
结合整体注意力与分形稠密特征的图像超分辨率重建
2023-01-09 14:28陈乔松孙开伟
计算机工程 2022年11期
陈乔松,蒲 柳,张 羽,孙开伟,邓 欣,王 进
(重庆邮电大学计算机科学与技术学院数据工程与可视计算重庆市重点实验室,重庆 400065)
0 概述
图像超分辨率重建[1]是将给定的低分辨率图像通过特定的算法恢复成相应的高分辨率图像。图像分辨率泛指成像或显示系统对细节的分辨能力,代表图像中存储的信息量。在一般情况下,高分辨率图像的像素密度越大,图像中包含的细节越多,但是由于硬件设备限制,往往无法直接获取到高分辨率图像,因此如何在现有的硬件条件下提高图像分辨率成为亟待解决的问题。
图像超分辨率重建方法主要分为基于插值[2]、基于建模[3]、基于学习[4]3 类。基于插值的超分辨率重建方法通过某个点周围若干个已知点的值以及周围点和此点的位置关系,根据计算公式得到未知点的值。基于建模的超分辨率重建方法是对同一场景下的多幅低分辨率图像之间的相关性进行建模,包含频域法和空域法。目前,基于学习的超分辨率重建方法应用比较广泛,通过使用大量的图像数据,建立高低分辨率图像之间的映射关系,低分辨率图像可依赖已建立好的关系生成高分辨率图像,主要包括字典学习[5]、线性回归[6]、随机森林[7]和深度学习[8]等方法。
卷积神经网络(Convolutional Neural Networks,CNN)是深度学习框架中的一种重要网络结构,通过带有卷积结构的深度神经网络处理相关机器学习问题,在超分辨率重建中应用广泛,而且取得了不错的效果。文献[9]提出三层神经网络SRCNN 用于超分辨率重建,其相比于传统方法具有更高的分辨率。文献[10]在SRCNN 的基础上提出改进的FSRCNN模型,该模型通过在网络末端使用反卷积进行上采样,减少了图像的预处理过程。文献[11]提出VDSR 模型,该模型借鉴残差思想避免了深层网络带来的副作用,降低了网络训练难度。文献[12]提出DRCN 模型,该模型使用递归结构,在增加网络深度的同时扩大了感受野,提升了网络表征能力。文献[13]提出RED 模型,该模型采用编码-解码框架,利用对称结构便于反向传播,且避免了梯度消失问题。文献[14]提出的SRGAN 利用感知损失和对抗损失来提升恢复图片的真实感,使得输出图像具有逼真视觉效果。文献[15]提出MSRN 模型,该模型利用多尺度残差块来提取低分辨率图像的特征,实验结果表明其在客观评价指标上优于对比模型,在主观视觉效果上得到的重建图像边缘和轮廓更加清晰。
然而,多数现有图像超分辨率重建模型的特征提取能力不足,导致高频信息丢失并且纹理细节无法被重建,同时大部分模型难以区分高频和低频信息,使得在网络重建时不能注意到真正有用的特征图,从而降低了网络重建能力。针对以上问题,本文提出一种基于整体注意力机制与分形稠密特征增强的图像超分辨率重建模型(简称为HAFN)。建立特征增强模块,通过4 条分支路径提取不同尺度的特征,同时利用局部稠密跳跃连接将高频信息和低频信息相结合,从而提供互补的上下文信息。引入整体注意力机制,通过层次、通道、空间三方面整体调整特征图,从而有效筛选出高频特征,为重建模块提供更丰富的细节信息。
1 基于整体注意力与分形稠密特征的图像超分辨率重建
1.1 模型框架
考虑到现有模型存在的局限性,本文设计一种新的HAFN 模型框架,如图1 所示,主要包含浅层特征提取模块、分形稠密特征增强模块、重建模块三部分,其中:浅层特征提取模块由两层卷积层组成,用来提取角点、颜色等低维信息;分形稠密特征增强模块由4 条不同的分支组成,每条分支的卷积核数量不同,该模型共级联了9 个分形稠密特征增强模块,主要作用是提取更丰富的高频信息,并且增加了模型的容错性和稳健性;重建模块是超分辨率重建任务中非常重要的模块,本文在重建图像时首先利用亚像素卷积层[16]将提取的浅层特征图放大至目标图像大小,然后将主干网络的输出特征图也进行同样的放大操作,并将两者进行逐像素相加,最后利用1×1 的卷积层将其压缩至RGB 三通道得到网络最终输出图像。
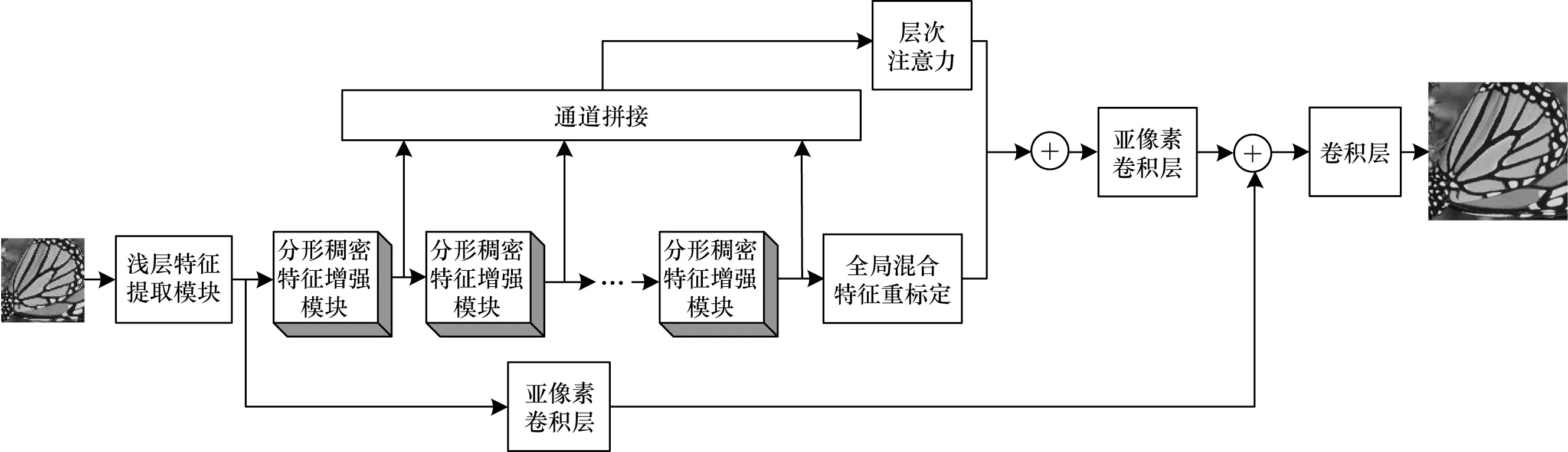
图1 HAFN 模型框架Fig.1 Framework of HAFN model
1.2 分形稠密特征增强模块
本文采用分形稠密特征增强(Fractal Density Feature Enhancement,FDFE)来实现深层特征的提取,结构如图2 所示,其中X表示输入图像。

图2 分形稠密特征增强模块结构Fig.2 Structure of FDFE module
FDFE 模块利用4 条不同的分支路径,每条路径上的卷积个数不同,但卷积核大小一致,从而实现多尺度的特征提取,而且模型会将不同路径的特征图进行相互融合,充分利用不同的特征,然后继续传递。同时,不同路径实现了信息共享,在反向传播时,当一条路径学习到最优参数时可以反馈给其他各条路径,通过共同学习和优化来重新校准特征,而且利用不同路径的梯度可以缓解梯度消失问题,提高模型性能。
该模块借鉴了DenseNet[17]思想,模块输入与各条路径融合后的特征进行通道拼接,这样可以综合利用浅层复杂度低的特征,得到一个光滑且具有更好泛化性能的决策函数。因此,该模块的抗过拟合性能较好,并且特征的重复利用大幅提升了重建精度。
1.3 整体注意力模块
在深度神经网络训练过程中产生的特征图包含了通道、空间和层次信息,这些信息对高频细节的恢复有不同程度的影响,若能增强目标特征,则网络的表达能力会进一步加强。首先引入层次注意力(Layer Attention,LA)单元获取不同层次之间特征图的相关性,然后设计全局混合特征重标定(Global Mixed Feature Recalibration,GMFR)单元建立特征图通道和空间位置的相互依赖关系,最后使用特定结构将这两个单元融合形成整体注意力模块,自适应调整特征的表达能力。
1.3.1 层次注意力单元
层次注意力[18]单元结构如图3 所示,首先将N个FDFE 提取(本文N设置为9)的特征图进行拼接后作为模块输入特征组(Feature Groups,FG),其维数为N×H×W×C,然后利用view()函数将输入特征图转换为N×HWC的二维矩阵,并利用矩阵乘法和相应的转置相乘得到相关性矩阵wi,j,计算公式如式(1)所示:

图3 层次注意力单元结构Fig.3 Structure of LA unit
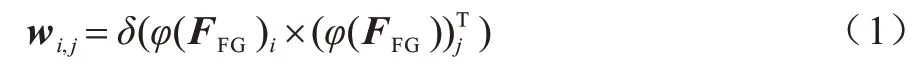
其中:i,j表示层的序号,i,j=1,2,…,N,N表示FDFE模块个数;FFG表示原输入特征组;δ()表示Softmax操作;φ()表示矩阵变换操作。
最后将重构后的特征组与预测的相关矩阵和比例因子α相乘,并加上初始输入特征组得到层次维度的加权自适应特征图FLayer,如式(2)所示:

其中:α表示初始化为0 的可学习参数,随着训练次数的增加而增大,直到学习到一个较好的值;FFGi表示经过矩阵变换操作的特征组。
1.3.2 全局混合特征重标定单元
全局混合特征重标定单元有效整合了空间注意力和通道注意力,如图4 所示。本文对文献[19]提出的空间注意力进行改进,首先通过一个3×3 的卷积层,然后使用深度可分离进行卷积,在减小参数量的同时能通过单独对每个特征图卷积,实现重要信息的最大化利用,执行过程如式(3)所示:

图4 全局混合特征重标定单元结构Fig.4 Structure of GMFR unit

其中:M1表示空间注意力单元的输出;C和D分别表示普通3×3 卷积层和深度可分离卷积;I表示输入特征图。
通道注意力[20]分为挤压和激励两个过程,挤压是全局均值池化操作,可以帮助获得更大的感受野,执行过程如式(4)所示:
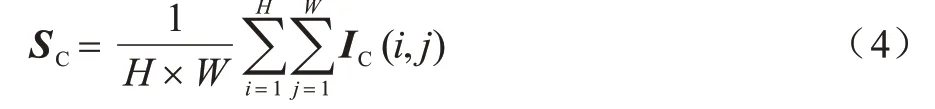
其中:下标C 表示通道;H和W表示特征图的尺寸;S表示经过池化操作后的输出;IC(i,j)表示输入特征图的某个像素点。
激励操作通过一个全连接层对特征图进行线性变换,将通道数量压缩到个,其中r为超参数,再通过ReLU 激活层和全连接层将通道数恢复至输入通道数,执行过程如式(5)所示:

全局混合特征重标定单元融合了这两种类型的注意力机制,并将融合后的特征图与初始输入特征进行跳跃连接,加强特征的信息表达能力,融合公式如式(6)所示:

其中:M表示混合特征重标定模块的输出;I表示模块的初始输入;M1和M2分别表示通道注意单元和空间注意力单元的输出;σ表示Sigmoid 操作;+表示逐像素相加;⊗表示矩阵相乘。
1.3.3 整体注意力融合
为同时利用层次注意力单元和全局混合特征重标定单元的优点,将两者进行融合形成整体注意力模块,融合结构如图5 所示,其中i=9。

图5 整体注意力模块结构Fig.5 Structure of holistic attention module
层次注意力单元的输出首先利用1×1 卷积进行挤压,去除一些无用的特征信息,然后与全局混合特征重标定单元的输出进行通道融合,从而得到不同类型的特征图,最后使用卷积层进行激励操作,整体注意力融合公式如(7)所示:

其中:F表示整体注意力模块的输出特征图;C表示1×1 卷积层;FLayer表示层次注意力单元的输出;M表示混合特征重标定的输出;+表示通道拼接操作。
2 实验结果与分析
2.1 网络训练优化与实现细节
硬件环境为Intel®CoreTMi5-6500 CPU@3.2 GHz CPU、NVIDIA GTX1070 GPU、内存大小为16 GB。软件环境为Windows 10 操作系统、MATLAB R2018b、CUDA v9.0 以及计算机视觉库PyTorch[21]。
在不同图像尺度下进行网络模型训练以及性能评估,使用DIV2K[22]作为训练集,该数据集是新发布的用于图像重建任务的高质量图像数据集,包含了800 张训练图像、100 张验证图像,测试集采用Set5[23]、Set14[24]、BSDS100[25]和Urban100[26],其 中Set5、Set14、BSDS100 这3 个数据集由不同频率的自然风光图片组成,Urban100 由不同频率的城市场景图片组成。
在数据预处理阶段,首先将高分辨率图像随机剪裁成48×48 像素的子图像,然后进行水平垂直翻转以实现数据增强并进行双3 次插值的退化处理。在训练过程中,最小批次设置为16,优化算法为Adam[27-28],初始学习率为1e-4,并采用StepLR 策略,每训练200 轮,学习率减半,总共训练1 000 轮。使用L1 作为损失函数,计算公式如式(8)所示:

其中:A表示总训练样本数;O表示重建的超分辨率图像;G表示对应的标签;z表示训练样本的序号。
2.2 客观性能评价
采用峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)[29]和结构相似性(Structural Similarity,SSIM)[30]作为重建图像质量的评价指标。PSNR 计算公式如(9)所示:

其中:n是灰度图像的比特数,设置为8;eMSE为重建图像与真实图像的均方误差。
eMSE计算公式如式(10)所示:

其中:X、Y表示重建图像和真实图像;X(i,j)和Y(i,j)分别表示重建图像和真实图像的某个像素值;H×W表示图像尺度。
从亮度、对比度和结构三方面出发度量图像相似性,计算公式如式(11)~式(14)所示:
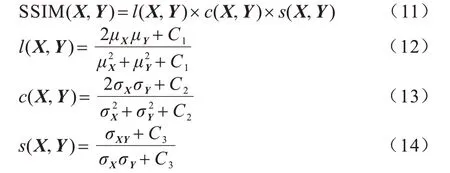
其中:l(X,Y)、c(X,Y)、s(X,Y)分别表示亮度、对比度、结构比较;C1、C2、C3表示不为0 的常数;μX和σX表示重建图像的像素均值和方差;μY和σY分别代表真实图像的像素均值和方差。
将本文HAFN 模型与Bicubic[31]、SRCNN[9]、VDSR[11]、LapSRN[32]、MSRN[15]、DRCN[12]、CARN[33]、IMDN[34]、DRRN[35]等图像超分辨率模型进行性能 对比。表1~表3 给出了不同图像超分辨率模型在4 个测试数据集上当图像放大2~4 倍时的实验结果,其中,最优结果加粗表示,次优结果添加下划线表示。

表1 10 种超分辨率模型在图像放大2 倍后的PSNR 和SSIM 对比Table 1 Comparison of PSNR and SSIM for ten super-resolution models when the image is magnified by two times

表2 10 种超分辨率模型在图像放大3 倍后的PSNR 和SSIM 对比Table 2 Comparison of PSNR and SSIM for ten super-resolution models when the image is magnified by thee times

表3 10 种超分辨率模型在图像放大4 倍后的PSNR 和SSIM 对比Table 3 Comparison of PSNR and SSIM for ten super-resolution models when the image is magnified by four times
从表1~表3可以看出,虽然图像放大2 倍时,在BSDS100 数据集上HAFN 的SSIM 指标略低于MSRN,但是无论图像放大2 倍、3 倍还是4 倍,HAFN 在4 个数据集上的PSNR 指标均超过其他模型,且在图像放大2倍时,在PSNR指标上相比于MSRN最多超出0.44 dB,在图像放大3 倍时,最多超出0.57 dB,在图像放大4 倍时,最多超出了0.37 dB。综上所述,HAFN 重建的图像质量相比于其他模型更好。
2.3 主观性能评价
如图6 所示,选取Urban100 数据集中的img072.jpg 图像进行主观性能评价,首先切割局部子图像,然后分别使用不同模型对其放大3 倍并将重建图像进行可视化对比,可以看出HAFN 重建图像相比于其他模型重建图像背景中的线条更加分明,模糊度更小,边缘更加突出,纹理信息更丰富。

图6 图像放大3 倍后的视觉效果对比Fig.6 Visual effect comparison when the image is magnified by three times
2.4 计算量与参数量对比
为从不同角度验证HAFN 的优越性,对HAFN和其他模型的计算量和参数量进行对比。在Urban100 数据集上,基于各个模型将图像放大4 倍后得到819×1 024 像素的图像,计算量对比如表4 所示,可以看出HAFN 的PSNR 值是最高的,而且计算量明显少于MSRN 和VDSR。

表4 不同模型的计算量对比Table 4 Comparison of calculation quantity with different models
同时,在Urban100 数据集上,基于各个模型将图像放大4 倍后得到819×1 024 像素的图像,参数量对比如表5 所示,可以看出HAFN 的参数量相较于其他模型更具优势。
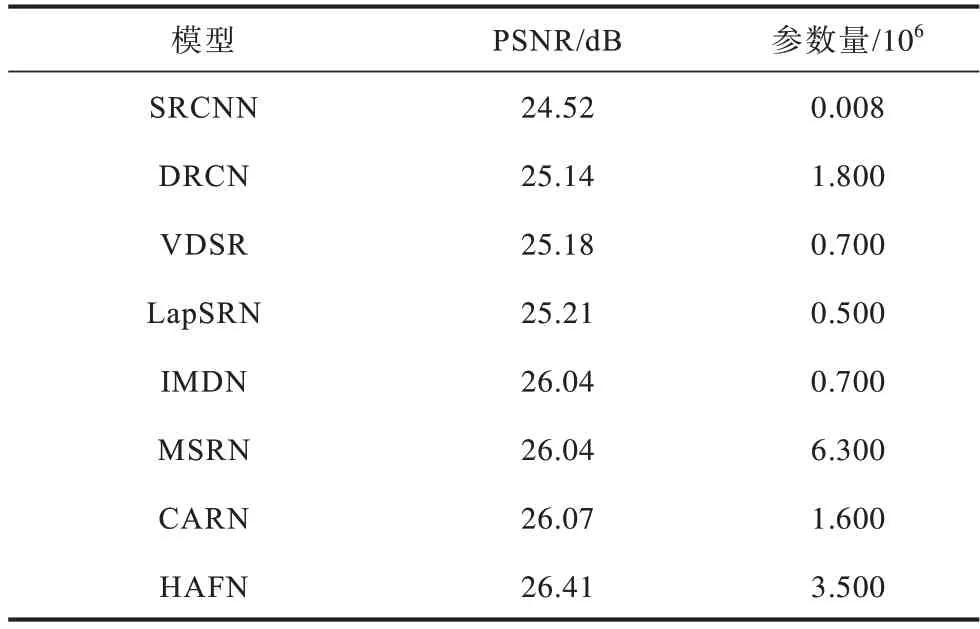
表5 不同模型的参数量对比Table 5 Comparison of parameter quantity with different models
2.5 运行时间对比
在Set14 数据集上利用HAFN 与VDSR、DRCN、LapSRN 等模型将图像放大3 倍和4 倍,并在GPU 上对其运行时间进行对比,对比模型的算法代码来自相关文献的公开源码。从表6 可以看出,HAFN 的PSNR 值明显高于其他模型,而且在图像放大3 倍时,HAFN 运行时间约为LapSRN 的0.43 倍,为VDSR 的0.325 倍,证明了HAFN 更适用于对实时性要求较高的场景。
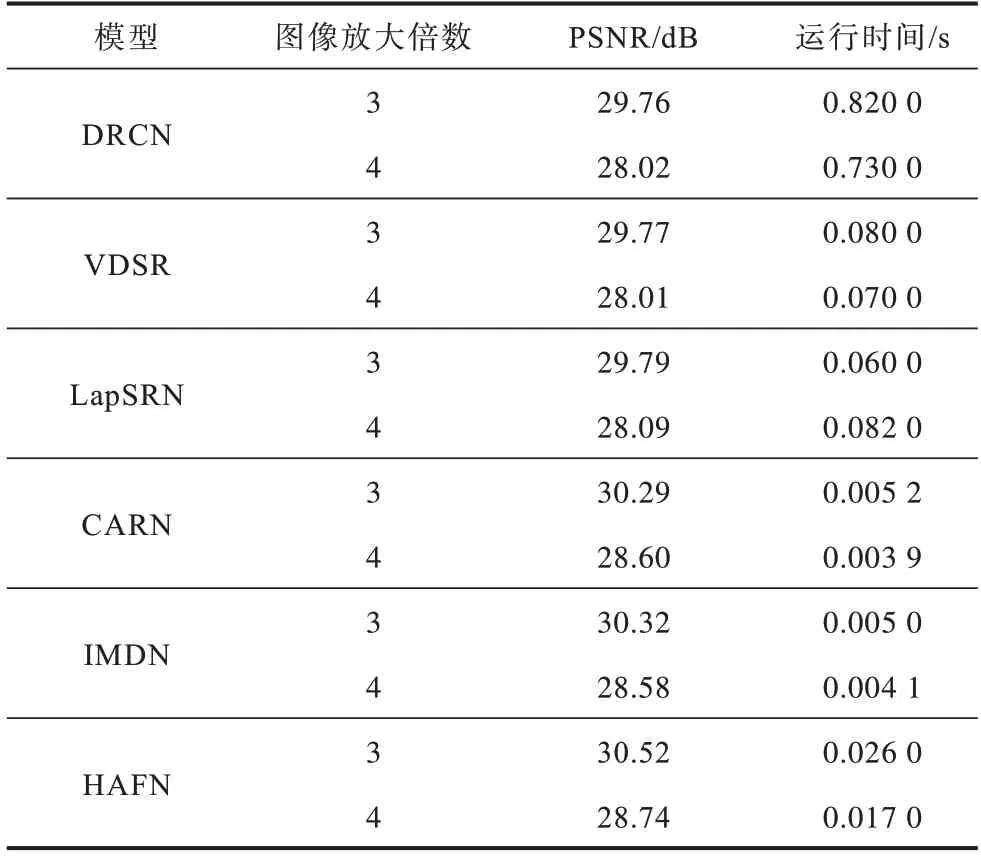
表6 不同模型的运行时间对比Table 6 Comparison of running time with different models
2.6 消融实验分析
2.6.1 层次注意力机制的有效性验证
为验证LA 单元的有效性,主要设计了2 种模型,第1 种是加LA 的模型(简称为LA),第2 种是不加LA 并且不对层次特征做任何处理的模型(简称为No LA),其他模块一致。如表7 所示,在Urban100数据集上,先将图像放大2 倍,再将各个FDFE 模块融合后加入层次注意力单元能够有效地提高重建图像的质量,LA 模型相比于No LA 模型的PSNR 和SSIM 分别提高了0.17 dB 和0.000 4。

表7 层次注意力机制的有效性验证结果Table 7 Effectiveness verification results of layer attention mechanism
2.6.2 全局与局部混合特征重标定对模型性能的影响
为验证全局和局部混合特征重标定方法对于模型重建性能的影响,分别训练加入全局混合特征重标定单元的超分辨率重建模型(简称为GMFR)和加入局部混合特征重标定(Local Mixed Feature Recalibration,LMFR)单元的超分辨率重建模型(简称为LMFR)。如图7(a)所示,在级联的第9 个FDFE模块末尾加入全局混合特征重标定单元。如图7(b)所示,在每个FDFE 模块末尾加入局部混合特征重标定单元。

图7 混合特征重标定单元结构Fig.7 Structure of mixed feature recalibration unit
如表8 所示,在Urban100 数据集上,GMFR 模型在PSNR 和SSIM 两个指标上均优于LMFR 模型,因为局部混合特征重标定只考虑当前的输出特征图,而无法建立全局的上下文关联关系,同时还增加了计算成本。

表8 加入全局与局部混合特征重标定单元的模型性能对比Table 8 Model performance comparison of adding LMFR and GMFR units
3 结束语
针对现有图像超分辨率重建模型存在的局限性,本文提出一种基于整体注意力机制与分形稠密特征增强的图像超分辨率重建模型。通过分形稠密特征增强模块提取不同尺度下的特征图,同时采用层次注意力机制和全局混合特征重标定方法自适应学习重要特征,为重建模块提供丰富有效的高频信息。实验结果表明,该模型在测试数据集上相比于其他模型重建效果更好。后续将利用该模型对受不同噪声干扰的退化图像进行超分辨率重建,使其适用于复杂噪声环境,进一步提升模型应用范围。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
小雪花·成长指南(2022年1期)2022-04-09
汽车维修与保养(2020年11期)2020-06-09
甘肃教育(2020年22期)2020-04-13
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
家庭影院技术(2018年9期)2018-11-02
中国惯性技术学报(2017年1期)2017-06-09
电子制作(2017年23期)2017-02-02
第二课堂(课外活动版)(2016年2期)2016-10-21
