
基于视频关键帧提取和三维卷积的行为识别
2023-01-13 13:33方婷红董建设杨正昊王志凌
天津职业技术师范大学学报 2022年4期
方婷红,董建设,杨正昊,王志凌
(天津职业技术师范大学信息技术工程学院,天津 300222)
近年来,随着计算机视觉技术的发展,各种技术成果层出不穷,人体行为识别技术也逐渐得到广泛重视,其应用领域也日益广泛,如虚拟现实、视频监控、医疗卫生等领域。早期,提出了一种基于人工识别的方法,即利用传统的机器学习算法,从物体的局部或整体特征中抽取出物体的局部或整体特征,并将所提取的特征进行编码和标准化,最终将所提取的特征进行训练,从而获得相应的预测分类效果。传统的行为识别方法主要是对视频区域的局部高维视觉特征进行提取,再把提取的特征剪裁成固定大小的视频片段,最后利用分类器进行最终的分类识别。其中,Laptev[1]研究发现了局部表示方式的时空兴趣点检测(STIPS)方法,在时域空域中提取兴趣点作为时域空域中变化的邻域点,由此来描述视频中的人体局部特征,从而进行行为识别。由于Laptev的方法存在提取有用兴趣点过少的不足,Dollar等[2]在此基础上,提出了采用Gabor滤波器结合高斯滤波器,增加稳定的兴趣点进行行为识别的方法。Richardson等[3]提出了马尔科夫逻辑网络(Maikov logic networks),该网络能够描述运动之间的时间和空间关系,提高行为识别的准确率。Wang等[4]提出密集轨迹(dense trajectory,DT)算法,在每个空间尺度上进行密集采样,之后在每个空间尺度上再次进行分别追踪,形成轨迹描述来对行为识别进行分类。但移动的相机,会对行为识别的准确率产生影响,因此Wang等[5]对光流图像进行了优化,并对密集轨迹(improved dense trajectory,iDT)算法进行了改进,用于人体行为识别。
基于人工特征的提取方法已经比较成熟,但这种方法只针对固定的图像进行特征抽取,不能保证视频的普遍性,且运算速度很慢,难以适应实时需求。随着深度学习的深入研究,新方法已经逐步替代了以往的方法,得到了更为高效、准确的信息。目前的主流算法有3种:双流神经网络、3D卷积神经网络和多种混合网络。Simonyan等[6]利用2个单独的网络分别提取时间、空间特征,使用Two-stream方法进行行为识别。Ji等[7]利用三维卷积核提取连续视频帧中的运动信息,采取基于3D卷积神经网络进行行为识别。Tran等[8]提出C3D模型,直接提取视频的行为特征,将3D卷积核大规模地应用于行为视频中。吕淑平等[9]提出了(2+1)D的卷积方式代替3D卷积,加深了网络结构,有利于对运动时间较长、视频像素更丰富的视频进行有效学习。Diba等[10]在C3D的基础上结合了DenseNet网络模型,极大地减少了网络结构参数量,但网络模型中的稠密链接增加了计算负荷。罗会兰等[11]提出了空间卷积注意力机制(SCA)结合时间卷积注意力机制(TCA),获取人体行为视频的时间与空间信息。吴丽君等[12]提出了通道注意力机制结合时间注意力机制,通过调整网络的卷积层和池化层的顺序,有效保留了更多的通道信息和时间信息。Donahue等[13]在卷积网络CNN中加入了长短时记忆网络模型,分别对输入的人体行为视频进行视觉特征学习和隔离学习,在行为识别方向上取得了不错的结果。Ng等[14]为了解决卷积网络因提取信息不够完全而导致行为类别识别不准确的问题,采用全局视频级别的卷积网络结合长短时记忆网络进行时空上的特征提取。Li等[15]将可视注意力机理与可视注意模式相结合,从而使其更好地改善行为辨识的正确性。Liu等[16]在空间维中引入了空间信息的稀疏性,并采用一种轻量化的组帧网(GFNet),实现对图像的行为识别。Yang等[17]采用一种用于行为识别的快速插入式的时间金字塔网络(TPN)。Arnab等[18]将人体行为视频构建成一组时空标签和位置编码,作为Transformer输入对人体行为进行识别。C3D网络能够对视频直接提取时空特征,但原始的C3D网络模型采用随机提取视频帧的方式对视频进行处理,导致提取出的视频帧的冗余信息较多,对行为识别率影响也较大。为此,本文提出一种基于视频关键帧提取的C3D网络模型算法,利用视频聚类关键帧提取技术消除对数据的冗余性问题,提取少量具有代表性的关键帧作为网络模型的输入,采用以0.5的概率对已提取的关键帧进行水平翻转,并进行数据增强,在原始C3D模型中引入注意力机制(convolutional block attention module,CBAM)对关键帧进行特征提取。
1 人体行为识别算法
1.1 C3D神经网络
C3D神经网络是一种具有典型意义的立体卷积方法,相对于二维卷积,3D卷积由于三维卷积和三维池化的运算性质,能够较好地抽取出时间区域的特征。2D卷积无论输入单通道图像还是多通道图像,结果均为单张图像,损失了时间域上的信息。3D卷积输出保持空间域上的特征,是立体的输出。同样,对于3D池化操作来说,也保持着时空特征。该网络的输入是视频片段,输出是数据集类别的标签。所有的影像画面尺寸均为128×171。同时,将该片段分割成16个画面,以3×16×128×171的形式输入到网络中。C3D网络通过不同的卷积核实验,最终验证了所有的卷积核采用3×3×3大小最为合适,对应的步长为1×1×1。其中,第一层池化层采用1×2×2的卷积核大小,目的是保留当前的时间信息,池化层则使用2×2×2的卷积核。C3D经纬构造采用三维卷积操作,8次卷积操作,4次池化操作,最后经过2个全连接层和softmax层后,网络得到最终的效果。C3D神经网络的总体框架如图1所示。
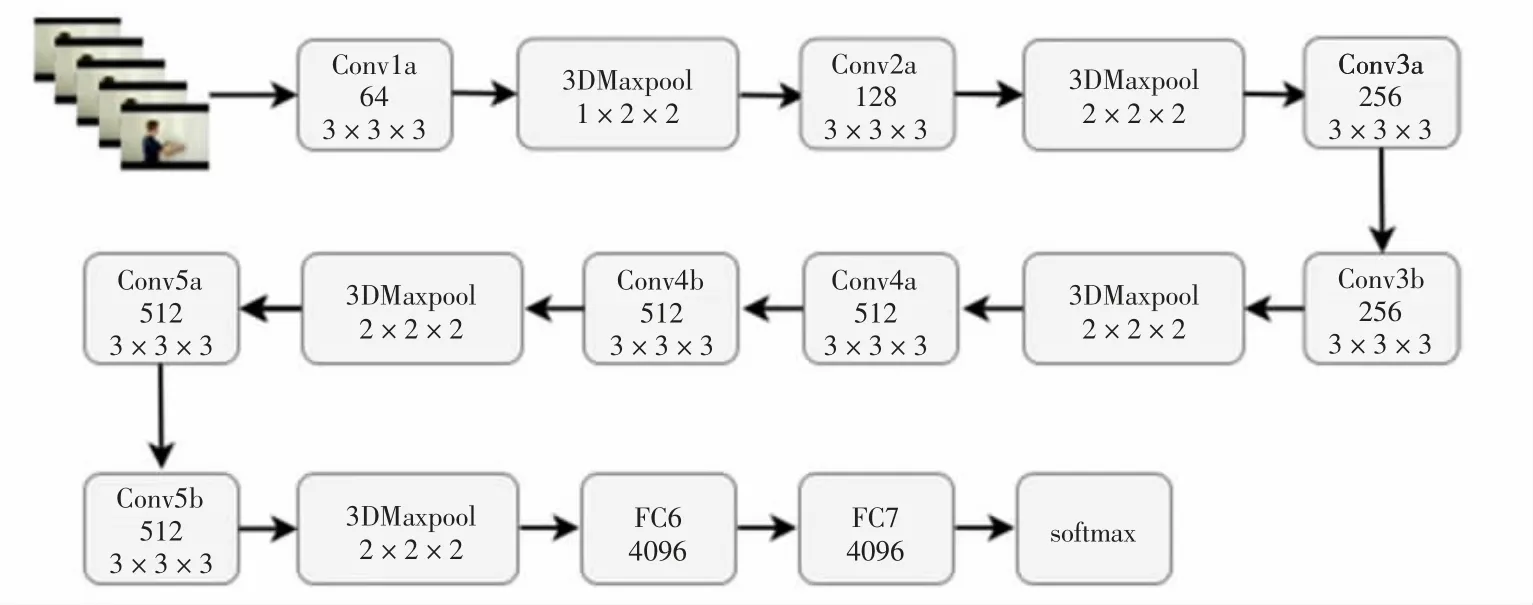
图1 C3D神经网络整体结构图
1.2 基于视频聚类关键帧提取算法
视频中的信息量比图片信息量更为丰富,但在一个序列中,存在很多多余的数据,所以在无监督情况下,提取出关键性的数据尤为重要。目前,主要的关键帧提取方法有5种:基于镜头边界提取关键帧[19]、基于运动分析提取关键帧[20]、基于图像信息提取关键帧[21]、基于镜头活动性提取关键帧[22]和基于视频聚类提取关键帧[23]。与前面4种不同的关键帧提取算法相比,利用视频聚类技术对关键帧进行分割,可以有效地对关键帧进行分割。在视频分类过程中,将视频分割成不同的图像,得到典型的图像特征。朱映映等[24]提出以图像颜色直方图计算图像之间的最大相似性,然后根据图像间的相似性度量聚类的方法,较好地解决了计算效率问题。参考上述聚类标准方法,本文对视频进行关键帧提取时,采用算法如下:
(1)变换图像色彩空间,从RGB变换到HSV彩色空间。
(2)对HSV彩色空间中的彩色直方图进行计算,并标准化。即H颜色直方图分成12份,S、V颜色分成5份,分别计算其颜色直方图。
(3)开始聚类,将图像组的第一帧图像当作初选的群集中心,取一帧与目前的群集中心进行相似度测量,如果最大相似度仍然小于给定的临界点threshold,表示该帧与所有的聚类中心之间的距离过大,因此需要单独成为一类。重复此过程,直到取完所有的帧。每一次当前类中加入一张新的图像时,需重新计算聚类中心,即求一次平均值。
(4)在聚类结束后,根据离簇中心最近的帧数进行运算,将其视为关键性的帧数。
1.3 注意力机制的引入
C3D模型在提取空间和空间特性时,会考虑到视频中的每个像素,而在行为识别视频中,C3D模型对每个像素都具有同样的意义。但是,在行为识别视频中,更需要去关注空间中对于人体部分的特征,因此使用注意力机制尤为重要。
本文采用轻量级的注意力模型CBAM[25]用于加强空间和时间上的特征提取,采用通道注意力和空间注意力串联的方式,并在此基础上,从2个方向推导出注意因子。针对通道注意,重点在于哪条通道上的特点,将2个特征图进行全局平均和全局最大值操作,分别发送到第二层。在此基础上,利用Sigmoid函数对2个特征图进行相加运算,求出0~1的权值,根据要素属性对其进行相乘运算,生成空间注意力模块所需的特征。
以通道注意力模块所输出特征图作为空间注意力模块所输入特征图,重点在于空间区域的特性具有重要的含义。利用通道进行全局最大值和整体最大值的池化操作,得到2个特征图,同时进行拼接运算。利用7×7大小的卷积核提取特征,通过Sigmoid函数产生空间权重系数。利用空间权重系数对输入特征图进行乘法操作,获得最终的特征图,CBAM结构如图2所示。

图2 CBAM结构图
将CBMA注意力机制引入C3D模型,得到三维卷积提取特征图F∈RC×M×H×W作为CBAM的输入,式中:R为网络时空域;C为网络通道数;M为视频帧数;H为视频帧图像高;W为视频帧图像宽。
通过信道注意力模型对该特性进行分析,得出Mc(F),Mc∈RC×1×1×1的信道注意力模型,并与原有的特征图分别相乘,从而获得经过改进的信道注意力特性曲线F'。

式中:○×为逐个元素相乘。
新特征图F'又经过空间注意力模块,得到二维空间特征图Ms(F')。其中,Ms∈R1×1×H×W为空间注意力模块,将其乘以特征图F'中的每一个要素,获得细化特征图F″。

1.4 系统整体结构
综合上述关键技术,本文采用如图3所示的基于聚类视频关键帧提取的行为识别算法,对大量动作视频进行少而精的关键帧提取,利用数据增强算法对提取的关键帧进行0.5的概率水平翻转作为模型的输入,在原始C3D模型中加入CBAM注意力机制对输入数据提取行为特征,加强数据的空间联系和时间联系,提高行为识别的准确率。
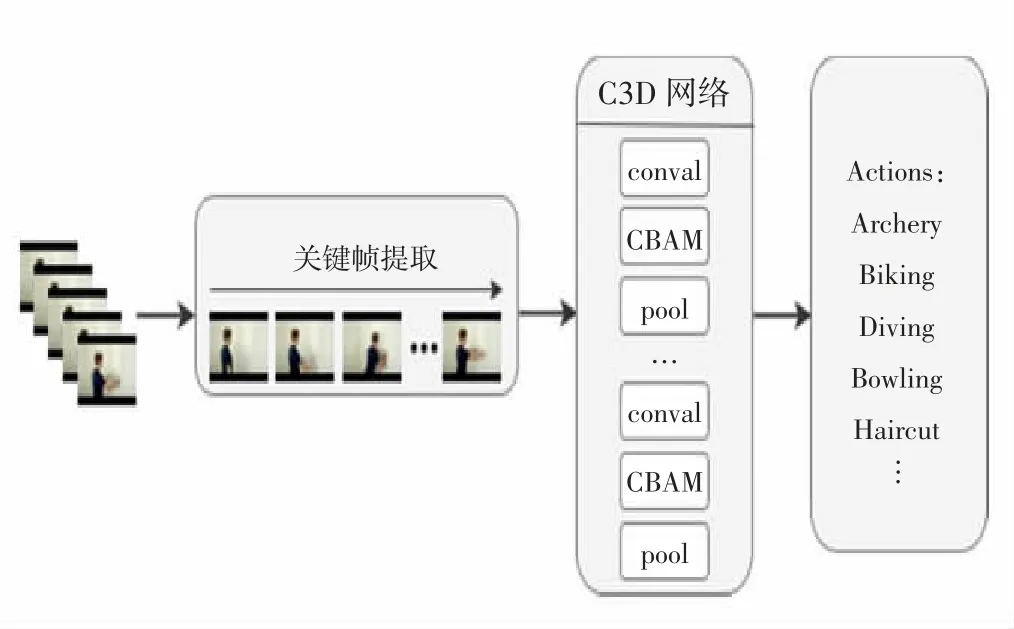
图3 基于视频关键帧提取的C3D模型结果
2 实验结果与分析
2.1 实验环境和相关设置
本文采用Windows 10操作系统,采用Intel(R)内核(TM)i7-10700 cpu@2.90 GHz,32 GB的存储空间,NVIDIA GeForce RTX 3080。Python3.7的程序设计和PyCharm 2019的开发,利用Pytorch的深度研究构建、训练和测试网络。
网络内迭代周期(epoch)次数设定为100次,初始学习率设定为0.003,并在每训练4次迭代周期结束时,学习率减少到原来的1/10,训练所用批量大小取32,随机失活率设置为0.85,以6∶2∶2的比例划分训练集合、校验集合和测验集合。
2.2 行为识别数据集
本文采用人体行为识别的公开数据集UCF101开展实验。UCF101是一个由YouTube搜集的真人动画短片,总共13 320个片段,视频总时长达到27 h,总共101个动作。UCF101数据集包含了人与物的相互交流、简单肢体动作、人际之间互动、演奏乐器以及体育运动等。此外,每个类别分为25组,每组有4~7个短视频,各视频时长均不相同,但大小均为320×240,并且每个视频的帧率不固定,一般为25帧或29帧,对于一个视频只能包含一个行为类别。UCF101在运动上具有最广泛的灵活性,包括摄像机运动、物体外观和姿势、物体尺寸、视角、混乱的场景;由于光照环境会有很大变化,所以UCF101是最具有挑战性的人类行为识别系统。
2.3 数据预处理
利用视频聚类关键帧算法对行为视频数据集进行关键帧提取并保存提取的关键帧数量,提取出的关键帧对比原始的C3D模型,采取每隔4帧截取1帧,直至截取时序达到16帧的均匀采样方法更具有代表性。对提取出的关键帧进行训练集、验证集、测试集的划分,划分的比例为6∶2∶2,并将所得关键帧裁剪成171×128个像素,存储在指定地点。在输入数据的过程中,将已经裁剪过的关键帧随机调整成112×112像素大小,其目的是使模型的精度和稳定性能够更好地加强。把调整后的视频关键帧作为输入数据并且对每个调整好的输入数据采取水平翻转和去均值的数据增强方法。
2.4 实验结果分析
本实验采用UCF101数据集进行训练,迭代周期次数为100次。评价标准采用了准确率(accuracy,ACC)、模型评估指标(area under curve,AUC)和平均精确度(mean average precision,mAP)和模型参数(params)对模型进行评价。其中,ACC评价标准分别采用了Top-1 Accuracy和Top-5 Accuracy的评估方法对实验进行评价。Top-1 Accuracy评估函数是将实验中预测标签取最后概率向量中最大的值作为最后的预测结果;Top-5 Accuracy是最后概率向量里最大的前5个标签值中出现正确值即为预测正确。AUC评估函数是现有分类模型中主要的评测标准之一,其不关注具体准确率,只关注排序结果,适用于排序问题的效果评估。mAP评价函数一般应用于多类别的目标监测任务,其能够衡量出模型在所有类别上的性能。params评估函数对应为空间概念,即空间复杂度,是指模型中含有参数的数量,直接决定模型的大小,也影响着推断时对内存的占用量。实验采用Top-1和Top-5准确率评估方法将原始C3D模型和本文模型进行对比,UCF101准确率(Top-1)、(Top-5)变化曲线分别如图4和图5所示,UCF101损失率变化曲线如图6所示。

图4 UCF101准确率(Top-1)变化曲线

图5 UCF101准确率(Top-5)变化曲线
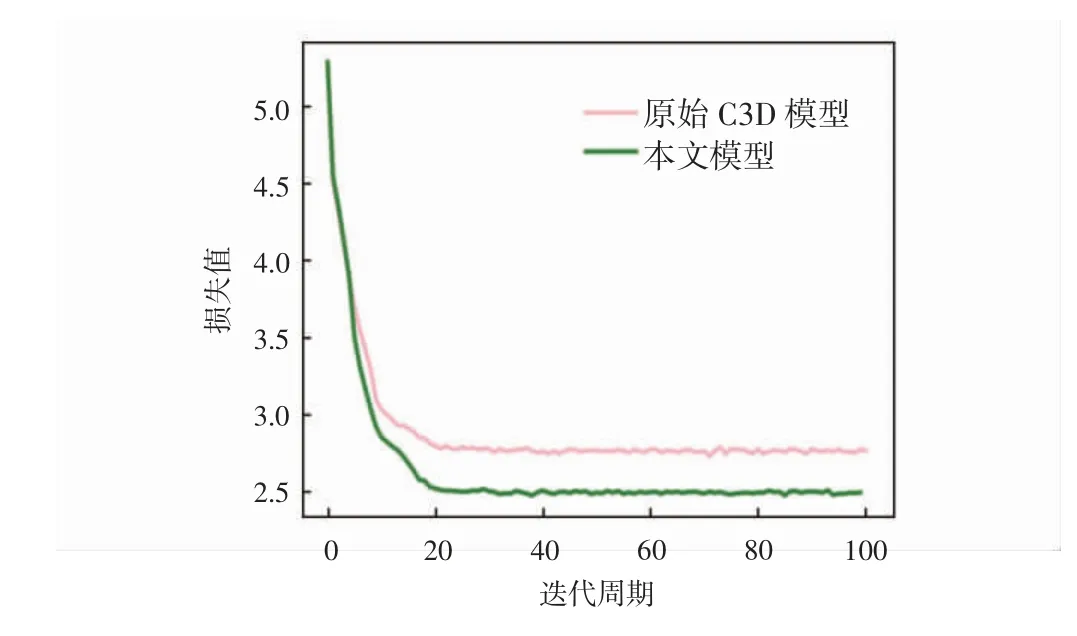
图6 UCF101损失率变化曲线
从图4和图5可以看出,原始C3D模型随着迭代次数的增加,准确率逐步上升,Top-1准确率在15次迭代后逐渐收敛,Top-5准确率在20次迭代后逐渐收敛,在100次迭代中,准确率Top-1和Top-5最高能达到31.14%和59.34%;本文模型Top-1准确率在20次迭代后趋近于收敛,Top-5准确率在30次迭代后逐渐收敛,最高准确率分别达到60.49%和88.17%,对比原始C3D模型准确率有明显提高。从图6可以看出,本文模型在0~20次迭代中,损失值急剧下降,20次迭代后损失值逐渐趋近收敛于2.47%,原始C3D模型在0~20次迭代中,损失值快速下降,20次迭代后损失值逐步收敛于2.83%,实验对比结果显示,本文模型损失值降低了0.36%。本算法与当前流行人体行为识别算法C3D、Res3D、Spatial Stream-Resnet和LSTM Composite Model在UCF101数据集上的测试结果以及各种指标结果的对比如表1所示。

表1 UCF101数据集各模型方法结果对比
从表1可以看出,在AUC评价指标上,本研究方法可以同时考虑分类器对于正例和负例的分类能力,分类效果更好;在mAP指标上,本研究方法的网络结构较优,行为识别检测较准确;在params评价指标上,本方法仅低于C3D模型和LSTM Composite Model,参数量相对较少,降低了对内存的占用量。
3 结语
本文针对C3D网络模型难以注意到行为视频有代表性关键帧信息,造成识别效果不佳的问题提出了基于视频关键帧提取的人体行为识别C3D网络模型。模型对数据集采取视频聚类的方法进行关键帧提取,并加入轻量级的注意力模块加强对人体行为特征的关注度。在UCF101数据集中,将本文算法与原始C3D模型和其他常用算法进行分析比较,结果验证了本文方法的可行性。
猜你喜欢
现代计算机(2022年4期)2022-04-24
小雪花·成长指南(2022年1期)2022-04-09
微型电脑应用(2020年12期)2020-12-25
甘肃教育(2020年22期)2020-04-13
铁道通信信号(2019年6期)2019-10-08
扬州大学学报(自然科学版)(2019年2期)2019-08-12
软件导刊(2018年4期)2018-05-15
雷达学报(2017年6期)2017-03-26
第二课堂(课外活动版)(2016年2期)2016-10-21
互联网天地(2016年1期)2016-05-04
