
基于DDPG 三维无人机路径规划①
2023-01-29 03:47:58司鹏搏杨睿哲孙艳华
高技术通讯 2022年10期
司鹏搏 吴 兵 杨睿哲 李 萌 孙艳华
(北京工业大学信息学部信息与通信工程学院 北京 100124)
0 引言
无人机(unmanned aerial vehicle,UAV)由于其体积小、成本低、环境适应力强等优点,获得了广泛关注,已被应用在目标追踪[1]、通信[2]、监测[3]、农业[4]、灾难管理[5]等方面。无人机在完成任务时,自主导航是实现对无人机控制的关键部分,因此,无人机路径规划是实现无人机自主飞行的重要因素。路径规划是确定无人机从起始点到目标点的路径,其目的不仅在于寻找最佳和最短的路径,而且还为无人机提供无碰撞的环境,并在运动动力学约束下优化给定的成本函数[6]。
近年来,对无人机路径规划的研究越来越多。无人机飞行路径规划是一个复杂的优化问题,需要考虑路径长度、时间消耗、能量消耗、障碍规避、鲁棒性等多个问题,文献[7]提出一种基于多宇宙优化器(multi-verse optimizer,MVO)的2D 无人机路径规划方案,将服务质量(quality of service,QoS)作为衡量路径优劣的指标,考虑多个无人机的协同工作与碰撞,同时也将最短路径与最短时间作为约束条件。文献[8]研究一种城市环境中无人机导航覆盖路径规划算法,考虑障碍物环境下无人机无障碍最短路径的路径规划,并探索不同障碍物形状对路径的影响。在实现无人机路径规划优化问题的探索中,研究学者提出了很多无人机路径规划算法,如A*算法[9]、人工势场[10]、线性规划[11]、随机树[12]等算法,但是,当无人机路径规划具有多个约束条件时,这些方法中的大多数都具有较高的时间复杂度和局部极小陷阱[13],且如果在大范围的环境下,计算压力也会急剧增加。
为了解决这些问题,将深度强化学习(deep reinforcement learning,DRL)算法引入无人机路径规划研究中。深度强化学习是将具有感知能力的深度学习与具有决策能力的强化学习相结合,所形成的一种端对端的感知与控制系统,使用函数拟合的方法对Q 表逼近,使其在高维环境下也有很好的效果,具有很强的通用性[14]。文献[15]研究搜索和救援场景中的无人机导航,提出扩展双深度Q 网络(double deep Q-network,DDQN)算法用于基于无人机捕获的图像来提高无人机对环境的理解,大幅减少了每个任务期间处理的数据量。文献[13]将环境建模为有障碍的三维环境,提出将强化学习算法与灰狼优化算法(grey wolf optimizer,GWO)结合的算法,并将路径规划分为搜索、几何调整和最佳调整三部分,解决局部优化中陷入困局和无人机路径规划不平稳的问题。文献[16]提出了一种快速态势评估模型,能够将全球环境状况转换为顺序的态势图,采用了决斗双深度Q 网络(dueling double deep Q-network,D3QN)算法,并将ε 贪心策略与启发式搜索规则结合选择动作,使用网格方法将动作划分为8 个离散的值。文献[17]用Q 学习算法,并将Q值基于表的近似和神经网络(neural network,NN)近似进行对比,而对于无人机的动作值同样需要离散化。以上深度强化学习算法的应用虽然都取得了良好的效果,但大多数算法都需要将动作空间离散化,这样就限定了无人机只能在特定几个方向进行转角与飞行,而在实际中无人机的飞行方向需是全方位的,且由于需不断躲避障碍物,其高度也不断变化,此时,再将动作值离散化会大幅增加计算负担。
本文研究复杂环境、连续空间状态下,无人机无碰撞的路径规划问题。首先,建立一种复杂3D 场景模型,将无人机任务过程划分为飞行、等待、通信3 个阶段;其次,提出一种无人机高度避障方法,引入偏离度δ 表示无人机与障碍物及目标用户的相对位置;最后,采用深度确定性策略梯度算法[18](deep deterministic policy gradient,DDPG)实现无人机路径规划,并与现有算法比较以验证提出方法的有效性。
1 系统模型
假设在一定区域的城市空间中,分布着如手机、电脑等智能用户,由于自然灾害、距离等原因,用户不能直接与基站通信,为保障灾后救援,满足用户需求,使用体积小、对环境要求低的无人机作为中继通信。无人机的飞行任务需满足以下约束。
(1) 用户(UEs)随机分布,且UEs 之间互联互通,每个UE 都能接收来自邻近UEs 的消息。
(2) UAV 从结束收集UE 数据到结束收集下一个UE 数据为一个飞行任务。
(3) UAV 在一个任务中能量充足,不考虑由于能量耗尽导致任务终止。
如图l 所示,包括1 个UAV 以及随机分布的N个UEs 和M个障碍物OBs 。当UE 有数据传输请求时,会向全网广播其位置信息。而位于UAV 通信范围内的UE 则会将其获得的具有数据传输请求的UE 位置信息传递给UAV 。UAV 获得数据请求信息后,利用深度确定性算法规划路径、规避障碍,向目标UE 移动并为其提供服务。UAV 服务完毕后,若无新的UE 数据上传请求,UAV 将悬停在此处,等待新的目标UE。实际情况中,UAV 由于体积小,搭载能量有限,UAV 需要在有限的能量限制下服务更多UE;同时,为满足用户的服务质量,需要在最短时间内完成飞行任务,并且避免与障碍物的碰撞。
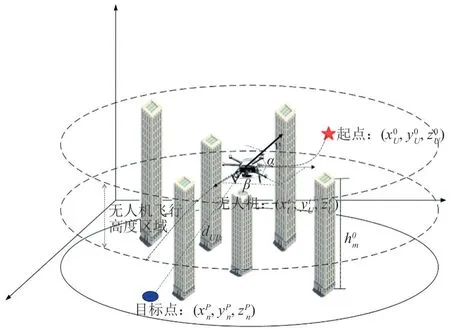
图1 无人机路径规划系统模型


2 无人机任务建模与分析
假设UAV 已完成UEs 中Pn-1的数据收集,正在等待或直接前往Pn收集数据,则无人机从Pn-1飞往Pn。
2.1 任务建模
2.1.1 飞行距离
t时刻UAV 到UE 的位移dUP为
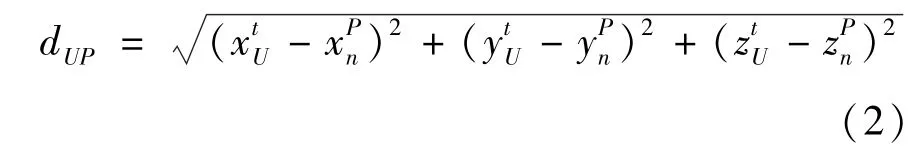
则,UAV 飞行的最短距离dmin为
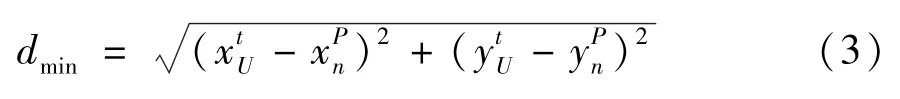
实际情况中,UAV 需躲避障碍,避免碰撞,UAV实际飞行距离dU满足:dU≥dmin。
2.1.2 俯仰角α 与偏航角β
UAV 的速度v与z轴的夹角为俯仰角α;UAV与Pn投影在xoy平面,UAV 的速度v与x轴的夹角为偏航角β,则:
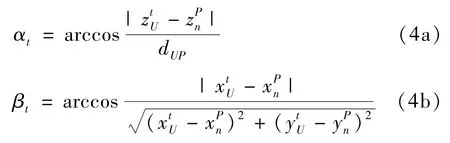
αt、βt分别为t时刻的俯仰角和偏航角。
UAV 在飞行中,α 与β 随UAV 速度的变化而不断变化,则α 与β 的变化有以下规律:

2.2 成本函数
2.2.1 障碍规避与目标抵达
UAV 在接收到Pn的位置信息后,在向Pn飞行的过程中,需要避开障碍,尽可能到达Pn上方接收数据,因此,引入偏离向量集Φ=,其中,辅助判断UAV 与障碍物是否碰撞,其中:

对于UAV 悬停位置的判断,引入目标偏离向量σP=(σPx,σPy),其中:

当UAV 到达目标UE 附近,为提高数据传输效率,则存在极小值ϵ(0 <ϵ <1),使得UAV 悬停位置满足以下约束条件:

2.2.2 任务时间
UAV 完成一个任务过程所需时间包括3 部分:飞行时间Tf、等待时间Tw、通信时间Tcom。
飞行时间Tf:UAV 从Pn-1出发至到达Pn耗费的时间,当UAV 以最大速度飞行最小距离时,耗费最短飞行时间为

UAV 在飞行中,为躲避障碍,需不断改变飞行方向及飞行高度,则飞行时间Tf满足:

等待时间Tw: UAV 等待下一个具有数据传输请求UE 出现的时间。
通信时间Tcom:UE 将数据传输到UAV 耗费的时间,在该过程中,数据接收率为R,则传输Dn数据量耗时为

综上,UAV 完成从Pn-1到Pn的数据收集任务耗费的总时间为
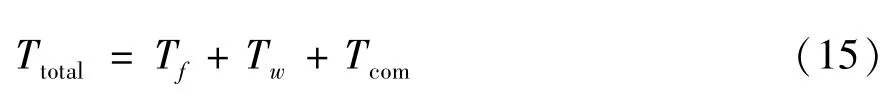
2.2.3 能量消耗
在一个数据收集过程中,耗能分为3 种,分别为飞行、等待、通信,各阶段耗能情况如下。
飞行能耗:每时隙耗能ef,耗时Tf,则总耗能为

等待能耗:UAV 悬停在UE 上方每时隙耗能ew,耗时Tw,则悬停总耗能为

通信能耗:每时隙耗能ecom,耗时Tcom,则通信总耗能为

综上,UAV 在一个任务中总耗能为
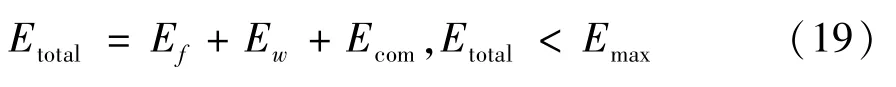
3 基于DDPG 的无人机路径规划
3.1 深度确定性策略梯度算法
深度确定性策略梯度算法适用于连续动作空间,包括Actor 网络和Critic 网络两部分,二者利用深度神经网络分别实现对策略和Q函数的逼近[20-21]。DDPG 的训练过程如下。
(1) Actor 网络在状态st下给出动作at=π(st),为了增加样本的随机性,会对Actor 网络给出的动作at=π(st) 增加一个随机噪声(使用Uhlenbeck-Ornstein 随机过程,作为引入的随机噪声)A,即行为动作φt=π(st)+A。
(2)动作φt作用于环境,DDPG 得到奖赏rt和下一个状态st+1,DDPG 将集合(st,φt,rt,st+1) 存储到经验缓冲区H。
(3)DDPG 从经验缓冲区随机选取大小为K的小批量数据集作为Actor 网络和Critic 网络的输入。
(4)在Critic 网络,目标Critic 网络利用式(20)根据小批量数据集计算累计奖赏更新:
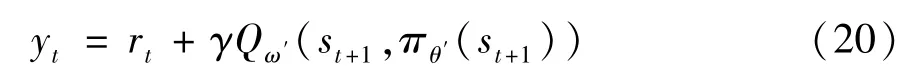
在线Critic 网络利用动作φt逼近目标Q值Qw(st,φt),并使用最小化损失函数式(21)进行在线Critic 网络的更新。
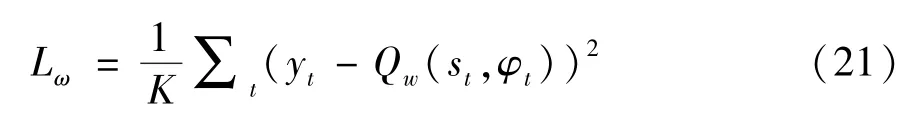
其中,ω 为在线Critic 网络的参数,ω' 为目标Critic网络的参数,πθ'(st+1) 为目标Actor 网络根据小批量数据集得出的下一状态的动作。
(5)在Actor 网络中,使用式(22):
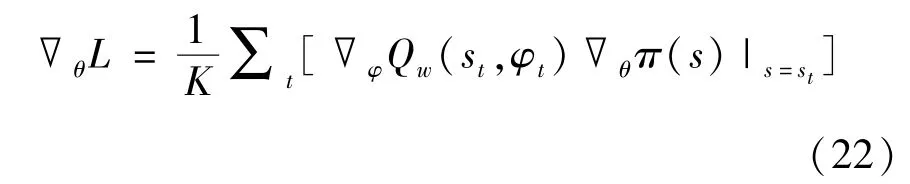
对网络进行更新,其中,θ 为在线Actor 网络的参数,θ'为目标Actor 网络的参数。
(6)通过步骤(4)、(5)分别对在线Critic 网络及Actor 网络参数更新,而目标网络的参数以一定的频率从在线网络复制更新,更新规则分别为式(23a)与(23b)。

3.2 基于DDPG 的无人机路径规划设计
本文针对连续空间内无人机路径规划,将适用于连续空间问题的DDPG 算法引入,以寻求满足优化目标的最优路径。

动作空间:t时刻分别在x轴、y轴、z轴方向的加速度,则t时刻的动作值为
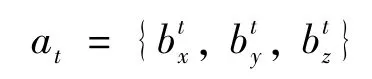
奖赏:合理的奖赏设置能够更加快速地训练出最优的策略。为使UAV 用最短时间、最小能量消耗到达目的点,同时避开障碍,以及更加接近目的点,则将奖赏划分以下几个部分。
障碍物奖赏robs:如果UAV 与障碍物的位置关系满足式(7)、(8)、(9),则robs=0,否则robs=,并且结束游戏。
路径奖赏rTE: 主要包括对路径中的时间及能耗的衡量。
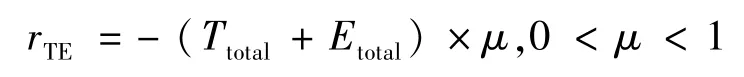
目的点奖赏rdes:衡量UAV 是否到达目的点完成任务,rdes=。
区域奖赏rb: 将UAV 限定在一定区域内,当UAV 飞出该区域,rb=。
综上,则t时刻总奖赏为式(24)。
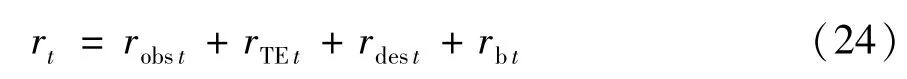
则基于DDPG 无人机路径规划算法(deep deterministic policy gradient algorithm UAV path planning,DDPG-UPP)具体内容如算法1 所示。


4 仿真分析
本部分将通过仿真评估算法DDPG-UPP 的性能,仿真环境使用Python 3.6、TensorFlow 1.12。本实验将模拟500 m×500 m×500 m 区域内无人机使用DDPG-UPP 算法从起点到目标点的路径规划情况,其中障碍物随机分布在该区域内。本文测试DDPG-UPP 算法的性能通过不同学习率性能比较、不同算法及不同维度路径规划的性能比较,从而获得最优学习率并验证DDPG-UPP 算法的最优性。仿真使用的各参数设置如表1 所示。

表1 仿真参数
算法1[22]采用演员评论家(Actor-Critic,AC)算法,并融合指针网络(pointer network-A*,Ptr-A*)进行无人机路径规划探索,将Ptr-A*的参数在小规模聚类问题实例上进行训练,以便在Actor-Critic 算法中进行更快的训练。
算法2[16]采用决斗双深度Q 网络D3QN 算法,同时使用ε-greedy 策略与启发式搜索结合选择动作,实现离散环境下无人机自主路径规划。
算法3 采用了策略梯度(policy gradient,PG),将策略表示为连续函数,并用梯度上升等连续函数优化方法寻找最优策略,有效弥补了基于值函数算法(DQN 等)适用场景的不足。
图2、图3 分别为在二维与三维环境下对无人机路径规划的效果采样图。图3 对三维环境无人机路径规划仿真实验中设置无人机与目标点的阈值为20,即当无人机在以目标点为中心、20 为半径的球形区域内时,可认为无人机到达目标位置。通过对比,在将环境从二维拓展到三维并不断增加障碍物数量的过程中,使用本文算法训练的无人机都能准确到达目标点,同时精准避开障碍物。
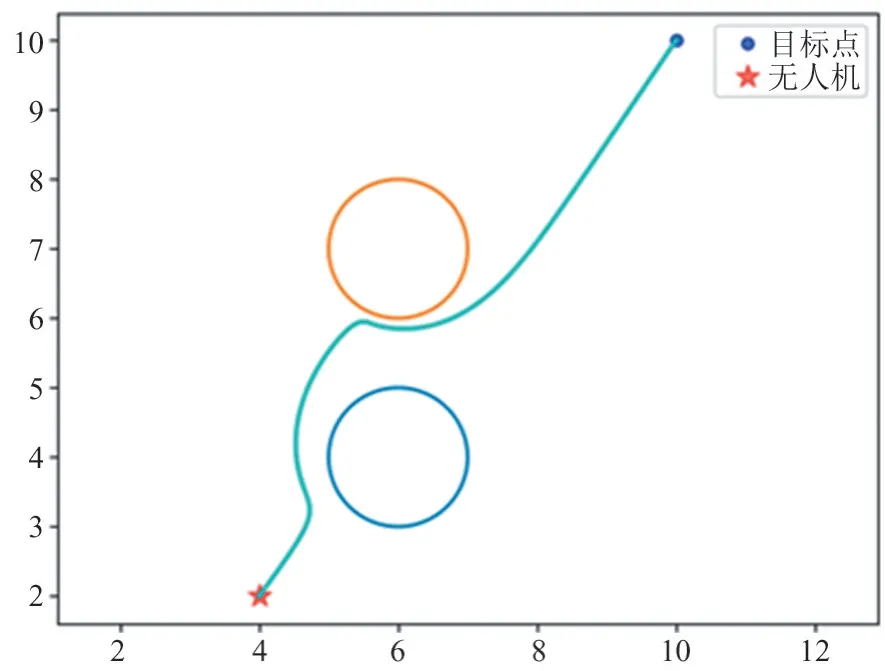
图2 二维场景路径仿真图
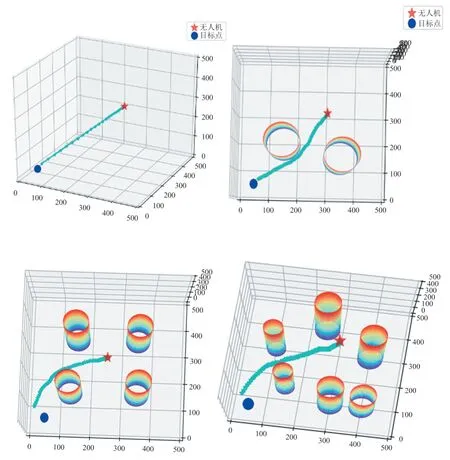
图3 三维场景路径仿真图
图4 展示了算法DDPG-UPP 在不同学习率下的性能评估。学习率决定着目标函数能否收敛到局部最小值以及何时收敛到最小值,合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。从图4 可以看出,当Actor 网络学习率为0.005、0.001,Critic 网络学习率为0.01、0.002 时,随着训练次数的增多,UAV 在不断试错过程中获得的奖赏会逐渐稳定,这表明UAV 学会到达目标点并满足约束条件的最优路径。同时,如图5 所示,UAV 到达相同的目标点所需要的步数也逐渐减小,并稳定到固定值,UAV 随着学习次数的增多,能够更加准确地到达目标点。而对于Actor 网络学习率为0.0005、0.0001,Critic 网络学习率为0.001、0.0002 时,奖赏值及到达相同目标所需的步数虽然也收敛到定值,但相较于a=0.005、c=0.01 与a=0.001、c=0.002 的学习率,此时算法的性能并未达到最优,无人机学习到的路径并不是最优路径。另外,当学习率为Actor=0.01、Critic=0.02 时,算法不收敛,无人机并不能学会到达目标的最优路径。因此,学习率的大小对算法DDPG-UPP 的性能至关重要,能指导UAV 在合适的时间找到最优路径。
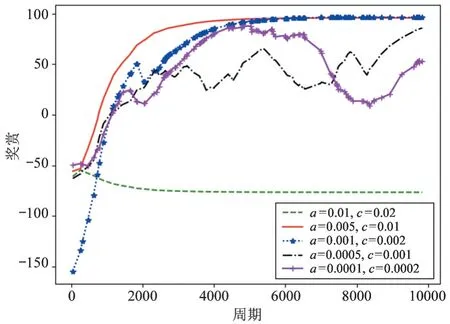
图4 不同学习率下算法DDPG-UPP 的性能对比图(Reward)
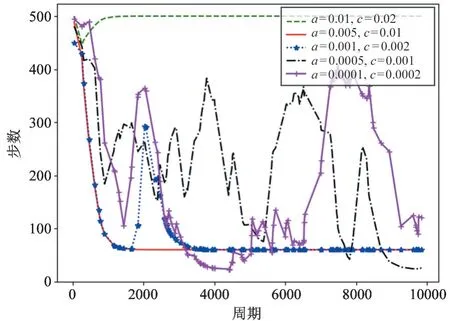
图5 不同学习率下算法DDPG-UPP 的性能对比图(Step)
图6、图7 分别为不同算法下无人机路径规划奖赏以及到达相同目标所需步数的对比图。将本文提出的DDPG-UPP 算法与算法1、算法2、算法3 的性能比较,如图6 所示,DDPG-UPP 算法用于UAV路径规划相较于算法1、算法2、算法3 收敛较快且获得的奖赏值也明显高于其他3 种算法,表明使用DDPG-UPP 算法获得的路径在能耗及时间都是最少的。这是因为算法2、算法3 适用于离散动作空间,UAV 在进行训练前需将动作空间离散化,而对于UAV 路径规划的动作空间,要想实现UAV 更加自主、高效动作,其离散动作空间复杂化,且在每一次训练中,无人机只能在特定的几个方向中选择,大幅降低了无人机的灵活性;其次,对于算法1,虽然Actor-Critic 算法可用于连续动作空间,但由于Actor 的行为取决于Critic 的值,Critic 难收敛导致Actor-Critic 算法很难收敛,尽管算法1 融入了指针网络Ptr-A*以加快Actor-Critic 算法的收敛,但相较于本文算法仍有很大差距。本文算法也采用Actor-Critic结构,但融入了深度Q 网络(deep Q-network,DQN)的优势,既解决了算法2 的空间离散问题,又区别于算法1、算法3 中Actor的概率分布输出,而是以确定性的策略输出加快了算法的收敛。因此,如图6、图7 所示,本文算法不仅能够使UAV 更快获得到达目标的最优路径,而且使得无人机能耗及时间都是最小的,同时能在到达相同目标时使用更少步数。
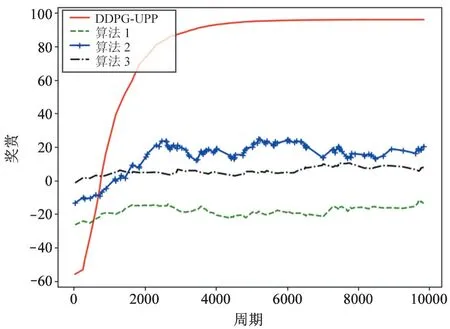
图6 不同算法下无人机路径规划性能对比图(Reward)
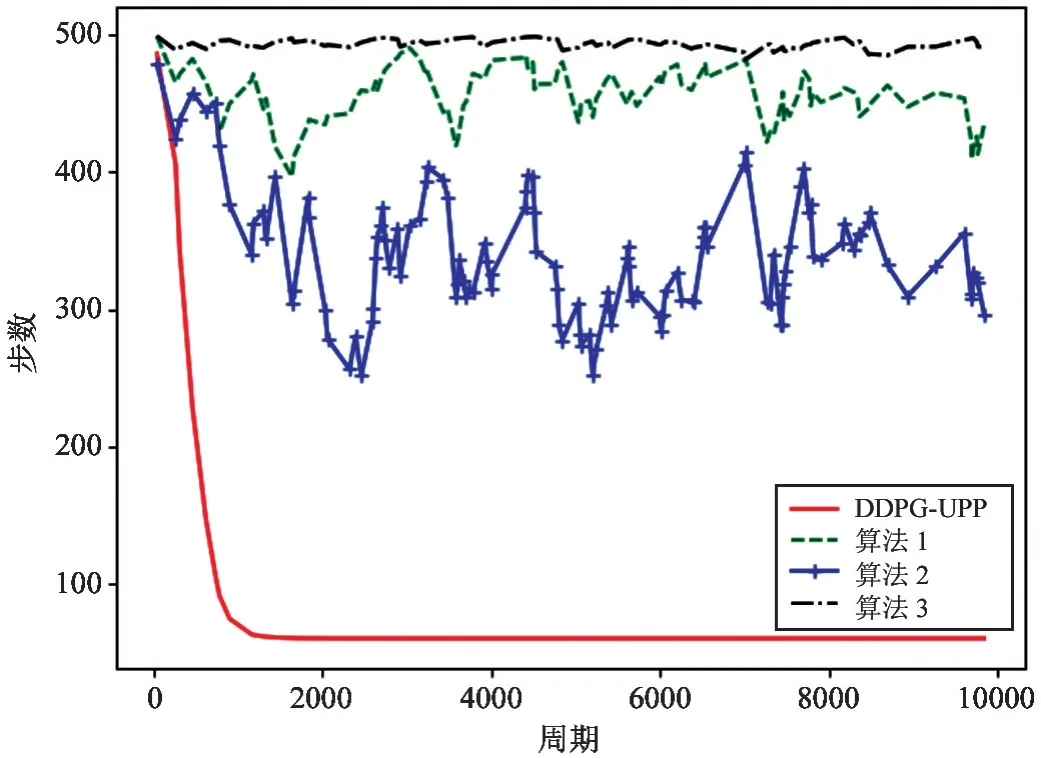
图7 不同算法下无人机路径规划性能对比图(Step)
图8 为二维环境与三维环境下分别使用DDPGUPP 算法与算法2 的性能对比图。首先,图8 显示无论是二维环境还是三维环境,使用DDPG-UPP 算法的性能都要优于使用算法2。这是由于算法2 虽然改变了DQN 的模型结构,但仍需将动作空间离散化,而针对本文无人机飞行环境,则至少需要将动作空间离散为6 个维度,在每一次试错中,相较于本文算法,算法2 都增加了试错成本,同时也增加了计算复杂度,从而增加了无人机探索最佳路径的难度;其次,DDPG-UPP 算法在无障碍环境中的奖赏值要高于有障碍环境,且较有障碍环境更快收敛,这是因为环境中的障碍会在一定程度上阻碍无人机的探索,无人机需进行更多次尝试才能学习到最优路径;此外,对于本文算法,在同时考虑障碍物的环境下,在三维环境中的性能也要明显优于二维环境。综上,本文算法在三维环境避障路径选择中相较于其他算法具有更优的性能。
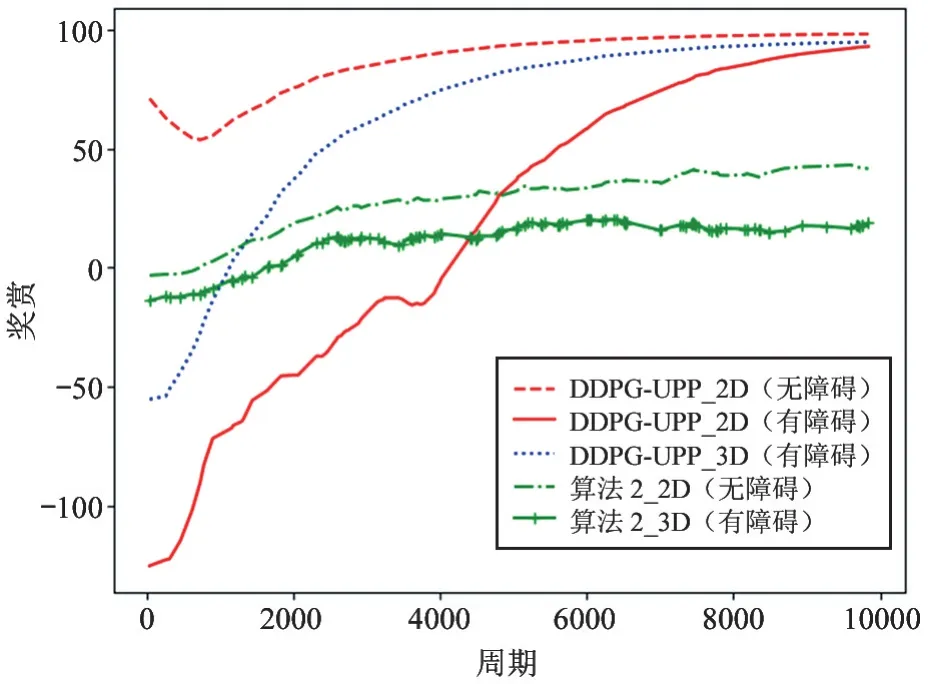
图8 不同维度下无人机路径规划性能对比图(2D 与3D)
5 结论
本文研究了一种三维复杂环境下无人机路径规划方法,提出一种无人机高度避障方法,引入偏度δ表示无人机与障碍物及目标用户的相对位置,使UAV 能够更加自主、灵活地避开障碍,更加适应UAV 实际工作环境。另外,考虑UAV 动作空间的连续性,采用深度确定性策略梯度算法进行无人机路径规划。实验结果表明,本文算法能够克服传统算法需将动作离散化的弊端,增加了环境适应性。
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
动漫界·幼教365(中班)(2020年3期)2020-04-20 11:03:27
铁道通信信号(2020年9期)2020-02-06 09:15:54
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
领导决策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
中国卫生(2016年2期)2016-11-12 13:22:16
中国工程咨询(2016年4期)2016-02-14 07:28:28
