
基于文本数据特征识别的电力运营信息模型设计
2023-01-08 16:48俞阳邹云峰康雨萌孙少辰
电子设计工程 2023年1期
俞阳,邹云峰,康雨萌,孙少辰
(国网江苏省电力有限公司营销服务中心,江苏南京 210000)
在电力服务运营过程中,各电网公司积累了海量、多样化的电力运营数据。这些数据中非结构化数据占80%以上[1-3],如录音、文本数据等。非结构化数据主要来自于电网公司的客户服务系统,其文本数据蕴含客户故障报修、信息查询、业务办理等业务需求[4-5]。如何充分利用该文本数据,深入了解客户的真实需求,对进一步提高供用电服务水平、改善用户用电体验均具有重要意义。
基于传统数据挖掘技术无法实现文本数据的特征分析,因此文本挖掘技术应运而生。文本挖掘技术结合计算机技术、人工智能算法等,实现文本中有价值信息的提取[6-7]。目前,文本挖掘在电力领域的应用主要有电力设备的状态感知、故障诊断和系统可靠性评估等[8-10],但其在电力运营领域应用较少。
针对此,该文将文本挖掘技术应用于电力运营文本数据的信息处理,以实现电力运营文本分类。同时深入了解电力客户需求,进而提高电网公司服务水平。
1 电力运营文本数据预处理
电力运营文本数据特征识别的流程框架,如图1所示。将输入的文本数据经预处理得到文本数据的中间形式,然后通过文本特征识别模型挖掘文本数据的内在联系,最终输出文本特征识别结果。若原始运营文本数据质量差,则将大幅降低对特征识别结果的准确率。因此,文本预处理是进行文本数据挖掘与特征提取的关键前置步骤。

图1 文本数据特征识别流程
1.1 电力运营文本数据特征分析
典型的电力运营文本数据具有以下明显的特征[11]:文本长度短、专业性强、规范性差、价值密度低。
因此,文本数据的预处理对于剔除电力运营文本信息中的异常数据,过滤无实际意义的文本信息,并最终实现对地点、故障等关键特征的提取具有重要意义。该文采用的电力运营文本数据预处理步骤包括:文本清洗和文本分词。
1.2 电力运营文本数据清洗
电力运营文本数据清洗流程如图2 所示[12],主要包括以下步骤:剔除空白文本数据、剔除过短文本数据、规则过滤文本数据。
1.3 基于Dijkstra的文本分词算法
基于迪杰斯特拉(Dijkstra)的文本分词算法步骤,如图3 所示[13]。
由图3 可知,其主要包含以下步骤:
1)构建文本数据的有向无环图,假设A=a1a2…ai-1ai…aj…an为文本数据,其中ai为单个文字,文本数据共包含n个文字。如图4 所示,构建的有向无环图G方法如下:

图4 文本数据对应的有向无环图
1)G包含n+1 个节点V0,…,Vn,任意相邻节点Vi和Vi+1通过有向边连接,方向从Vi指向Vi+1,该边对应词ai,边的权重值为wi;
2)对于词典中的词Bk=aiai+1…aj,则在节点Vi-1与Vj之间增加一条有向边,方向从Vi-1指向Vj,该边对应词Bk,边的权重值为wk。
2)将文本数据对应的有向无环图G中的节点划分为两类:已知最短路径的节点与未知最短路径的节点,分别对应节点集合S和U。将中间向量L={lk},lk表示节点Vk到初始节点V0的最短路径长度值。
3)初始状态下,S只包含初始节点V0,U包含节点V1,…,Vn共n个节点。然后从U中筛选到初始节点V0长度值最短的节点Vk,并将节点Vk从U转移到S,且有:

4)将节点Vk当作中继节点,继续在U中搜索到初始节点V0的最短路径。假设搜索的下一个节点为Vu,则有:

5)判断是否搜索至目标节点Vg,若为否,则循环步骤3)和步骤4);若是,则退出循环,输出结果。
2 电力运营信息模型设计
2.1 TF-IDF模型
经过上述电力运营文本分词,将得到包含文本数据含义的特征项。该文采用词频-逆向文档频率算法(Term Frequency-Inverse Document Frequency,TF-IDF)来提取这些特征项。TF-IDF 是文本挖掘中常用的基于文本相似的特征提取技术,采用权重来评估单词、句子甚至文档的重要性[14]。
TF-IDF 的核心思想是对于一个单词,其高频率地出现于某个文本数据中,且该单词又较少出现在总文本样本中的其他文本数据中。则可以认为该单词对于该文本样本具有较强的区分能力,能够用作为该文本数据的分类标签。因此,TF-IDF 算法采用词频与逆向文档频率之乘积作为权重,其计算方法如下:
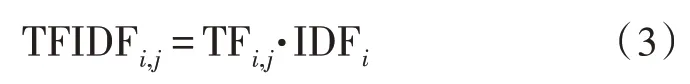
式中,TFi,j是单词i在文本j中的出现频率,计算方法如下:

IDFi描述的是单词i在其他文本中出现频率的倒数,计算方法如下:

式中,D为文本样本总数,{j:i∈j} 为包含单词i的文本数量。为了避免所有文本样本不包含单词i导致分母为零的情况,通常在{j:i∈j} 的基础上加1。
2.2 数据处理模型
1)深度学习模型
典型深度学习网络的结构如图5 所示,其由输入层、输出层和多层隐藏层构成。

图5 深度学习网络结构
深度学习网络通过层层迭代实现信息传播与特征的学习。层与层之间的关系如下:

式中,zl表示l层的输入信息;fl-1()表示l-1 层的激活函数;Wl与bl分别为从l-1 层到l层的权重值和偏置值。
2)LSTM 模型
对于处理具有时间序列特征的数据样本,传统的深度学习模型适应性较差,因此长短期记忆(Long Short-Term Memory,LSTM)模型由此发展而来,其属于循环神经网络(Recurrent Neural Network,RNN)的一种。RNN 的典型网络结构模型如图6 所示。其与传统神经网络的区别在于隐藏层的输入由当前时刻的输入信息和上一时刻隐藏层的输出信息构成,从而使得网络具备了记忆功能。

图6 RNN结构
LSTM 相对RNN 的区别在于LSTM 采用了特殊结构的记忆单元作为循环单元[15-16]。典型记忆单元的结构如图7 所示。

图7 LSTM结构
由图7 可知,LSTM 引入了一个内部状态ct,计算方式如下:

式中,ft∈[0,1]D、it∈[0,1]D、ot∈[0,1]D分别为遗忘门、输入门和输出门的状态,其实现信息传输路径的控制。为中间状态,计算方式如下:

上述三个门实现的功能如下:遗忘门实现上一时刻内部状态遗忘信息的控制;输入门实现当前时刻中间状态保留信息的控制;输出门实现当前时刻内部状态输出信息的控制。其计算方式如下:

2.3 信息处理算法
基于上述算法模型,设计了基于TF-IDF-LSTM的电力运营信息处理算法流程,如图8 所示。将电力运营原始文本作为输入,然后进行文本清洗、文本分词等数据预处理操作;进一步基于TF-IDF 算法实现文本数据特征的提取;最终,通过LSTM 模型实现电力运营文本的分类识别。

图8 电力运营信息处理算法流程
3 算例分析
为验证该文所提算法的准确性和有效性,文中选取某电网公司在2020 年的10 000 条真实电力运营文本数据作为实验样本,并将其以4∶1 的比例随机划分为训练集和测试集。分类结果包括业务办理、信息查询、停送电查询、法律法规、服务质量、停电、电能质量和供电安全共八类。
3.1 电力运营信息处理算法性能对比
选取LSTM、TF-IDF-SVM 两种算法与该文所提TF-IDF-LSTM 算法进行对比。选取2 000 条测试文本数据,一级分类结果的准确率如表1 所示;二级分类结果的准确率如表2 所示。

表1 一级分类不同算法的性能对比

表2 二级分类不同算法的性能对比
对于一级分类,所提TF-IDF-LSTM 算法的准确率为92.6%,LSTM 与TF-IDF-SVM 算法的准确率分别为84.1%和84.8%;对于二级分类,所提TF-IDFLSTM 算法的分类准确率均大于90%,LSTM 和TFIDF-SVM 算法分类准确率均小于90%。
由此可见,该文所提TF-IDF-LSTM 算法具有更高的分类准确率。这是因为文中所提算法相比于LSTM 算法,通过TF-IDF 算法提取特征信息,实现了分类学习模型的预训练。相比于TF-IDF-SVM 算法,LSTM 算法通过记忆单元的特殊结构提高了模型的学习能力,从而提升电力运营文本分类结果的准确性。
3.2 电力运营信息处理算法应用效果
将该文所提算法模型应用于该电网公司2018-2020 年中的全部电力运营信息文本,得到的文本分类结果如图9 所示,纵坐标代表数据量。可以看到在客户的反馈中,业务办理、信息查询和停送电查询这三类比重较大,占全部业务诉求的91%。对于这三类业务的处理,电网公司可以进一步加大网上业务办理以及微信查询等功能的应用推广。以满足客户的业务需求,并减少客服人工资源的投入,提高运营服务水平。

图9 电力运营文本分类结果
4 结束语
该文开展了文本挖掘技术在电力运营信息中的应用研究,提出了基于TF-IDF-LSTM 的电力运营文本分类方法。通过算例分析表明:文中所提算法相比于仅采用LSTM 算法,能够通过TF-IDF 算法实现文本特征单词的预提取,且提高模型的泛化能力;相比于TF-IDF-SVM 模型,采用LSTM 算法具有更高的学习能力,且分类结果更加准确。然而该文仅实现了对电力运营文本的分类,如何结合电力生产的文本数据实现电网故障的精准定位,辅助电力运维业务的智能化,将在未来的研究中展开。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
机械工业标准化与质量(2022年6期)2022-08-12
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
数学小灵通(1-2年级)(2021年4期)2021-06-09
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
当代陕西(2019年10期)2019-06-03
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
