
在线社交网络中基于机器学习的多维用户信任评估方法
2023-01-19 10:07张欣欣周赵斌
福建师范大学学报(自然科学版) 2023年1期
周 峤,张欣欣,周赵斌,许 力
(福建师范大学计算机与网络空间安全学院,福建省网络安全与密码技术重点实验室,福建 福州 350117)
随着移动互联网技术的发展,Facebook、Twitter、新浪微博等在线社交网络(OSNs)已经成为人们生活中不可或缺的一部分.如此庞大的用户群体中蕴含了一定比例的不可信用户,他们会在网络中发送大量垃圾信息,以达到虚假广告宣传、诈骗等目的[1].这类行为不仅影响了普通用户的使用体验,还会加重网络负载、降低平台公信力,最终导致大量用户流失.
为了避免上述情况的发生,如何检测网络中的不可信用户成为了一个重要的研究课题.信任作为人际交往中的重要依据,很自然地被引入到以人为主体的OSNs中[2].现有的信任评估方法大致可分为信任传递和信任建模[3].
信任传递通常基于图论,研究如何在用户间传递信任.Avesani等[4]通过迭代计算不同跳数用户的信任值获得一张信任网络图.Wang等[5]将信任传播与流体运动相类比,估计出用户能够接收到的信任值.但这类方法存在着一些问题待解决:如何选取合适的路径、确定路径长度、聚合用户信任值以及解决传播过程中的衰减问题等[6].
信任建模则重点关注用户自身,试图从用户的相关数据中提取出有效的特征来评估用户的可信程度[7].Liu等[8]根据用户间的交互行为来评估用户是否可信.Nepal等[9]通过聚合其他用户对目标用户及其所在社团的信任生成最终的信任评估结果.但是此类方法中特征的权重值往往是固定的,并且需要依靠方案设计者的经验进行设置,因而无法根据环境变化自动调整,而这与OSNs的动态性相悖.
机器学习作为一种能够根据输入数据智能建立数学模型的方法,能够很好地解决特征权重设置的问题[10].Sadiq等[11]考虑了包括粉丝数、好友数在内的多项特征,用于评估用户的信任程度.但是该方法没有考虑用户之间的关系,而在OSNs中用户关系相关的特征能够用于获取更多有用的信息.Chen等[12]考虑了多种用户属性以及用户之间的关系,提出了进行信任评估的机器学习框架.但其提出的特征中包含大量需要迭代计算的全局性特征,而在拥有海量用户且动态变化的OSNs中计算这些特征会造成较大的系统开销.
还有一些学者选择使用深度学习的方法来进行信任评估.C-DeepTrust[13]将用户评级、用户评论、用户偏好等信息输入到多层神经网络中,并通过输出的上下文感知相似度来判断用户之间的信任关系.TrustGNN[14]将信任的传播性和组合性整合到图神经网络中以进行信任评估.但这些方法没有深入挖掘用户自身的信任特征,最终结果也只能反映两两用户之间的信任关系,无法对用户的身份进行判断.
为了应对上述挑战问题,本文提出了一种基于机器学习且考虑多维特征的用户信任评估方法MDTrust.该方法首先从用户的历史数据中提取出4类共13项特征,以充分模拟现实中的信任建立过程.其次,考虑到在具有海量数据的OSNs中获取全局性特征的计算开销,本文提出了名为最大平均值对数误差的特征计算方式,用来计算用户的局部性特征以代替全局性特征进行用户信任评估.该方法使用6种机器学习模型,对所提出的特征权重进行自动学习.在真实的Twitter数据集上进行实验的结果表明,MDTrust使用最大平均值对数误差计算得到的特征在识别不可信用户方面能够取得很好的效果,各项评估指标的结果均高于同类型的其他方法,并且识别效果不会随着用户数量变化而波动.
1 提出方案
1.1 问题描述
用U={u1,u2, … ,un}表示OSNs中的用户,用F={fg11,…,fg1l1,…,fgk1,…,fgklk}表示从用户数据中提取得到的特征,其中gi表示第i类特征,li表示第i类特征的数量.本文将用户信任评估定义为二元分类问题,即对于用户un而言,其信任值tn要么为0,要么为1,对应用户身份可信和不可信2种情况.其计算方法可表示为tn=Φ(Fn),Φ(·)为选择的机器学习模型.本文使用监督学习的方法训练模型,因此每名用户的信任值tn是已知的,模型的目标是根据提取出的用户特征准确预用户对应的信任值.
1.2 特征选取原则
在定义特征时遵循以下原则.
(1) 关注相对值而非绝对值.不可信用户可以通过修改自身数据以达到伪装身份的目的,但无法获得网络中所有用户的数据,因此修改后的数据仍会表现出与普通用户之间的差别.
(2) 关注平均值而非最值.最值可能会使系统错误地将某条异常信息作为评价用户身份的特征.而平均值更偏重于考虑用户以往所有的行为,并能降低异常值的影响.
(3) 摒弃全局性特征.考虑到OSNs中的海量数据,选用需要迭代计算的全局性特征会造成高昂的计算与存储开销,因此本文仅选择用户的局部性特征进行信任评估.
基于以上原则,本文参考文献[12],定义了一种名为最大平均值对数偏差的特征计算方式
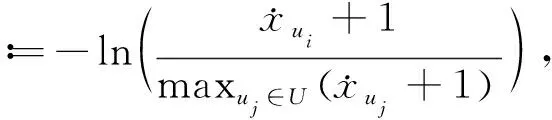
(1)

1.3 特征定义
1.3.1 基于用户个人资料的特征
如果一个用户的个人资料越完整,就越容易获得其他用户的信任,因此用户个人资料中的相关信息能够帮助判断一个用户的可信程度.方法定义了3项基于用户个人资料的特征.
(1)个人资料完整度分数
经常使用OSNs的用户会对其个人资料进行个性化设置,而不可信用户则通常不会去完善个人资料.本方法定义了衡量个人资料完整度的6个要素.
对于用户名、用户头像和个人资料背景图,如果用户进行了个性化设置,则将对应分值记为1;若使用的是系统默认设置,则将对应分值记为0.
对于用户的个人简介、简介中包含的网址链接和用户所在的地理位置,如果用户填写了相应内容,则将对应分值记为1;若内容为空则将对应分值记为0.
用户ui的个人资料完整度分数可通过以上6个值取平均值得到.个人资料完整度分数越高,表示该名用户对自己的资料进行了详细的设置与完善,其可信程度也就越高.
(2)社团多样性偏差
可信用户会加入感兴趣的社团,与志趣相投的其他用户讨论同样的话题,而不可信用户则不会花时间在这项活动上[15].公式(2)定义了社团多样性偏差(CDD)用于衡量用户加入社团的丰富程度.
(2)
其中#coms(ui)表示ui加入的社团数量.用户加入的社团越多,其可信度相对来说也会越高.
(3)账户创建时间偏差
一个账户创建的时间越久,使用该账户的用户的可信程度就越高,因为这意味着该用户之前未发生过恶意行为,否则其账户很可能被封禁.而大多数不可信用户的账户都是新创建的,因此两者在账号创建时间上存在差异.公式(3)定义了账号创建时间偏差(ATD)来衡量这种差异.
(3)
其中days(ui)表示ui的创建天数.用户账户创建的时间越久,说明其可信程度越高.
1.3.2 基于用户发布内容的特征
用户发布的内容中具有丰富的信息,这些信息能够帮助衡量用户的可信程度.本文定义了4项基于用户发布内容的特征,以捕捉可信用户与不可信用户在发布内容上的差异.
(1)内容标签数偏差
用户在发布内容时会加上标签以表明内容所属的话题,这样能够使得自己发布的内容很快被搜索到.而不可信用户在发布内容时往往不会加上标签,因为这样可能会导致内容被举报的概率增加[16].公式(4)定义了内容标签数偏差(TND)用来衡量两类用户在内容标签数上的差异.
(4)

(2)用户提及数偏差
可信用户使用OSNs的目的之一就是与好友进行交流,而不可信用户则很少进行这类社交行为,因此发布内容中的@数会明显多于不可信用户. 公式(5)定义了用户提及数偏差(UMD).
(5)

(3)URL数量偏差
不可信用户通常会在发布内容中加入URL以吸引用户点击,从而达到窃取用户隐私信息、网络诈骗等目的[17].而普通用户发布的内容中通常不会包含URL链接,因此两者在该项特征上存在差异. 公式(6)定义了URL数量偏差(UND).
(6)

(4)内容长度偏差
通常高质量的内容其长度会更长,而可信用户发布的内容质量普遍高于不可信用户,因此两者在内容长度上存在差异. 公式(7)定义了内容长度偏差(CLD).
(7)
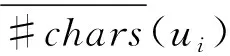
1.3.3 基于用户反馈的特征
点赞、转发、评论等反馈行为可以反映出OSNs中其他用户对某位用户的态度,因此该类特征可以帮助平台进行用户信任评估. 本文定义了3项基于用户反馈的特征.
(1)转发次数偏差
优质的内容会通常得到大量转发,并且它们的创作者基本上都是可信用户. 而不可信用户发布的内容往往不会得到转发. 公式(8)定义了转发次数偏差(SND).
(8)
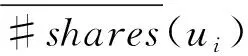
(2)点赞次数偏差
高质量的内容往往会获得更多的点赞数. 如果1名用户获得的点赞数很多,那么他很有可能是一名可信用户. 公式(9)定义了点赞次数偏差(LND).
(9)

(3)评论次数偏差
大多数用户倾向于回复高质量的内容以及与熟悉的用户互动,因此可信用户收到的评论数会多于不可信用户. 公式(10)定义了评论次数偏差(RND).
(10)

1.3.4 基于用户关系的特征
用户之间的关系蕴含着丰富的信息,可信用户与不可信用户在用户关系上存在着差异,这些信息能够帮助我们评估用户的可信度. 本文定义了3项基于用户关系的局部性特征进行用户信任评估.
(1)关注数-粉丝数比率
关注数和粉丝数是衡量OSNs用户可信度的重要指标. 不可信用户往往不会拥有很多粉丝,并且会尝试关注很多用户以提升在他人眼中的可信程度[18].公式(11)定义了关注数-粉丝数比率(FFR).
(11)
其中#friends(ui)和#followers(ui)分别表示ui的关注者数量和粉丝数量. 通常不可信用户的粉丝数很少,而关注数很多,因此FFR值会大于不可信用户[16].
(2)网络知名度偏差
一个用户的粉丝数可以反映该用户的知名度. 虽然不可信用户可以通过购买虚假粉丝的方式增加粉丝数,但与整个OSNs中知名度高的用户相比,两者粉丝数的差距仍然很大. 公式(12)定义了网络知名度偏差(NRD),用于衡量用户ui和OSNs中最受欢迎的用户之间粉丝数的差异.
(12)
(3)互相关注比率
OSNs中相互关注比单向关注更能够反映用户之间的互相信任. 不可信用户无法控制其他用户关注自己,因此双向关注数较少[15]. 公式(13)定义了互相关注比率(MFR).
(13)
其中fol(ui)表示ui的粉丝数. 一个用户拥有的互相关注数多,说明其在OSNs的好友数多,这能够从一定程度上反映出他人对该用户的信任程度.
1.4 基于机器学习的信任评估框架
MDTrust流程框架分为数据收集模块、特征选择模块和机器学习模块(图1).数据收集模块负责从OSNs中收集计算特征需要的相关数据,并发送给特征选择模块进行处理;特征选择模块是整个框架中最重要的部分,其收到原始数据后,会根据本文定义的特征计算方式从原始数据中提取出一共4类13项特征;得到的特征会作为机器学习模块的输入,用来训练能够有效区分可信用户与不可信用户的机器学习模型,模型会自动学习特征的重要性,并自动分配特征的权重.训练完毕的模型会投入到OSNs中进行网络中的用户信任评估.

图1 基于机器学习的信任评估框架Fig.1 The trust evaluation framework based on machine learning
2 实验分析
2.1 评价指标
在本文中,假阳性(FP)和假阴性(FN)分别代表被错误识别为不可信用户的可信用户以及被错误识别为可信用户的不可信用户,而真阳性(TP)和真阴性(TN)分别代表被正确识别的可信用户和不可信用户.本文采用了机器学习中常用的5项评价指标用于评估方法效果,分别是正确率(Accuracy),精度(Precision),召回率(Recall),F1分数(F1-Measure)以及马修斯相关系数(MCC).
(13)
(14)
(15)
(16)
(17)
2.2 数据集介绍
实验中所采用的数据集是由Cresci等发布的Twitter数据集[19].该数据集最初用于检测Twitter中的虚假用户.表1给出了数据集的具体构成.
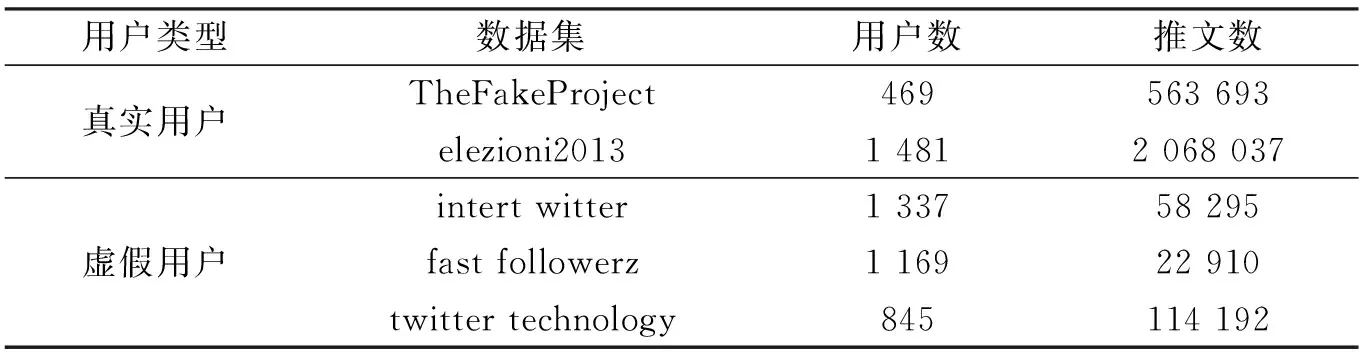
表1 Twitter数据集介绍Tab.1 Description of Twitter dataset
2.3 对比方法
本文将MDTrust与其他基于机器学习的信任评估方法[11-12]进行了比较.文献[11]提出了包括好友数、粉丝数在内的一共14项特征,用来区别普通用户和不可信用户,但是该方法没有考虑用户关系以及用户反馈行为相关的特征;文献[12]与本文类似,从多个维度提取了与信任相关的12项特征,但是该方法提出的特征大多数都是基于数据的最值计算得出的,这种计算方法会导致最终得到的特征容易受到异常值的影响,进而影响最终的判断;并且该方法包含需要迭代计算的全局性特征,这对于具有海量数据并且经常动态变化的OSNs而言会造成较大的计算开销.
2.4 实验结果分析
实验采用了基于Python语言的机器学习库scikit-learn,用于展示本文基于最大平均值对数偏差得到的特征集合与其他特征集合在不同机器学习模型上的结果差异.本文首先将完整数据集划分为不同大小的子集,每个子集中的可信用户数量相同,通过随机选择算法增加不可信用户的数量,使得每个子集中不可信用户数量占比分别为10%~60%,以评估MDTrust在面对不同比例的不可信用户时的表现.最后评估MDTrust在完整数据集上的效果.本文对每组数据进行了5次5折交叉验证用来训练和测试不同的机器学习模型,并将5次验证的平均值作为最终的结果.
图2—图7展示了MDTrust与其他基于机器学习的用户信任评估方法在逻辑回归、支持向量机、朴素贝叶斯、贝叶斯网络、决策树、随机森林6种机器学习模型下,面对不同占比的不可信用户时的分类正确率.可以观察到,对于选用的所有机器学习模型,MDTrust的正确率都要高于其他2种方法.这意味着本文提出的最大平均值对数偏差能够很好地区别可信用户与不可信用户;此外,MDTrust在面对占比为10%~60%的不可信用户时依旧能够保持比较稳定的正确率,这说明MDTrust中的局部性特征效果良好,因此本方法不太会受到OSNs中不可信用户数量的影响.对于逻辑回归模型,当不可信用户占比为20%时,Chen[12]提出的方法与本方法的正确率接近.当占比增加时,Chen的方法和MDTrust在正确率的差距不断增大,直到不可信用户占比为60%才有所回升,这可能是因为Chen的方法中包含部分全局性特征,这些特征在用户数量较少时不能发挥其作用,而MDTrust所提出的用户关系局部性特征的效果则不会受到用户数量影响.Sadiq[11]的方法与MDTrust的正确率一直有较大差距,这可能是因为其方法只考虑了用户相关的特征,而忽视了用户关系相关的特征对于用户信任评估的作用,并且这些特征都是通过直接计算绝对值得到的,而本文充分考虑了包含用户关系在内的4类特征,并且提出的最大平均值对数偏差消除了绝对值对结果的影响.对于其他5种机器学习模型,MDTrust的正确率都要高于对比方法.MDTrust在面对不同情况时正确率的波动幅度均维持在3%以内.可以说MDTrust在识别用户身份时正确率优秀且稳定.

图2 使用逻辑回归模型的正确率Fig.2 Accuracy on logistic regression model

图3 使用支持向量机模型的正确率Fig.3 Accuracy on support vector machine model
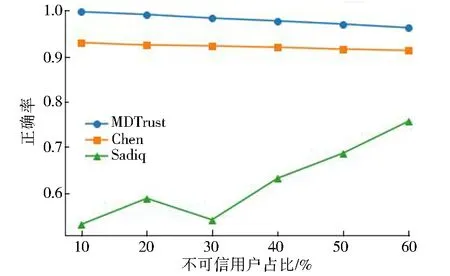
图4 使用朴素贝叶斯模型的正确率Fig.4 Accuracy on naive Bayes model
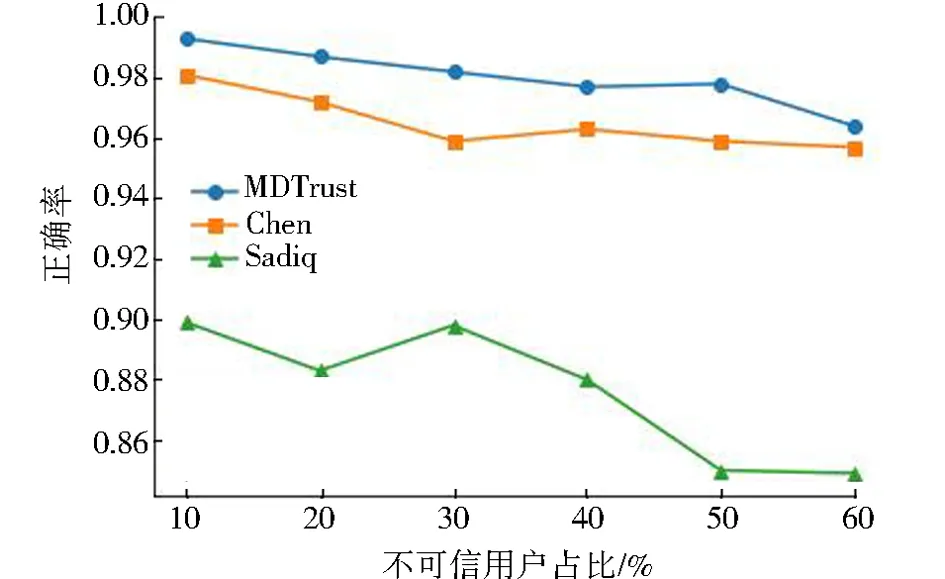
图5 使用贝叶斯网络模型的正确率Fig.5 Accuracy on Bayesian network model
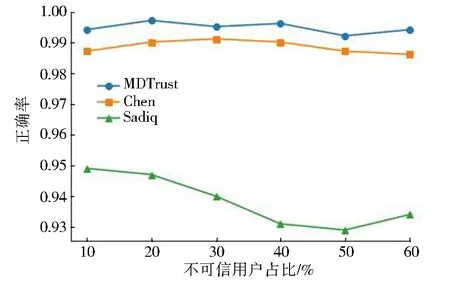
图6 使用决策树模型的正确率Fig.6 Accuracy on decision tree model

图7 使用随机森林模型的正确率Fig.7 Accuracy on random forest model
3种方法在完整数据集上的结果如表2所示,粗体表示每项指标的最优值.MDTrust在所有指标上都要优于另外2种方法,其中使用随机森林模型能够得到最高的正确率,这说明MDTrust使用最大平均值对数偏差计算得到的特征能够准确地区分出可信用户和不可信用户.

表2 完整数据集上的测试结果Tab.2 Results on the full dataset
3 结论
本文提出了一种基于机器学习的多维信任评估方法MDTrust.该方法首先定义了最大平均值对数偏差用以从OSNs的用户数据中计算特征.其次,本方法从多个维度出发,提取出一共4类13项与信任相关的特征,以模拟现实中信任的建立.考虑到OSNs的海量数据和动态性,MDTrust仅使用局部性特征进行信任评估.MDTrust使用了6种不同的机器学习模型,以评估提出的特征识别不可信用户的效果.在Twitter数据集上进行的实验结果表明,MDTrust不仅能在正确率上取得最好的效果,在其他指标上的表现也是最优的.这说明MDTrust能够有效地区分可信用户与不可信用户.
猜你喜欢
中华养生保健(2020年7期)2020-11-16
学生天地(2020年6期)2020-08-25
数学年刊A辑(中文版)(2020年2期)2020-07-25
桃之夭夭B(2017年2期)2017-02-24
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
故事会(2016年15期)2016-08-23
系统医学(2016年8期)2016-02-20
高中生·青春励志(2014年11期)2014-11-25
空间控制技术与应用(2010年3期)2010-12-23
