
Matlab平台下语文教材选文推荐的算法分析
2023-01-18 05:54:58赵向军
南京晓庄学院学报 2022年6期
郭 娜,赵向军
(1.江苏师范大学 信息化建设与管理处,江苏 徐州 221116;2.南京晓庄学院,江苏 南京 210017)
教学是学校教育的核心,教材是教学的主要依据,是师生相互作用的桥梁,更是学生吸收科学文化知识、启迪智慧、培养能力的源泉.其中,语文教材肩负着传播文化知识和培养学生语言能力的重任,开发和利用丰富多彩的语文课程资源是充实课程内容,提高教学质量的关键.
虽然计算机技术及众多相关应用已普及教育领域,但关于教材选编的研究仍停留在理论方面,语文教材的选编工作也多选用人工收集、过滤和编排的方式.于是,一些问题随之产生:(1)语文教材选编时间长,过程耗时耗力.(2)编写一旦完成就难以改动,易导致内容陈旧,缺乏时代感.(3)过于依赖人的经验,缺乏量化指标的参与.在大数据时代,互联网上的汉语言教学素材不断涌现,为素材需求者提供了丰富的资源.如若充分利用这些海量教学素材,定时更新学生使用的语文教材,有益于增强教材内容的时代感.但不可避免的是,急剧增的教学素材也诱发了资源过载问题,如何从丰富的文本类汉语言教学素材中,依据规范的准则,设计自动化或半自动化的推荐方法,快速挑选出优质的教学素材是一个值得研究的问题.
为此,本文广泛收集学生经典读物,通过分词、词频统计、词量化和文档量化等操作形成文本库.同时,分析教材选文依据,设计选文推荐算法,保证语文教材在词汇上具有连续性、顺序性、重复性和整体性特征.
1 文档的矩阵表示
文本类教学素材在计算机领域被称为文档,要想让计算机高效地处理文档,就必须设计出一种理想的文档表示方法,这个设计过程被称为文档建模.文档建模既要能真实地反映文档的内容,又要能区分不同文档.
1.1 词的向量化
词的向量化是文档量化表示的前提.词的向量化是将自然语言中的词映射成向量,主要有2种表示方式:第一种是one-hot representation方式.第二种是Distributed representation方式,最早由Hinton[1]提出.分布式表示是将词汇量化到一个维数固定的实数空间中,相对于第一种表示方式,该空间中的词向量具有低维、密集的特点.对于语义越相近的词汇,其在向量空间中的距离也相对接近,很好地克服了one-hot representation方式的缺陷.
获取Distributed representation形式的词向量的方法有很多,包括LSA、LDA 、神经网络和word2vec工具等.其中,由google在2013年提出的word2vec工具因具有良好的量化效果而被广泛使用.Word2vec是由Mikolov通过借鉴NNLM(Neural Network Language Model)[2]以及Log_linear模型[3]提出的,它利用词的上下文信息将一个词转化成一个低维实数向量,具有高效便捷的特点.Word2vec包含两种不同的模型,其中CBOW模型的目标是利用当前词语的上下文来预测当前词语的概率.当利用词向量表示一个词时,可以发现类似这样的规律:“king”-“man”+“woman”=“queen”,由此说明了词向量强大地表达语义的能力.
1.2 文档的特征选取及量化表示
用于表示文档的基本单位通常称为文档的特征或特征项.目前中文文本量化多采用词作为特征项,称作特征词.用特征词表示文档,可计算文档与文档间的相似度,然而,如何选取文档的最佳特征词是量化文档的关键点.
本文采用文档频数法(Document Frequency,DF)进行文档特征选取.文档频数是最为简单的一种特征选择算法,它指的是在整个数据集中有多少个文档包含这个单词.在训练文本集中对每个特征计算它的文档频数,若该项的DF 值小于某个阈值则将其删除,若其DF值大于某个阈值也将其去掉.
常用的文档表示模型有词袋模型(Bag of Word,BOW)[4]和向量空间模型(Vector Space Model,VSM)[5].在词袋模型中,文档被表示为一组词汇的无序集合,词汇之间相互独立,特征维数较高,且忽略语法和语义信息.向量空间模型较为灵活,它以词汇的统计信息作为特征权值,相对于词袋模型来说,它所建模出的文档向量的维度有所降低,但仍然无法处理文档中词汇的语义联系.为此,本文基于词向量提出了文档的矩阵表示方法,矩阵中的行向量对应文档的特征词,行与行的角距离表征了特征词之间的某种联系.该种表达方式充分利用了文档中每个词汇所表达的信息内涵,利于挖掘文档的语义关系.由前文介绍可知,通过训练word2vec模型获得的词向量不仅具有低维、稠密特性,还能够充分表达词语间的语义信息.所以,利用词向量间的组合或运算是量化表示文档的有效方法之一.目前,关于这方面的研究进展缓慢,常见的方法是对一篇文档所包含的所有词向量进行求平均值[6]或对词向量进行聚类[7],但这两种方法均未重视单个词对整个文档的影响力,同时,前者在求平均之后,词向量所表达的含义已经丧失,利用平均词向量表示文档具有不合理性.本文将一篇精选文档可表示为(W1,…,Wi,…,Wn),其中,Wi表示文档的第i个特征项,实际上为一词向量,在词向量表中可找到与之对应的实际词,n表示文档包含的特征词数.利用该表示方法和合理的文档距离度量公式,可挖掘包含相似词汇的文档.
2 语文教材选文推荐
2.1 推荐依据及过程
词汇是学生遣词造句的基础,是阅读与写作的前提,教材中词汇的编排是否科学直接关系着学生的学习效果.如果教材中包含过多超纲词汇,文章将晦涩难懂,如果过于简单,文章又味如嚼蜡,只有一本词汇编排合理的教材才能使语言学习事半功倍.
在[8]一文中,作者研究发现,小学生认知词汇是一个循序渐进的过程,我们应了解学生习得词语的规律,按照词汇的顺序选编教材,保证词汇在教材整体上呈现连续性.词频是词汇被使用的频度,如果先导课文中包含过量的低频词汇,将不利于后继课文的教学,也不符合学生由浅入深的认知规律.因此,按照词汇频度的大小设置学习词汇的先后顺序,保证高频词先学,低频词后学,是符合学生的认知规律的一种体现.
同时,推荐选文应实现相邻选文间具有一定的重复词汇,即当前选文应包含少量的前文词汇和后文词汇,以便达到温故和学新的效果.
此外,相关词之间存在着紧密联系,如“学生”和“老师”之间存在“教”与“学”的关系.在同一课文或相邻课文中编排关系密切的词汇,有益于学生感知词汇之间的关系,保持知识间的联系.然而,在现有教材中,密切相关的词汇分布较为分散,使得教师在教学过程中必须补充相关知识.为了捕获这些关系紧密的词汇,本文采用k-means聚类算法对词汇表中的词汇进行聚类,每个类可称为一个词包,词包内的词汇具有紧密的关系.
综上所述,语文教材选文推荐的准则主要包括以下几点:
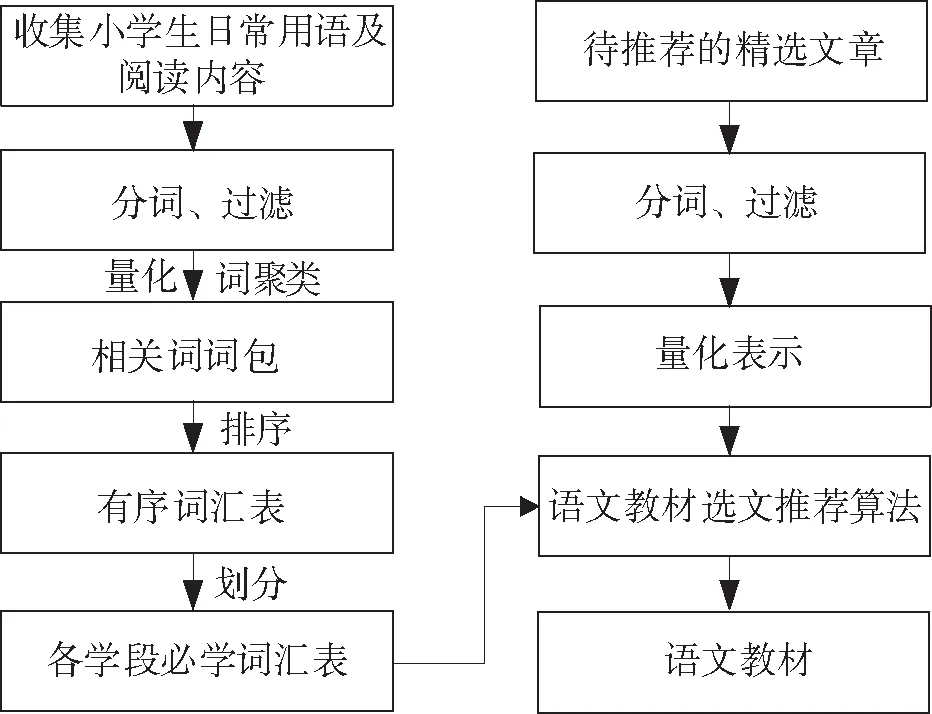
图1 语文教材选文推荐过程
(1) 小学生认知词汇是一个循序渐进的过程,应以词汇序表中的词汇作为推荐选文的依据,保证选文的词汇遵循连续性、有序性.
(2) 应保持相邻选文具有一定的重复词汇,保证温习和学新效果.
(3) 尽可能地使密切相关词汇分布在同一选文或相邻选文中.
(4) 教材选文在满足各学段的学生学习需要的同时,不得逾越学生的词汇接受能力.
在确定选文推荐的原则后,可设计出教材选文推荐的整体过程,如图1所示.从图中可以看出,教材选文推荐工作是在获得各学段必学词汇表的基础上,将待推荐精选文章通过选文推荐算法与必学词汇表相匹配,挑选出最佳选文.
2.2 文本文档的相似度度量
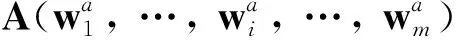
(1)
(2)
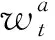
(3)
除去该类词,文档a,b中尚有如下词集合
S2={s|s∈{1..n},∀t∈{1..m},(s,t)∉S1},
(4)
S3={t|t∈{1..m},∀s∈{1..n},(s,t)∉S1},
(5)
则,文档a,b的相似度可定义为:
(6)
其中第一项为相匹配词的距离,后两项体现了无匹配词所起作用,在各项前可以增加调和系数,用于协调各成分所起作用.
2.3 选文推荐算法
教材选文推荐算法是基于各年级的必学词汇表,从待推荐的优质文章库中挑选出与之匹配度最高的一系列选文,形成教材的过程.一般来说,一篇课文所包含的新词数应被严格控制.所以,在推荐选文前,需将必学词汇表划分成若干个有序词汇集,词汇集的数量由本年级教材所需课文数决定.由前文选文推荐依据可知,相邻选文之间应具有一定的重复词汇.解决该问题的方法是在划分词汇集时,使得词汇集之间存在一定的交集.获得每一篇教材选文的过程实质是文本分类问题,即将待推荐选文归类到对应词汇集的过程.教材选文推荐算法描述如下:
输入:各年级的必学词汇表V{D1,D2,D3,D4,D5,D6},其中,Di表示i年级的必学词汇表.待推荐选文集C={A1,…,Ai,…,An},其中,Ai表示第i篇文章的特征矩阵,矩阵的每一行对应一个特征词的词向量.需推荐教材选文的年级class,教材的选文数count,文章间的重复词汇数rep.
输出:O={B1,B2, …,Bcount} ,即对应class年级的一套语文教材.
算法步骤:
(1) 划分class年级的必学词汇表Dclass为若干个词汇集M{W1,…,Wi,…,Wcount},且词汇集之间存在重复部分.假设词汇集Wi中最后一个词汇对应必学词汇表中的下标记为x(i),则词汇集Wi所包含的词汇可表示为:
Wi{wx(i-1)-rep+1,wx(i-1)-rep+2,…,wx(i)}.
(7)
(2) 量化词汇集
wi=FV(wi)Wi{wx(i-1)-rep+1,wx(i-1)-rep+2,…,wx(i)},
(8)
其中FV(.)为特征向量算子,Wi就是量化后的第i个词汇集.
(3) 依据公式(6),计算所有待推荐选文C与各词汇集M之间的相似度,构成距离矩阵
(9)
(4) 对于每个词汇集,根据距离矩阵(9),按距离由小到大的顺序对待推荐选文C排序,可得:
Si={
(10)
其中,di1表示在C中与词汇集Wi距离最近的文章的下标,Ddi1则是文章Adi1与词汇集Wi的距离.
(5) 为每个词汇集匹配候选文章集
Hi={Adij|Ddij>=ε,dij∈Si},j∈[1,n].
(11)
其中,ε为选文与词汇集Wi的距离阈值.
(6) 确定每个词汇集的最佳选文
① 对于∀Hi(i∈[1,count]),如果Hi≠Ø,令Bi=Adi1,否则从Hi向上、向下各找到一个不为空的候选文章集Hprior和Hnext,将Hprior和Hnext两个集合中的元素按序合并,并赋值给Hi,令Bi=Adi3
② 对于∀Bi,如果∃Bi=Bj(j∈[1,count]),找到Hi中的Dindex(Bi)和Hj中的Dindex(Bj)的值, 如果Dindex(Bi)>Dindex(Bj),Bj=Anext(Hj),否则,Bi=Anext(Hi).其中,index()是求一篇文章下标的函数,next()是求Hj集合中尚未访问的第一个元素的d值.
③ 重复②,直到求出所有Bi,且对于∀Bi,不存在Bi=Bj(j∈[1,count])
算法分析:该算法的实质是将必学词汇表划分为若干个有交集的词汇表,且交集的大小固定.然后,利用文档相似度函数,为每个词汇集匹配选文.算法的关键步骤是(6),该步骤的作用是在各选文候选集中,挑选与词汇集匹配度最高,且与其他词汇集的选文不冲突的最佳选文.对于部分词汇集来说,由于精选文本库中的文章有限,有可能出现选文候选集为空的情况.当某词汇集的选文候选集为空时,本文选取与之最近且不为空的两个选文候选集,将他们中的元素合并排序作为该词汇集的选文候选集.在保证每个词汇集的选文候选集不为空后,从选文候选集中选择与词汇集相似度最大的文章作为该词汇集的最佳选文.但是,对于不同的词汇集,可能出现相同的最佳选文.为了避免教材中出现重复选文,对于所有匹配到相同选文的词汇集,D值最大的词汇集的最佳选文不变,其余的词汇集均需在各自的候选集中重新选择未被匹配且D值最大的文章作为最佳选文,反复比较选文是否有重复,直到所有词汇集都具有唯一的最佳选文.
3 实验与结果分析
本实验以新课标苏教版小学1—6年级语文课文为精选文本库.同时,借助Matlab平台,实现语文教材选文推荐算法.如果想要获取各学段的教材,必须保证精品文本库足够大.因此,在精选文本库中文章数量有限的情况下,故本文仅实现了部分学段的教材选文推荐,并与某版本原学段的课文进行了对比分析,证明本文算法的有效性.
3.1 实验数据
本文通过广泛收集学生经典阅读书目,通过文本处理技术,去除过于简单和无意义的词汇,经过词频统计、词聚类等操作获得约含3490个词汇的词汇序表.依据每学段可接受的词汇量,划分出各学段的必学词汇表.如表1所示,列出了二年级的部分必学词汇及词汇频度,其中,序号标识了词汇在词表中的顺序.从表中我们可以看出,序号为11“妈妈”和序号为12“爸爸”是关系密切的词汇,他们在词汇序表中处于相邻位置,这样便于为学生推荐同时包含这两个词汇的文章.
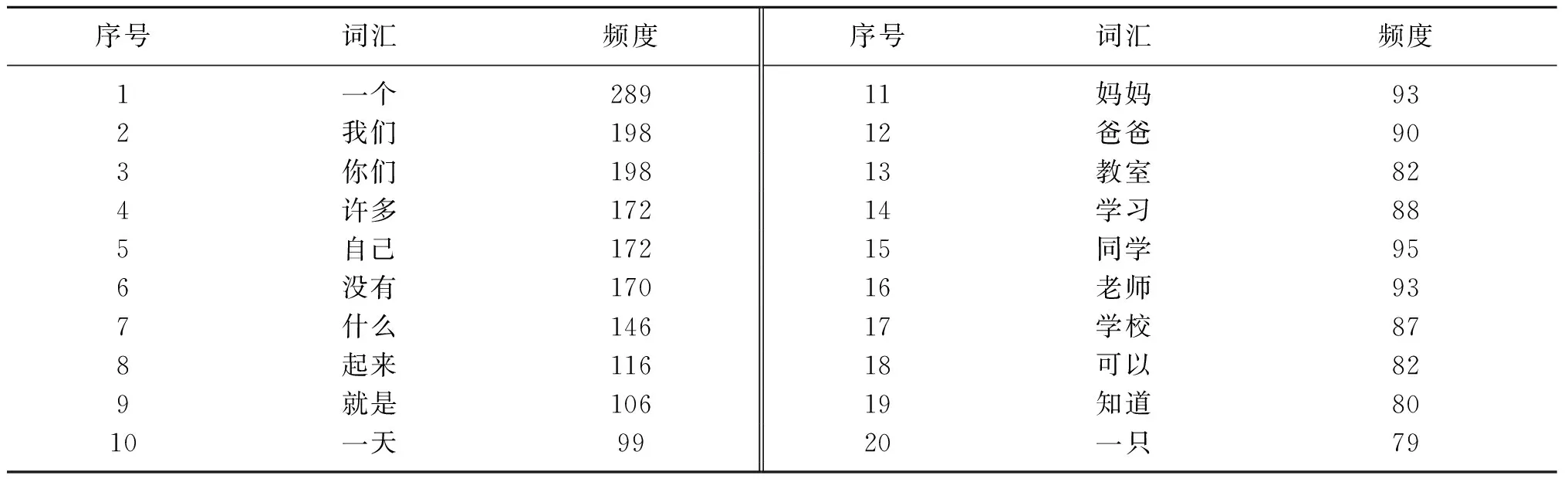
表1 二年级部分必学词汇及其词汇频度
3.2 实验结果与分析
设置相邻词汇集间的重复词汇数rep=8,同时,实现教材选文推荐算法可得到二年级上册语文教材选文的推荐结果,如表2所示.为了方便观察,本文用result〔〔〔表示选文及课文名称,其中result是总文件夹的名称,英文one,two,three,four,five,six分别代表一到六年级,A代表上册,B代表下册,“i.xls”表示相应年级和册数下的第i篇文章.

表2 二年级上册语文教材部分选文推荐结果
从表2中可以看出,利用选文推荐算法所推荐出的选文与原二年级上册课文存在较大差异,例如,本文推荐的二年级上册第1篇课文应为原二年级上册第9篇课文.与此同时,我们统计了推荐选文与相应词汇集之间的重复词汇数,在表中第3列已经列出,需要注意的是,这里的相同词汇是指具有实际意义的词汇,单个字不计入统计范围.在表中,我们可以看出,有些推荐出的选文与词汇集间相同的词汇数较少,如第11、12个词汇集,相同词汇数仅为2和3.这是因为在苏教版小学语文教材内,还没有可以较好地匹配该词汇集的文章.如果进一步丰富精选文本库,为其收纳更多的优质文章,推荐结果将得到改善.由于本文制定的词汇序表符合学生的认知规律,而教材选文推荐算法又以词汇序表为依据,所以,我们所推荐的选文在词汇上符合学生的认知规律.此外,从表2也可看出,推荐选文间的相同词汇数远远超过原教材课文间的相同词汇数,由此说明了选文推荐算法能够更好地保证选文词汇的合理分布.
4 总结与展望
针对目前教材选文缺乏自动方法的现状,设计了语文教材选文推荐算法.在分析学生认知词汇规律的基础上,广泛收集学生的经典读物,使用文本分析方法生成用于指导教材选编的词汇序表,经过标准化各学段所需学习的词汇量,将词汇序表划分成各学段的必学词汇表.基于必学词汇表,设计半自动化的语文教材选文推荐方法,为编者推荐最佳选文,且推荐的选文在教材的整体上满足词汇的连续性、顺序性和整体性规则.
但本文选用苏教版小学语文1—6年级课文作为待推荐选文,如果能收集大量的优质文章作为待推荐内容,可保证推荐出的选文具有更高的科学性.此外,本文仅仅从词汇的角度考虑推荐教材选文,还未综合考虑文章的体裁、题材和主题等复杂因素,以后可综合考虑多种因素进一步推进教材选文的自动化进程.
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
女刊·瘦美人(2017年1期)2017-06-14 00:00:10
中学生数理化·高三版(2017年1期)2017-04-20 21:16:50
信息安全研究(2016年4期)2016-12-01 06:06:54
凤凰生活(2016年3期)2016-03-08 00:15:52
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
电脑迷(2014年16期)2014-04-29 03:32:41
海外英语(2013年10期)2013-12-10 03:46:22
电脑迷(2012年4期)2012-04-29 06:12:13
双语时代(2009年3期)2009-09-24 08:45:32
