
多因素的XGBoost城市轨道交通短时客流预测方法
2023-01-12 03:57刘晓锋
装备制造技术 2022年10期
付 甜,刘晓锋,陈 强
(天津职业技术师范大学 汽车与交通学院,天津 300222)
0 引言
随着城市地铁线路的扩增,城市轨道交通路网的规模日益扩大,运营组织的形式也逐渐复杂,从而产生不安全事故可能性加大,其中地铁站客流量的突增很容易引起拥堵,会产生安全隐患,因此地铁运营部门需应用相关短时客流预测技术提前进行安全部署,进一步减少不安全事故发生。城市轨道交通客流预测方法有很多,如光志瑞[1]使用线性回归模型对地铁进出站客流进行了预测,具有较高的实际意义。王莹[2]等使用时间序列模型对地铁进站量进行了预测,预测精度进一步提高。李继鹏[3]等使用灰色理论对地铁客流进出站客流进行了预测,得到了较为准确的预测结果。但在某些方面还是有局限性,比如在处理大数据集的时候,速度会降低精度也不高等。因此,需要找到相关的技术和方法来使我们的客流预测精度提高速度也加快。在集成学习方法中比较典型的高准确率、高效率处理大数据的模型为树模型,代表的模型为XGBoost[4](Extreme Gradient Boosting)和随机森林[5](Random Forest,简称RF),XGBoost模型通过多弱学习器并行使用并将其结果集成起来作为最终预测结果从而提高精度和速度,所以常在各种算法大赛中看到。随机森林模型对于大数据集的处理能力很强并且精度也高。
从预测对象范围来看,Wei等[6]在早期的客流预测模型中把星期属性作为影响因素进行轨道交通短期客流预测,提升了精度,但没有考虑到了模型的通用性。后有李春晓等[7]将日期进行更加细化的划分,通过实际应用可以得到,影响客流的因素有很多,如日期所在星期、节假日等属性都有关系;除此以外,武创等[8]发现,当出现极端天气(如暴雪、暴雨等)时,乘坐地铁的人数会降低,因此,天气对乘客的出行也有较大的影响;李国强等[9]研究发现,兴趣点(Point of Interest,POI)数据也对车站客流量有较大影响,不同站点日客流量不等,之所以这样是因为车站所处的位置,具有代表性的有些车站周围是商业区,有些车站却处于郊区等。Jun等[10]研究发现首尔市轨道交通站点土地利用属性对车站站点客流量有较大影响。国内外学者虽然在地铁站点短期客流预测方面收获颇多,但对客流影响因素的进一步挖掘从而会导致模型预测精度提高的研究相对较少。为此,在基于杭州地铁2019年1月全站客流的历史AFC刷卡数据,对城市轨道交通客流的波动特征及影响因素进行了分析,并综合考虑日期属性、POI属性以及天气属性,将多特征输入XGBoost模型当中;最后,以杭州地铁客流为例,验证模型的精度。结果表明,考虑多特征的XGBoost模型与单一XGBOOST模型相比具有更高的预测精度。
1 轨道交通站点客流特征分析
1.1 日期属性对客流的影响
提取2019年1月1日-25日共四个星期的进站客流数据,以十分钟为时间间隔观察杭州地铁每日全站进站客流,结果如图1所示。图中可以看出,城市轨道交通客流呈现出以星期为周期的显著变化特征,其中day1对应曲线为元旦当天客流数据,由图可以看出除去元旦当天的客流数据其他客流数据呈现以星期为周期的变化规律,客流基本相似。这一规律说明了地铁人流量与节假日有很大的相关性。

图1 单日进站客流量
1.2 站点POI数据对客流的影响
提取杭州地铁站点POI数据和2019年1月1日元旦当天AFC刷卡数据。观察不同站点客流量并进行比较,不同站点人流量会有很大的差别,重要的枢纽站点人流量负载会很大;其中火车东站进站人流量高达201202人次。
1.3 天气对客流的影响
市民对交通方式的选择会受到天气[11]的影响,比如大雪或大雨天气,汽车或公交车司机行驶速度会降低,这会引起相应的道路交通拥堵、安全风险增高。但因为地铁的运营受天气影响较小,所以市民更愿意选择地铁作为出行交通工具。
2 基于多因素的XGBoost城市轨道交通短时客流预测方法
2.1 XGBoost模型
XGBoost是一种boosting算法,XGBoost所应用的算法是梯度下降树的改进,其核心思想是每迭代一次增加一棵树,拟合上次预测的残差,进而慢慢接近真实值。并根据每个样本特征,计算每个节点对应的得分,其所有的得分之和即为该样本的预测值。
在轨道交通客流预测问题上,XGBoost使用的是基本回归树模型,即

式中:为模型预测值,xi为第i个样本的类别标签,K为树的总数,f噪表示第噪棵树。
将XGBoost对这个树进行模型学习的过程中的损失函数定为目标函数,当目标函数为最小时,此时模型为最优模型,预测精度也最高,可表示为

式中:ob(jt)为目标函数值;l()为训练误差,一般为常数,用来衡量预测分数和真实分数的差距;Ω((ft))表示第K棵树的复杂度,如式(3)所示。
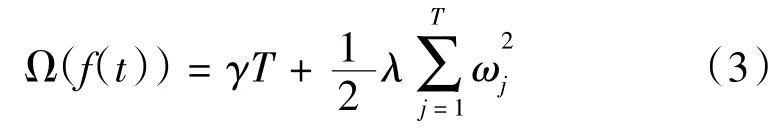
其中T为该树的叶子节点个数;γ为节点切分的难度,控制叶子节点分数,防止过拟合;ω为叶子的节点向量模;λ为正则化系数,也防止过拟合。
模型学习过程中,目标函数越小模型越优。XGBoost利用“贪心法”对决策树已有的叶子节点进行分割并获取最大增益值,为判断分裂的条件函数(式4),当条件函数大于0则进行切割,若条件函数小于0则不进行切割。其中中括号里第一项是进行切割后左节点产生增益,第二项是进行切割后右节点产生增益,第三项是切割前增益,XGBoost对样本的遍历转化成了在叶子节点上的遍历,特征的选择和切割可以并行实现。

2.2 确定客流量的特征变量
以杭州客流量为研究对象,取1月1日到25日和28日的历史运行数据进行试验,数据采集时间间隔为10 min。其中将前25天的数据作为训练样本,28日的客流数据作为测试样本。根据轨道交通站点客流特征分析,选择AFC数据、日期属性、天气属性以及POI数据为输入变量,28日客流数据为输出变量,部分历史运行数据见2.3。
2.3 具体特征变量
影响城市轨道交通短期客流的特征包括:AFC刷卡数据、POI数据、天气因素以及日期属性,具体见表1。

表1 城市轨道交通客流影响因素指标体系
其中AFC刷卡数据含义见表2,并对AFC数据以10分钟时间粒度进行汇总。其中日期属性包括共5个因素,week为星期,星期一到星期日分别用1到7表示;weekend=周内用0表示,weekend=周末用1表示,1月1日为元旦节假日,属于异常值,进行剔除。天气属性用城市的天气特征(阴、晴、雨、雪以及温度共5个属性)来表征,其中temp取最高温最低温的平均值,晴天用0表示;多云用1表示;阴用2表示;小雨用3表示;中雨用4表示,部分天气因素见表3。POI数据以站点周边的用地属性个数(如体育休闲服务、交通枢纽、公共设施、住宅区等18个属性)来表征(表4),并将站点转换为数字,如表4中stationID列数字。

表2 部分历史客流数据含义

表3 部分天气数据

表4 部分POI数据
3 案例分析
3.1 数据来源
为预测地铁客流数据的变化情况,实验使用的数据分别来自2019年天池比赛(杭州地铁站的历史刷卡数据)、百度天气网站(杭州市历史天气数据)以及kaggle网站(POI数据),采集杭州地铁全线2019年1月1日到25日多因素与进站客流数据作为训练集,28日进站客流数据作为测试集,以10 min为间隔统计数据;其中地铁的运营路线有3条、站点81个和数据约7000万条作为训练集。用考虑多因素的XGBoost模型对28日进站客流量进行预测,并用误差评价指标MSE、R2、MAE对预测结果进行准确性验证,最后与随机森林模型进行比较研究,分析算法的适用性。
3.2 参数设置
采用最常用的网格搜索,其核心思想是通过遍历参数组合最终选取一个最优组合,在利用构建的模型进行轨道站点短期客流预测时,需要根据具体模型考虑的具体因素对模型设置参数。

表5 模型主要参数设置
3.3 预测结果及评价
采用3.2中的参数建立相应的客流预测模型对28日的轨道交通站点的日进站点客流量进行预测,其预测结果如图2、表6、表7和表8所示。

表6 单一XGBoost模型与单一随机森林模型对比
表6的预测结果表明,模型1的预测效果优于模型2,模型1的MAE相较于模型2降低11.03%。
表7的预测结果表明,模型8的预测效果最好,考虑多因素的随机森林预测模型精度均高于单一随机森林预测。其中模型8的MAE相较于模型2降低了17.63%。

表7 单一随机森林(模型2)和多特征随机森林模型对比
由表8和图2的预测结果可知:从预测效果上来看,模型7的预测效果最好,考虑多因素的XGBOOST预测模型精度均高于单一XGBoost预测。其中模型7的MAE相较于模型1降低了26.64%。由此可以看出:XGBoost预测模型在不同情形下比随机森林预测精度好,考虑多因素分析预测比单一因素预测精度要好。
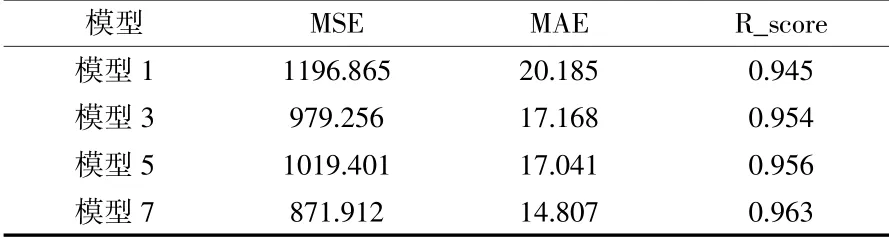
表8 单一XGBoost模型1)和多特征的XGBoost模型对比

图2 不同特征的XGBOOST模型客流预测结果对比
4 结语
国内外学者们对轨道交通站点客流预测的相关研究取得了丰硕的成果,但涉及站点客流预测精准度的提高、站点客流影响因素的深入挖掘等方面的研究还相对较少。基于城市轨道交通站点客流预测研究进展提出的XGBoost模型,由于综合考虑了日期、天气因素、历史客流数据以及土地利用属性,其客流量的预测精度高于随机森林模型,同时也体现出日期等对人员出行有很大影响,是预测客流量不可忽略的因素。在未来的研究中,可将社会经济因素、城市人口数量、环境因素、交通接驳条件等多特征作为影响因素来处理提高站点客流数据预测精度,以此为研究轨道站点短期客流量的预测方法提供一种思路。
猜你喜欢
环球时报(2022-12-12)2022-12-12
现代电子技术(2021年15期)2021-08-06
科学家(2021年24期)2021-04-25
电子制作(2019年14期)2019-08-20
数学大王·中高年级(2019年5期)2019-06-09
智富时代(2018年7期)2018-09-03
智富时代(2018年7期)2018-09-03
党的生活·党员电教与远程教育(2017年9期)2017-10-17
故事会(2016年21期)2016-11-10
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
