
多模态技术赋能智能化内容创作
2023-01-16 14:12吴晓英
中国传媒科技 2022年12期
吴晓英
(新华通讯社,北京 100083)
星空、大漠、草地,身着不同款式宇航服的宇航员骑在一匹或是前蹄高扬,或是碎步小跑,或是悠闲踱步的白马上,黝黑、湛蓝、暗红,不同色调天空的映衬下,一幅幅充满着超现实主义虚无感和永恒感的画作浮现在人们眼前。让人意想不到的是,这一切竟出自机器人之手。
2022年4月6日,位于美国旧金山的人工智能非营利组织OpenAI,发布了一款人工智能算法模型“DALL-E 2”。只需输入“一个骑着马的宇航员,超现实主义风格”这样的简单文字描述,“DALL-E 2”就会将图1展现在人们眼前。并且,鉴于超高的分辨率,“DALL-E 2”创作的图片看起来就像真实的照片一样。[1]

图1 “DALL-E2”生成图
多模态技术已成为2022年最值得期待的人工智能应用之一。
1.令人惊叹的跨模态生成
在现实世界中,人类同时通过看、听、说、触等感官探索和理解世界,因此现实世界中的信息,天然以语音、文字、图像、手势及表情等多模态形式存在。在传统的人工智能应用中,语音、文字、图像、手势及表情等都是各自独立的技术体系,彼此之间没有关联,因而是以一种单模态形式演进的。人工智能要想更接近人类智力,多模态是其发展的必由之路。
OpenAI此次发布的“DALL-E2”算法模型,正是对多模态技术的有益探索。通过将文字与图像两种模态的信息深度融合,实现文字感应、图文映射、逻辑推理、辩证思考等高阶人类思维活动,从而,模拟人脑完成从文字内容到图像内容的跨模态创作。
除了“看话做图”,“DALL-E 2”还能实现“看图做图”,即在不改变原图主题内容的前提下,以不同配色,多种流派,生成风格迥异的崭新图片。例如,将《蒙娜丽萨的微笑》生成印象派画作或是漫画风格。虽然画风诡异,但生成的图片着实让人惊艳。此外,通过文本指令,“DALL-E 2”亦能够毫无违和地实现图片的编辑和修改。例如,在碧蓝的天空中加一行大雁,删除图片中的小狗,将圆形型的餐桌改成方形等,按指令修改后的图片都能不露一丝痕迹,做到天衣无缝。[2]
《MIT技术评论》对“DALL-E 2”算法模型给出的评价是:“虽然它创作出的图片既中规中矩又天马行空,但它证明了,人工智能已学会将大千世界中的各个物体组合在一起的基本逻辑。这太令人震惊了。”[3]
近日,麻省理工的科学家们也研制出了一个有趣的AI应用“Speech2Face”。它的主要作用是通过声音推测说话人的长相。世界上没有两张完全一样的脸,同样,世界上也没有两个完全一样的声音。不同声音的产生,主要由说话人的声带、颧骨、下巴、鼻子、嘴唇等的长短、厚度、结构决定。因此,机器通过捕捉声音间的细微不同,描绘出不同的颧骨、下巴、鼻子、嘴唇等脸部特征,进而推测出说话人的长相。
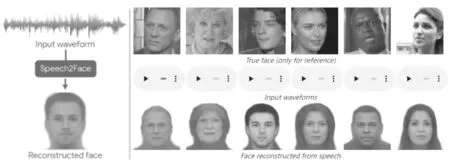
图2 “Speech2Face”画出的人脸
科学家们使用Youtub上数百万视频中,十几万人的声音对“Speech2Face”进行训练。经过大量训练的“Speech2Face”,只需要收听3 ~ 6秒的声音,就能画出人脸。当然,听得时间越长,“Speech2Face”画出的人脸越准确。“Speech2Face”完美实现了从音频到图像的跨模态生成。
2.深度学习——跨模态生成本后的利器
“DALL-E 2”是如何实现创造性地跨模态生成呢?还是以“一个骑着白马的宇航员”为例,看一看它背后的逻辑。
首先,要让机器掌握文字与图像间的映射关系,比如,当机器看到“马”这个字时,能立刻检索出所有“马”的图像。那么,机器是如何认识“马”的呢?这就要靠深度学习了。
深度学习最拿手的事就是给图像分类。人们先将大量包含图像“马”的图片按照一定规则转换成机器认识的数字串,输入到机器中,深度学习对这些数字串进行特定的数学运算,将关于图像“马”的特征数字提取出来,形成一个基于图像“马”的特征分类。当再有新的图像“马”输入时,机器通过上述步骤将提取出的特征与已有的图像“马”特征分类进行比对,相似度达到一定比值时,机器就认为新输入的图像是“马”。这样机器就完成了对图像“马”的认知过程。
那么,如果再深入思考一下,深度学习又是如何进行特征提取的呢?那就是深度学习中的深度神经网络。
深度神经网络好像人类大脑,也是由一个个独立的“神经元”组成。但和生物学上的“神经元”不同,这里的“神经元”是一组组执行乘法和加法的数学运算。单个“神经元”没有什么意义,但当成千上万的“神经元”连接在一起时,神奇的事情就发生了。
还是以“马”为例,由于“神经元”在深度神经网络中是以列(或层)的形式连接在一起的,将图像“马”转化的原始数字串输入第一列(或层)后,数字被送到不同的“神经元”中,其中一个“神经元”通过数学计算,负责判断这组数字是直线还是弧线;如果是弧线,这个结果就被输入给第二列(或层)中的某个“神经元”,这个“神经元”再负责判断这个弧线是圆形还是椭圆形;判断后的结果再被送到第三列(或层)中的某个“神经元”,再判断它是眼睛还是头;然后再进入下一层,判断它是马的头还是牛的头。很多个这样的“神经元”同时工作,相互叠加,最终产生了图像“马”这一终极结果。以此类推,深度学习帮助机器认识了“宇航员”的图像、“星空”的图像、“草地”的图像等。
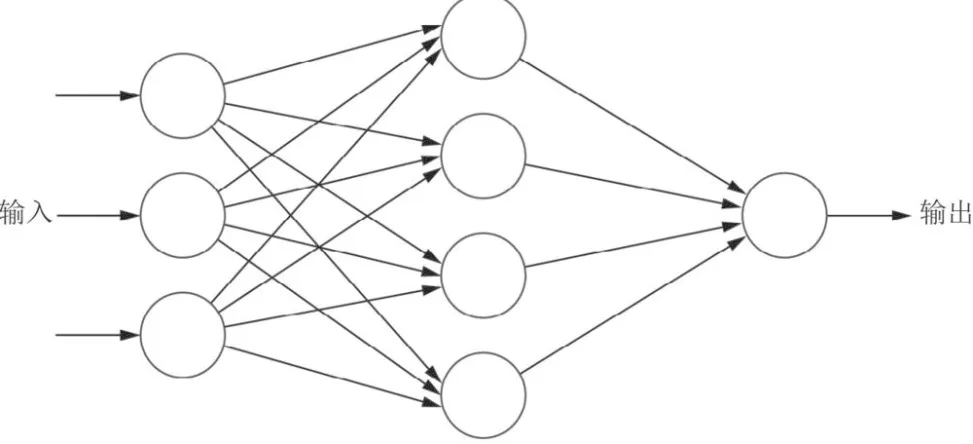
图3 “DALL-E 2”跨模态生成呈现的映射关系
至此,机器学会了图像与文字间的映射关系。然后,通过反向转换,将“一个骑着白马的宇航员,超现实主义风格”这句文字同样以数字串形式输入机器,机器将包含“白马”“骑着马的宇航员”“超现实主义风格”等图像检索出来,再进行随机组合,一幅幅“光怪陆离”的画作就此诞生了。
现在,再来看看“听声音识人脸”这个有趣应用背后的逻辑。首先,在用于训练的视频中挑选一个人物,然后将视频中的人物通过编解码技术,转换为一个脸部特写图像。接着,就像上述认识“马”的过程一样,通过一个又一个“神经元”的复杂连接,先识别线条和轮廓,再识别圆、扁、长、方,最终确定鼻子、嘴唇、下巴等面部器官的形状,提取出面部特征信息。然后再将这个人在视频中的说话声音转换成声谱图,同样通过高低、强弱等维度的识别,提取出声音特征信息。两个特征信息相互匹配,声音背后的人物就被描绘了出来。
深度学习目前已成为人工智能界最热门的研究领域。它最吸引人的地方是其对特征信息的自动提取和计算。但事物总是有两面性的,正是这种自动性,使得深度学习的算法模型就像一个黑匣子,很多时候,人们只能看到结果,而无法解释过程。
曾经有科学家做过这样一个实验,运用深度学习模型训练机器认识“哈士奇”和“狼”。科学家将一些家养的哈士奇图片和在冰天雪地里拍的“狼”的图片拿来训练模型,令人惊讶的是,模型学习得很好,当看到新的图片时,它能很准确地辨认出是“狼”,还是“哈士奇”。科学家们欢欣鼓舞,并且开始研究它的运算机制,想看看深度神经网络是如何进行学习的。结果让人大跌眼镜,深度神经网络居然是依据图片中的白色雪地进行判断,当图片中有白色雪地时,模型就认为它是“狼”,即使把一只“哈士奇”放在雪地里,模型也认为它是“狼”。
鉴于,深度神经网络的智能和强大,深度学习在解决问题的同时也会带来一些不确定性,在使用时,需要谨慎操作。也许机器已经学会了一些人们意想不到的东西。[4]
3.基于跨模态生成的多模态搜索
信息大爆炸的今天,网络已成为人们获取信息的主要途径之一。除了在日益庞杂的“大数据”中寻找信息,内容创作者们还要挖掘“信息背后的信息”,明确信息内的脉络,梳理信息间的关系,这些都需要耗费大量的精力和时间。加入多模态技术的搜索引擎,能够实现一次输入,多种生成,多元推荐的搜索体验,极大提升了信息搜索的智能化。
2022年4月20日,拥有大量文字、图片和短视频信息的内容生产平台——小红书,发起了一场线上直播。直播中,小红书技术团队就多模态搜索的研究及应用进行分享。当在最新一版小红书App搜索栏中输入关键词“冰墩墩”后,除传统的文字内容推荐外,与冰墩墩相关的各类图片、音乐、短视频等内容也同时展示。据小红书多模态算法组负责人汤神透露,仅仅添加一个多模态搜索功能后,小红书的独立访客点击率和页面浏览量点击率就整体提升了2~3倍。
事实上,在2020年万象·百度移动生态大会上,百度的多模态搜索应用就已让人叹为观止。从文字、声音,到图片、视频;从听清、看清,到听懂、看懂;从海量搜索,到最佳推荐,多模态搜索为机器像人脑一样学习和认识世界提供了有力支撑。
在语音搜索上,通过集成语音识别、语音合成等技术,百度搜索引擎能够剔除环境噪声,分辨方言俚语,调整语音语调,实现对语音的清晰辨认;凭借深度语义理解,挖掘口语化、缩略表达等背后的真实语义,实现语音到文字的准确转换;利用最优化匹配模型,实现搜索结果的精准反馈。
在视觉搜索上,综合图像识别、人脸识别、OCR、物体检测、实体匹配等技术,搜索引擎通过优化操作路径,能够将人机交互时长控制在100毫秒左右;通过感知维度缺失、遮挡、不规则等物体存在现象,能够准确理解每个像素的物理意义;通过抽象出整个像素集合体背后的物体信息,能够实现视觉搜索的所见即所得,即“以图搜图”“以图搜文字”“以图搜视频”等。
除文字、语音、图像、视频等模态外,多模态搜索领域还包括身体手势、面部表情等信息表现形式,随着三维数字化技术的融入,多模态搜索的未来将会是以虚拟人形态呈现的交互式智能化搜索场景,人类通过与机器的自然交谈,实现各类复杂信息的搜索与最佳推荐。搭载了虚拟人技术的多模态搜索将是智能化内容创作的下一个蓝海。[5]
4.蓬勃发展的智能化内容创作
在纯文本内容创作上,智能化应用已有了较大发展。在国外,OpenAI在2020年推出了人工智能算法模型“GPT-3”,通过近2000亿个单词的训练后,聪明的“GPT-3”不仅能够依据一些简单的文本提示(如标题、大纲等),写出语言顺畅、文字优美的故事、新闻稿、访谈、甚至论文,还能写诗、翻译、编代码和回答问题。
当年曾轰动一时的假新闻案,就为“GPT-3”的创造力提供了最好佐证。加州大学伯克利分校的一名学生利用“GPT-3”生成了一篇“心灵鸡汤”类文章,并发表在自己的博客上。随后,这篇文章迅速被几大新闻网站转载并置顶。很少有人意识到,这居然出自机器之手。[6]
2020年11月,Facebook也推出过一个名为“M2M-100”的人工智能算法模型。该模型可以实现100种语言间的实时互译。这一智能模型,打破了数十亿人之间的语言壁垒,人们可以更加便利地交流、沟通,了解彼此。
2021年11月,OpenAI又为“GPT-3”增添了一个新功能,自动分析社交新闻网站上的跟帖内容,形成分析报告。通过对比,“GPT-3”生成的分析报告,无论在词语描述、数据统计,还是内容结构上,相较之人工编写的分析报告都更受欢迎。
据OpenAI透露,2022年的7、8月份,它们将推出“GPT-3”的升级版“GPT-4”。虽然还没有来自官方的任何消息,但业界预判,新生代“GPT-4”最震撼的可能是基于人类反馈的强化学习能力。《浪潮之巅》的作者吴军曾说过:“与机器相比,不靠谱,会犯错,能想象,恰恰是人类创造力的源泉。而机器因为暂时还不会犯错,所以没有根本上的创造性。”也许“GPT-4”就是一个“学会犯错的机器人”,它将会开启机器的“创造之门”。[7]
在国内,浪潮人工智能研究院于2021年9月发布了人工智能算法模型“源1.0”,通过高达5TB高质量中文数据集的训练(相当于近5年内整个中文互联网的全部内容),“源1.0”在新闻分类、文献摘要识别、成语阅读理解、原生中文推理等方面均获得了出色表现。
在创建“源1.0”的同时,浪潮人工智能研究院同步构建了全球最完整的中文语料库(一个结构化的机器可读的文本库)。这一举措有效解决了模型训练中缺少大规模的标准中文语料库的难题,对基于中文的智能化内容生成将产生重要意义。
与GPT-3相比,“源1.0”使用了 2457 亿个参数,这意味着“源1.0”在处理更复杂的语法结构和语句理解任务上将更加得心应手。此外,与GPT-3相比,“源1.0”在硬件资源的投入上也进行了优化。GPT-3 的训练需要超过 10,000 块GPU的大型集群,而“源1.0”通过优化训练代码瓶颈,仅需要 2,128 块GPU就能在合理时间内完成训练。随着开发人员对代码的不断优化,“源1.0”的性能将进一步得到提升。
在融媒体产品内容创作上,正如前文所述,依托多模态技术的不断演进,文字与图片,图片与图片,文字与音频,文字与视频、人类与虚拟人间的相互创作正在蓬勃兴起。
最近,一家名为“北极鹅”的科技公司打造了一款虚拟剧本创作者“蔡晓”,作为实验,该款虚拟人目前已参与到“剧本杀”类推理游戏的内容创作中。人类玩家和虚拟人玩家通过“交互式叙事”的创作模式共同演绎游戏故事的脉络和情节发展。每轮交互后,人类对机器的表现进行研判,对恰当的表现实施正反馈,对不恰当的表示进行负反馈。通过人类反馈的强化学习,虚拟人的“思考力”和“创作力”在一轮轮的人机交互中得到不断提升。[8]
结语
自2016年,《华盛顿邮报》首次推出机器人写稿以来,人工智能对新闻内容创作的影响与挑战一直是新闻从业者关注的焦点。随着技术的不断演进与整合,在新闻内容创作方面,人工智能已经具备了人类大脑的某些特征。
在基于“规则”的新闻内容创作上,如财经、体育、突发事件等资讯类新闻,人工智能拥有了人类一样的思维、表达、搜索和创作能力,机器无论在效率还是质量上都已完胜人类。
在基于“思想”的新闻内容创作上,如深度报道,专题评论等思考类新闻,人工智能也有了惊人的成长。目前,制约人工智能更像人类一样“思考”的主要因素有两个,一是用来训练模型的巨大数据样本;二是超高的计算能力、超长的计算时间和超大的存储空间。为此,科学家们也在做着不懈的努力。近日,Meta AI(前身为Facebook AI)开放了一个“GPT-3”的复刻版算法模型,在保持功能不变的情况下,其运行能耗是“GPT-3”的1/7。
可以预见,不远的未来,人工智能将替代人类进行海量内容搜索、筛选、整合及各类融媒体新闻内容的创作工作。但是挑战也是机会,人类可以从大量的重复性劳动中解脱出来,依托机器深度挖掘线索、弥补技能短板、充分激发灵感,进而指导机器做出超乎想象的内容创作,让更多的天才创意得到实现。相信在人机协作的模式下,人工智能必将为新闻内容创作带来无限可能。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
环球时报(2022-07-13)2022-07-13
昆明医科大学学报(2022年3期)2022-04-19
环球时报(2022-03-14)2022-03-14
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
电影(2018年8期)2018-09-21
现代装饰(2018年5期)2018-05-26
中国生化药物杂志(2015年4期)2015-07-07
弹箭与制导学报(2015年1期)2015-03-11
郑州大学学报(医学版)(2015年2期)2015-02-27
