
类脑处理器异步片上网络架构
2023-01-30 10:23杨智杰彭凌辉徐炜遐
计算机研究与发展 2023年1期
杨智杰 王 蕾 石 伟 彭凌辉 王 耀 徐炜遐
(国防科技大学计算机学院 长沙 410073)(yangzhijie@nudt.edu.cn)
随着现代微处理器面积逐步增加,传统的总线架构越来越难以满足计算单元之间的通信需求[1-2].这是因为较长的线路负载和电阻导致了信号传播缓慢的问题.片上网络(network-on-chip, NoC)具有可扩展性高、吞吐量高和通用性高的特点,在先进微处理器中已经被广泛应用[3-5].然而,使用同步电路实现的NoC仍然面临在处理器上生成全局时钟树的问题.随着芯片规模的不断增大,采用全局时钟树的设计越来越难以实现时序收敛并且存在时钟倾斜问题[6].因此采用异步NoC构建全局异步局部同步(global asynchronous local synchronous, GALS)架构成为了一种潜在的解决方案.GALS架构具有多种优势,其功耗较同等功能和相似配置的同步设计更低、能效更高、鲁棒性更好[7],并且有限的异步设计使其可以使用现有的商用电子设计自动化(electronic design automation, EDA)工具进行实现和验证[8].
类脑处理器通过模拟大规模的神经元活动行为完成特定的智能任务,较传统深度学习处理器而言,它具有更高的能效,因此近来得到了长足的发展.由于NoC的可扩展性和高吞吐量,在多核类脑处理器架构中多采用NoC的方式实现神经元核间的互连通信.许多这方面的工作包括:Shenjing[9]类脑处理器和比利时鲁汶大学的MorphIC[10]类脑处理器都采用同步NoC设计;美国斯坦福大学的Neurogrid[11]类脑处理器和瑞士苏黎世联邦理工的DYNAPs[12]类脑处理器都采用异步NoC设计构建数模混合系统.其余的大部分相关工作诸如美国IBM公司的TrueNorth[4]类脑处理器、美国Intel公司的Loihi[5]类脑处理器和英国曼彻斯特大学的SpiNNaker[13]类脑处理器等,都采用异步NoC设计构建GALS架构的类脑处理器.其中的原因有2个:1)比起同步NoC,异步NoC的握手通信与大脑的信息传递机制更加相似、更具有鲁棒性;2)基于异步NoC构建的GALS类脑处理器在处理具有稀疏特点的类脑应用流量时,能够展现出更低的能量消耗.用异步NoC设计在一定程度上突破了功耗墙并且使得模拟更大规模的神经元活动行为成为可能.
然而,采用异步NoC构建的GALS类脑处理器设计也面临一些挑战.首先,要保证异步NoC链路的高吞吐量以满足类脑应用猝发通信的需求,一般需要采用接近同步设计的、比4段握手数据打包协议的性能和能效更高的2段握手数据打包协议.然而,基于数据打包协议的异步通信需要在链路上进行精准的延迟匹配才能保证功能的正确性,这对设计者和EDA工具提出了较高的要求.其次,由于亚稳态的存在,使得同步域和异步域之间的同步成为阻碍功能正确的困难,给测试和验证带来了挑战.
在本文中,我们针对多核类脑处理器的通信需求,提出了一个用于GALS类脑处理器核间片上互连通信的NoC架构——NosralC.为了利用异步设计带来的功耗和鲁棒性优势,同时最大程度减少异步逻辑对整体设计带来的各种挑战,在NoC设计中,路由器采用同步电路实现,而链路采用2段数据打包的异步握手方式实现.这样的实现方式使得整个设计中的异步逻辑占比较低,更接近同步设计,因而对测试和验证更加友好.同时,在NosralC中还解决了同步域与异步域数据交换中存在的亚稳态问题,并正确匹配了异步链路间的延迟,保证了设计功能的正确性.与相关工作相比,NosralC的不同之处在于其仅链路被设计为异步的,而大多数相关工作例如IBM公司的TrueNorth类脑处理器和Intel公司的Loihi类脑处理器则采用完全异步电路实现的路由器和链路来构建NoC.NosralC展示了异步NoC相比其同步同等设计基线,在多个类脑应用数据集下均具有显著的功耗和能效优势,同时不会带来较大的现场可编程门阵列(field programmable gate array, FPGA)片上资源开销以及额外的性能开销.因此,NosralC可以作为一种更具优势的方案,用于多核类脑处理器中神经元核的片上互连通信.
本文的主要贡献有2个方面:
1) 提出了一个异步NoC架构——NosralC,用于实现多核GALS类脑处理器的核间片上互连通信.NosralC的链路是采用异步电路实现的,基于2段握手数据打包协议,路由器是采用同步电路实现的.
2)在4个类脑应用数据集上对NosralC及其同步同等设计基线进行了功耗、能效、资源占用和性能等方面的对比,展示了在类脑处理器的片上互连通信设计中,采用NosralC的结构构建GALS的类脑处理器会更加具有优势.NosralC在FPGA上进行了设计验证,并证明了其可实现性.
实验表明,NosralC较拥有同等功能和相似配置的同步设计,在免费语音数字数据集(free spoken digital dataset, FSDD)[14]、类脑德州仪器数字数据集(neuromorphic Texas Instruments digits, NTI-DIGITS)[15]、动态视觉传感器 128 手势数据集(dynamic vision sensor 128 gesture dataset, DVS128 Gesture Dataset)[16]、 类 脑 混 合国家标准和技术研究所数据库(neuromorphic mixed National Institute of Standards and Technology database,NMNIST)[17]这4个类脑应用数据集下展现出了37.5%~38.9%的功耗降低、5.5%~8.0%的平均延迟降低和36.7%~47.6%的能效提升,同时不带来较大(小于6%)额外资源开销和性能开销(吞吐量降低0.8%~2.4%).
1 背景和相关工作
本节将介绍本研究相关的背景知识,包括异步电路、异步NoC和类脑处理器等的相关工作.
异步电路通过握手协议的方式实现电路的控制.与同步电路不同,它无需采用统一的时钟信号进行控制.在这种控制方式下,电路状态的变化仅由外部输入的变化引起,因此使得其相较于同步电路具有低功耗的优势.除此之外,不使用统一的时钟又使得其能够克服大时钟网络的时序收敛难和时钟倾斜问题.
1.1 异步电路的握手与数据传输
异步握手协议定义了异步模块在通信时的接口信号时序,保证异步电路各个组件之间的数据流动并且不发生冲突.异步握手协议主要包括2类:4段握手协议和2段握手协议.
如图1所示是4段握手协议.该协议是基于电平的,只有高电平表示控制信号的请求和应答.4段指的是通信动作的次数.4段握手协议的缺点是多余的归零翻转造成了不必要的时间和能量的损耗.
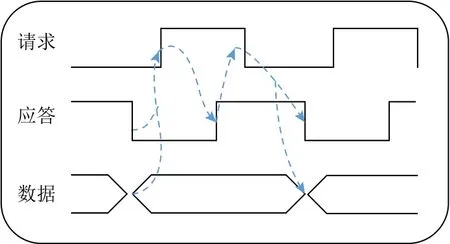
Fig.1 Four-phase handshake protocol图1 4段握手协议
图2所示的是2段握手协议.在2段握手协议中,请求和应答信号使用信号线上的电平翻转沿表示,每次翻转都代表1次信号事件.因此,2段握手协议比4段握手协议电路速度更快、传输速率更高,适合需要高性能的设计场景.
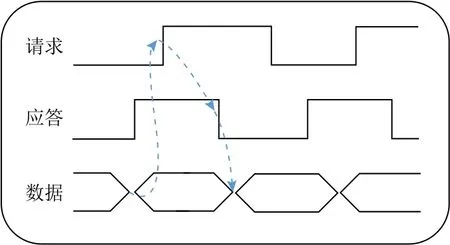
Fig.2 Two-phase handshake protocol图2 2段握手协议
然而,由于缺少统一的时钟进行控制和同步,异步电路中的数据传输需要解决控制通路和数据通路的延迟匹配问题,以保证数据在传输时的正确性.异步电路的数据传输方式有2种:一种是握手信号和数据信号分开的方式;另一种是将握手信号编码到数据信号中一同传递的方式.
如图3所示是单轨数据编码.该编码方式又被称为数据打包编码.在这种方式中,1个数据线传输1 b数据,发送方和接收方通过额外的请求和应答信号完成握手.基于这种方式实现的异步电路可以得到和同步电路相当的面积,而且可以使用传统的同步电路EDA工具实现.但其挑战在于必须满足异步电路的请求信号的传输延迟不小于对应的数据通道传输延迟的要求,否则将发生错误.因而,采用该方式常常需要相应地对请求信号和数据通道信号进行精准的延迟匹配,以保证功能的正确性.
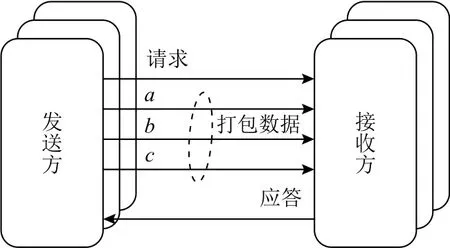
Fig.3 Single-rail data coding图3 单轨数据编码
如图4所示是双轨编码,该编码方式又被称为延迟无关的编码方式.因为这种方式使得接收方能够从传送的数据中检测出“完成”编码标记而不需要请求信号.但是双轨编码比单轨编码占用更多的电路面积、带来更高的功耗并且传输速率也更低.
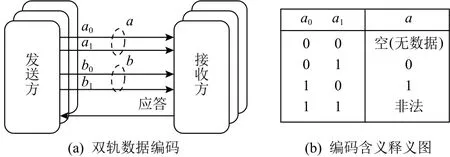
Fig.4 Two-rail data coding图4 双轨数据编码
1.2 异步NoC
NoC 是片上系统(system-on-chip, SoC)的一种通信架构,它的概念在2001年由Benini等人[18]提出,而其发展则由工业界不断推动.从美国Sun公司的8核处理器UltraSPARC T1的交叉开关互连网络[19],到美国Tilera公司的64核处理器TILE64的2维Mesh互连网络[20],NoC已逐渐成为多核SoC片上互连的主流通信架构.NoC包括计算和通信2类节点,有效实现了计算与通信的分离.与传统的总线及交叉开关互连结构相比,NoC具有高带宽、高可扩展性和高可重用性的优势.
基于异步NoC的处理器主要有GALS和全异步2种实现方式.其中GALS的设计方法除了能够克服同步设计中全局时钟树时序难以收敛的问题,还能够保持一个大部分设计是同步设计的设计流程,便于使用现有成熟的EDA工具进行设计和实现.下面列举学术界对异步NoC的相关工作.
CHAIN[21]是曼彻斯特大学设计的一款基于延迟无关的异步模型的点对点互连架构.在0.18 μm工艺下,每个链路可以达到1 Gbps的吞吐量.QNOC是Fakhri[22]提出的一款能够提供多服务级别和保证服务质量的2维Mesh结构的异步NoC,它采用4段数据打包协议,支持虫孔路由的流控机制.在0.18 μm工艺和每个 flit为 8 b的配置下,能够达到 1.72 Gbps的吞吐量.MANGO[23]是一款能够提供基于连接的受保证服务和无连接最佳服务的异步NoC,其网络中的链路和路由器完全使用异步电路设计实现.路由器使用4段数据打包协议,链路使用2段双轨延迟无关电路实现.在0.13 μm工艺下其吞吐量能够达到650 Mflitps.ANOC[24]是使用准延迟无关异步逻辑实现的一款异步低功耗NoC,使用2维Mesh结构构建了GALS系统,在 65 nm 工艺下其吞吐量达到 550 Mflitps,与相同功能的同步版本相比其功耗下降了86%.
1.3 类脑处理器及其NoC
类脑处理器是支撑脉冲神经网络(spiking neural network, SNN)运行的硬件平台,能够实现海量神经元计算和互连通信的模拟.因为其具有低功耗、高能效、高容错性等特点,已经被广泛地用于图像识别[25]、语音识别[26]和机器人控制[27]等诸多领域.近年来有许多类脑处理器被研制成功并提出了类脑计算硬件的设计方法学[28].
TrueNorth[4]是美国IBM公司研发的一种类脑处理器,它有4 096个核,通过2维Mesh网络连接在一起.Loihi[5]是由美国Intel公司研发的一个数字形态类脑处理器,其单处理器有128个类脑核,每个类脑核可以模拟13万个“集成−放电”模型神经元和1.3亿个突触.神经元核间通过异步NoC实现片上互连通信.DYNAPs[12]是瑞士苏黎世大学提出的一种混合信号多核类脑处理器,它使用异步数字电路实现的2维Mesh NoC进行通信和采用模拟电路实现的神经元进行计算.SpiNNaker[13]是由英国曼彻斯特大学提出的一种大型数字类脑系统,它通过将100万个ARM处理器连接在一起实时模拟大脑.其中18个ARM处理器被集成到1个多处理器芯片(chip multiprocessors, CMP)中,216个 CMP 以 2 维环形网络互连构成了整个系统.在其互连系统中,片上微处理器和存储器之间的通信使用GALS实现,片间网络的通信采用同步路由器和异步链路实现.Neurogrid[11]是斯坦福大学提出的一种数模混合类脑系统,能够提供对数百万个神经元和数十亿个突触进行仿真的能力,它以树形网络组织了16个互连的处理器,片上的任意神经元可以通过多播通信将信息异步地发送到其他处理器的突触上.
目前大多数类脑处理器的片上互连采用纯异步电路实现NoC.除了SpiNNaker采用同步路由器和异步链路实现片间互连以外,没有人采用异步链路和同步路由器的架构实现类脑处理器的片上互连,来构建GALS的类脑处理器架构.而我们认为,这种采用异步链路和同步路由器的架构能够保持一个大部分设计是同步设计的设计流程,便于使用现有成熟的EDA工具进行设计和实现,同时,在满足类脑应用通信需求的条件下,异步通信可以带来低功耗优势.
2 架构设计
本节将首先分析SNN的片上执行模式和流量特点,以便了解其在类脑处理器上的执行过程与设计需求;然后介绍为类脑处理器核间片上互连通信所设计的NoC架构,分别从整体设计到详细的路由器模块设计以及异步链路设计.
2.1 类脑处理器工作方式与SNN通信模式
SNN是以时间步为最小时间单位执行的.因此,为了在类脑处理器上执行SNN,类脑处理器的工作方式也必须参照SNN在1个时间步当中执行的各项操作来设计.
如图5所示,在基于NoC的类脑处理器上执行多个(图5中以2个为例)时间步的SNN的操作可以被分为5个工作步骤执行:1)输入脉冲加载,即外部脉冲序列由片外存储器或传感器传输加载到片上;2)脉冲通信传递,即所加载的脉冲序列被转换为脉冲数据报文,在NoC上被路由至目的节点(目的神经元);3)脉冲接收与神经元计算,即每个NoC节点下载属于其的脉冲数据报文到神经元当中,读出与脉冲对应的突触连接的权值并进行神经元的膜电压累积计算;4)脉冲生成,即当所有脉冲数据报文都已经被目的节点收到并完成累积计算后,所有神经元使用其预置的阈值与其膜电压进行比较,若膜电压超过阈值,则神经元会产生脉冲输出;5)脉冲输出与传递,即上个时间步当中神经元产生的脉冲输出会被转换为脉冲数据报文,作为当前时间步的一部分输入脉冲,通过NoC发往其所属的目的节点,同时来自外部存储器或传感器的脉冲序列也一并被加载并被传递.在第1个时间步当中,由于没有内部神经元产生脉冲输出,因此并不包含步骤5,而在从第2个时间步开始的后续时间步当中都包含这个工作步骤.
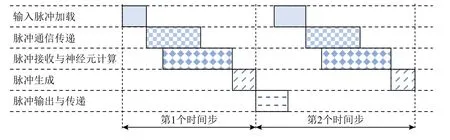
Fig.5 SNN on-chip execution pattern in time step图5 以时间步为单位的SNN片上执行模式
从图5中我们可以发现,在每个时间步(除第1个时间步外)的开始,上个时间步中由神经元产生的脉冲输出而生成的数据报文开始持续地经由NoC发往目的节点,同时此时间步的来自外部存储器或传感器生成的脉冲数据报文也会持续地被发送到NoC上,从而在时间步的开始时产生猝发的通信需求.
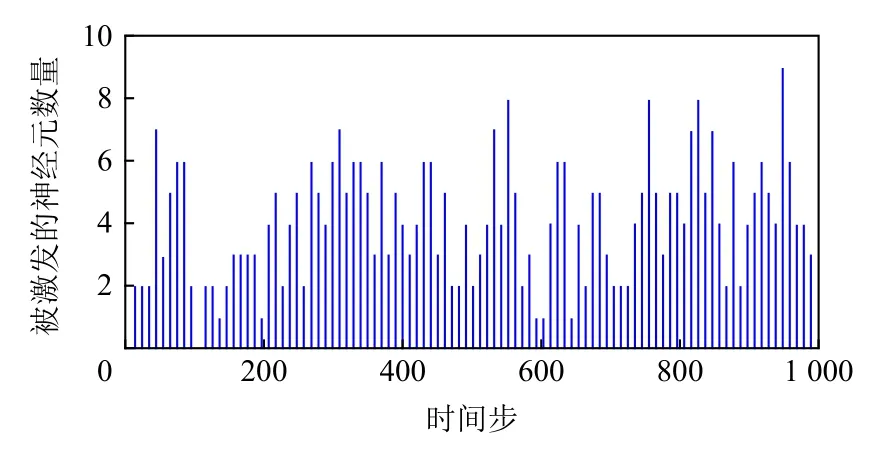
Fig.6 Number of fired neurons in 1 000 execution time step图6 在1 000个时间步中被激发的神经元数量
图6为我们的研究发现,在SNN(以液体状态机[29]执行FSDD数据集[27]为例)执行的每个时间步当中,产生输出脉冲的神经元数量占据神经元总数的百分比为1%~2%,并且在SNN(以液体状态机[29]网络为例)当中,神经元的连接也是稀疏的,其连接概率一般为40%~50%.因此,由产生脉冲输出的神经元数量与神经元扇出连接数量的乘积所定义的SNN片上执行通信量,在1个时间步中是非常稀疏的.
2.2 整体设计
设计一个类脑处理器中最具挑战性的工作之一就是设计一个支持大量神经元互相通信的、可扩展的脉冲通信系统.由于NoC具有高性能、可扩展、大量并行、低延迟、低功耗的优势,非常适合用做类脑处理器中的通信系统.
如图7所示是我们为类脑处理器核间片上互连通信设计的NoC架构NosralC的框图.由图7可知,NosralC包含2级结构,即负责脉冲序列传递和神经元之间通信的NoC以及负责完成神经元计算的神经元核.其中,通信节点路由器以2维Mesh的方式进行互连.在Mesh型拓扑中,路由器和四周的邻居路由器相连,使得整个NoC具有较大的吞吐量和并行度.这样的拓扑结构带来2个优势:1)全互连和高并行的设计使得网络可以支持不同拓扑结构的SNN模型,具有通用性和可扩展性;2)相较于其他网络拓扑,Mesh结构具有大吞吐量的优势,可以满足类脑应用猝发流量的通信需求.
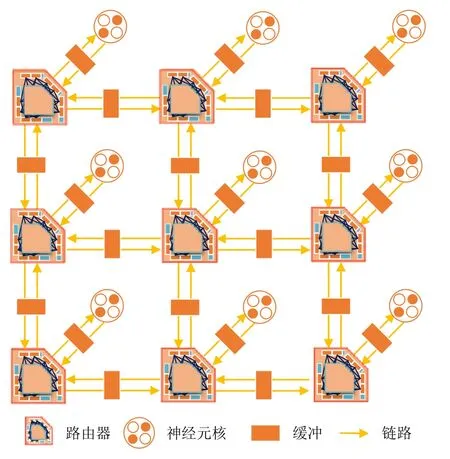
Fig.7 Block diagram of NoC architecture for on-chip intercon nection and communication of neuromorphic processor图7 类脑处理器片上互连通信NoC架构框图
2.3 路由器设计
2.3.1 数据报文与路由器总体设计
如图8所示是我们设计的路由器的整体结构,它采用的是经典的5端口双工设计,即每个路由器分别有东、西、南、北、本地5个方向,每个方向包含输入和输出2个端口,分别完成数据报文的输入和输出功能.
在考虑硬件开销以及平衡通信和计算时间的基础上,我们将NoC规模设置为16×16的阵列.每个路由器节点下挂载的神经元核内支持256个神经元,因此整个系统支持65 536个神经元的模拟.
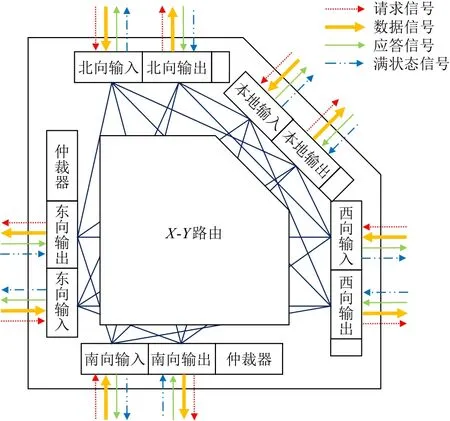
Fig.8 Block diagram of 5-ports duplex router design图8 5端口双工路由器设计框图
如图9所示是我们的数据报文设计框图,其总长度为32 b.其中,目的坐标XD和YD标识了目的路由器的坐标,源坐标XS和YS标识了源路由器的坐标,它们均为4 b,用于数据报文在NoC上的路由.因此坐标最大支持16×16规模的NoC.神经元编号字段为16 b,用于存放全局唯一的源神经元编号.神经元编号可以唯一标识65 536中的1个神经元而不会产生冲突,便于接收方根据该编号识别脉冲数据报文的来源,取出对应的突触连接的权值进行计算.

Fig.9 Design of data packet format图9 数据报文格式设计
2.3.2 输入模块与路由算法
如图10所示是路由器的输入端口设计以及路由算法示意图.其中先进先出(first in first out, FIFO)缓冲用于缓存从NoC中接收的数据报文,其深度是可配置的;满信号用来指示缓冲器的状态,如果不为1,则说明FIFO还没有满,因而可以对该端口发出请求.在得到写应答信号的应答后,数据信号输入端口接收到数据报文并将数据存入FIFO缓冲器中.FIFO 控制器会记录FIFO的状态,用于控制对FIFO的读写.
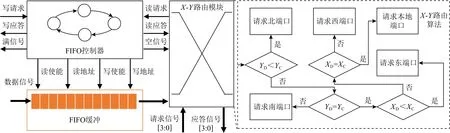
Fig.10 Design of input module and schematic of X-Y routing algorithm图10 输入模块设计和X-Y路由算法示意图
路由算法确定了数据报文在网络中按照何种路径从源节点传输到目的节点.在Mesh网络中,为了防止死锁,一般采用维序优先的路由算法.因此,在本设计中我们采用X-Y路由算法.如图10右侧所示是X-Y路由算法的示意图,根据该路由算法可以实现计算当前数据报文下一跳传输方向的功能.X-Y路由算法是一种确定性路由算法,只要给定源坐标与目的坐标,就能唯一确定1条路由路径,并且它十分便于硬件实现,同时也能够满足SNN通信的路由需求.
在工作中,依据X-Y路由算法,我们首先将网络中的所有路由器都用一个2维坐标(X,Y)表示,数据报文中的坐标信息也用2维坐标(X,Y)表示以便一一对应.假设当前路由器的坐标为(XC,YC),数据报文中的目的坐标为(XD,YD).如果目的坐标和当前路由器的坐标一致,当前路由器将下载该数据报文并发送到本地神经元核中;否则,每个路由器会先沿着X方向传输数据报文,直到当前到达路由器的X的坐标与数据报文携带的目的地的X坐标相等,然后路由器才会沿着Y方向传输数据报文,直到当前到达路由器的Y坐标与数据报文携带的目的地的Y坐标相等.由于SNN的通信流量较为稀疏,因此我们没有使用复杂的虫孔路由和虚通道技术.
2.3.3 输出模块与仲裁机制
如图11所示是路由器的输出端口设计和仲裁机制示意图.每个输出端口都连接了其他4个方向的数据通路,如果同时有多个数据报文请求同一个输出端口,那么就需要仲裁模块进行仲裁,选出优胜者执行当前时钟周期下的数据传输.在本设计中采用Round-Robin仲裁算法,即轮询仲裁,它指的是轮流对多个请求进行响应.这种仲裁方法比较公平,并且无需记录状态,比较适合硬件实现.
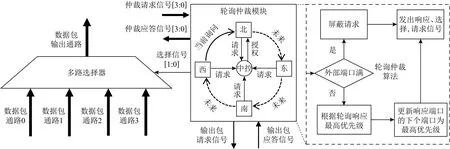
Fig.11 Design of output module and schematic of round robin arbitrating mechanism图11 输出模块设计和轮询仲裁机制示意图
2.4 异步链路设计
由于类脑应用的流量模式具有稀疏的特点,因此我们选择采用异步链路构建NoC的链路,这种异步通信的方式更加符合大脑工作的特点.如图12所示是该异步链路的控制通路和数据通路框图.在该框图中,我们使用click单元[30]和2段握手数据打包的方式进行数据通信.之所以选择click单元,是因为这种设计避免了锁存器和c单元的使用,仅仅依靠边缘触发器作为唯一的存储单元,并且性能接近先进的MOUSETRAP[31],所需的设计流程也更加简单、更接近同步电路,便于使用传统的EDA工具进行测试与实现.
图12上方的是click单元,图12下方的是由寄存器构成的寄存模块.链路之间通过请求和应答信号进行异步通信.click单元通过握手信号的组合产生传输触发信号,驱动触发器进行数据传递.在数据传递之后的一段时间,其控制逻辑会自动翻转输出的请求信号,以实现下一次请求的输出.值得注意的是,图中虚线框的部分对于产生寄存器传输触发信号的宽度具有较大影响.如果该信号的宽度较窄,那么将会导致亚稳态问题,从而使得寄存器采样输出不稳定,产生抖动的现象.这种情况会影响数据传输的正确性.因此,只有正确匹配其延迟,使得其宽度足够,才能避免亚稳态问题的发生,保证传输数据的正确性.
2.5 同步异步接口
在同步域中,数据流动是时钟驱动的,而异步域采用握手信号驱动数据的流动,因此在同步域与异步域之间需要一个适配两者的逻辑转换模块,以完成数据在域间的传递.在NosralC当中,我们使用了一个同步FIFO作为域间的缓冲,同时使用特定的转换逻辑,将异步域中的握手信号转换为对FIFO的读信号和写信号,以此实现数据的传入与取出.
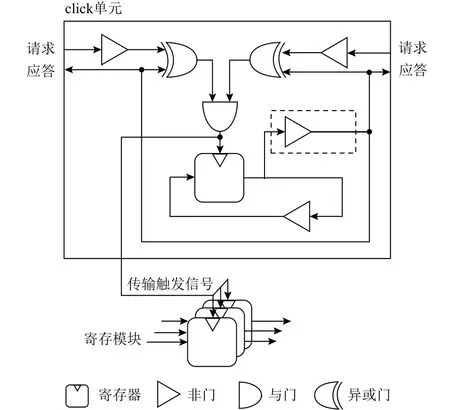
Fig.12 Block diagram of data channel and control circuit of asynchronous link图12 异步链路的数据通路和控制电路框图
如图13和14所示分别是数据从同步域传入异步域以及从异步域传入同步域的转换电路实现.在转换电路中,我们采用FIFO实现域间数据的传递,这种方法属于利用双/多触发器进行域间同步的方式,可以解决域间数据传递的亚稳态问题,同时相较于暂停时钟的域间同步实现方式性能更高.
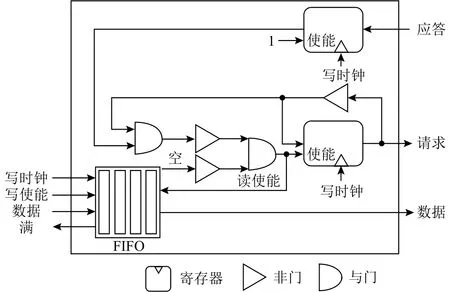
Fig.13 Writing channel of data conversion circuit between synchronous domain and asynchronous domain图13 同步域与异步域数据转换电路写通道
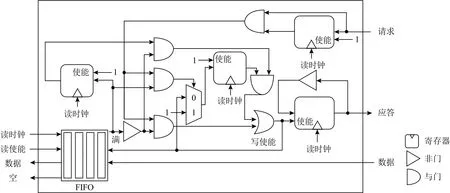
Fig.14 Reading channel of data conversion circuit between synchronous domain and asynchronous domain图14 同步域与异步域数据转换电路读通道
2.6 GALS系统的设计流程
如图15所示是NosralC的设计流程.为了充分验证NosralC在同步异步交互当中可能存在的亚稳态问题以及延迟匹配的正确性,我们通过4个步骤实现:1)对寄存器级传输(register-transfer level, RTL)代码进行行为级仿真,验证设计的基本功能;2)对设计增加时序约束,使用工艺库中的基本功能单元,例如查找表(look up table, LUT)等替换 RTL 语句中的理想延迟进行延迟匹配;3)经过综合与实现,我们得到了门级网表,并在增加了时序信息后的仿真中对设计进行测试,以验证是否能够满足既定时序约束以及链路延迟匹配是否实现正确功能;4)将设计生成的比特流下载到FPGA板上进行上板验证,测试设计在真实硬件上运行的正确性.
3 实 验
本节将介绍我们对NosralC的功耗、性能和资源利用评估的结果.NosralC是使用RTL级Verilog代码实现的,并使用Vivado工具进行综合,最终在FPGA平台上进行了功能测试与验证.
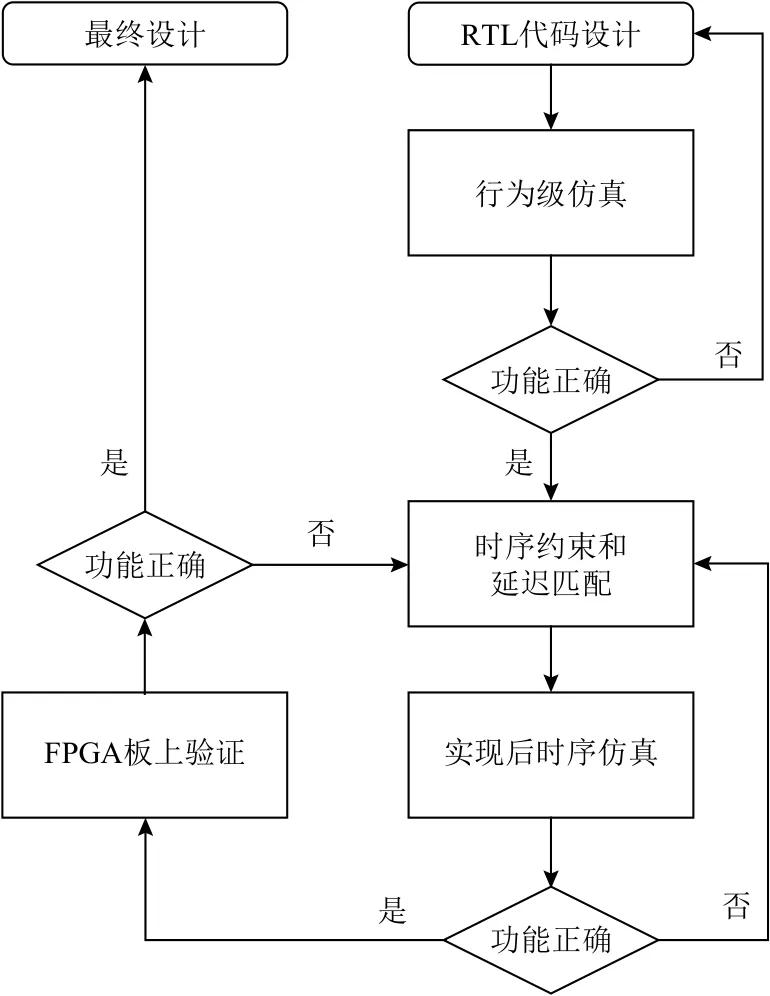
Fig.15 Design flow of GALS based NosralC architecture图15 基于GALS技术的NosralC架构设计流程
用于测试的数据集包括FSDD[14]语音数据集、NTI-DIGITS[15]数字语音数据集、DVS128 Gesture[16]手势数据集和NMNIST[17]图像数据集.其中DVS128 Gesture手势数据集和NMNIST图像数据集都是由仿生的动态视觉传感器采集生成的,输入像素通过泊松分布的编码方式转换为了SNN可以处理的脉冲序列,符合类脑应用的特点.
用于执行测试数据集的SNN是一个具有1 000个神经元的液体状态机.具体的网络配置如表1所示.该 液 体 状 态 机 网 络 执行 FSDD,DVS128 Gesture,NMNIST,NTI-DIGITS数据集的精度分别可以达到92%,98%,98%,87%.
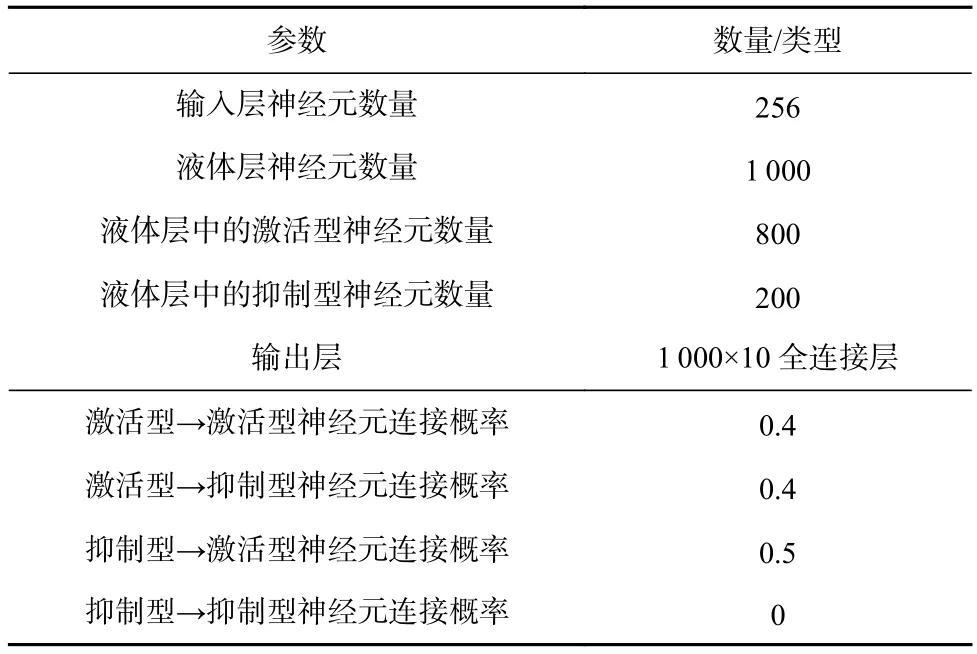
Table 1 Configuration of Liquid State Machine SNN表1 液体状态机SNN配置
硬件架构测试的激励,即脉冲数据报文,是由外部载入NoC各节点下的存储器中的.而这些数据报文的生成是依据在软件框架中网络执行的轨迹,即神经元在各个时间步中互相发放和传递脉冲的情况以及神经元映射到NoC下挂载的各个节点的分布生成的.由于NosralC只是一个NoC架构,主要负责完成神经元的核间脉冲数据报文传递通信,不涉及到神经元的计算,并且GALS的设计也不会产生报文丢失的情况.因此GALS的设计不会对网络分类精度产生影响.
NosralC与其同步同等设计基线的架构配置信息为:2种架构的节点数都是16×16,即256个节点;两者拓扑结构都是2维Mesh结构;在同步实现基线中,其路由器的FIFO深度为32,而在NosralC中,异步接口的FIFO深度为16,其同步路由器的FIFO深度为16.
对于硬件验证,NosralC被以二进制比特流的形式下载到了FPGA上进行实际的板上验证,并证明了设计正确完成了异步链接间的延迟匹配,克服了同步异步交换时出现的亚稳态问题.我们用于对比的基线是具有相同功能的同步实现的NoC,频率为20 MHz.
3.1 功耗评估
为了评估NosralC与同步同等功能的设计在功耗指标上的对比,我们首先使用4个测试数据集FSDD,NTI-DIGITS,DVS128 Gesture,NMNIST 对设计进行测试,得到了对应的仿真波形vcd文件.然后我们使用功耗评估工具,基于仿真波形和相同的工艺库,对2个设计在4个测试数据集下的平均功耗进行评估.
评估结果如表2所示.可以看到在4个类脑应用数据集上,NosralC比同步同等设计基线在功耗方面有37.5%~38.9%的降低.这是因为这些数据集的流量模式具有稀疏的特点,而NosralC采用异步链路,数据传输是通过握手协议进行的,即按需传输,翻转频率较同步链路更低,因此较同步同等设计基线其动态功耗有所降低.而NosralC较同步同等设计基线的静态功耗降低的原因有2个:1)由于使用了异步链路而不是全局时钟,使得时钟网络规模降低;2)由于同步链路部分逻辑的翻转频率要高于异步链路,而翻转频率高的门单元漏流也高,因此同步链路的静态功耗要高于异步链路.因而在类脑处理器中引入异步设计用于互连,可以在一定程度上降低处理器的整体功耗.
3.2 性能评估
为了评估NosralC和同步同等设计基线的总延迟、每个报文的平均延迟和吞吐量等性能指标,我们使用前述4个类脑应用测试数据集对它们进行了测试.其中,平均延迟是指任意数据报文从被发送到NoC上直到被目的路由器节点接收到的延迟的平均值;吞吐量是指总延迟(从第1个数据报文被发送到NoC上开始到最后1个数据报文被目的节点接收为结束的时间间隔)与数据报文数量的比值.
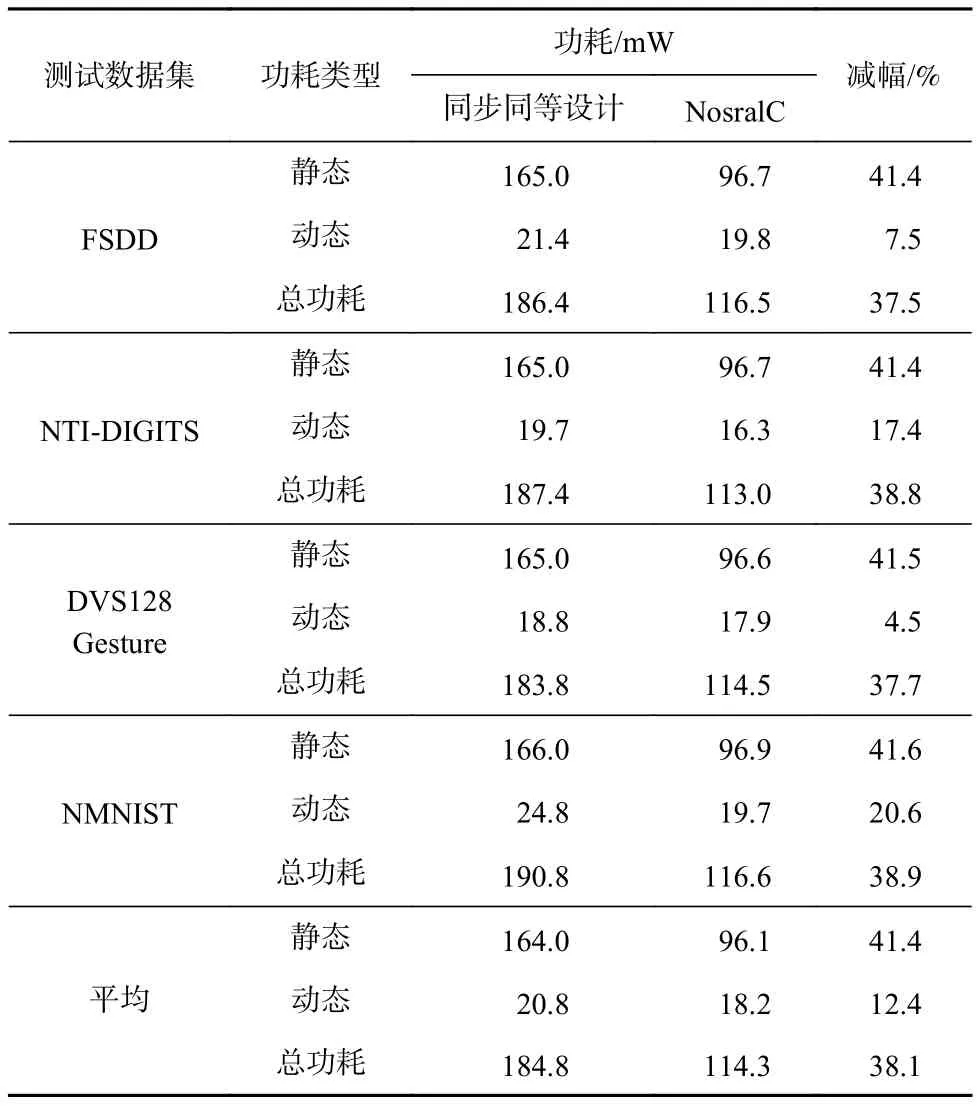
Table 2 Power Comparison Between Synchronous Counterpart Baseline and NosralC表2 同步同等设计基线与NosralC的功耗对比
3.2.1 平均延迟
如表3所示是NosralC和同步同等设计基线在4个类脑应用测试数据集下的平均延迟对比.可以看到,在NosralC中数据报文的平均延迟比同步同等设计基线减少5.5%~8.0%.由于从1个神经元产生脉冲数据报文到目的神经元接收到脉冲数据报文中间经过了NoC的传输,所以网络架构的平均延迟可以从一定程度上表征SNN中突触的传输延迟这个关键指标.
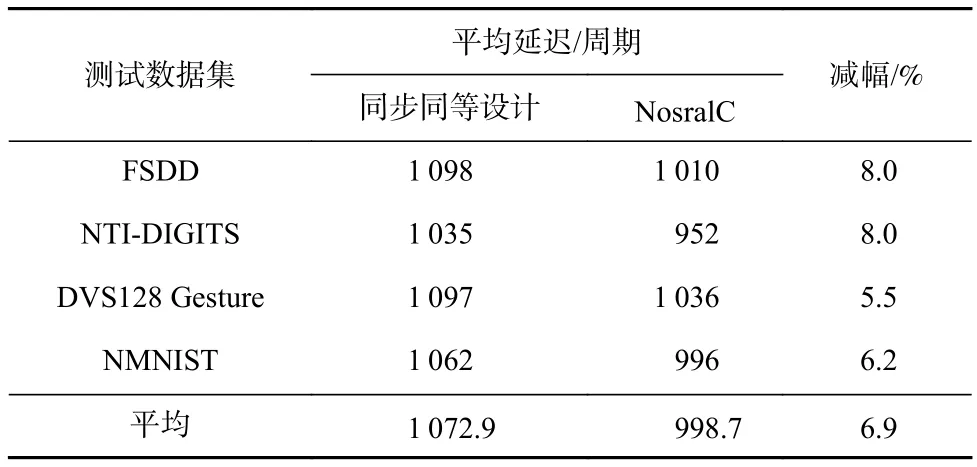
Table 3 Average Delay Between Synchronous Counterpart Baseline and NosralC表3 同步同等设计基线与NosralC的平均延迟对比
3.2.2 吞吐量
如表4所示是NosralC和同步同等设计基线在4个类脑应用测试数据集下的吞吐量对比.在本文中,吞吐量被定义为总运行时间(从第1个数据报文被发送到NoC开始到最后1个数据报文下NoC为结束)与发送报文总数的比值.可以看到,在NosralC中,数据报文的吞吐量比同步设计低0.8%~2.4%.在没有拥塞且注入率为20M报文/秒的情况下,最高吞吐量可达217M报文/秒.之所以强调在没有拥塞的情况下是因为在这种情况下才能维持恒定的注入率,否则数据报文只会等待拥塞情况缓解才能被发送到NoC上,从而无法维持恒定的注入率,因此没有拥塞的情况是一种理想的情况.
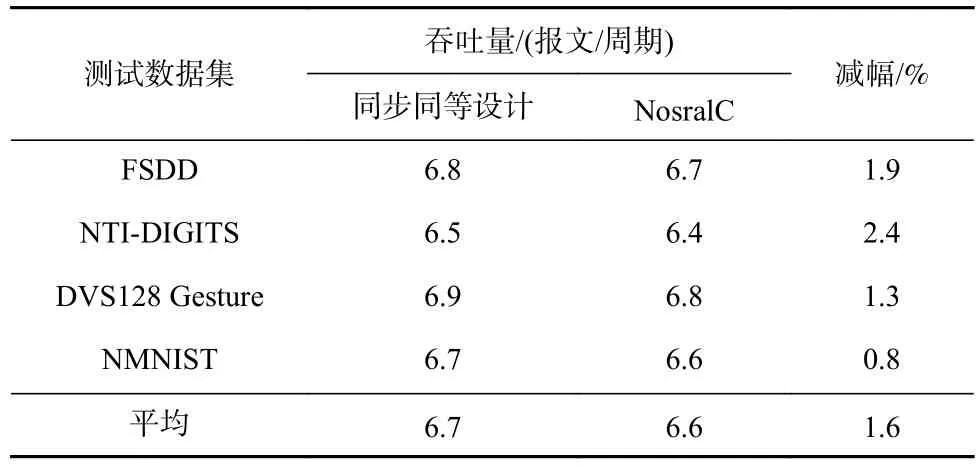
Table 4 Throughput Comparison Between Synchronous Counterpart Baseline and NosralC表4 同步同等设计基线与NosralC的吞吐量对比
如图16所示,我们研究了在不同注入率情况下的吞吐量变化情况,以表征网络的拥塞情况.可以看到,一开始随着注入率增大,吞吐量也增大,这是因为网络还没有出现拥塞,所以注入越快,吞吐量越大;当注入率到达一定程度时,吞吐量出现了拐点,并且随着注入率的增加而不断降低,说明此时网络出现了堵塞,使得数据报文无法上网.
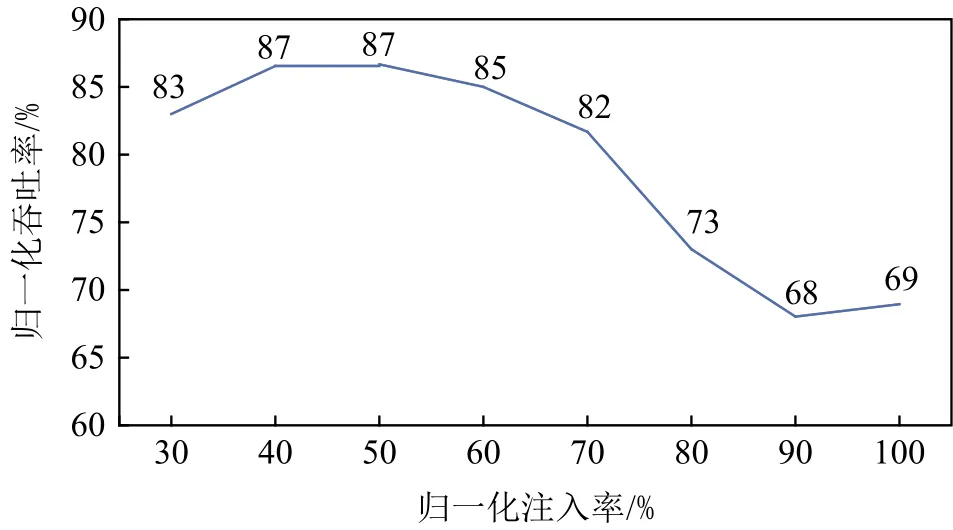
Fig.16 Throughput variation under different injection rates图16 不同注入率下的吞吐量变化
3.3 能效评估
为了评估NosralC和同步同等设计基线的能效指标,我们使用4个类脑应用测试数据集对它们进行了测试.我们将1个数据报文的通信定义为1次操作.如表5所示是据此定义得出的能效对比.在4个类脑测试数据集下,相较于基线,NosralC可以达到36.7%~47.6%的能效提升.
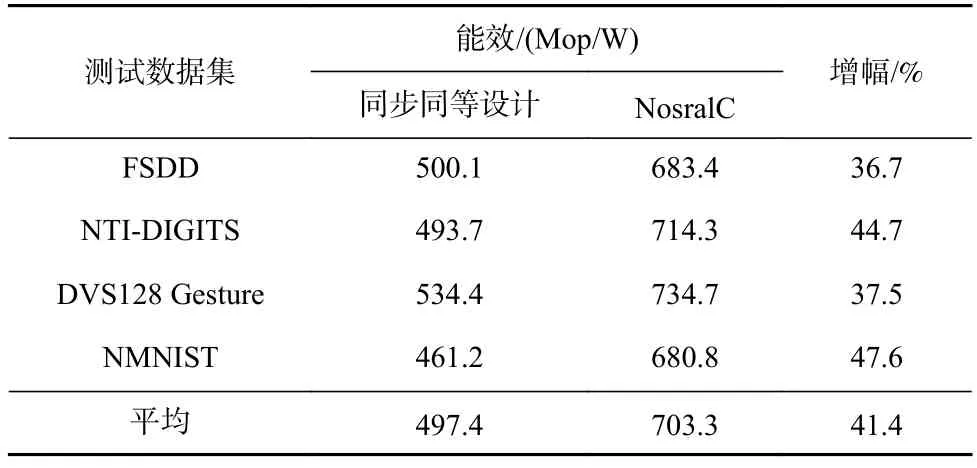
Table 5 Energy Efficiency Comparison Between Synch ronous Counterpart Baseline and NosralC表5 同步同等设计基线与NosralC的能效对比
3.4 资源评估
为了评估NosralC和同步同等设计基线在FPGA资源占用上的对比,我们使用Vivado对2个设计进行了综合,得到的资源利用量对比如表6所示.可以看到,NosralC在资源消耗上与同步同等设计基线相近,仅仅增加了4.2%的资源占用.
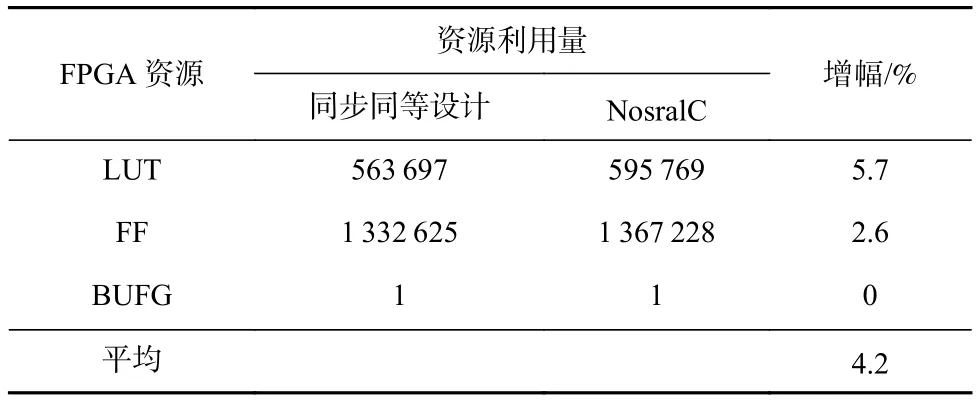
Table 6 Resource Utilization Comparison Between Synch ronous Counterpart Baseline and NosralC表6 同步基线与NosralC的资源利用量对比
3.5 与相关工作的比较
如表7所示是我们与先进相关工作的比较.本文选取了2个类脑处理器TrueNorth和Loihi中的异步NoC与NosralC进行了比较.由于这2个工作都是以先进工艺实现的专用集成电路(application specific integrated circuit, ASIC),而 NosralC 采用 FPGA 进行实现,所以在实现频率难以达到Loihi的水平.而在平均延迟方面,由于NosralC支持的网络规模较Loihi更大,传输节点跳数更多,同时等效频率也低于Loihi,因此NosralC传输延迟较大.
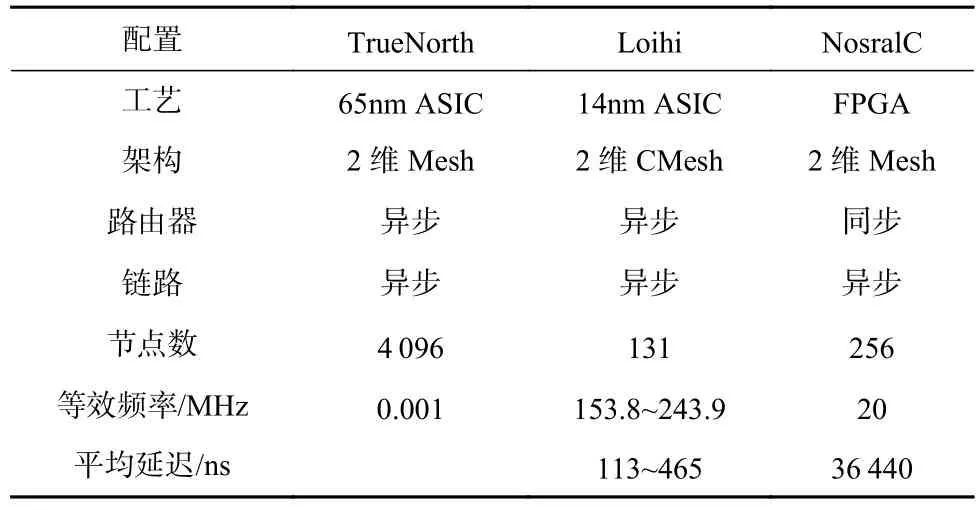
Table 7 Comparison of NosralC and the State of the Art Work表7 NosralC与先进相关工作的比较
4 结 论
本文提出了一个用于GALS多核类脑处理器片上互连的高性能低功耗异步NoC架构NosralC,采用异步链路和同步路由器实现.我们在FPGA上进行了设计验证.实验表明,该实现较其同步同等设计基线在处理液体状态机执行4个类脑应用数据集的流量模式下具有能效优势,同时不带来较大性能开销和资源开销.在未来,我们将研究神经元核的实现,以便基于该NoC完成多核类脑处理器,实现大规模神经元智能活动的模拟与计算.
致谢特别感谢课题组陈小帆、康子扬、李石明和周干等人对此工作做出的贡献.
作者贡献声明:杨智杰负责论文撰写、设计代码撰写和实验验证;王蕾负责理论指导、论文修改、设计代码撰写和实验验证;石伟负责论文修改、设计代码撰写和实验验证;彭凌辉负责设计代码撰写和实验数据记录;王耀负责论文修改、设计代码撰写和实验验证;徐炜遐负责理论指导.
猜你喜欢
汽车电器(2022年9期)2022-11-07
科教新报(2022年24期)2022-07-08
作文小学中年级(2021年10期)2021-12-26
科教新报(2021年23期)2021-07-21
恋爱婚姻家庭·养生版(2021年5期)2021-05-31
科学24小时(2021年1期)2020-12-24
铁道通信信号(2020年4期)2020-09-21
中国惯性技术学报(2020年2期)2020-07-24
中国外汇(2019年11期)2019-08-27
中小学信息技术教育(2017年6期)2017-06-23
