
基于卷积神经网络的皮肤病诊断多二分类器研究①
2023-01-29 03:47代闯闯栾海晶杨雪莹过晓冰牛北方陆忠华
高技术通讯 2022年10期
代闯闯 栾海晶 杨雪莹 过晓冰 牛北方 陆忠华③
(*中国科学院计算机网络信息中心 北京 100190)
(**中国科学院大学 北京 100049)
(***联想研究院 北京 100094)
0 引言
卷积神经网络是受生物学上感受野机制启发而提出的[1-2]。在20 世纪末,卷积神经网络LeNet-5[3-5]应用到手写数字识别领域,除此之外,基于LeNet-5的手写数字识别系统被美国很多银行所使用,用于识别支票上的手写数字。目前,随着计算能力的提高,在基于图像处理的深度学习领域中,新的网络模型不断被提出并得到应用。2012 年,AlexNet[6-8]模型的提出证明了卷积神经网络(convolutional neural network,CNN)在复杂模型下的有效性,该模型结合图形处理器(graphics processing unit,GPU)进行并行训练可在有限时间内得到预期的效果[9],并赢得了2012 年ImageNet 图像分类竞赛的冠军[10]。随着AlexNet 结构的进一步发展,2014 年,ILSVRC 竞赛中VGG[11-13]模型应运而生,仅次于本次竞赛中的冠军GoogLeNet[14-15]。然而,VGG 模型在多个迁移学习任务中的表现要优于GoogLeNet,并且从图像中提取CNN 特征,VGG 模型是首选算法。GoogLeNet模型的提出则证明随着卷积层数的增加和网络结构的深入,模型的学习效果会更佳[16],因此获得了2014 年ImageNet 图像分类竞赛的冠军。2015 年,深度残差网络的提出使得更加简化的卷积结构和更深的网络得到应用[17]。
近年来,随着人工智能和大数据科学的发展,新的深度学习模型尤其是卷积神经网络模型得到不断发展[10,16-17],深度学习在图像识别问题中得到越来越多的应用。深度学习方法受数据驱动在医疗领域得到应用,因为基于不同的医疗领域,各数据来源和疾病特征不同,需要对现有的模型和分析框架做相应的调整,一些像素过大的图片数据如CT 扫描作为输入时需要进行信息压缩或者特征提取再进一步使用网络进行学习[18],有关分类诊断如黑色素瘤的良性或恶性的判别需要借助皮肤癌领域对于疾病的细分知识[19-20]。
1 神经网络模型介绍
1.1 AlexNet
AlexNet 是Hinton 和他的学生Alex Krizhevsky在图像分类挑战上提出的一种卷积神经网络结构模型,用来对ImageNet 上120 万张高清图像中的1000类进行分类,在测试集上实现了37.5%的top1 错误率,17.0%的top5 错误率。AlexNet 是卷积神经网络在图像分类上的一个经典的网络结构,具体的网络结构如图1 所示。
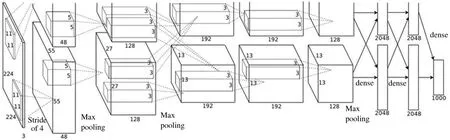
图1 AlexNet 网络结构
AlexNet 模型中使用了修正线性单元(rectified linear unit,ReLU),ReLU 函数的公式如下:
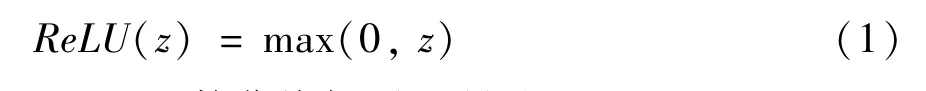
ReLU 函数曲线如图2 所示。
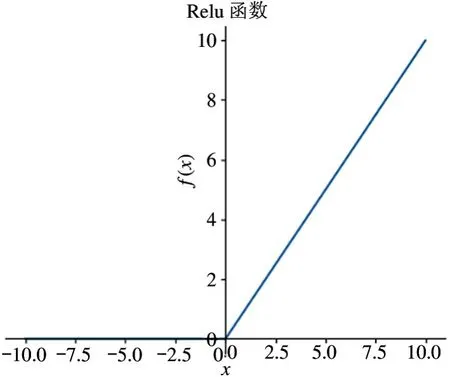
图2 ReLU 函数曲线
通过式(1)和图2 可以看出,ReLU 函数非常简单,在x<0 处取值为0,在其他地方取值为x。ReLU代替了传统的Tanh 和Logistic 等激活函数,运算速度快,能够很好地解决梯度消失的问题[21-22]。ReLU函数最先在Hinton 的ImageNet 的论文中[10]提出,截至目前,已得到了广泛的应用。然而,ReLU 函数在网络模型训练过程中最大的缺点是容易出现“死亡现象”,即如果反向传播过程中有一个参数为零,则会导致其后的参数均无法进行更新,随后提出的Leak ReLU、PreLU、Random ReLU 等改进版本的激活函数则可很好地解决这个问题。
1.2 GoogLeNet
随着当前深度学习的网络规模的扩大以及训练参数的增多,在训练过程中容易出现过拟合的现象。除此之外,深度学习涉及的数据计算量巨大,且随着卷积层数的增加使得数据计算量上升至指数级别,因此仅单纯地追求模型识别准确率的提高而盲目增加网络规模是不可取的,需要着眼于特征提取模块的设计,在基本的特征提取单元上进行一些优化操作,然后运用优化后的特征提取模块去构建网络,可能会有利于模型准确率的提高。GoogLeNet 提出了Inception module 的概念,Inception 模块同时使用1 ×1、3 ×3、5 ×5 等大小不同的卷积核,并将得到的特征映射在深度上拼接起来作为输出特征映射,一方面使得网络层具有更加强大的特征提取功能,另一方面使得网络层更深、更宽,结构变得更加稀疏,但参数量没有增加,计算量维持在一定范围内[23-26]。Inception 是一种网中网的结构,即原来的结点也是一个网络。Inception 一直在不断发展,目前已经提出了V1[16]、V2、V3[27]、V4。Inception V1 的结构如图3 所示,模块中的前置1 ×1 卷积可用来减少特征映射的深度,起到了降维的作用。
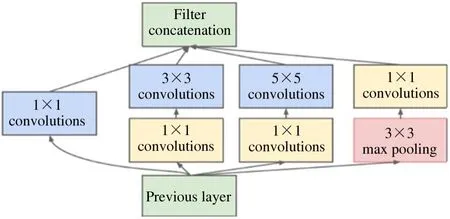
图3 Inception V1 的模块结构
GoogLeNet 是由上图中的Inception 模块所构建的模型,包含9 个Inception 模块、5 个池化层、一些卷积层和全连接层构成,一共22 层网络,如图4 所示。GoogLeNet 由于网络的卷积核可共享,计算梯度可累加,因此不会出现梯度消失的现象,其典型代表应为ResNet[17,28]。
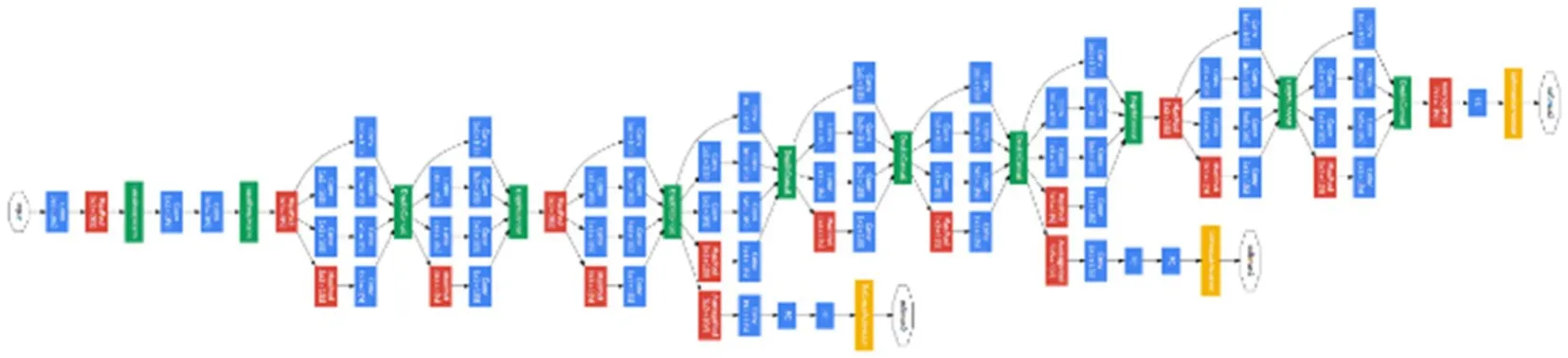
图4 GoogLeNet 网络结构[27]
2 数据预处理及预分类
本研究将基于皮肤病图像数据集的特点以及皮肤病的病理特征,提出分割、筛选、分类和分析的框架进行皮肤病的分类。首先对原始数据集进行数据预处理及预分类,预处理包括对原始图像的光强调节、亮度归一和切片,预分类是指通过一个CNN 分类器将图像块分成皮肤、毛发、背景、器官4 类;再对皮肤类图像块进行疾病的细分类,分别通过基于AlexNet、GoogLeNet、多二分类器和随机森林[29]的方法得到相应图像块的概率向量;最后根据图像块的概率向量从不同的角度进行信息的整合及预测,最终对相应的图像做确切诊断。整体研究流程如图5所示。
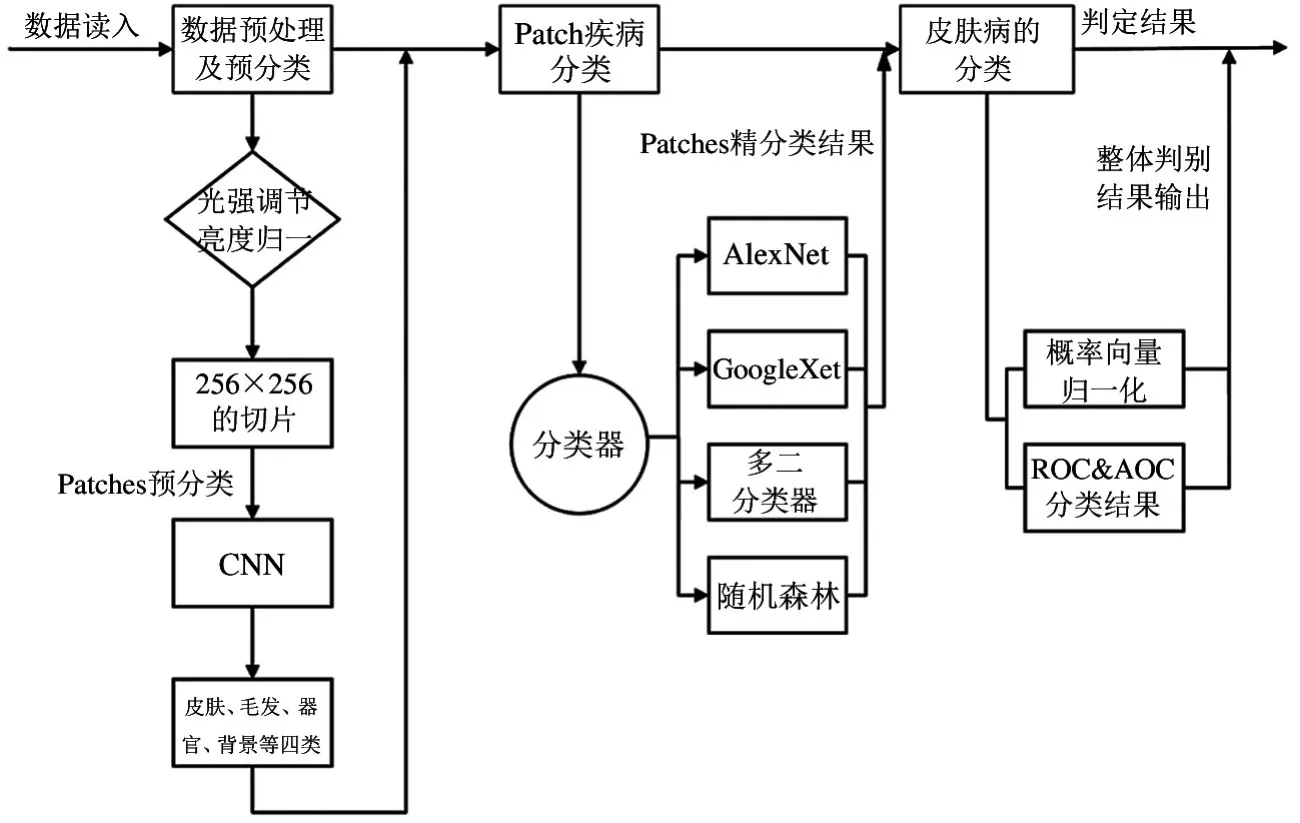
图5 研究整体流程
由于医学影像数据具有来源复杂以及数据采集不够规范的特点,将图像预处理划分为如下3步:(1)亮度归一化调节;(2)图像块分割;(3)图像块分类筛选。非线性变换的亮度调整减轻了图像采集过程中外部光线因素的不利影响,可提高对图像识别的准确率。图像块分割是指对原始影像数据进行切片处理,根据一致性的规则从每张图片中切割出若干小的分块(256 ×256 像素,RGB 三通道),完成数据的规范化,使得不同像素的医学影像能够适用于同一个模型。图像块分类筛选指的是使用卷积神经网络训练识别医学影像分割的有效部分,排除干扰信息。本研究使用CNN 对图像块进行训练,筛选出皮肤面积占比大于3/4 的有效图像块用于进一步的疾病分类。
对经预处理后筛选出的包含皮肤信息的图像块,使用CNN 进行分类,可将其分为白癜风、痤疮、银屑病、健康4 类。使用经归一化的四维概率向量表示每一个图像块经过CNN 预测后的结果。研究中使用Caffe[30]深度学习框架,并在多个经典的CNN 和自定义的网络结构进行了测试,最终选取GoogLeNet 和AlexNet 作为本研究的核心网络,调整了网络训练中的softmax-loss 层,修改参数权重提升整个网络对皮肤病诊断的敏感度。针对某一病例,均对应多个图像信息,因此需对疾病分类CNN 得到的结果进行信息的整合。
2.1 数据预处理
2.1.1 数据集简介
数据集由128 张2000~4000 像素不等的病人皮肤照片组成。病人的皮肤照片包括了银屑病、痤疮和白癜风等3 种皮肤病。图6 是病人的侧面照片的示例图。
图6 示例图
2.1.2 预处理步骤
(1) 亮度调整
在进行图像采集时,不同的光线采集条件会对所采集图像的颜色、亮度等特征产生干扰,因此需对图像亮度进行归一化处理。经过实验验证,当亮度归一化比例取0.62 时效果最好。亮度调整的示意图如图7 所示。
图7 亮度归一化
(2) 数据集的扩充及实现
由于深度学习需要海量数据进行模型训练,因此本实验利用常规图像扩充技术进行数据扩增。数据的扩增主要包括图像的旋转、镜像、缩放和平移等,本研究中采用了镜像和旋转两种方法对常规图像进行集合扩增。
(3) 图片剪裁
由于初始数据集中图片的大小不等,且某些网络的结构对输入图片的大小也有严格的要求,实验中会将初始宽高在2000~4000 像素不等的图片裁剪成256 ×256 的分块。图片剪裁操作的示意图如图8 所示。
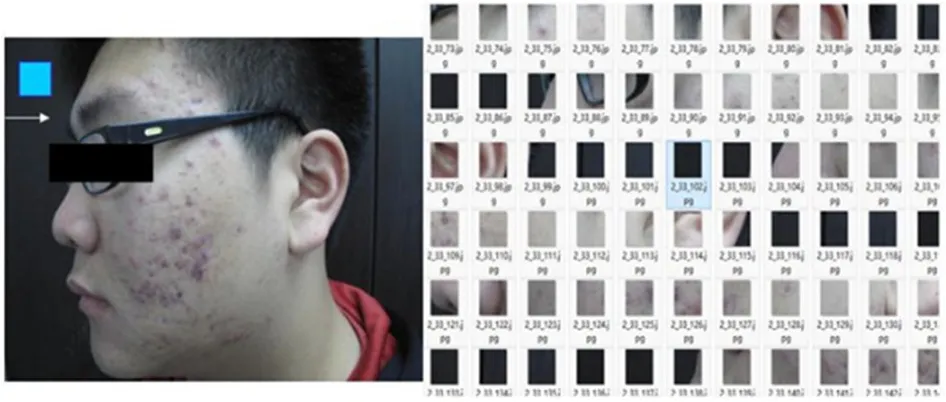
图8 图片分割
在图像块中,如图9 中包含背景图像块、图10中健康皮肤的图像块和图11 中包含其他无关信息的图像块,会对判别结果产生误导,实验中需要将它们从训练集中剔除。

图9 包含背景的图像块

图10 健康皮肤的图像块

图11 其他无关信息的图像块
2.2 数据预分类
对经预处理后的图像块进行疾病的细分类,本研究采用随机森林和普通的卷积神经网络等方法并交叉验证其稳定性,最终确定GoogLeNet 作为预分类的分类模型。经多次实验与交叉验证,测试集准确率稳定在94%左右,实验的混淆矩阵和准确率如表1 所示。
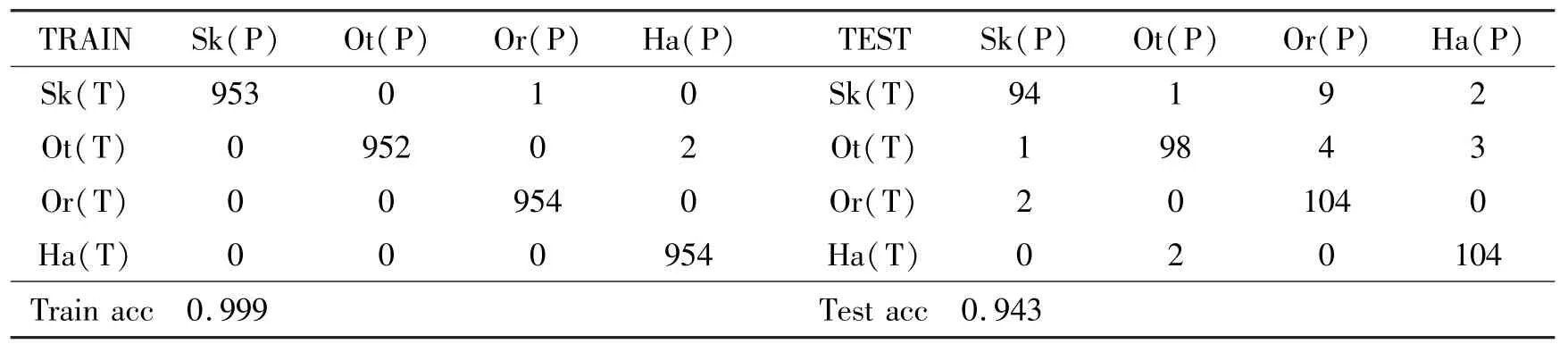
表1 预分类实验结果
经图像块预分类后,可得到包含患者皮肤信息的有效图像块样本。经人工筛选标记得到健康、银屑病、痤疮、白癜风4 类皮肤图像块样本。然后将数据集划分为训练集和测试集,训练集每类包含682个样本,测试集每类包含76 个样本。
3 皮肤病分类的多二分类器设计
针对皮肤病的多分类问题,若要通过神经网络训练获得一个良好的结果,则需设计一个合适的神经网络。随着深度学习的快速发展,网络结构也不断更迭,本文旨在不改变网络结构的前提下,尽可能提高分类器的准确率。卷积神经网络相对于其他的分类器来说,可看作是一个特征提取的过程,而一般的分类器往往是通过某些已经发现的特征来进行分类。如果将具有某些共同特征的元素归到同一类,再进行训练,这些共同的特征可能会更容易地被提取出来,因此拟通过这个网络来训练多个二分类器从而实现对初始多分类器的优化。
多个二分类器类似于二叉树的模型,先将数据分成两类,再对每一类构建二分类器,得到的一个“二叉树”如图12 所示。将皮肤病分类(白癜风、痤疮、银屑病、健康)的四分类的问题,标签记为1(白癜风)、2(痤疮)、3(银屑病)、4(健康),第一个分类器先区分1(白癜风)、2(痤疮)和3(银屑病)、4(健康),再构建2 个分类器分别区分1(白癜风)和2(痤疮)、3(银屑病)和4(健康),一个数据经过2 个分类器即可获得最终结果。然而该方法却存在很多不足之处,由于图像种类繁多,为每个二分类器单独设计网络不太现实,数据量的变化对网络的训练有很大的影响,在数据量不足的时候很容易过拟合。基于神经网络的多二分类器训练中若某个网络中的二分类器出现分类错误,该分类器就无法获得正确的分类结果。
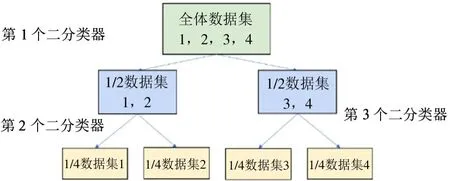
图12 多个二分类器
为降低分类时的错误率,随后提出一种改进的方法。该方法的主要思想是首先获得一个二叉树,针对该二叉树的每一层只构造一个分类器,每个分类器都使用所有的数据集,使得每一个节点的孩子节点在其所在层对应的分类器都属于不同类别,具体如图13 所示。对于最后一层若不包含所有标签类别,将剩余标签随意加入两类中的一类。以四分类为例,则只需要构造2 个二分类器,第1 个用于区分1(白癜风)、2(痤疮)和3(银屑病)、4(健康);第2 个用于区分1(白癜风)、3(银屑病)和2(痤疮)、4(健康);经过2 个分类器就可以得到结果。假如第1 个分类器将1(白癜风)、2(痤疮)标记为0,3(银屑病)、4(健康)标记为1;第2 个分类器将1(白癜风)、3(银屑病)标记为0,2(痤疮)、4(健康)标记为1。若一个数据,第1 个分类器将其标记为1,第2个分类器也将其标记为1,则不对应任何的情况,对于此问题,本研究提出了如下2 种解决方法。
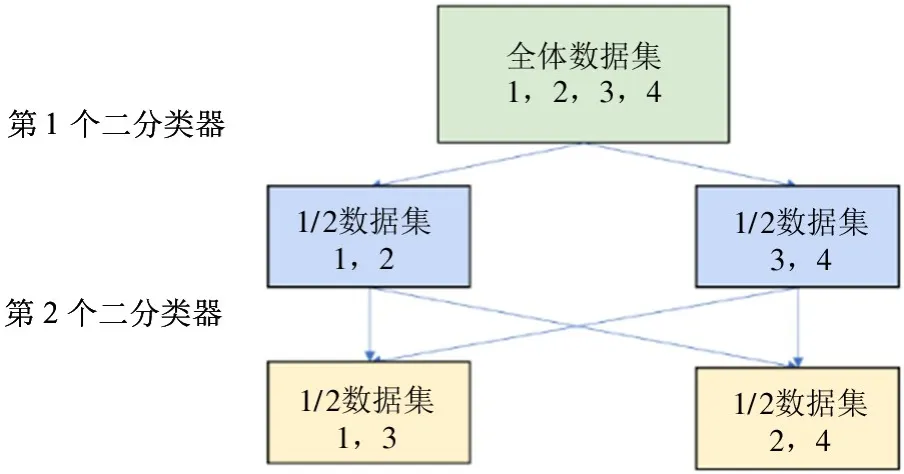
图13 改进的多个二分类器
(1) 对无法分类得出结果的数据再进一步分类。既然是不对应任何结果的情况,那么至少有一个分类器在分类时出现了错误。那么由多个二分类器构成的分类器则对这个数据不太适用,可以将这个难以识别的数据再放入多分类器进行判别。
(2) 对无法分类得出结果的数据不做处理,由于这个数据在某个网络中出现了错误,则多分类网络在处理这个数据的时候很可能会出现错误,实验中可再定义出一类记为无法判断,不做任何处理。
这2 种处理方法各有优劣,第1 种不会出现无法判断的情况,每一个数据都能给出一个结果,而第2 种方法简单高效,可以对复杂特征减少误判,后续的研究将对这2 种方案分别进行具体实验分析。
4 实验结果分析
4.1 AlexNet—实验结果分析
在训练皮肤病四分类(健康、银屑病、痤疮、白癜风)的CNN 时,首先尝试了卷积神经网络Alex-Net。数据集中的训练集每类包含682 个样本,测试集每类包含76 个样本,该卷积神经网络的四分类结果如表2 所示。综合实验结果计算得到网络的准确率是0.8750。
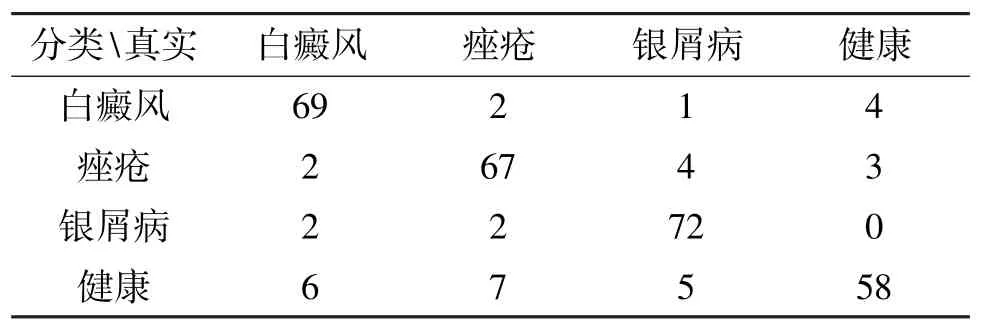
表2 AlexNet 网络四分类结果
为了提高准确率,将数据集随机分为三类(去掉健康皮肤的分类)和四类进行十折交叉验证,三分类实验结果为0.8202、0.8465、0.8596、0.8070、0.8356、0.8465、0.8421、0.8246、0.8133、0.8202,平均准确率为0.8320;四分类实验结果为0.9049、0.8721、0.9049、0.9114、0.9102、0.9245、0.9213、0.9245、0.9278、0.9235、平均值为0.9125。该实验表明实验结果过分依赖于数据集的选取,可能是数据集少,不完善所造成的结果。
为进一步提高准确率,实验随后使用了多二分类的方法,训练3 个二分类网络后,针对无法判断分类结果的数据再使用上述的四分类器,最终的实验结果如表3 所示,计算实验结果准确率为0.9177;如果将无法判断的部分不做处理,得到的结果如表4所示,计算实验结果准确率为0.9377。
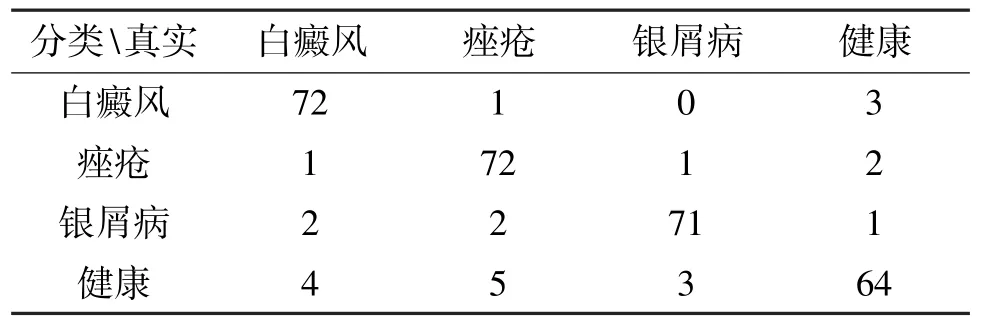
表3 AlexNet 多二分类和四分类实验结果
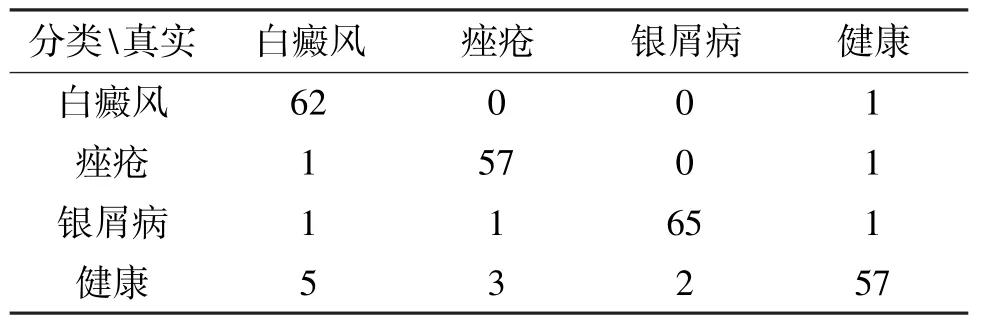
表4 AlexNet 网络多二分类实验结果
通过上面的结果可以发现,使用这个方法对结果的提升还是比较明显的,在舍弃数据的情况下也可将准确率提升至93%。
4.2 GoogLeNet-实验结果分析
在训练皮肤病四分类(健康、银屑病、痤疮、白癜风)的CNN 时,实验又尝试了卷积神经网络GoogLeNet,当使用GoogLeNet 网络时的四分类结果如表5 所示,计算实验结果准确率为0.8849。

表5 GoogLeNet 网络四分类结果
为进一步提高准确率,实验随后又使用了多二分类的方法,在训练3 个二分类网络后,针对无法判断分类结果的数据再运用四分类器,最终的实验结果如表6 所示,计算实验结果准确率为0.88196;如果将无法判断的数据不做处理,得到的结果如表7所示,计算实验结果准确率为0.9242。在运用GoogLeNet 进行测试后,发现在舍弃一部分数据后准确率仍能得到显著提高,即使舍弃数据仅占一小部分的比例。
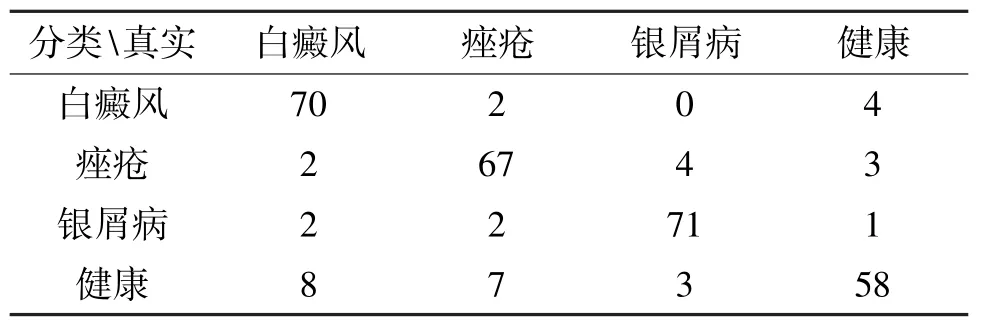
表6 GoogLeNet 多二分类和四分类实验结果

表7 GoogLeNet 多二分类实验结果
4.3 实验分析
综合来看,多二分类器下AlexNet 和GoogLeNet模型对于准确率的提升效果一致。与普通的分类器相比,多二分类器能够快速发现数据集的共同特征,在第1 种策略数据出错时至少要有2 个二分类器出错,降低了误判的概率,准确率会比直接运用四分类器时高。第2 种策略舍弃的那部分数据,必定是某个二分类器错判的数据,也是模型不易判断的数据,该部分数据在判断的时候准确率会较低,舍弃数据后准确率会得到提升。与使用AlexNet 的结果相比,GoogLeNet 的准确率反而较低,所以不是网络的结构越复杂,效果越好。GoogLeNet 虽然在结构上做了不少优化,但是其二十几层的深度要求更多的数据去训练,否则带来的过拟合现象会降低测试集的准确率,因为本实验数据相对较少,很容易出现过拟合现象。
5 皮肤病诊断
经过对图像块的分类,得到了对于每个图像块的疾病概率,需将图像的所有图像块信息进行整合以获取最终的分类结果。通过对图像块的疾病分类预测得到每个图像块对应的概率向量如下:
Patch 1: (P11,P12,P13,P14)
Patch 2: (P21,P22,P23,P24)
Patch 3: (P31,P32,P33,P34)
Patchn: (Pn1,Pn2,Pn3,Pn4)
其中P11、P12、P13、P14分别是第i个图像块被判别为健康、银屑病、痤疮、白癜风的概率。然后用式(2)分别算出当前患者患有银屑病、痤疮、白癜风的归一化概率。
将最大概率所对应的皮肤病类别判定为患者所患的疾病类型。图14 是运用混淆矩阵的方法来展示处理后的效果图。
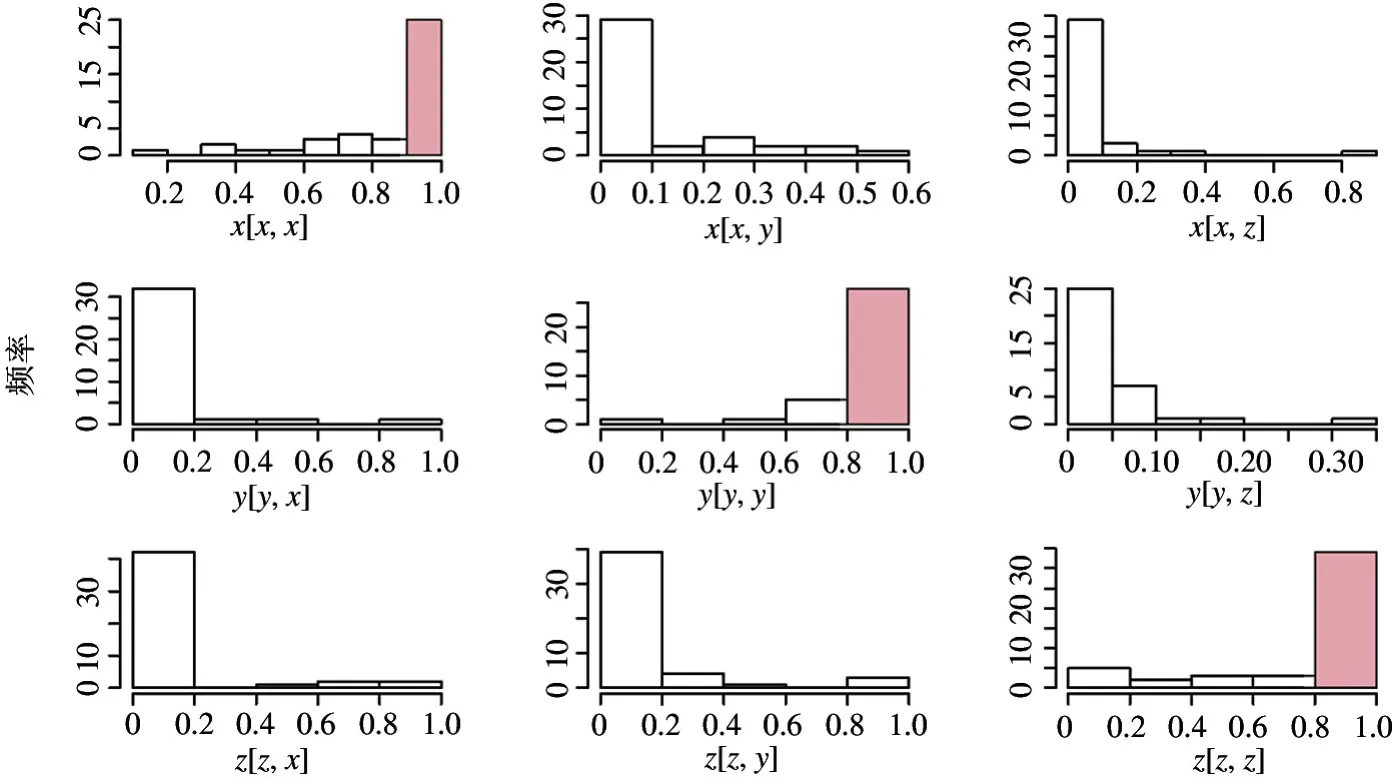
图14 皮肤病分类
其中(i,j) 位置上的图是实际第i类样本的图像块在第j类疾病上对应的概率累计值的统计直方图。通过观察(x,x)、(y,y)、(z,z) 位置上的直方图,每个样本值都较高并均接近于1,说明patches信息的整合是很有效的。
除了“混淆矩阵”的方法之外,本方法还采用了受试者工作特征(receiver operating characteristic,ROC)曲线来评价分类器的效果,如图15 所示。在ROC 曲线中代表白癜风的曲线与坐标轴围成的面积(即AUC 统计量)是0.9707;代表痤疮的曲线与坐标轴围成的面积(即AUC 统计量)是0.9668;表示银屑病的曲线与坐标轴围成的面积(即AUC 统计量)是0.9234。
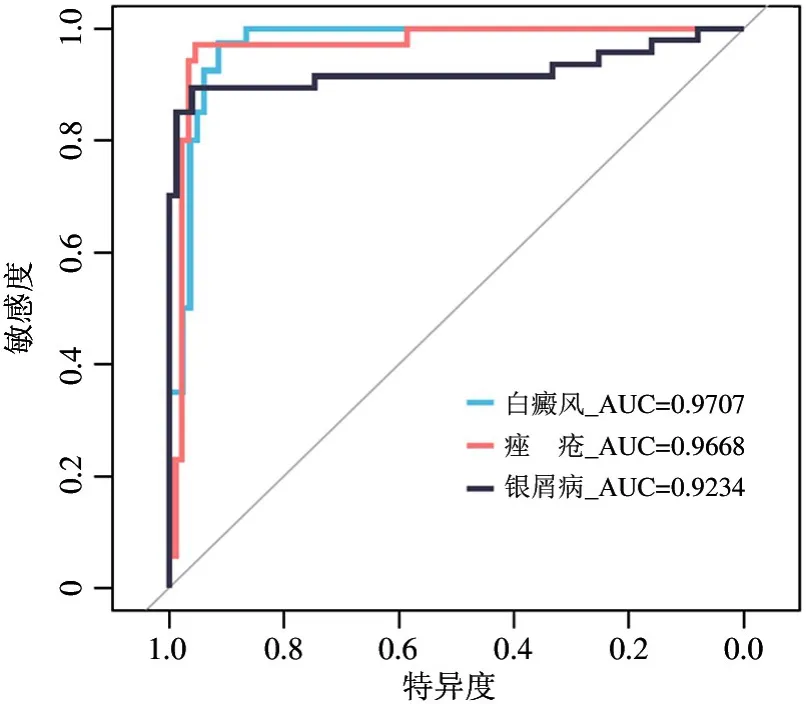
图15 ROC 曲线
对概率累计值取softmax 的诊断分类方法准确率可达到90.9836%,现实情况下,阈值的选取会影响分类器的真阳率(true positive rate,TPR)、假阳率(false positive rate,FPR),TPR、FPR 计算公式分别如式(3)、式(4)所示。
准确率并不是唯一的分类器评价标准。某些情况下TPR 和FPR 的重要程度不同,由于某一种错误判断需要承担的风险和代价很大,所以不能将提高诊断准确率作为唯一标准,得到高的TPR 才是至关重要。
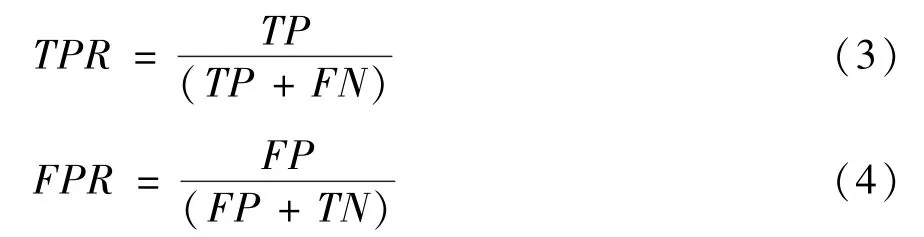
下图是在皮肤病分类诊断问题中,考察归一化的概率累计得分在阈值λ 变动下TPR、FPR 和TPRFPR 的变化如图16 所示(其中从上到下分别对应白癜风、痤疮、银屑病)。
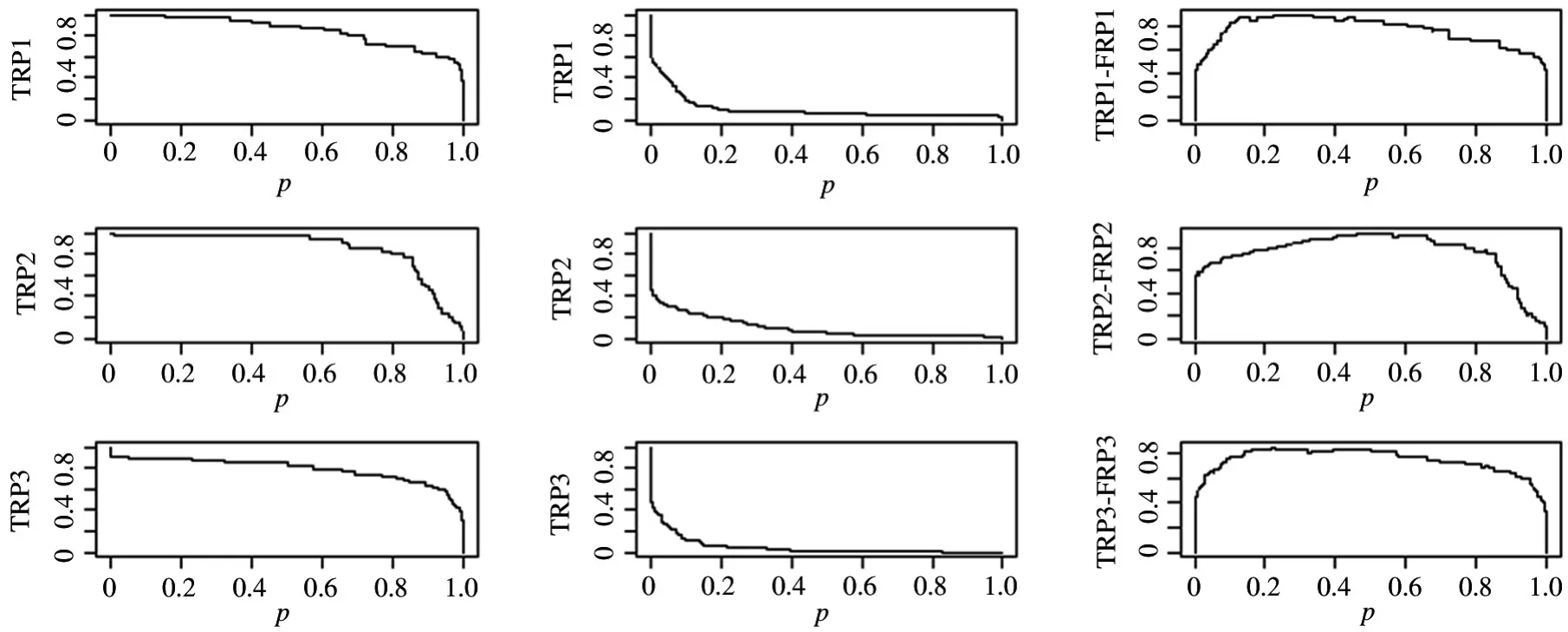
图16 TPR、FPR、TPR-FPR 变化曲线图
在现实问题中,可通过构造一个关于TPR、FPR的函数用优化方法确定阈值。记阈值为λ,目标是选取合适的阈值使得TPR 比较大并控制FPR,可如下表示:
maxλf(TPRλ,FPRλ)
其中f关于TPR 单调递增,关于FPR 单调递减,可以如式(5)所示。
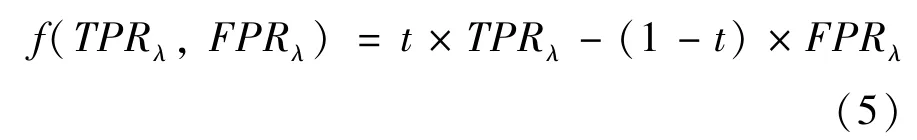
最佳阈值λ 的范围和参数t的函数关系如图17所示,其中两条线段分别是最佳阈值的上下界。
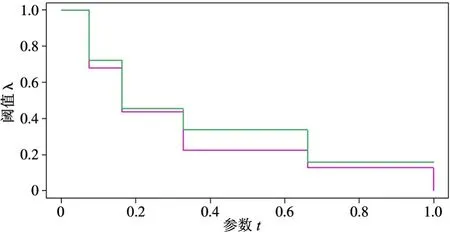
图17 最佳阈值变化折线图
6 结论
本研究构建了从原始的医学图像数据预处理到疾病分类判断的完整流程,并在三类常见皮肤病的诊断问题中得到检验。目前的工作仍存在很多问题与不足:(1)分类器过分依赖于计算资源;(2)使用的数据集过小,覆盖的疾病种类有限,过多的网络参数容易产生过拟合的问题;(3)基于图像的疾病分类判断未充分利用其他辅助信息,例如病人基本信息、化验信息等;(4)未使用三类常见皮肤病的分类结果来研究这些疾病间的联系。
数据驱动的医疗辅助诊断方兴未艾,相信在未来,随着联邦学习、集成学习等相关研究应用到医疗影像诊断领域中,其在保护数据隐私的前提下会取得更大的进展和应用。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
中国医学科学院学报(2015年5期)2015-03-01
中国当代医药(2015年32期)2015-03-01
中华皮肤科杂志(2014年4期)2014-12-19
中华皮肤科杂志(2014年3期)2014-12-19
