
一种基于模态分解和机器学习的锂电池寿命预测方法
2023-01-06 02:43肖浩逸何晓霞梁佳佳李春丽
储能科学与技术 2022年12期
肖浩逸,何晓霞,梁佳佳,李春丽
(武汉科技大学理学院,湖北 武汉 430065)
在环境污染、新冠疫情、国际局势等一系列不确定性因素的背景下,伴随着石油价格的上涨,能源和储能系统变得至关重要。锂离子电池由于具有能量密度高、污染低、充电快、重量轻、性能好等优点,已经广泛应用到一系列电子设备中,在航空航天、移动通信和新能源电动汽车等各个领域都是主要的能源来源[1-2]。但是伴随着电池使用次数和充放电循环次数的增加,电池性能会下降,容量通常会降低,安全性也大幅下降,甚至可能会导致一些灾难[3]。因此为了确保电子设备的安全性和可靠性,有必要对锂电池的健康状况(state of health,SOH)进行有效的控制和管理[3-4]。其中电池剩余使用寿命(remaining useful life,RUL)是电池健康管理的重要指标,剩余使用寿命的预测能提高电源性能,对于优化电池管理系统设计和终生校准保护至关重要[1,5]。
对于RUL 的预测方法,目前多数文献采取数据驱动方法。基于数据驱动方法可以直接从电池的监控测量指标中去分析与挖掘电池性能退化趋势的影响因素[6],该方法能回避一些电化学反应的复杂和专业性问题,具有较强的普适性[7]。关于数据驱动的方法的文献层出不穷[8-10],其中有使用传统统计学方法,如指数模型、多项式模型甚至是混合模型去拟合容量衰减的轨迹[11]。文献[12]采用了经验指数和多项式回归融合,并加入粒子滤波(particle filtering,PF)等算法融合,还有高斯过程回归(Gaussian process regression,GPR)[7,13],自回归移动平均(auto-regressive moving average,ARMA)[14]等等方法做出电池剩余寿命的预测。
起源于人工智能领域的机器学习技术,拥有着极其强大的预测能力,在电池寿命预测领域也有广泛的应用。文献[15]使用电池早期循环数据,构建WOA-XGBoost的混合模型进行寿命预测,文献[16]使用相关向量机(relevance vector machine,RVM)进行预测,还有时间规整图和支持向量机回归(support vector machine regression,SVR)的结合[17]等。基于深度学习的高精度预测算法被认为是最适合的预测模型[1]。神经网络系列算法由于具有强大的特征学习和非线性趋势拟合的能力,同样也被广泛运用于RUL 预测。文献[18]采用长短期记忆神经网络(long short-term memory,LSTM)进行电池寿命预测,文献[2]采用4 种神经网络对比研究,发现长短期记忆网络预测效果最佳。因此很多学者都会基于改进的LSTM网络方法去预测电池剩余使用寿命[19-20]。基于LSTM 网络改进的门控单元循环神经网络(gated recurrent unit,GRU)也经常在电池寿命预测中被采用[21]。同样有将传统方法与神经网络结合起来去预测电池寿命[22-23],甚至是采用不同种类的神经网络融合的方法[24-26]。
电池在充放电循环中会出现一定的容量再生的现象,并且受到一些客观因素(温度、电化学反应、测量设备误差等)的影响,电池容量的原始数据总是充满噪音的,高频动态和非线性容量曲线会影响神经网络准确学习电池容量的衰退特征[27]。针对该现象,现有的大量文献都使用经验模态分解(EMD)对电池容量数据进行分解降噪处理,然后再采用ARMA[28]、GPR[29]或神经网络[30-32]等方法进行RUL预测。基于EMD 改进的自适应白噪声完整集成经验模态分解(complete ensemble empirical mode decomposition with adaptive noise analysis,CEEMDAN)广泛应用于股票投资、生物医学等时间序列数据的领域[33],采用CEEMDAN进行降噪得到趋势项,然后再构建神经网络进行预测会得到更好的预测效果。
然而大多数的文献对容量曲线进行EMD 分解之后只保留了趋势项进行预测,而对虽然充满噪音却同样也可能含有一部分真实特征信息的高频波动分量进行了舍弃。为了得到更准确的预测效果,分量里面的信息同样应给予一定的权重。文献[28]对每个波动分量进行白噪声检验,然后利用皮尔逊相关系数进行加权重构。文献[30]采用灰色关联度分析(grey relation analysis,GRA)进行了特征筛选,文献[34]对电池原始特征提取和变换后,采用随机森林(random forest,RF)筛选出重要性高的特征。
基于上述分析,本工作采用电池容量作为健康状况的指标。首先采用CEEMDAN 分解电池容量的序列数据进行降噪,为了准确度量波动分量对原始数据信息的解释程度,本工作提出了使用RF 回归去得到每个分量对原始数据解释能力的权重。然后对每个不同频率的波动分量构建不同的神经网络模型得到预测结果,再与RF 得到的重要性的权重数值进行加权整合重构。这样既避免了波动分量中噪音对模型预测能力的影响,且未完全抛弃波动分量里面的特征信息。最后本工作对预测表现较好的两种网络——LSTM 和GRU 引入了一种简单编码解码(simple encoder-decoder)的机制,让其更好地学习到序列数据全局时间上的特征和远程的依赖关系。使用美国国家航天局(NASA)的锂离子电池公开数据集验证该模型的有效性。实验结果表明,CEEMDAN-RF-SED-LSTM 在电池的RUL 预测上表现效果好,加入了RF和SED的组合模型预测结果具有更高的精度。
1 相关理论基础
1.1 电池健康状况定义
电池的健康状况是表示电池当前性能退化程度的重要指标[27]。随着电池使用次数增多,最大可用容量会不断降低。电池剩余使用寿命由容量比定义。

式中,C0表示初始额定容量,Ct表示t时刻测量的容量。一般认为电池寿命达到原始容量的70%~80%时,则认为其寿命终止。而电池RUL就是指在电池使用过程中容量达到初始容量70%~80%之前剩余还能使用的循环充放电次数。
1.2 自适应白噪声完整集成经验模态分解
CEEMDAN 是基于EMD 的改进的算法[35],常用于处理非平稳非线性的数据。它将原始数据中加入白噪声,可以放大各个模态之间的不相关程度,便于将原始数据的模态分解开,具有运算速度快、屏蔽迭代次数少、更好的模态分解效果等优点。其步骤主要分为如下几步:
(1)向数据里加入振幅为εk-1的高斯白噪声εk-1Ek-1ωi(t),(i= 1,2,…,I),Ek(·) 表示经过EMD分解后得到的第k个模态分量。
(2)将每个加入了白噪声的数据Rk-1(t)+εk-1Ek-1[]ωi(t) ,(i= 1,2,…,I),进行EMD 分解,得到每个第一个模态分量IMFki,然后取均值,得到本轮分解出来的模态分量IMFk。
(3)更新本轮的残差Rk(t)=Rk-1(t)-IMFk,然后确定下一轮的白噪声幅值εk-1,重复步骤(1)和(2),直到最后的残差无法分解停止。
1.3 随机森林
随机森林最早由Breiman[36]提出,其思想来自于集成学习法。随机森林采用了随机特征选择的策略。使用重采样的样本,但是在每棵决策树的一个节点分裂时,仅随机从p个特征变量里选取m个变量进行分裂,每棵决策树都如此。这样就尽可能降低了决策树之间的相关性。然而在每棵决策树分裂时未使用全部特征变量的信息,无疑会增大偏差。但是会换取方差更大幅度地减小,从而整体上降低总误差即均方误差。
在决策树进行节点分裂的时候,每次使用了一个变量。可以考察该变量分裂使得损失函数即残差平方和下降的幅度。对于所有变量,可以度量随机森林的每棵决策树由该变量分裂导致的损失函数的下降幅度,再对每个下降幅度进行每棵决策树平均,可以作为该变量重要性的度量。
随机森林算法在筛选变量方面具有优良的性质,不易过拟合,准确性高,适用于高维数据,并且不会受到自变量之间存在着多重共线性的影响。作为非线性非参数的方法,很适合用来作为模态分解后的波动分量的重要性度量,能准确衡量每个分量对于原始数据的解释能力,并以此得到每个分量的重要性度量。
1.4 神经网络
本工作采用了5种神经网络的基础模型,分别为多层感知机(multi-layer perceptron,MLP)、一维卷积神经网络(1D CNN)、循环神经网络(RNN)、长短期记忆神经网络(LSTM)、门控循环单元神经网络(GRU)。每种网络的基本架构简介如下。
1.4.1 多层感知机
MLP是指在神经网络中加入一个或者多个隐藏层去克服线性模型的限制,能够更普遍地处理函数关系。原理公式为:

1.4.2 一维卷积神经网络
一维卷积神经网络可以用于处理序列数据问题,而且计算代价小。本工作一维卷积网络如图1所示。

图1 一维CNN结构图Fig.1 A 1D CNN structural diagram
输入序列数据经过卷积核做互相关运算,得到局部一维序列子段,然后采用最大池化层提取每一小段的信息,保留主要的特征同时减少参数,最后采用全连接层得到xt+1的估计量。
1.4.3 循环神经网络
循环神经网络(RNN)对具有序列特性的数据十分有效,它能挖掘数据中的时序信息。其原理见图2。
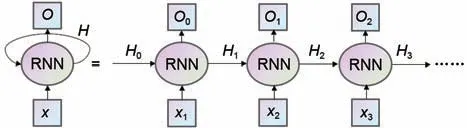
图2 RNN结构图Fig.2 An RNN structural diagram
可以看出每步的输出O不仅受到输入x的影响,还会受到上一时刻的隐状态H的影响。当前时间步隐藏变量由当前输入和前一时刻隐藏变量一起计算时得出:

1.4.4 门控循环单元神经网络
GRU 和LSTM 改进了RNN 梯度爆炸或是消失等缺点,并且通过“门”的机制可以控制隐藏状态。GRU 具备重置门、更新门和候选隐状态。重置门让GRU 获取序列中的短期依赖关系,而更新门有助于学习序列中的长期依赖关系,其内部神经元结构如图3所示。

图3 GRU神经元内部结构图Fig.3 Internal structure diagram showing the GRU neuron
其原理公式为:


1.4.5 长短期记忆神经网络
虽然相比GRU,LSTM 的计算代价要大一些,但许多文献表明LSTM是在序列数据预测中表现最为良好的循环神经网络[1-2]。LSTM同样具备学习序列数据之间的长期和短期的特征。它具备输入门、遗忘门、输出门和候选记忆元,其内部神经元结构如图4所示。
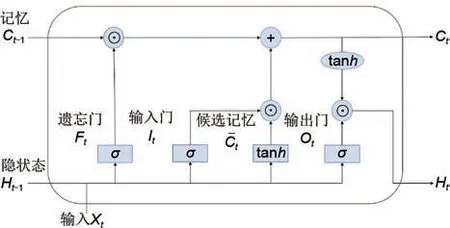
图4 LSTM神经元内部结构图Fig.4 Internal structure diagram showing the LSTM neuron
其原理公式为:

1.4.6 简单编码解码
本工作引入了一种简单编码解码(SED)的结构以便让神经网络能在预测时间步长上通过解码器的隐藏状态更好地学习序列数据全局时间上特征和远程依赖关系。编码器中的输出作为隐藏状态神经元放入解码器再次进行循环神经网络的隐藏层运算,其结构如图5所示。

图5 简单编码解码结构图Fig.5 A simple encoding and decoding structural diagram
2 预测流程及评价指标
2.1 预测流程
本工作提出的RUL预测的流程如图6所示,其主要步骤如下。

图6 整体预测方法框架Fig.6 The Overall Forecasting Methodology Framework
(1)选取一个电池的所有电容量数据进行CEEMDAN分解为N个分量IMFi,然后将每条分量进行神经网络拟合,得到每条分量的神经网络模型。
(2)将每条分量作为特征变量,原始数据作为响应变量,进行随机森林回归,得到每个分量的变量重要性的数值,作为权重。
(3)将每条分量的神经网络模型进行预测,得到所有分量的预测值,然后利用随机森林的变量重要性权重进行加权重构,得到原始数据的估计值。最后和真实数据进行评价指标的计算,作为预测模型性能的评价准则。
2.2 模型评价指标
对于模型的预测结果采用如下4 个指标进行评价,分别是平均绝对误差(mean absolute error,MAE)、均方根误差(root mean square error,RSME)、平均绝对百分比误差(mean absolute percentage error,MAPE)和相对误差(relative error,RE)。其计算公式定义见式(16)~(19)。

其中,n为序列的长度,xt为整个序列的取值,RULpred和RULtrue代表预测的剩余使用寿命和真实的剩余使用寿命。
3 RUL预测结果和分析
3.1 数据集介绍
本工作使用的是美国国家航天局(NASA)的锂离子电池公开数据集。选取第一组4个电池作为研究对象,编号为B0005、B0006、B0007、B0018。其测试的温度为24 ℃,充电过程是以1.5 A的恒定电流进行充电,直到电池电压达到4.2 V,然后以恒定电压充电,直至充电电流降至20 mA。放电过程是以2 A 的恒定电流模式进行放电,直到电池5、6、7 和18 的电压降到2.7 V、2.5 V、2.2 V和2.5 V时停止。电池达到寿命的情况为额定容量下降到初始容量的70%,即4块电池的额定容量从2 Ah到1.4 Ah时,可认为其寿命终止。4块电池的容量随充放电循环次数的变化见图7。
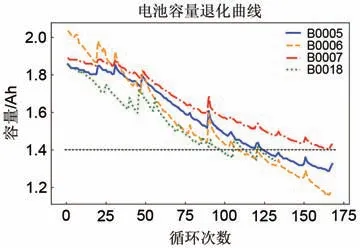
图7 NASA数据集电池容量退化曲线Fig.7 The NASA dataset battery capacity degradation curve
3.2 CEEMDAN分解
使用CEEMDAN对4组电池的容量数据进行分解,B0005和B0006电池容量分解结果如图8所示。
如图8所示,实验过程中每个电池都分解出了四条分量,其中IMF4 为趋势项,其他IMF1 到IMF3 为高频分量,这些分量包含噪音,但也可能包含一部分真实信息。分量依次按照频率的高低进行排列。并且每条分量的最大值和最小值,即波动幅度都不完全相同。下文通过随机森林对分量进行权重优化。

图8 B0005和B0006电池容量分解的模态分量Fig.8 Modal components of B0005 and B0006 battery capacity decomposition
3.3 随机森林回归
将每个电池的IMF1至IMF4作为特征变量,原始数据作为响应变量进行随机森林回归,然后进行变量重要性计算和排序,得到数值结果见表1。

表1 随机森林回归结果Table 1 Random forest regression results
所有电池的随机森林回归的拟合优度是99%以上,意味着分解出来的分量对于原始数据有非常好地解释能力。IMF4 是趋势项,因此权重固定为1,由此计算得到的每个高频波动分量的权重系数如表1所示。从表中可以得出每条分量对于原始数据的解释能力是不一样的,而且不一定频率越低的分量对原始数据的解释能力越高,例如B0006电池的IMF1的重要性系数比IMF2高,B0007电池的IMF2的重要性系数比IMF3要高。因此对于每个分量的权重系数调整是有必要的。
3.4 神经网络预测
本工作首先采用单独神经网络、CEEMDAN+神经网络、CEEMDAN+RF+神经网络3 种方法在B0005号和B0006号电池上进行测试,比较5种不同网络的预测性能,以及加入了CEEMDAN 和RF进行优化后的模型的性能对比。计算每个模型的预测4个评价指标以及运行时间如表2和表3所示。
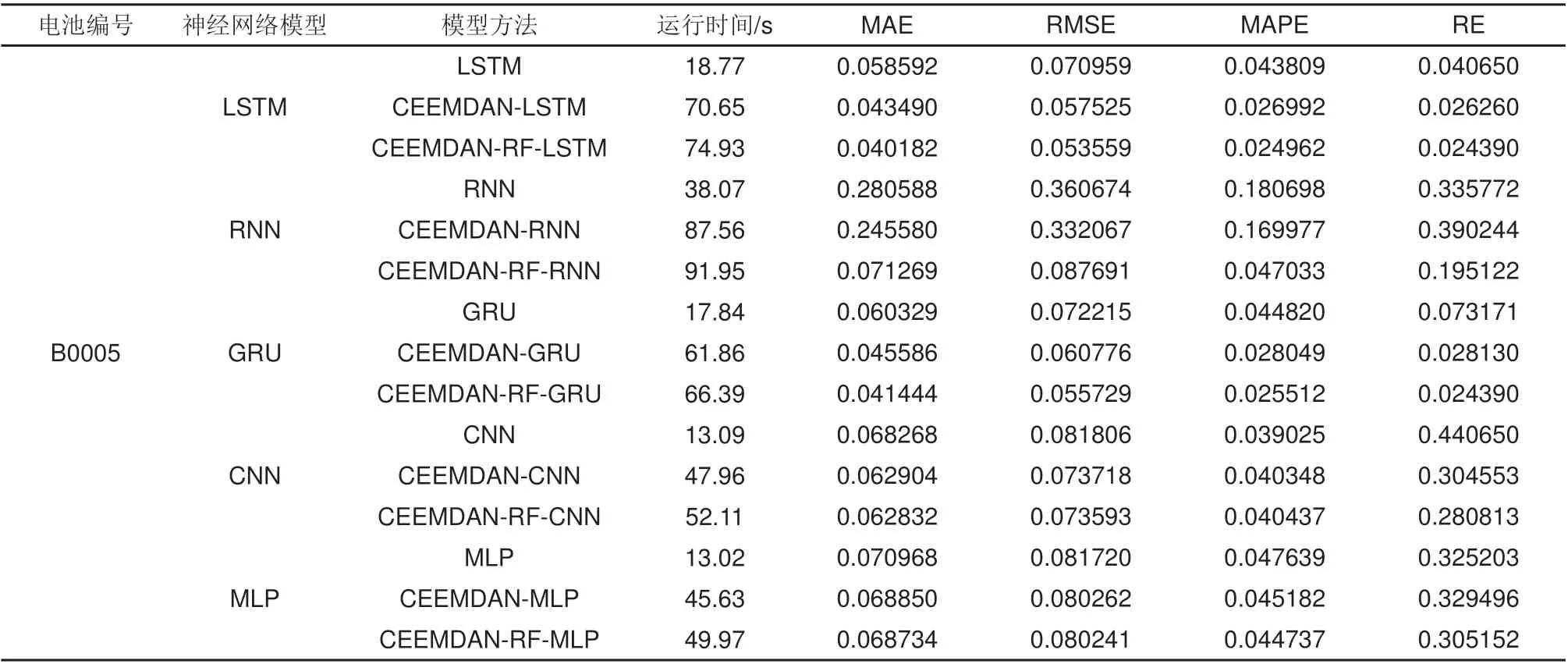
表2 B0005预测评价指标结果Table 2 B0005 prediction and evaluation index results

表3 B0006预测评价指标结果Table 3 B0006 prediction and evaluation index results
从表2 和表3 中,首先对比5 种不同神经网络在B0005 和B0006 的预测表现,无论是单独使用神经网络或是采用不同的组合方法,5 种神经网络的性能均为LSTM 和GRU 最佳,其中LSTM 在精度上略优于GRU,但同时计算时间也略有增多。CNN 和MLP 在预测精度上表现中等,但其计算时间要显著低于其他3 种网络。表现最差的网络是RNN,无论从精度还是运算时间上来看,都不如其他4 种网络。这可能是电池数据中的高频动态和非线性容量曲线影响了其性能。
再从方法组合的角度进行对比,采取了CEEMDAN 分解之后再去进行神经网络的预测基本上会比单独神经网络模型得到的结果具有更低的误差,并且模型加上RF 进行分量的权重调整预测结果后,从MAE、RMSE、MAPE、RE 四组误差指标上进行比较,全面优于只采用CEEMDAN+神经网络方法的精度。此外,4 组误差指标在每一个神经网络的模型上都是进一步下降的,这说明采用RF进行分量权重调整的策略是有效的。
下文对表现较好的两种网络——LSTM 和GRU 引入了简单编码解码(SED)的机制,让其更好地学习到序列数据全局时间上的特征和远程的依赖关系。图9 比较所有的组合方法在B0005 和B0006上的预测性能表现。
由于LSTM 网络表现最佳,图9 中只展示了LSTM 网络在不同方法组合中的4 组评价指标,其他网络也类似图9 中结果。可以看出在引入了简单编码解码(SED)的机制后,在电池B0005 和B0006 上进行训练与预测,所有误差指标都再次进一步下降,并且下降幅度较大,说明在进行简单编码解码后,神经网络模型能更好地学习到电池容量序列数据在全局时间上退化的特征。对4组电池使用组合模型得到的预测评价指标计算如表4 所示,其CEEMDAN-RF-SED-LSTM 拟合效果图见图10。

图9 所有组合方法的评价指标对比Fig.9 Comparison between the evaluation indicators for all combination methods
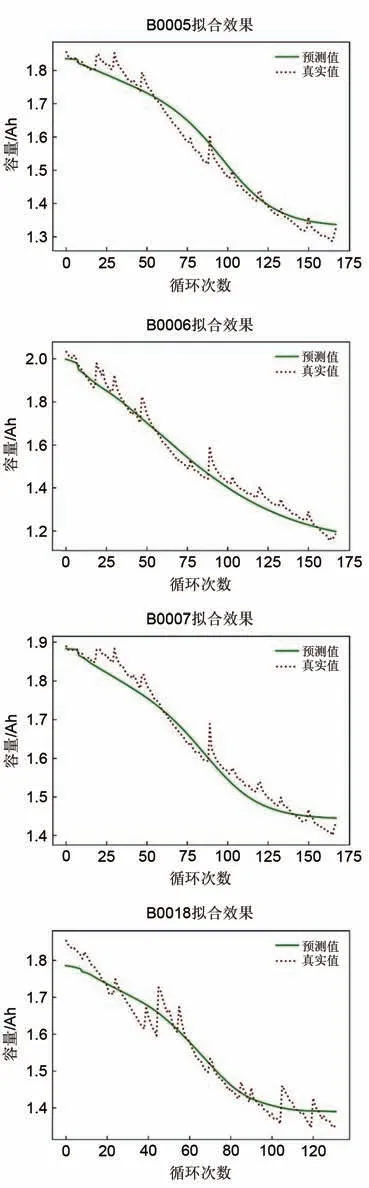
图10 四组电池的CEEMDAN-RF-SED-LSTM模型拟合图Fig.10 Fitting diagram showing the CEEMDAN-RFSED-LSTM model for the four understudied groups of batteries
结合表2、表3 和表4 可知,CEEMDAN-RFSED-LSTM 方法相比单一的LSTM 模型,误差指标平均下降了40%~50%,相比CEEMDANLSTM 方法,误差指标下降了30%~40%。并且在其他神经网络上也具有类似的表现。四组电池的预测误差指标MAE 和RMSE 都控制在5%以内,具有较高的预测精度。

表4 四组电池预测评价指标结果Table 4 Prediction and evaluation index results of the four groups of batteries
实验结果表明,本工作提出的CEEMDAN-RF-SED-LSTM 在电池的RUL 预测上表现效果好,预测结果相比单一模型具有较高的精度。
4 结论
本工作采用模态分解和机器学习算法,提出了一种CEEMDAN-RF-SED-LSTM 方法框架去预测RUL。选取电池容量作为健康因子,使用随机森林回归对自适应白噪声完整集成经验模态分解(CEEMDAN)方法分解出来的电池容量的序列数据每条波动分量计算它们对原始数据的解释程度,得到每个分量的重要性排序和数值,然后与不同频率的波动分量的神经网络模型得到预测进行加权整合重构。进而得到锂离子电池剩余使用寿命的预测。选取NASA 数据集验证该模型的精度,得到结论如下:
(1)电池数据由于容量再生和一些客观因素的影响,原始数据总是充满噪音的,高频动态和非线性容量曲线会影响模型准确地学习电池容量的衰退特征。而采用CEEMDAN 分解对电池数据进行降噪处理是有效的,能进一步帮助模型提高精度。
(2)分解出来的高频分量虽然充满噪音,却同样可能含有部分数据真实特征信息。实验结果表明,本工作使用随机森林回归去调整每条波动分量权重的方法是有效的,5 种神经网络预测结果的误差都进一步下降。
(3)在时间序列数据的预测问题上,5 种神经网络中LSTM 和GRU 两种网络表现最为良好,一维CNN 由于其计算代价小、速度快,综合考虑同样也具有不错的效果。
(4)对神经网络引入简单编码解码(SED)的机制,可以让其更好地学习到序列数据全局时间上的特征和远程的依赖关系。结果表明使用SED 机制可以让LSTM 和GRU 神经网络的预测误差指标进一步下降。
实验结果表明,在相同的预测条件下,CEEMDAN-RF-SED-LSTM 模型在电池RUL 预测上表现最为优良,预测误差最低,该模型为现有电池RUL预测研究提供了参考。
猜你喜欢
物联网技术(2020年12期)2021-01-27
读者·校园版(2020年19期)2020-09-16
当代陕西(2019年19期)2019-11-23
智族GQ(2019年9期)2019-10-28
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
英美文学研究论丛(2018年1期)2018-08-16
汽车零部件(2017年4期)2017-07-12
教学月刊·中学版(教学参考)(2016年5期)2016-06-14
