性信息,并且在注意力节点和译文质量之间建立起联系,通过屏蔽对词性信息具有负面作用的节点来提升译文的翻译质量。
2 面向词性的翻译模型解释方法
2.1 Transformer模型
Transformer模型是一个序列到序列的神经机器翻译模型,由编码器和解码器组成。在Vaswani等人[1]提出的Transformer模型结构中,编码器由6个编码层组成,解码器由6个解码层组成。编码层主要由编码器自注意力层和前馈神经网络层组成,解码层主要由解码器自注意力层、编码器-解码器注意力层、前馈神经网络层组成。本文主要的研究对象是上述三种注意力层中的注意力节点。
Transformer模型与过去的神经机器翻译模型的最大差别在于,Transformer模型内部没有循环神经网络,而是完全由注意力节点构成的。自注意力层的主体为多头注意力,多头注意力由多个注意力节点的输出值拼接而成。Transformer模型处理一个句子时,首先根据词嵌入向量和注意力权重计算其Q、K、V向量,然后计算各注意力节点的输出。注意力节点输出值的计算如式(1)所示。
(1)
之后将层内所有注意力节点的输出值进行拼接,得到多头注意力输出值。其计算如式(2)所示。
其中,WO是每个注意力节点的权重,hi=Attention(Qi,Ki,Vi)。
2.2 节点屏蔽
本文主要将Transformer模型中的注意力节点作为研究对象,尝试理解Transformer模型中各注意力节点在翻译过程中的工作机制,分析Transformer模型中不同节点对于翻译各词性单词以及整体翻译质量的作用。屏蔽节点时,需要对计算多头注意力的方法进行调整。在将各注意力节点输出值合并为多头注意力前,将需要屏蔽的注意力节点的输出矩阵置为0矩阵,式(2)中的每个hi的计算方式进行修改如式(3)所示。
其中,φi是屏蔽参数。对于注意力节点hi,需要屏蔽hi时将φi置为0,不需要屏蔽hi时将φi置为1。屏蔽节点组时,则需要对屏蔽的各个节点同时进行屏蔽操作。
2.3 节点词性贡献度的计算
本文用节点词性贡献度来反映屏蔽节点对各词性单词的翻译准确率的影响情况,从而分析节点对各词性单词正确翻译的贡献程度。本文分别计算了单节点词性贡献度和节点组词性贡献度,其中计算单节点词性贡献度的方法共三步:
第一步是对参考译文用stanfordCoreNLP进行词性标注,依据是宾州树库(Penn Treebank)中的词性类型。宾州树库中,一些词性被拆解为词性子类,如形容词被拆解为一般形容词、形容词比较级、形容词最高级,本文将名词、动词、形容词、副词的单词各自进行聚类,并统计出参考译文中各词性单词的总词数,参考译文中词性p的总词数记为totalp,ref。
第二步是不屏蔽节点,使用完整模型进行翻译,用模型输出的译文与参考译文进行比较,获得每种词性正确翻译的总词数。完整模型的输出译文中词性p的正确翻译的总单词数的计算如式(4)所示。
其中,对于参考译文中第j个句子中词性p的第i个不重复单词wi,统计其在参考句子中出现的次数nwi,ref,模型输出的翻译结果中出现的次数记为nwi,model。每个句子中,词性为p的不重复单词共有m个,数据集上共有s个句子。
第三步是分别屏蔽每个节点,用式(4)的方法计算每种词性正确翻译的总词数,统计屏蔽节点h后模型输出译文中正确翻译的词性p的总单词数,如式(5)所示。
其中,对于参考译文中第j个句子,词性p的第i个不重复单词wi,统计其在参考句子中出现的次数nwi,ref,wi在屏蔽节点h后模型输出的译文对应句子中出现的次数为nwi,maskh。每个句子中,词性为p的不重复单词共有m个,在数据集上共有s个句子。最终计算得到节点h对于词性p的节点词性贡献度,如式(6)所示。
其中,totalp,ref指参考译文中词性p的单词总数。节点词性贡献度difp,h表示屏蔽节点h后,词性p单词的翻译准确率的变化情况。difp,h反映了节点h对于词性p单词正确翻译的贡献程度。difp,h>0表示屏蔽节点h后,词性p单词的翻译准确率上升,说明节点h对词性p单词的正确翻译具有负面作用,difp,h越大,该节点的负面作用越大,屏蔽该节点后词性p单词的翻译准确率上升越多,将difp,h>0的节点记为负作用节点;difp,h<0表示屏蔽节点h后,词性p单词的翻译准确率下降,表示节点h对词性p单词正确翻译具有正面贡献,difp,h越小,该节点的正面贡献越大,屏蔽该节点后词性p单词的翻译准确率下降较多,将difp,h<0的节点记为正贡献节点。
计算节点组词性贡献度的方法是根据difp,h对所有节点的贡献进行排序,分别选出对于各词性difp,h最大和最小的50个节点作为高贡献节点组和负作用最大节点组。对于词性p相关的节点个数为n的高贡献节点组记为Grouphigheffect,n、Grouppositive effect,p,n,负作用最大节点组记为Grouphigheffect,nGroupnegative effect,p,n。对于高贡献节点组,按照difp,h从小到大的顺序,由0到50每次递增10个节点进行批量屏蔽;对于负作用最大节点组,按照difp,h从大到小的顺序,由0到50每次递增10个节点进行批量屏蔽。具体的节点组实验与分析见3.3。当屏蔽节点个数为n时,词性p单词的翻译准确率的变化程度记为节点组词性贡献度difGroup, p, n,其计算如式(7)所示。
3 实验与分析
3.1 实验设置
本文主要使用Facebook在2019年发布的transformer.wmt19.de-en和transformer.wmt19.ru-en预训练翻译模型。两个翻译模型均有编码层和解码层各6层,每层有16个注意力节点。预处理使用moses进行分词,使用subword_nmt进行BPE处理。两个翻译模型在解码时均设置beam size为5,batch size为8,最大解码长度为200,长度惩罚系数为1。最终使用sacreBLEU计算BLEU值。
本文将newstest2019-deen和newstest2019-ruen作为开发集进行单节点分析。根据单节点的节点词性贡献度选出各词性的相关节点组,将newstest2020-deen和newstest2020-ruen作为测试集,进行屏蔽节点组的分析和提升译文质量的实验。transformer.wmt19.de-en预训练翻译模型在newstest2020-deen数据集上的BLEU值为30.47,transformer.wmt19.ru-en预训练翻译模型在newstest2020-ruen数据集上的BLEU值分别为32.7。本文主要对目标语进行分析,故统计数据集参考译文中各词性单词的数量,如表1所示。

表1 实验数据依据词性的分布情况
3.2 对单节点的分析
本文主要使用节点词性贡献度difp,h来反映节点h对于正确翻译词性p的单词的贡献程度。对difp,h的计算方法如前文2.3所述。difp,h>0表示屏蔽节点h后,词性p单词的翻译准确率上升,表示节点h对词性p单词正确翻译具有负面作用,difp,h越大表示负面作用越大;difp,h<0表示屏蔽节点h后,词性p单词的翻译准确率下降,表示节点h对词性p单词正确翻译具有正面贡献,difp,h越小表示正面贡献越大。
对于每种词性,根据difp,h绘制了热力图,图1展示了在newstest2019-deen数据集上,名词、动词、形容词、副词、介词、限定词六种主要词性的节点词性热力图。该热力图反映了屏蔽模型单个节点对于翻译该词性单词的影响情况。在热力图中,图的纵坐标为层序号,表示节点所在的注意力层。0~5表示编码器自注意力层的1~6层,6~11表示解码器自注意力层的1~6层;12~17表示解码器的编码器-解码器注意力层的1~6层。横坐标为层内节点序号,层内节点序号表示节点在层内的序号,用0~15表示一层内的16个注意力节点。热力图每个格子的颜色深浅反映了该节点的节点词性贡献度的大小,格子上的数值为节点词性贡献度的百分数。


图1 屏蔽单节点对于各词性单词翻译准确率的影响
根据节点词性贡献度的正负将节点划分为正贡献节点和负作用节点。difp,h<0的节点为正贡献节点,difp,h的值越小,节点颜色越浅,节点h对于正确翻译词性p单词的贡献越大;difp,h的值越大,节点颜色越深,表示节点h对于正确翻译词性p单词的贡献越大。difp,h>0的节点为负作用节点,节点颜色较深,表示节点h对于翻译词性p的单词有负面作用,屏蔽该节点会使词性p的单词的翻译准确率提高。
节点词性热力图反映了每种词性相关的注意力节点在模型内部的位置分布情况、每种词性相关节点的数量情况以及各注意力节点对于正确翻译某种词性单词的贡献程度。为了便于比较各词性间的差异,各词性热力图的色条使用了相同的上下界。可以看出有少量节点对于多种词性信息都有较大贡献,如编码器第6层第1个节点,即热力图中坐标为(0, 5)的节点,在各热力图中颜色都较浅,说明该节点对六种词性单词的正确翻译都有较大贡献;有些节点对于多种词性都有负面作用,如编码器自注意力层第6层第12个节点,即图中坐标为(11, 5)的节点,在各热力图中颜色都较深,说明该节点对六种词性单词的正确翻译都有负面作用;而大部分节点对于某些词性具有正面贡献,对另外一些词性具有负面作用。
对于不同词性,贡献较大节点的数量是不同的。名词作为出现频率最高的词性,对于名词的翻译有正面贡献的节点较多。此外,有些注意力节点对于多种词性信息都有贡献,这说明对于一个节点,不应该明确地将其划分为是否关注某种词性,而应该通过节点词性贡献度定量地分析节点对于各词性单词正确翻译的作用。
从热力图颜色的深浅可以看出,对于形容词、副词来说,颜色较深或较浅的节点较多,即屏蔽单个节点对词性单词翻译准确率影响较大的节点较多;而对于名词、动词等词性来说,颜色较深或较浅的节点数较少,即屏蔽单节点对词性单词翻译准确率影响较大的节点较少。出现这种现象的原因可能是屏蔽单节点对词频较低词性的单词翻译准确率影响较大。
另外,由热力图深浅可以看出三种注意力节点的深浅有一定差异。通过进一步对比deen和ruen翻译模型上的实验结果,发现Transformer中编码器自注意力、解码器自注意力和编码器-解码器注意力三种注意力节点的词性信息贡献度有一定区别。图2对比了deen和ruen的翻译模型在动词上的情况。图中横坐标为层序号,表示节点所在的注意力层,0~5表示编码器自注意力层的1~6层,6~11表示解码器自注意力层的1~6层,12~17表示编码器~解码器注意力层的1~6层。纵坐标为各层的动词正贡献节点的节点词性贡献度的绝对值之和。两个模型上,均发现有0~5层和12~17层的值相对较大、6~11层的值相对较小。说明两个模型上解码器自注意力节点对动词翻译的贡献相对较小,另外两种注意力节点对动词翻译的贡献相对较大。实验结果显示,两个模型在其他词性上也有解码器自注意力节点贡献相对较小,另外两种类型的注意力节点贡献相对较大的现象,这也与Michel等人[6]、Wang等人[7]的研究结果相一致。
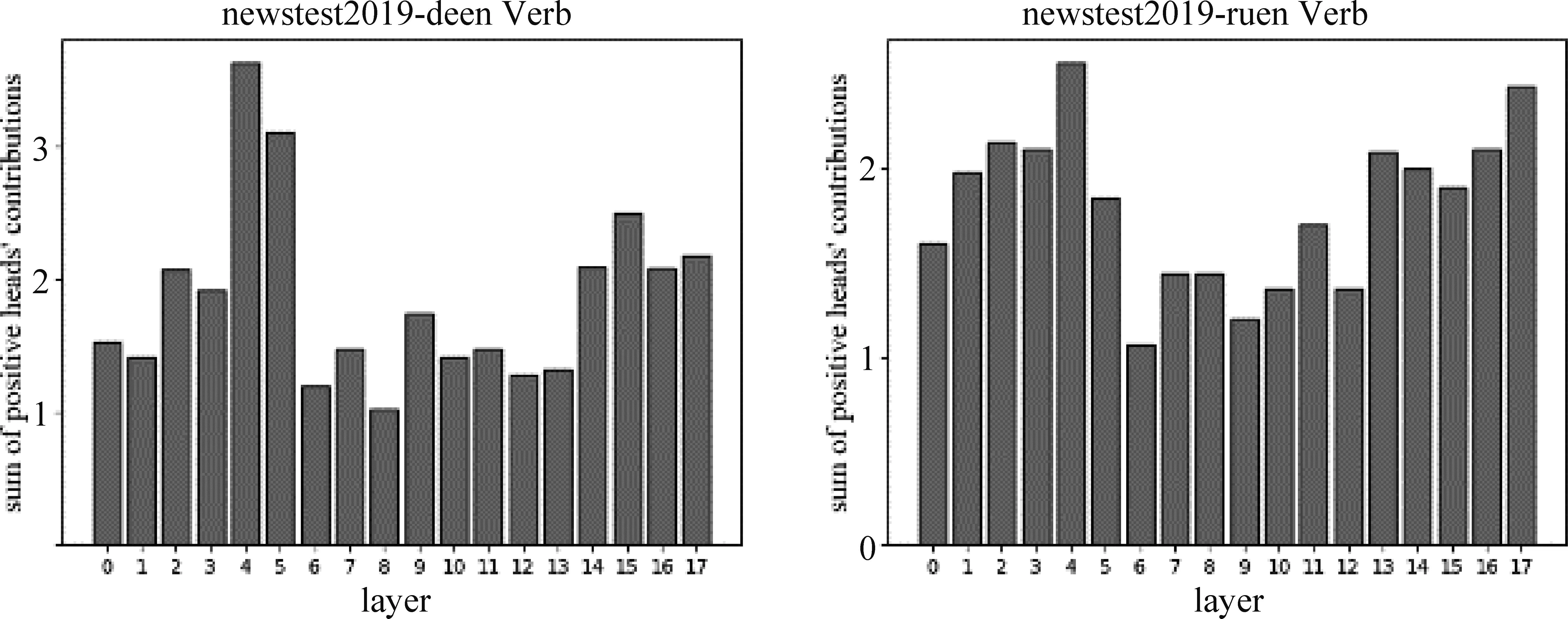
图2 不同类型注意力节点对动词的词性贡献程度
3.3 对节点组的分析
将newstest2019-deen和newstest2019-ruen数据集作为开发集,在两个翻译模型上计算各节点的节点词性贡献度,其中两个模型均有288个注意力节点。对于每种词性,按照节点词性贡献度对所有节点进行排序,选出贡献最大和负作用最大的节点各50个分别作为该词性的高贡献节点组和负作用最大节点组,并以随机屏蔽节点组作为对照试验,对节点组进行批量屏蔽,将newstest2020-deen和newstest2020-ruen作为测试集,统计屏蔽节点组后译文的变化情况。两个翻译模型的实验结果显示负作用最大节点组中有部分节点对于词性信息的负面作用较大,屏蔽这部分节点可以提升译文质量。
3.3.1 节点组与词性信息
对于各词性,分别在开发集newstest2019-deen和newstest2019-ruen上根据节点词性贡献度选出对于两个翻译模型贡献最大和负面作用最大的各50个节点作为词性p的高贡献节点组和负作用最大节点组,由0到50每次递增10个节点进行批量屏蔽。根据3.2节中计算得到的节点词性贡献度,发现除名词外,其他词性的正贡献节点和负作用节点个数都超过50个,而名词有22个负作用节点和6个无影响节点(节点词性贡献度为0的节点)。因此,名词的负作用最大节点组选取了名词的22个负作用节点、6个无影响节点和22个正面贡献最小的正贡献节点。分别在两个测试集上计算高贡献节点组和负作用最大节点组在屏蔽前n个节点时词性p的节点组词性贡献度difpositive,p,n和difnegative,p,n。另设随机屏蔽组作为对照组,屏蔽了两个实验组相同的节点数,进行10次随机屏蔽实验,计算各词性翻译准确率变化情况求平均值,获得随机屏蔽组贡献度difstochastic,p,n。
newstest2020-deen的实验结果如图3所示。其中横坐标表示屏蔽的节点的个数n,纵坐标表示对应的节点组词性贡献度。mask positive heads折线表示屏蔽高贡献节点组Grouphigheffect,n的情况,mask negative heads折线表示屏蔽负作用最大节点组的情况,mask heads stochastically折线表示随机屏蔽对照组的情况。


图3 屏蔽词性相关节点组对词性单词翻译准确率的影响
由图3可以看出,对于每种词性,屏蔽高贡献节点组时,该词性单词的翻译准确率会显著下降;屏蔽负作用最大节点组时,该类词性的翻译准确率多数呈先小幅提升后小幅下降的形态,随机屏蔽对照组的下降程度介于两者之间。
3.3.2 节点组与BLEU值
图4反映了在newstest2020-deen上屏蔽各词性相关的节点组对BLEU值造成的影响。其中横坐标表示屏蔽节点的个数n,纵坐标表示屏蔽词性p相关的n个节点时,BLEU值的变化情况。mask positive effect heads折线表示屏蔽高贡献节点组的情况,mask negative effect heads折线表示屏蔽负作用最大节点组的情况,mask heads stochastically折线表示随机屏蔽对照组的情况。


图4 屏蔽词性相关节点组对于译文BLEU值的影响
对于实验选取的六种词性而言,屏蔽相关节点组后,可以看出BLEU值和相关词性的翻译准确率变化情况在折线图上具有相似的形态。对于每种词性,模型中都有部分节点于其正确翻译具有正面贡献,屏蔽这部分节点会使该词性的翻译准确率和译文整体的翻译质量显著下降,可以说这部分节点对于该词性单词的正确翻译具有较大的贡献,包含了较多的语言学知识,对于翻译模型较为重要。
在newstest2020-deen上,屏蔽限定词、介词的负作用节点组后, BLEU值先有微小的提升,然后下降,而屏蔽名词、动词的负作用节点组时,BLEU值较屏蔽其他词性负作用节点组时有较大的提升。可以看出模型中有部分节点对于模型翻译性能具有较大的负面作用,屏蔽这类节点可以使模型翻译质量提升较多。
屏蔽负作用节点组对BLEU的影响如表2所示。从表2可以看出:

表2 屏蔽负作用节点组对BLEU的影响
对于transformer.wmt19.de-en预训练翻译模型,在newstest2020-deen上,屏蔽对于名词负面作用最大的30个节点时BLEU值提升最多,由30.47提升至31.60;屏蔽对于动词负面作用最大的20个节点时BLEU值提升最多,达到了31.40。对于transformer.wmt19.ru-en在newstest2020-ruen上,屏蔽名词负作用最大的30个节点时,BLEU值提升最多,由32.70提升至33.59。
在此基础上, 使用组合屏蔽多种词性相关节点组的方法进行了实验,实验结果发现,在transformer.wmt19.de-en模型上,效果最好的是同时屏蔽30个名词负作用节点和20个动词负作用节点,这种组合方法较屏蔽其他词性节点组合而言,对模型翻译性能提升最多,可以使newstest2020-deen的BLEU提升至32.15,这种方法在transformer.wmt19.ru-en模型上使newstest2020-ruen的BLEU值提升至33.71。
由图4可以看出,屏蔽不同词性相关节点组对翻译性能的影响不同。当屏蔽节点个数较多时,不同词性相关节点的重合程度较高,屏蔽节点个数较少时,不同词性相关节点重合程度较低。为了减少节点重合的影响,以屏蔽10个正面贡献最大节点为例,可以看出屏蔽名词相关节点组使BLEU值下降最多,屏蔽动词、限定词、介词相关节点组使BLEU值下降程度次之,屏蔽副词使BLEU值下降较少。这种情况可能是由于各词性单词的词频不同,由表1可以看出,对于newstest2020-deen数据集,在六种词性中,名词的词频最高,动词、限定词、介词的词频中等,形容词、副词的词频较低,而BLEU值的计算机制决定了屏蔽词频越高的词性相关节点对BLEU值的影响越大。
另外,对于限定词、介词和从属连词,由于其正确翻译对于上下文信息要求较高,屏蔽节点个数较少时对BLEU值的影响相比其他词性较小,而屏蔽节点个数较多时,对BLEU值影响相比其他词性较大。由图4中可以看出,对于限定词、介词和从属连词,屏蔽10个负作用最大节点时,其BLEU值下降程度低于名词和动词,而屏蔽50个负作用最大节点时,其BLEU值下降程度高于名词和动词。
3.3.3 屏蔽负作用节点以改正翻译错误
对于某些词性,模型中存在一些节点对于该词性单词的正确翻译具有负面作用,屏蔽这类节点可以提高该词性单词翻译准确率并改正一些翻译错误。下面列举两个来自newstest2020-deen的典型句,通过屏蔽由newstest2019-deen选出的名词负作用最大的10个节点改正了名词翻译缺失的翻译错误,从而提升了翻译质量。
典型句1:
参考译文:TheBritishPrimeMinisterJohnson has sharp criticism for the ‘capitulation act’ ratified by parliament.
原模型译文:Mr.Johnson has been a fierce critic of the surrender bill passed by Parliament.
屏蔽名词负作用节点组译文:BritishPrimeMinisterMr.Johnson has been a fierce critic of the surrender bill passed by Parliament.
典型句2:
参考译文: Although extremely practical, inductive technologyviaQistandardshould not be used.
原模型译文: Inductive technology is extremely practical, but should not be used yet.
屏蔽名词负作用节点组译文: Inductive technologyviaQi-standardis extremely practical, but should not be used yet.
可以看出,通过屏蔽10个对名词负作用最大节点,翻译模型将典型句1中缺失的British PrimeMinister和典型句2中缺失的via Qi standard正确翻译出来,改正了名词翻译缺失的错误。
4 结论
目前Transformer模型在神经机器翻译中被广泛使用,但它对于使用者而言仍是“黑箱”模型,这使得研究者难以在原有模型的基础上进一步提升翻译质量。针对Transformer模型,本文主要研究了其注意力节点和词性信息的关系,通过屏蔽节点的方法,分别对单节点和节点组进行分析。由实验结果发现部分节点对模型的翻译性能具有负面作用,屏蔽这些节点可以在测试集上提高译文质量。未来工作中,我们计划从其他语言学信息的角度,进一步解释神经机器翻译模型的工作机制。
猜你喜欢
好日子(2022年3期)2022-06-01
湘潮(上半月)(2021年10期)2021-12-02
公民与法治(2020年15期)2020-09-25
意林·少年版(2020年23期)2020-01-15
石河子大学学报(哲学社会科学版)(2019年3期)2019-07-27
中国生物医学工程学报(2019年4期)2019-07-16
知识经济·中国直销(2018年1期)2018-01-31
电线电缆(2017年5期)2017-10-18
商周刊(2017年6期)2017-08-22
厦门理工学院学报(2016年1期)2016-12-01
