
一种稳定的2D骨骼捕捉策略及摔倒检测方法*
2023-01-10 03:25陈文轩郭植星
机电工程技术 2022年12期
陈文轩,曾 碧,郭植星
(广东工业大学计算机学院,广州 510006)
0 引言
根据数据显示,我国老年人口预计到2025年将达到2.8亿左右,约占全国总人口的19.3%。到21世纪中叶,65周岁以上的老年人口将接近峰值,老年人口达到4.83亿,占全国总人口比重将达到34.1%,届时我国老年人口将占到亚洲老年人口的40%[1]。随着人口老龄化现象不断加剧,用于服务老年人的公共设施的数量和规模将不再能满足社会的需求。老年人身体机能差,平衡能力不强,应变能力弱,就容易出现摔倒的情况,而老年人骨骼就像玻璃般脆弱,一旦摔碎,再难粘合恢复,从而引起严重后果[2]。
在过去20年间,一直都有学者在研究跌倒检测方法。国内外摔倒检测方法分3类:基于环境传感器的方法、基于视频的方法及基于可穿戴传感器的方法。基于环境的方法[3]有侵犯性小、算法效率高和实时性好的优点,但缺点也相当明显,它难以判定掉落的是人还是物体,导致误判率非常高,且场地需要有一整套完整的部署,造价昂贵,限制比较大,难以普及到大多数人的家庭中。基于穿戴式的摔倒传感器[4-6]容易对使用者造成不便,而且传感器的电源供应也有局限,导致老人并不喜欢佩戴该类传感器。基于视觉的方法有更好的研究前景,在于它全自动、普适性强且视频流能提供更多的场景信息。而在基于视觉的方法中,将RGB图像[7]作为输入的方法需要依靠深度网络学习排除图像中的冗余信息而导致模型规模较大,模型算力需求大而在现实中无法达到实时性;基于RGBD的方法需要特殊的深度传感器设备,成本较高;基于光流法需要基于前后两帧图像计算稠密光流图像,这个过程就会消耗大量的时间,在现实中也并不具有实用性。Johansson[8]在生物学观察中表明,即使缺乏外观信息,人类也能够从人体几个关节连续的运动中识别出不同的动作。这是因为在人的主观视角中,人体骨骼是一种简洁的数据形式,且序列化的骨骼数据也能较好地描述人的动态变化信息。骨骼数据是所有人体内所有关键关节的三维坐标,其可以通过不同的姿态估计方法从多帧图像或直接由Kinect等传感器采集得到,时效性好,因此基于骨骼点的摔倒检测方法具有良好的应用前景。
但目前公开的摔倒数据集大多没有骨骼点数据,而且视频中存在多人走动、背景复杂等干扰因素,需要摔倒领域的研究者付出大量的人力成本才能标注好。再者目前基于骨骼点的摔倒检测算法并没有较好的逻辑链条,如Yin Zheng[9]和卫少洁[10]都使用目标检测与姿态估计方法对现实场景中的人物进行骨骼提取,获取一段骨骼序列后输入到不同的判别模型进行判别。Yin Zheng[9]使用ST-GCN图卷积模型,而卫少洁[10]使用的是LSTM对摔倒行为进行判别,虽说这些方法能在公开数据集上得到很好的效果,但都仅针对判别模型进行改进,都没有考虑目标检测与目标跟踪对骨骼提取的稳定性问题。上述两个问题都会导致在摔倒数据集上训练的算法系统难以泛化到现实世界中。
本文主要研究解决如何将基于摔倒数据集训练出来的模型,能确切地应用在现实世界的问题:(1)为减少研究者在标注过程中的人力成本,本文提出了一种骨骼捕捉策略,它利用单目标跟踪算法与目标检测相结合,自动捕捉场景中人物骨骼点,从而稳定有效地提取出可用的训练骨骼点,使得后续的模型训练更加有效;(2)针对现有摔倒检测系统存在的缺点,本文提出一种优化的摔倒检测方法,它利用SORT多目标跟踪算法跟踪姿态估计方法生成的BoundingBox,并采用阈值法消取多余的骨骼点,该方法不仅有较好的时效性,且能提高整体的摔倒检测系统的稳定性,降低系统误判率。
1 相关工作
目前所有针对摔倒行为的公开数据集并无骨骼点数据。较大规模的摔倒数据集,如Le2i Fall Dataset、UP Fall Dataset、Multiple Cameras Fall Datasets等[11-13],除了UP Fall数据集会有一些加速度传感器或光流图像数据其他都只是视频流数据。而骨骼点坐标数据有2D或3D。一般来说2D姿态的质量优于3D姿态。如图1所示,图1(a)中是HRNet[14]估计的2D姿势可视化。显然,它们的质量比图1(b)所示的Kinect传感器收集的3D姿态估计要好得多。因此主要使用与现实任务关键点匹配度较高的2D姿态估计算法来将摔倒数据集转换为骨骼点坐标。

图1 2D与3D可视化骨骼对比图
姿态估计算法分为两类,一种是自顶向下,较好的算法是CPN[15]和HR_Net,算法的大概逻辑是先检测画面中的所有人物,将每一个BoundingBox中的图片输入到单人姿态估计网络中进行估计。另一种是自下而上,较好的代表是Openpose[16],算法逻辑是检测画面中所有的关节点,再使用匈牙利算法等聚类算法进行最优匹配。
摔倒数据集中的视频流数据会有不同程度的干扰问题。如Multiple Cameras Fall数据集数据集拥有8个不同的视角,为反映真实的生活状态,视频中会有背景复杂、目标遮挡、目标尺度过小等难点。而Le2i Fall数据集和UP Fall数据集中有多人走动、背景阴暗、动作执行者缺失等难点。如图2所示。这是从UP Fall数据集中截取正向视角与侧面视角的几帧图像,展示一个人模拟摔倒的全过程。正向视角中出现了一个坐着的人,而侧面视角的玻璃外面有一个行走的人,他们的行为都并不符合当前帧动作执行者的标签。如果仅用姿态估计算法进行骨骼提取,会污染训练数据并且难以进行筛选。

图2 UP Fall数据摔倒视频部分截图
摔倒判别系统有基于光流法[17-18]或基于深度图像[19]的方法,但它们受到环境中的光照或移动的物品影响较大,且相对于基于骨骼点的摔倒检测系统不够鲁棒或达不到时效性。一般基于2D人体姿态骨骼点的摔倒判别系统框架主要分成4个部分,分别是检测、跟踪、姿态估计以及摔倒检测。分类模型可以是传统的SVM[21]或者LSTM。算法逻辑是先用目标检测检测环境中的人物,再用单目标或多目标追踪算法累积骨骼序列,最后进行分类判断。基于实时性考虑,目标检测算法会选择单阶段的YOLO系列的算法。出于在实际家庭场景中多于两个人的情况较多,即便单目标跟踪能力要好于多目标跟踪法也并不适用于现实。此时这个摔倒系统在现实应用时极容易因为目标检测算法的不稳定而丢失跟踪,导致后续的判别模型无效。因为如今深度学习的模型在追求速度的前提下就会损失一定的精度。图3所示为YOLOv5[21]和MiniYOLOv3[22]目标检测算法对UP Fall数据集的人物检测结果显示,可以看到第26帧侧视角画面出现了误检的情况,对比后两帧正视角的连续画面,虽然两者都没有误检或漏检,但YOLOv5对于检测人物边界的精确度要远高于MiniYOLOv3且MiniYOLOv3对后两连续帧检测的BoundingBox形变较为严重。这种情况容易导致跟踪算法丢失追踪目标,出现频繁切换运动目标ID的情况,进一步影响整体系统对摔倒系统的判断。但YOLOv5的高精度源于其大参数模型,它的速度远不如MiniYOLOv3高。因此本文针对上述问题提出了一种骨骼捕捉策略以及摔倒检测方法。这两个方法都能使摔倒系统能更好地应用在现实世界中

图3 YOLO目标检测算法对比图
2 本文算法
2.1 骨骼捕捉策略
骨骼捕捉策略使用的是自顶向下的HRNet方法。基于以下几点原因,第一是自下而上的姿态估计算法依靠聚类算法去划分关节点,当目标显示不完全或两个多人目标重叠的时候,提取到的骨骼数容易缺失或错乱,无法转换为有效的训练数据;第二是目前SOTA算法中自下而上的姿态估计算法并无自顶向下的姿态估计算法精度高。为了获得置信度更高且精确的骨骼坐标数据,本文使用的是自顶向下的姿态估计算法。针对视频中的多人走动、动作者不在画面中、遮挡或背景阴暗的问题,本文的骨骼捕捉策略引入了RiamRPN++[23]单目标追踪算法。整体算法流程的描述如下:遍历每一个数据集的动作视频,人工框选动作执行者出现的第一帧画面,利用单目标跟踪算法对其进行跟踪并输入到姿态估计算法中,这样就可以过滤掉多余的人,筛选出主要的动作执行者。但在Multiple cameras Fall数据集中拍摄的场景比较复杂,UP Fall数据集动作执行者速度较快,这些情况都容易导致单目标跟踪算法丢失目标,难以重捕获跟踪目标导致转换出错误的骨骼数据污染训练数据。因此本文引入目标检测算法,利用目标检测得到的目标预测框不断纠正单目标算法的跟踪区域。当目标检测框与单目标跟踪框的IOU重合在[0.8,0.9]的区间内时,对单目标跟踪框进行修正,使得跟踪更加稳定。当动作执行者消失在画面中时,提取到的骨骼点整体均值会小于0.3且无IOU重合度高的检测框,此时应当抛弃当前帧的骨骼数据。整体骨骼捕捉策略流程如图4所示。
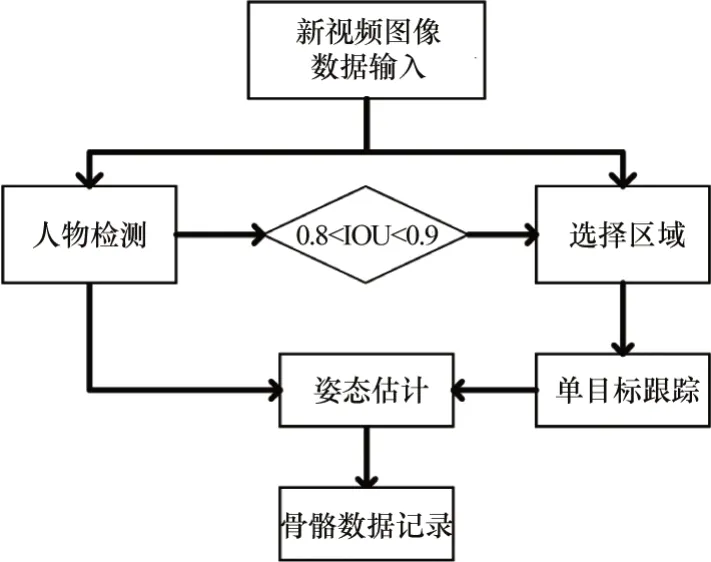
图4 骨骼捕捉策略流程
2.2 摔倒检测优化方法
摔倒检测系统优化框架分两部分,数据预处理优化及系统逻辑优化。在数据预处理部分,要想在现实世界中达到更好的泛化性,就需要引入大量的数据训练。但不同的摔倒数据集中标签和标注的方式并不统一。这就需要对标签进行重标注,而重标注需要选择合适的方式。Le2i Fall数据集只对摔倒的开始帧和结束帧作了编号。Multiple Cameras Fall数据集用数字1~9分别代表了Falling、Lying on the ground、Crounching、Moving down、Moving up、Sitting、Lying on a sofa以及Moving horizontaly这9种标签,数据集对每一帧图像都标上了数字。而UP Fall数据集中则将摔倒分成了5种类型,分别用数字1~11代 表Falling forward using hands、Falling forward using knees、Falling backwards、Falling sideward、Falling sitting in empty chair、Walking、Standing、Sitting、Picking up an object、Jumping、Laying共11种标签,但数据集作者在录制时限制了每个志愿者做的每个动作视频在10~60 s以内,并对整个视频标注为当前的动作的数字。图2UP Fall数据集中的第1帧中志愿者是站立状态,在第17帧开始有向前倾的动作,在47帧时已经完全躺在保护垫上并维持躺倒姿势直到视频结束的172帧。摔倒动作发生在一瞬间,仅持续了大概30帧的时间。如果标注方式如UP Fall数据集那样将整个10 s视频都纳入摔倒标签中,容易和躺倒的动作混淆,因此本文基于现实应用的考虑采取了Multiple Cameras Fall的标注方式,对每一帧图像都标上一个动作标签,人为判断每个动作之间分离的界限。摔倒检测的任务集中在识别摔倒行为而非区分众多不同的动作。因此本文结合了三个数据集的动作标签描述,在重标注数据集的时候将其简单概括为7类(分别对应数字1~7),Standing、Sitting、Falling down、Waliking、Standing、Sitting、Lying down。例如Le2i Fall数据集中目标对象展示是一个扫地的动作,就可以使用Walking或者Standing替代。UP Fall数据集中摔倒视频的后半段就会换成Lying标签。标注实例如图5所示。
图5 UP Fall数据集重标注示例
姿态估计算法会因为画面中遮蔽或光线等因素而对当前关节点的准确度进行评估,得到置信度Ci。现实中对一个动作是否发生的判断也应当是一个概率值。因此置信度较差的骨骼点难以作为判断动作的有效依据,因此需要减少错误骨骼点对整体算法框架的影响。将标签乘上当前帧所有骨骼点的置信度平均值,使得标签值成为会根据姿态估计得到的可信度进行调整的概率值。计算过程如下式所示:

式中:Ctave为t时刻下所有骨骼置信度的平均值,融合到t时刻下的Labelt并使其成为一个概率值。
不同的数据集的视频画面分辨率不同,如UP Fall数据集是640×480,而Le2i Fall数据集是320×240。姿态估计算法得到的是骨骼点在像素坐标系下的位置。需要将骨骼点数据除以视频帧的长度和宽度,缩放到基于数据集视频帧的相对大小。此时需要进一步消除人物在不同位置做动作带来的误差。以每帧所有骨骼点为单位作Max-Min归一化:

式中:xmax、xmin为单帧中最大、最小的关节点数据,
一般基于骨骼的动作识别算法,如文献[24],使用的是公开的NTU120[25]数据集。虽说NTU120数据集对于每一类动作的数据收集并无统一时间序列长度,但为了统一输入数据维度,多数基于骨骼的动作识别文献会以300帧(若不足300则填充0~300)作为时间维度的长度,然后选择其中的关键帧确立为更加短的时间维度长度。本文主要任务是检测摔倒行为,它是一种短暂甚至是瞬时发生的行为。本文使用的数据集是设定摄像机在18~30 fps,在标注所有数据集的过程中,本文总结出了发生一次摔倒行为的视频中可供标注的画面在30~75帧(取决于摄像机的帧率)。因此可以断定摔倒行为的持续时长约在1~2.5 s,它可以简单概括为向下倾斜、倒下以及完全躺倒3个状态。参考目前家庭监控摄像机多在25 fps以及摔倒行为持续的时长。本文选择将一次动作的判断定义在30帧,并参考文献[10]采取窗口滑动法提取用于后续训练的骨骼序列样本。窗口滑动法如图6所示。其中size大小为30。窗口沿帧顺序方向滑动一个单位即可获得一个训练样本Xi以及对应标签Li,其中Xi由30个连续帧的14个骨骼点的x坐标、y坐标以及骨骼置信度组成,Li则是融入骨骼置信度的标签。
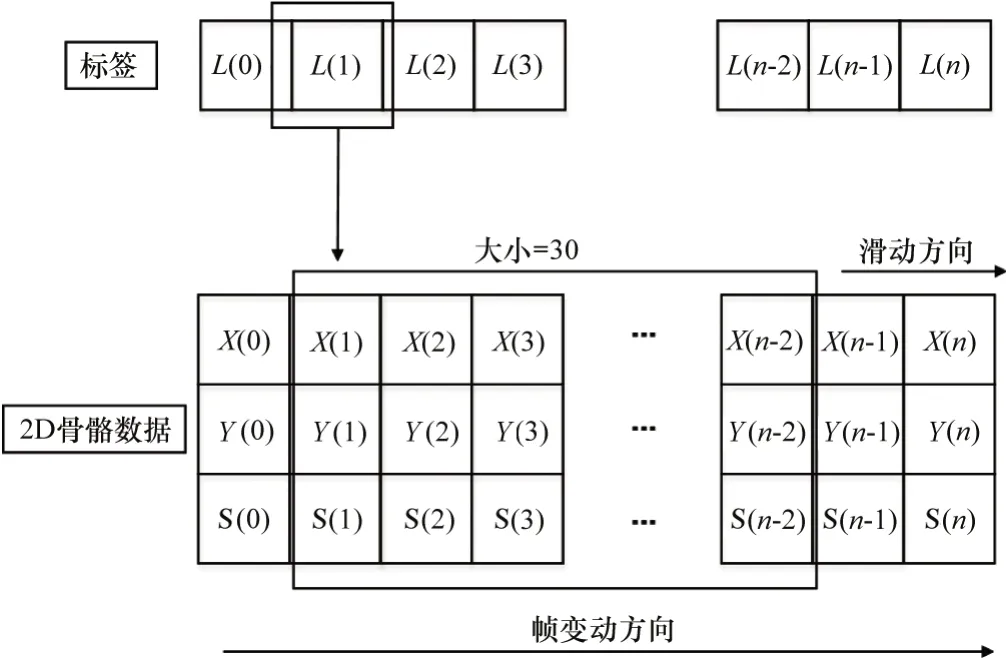
图6 训练样本处理
摔倒检测系统优化方法的整体流程如图7所示。多目标跟踪算法为SORT[26],它是2016年中多目标跟踪领域的SOTA方法。它没有使用深度学习,但有极为良好跟踪效果且能达到很高的时效性。针对图3中第26帧中误检的问题,如果只是单帧出现,则不会被追踪算法分配ID,更不会集满30帧连续骨骼数据并输入到摔倒检测网络中,但如果在家庭中出现连续超过30帧误检时,不仅占据内存还会提高系统的误判率,一直触发警报。因此本文使用了阈值法对提取到的骨骼置信度进行筛选,计算姿态估计算法提取的骨骼点的置信度均值,如果骨骼点的置信度均值连续20帧小于0.35,则将其ID标记FalseSkeleton,不输入到最后的判断中。针对图3第27、28帧前后形变严重的问题,因为姿态估计算法得到的骨骼点形成的外边框比目标检测的BoundingBox变化更小更稳定,因此本文利用多目标跟踪算法跟踪人体姿态估计生成的人体框。
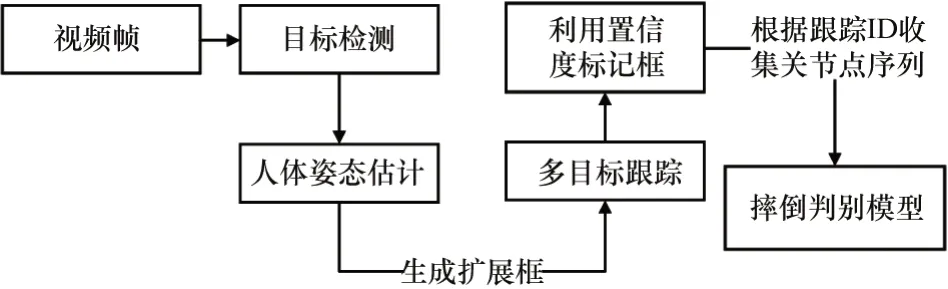
图7 摔倒检测优化方法流程图
3 实验
3.1 实验设置
本文的实验环境是将GTX2080Ti 11G独立显卡作为训练设备和骨骼提取设备,而摔倒检测算法的测试设备为Intel Core i5-6300HQ 2.3GHz处理器与GTX1060 6GB独立显卡的笔记本电脑。摔倒检测算法的实验模型LSTM是基于上述捕捉骨骼策略提取的所有摔倒骨骼数据集进行训练。将整体3个数据集按8:2比例分成训练集和测试集。模型训练批次大小为256,初始学习率设置为1×10-4,训练80轮,在第20轮与第40轮微调学习率为原来的0.5倍,使用Adam优化梯度下降,权重衰减1×10-4,其余采用默认参数。
3.2 实验分析
对骨骼捕捉策略进行实验,实验效果如图8所示。绿色框是RiamRPN++单目标跟踪框,为了跟踪算法能更稳定地跟踪目标,人工框的区域应该尽量小。因为姿态估计算法需要较为完整的人物图像输入才会有更好的结果,因此采用基于跟踪框延伸的红色扩展框作为姿态估计算法的输入数据,绿色框仅作跟踪使用。蓝色框为YOLOv5的目标检测算法的检测框。当检测框与扩展框的IOU在0.8~0.9区间时,就会使用检测框为跟踪框进行修正。当IOU大于0.9时,选择目标检测算法作为姿态估计算法的输入,当检测框没有或者其小于0.8时,则使用扩展框作为姿态估计算法的输入,起到互补的作用。这样一方面可以过滤掉场景中的其他检测框,另一方面可以纠正单目标跟踪算法的跟踪轨迹,使输入到HRnet姿态估计算法中的画面更适合,从而提取更适用的骨骼数据。从图8第一行视角也可以看到追踪算法始终稳定地跟踪着动作执行者,而且图8中第一行全部帧以及Frame126与Frame127背景都出现了额外的目标,但并无提取出多余动作者的骨骼点。当第二行Frame159运动目标消失在画面时,目标跟踪框依旧在提取骨骼点,但画面右上角显示出骨骼的平均为0.213 8且并无高IOU的检测框,此时并不会存储到训练数据中。当Frame197重新出现运动目标时,单目标跟踪算法会重新捕捉并追踪。实验效果表明骨骼捕捉策略可提取较高质量的骨骼数据,减少大量的人工标注成本。
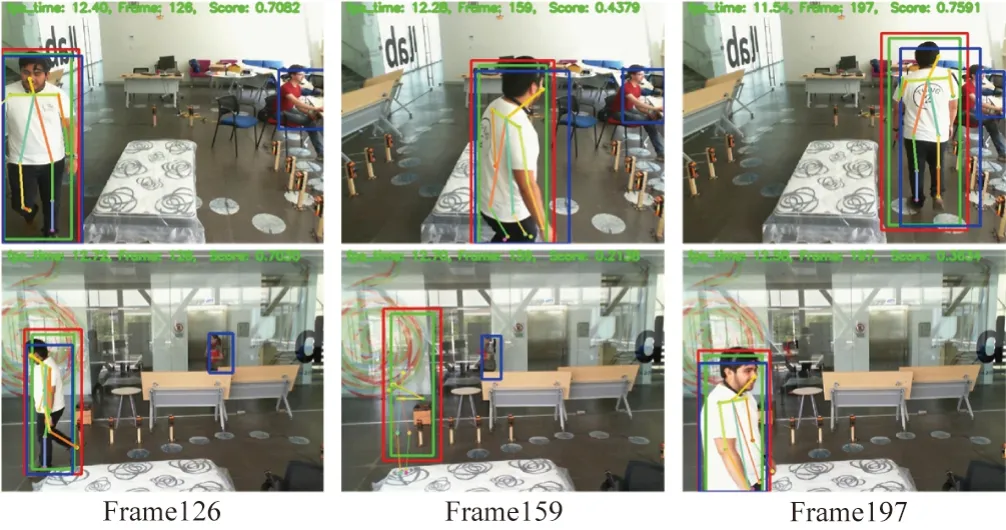
图8 RiamRPN+Yolo骨骼数据提取效果图
对摔倒检测优化框架中的系统逻辑优化进行效果实验对比,实验效果如图9所示。本文将同一个视频输入到经过摔倒检测优化框架(第一行)以及没有经过优化框架的摔倒检测系统(第二行)进行测试。从第144帧、204帧和第214帧可以看到,第一行与第二行人物的Bounding Box都不相同。优化策略的Bounding Box要比Yolo检测框小且变化是更加稳定的,这是因为优化策略的Bounding Box是基于骨骼点向外延伸。检测框更小的变化更有利于跟踪。从后面144帧摔倒到295帧的完全站立可看到,优化策略一直捕捉到跟踪目标并稳定分配为ID2。而普通策略在260帧中已丢失了原来的ID4,并在295帧开始重新分配了ID5。虽然从204帧中多目标跟踪算法跟踪了YOLOv3误检的环境中的凳子,使得第一行和第二行所分配的ID都不是从1开始。但从144帧开始,普通策略的系统对凳子和人物的ID分配已经历多次的变化。这是因为优化策略可继续对凳子进行跟踪并对低置信度的骨骼点进行FalseSkeleton的标记,从而不会输送到后续的动作判断模型中。此实验说明本文的摔倒检测优化方法可以不牺牲算力的前提下使得摔倒检测系统对目标的跟踪更稳定,使得误判率更低。

图9 摔倒优化框架(第一行)及非优化框架(第二行)对比效果图
图9同样是对经过摔倒检测优化框架中的数据预处理的实验效果对比。本文的研究目的并非是摔倒检测模型,因此只选择了简单的3层LSTM模型进行训练。模型对数据集的测试集精度达到了93%。可以看到在模型很好地学习到了本文基于骨骼捕捉策略所获得的较高质量的数据集,并能在现实视频中很好地检测出人物的动作。如144帧中的Fall Down,204、214、260的up(第一行中因丢失目标而失去up动作判断)以及295帧的walking动作。在显示黑框中,动作可视化后面都是模型输出对于当前动作的概率值,如第二行的260帧与295帧,因为当前帧提取到的骨骼点置信度较高,模型对其动作概率值判断约65%和78%。这样更加贴合现实的逻辑。
4 结束语
为了将在摔倒数据集上训练的老人摔倒检测系统能更好地泛化到现实世界中,本文提出了一种骨骼捕捉策略,经试验效果显示,它能过滤摔倒数据集的干扰,并提取出适合训练的骨骼数据,可以大幅度减少标注者的工作量。为了进一步使得摔倒检测系统能更适用于现实世界,本文还介绍了一种摔倒检测优化方法,它包括数据预处理优化及系统逻辑优化。经实验对比验证,基于数据预处理优化策略训练的LSTM模型,在逻辑优化的系统中能准确识别自拍摄的测试视频,在GTX1060显卡中达到约45 fps,模型的准确率达到93%。优化检测方法不仅提高整体系统的稳定性,还降低系统误判率。本论文的工作离部署到边缘设备上还有一定的距离,因此未来的工作中需要在保证摔倒系统各部分精度的前提下进行更加轻量化的实验,以更低的算力成本植入到嵌入式设备中。
猜你喜欢
计算机工程与应用(2022年15期)2022-08-09
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
中老年保健(2021年5期)2021-12-02
中老年保健(2021年5期)2021-08-24
学生天地(2020年3期)2020-08-25
汽车观察(2018年9期)2018-10-23
计算机应用(2018年5期)2018-07-25
诗选刊(2015年4期)2015-10-26
少年科学(2009年12期)2009-07-07
