
基于暗块提取的无监督语义分割算法*
2023-01-30 04:17谢慧明常博学黄仕峰覃阳
桂林航天工业学院学报 2022年4期
谢慧明 常博学 黄仕峰 覃阳*
(1 桂林航天工业学院 工程综合训练中心,广西 桂林 541004;2 桂林航天工业学院 机电工程学院,广西 桂林 541004;3 桂林电子科技大学 人工智能学院,广西 桂林 541004)
图像语义分割需要是给图像中的每个像素预测一个类别,主要应用于目标检测、符号识别以及图像压缩等方面,是机器视觉中的一个研究热点。在有监督应用场景中,用一组图像和像素级的语义标签(比如天空、自行车等)来训练一个分类系统。目前应用比较广泛的有监督框架是全卷积网络(FCNs)[1],它是一个端到端(end-to-end)的网络框架,输入一幅图像后可以直接在输出端得到每个像素所属的类别。典型的FCNs算法先为每个像素裁剪一个局部区域,然后采用一个微调网络(fine-tuned backbone network)来预测每个像素的类别,能获得较高的正确率。但是有监督语义分割需要像素级的语义标签,而获取这样的标签将需要巨大的劳动力[2]。
在无监督应用场景中[3],图像分割主要用来预测更笼统的类别,比如 “前景“和”背景“。无监督比有监督更具挑战性,尤其是采用无监督方法将图像分割为任意数量(≥2)的合理区域。研究者们提出了许多不同的基于聚类的图像分割方法,聚类算法是一种无监督学习算法,主要通过相似性度量来进行分类,不需要事先知道分类的准则,也不需要训练样本。被应用到图像语义分割的聚类算法主要有K-mean[4]、FCM[5]、谱聚类[6]和mean-shift[7]等。但是这些基于聚类的分割方法存在以下的一些问题: 1)需要提前给定类别数。2)分割结果受初始中心点或某些参数的影响比较大。3)分割过程中对纹理信息和空间信息利用不够,导致过分割的产生。
综合以上几点,本文提出一种利用暗块提取(DBE:Dark Block Extraction)算法[8]对图像进行语义分割的方法,该算法能自适应得到类别数和分类结果。在实际应用过程中,本文根据算法特点以及分类效果进行了相应的改进:1) DBE算法需要计算像素间的距离矩阵,如果直接处理高分辨率的图像,需要较大的时间复杂度和空间复杂度。因此,本文首先利用超像素分割算法对图像进行预分割,这样只需要计算超像素块之间的距离而非像素点间的距离,降低了时间复杂度和空间复杂度。2) 两个相邻波谷之间的像素块实际上属于同一类,本文考虑到噪声的存在,设置两个参数来选取这个区域中可靠性高的像素块赋予这一类的标签,这个区域中的其他超像素块可以看作是一个缓冲区,其标签将在最终分类中确定。3) 在调试过程中发现如果两个波峰之间的波谷数值较大,这两个峰值对应的类别在图像中是同一类别,本文求取了一个门限值,将波谷值与门限值进行比较,判别是否合并相邻的两个类别。4) 使用得到的类别数以及类别标签来对由栈式编码器和 softmax 分类器[9]组成的分类系统进行训练,再使用训练好的分类系统对整幅图像进行预测得到每个像素的标签。5) 对超像素块内的像素标签进行投票,选取标签数量最多的标签为这个超像素块所有像素的标签,语义分割完成。
1 方法
本文方法主要概括为3部分:获取图像超像素分割结果的过程、获取类别数和高可靠性类别标签的预分类过程、分类系统的训练和预测的最终分类过程。
1.1 超像素分割
在使用DBE算法获取类别数时,需要计算数据之间的距离。而计算每个像素点与其他所有像素点之间的距离,将需要较大的时间复杂度和空间复杂度。Ren和Malik 在 2003 年提出超像素概念[10],他们认为单个像素不具备任何意义,自然图像的理解是基于超像素的,即在局部区域中具有相似特征(如图像轮廓,纹理和颜色) 的元素集合。因此本文考虑先对图像进行超像素预分割,这样只需要计算超像素块之间的距离而非像素点间的距离,降低了时间复杂度和空间复杂度。同时在预分割过程中又希望能够进行足够细粒度的分割,分出足够多的区域(即保证每一类场景都能有足够多的区域),后续的算法再对它们进行合并,使最终结果更准确。
本文分别采用了Felzenszwalb算法和SLIC算法对图像进行预分割,其分割结果如图1所示。Felzenszwalb算法[11]是Felzenszwalb和Huttenlocher在2004年提出的一种有效的基于图的图像分割算法,该算法是基于图的贪心聚类算法,实现简单,速度比较快,精度也不错,并且能分出比较准确的边界。但是Felzenszwalb算法分割得到的超像素块对于本文的后续应用而言细粒度不够,如图1(a)所示的天空的细粒度就不够。SLIC算法[12]是在2010年被提出的一种图像分割算法,它是先将彩色图像转化为CIELAB颜色空间,得到3维特征向量,再加上像素点所处的坐标,最终得到5维特征向量。然后利用5维特征向量来构造距离,对图像像素进行局部聚类最终得到分割结果。SLIC算法易于实现,运行速度快,能生成紧凑、近似均匀的超像素。但是SLIC算法分割出的超像素块边界条纹没有Felzenszwalb算法的精细,如图1(b)所示的细节图可以看出其对树干的分割没有精准命中边界。这两种算法均可使用Python的skimage.segmentation工具包实现。
因此本文考虑对这两种算法的分割结果进行融合,拟获得足够数量、边界准确的超像素分割结果。融合的策略如下:对于Felzenszwalb算法分割出的超像素块PFi(i=1,2,…,NF),其中NF为Felzenszwalb算法分割出的超像素块数量,遍历每一个超像素块,如果在超像素块PFi中,SLIC算法得到的分割区域数量为Ci,那么就根据SLIC算法的分割情况将PFi细分为Ci个区域。融合的结果如图1(c)所示,可见融合后的分割结果满足了边界准确、细粒度足够两个条件。
1.2 预分类
在无监督图像语义分割中,类别数的选择是一个重要且具有挑战性的工作,对于构建一个强大的语义分割系统至关重要。文献[8]提出的暗块提取(DBE:Dark Block Extraction)算法是一个不需要聚类就能自适应获得类别数的算法。结合自然图像数据和DBE算法的特点,本文提出的类别数及类别标签获取方案的预分类算法流程图如图2所示,主要包括以下4个步骤:
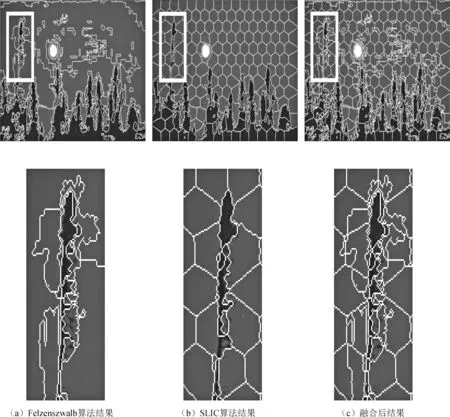
图1 超像素分割结果
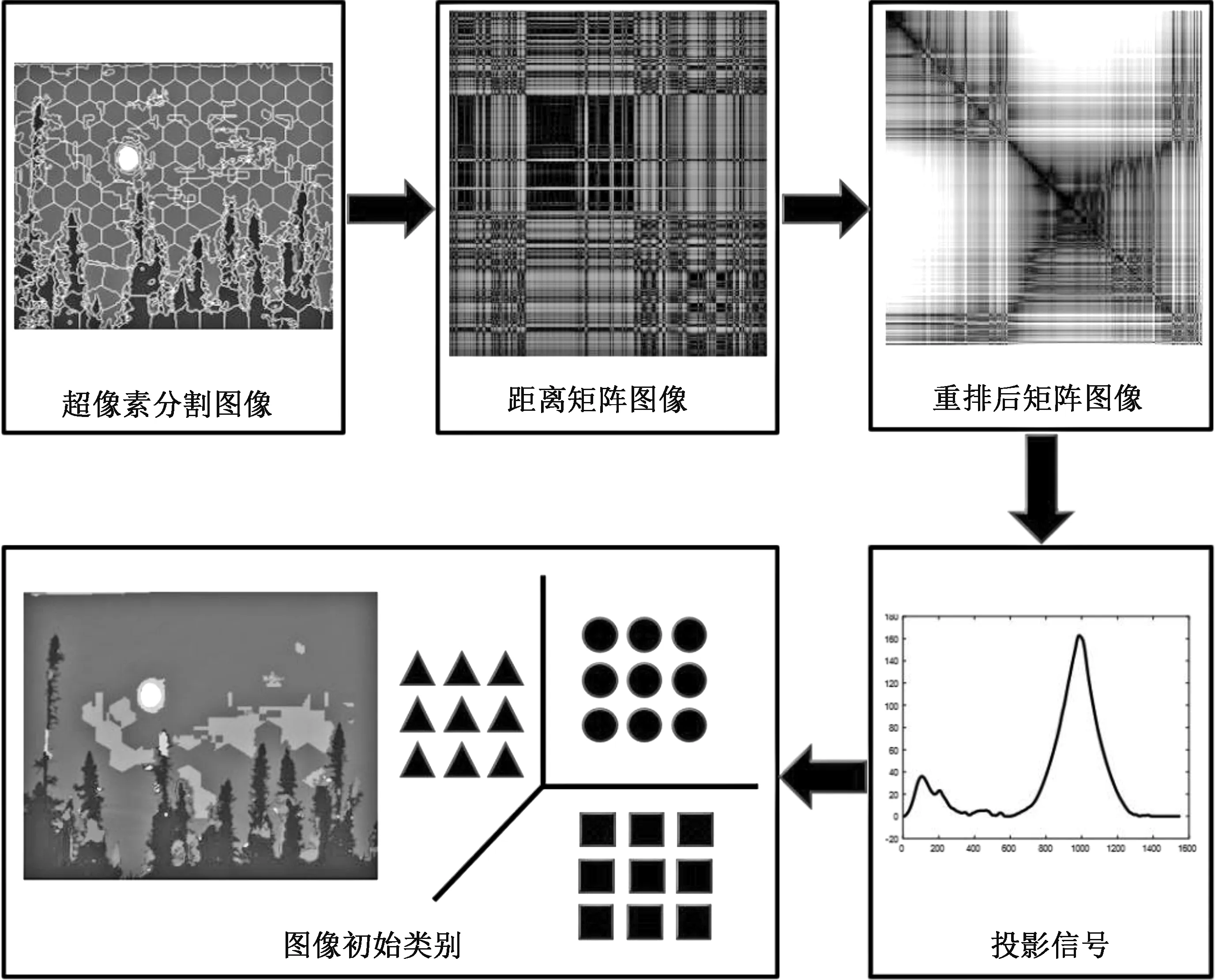
图2 预分类算法流程图
1)数据准备。首先,对自然图像的每个像素构建特征向量,特征向量的主要构成为:①由图像的RGB通道得到3维特征向量。②分别用4个3*3的卷积核(如图3所示)对图像的RGB通道进行滑窗,得到12维特征向量。③对图像求解LBP[13](Local Binary Pattern)特征得到1维特征,最终得到16维的特征表示。其次,根据1.1描述的方法获得Nm个超像素块。再次,计算每个像素块中像素的特征向量均值和方差,作为这个像素块的特征向量。最后利用欧式距离对超像素块间构建出一个Nm×Nm的距离矩阵。
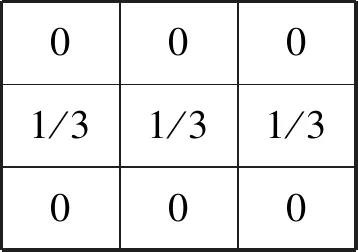
图3 4个3*3的卷积核
2)矩阵重排。由图2(b)可以看出构建出的距离矩阵无法提供任何与类有关有效信息。在文献[14]中,Catt等人发现适当地对矩阵进行重新排序,生成的矩阵图像能够更好地突出数据中的潜在聚类结构(如图2(c) 所示的图像)。在文献[14]给出了多种重排的方案,适当的重排方法得到的矩阵图像可以将潜在类突出显示为沿图像对角线的一组暗块,暗块中的数据集具有较低的相异性。在本文,我们采用VAT(visual assessment of cluster tendency)算法[15]来对矩阵进行重排,它的核心算法是Prim算法[16]。
3)类别提取。由图2(c)可见重排后的图像以对角线暗块的形式突出显示潜在类别,我们人类可以简单地获取到类别数,但计算机需要我们输入一些算法才能有效地提取到类别。本文选取的是DBE算法,它是专门为提取对角线暗块而设计的,主要采用的是一些常用的图像和信号处理技术。DBE算法的具体步骤描述如下:
在实际的道路桥梁施工建设当中,施工单位如果不能够妥善的处理好桥梁的桩基问题,那么必然会引起整个桥梁的安全质量问题,从而严重的威胁着行驶的车辆安全问题。在道路桥梁的施工建设过程中,桥梁桩基问题是整个桥梁建设的基本。桩基的质量严重的影响着整个桥梁的安全问题。然而造成桥梁桩基问题的根本原因在于打桩工艺的好坏问题。此外在实际的施工中,施工单位要高度重视打桩工艺环节的建设,从而保证桥梁桩基的质量,进而有效的保障桥梁整个质量。
①采用Ostu算法对重拍后的矩阵进行二值化处理,然后对二值化图像进行形态学滤波(先膨胀,再腐蚀)。
②对滤波后的二值图像应用欧几里得距离变换转化为灰度图像,然后沿图像的主对角线轴投影像素值,形成投影信号。
③使用一个简单的均值滤波器来对投影信号进行平滑,再对平滑后的投影信号求一阶导数,使用一阶导数来检测投影信号的波峰和波谷。
④去除高度相对较小的峰值,只有当两个相邻波谷之间的宽度大于γ*Ls时,两个相邻波谷内的峰值才会保持为有意义的峰值,其中Ls是投影信号的长度,并且本文在实验中将γ设置为0.025。这样求得的波峰的数量就是数据的类别数,DBE算法更多具体的信息,可以参阅文献[8]。
4)标签提取。在投影信号中,两个相邻波谷之间的像素块实际上属于同一类。假设第t个波谷与第t+1个波谷之间有Nt个超像素块,那这Nt个超像素块就应该属于第t类。由于噪声的存在,不能简单地把全部的Nt个超像素块都归属于第t类。在本文中,设置了两个参数:β1和β2,假设第t个波谷与第t个波峰之间有Nt1个超像素块,第t个波峰与第t+1个波谷之间有Nt2个超像素块,将波峰左边靠近波峰的β1*Nt1个超像素块以及靠近波峰右边的β2*Nt2个超像素块里所有的像素都赋予第t类的标签,其他的超像素块可以看作是一个缓冲区,其标签将在最终分类中确定。
5)类别合并。在调试过程中发现有些图像的投影信号会出现如图4实线所示的情况:突出显示的两个峰值对应的类别在图像中属于同一类,同时发现这两个波峰之间的波谷数值较大。因此本文对投影信号求取均值,如图4虚线所示,以均值为门限,如果两个波峰间的波谷值大于均值就将这两个类别合并,对应的标签也赋值为同一个标签值。
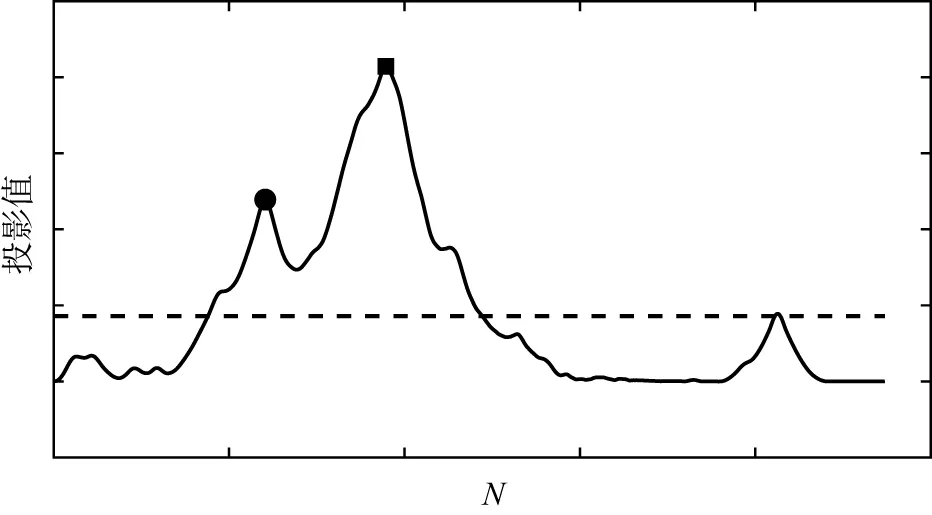
图4 投影信号及其均值信号
1.3 最终分类
由1.2预分类的介绍可知,有部分像素的标签还未确定,将由最终的分类系统进行确定。本文采用的是由栈式自编码器和 softmax 分类器组成的分类系统[9]。栈式自编码器是一种无监督学习算法,分为三层:分别为输入层、隐藏层和输出层。它利用反向传播算法对整个网络进行训练,让输出值无限接近于输入值,训练完成后再取隐藏层的信息用于分类,因为隐藏层学习到的是多层次的特征,类似于人脑的分层模型,它提取的特征随着隐藏层的推进而不断升级,最深的隐藏层学习到的特征最高级。本文利用softmax分类器[9]对学习得到的最高级的特征进行分类,softmax分类器简单易操作,与栈式自编码器构成的分类框架可以很好的进行微调(fine-tuning),并且这个分类框架能得到比传统分类器更好的分类效果[9]。分类框架具体信息以及参数选择,可参阅文献[9]。在本文中,预分类数据准备时获取的16维特征被用来作为栈式稀疏自编码器的原始输入数据,将预分类中获得标签的像素作为训练数据对分类系统进行训练。训练完成后,将整幅图像每个超像素的16维特征输入到训练好的分类系统即可得到每个像素的标签。
最后,对超像素块内的像素标签进行投票,选取标签数量最多的标签为这个超像素块内所有像素的标签,语义分割完成。
2 实验结果及分析
2.1 数据说明及参数设置
kmeans算法和FCM算法都是对超像素块进行聚类,输入的特征与输入到DBE算法的特征一样,类别数赋予的是数据集中真实的类别数。本文算法设置Felzenszwalb算法的参数为:scale = 32, sigma = 0.5, min_size = 64。本文算法设置SLIC算法的参数分别为:1) 所需超像素的数量为200。2) 颜色和空间差异之间的加权因子为10。3) 合并半径(在形态上小于此的区域与相邻区域合并)为1。4) 如何计算簇颜色中心选的是'median'(中值滤波)。本文设置栈式自编码器和softmax 分类器组成的分类系统的参数为:两个隐藏层,第一个隐藏层的节点数为50,第二个隐藏层的节点数为25,隐藏层的激活参数为0.1,权重衰减参数为3e-3,稀疏惩罚项的权重为3。
本文主要测试了β1和β2两个参数对正确率的影响如图5所示。1) 设置β2=0.1,让β1从0.5开始以0.05为步进增加到0.9得到如图5(a)所示的图。2)设置β1= 0.85,让β2从0.05开始以0.05为步进增加到0.4得到如图5(b)所示的图。从两个图可以看出,随着β1的增大,正确率呈现下降的趋势,但下降得不明显;随着β2的增大,正确率先上升后下降,这是由于暗块的后半部分是与下一类的数据进行衔接,取的数量增多之后可能会取到下一类的数据。鉴于以上两点以及对训练时长的考量,本文选取β1= 0.85,β2=0.1。
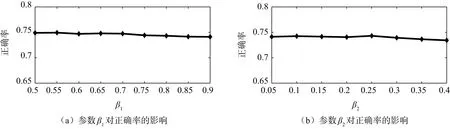
图5 参数β1和β2对正确率的影响
2.2 实验结果
Berkeley图像分割数据集的部分实验结果如图6所示,可以看出本文算法相与其他两种算法相比,分割结果更加接近人工分割结果。Kmeans算法和FCM算法对目标和背景,产生了误分,而且分割出的目标和背景完整度不高。而本文算法,分割效果更好,目标区域和背景区域比较清晰,目标和背景完整性更好,并且对背景差距较小的图片分割效果也很好。

图6 实验结果对比
为了更好地描述本文算法的有效性和准确性,本文根据真实的标签对三个算法计算了正确率,结果如表1所示,从表1可以看出,对于 Berkeley 数据集,本文算法获得的正确率比Kmeans算法和FCM算法更高,至少高了2%,可见本文算法的分割效果更好。

表1 不同算法的正确率
本文算法得到的分割结果不管是在视觉上还是正确率上都比其他两个算法要好,主要有以下两点原因:
1) DBE算法根据距离间的大小关系,将距离更小、相似度更高的像素块排列在一起,从而得到高可靠性的类别数和类别标签,为后续提取高级特征提供了可靠的训练依据。而Kmeans算法和FCM算法虽然也是利用距离的大小进行分类,但它们对类别数以及初始的聚类中心较为敏感,如果类别数和初始聚类中心设置不合理,将不能得到很好的分类结果。
2)由栈式自编码器和 softmax 分类器组成的深度学习框架学习到了高级的特征,利用这些高级特征进行分类相对于Kmeans算法和FCM算法利用的低级特征分类能具有更好的分类效果。
3 总结
本文提出一种基于DBE和栈式编码器的无监督语义分割算法,可以自适应得到每幅图像的类别数,并输出语义分割结果。实验结果表明,当前的一些分割算法相比如:kmeans算法、FCM算法,本算法能获得更好的语义分割效果,其正确率为0.741 5,还有改进的空间。后续将探索如何改进DBE算法以获取更准确地预分类结果以及改进训练框架对训练过程进行提速,做到高效实时的语义分割。本文算法只在Berkeley 图像分割数据集上进行了验证,具有一定的局限性,后期硬件条件更完备之后,可将本文算法推广到更多的语义分割数据集上进行应用。
猜你喜欢
石家庄铁道大学学报(自然科学版)(2021年4期)2021-12-07
中华养生保健(2020年7期)2020-11-16
东坡赤壁诗词(2020年5期)2020-11-06
水道港口(2020年4期)2020-09-27
民族古籍研究(2018年1期)2018-05-21
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
西夏学(2016年2期)2016-10-26
故事会(2016年15期)2016-08-23
计算机应用(2016年5期)2016-05-14
