
大数据分析技术在金融监管平台中的作用
2022-12-28 11:20唐静
中国新技术新产品 2022年19期
唐 静
(湖南环境生物职业技术学院,湖南 衡阳 421005)
0 引言
在金融科技不断进步和发展的形势下,许多新的金融形态应运而生[1]。与此同时,各种跨境、跨行业的金融产品层出不穷,但是在其发展过程中也产生了各种金融风险。如何正确应对金融科技带来的新的监管挑战,也逐渐引起了世界各国金融监管机构的关注。鉴于我国单一化的金融业监管、金融科技自身的特点以及现行法律法规的滞后性,现行的监管模式并不能完全遏制金融犯罪。在现实社会中,第三方支付机构的监管机制不完善,“洗黑钱”“套现”等风险依然存在。在目前的金融科技的监管中,监督主体虽然明确,但在实际的监督活动中,“真空监督”的现象也时有发生。在金融科技不断进步之下,传统金融正逐渐向无国界金融发展。所以,如何保证我国金融科技创新能力继续走在世界前列,并根据金融科技自身特点构建一个适时、有效的监管模式,是目前我国金融科技发展的最大瓶颈。各国应当加强金融科技监管合作,用科技监管科技,进而解决金融科技监管的滞后问题。
1 大数据分析技术在金融监管平台的应用研究
1.1 大数据分析研究意义
科技不仅改变了人们从购物到社交的方式,也重塑了金融服务业。在过去的几年里,一些创新型金融公司竞相出现,利用互联网技术帮助人们找到更多的投资机会、方便了人们的支付手段,甚至让小额贷款也变得容易了很多。新金融技术的发展不得不归因于个人和企业的大数据爆发,人工智能、计算能力、密码学以及互联网的普及[2]。这些技术之间有强大的互补性,因此也带来了许多新的应用,涉及支付、融资、资产管理、保险和咨询等服务。随着新大数据分析的发展,监管模式的推陈出新,对中国的金融行业监管及风险控制具有现实意义。
1.2 Python语言的使用
作为一种高级计算机程序设计语言,Python的优点是可以完成以下工作任务,见表1。
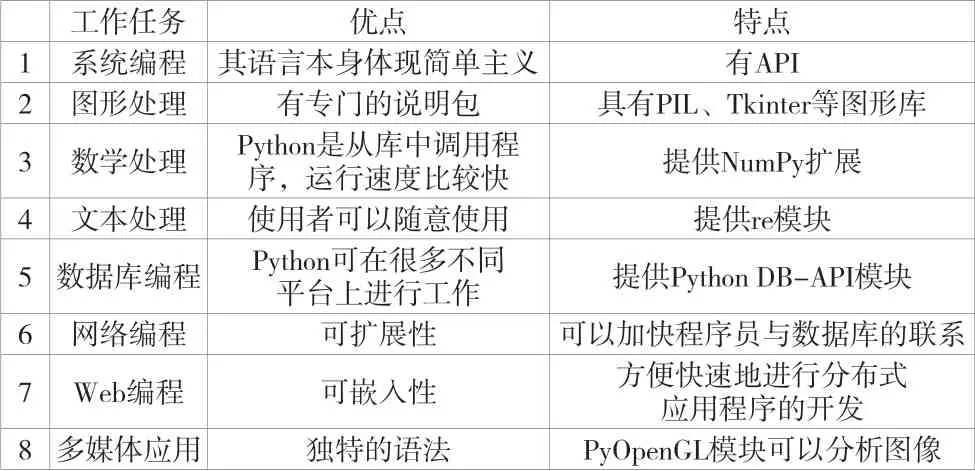
表1 Python的工作任务以及优点
1.3 金融监管平台大数据处理算法
1.3.1 随机森林算法
随机森林是包括多棵决策树,可以用来执行回归和分类任务的机器学习算法[3]。其输出类别是由多棵决策树的输出类别的众数决定的。
1.3.2 随机森林模型构建原理
用N表示样本个数[4],M表示特征个数。从容量为N的原样本集中有放回地进行重复抽样,每次抽取的样本容量也都为N,抽样N次,形成N个训练集。这样每次抽样时原样本集中数据未被抽中的概率如公式(1)所示。

当N很大时,1/e为概率值,趋于0.368,如公式(2)所示。

式中:1/e为固定值0.368,e为无限不循环小数。
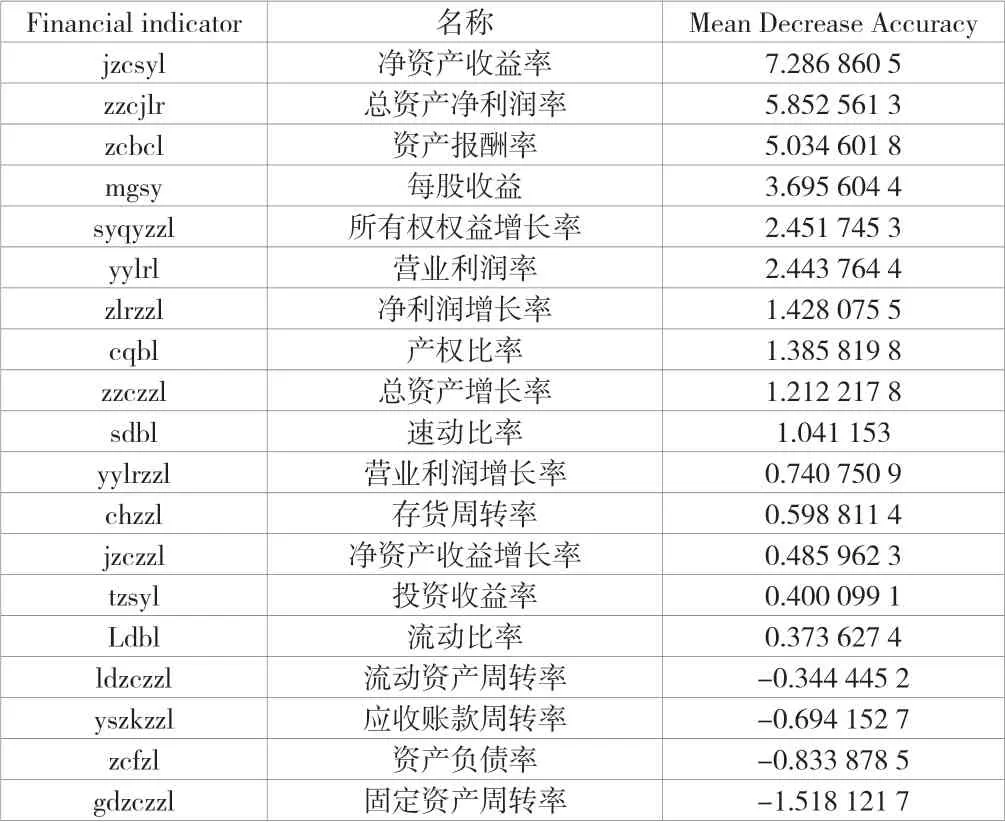
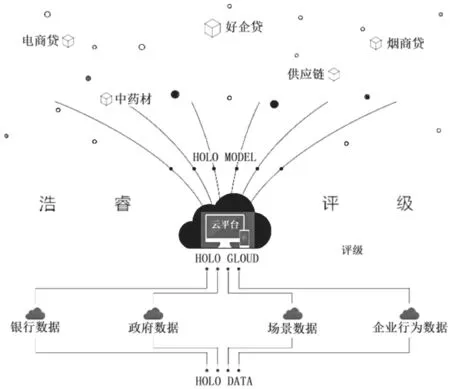
这表示每次抽样时,原样本集中的数据有大概37%的样本不会被抽中,这些数据被称为袋外数据。未被抽中的数据集可直接作为测试集,用于测试模型的预测精度。然后按一定比例确定特征数(通常取总特征数的平方根),输入k(k 训练完成形成N棵决策树,随机森林模型最后输出的分类结果由这N棵决策树通过自己的分类结果进行简单投票而决定。决策树生成流程如图1所示。 图1 随机森林中单个决策树训练过程 1.3.3 随机森林收敛性的分析 随机森林在数学上的定义可以表达为例如现有由h1(x),h2(x),…,hk(x)构成的随机森林。边际函数如公式(4)所示。 式中:mg(X,Y)为边际函数;avk(I(hk(X)=j))为正确分类下得到的票数;为不正确分类的情况下得到的票数。 边际函数表示的意思是,在正确分类的情况下得到的票数比在不正确分类情况下得到的票数多的程度。显然,该函数越大,说明原分类器分类效果越可靠。泛化误差PE*如公式(5)所示。 式中:X、Y为概率定义空间。 随机森林边缘函数如公式(6)所示。 式中:P(hk(X)=Y)为正确判断的概率;为错误判断的概率最大值。 每棵决策树生成随机森林时,总是有一个初始数据集和没有被抽取的数据集Ok(x)。Q(x,yi)即如公式(7)所示。 式中:Q(x,yi)为x在Ok(x)中yj的比例,为正确分类的概率估计。由此可对随机森林强度和相关性进行分析。 随机森林强度如公式(8)所示。 式中:E为数学期望。 将公式(6)代入公式(7),所得如公式(9)所示。 式中:S为随机森林强度;n为数量;Q(xi,y)为xi在Ok(x)中y的比例;(xi,j)为Q(xi,y)中的最大值。随机森林相关度如公式(10)所示。 式中:pu为I(ku(xi)=y)的OBB估计;为I(ku(xi)=的OBB估计。 pu和的 计算如公式(11)、公式(12)所示。 式中:I为指示函数;ku(xi)=y为观测的真实结果;ku(xi)为观测的预测结果。 将公式(10)和公式(11)带入公式(9),所得如公式(13)所示。 随机森林的性能体现在其收敛程度、强度和相关程度[5]。收敛性在于决策树的泛化误差都收敛,出差会有上限,这说明随机森林对未知事物具有良好的适应性,不会造成很大的误差,也不易造成过拟合。 该文实证过程中采取的数据均来自国泰安CSMAR数据库。行业的划分以证监会的分类为标准,选取了医药制造业中的221家公司。采用其2020—2022年3年的22个财务指标数据为研究对象。利用Python语言建立随机森林模型。 1.4.1 模型构建及操作过程 导入数据:将数据集导入Rstudio; 在Rstudio中观察导入的数据是否正常:View(rdata); 将Rstudio的储存路径更改为D盘下的r_working文件:setwd(“D:\r_working”)。 1.4.2 金融数据特征变量的分析 Mean Decrease Accuracy代表的是基于特征变量对准确率影响程度的大、小,数值越大,说明重要性越大。并基于此进行特征变量排序,见表2。 表2 数据特征标量的重要性大、小 1.4.3 数据随机算法准确性分析 在rdata的数据范围内,通过重复取样,将样本分为2种类型数据集,占比分别为70%和30%,即sample_set<-sample(2,nrow(rdata),replace=T,prob=c(0.7,0.3))。 将第一种类型数据集命名为训练集train_set,即train_set<-rdata[sample_set==1,]。 将第二种类型数据集命名为测试集test_set,即test_set<-rdata[sample_set==2,]。 基于2019—2021年的医药制造业财务指标数据,建立的随机森林模型的准确率分别为100%、96.2%和97.4%,如图2所示,准确率都比较高,因此证明了该随机森林模型对与财务质量和状况的预测有较大的可行性。 图2 数据随机算法准确性分析图 该系统爬取主要针对网站信息国泰安CSMAR数据库进行数据爬取。为金融监管当局提供“非法集资”和“企业异常”风险敏感预警监测,监测数据和风险预警平台。大型部门运用大数据技术,并基于多维全面量化数据。通过信息跟踪、事件惯性突破建立一个特殊的风险识别模型。协助商业运营实体和政府监管机构进行筛选、预警重大财务、财务和法律风险。自2017年起,逐步升级大数据风险监测预警平台,优化风险预警模型,将监管业务从金融办延伸至财政厅、海关、住建部等政府机构和金融机构,打造完整的工业服务链。 在数据爬取时,需要导入Requests库和BeautifulSoup库函数。使用Requests抓取国泰安CSMAR数据库,把要爬取的整个页面抓取下来。使用BeautifulSoup中的find()和find_all()抓取需要的标签内容。 如图3所示,大数据模块决策树利用复杂网络关系算法构建多维企业关联图,通过关系筛选、关联操作和指标定位,快速、准确地挖掘企业风险线索,能够有效地反映企业的真实行为和对相关业务决策的支持。该程序集数据、平台和应用于一体。主要使用行业领先的大数据处理、分析和建模技术,真正恢复用户的信用等级、行为特征和风险配置,并可自动对客户进行风险评估,不需要银行进行烦琐的预贷尽职调查和贷后监控、预警,真正帮助银行进行客户探索、信贷审批、利率定价、信贷控制、监控和预警,并形成一个用于贷款、贷款和贷后流程的智能风控计划。 图3 大数据模块决策树风险分析图 该文共选取了22个财务指标,利用医药制造业的财务数据,运用语言中的randomForest软件包建立了随机森林模型。根据建模后得到的结果分析得知,无论是对训练集的分类还是对测试集的预测,构建得到的随机森林模型都能很好地发挥作用,预测准确率都在96%以上。这说明可以采用该方法对公司的财务风险进行预测。大数据模块决策树风险结果有利于公司对其进行数理统计,进而规避风险。




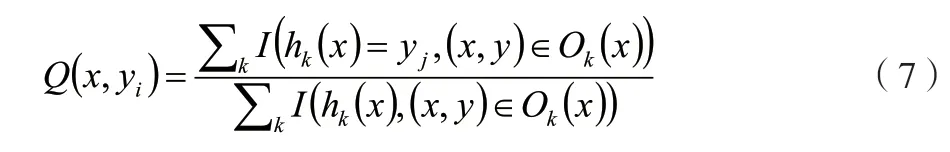


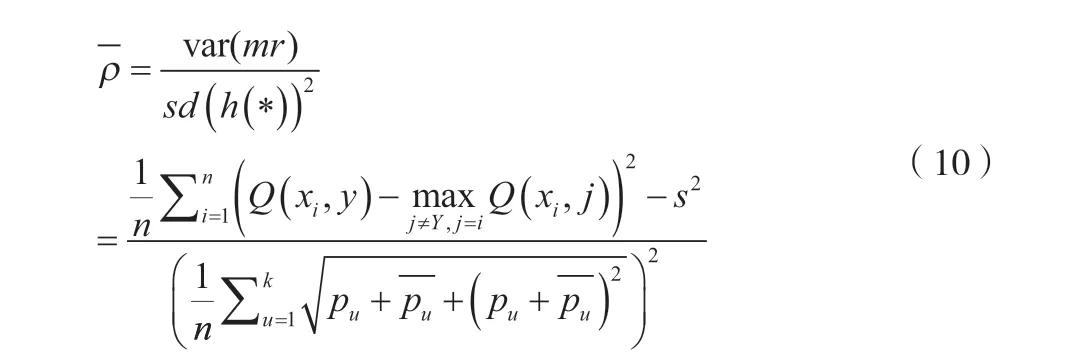


1.4 金融监管平台大数据处理过程

2 大数据分析技术在金融监管平台应用分析
2.1 金融监管平台大数据处理分析
2.2 大数据模块决策树风险的分析
3 结语
猜你喜欢
新高考·高二数学(2022年3期)2022-04-29
新高考·高二数学(2022年3期)2022-04-29
中学生数理化(高中版.高二数学)(2020年11期)2020-12-14
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
作文大王·笑话大王(2017年1期)2017-02-21
作文大王·笑话大王(2016年10期)2016-10-18
作文大王·笑话大王(2016年7期)2016-08-08
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
作文大王·笑话大王(2016年2期)2016-02-24
