
基于GMM与LSTM耦合模型的船舶航迹预测算法
2023-01-03 07:02赵煜尤再进吴丽淑李婉莹
上海海事大学学报 2022年4期
赵煜, 尤再进, 吴丽淑, 李婉莹
(大连海事大学交通运输工程学院, 辽宁 大连 116026)
0 引 言
随着海上交通运输的持续稳定发展,船舶的数量、尺度、性能得到不断提升,但与此同时,海上交通安全风险也在加剧,因此在海上交通密集、复杂水域进行精确、高效的交通事故预警尤为重要。另外,在海事搜救、海关缉私活动中,为保证搜救和缉私的顺利进行,需要基于已知的目标船历史位置信息对其航迹进行预测,以此推断其未来一段时间的位置信息[1]。因此,船舶航迹预测在减少海上交通密集水域船舶碰撞风险以及辅助进行海事搜救、海关缉私等方面均有重要的经济及科学意义。
近年来,国内外学者在船舶航迹预测方面做了大量的研究工作。胡玉可等[2]设计了一种基于对称分段路径距离的数据预处理方法,构建基于门控循环单元的循环神经网络(recurrent neural network, RNN)模型对船舶航迹进行预测,侧重于预测环节,数据处理部分的研究工作较少。NGUYEN等[3]将航行海域划分为空间网格,将船舶自动识别系统(automatic identification system, AIS)信息转化为序列到序列的形式,提出一种序列到序列的长短期记忆网络(long short-term memory network, LSTM)预测模型,实现了船舶航迹的实时预测以及目标港和到达时间的预测,但预测精度有待进一步提升。甄荣等[4]根据AIS信息和反向传播神经网络(back propagation neural network, BPNN)对船舶的位置、航向和航速进行预测,取得了较好的效果,但直接使用原始AIS数据进行预测,导致预测结果受原始数据影响较大,算法的通用性和鲁棒性都有待提高。MURRAY等[5]提出一种新的双线性自编码器方法来预测船舶轨迹,先通过高斯混合模型(Gaussian mixture model, GMM)对数据进行聚类,然后利用双线性自编码器方法对分类后的数据进行轨迹预测,取得了较好的预测结果,但耗时较长。刘姗姗等[6]和王研婷[7]提出卷积神经网络(convolutional neural networks, CNN)与LSTM相结合的船舶航迹预测方法,取得了较好效果,然而这两篇文献的实证部分都仅采用一艘船进行研究,结果存在偶然性,同时模型都缺少对航迹提取部分的研究。谢新连等[8]提出一种基于极限学习机(extreme learning machine, ELM)的船舶航行行为预测模型,其预测精度比传统的BPNN有了较大提升,但该文献实证部分仅选取琼州海峡水域进行研究,所提的预测模型在其他水域的适用性还有待验证。刘娇等[9]利用小波阈值去噪法处理训练数据,并提出一种差分进化与支持向量机(support vector machine, SVM)相结合的预测模型对船舶航迹进行预测,但难以实现实时预测。
国内外对船舶航迹预测的研究普遍存在航迹提取部分研究不足的情况,若使用同一艘船的历史航迹数据对该船的未来航迹进行预测,则这种预测对有固定航线的班轮较为有效,而对航线相对不固定的船舶就难以精准,还需要借助航线上其他船舶的历史航迹数据。船舶航迹预测的难点之一就是如何在海量的航迹数据中提取出符合要求的数据。本文针对这一关键问题,构建一种基于GMM与LSTM耦合模型的船舶航迹预测算法,这种算法需提前构建航迹数据库,再利用高斯混合聚类等数据处理方法从数据库中提取用于辅助预测的历史航迹数据,最后将提取出的数据输入LSTM预测模型完成航迹预测。
1 研究方法
本文研究基于大量历史航迹数据,通过数据挖掘的方法对目标船航迹进行预测。研究内容主要由数据库构建、航迹提取、航迹预测等3个部分构成。数据库构建包括数据预处理、航迹分割和航迹插值:数据预处理可以清除异常数据、噪声数据;航迹分割和航迹插值可以将航迹数据转化为等时间间隔的数据,实现航迹数据库的有效构建。航迹提取是从数据库中提取出用于神经网络训练的训练集数据,具体分为航迹初步提取和航迹聚类两部分。航迹聚类对初步提取出的航迹进行分类,并筛选出与预测航迹相似度最高的一类航迹;有效的航迹聚类是获取高质量训练集的核心。在航迹预测阶段,构建LSTM预测模型,将训练集和测试集数据输入模型进行运算,完成船舶未来航迹预测。通过实验验证这种方法的精确性和实用性。
2 数据库构建
定义船舶航迹数据库为
Di={H1,H2,…,Hn},i=1,2,3,4,5,6
(1)
式中:Di为船型为i的船舶航迹数据库,i=1,2,3,4,5,6分别对应货船、渔船、客船、游船、油船、拖船;Hj(j=1,2,…,n)为第j条航迹。
Hj={h1,h2,…,hm}
(2)
式中,hk(k=1,2,…,m)为第k个航迹点的相关数据,包括船型、船舶水上移动通信业务标识码(MMSI)、船舶在tk时刻的位置pk、航速vk和航向ck。
若航迹Hj与Hl具有相同的航迹点数m, 则这2条航迹之间对应点距离的集合为
Tjl={d1,d2,…,dm}
(3)
式中:dk为航迹Hj中第k个航迹点与航迹Hl中第k个航迹点之间的欧氏距离。
航迹长度采用欧氏距离度量,航迹Hj的长度为
(4)
2.1 数据预处理
从网址www.marinecadastre.gov/ais选取2019—2020年美国沿岸AIS数据作为实验数据,该数据包含大量信息,本文仅使用其中的7类数据:船型、MMSI、数据记录时间、经度、纬度、航速、航向。数据预处理如下:从总数据中选取特定经纬度范围内的数据,清除其中异常和不需要的数据,如MMSI不是9位、无效航向(不在区间[0,360°)内的航向数据)、船型缺失、航速为0的数据;将数据记录时间重置,以2019年1月1日0时0分0秒为0 s,其后的时间转化为相应秒数,便于后续处理。
2.2 航迹分割
按照船型不同,将预处理后的数据分为6类,分别对应前文提到的6类船型。为进行航迹插值,同时保证所提取的航迹点数据都来自同一条航迹,需要根据式(5)对船舶航迹进行分割点标注:
Ik≠Ik+1或|tk+1-tk|>1 200 s
(5)
式中:Ik和tk分别为第k个航迹点的MMSI和数据记录时间。满足式(5)的航迹点即为分割点,最终得到分割点集合G。
2.3 航迹插值
若原始数据不是基于等时间步长记录的,则航速相同的船在两个记录点间的航行距离一般是不同的,如不进行插值将其处理成等时间步长数据,就会极大地增加航迹提取和预测的难度,降低预测精度。对于部分原始数据缺失的情况,需要通过航迹插值进行修复。因此,经过航迹分割后的数据需要以航迹段为单位进行航迹插值,从而提高数据的质量和连续性。本文选择常用的分段三次Hermite插值法,以60 s的时间步长对原航迹数据进行插值[10],经过插值后的数据需要再通过式(5)进行航迹分割,更新集合G。
3 基于GMM的航迹提取算法
3.1 航迹初步提取
航迹初步提取是航迹提取算法的第一阶段,通过限定距离,提取出测试航迹段一定范围内的航迹数据。测试集可以分为已知航迹和待测航迹,已知航迹是航迹初步提取的依据。确定合理的距离阈值是航迹初步提取的重点:阈值过大,会导致大量无关数据被提取,增加聚类难度和程序运行时间,降低预测精度;阈值过小,会剔除大量可以用于预测的航迹数据,致使数据量较少甚至找不到可用的航迹数据。
合理的距离阈值需综合考虑航速、预测步长等因素,本文将已知航迹的长度Lq及其包含的航迹点数m纳入计算。在大量实验的基础上,得到距离阈值ε的估算公式:
ε=6Lq/m
(6)
再利用已知航迹上最后一个航迹点的数据ce、ve和pe,在数据库中寻找同时满足以下要求的航迹点:
|ck-ce|<30°,|vk-ve|<5 kn
(7)
d(pk,pe)<ε
(8)
假定预测未来t时间内的船舶航迹,记录满足式(7)和(8)的所有航迹点,选取每个航迹点前t时间内所有的航迹点数据,构成航迹集合Df。Df中每条航迹上的航迹点都需要根据式(8)进行检验,删除不满足式(8)的航迹点所属的航迹,最终得到经初步提取后的航迹集合Df。
3.2 航迹聚类
航迹初步提取只是通过限定距离提取出一定范围内的航迹数据,这部分数据中的航速、航向等特征仍存在较大差异。为提高预测精度,需将航迹集合通过航迹聚类进一步提取后再用于航迹预测。
本文使用GMM进行航迹聚类,GMM用高斯概率密度函数来量化事物,任意形状的概率分布都可以用多个高斯分布函数来近似,其分布函数如下:
(9)

在进行航迹聚类时,每组航迹数据集都可以通过GMM被划分为r个子集,故r值在很大程度上影响着聚类效果,本文采用贝叶斯信息准则(Bayesian information criterion,BIC)来确定最佳r值。BIC通过衡量模型拟合的优良性来确定模型最佳参数,是一种较好的模型参数数量确定准则,BIC值的计算式如下:
NlnO-2lnR
(10)
式中:N为模型参数的数量;O为样本数量;R为似然函数。从一组可供选择的模型中选择最佳模型时,通常选择似然程度高、模型复杂度较低的模型,即BIC值最小的模型[14]。
在进行航迹聚类时,选用弗雷歇距离度量不同航迹之间的相似度。弗雷歇距离用来描述路径空间相似度,可以应用于平面曲线之间的相似度估量。同方向不能回溯的离散点组间,其对应点之间最短距离的最大值就是离散点组间的弗雷歇距离。选用弗雷歇距离计算相似度时,相似度越高,弗雷歇距离越小。对于Hj、Hl两条航迹,弗雷歇距离可以根据式(3)表示成以下形式:
F(j,l)=maxTjl
(11)
3.3 聚类算法流程
聚类算法分两步进行,其具体步骤如下:
第一步,航行趋势的聚类。在航迹初步提取阶段,无法去除与对应点间距离的平均值较小、航行趋势差异较大的航迹。经实验检验,应用航行趋势差异大的航迹进行训练会导致预测航迹出现较大误差。为提高预测精度,聚类算法的第一步要提取出与测试集中航行趋势相似度最高的一类航迹数据,具体步骤如下:
①将经航迹初步提取得出的每条航迹都通过最小二乘法进行航迹的二阶拟合。②将拟合的结果矩阵作为聚类对象,设置最大聚类簇数为10,应用GMM进行聚类,根据式(10)计算每次聚类的BIC值。③选择BIC值最小的簇数b1作为最佳簇数,记录最佳簇数下聚类时各航迹所属的类,得到类别标定矩阵。④根据类别标定矩阵中的对应关系将Df分成b1个航迹集合。⑤将每个航迹集合中所有航迹通过对应点加权平均合并为一条航迹,得到b1条航迹。⑥通过式(11)计算每条航迹与测试集中已知航迹的相似度。⑦选择相似度最高的航迹对应的航迹集合构建新的航迹数据集Dz。
第二步,航迹距离的聚类。在航迹趋势聚类后,得到与测试航迹航行趋势最相近的一类航迹集合,但这类航迹在单位时间步长内的航行距离差异较大,致使预测航迹与真实航迹相比过长或过短。为降低这类误差,提高预测精度,需要对航迹距离进行聚类,具体步骤如下:
①根据式(4)计算Dz中每条航迹的长度。②以航迹长度为聚类对象,设置最大聚类簇数为10,应用GMM进行聚类,根据式(10)计算每次聚类的BIC值。③选择BIC值最小的簇数b2作为最佳簇数,记录最佳簇数下聚类时各航迹所属的类,得到类别标定矩阵。④根据类别标定矩阵中的对应关系将Dz分成b2个航迹集合。⑤计算每个航迹集合中所有航迹长度的平均值,得到b2个航迹长度平均值。⑥计算每个航迹长度平均值与已知航迹的长度的差。⑦选择差值绝对值最小的航迹长度平均值对应的航迹集合构建新的数据集De,De即为通过航迹聚类得到的航迹数据集。
4 LSTM预测模型
选用LSTM用于航迹预测,LSTM是一种时间递归神经网络,在时间序列预测上有着较好的表现[15]。与其他神经网络预测模型相比,LSTM增加了3个“门”结构:遗忘门、输入门和输出门。通过“门”结构,LSTM可以保存、丢弃记忆单元中的原信息以及保存新信息,使得LSTM在处理和预测延迟较长的时序数据上更具优势,且克服了梯度消失和梯度爆炸的问题。LSTM训练采用基于时间的反向传播(back propagation through time, BPTT)算法,其基本原理与经典的BP算法相似,包含正向和反向传播的过程[16]。
在预测时,先将训练集De输入预测模型,完成预测模型的训练,再将已知航迹输入训练好的模型中,得到预测航迹。预测模型输入数据为二维数据,即历史航迹的经度和纬度数据;输出数据也为二维数据,即预测航迹的经度和纬度数据。
对输入数据进行归一化处理:
(12)
式中:x为原始训练数据;maxX和minX分别为原始训练数据中的最大值和最小值。通过归一化处理,能消除数据量纲和取值范围的影响,同时保留原始数据中存在的关系[4]。将处理后的数据输入以LSTM层为主的神经网络预测模型,其具体结构见图1。
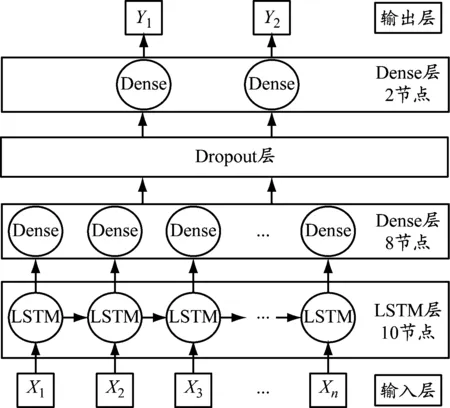
图1 神经网络预测模型结构
该神经网络包括1个输入层、1个输出层和4个隐藏层,隐藏层由LSTM层、Dropout层和Dense层(全连接层)构成。根据实验将LSTM层和第一个Dense层的节点数分别设置为10和8;利用第二个Dense层进行维度转换,导出最终的二维数据,其节点数为2;为防止过拟合出现,在第一个Dense层后设置一个Dropout层。神经网络的训练批量为n/30,n为De包含的数据数量;模型使用Adam优化器,学习率为0.03,Dropout层参数为0.1,最大迭代次数为200。
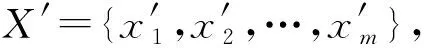
5 实证分析
为验证提出的船舶航迹预测算法在航迹数据提取和预测上的有效性,采用大量随机对比实验进行验证。从网址www.marinecadastre.gov/ais获取AIS数据,限定经度(西经)范围为[-76.5°, -71.5°],纬度(北纬)范围为[36.0°, 41.5°]。采集2019年全年数据构建数据库,采集2020年6月的数据构建测试集。表1记录了数据处理前后的航迹点数量。实验设备使用Intel(R) Core(TM) i5-1035G1的处理器,内存16.0 GB,显卡mx350。

表1 数据处理前后的航迹点数量
5.1 典型航迹预测
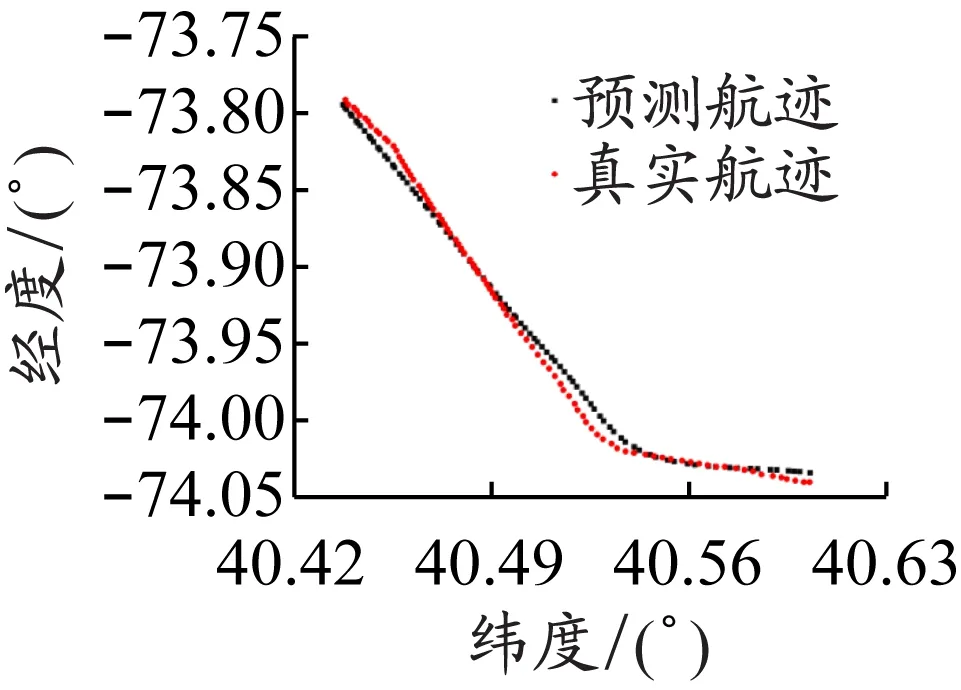
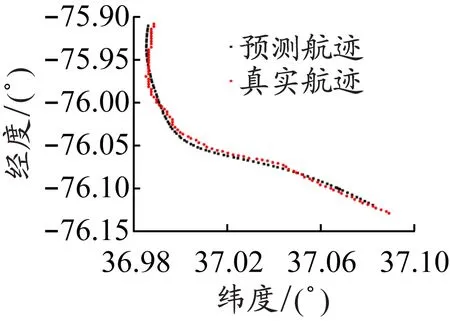
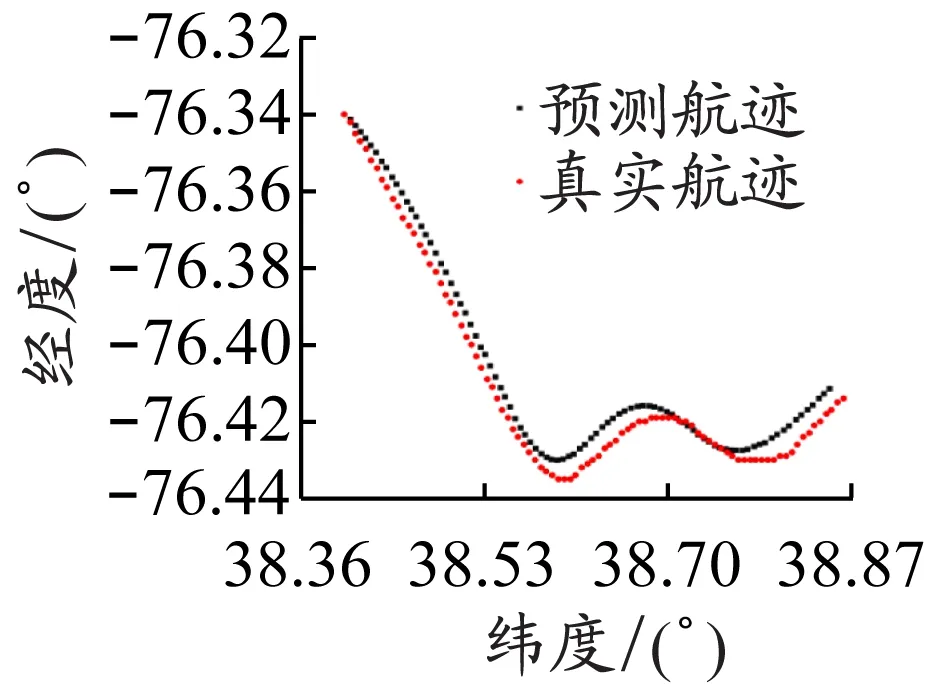
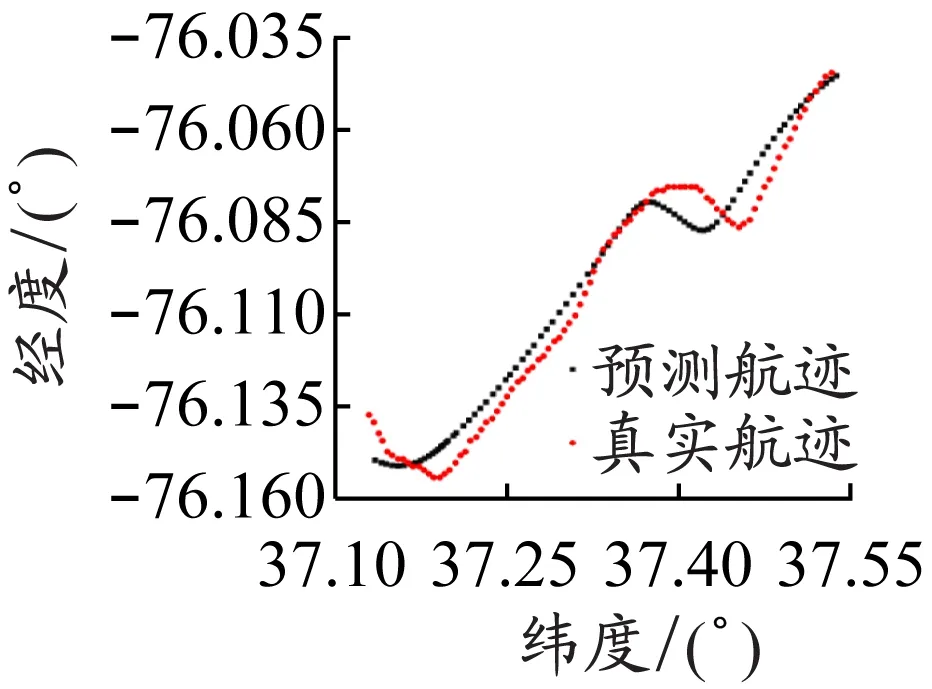
为了更直观地展示模型的预测效果,以稳定航速直道航迹、稳定航速小角度转向航迹、变化航速小角度转向航迹、稳定航速大角度转向航迹、稳定航速复杂航迹、变化航速复杂航迹这6种典型航迹为例,对预测效果进行展示和评价。图2是这6种典型航迹真实值和预测值点状图。
从图2可以看出,对直道航迹的预测效果最好,对小角度转向航迹的预测效果次之,对大角度转向航迹的预测效果稍差,对复杂航迹的预测结果相对较差,同时对稳定航速航迹的预测结果要比对变化航速航迹的预测结果好。由于这6种典型航迹各具特点,所以图2中各子图坐标尺度不一,这可能对图片的直观性有一定的影响。从稳定航速直道航迹到变化航速复杂航迹这6种典型航迹预测结果的MSE如下:经度预测结果的MSE分别为1.72×10-6、5.82×10-6、1.03×10-5、5.94×10-6、4.89×10-5、4.49×10-5;纬度预测结果的MSE分别为5.25×10-6、2.67×10-5、2.82×10-5、4.95×10-5、1.55×10-5、4.36×10-5;经度和纬度预测结果的MSE均值分别为3.49×10-6、1.63×10-5、1.93×10-5、2.77×10-5、3.22×10-5、4.42×10-5。MSE结果与点状图的观测相一致:随着航速变化和航迹复杂度增大,预测结果逐渐变差。接下来的实证部分由于预测航迹较多,不再用图展示预测结果,仅给出预测结果的MSE。
5.2 聚类效果分析
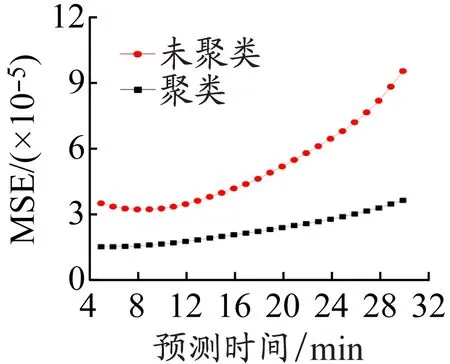
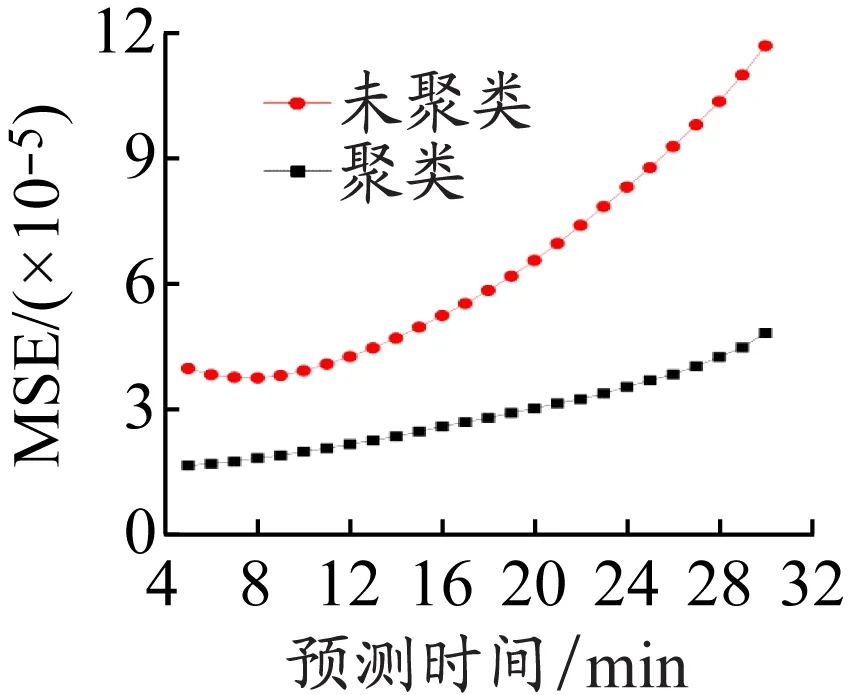
为验证聚类算法的有效性,随机从测试集中提取各类型船舶航迹数据共计100组作为测试集,然后从数据库中得到100组对应的初步提取的航迹集合Df,再将Df中的航迹进行航迹聚类后得到相应航迹集合De。分别将Df和De作为训练集,通过LSTM预测模型进行预测,分别得到未经过航迹聚类和经过航迹聚类情况下的预测结果。对这2种情况下的预测结果的MSE平均值进行分析,结果见图3。
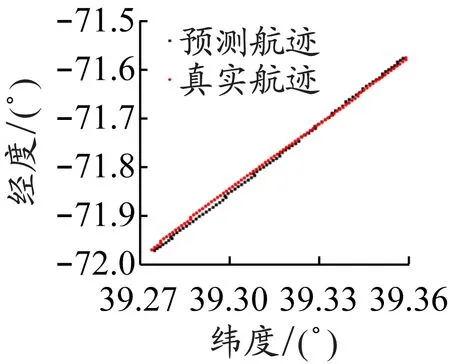
a)稳定航速直道航迹
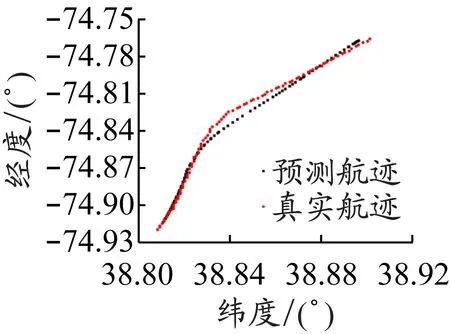
b)稳定航速小角度转向航迹
c)变化航速小角度转向航迹
d)稳定航速大角度转向航迹
e)稳定航速复杂航迹
f)变化航速复杂航迹
a)经度预测误差
b)纬度预测误差
从图3可以看出:各个预测时间下,经度和纬度预测结果的MSE在经过航迹聚类后都有明显下降,证明所使用的聚类算法可以根据航迹特征有效提取航迹数据集,提高预测精度;MSE平均值随预测时间的增加而不断上升,经航迹聚类后算法在预测到30 min时的经度和纬度MSE平均值分别为3.65×10-5和4.85×10-5。
5.3 不同预测模型的预测效果对比
为验证提出的LSTM预测模型的有效性,选取BPNN、SVM、ELM这3种常用的预测模型进行对比实验。BPNN的输入和输出节点数都为2,隐藏层节点数为3,学习率为0.02,最大迭代次数为1 000;SVM的核函数为“linear”,核尺度参数为“auto”,其他参数都采用MATLAB深度学习工具箱默认值;ELM的隐藏层神经元数量为9,激活函数为“sig”,其他参数都采用工具箱默认值。
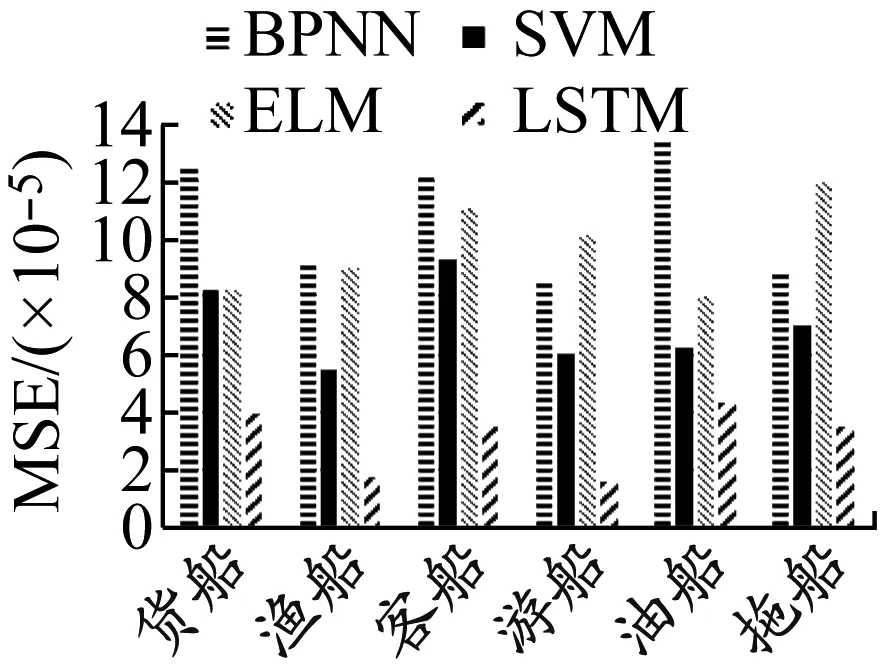
对比实验按不同船型进行,从每种船型航迹数据库中随机选取100组航迹数据进行预测,预测时间统一为30 min,取预测结果MSE的平均值进行对比,结果见图4。从图4可以看出,无论是在哪种船型数据集中进行的实验,LSTM预测的经度和纬度MSE远低于其他预测模型,充分验证了本文方法比传统的BPNN、SVM、ELM有着更高的预测精度。
a)经度预测误差

b)纬度预测误差
5.4 LSTM预测结果分析
从图4 LSTM预测误差可以看出,6类船舶经度和纬度预测结果的MSE均处于10-5数量级,只有油船经度预测结果的MSE和客船纬度预测结果的MSE值略大,超过了4×10-5。航迹预测过程中可能由于聚类错误等情况,出现MSE过大的异常点。考虑到平均值在异常点影响下可能无法反映真实情况,对不同类型船舶航迹预测结果的MSE进行进一步分析,其箱线图见图5。

a)经度预测误差

b)纬度预测误差
从图5可以看出:除客船外的其他5类船舶大部分(75%以上)预测结果的MSE都在5×10-5以下;客船经度预测结果MSE的非异常最大值为1.05×10-4,最小值为3.70×10-7,箱体数据表明75%的预测结果MSE都不大于5.09×10-5;客船纬度预测结果MSE的非异常最大值为1.25×10-4,最小值为1.70×10-7,箱体数据表明75%的预测结果MSE都不大于5.82×10-5。去除掉异常点后,客船大部分预测结果MSE也都在5×10-5以下,因此所提出的模型可以对包括客船在内的6类船舶在未来30 min内的航迹进行有效预测,箱线图的结果进一步验证了所提出算法的有效性。
5.5 LSTM预测算法耗时分析
在航迹预测领域,预测算法处理时间的快慢是衡量其性能的重要指标,如果耗时过长,其实用价值就会大大降低。为验证所提出算法的实用性,按船型分别对6类船舶进行100组随机实验,记录每次实验的各部分运行时间并计算平均值,结果见表2。
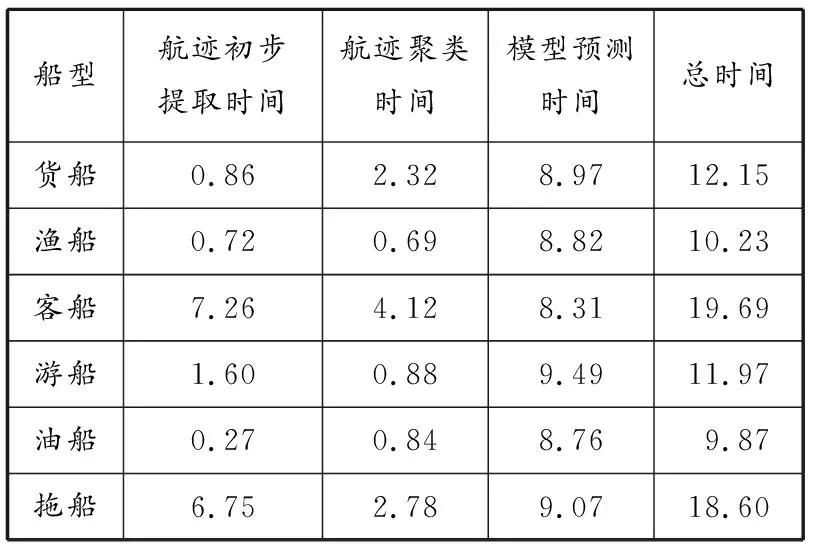
表2 LSTM预测算法耗时 s
从表2可以看出,不同类型船舶航迹的平均预测时间都在20 s以内,其中:油船的航迹预测总时间最短,只有9.87 s;客船和拖船的航迹预测总时间较长,分别达到了19.69 s和18.60 s。由于客船大多有固定的航线,每条航线上航次量大,所以客船的航迹预测运算量大;拖船的航迹数据量是所有船舶中最多的:因此对这两类船舶的航迹预测耗时较长。虽然各类船舶的航迹预测总耗时不同,但总时间平均值都小于20 s,同时根据记录的数据显示,600组数据中只有关于拖船的3组数据航迹预测总时间超过了60 s,最大为75.62 s,考虑到模型可预测船舶在未来30 min内的航迹,模型总运行时间在1 min内是可以接受的。
6 结 论
本文综合考虑航迹提取和模型预测,提出一种基于高斯混合模型(GMM)与长短期记忆网络(LSTM)耦合模型的船舶航迹预测算法。将历史数据按不同船型构建航迹数据库,通过限定距离实现航迹初步提取,采用基于GMM的聚类算法将初步提取出的数据进一步提取,最后通过LSTM预测模型完成航迹预测。大量的随机对比实验证明,本文所提出的基于GMM的航迹提取算法可以准确高效地提取航迹数据,LSTM预测模型在航迹预测上的预测精度远高于一般的BPNN、SVM和ELM预测模型。本文所提出的航迹预测算法可以有效地对各类船舶在未来30 min内的航迹进行预测,整个预测过程一般用时短于1 min,该方法在实现任意船舶中短期航迹实时预测上具有重要的实际价值。
本文基于船型建立数据库进行预测主要是为了在保证预测精度的前提下提高预测速度,但未对不同类型船舶的航迹特征进行深入分析。未来将在此方面展开深入研究,根据不同类型船舶的航迹内在特征为各类船舶设计专门的航迹预测算法,进一步提高预测精度。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
水上消防(2022年1期)2022-06-16
海洋开发与管理(2020年2期)2020-09-10
现代计算机(2018年27期)2018-10-25
舰船科学技术(2018年7期)2018-07-25
北京航空航天大学学报(2017年7期)2017-11-24
雷达学报(2017年6期)2017-03-26
北京航空航天大学学报(2016年6期)2016-11-16
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
