
采用GPU加速的无人机光通信系统对准技术
2022-12-28 04:49徐声振田明倪小龙于信白素平
长春理工大学学报(自然科学版) 2022年6期
徐声振,田明,倪小龙,于信,白素平
(长春理工大学 光电工程学院,长春 130022)
目前轻小型无人机平台(重量不超过25公斤、飞行高度不超过150米)在社会民生中的实时监测和评估方面具备特别优势,且具有广阔的应用前景。而随着航空遥感技术的发展,遥感数据的传输和存储已成为亟待解决的严重问题,微波通信等传统方法传输速率有限,针对这些问题[1-3],自由空间光通信是一种有效的解决方案。自由空间激光通信系统的关键技术之一就是实现高精度的动态跟踪[4]。目前信标理论定位已经在国内外进行了深入的研究,例如神经网络[5]、小波分析[6],但是计算和实时处理的性能不能满足系统要求。此外,近年来美国、欧洲、日本等国家投入了大量的人力、物力对空间激光通信进行了研究,空间激光通信经过多年探索也取得了突破性进展[7],而我国空间激光通信研究起步较晚[8],且针对轻小型无人机的光通信技术研究较少,因此,开展轻小型无人机的光通信技术研究具有重要的研究意义。如何实现小体积、轻量化、低功耗的无线光通信终端,同样也是轻小型无人机领域面临的重要问题。
本文采用大疆六旋翼轻小型无人机作为光通信平台,基于嵌入式平台设计并制作小型无人机平台光通信载荷。此外,本文在保证信标光斑亚像元细分定位精度条件下,采用图像处理器(Graphic Processing Unit,GPU)并行计算来加速灰度质心算法以实现高速率捕获、瞄准和跟踪,最终实现高稳定性、低误码率的无线光通信。实验证明经过GPU并行加速的光斑定位跟踪方法相比传统方法计算速度更快,设计的轻小型无人机光通信载荷具有体积小、重量轻、能耗低的优点。
1 光通信对准系统
图1为光通信对准跟踪系统的原理图。它主要由地端激光发射系统、图像采集系统、PID控制系统、无人机飞控系统以及嵌入式设备等组成。地端激光发射系统由激光器、三轴电机等构成。图像采集系统由CMOS相机、75 mm变焦镜头等组成。PID控制系统由二轴控制云台、嵌入式设备等构成。无人机飞控系统主要由主控器、GPS-Compass Pro、PMU和LED四个模块构成。
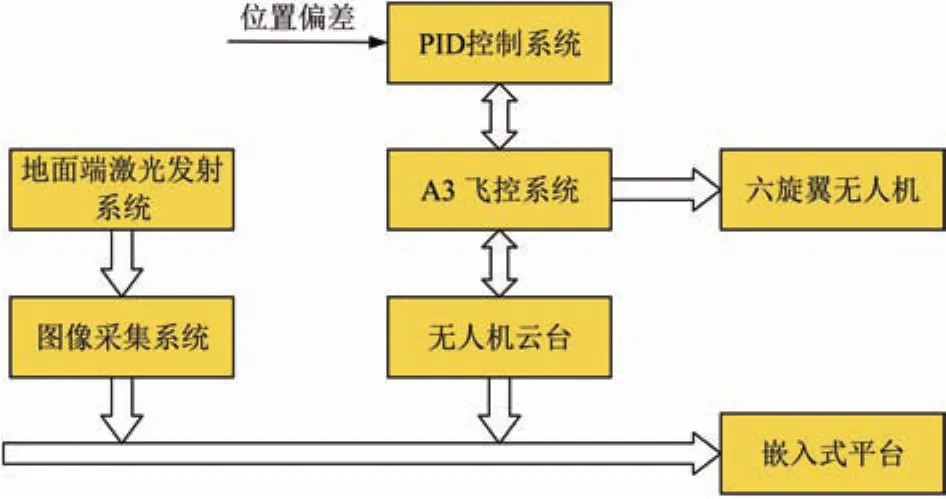
图1 光通信对准系统原理图
实验中由地端激光发射系统的高功率固体激光器产生标准高斯分布的激光光束,并使其出现在工业相机拍摄的视场角范围内;再在嵌入式设备上运行大疆Onboard SDK中编写的主程序,通过图像采集系统调用安装在嵌入式平台中的相机SDK驱动包内动态链接库函数打开相机摄像头;嵌入式设备读取相机图像数据并进行预处理,图形处理器加速质心算法算出光斑质心从而得到位置偏差数据,最后采用PID三环控制云台对准跟踪光斑质心。
2 光通信对准系统关键算法
2.1 灰度质心算法
目前光斑的亚像素质心定位算法主要有:高斯曲面拟合算法,数字相关亚像素算法和灰度重心算法等[9]。灰度重心法也叫密度质心算法,对于亮度不均匀的目标,可按目标光强分布求出光强权重质心坐标作为跟踪点。在计算机中图像是以矩阵的形式呈现出来的,因此对图像质心的计算实质上就是对各种矩阵进行计算。
设一帧灰度图像中有i、j两个方向,i、j方向像素点的数量分别为m、n,像素点(i,j)处的灰度值为f(i,j),则图像质心位置坐标(x0,y0)的表达式为:
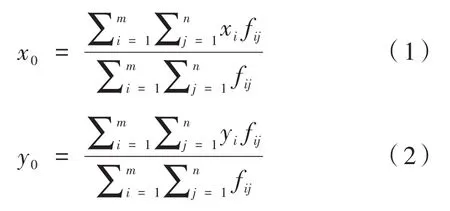
仅使用质心算法不能有效地提高光斑质心定位精度,需先用阈值去除噪声的影响。设置阈值的意义是,将低于阈值的像素看作是噪声,不参加质心计算,高于阈值的像素作为目标,减去阈值后参与质心运算[10]。
对于分辨率大小为m×n的灰度图像,超过阈值T的像素的灰度值直接参与质心运算,小于阈值T的则不参与运算,相应的灰度值表示为:

本文使用这种带有阈值检测的质心跟踪算法,且剔除背景噪声的干扰,实现光斑图像的高精度探测定位[11]。但是,采用传统的中央处理器来计算这种质心算法运行时间较长,无法达到实时性要求。因此采取了图形处理器并行优化质心算法以达到实时计算质心的目的。
2.2 图像预处理
为了进一步提高算法的质心探测误差,还需要采用自适应直方图均衡化(Adaptive Histogram Equalization,AHE)和中值滤波(Median Filter)函数对图像进行预处理。
直方图均衡化是一种最常用的图像增强方法,因为其简单且在几乎所有类型的图像上性能都比较好,它是一种非线性的图像拉伸。直方图均衡化根据输入灰度级的概率分布重新映射图像的灰度级来执行操作[12]。通过使用一个累积分布函数(CDF)映射函数来实现均衡化的目的。对于直方图H(i),它的累积分布H'(i)是:

均衡化后像素的强度值可以通过一个简单的映射过程来获得:
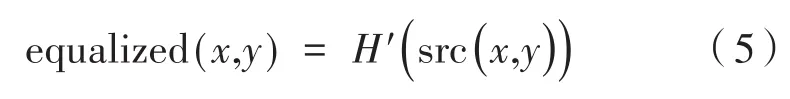
恢复后的累积分布直方图对原始图像的像素进行灰度映射,得到处理后的图像。和普通的直方图均衡化算法不同,AHE算法通过计算图像的局部直方图,然后重新分布亮度来改变图像对比度,从而改进图像的局部对比度[13]。
在图像处理中,图像去噪是一项必不可少的预处理任务,可提高图像质量[14]。中值滤波法是一种非线性平滑技术,可用于处理AHE算法所带来的椒盐噪声。
中值滤波的处理过程如图2所示,实验中选取3×3矩阵窗口作为滤波的卷积模板,即将矩阵中3行3列共9个像素值顺序排列,取中值16替代原像素值3作为当前元素的像素值。
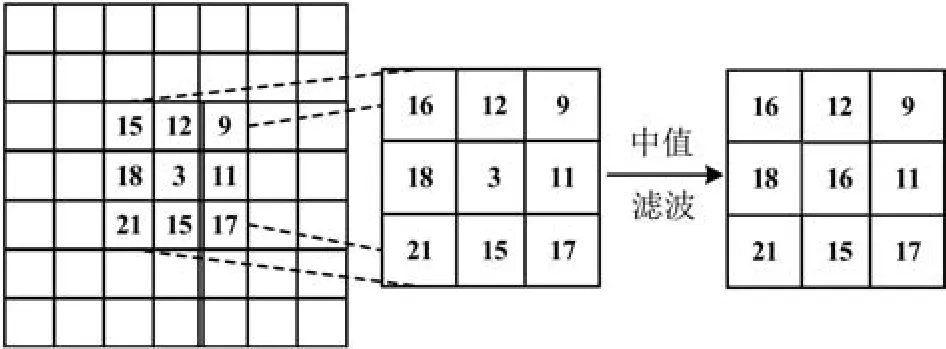
图2 中值滤波示意图
3 并行优化
3.1 算法并行优化
为了便于程序进行处理,将灰度质心算法公式分解为三部分依次进行计算,分别为公式(1)或公式(2)的分母A,公式(1)的分子B和公式(2)的分子C。
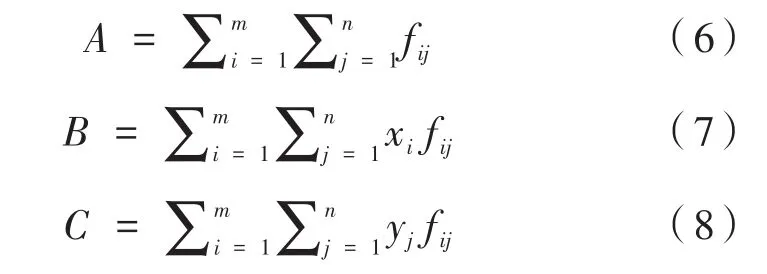
以公式(6)的计算过程为例,首先由Host端程序将图像像素数据从中央处理器(CPU)中以一维数组的形式复制到图形处理器(GPU)的全局存储器(Global Memory)中,再进一步分配到GPU中每个block的共享内存中供Device端程序进行并行计算。计算之前先判断图像灰度值是否大于阈值,大于则灰度值不变,否则将灰度值设为0。然后将保存在一维数组里的像素值分割成大小相等的n个数据块,GPU中每个thread只需要对某一小块数据进行简单的求和计算,计算完成后再利用归约算法将每个block中所有thread的计算结果归约成一个结果保存在block(0)中,完成后由 Host端程序将所有 block(0)结果从GPU显存拷贝至主内存。最后CPU计算所有block之和,即可得到公式(6)的计算结果。公式(7)和公式(8)的计算只需要在每个线程对数据块内的所有像素进行求和运算前乘以每个像素对应的行坐标或列坐标。
实验中所有程序均由C++语言编写,GPU加速部分程序采用了英伟公司提供的CUDA编程模型,并且编译生成为便于主程序调用的静态库。整个过程采用跨平台编译器CMake编译并生成可执行文件。由于从相机读取得到的图像格式是1 024×1 280分辨率的单通道8位灰度图,所以一张图片总共有1 310 720个像素点。GPU是以一维数组的形式读取Mat类图像的像素灰度值,也就是要对1 310 720个一维数组元素进行计算。在CUDA中,数据是从主内存复制到显存的Global Memory,而数据的复制过程往往耗时较长,可以通过增加线程的数量来提高显存的带宽。Jetson Xavier NX中每个block的最大线程(thread)数是1 024个,如果采用单个block,则每个线程要计算1 280个数值。为了充分地利用GPU资源,计算调用了32个block,每个block均调用256个thread参与并行计算。这样总共有8 192个thread同时对一维数组中的数值进行求和运算,大大提高了程序的并行效率。
通常显卡的内存都是DRAM,因此对显卡内存访问最有效的途径是连续访问。当并行执行线程时,每个线程都运行在一个连续的全局显卡内存块上,但当一个线程正在等待数据时,GPU切换到另一个线程,另一个线程将从另一个位置的全局显卡中转移内存块中的数据,如图3所示。
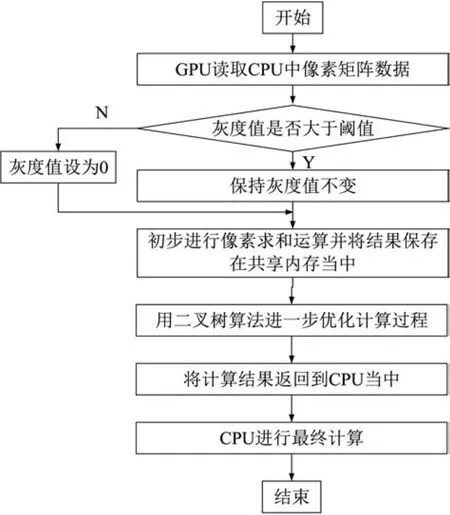
图3 并行优化流程图
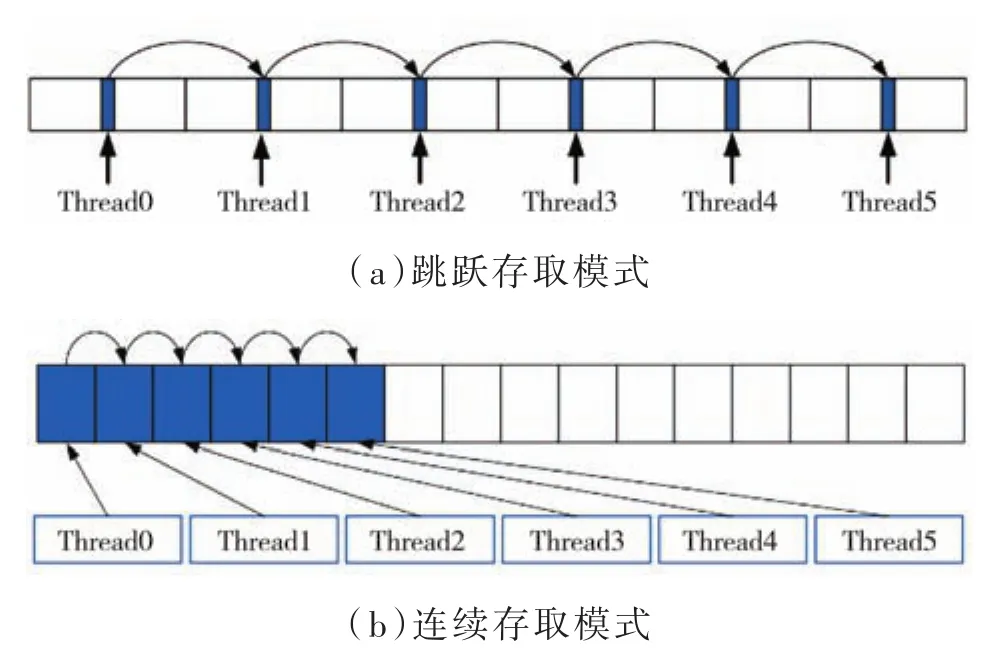
图4 存取模式对比
综上分析,虽然看起来每个线程对一块连续的地址计算,但实际上执行时,当一个线程在等待内存的数据时,GPU会切换到下一个线程,因此,在同一个线程中连续存取内存,在实际执行时反而不是连续了[15],而是跳跃式的存取模式。因此,需要采用全局内存访问合并技术,将显存的存取模式改进为连续存取模式,提高线程数据访问的效率。
3.2 二叉树算法改进
上述程序是通过一个线程(Thread 0)实现了一个Block块中所有像素点灰度值的累加。为了进一步提高程序的并行化程度,将每个Block块中的加法都进行并行化。本文采用了二叉树算法用于质心算法中的并行加法计算。
如图5中Block(0,0)所示,每个block中的每个格子都代表了一个线程中的所有像素点灰度值之和,第一轮迭代开始时,设置步长offset为1,掩码 mask为 1,则 Thread 0和 Thread 1相加,Thread 2和Thread 3相加,以此类推。当第二轮迭代开始时,设置步长为2,则Thread 0和Thread 2相加,Thread 4和Thread 6相加,以此类推。每迭代一轮步长和掩码更新一次且所有线程需要进行一次同步,以此类推,直至迭代结束,每个block最终都通过线程Thread 0完成归约并将结果保存在其共享内存shared[0]中。
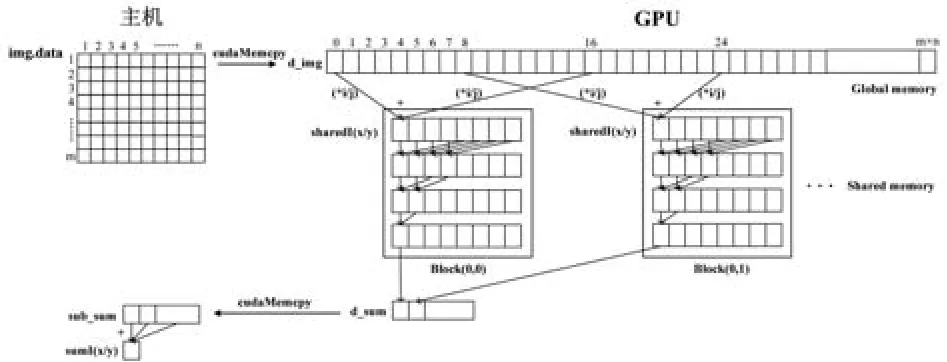
图5 二分法并行归约算法图
除了改进显存存取模式之外,还可以通过使用共享内存来改善全局内存合并访问。如图5所示,程序共申请了3组共享内存,分别用来保存每个线程在每一轮迭代过程中对这3条公式依次计算所产生的结果。程序总共启用了32个block,而每条公式都有32个归约结果,故总共有96个结果保存在各个block的共享内存当中,这96个数据传输到CPU中计算出每个公式的最终结果。
为了验证并行优化后质心计算的加速效果,实验采用了NVIDIA嵌入式设备Jetson Nano和Jetson Xavier NX对程序进行了测试。分别设置了两组对照实验,即采用传统方法(CPU)计算图像质心和采用并行优化方法计算质心。用这两种方法分别在Nano和NX中对100张光斑图像进行计算,光斑图像为8位单通道灰度图,分辨率1 024×1 280。程序的运行结果如图6所示,在Nano上采用传统质心计算方法的运行时间约37 ms,而并行优化算法后只需要约8 ms。而在NX上传统方法运行时间约17.5 ms,并行优化后约3.4 ms,可见采用这种GPU-CPU异构体系结构可以大幅减少算法的运行时间。
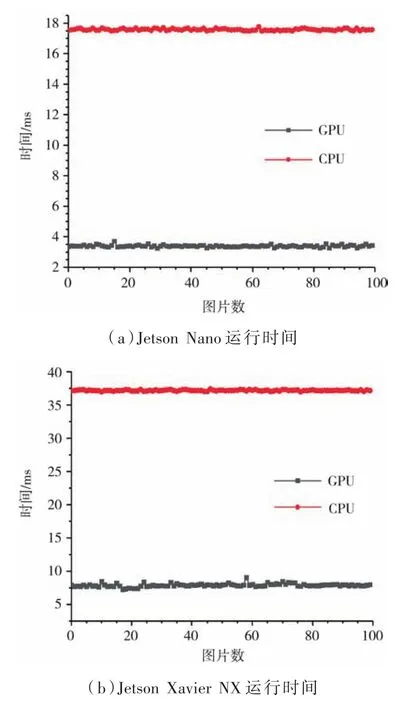
图6 GPU和CPU运行时间对比
4 实验与结果分析
为了测试采用GPU加速的无人机实时对准跟踪技术的准确性和可行性,实验采用搭载Jetson Xavier NX的Ronin-MX云台在大疆经纬Matrice 600 Pro轻小型无人机平台上进行了实验验证。图7(a)为实验中采用的无人机,自重9.6 kg,最大起飞重量为15.1 kg,满载时可飞行18 min,要求挂载的激光通信设备总重量要保持在6 kg以内。设计的光通信载荷外形如图7(b)所示,内部结构如图7(c)所示,主要包括摄像机、姿态传感器、嵌入式设备、焦距镜头、激光器等。图7(d)为光通信地面端跟踪实验设备图。

图7 光通信跟踪对准实验设备图
激光器选用夏普GH0631IA2GC激光二极管,生成的激光波长为638 nm,光斑形状为圆形。相机型号选用MindVision CMOS类型常规面阵黑白工业相机MV-SUA134GM-T,有效像素130万,图像分辨率1 280×1 024,像元尺寸4.8µm ×4.8µm,相机接口为USB3.0且支持Linux驱动。所使用的实验平台为NVIDA公司的Jetson Xavier NX开发套件,搭载48个Tensor Cored的384核NVIDA Volta GPU,同时配备6核NVIDIA Carmel ARM 64位CPU及8 GB LPDDR内存。Jetson Xavier NX采用基于Ubuntu18.0.4的Linux环境,支持NVIDIA CUDA并行架构和各类SDK扩展包,同时辅以跨平台编译器Cmake。它体型小巧、性能卓越,非常适合搭载在无人机吊舱内部作为控制核心。
在程序对相机得到的灰度图像进行质心计算之前,为了增强图像对比度和平滑噪声,需要调用OpenCV2中自适应直方图均衡化函数和中值滤波函数进行图像预处理。自适应直方图均衡化函数的对比度参数为2,块的大小为8×8;中值滤波函数内核大小(ksize)为 3,即取 3×3的矩形窗口。图像预处理后的激光光斑图像效果经过比例放大后如图8所示。自适应直方图均衡化处理后虽然图像对比度增强了,但光斑边缘模糊且背景中出现了很多椒盐噪声,而采用中值滤波函数对图像噪声进行平滑处理后,噪声明显变少且光斑边缘形状也更加清晰。

图8 图像预处理
实验中通过读取相邻两个采样数据之间的时间差值即可知使用传统方法(CPU)计算整个闭环控制系统后的单次运行时间,如图9所示,运行时间约39.35 ms,而对算法并行优化后的系统单次运行时间约32.38 ms,速度可达每秒31帧;由于读取相机图像像素程序的运行时间约28.4 ms,控制程序运行时间约0.5 ms,可见采用GPU并行优化后的光斑质心跟踪对准方法可以有效减少质心计算时间(时间减少了约7 ms),进而缩短闭环回路控制时间,提高控制系统的闭环带宽。
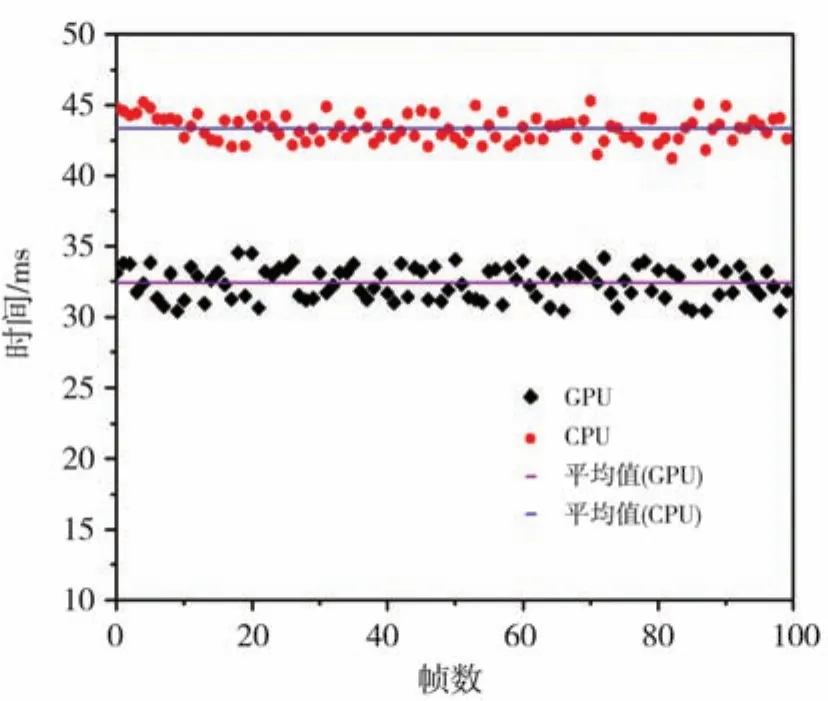
图9 单帧图像运行时间对比图
图10显示了采用GPU加速质心算法后,在Jetson Xavier NX上测得的包括分配内存、传输数据及GPU与CPU计算的时间。像素矩阵数据从CPU复制到GPU的时间(包括分配内存)约0.7 ms,GPU中并行计算及CPU计算最终结果的时间约0.1 ms,GPU将计算结果返回到CPU的时间(包括释放内存)约2.5 ms;采用并行优化算法后计算质心总共耗时约3.4 ms,可见采用GPU并行优化灰度质心算法后,如果能进一步优化数据传输过程,程序运行速度仍能有所提升。
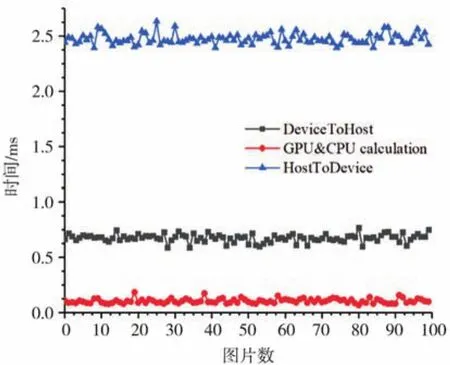
图10 计算和数据传输时间
实验通过PID控制算法控制Ronin MX云台横滚轴和仰俯轴电机运动的角速度,最终实现光斑质心与图像中心点重合并保持稳定状态。经过调试,最终的PID参数设置如下:比例增益值kp为113,积分增益值ki为0.5,微分增益值kd为11。将实验测量得到的阶跃响应离散数据用Matlab软件绘制出来,经过拟合后得到的横滚轴阶跃响应曲线如图11所示。仰俯轴PID控制参数同横滚轴一致。图11中横坐标表示系统的采样数(视频帧数),由图9可知每帧图像用时约32.38 ms,纵坐标表示光斑质心在横滚轴方向上的像素点位置相对值。分析实验数据可知,采用PID控制算法后,系统的上升时间tr为0.069 s,峰值时间td为0.109 s,调整时间ts为0.454 s,最大超调量为0.521,系统的震荡次数为2次,系统的稳态误差(脱靶量)稳定在0.1 mrad(about four pixel)以内。
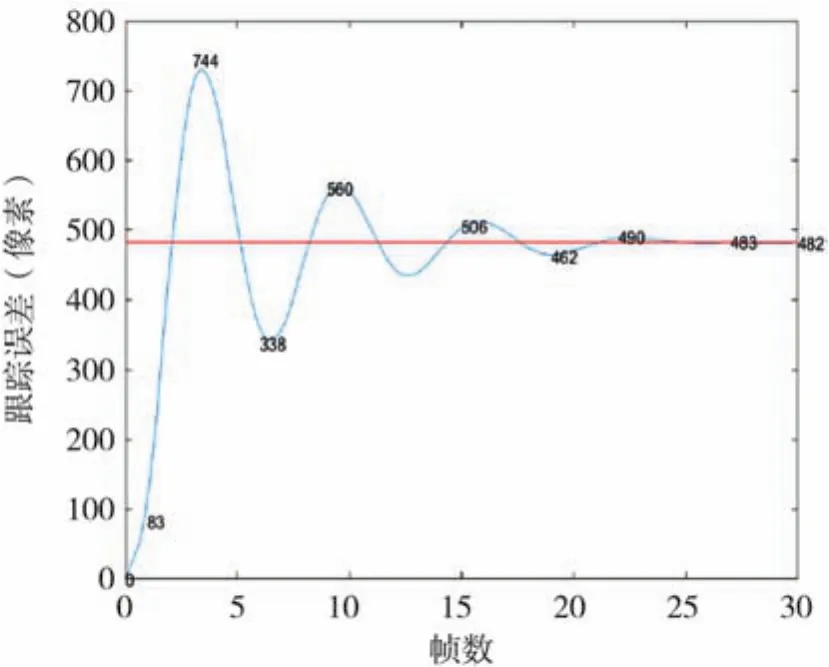
图11 阶跃响应曲线图
5 结论
本文在研究了灰度质心算法定位光斑质心从而实现激光通信的理论基础上,采用图形处理器并行优化的方法对算法的计算过程进行了加速,经过加速的算法运行时长从原来的11 ms缩短至不到4 ms,加速效果显著。并且,本文还设计了搭载Jetson Xavier NX的光通信载荷在大疆无人机上进行激光通信系统对准跟踪的实验验证。实验结果表明,采用图形处理器加速的无人机光通信系统对准跟踪技术具有快速性、准确性和稳定性,对准跟踪光斑质心的脱靶量小于0.1 mrad,光斑质心跟踪帧率可达到31 FPS,满足了光通信系统的要求。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
汽车实用技术(2022年5期)2022-04-02
北京航空航天大学学报(2021年4期)2021-11-24
无线电工程(2020年9期)2020-08-31
无线电工程(2020年8期)2020-07-25
阅读(高年级)(2019年9期)2019-11-15
VOGUE服饰与美容(2019年8期)2019-11-12
阅读与作文(小学高年级版)(2019年8期)2019-10-16
小资CHIC!ELEGANCE(2019年28期)2019-09-12
中学生数理化·教与学(2019年5期)2019-06-06
