
基于模糊综合评判的媒体新闻数据清洗方法研究
2022-12-27 03:51魏俊杰
中国传媒科技 2022年11期
魏俊杰 何 翼 熊 黄 庄 辉
(深圳新闻网传媒股份有限公司,广东 深圳518034)
1.新闻数据清洗相关定义及其应用现状
1.1 新闻数据清洗相关定义
数据清洗是指通过一定的技术手段来解决数据质量问题的过程,在不同领域实际应用中,数据清洗的具体操作可能会有所不同,一般来说包括数据质量管理、数据库以及数据挖掘三个方面。新闻数据清洗则主要是针对新闻数据进行上述操作,本研究数据清洗主要是指改善所使用的新闻数据质量这一过程。[1]
1.2 新闻数据清洗方法应用现状
1.2.1 国外应用现状
从国外研究情况来看目前有较多的数据集成商或服务商能够提供定制化数据清洗服务,且已经步入了较为成熟的商业化阶段。目前国外提供的清洗方案主要包括用户自定义工具和搜索引擎,两者有着各自的优势和弊端。
第一种用户自定义工具是一种半开放式框架,用户可以根据自己的需求来制定清洗规则,但最大难点在于需要运用清洗策略语句和类编程语言,这就大大提高了新闻工作者的工作难度,因此这类工具使用效果较不理想。[2]第二种搜索引擎主要是通过对维度、属性等进行预先分类,然后在用户搜索时能够给出筛选后的数据。这种方式使用较为便捷,但其弊端在于设置分类时主观性较大,分类指标设置过细,则可能将原本不属于数据噪声的信息去掉,因此还需进一步人工处理。[3]
1.2.2 国内应用现状
国内数据清洗应用已有较丰富的成型算法,且和电子商务等实际商业用途进行了结合,包含的数据类型有抽象数据、多元组等类型。但针对自然语言的数据清洗应用还较少,主要原因是所需技术需要多学科交叉配合,这就大大提升了制定数据清洗规则的难度。同时,国内数据清洗的商业化动力还较弱,主要还是停留在简单转化有限文本的层面。[4]
因此,本研究则针对笔者日常工作中的媒体数据,对其数据清洗问题进行进一步深入研究,利用基于模糊综合评判模型,从媒体角度在信息源头就去除数据噪声信息,保证新闻数据的质量,进而实现对新闻稿件的快速清洗。
2.基于模糊综合评判的媒体新闻数据清洗方法设计与应用
运用基于模糊综合评判的媒体新闻数据清洗方法时,第一步需要搭建总体框架,第二步需要建立新闻数据评级指标体系,第三步需要对该体系进行定量化评估。
2.1 总体框架
媒体新闻数据清洗方法总体技术框架如图1所示,主要包括了模式约束处理、实例数据清洗以及语义验证阶段。[5]
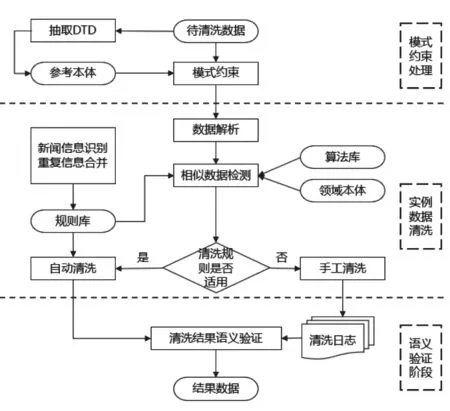
图1 数据清洗框架
2.2 建立新闻数据评级指标体系
2.2.1 构建媒体新闻指标体系
构建完数据清洗框架后,应当在实际工作中对新闻稿件筛选,主要包括的指标有新闻事件、新闻基本要素。新闻事件主要是反映新闻发生的时间、地点、人物等,这些属性可以作为数据清洗的维度。新闻基本要素主要是评估新闻的完整性和准确性,在数据清洗时可以利用其进行筛选,提高采集效率。新闻内容则包含了一些讨论内容或立场,在数据清洗时可以根据倾向分析快速识别舆论热点。[6]具体指标体系如表1所示。

表1 媒体新闻指标体系
2.2.2 基于模糊综合评判的定量化评估
本研究基于模糊综合评判法构建新闻稿件质量评级体系,并对各项指标进行量化。在实际工作中发现,对媒体新闻数据集合归属的界定不是很清晰,模糊概念之间的差异无法量化。因此,利用模糊集的概念对此类表述进行处理,将其表示成为三角模糊值,通过加权平均值的方式使得输出结果包含更多信息。
其模型集主要包括判断因素集合、评判等级集合以及权重集合,同时还包括单因素评判矩阵。在模糊向量和模糊关系矩阵都已有的前提下,可以对模糊变换进行综合评判。[7]主要步骤如下:
(1)划分因素集U
(2)初级评判
(3)总体评判矩阵
得到总体评判模型为:素集的权重模糊向量为A、迷糊关系矩阵为R,可得

能够看出对因素进行了K 次划分,第K 次划分的单层次评判就是K+1 次划分的综合评判。
(4)确定评判等级及隶属函数
本研究将评判等级划分为五级,从0~100 每隔20 分值为一级,将各级区间的中值设置为等级参数,即等级参数
分级完成后,建立各影响因子对应级别隶属度函数关系式,本研究选择线性隶属度函数,隶属第一级的隶属函数为:
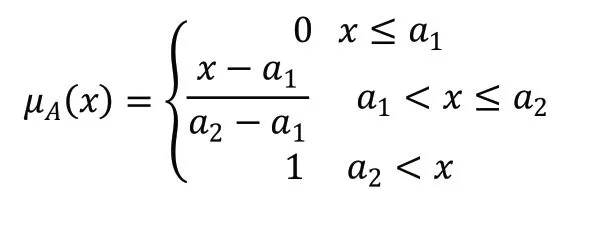
2.3 基于模糊综合评判的媒体新闻数据清洗实验及结果
2.3.1 实验新闻稿件数据源
本次实验新闻稿件选择深圳新闻网采编数据库,选择2021年10月至12月入库的1456.86 万条新闻数据进行数据清洗,实验指标设定如表2所示。主要原因如下:
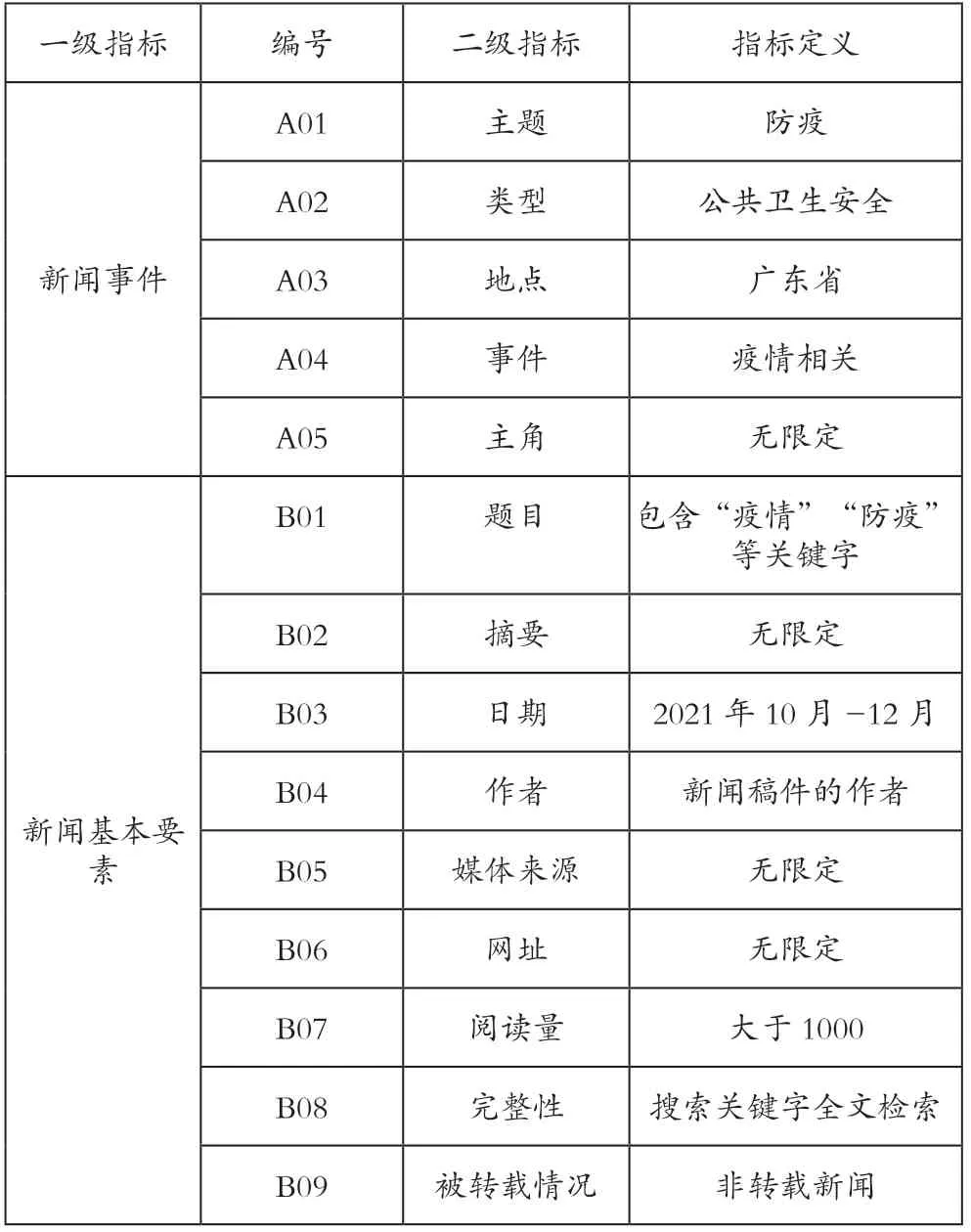
表2 实验设定指标
首先,数据质量较高,便于建立规则库。深圳新闻网数据源均为已审核过且能够直接使用的数据,其数据质量已有一定的保证,数据要素基本完整、标准化程度较高。因此选用该数据,可以有效降低数据预处理压力,从而能够更加精准地对数据清洗效果进行分析,并评判出清洗规则是否有效。其次,稿件内容较为广泛。深圳新闻网是立足于“中国改革开放窗口”深圳的国家重点新闻网站,是全国领先的地方网络媒体,有着完善的全库数据,并且与全国上百家大型媒体单位有合作,大部分新闻数据稿件能够互通互用,这就保证了实验数据源有着充分的基础。最后,新闻稿件数据能够转化为XML格式,这种格式有着可扩展等优势,已成为当前数据交换、电子商务等领域应用最为广泛的数据格式标准,本次实验中也采用该种数据类型。数据推送采用FTP 数据传送方式,设定推送间隔为三分钟。
2.3.2 数据清洗
2.3.2.1 标准化处理
由于新闻数据来源较为广泛,数据要素和表达形式可能有所不同,因此需要对一些新闻素材进行标准化处理。例如在有的稿件中将日期表示为“2021.11.5”,而有的稿件中又表示为“11/5/2021”,或者还有的使用英文表述。针对不同数据,需对应各自的拆分规则库,不同规则库有不同的提取规则,新闻稿件中的各数据已经是被拆分后的字段,符合一定的粒度级别以及相应的树状结构。拆分后的字段会在内存模型数据结构中进行保存。
在对数据进行标准化处理时,利用贪婪算法在动态表单入口处对其进行标准化处理,进而能够有效控制表单域排序,加快数据采集和传输效率。基于深圳新闻网语料库,采取内存层次模型进行标准化操作,处理的具体方法和步骤如图2所示。通过对新闻稿件标准化操作,能够对数据消除歧义,提高后续算法执行的可行性。[8]
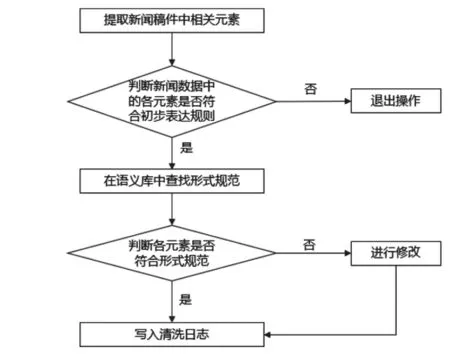
图2 标准化操作步骤
2.3.2.2 匹配消重处理
媒体新闻报道时,会存在相互转发的情况,而有些稿件并非原创,也会存在重复数据,因此需要对新闻数据进行匹配消重操作,将无效数据进行剔除。使用匹配技术对关键字进行检测,然后分别在文档级别和文档元素级别对其进行匹配,为了提高匹配效率,高级别粒度数据匹配时会参考低级别粒度的结果。本研究采用的主要是SNM(Sorted-Neighborhood Method)方法进行匹配消重,其基本思路是对全数据进行排序,并且对文件进行递归,再比较相邻记录的相似程度,最后经过计算完成记录匹配过程。[9]
第一步为创建排序关键字。该步骤需要根据数据总体情况进行评估,计算数据集中每条记录的键值,最后基于匹配标准进行判断。第二步是对整个数据集进行排序操作,如果在匹配关键字时认为有相似的重复记录,则会将其放置在邻近区域内,从而使得排序后的数据集有着更高的匹配性,大大降低了数据比较次数,提高了匹配效率。第三步为计算字段匹配得分,采用滑动窗口的形式进行比较。匹配算法包括:一般性匹配、字符串完全匹配、单错误匹配和缩写词匹配。经过该步骤后,被清洗脚本自动清洗的新闻则被认定为是稿件重复。第四步则是与阈值比较、分流数据,需设定一个阈值范围,可根据数据源的实际情况进行灵活配置。同时要记得将新闻数据写入相应清洗日志,退出流程。
2.3.2.3 补全缺失数据
在对数据仓储装载数据时,原始数据可能有所缺失,对有些重要新闻而言,缺少数据可能导致清洗策略失效。字段值的缺失,主要包括:缩写词、惯用语被格式化以及字段值不符合规则或超出范围等。具体来看,数据补全主要包括:第一是对不完整字段进行补充,例如一些新闻出处的URL 地址不完整,需要对其补充才能够得到必要参数。第二是对空值字段进行补全,例如一些新闻XML 文档中填写了新闻发生地点这一属性,但部分又未填写,而新闻发生地点这一属性是数据清洗的关键字,此时就需要对空值进行补全。第三是需要增加字段补全额外信息,例如一些新闻数据的来源类型、入库时间、邮编等信息不够完整,可以采用一些搜索树形式的外部辅助文件加以补全。[10]
本研究利用朴素贝叶斯方法来补全缺失的数据,该方法能大大降低计算复杂度且可以自动划分属性,相关公式为:
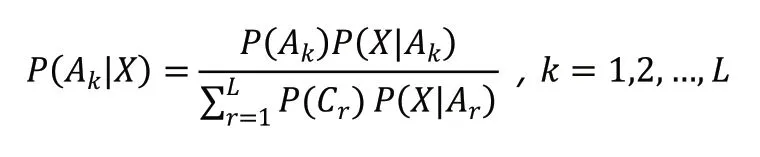
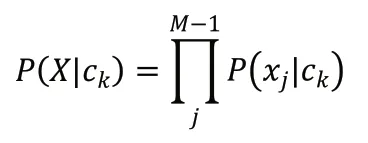
如果X 缺少了某个属性值,要对其进行补充,则设j 是记录中所有非缺失值的索引集合,则根据下式进行计算:
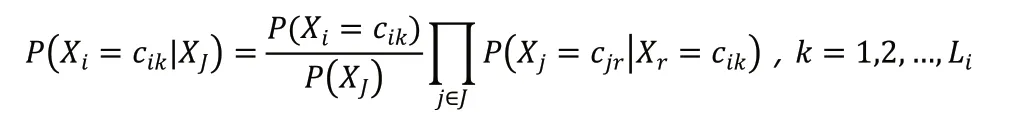
2.3.2.4 相关工具管理
在数据清洗时还需对使用的清洗工具进行管理,主要包括清洗任务管理、清洗算法管理、拓展算法管理、规则库管理以及清洗日志管理。
清洗任务管理主要是记录实体表以及表中的基本信息,包括表名、主键及相关描述等,一个清洗任务可能执行了多个实体表的目标。任务管理描述表如表3所示。

表3 数据清洗任务管理描述表
清洗算法管理主要是为了能够提高其清洗的灵活性,将所使用的算法加入到算法库中,然后在实际使用时,选择相应的算法可以较为灵活配置,在实际清洗工作中利用计算机集群进行工作,按照不同版块实施清洗任务。算法管理结构表入表4所示。
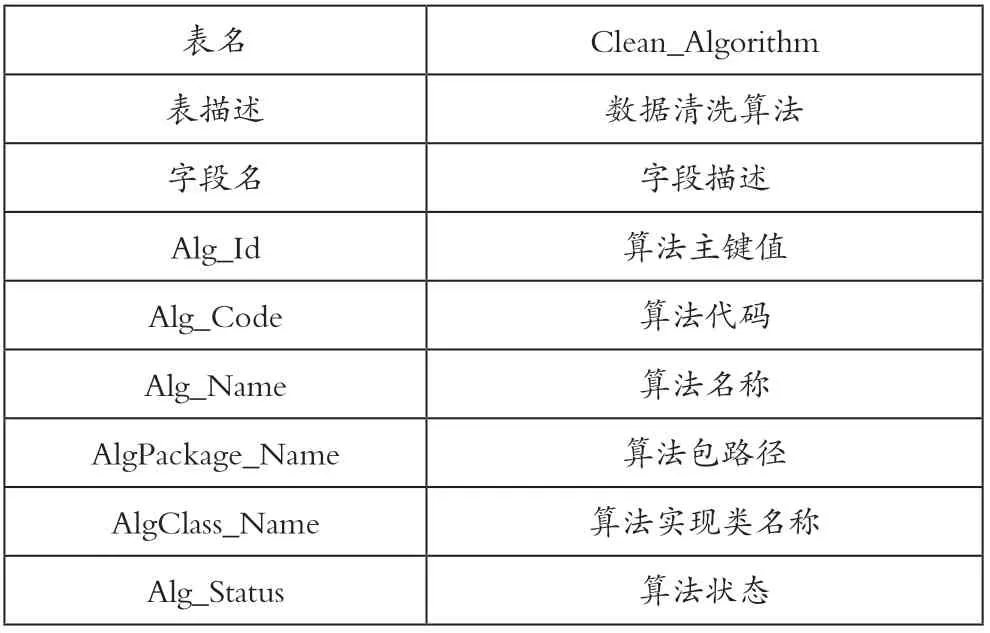
表4 数据清洗算法管理表
拓展算法管理则是在已有算法管理的基础上,通过算法接口实现算法的可扩展性。利用拓展算法管理,可以制定个性化的数据清洗算法,将其编译好后,保存在该管理配置表中,使用时调用相关接口。具体拓展算法管理表如表5所示。
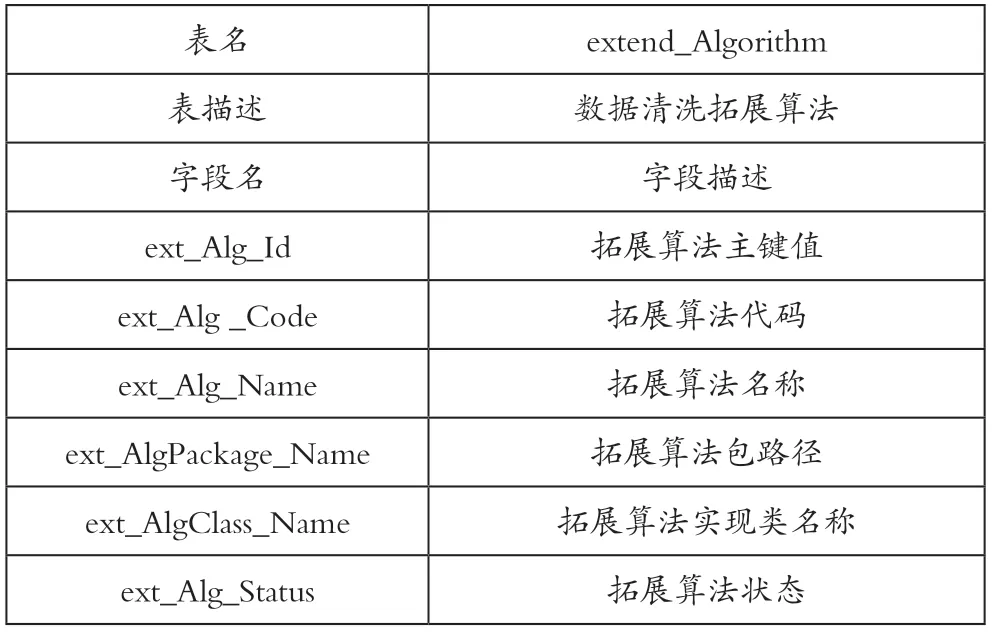
表5 拓展算法管理表
规则库管理则主要是存储数据清洗规则包含的一些运行参数、清洗指标等,主要需与实际业务相对应,具体规则库管理表如表6所示。

表6 规则库管理表
清洗日志管理主要是记录在数据清洗过程中的相关信息,做到清洗任务可回溯,例如对清洗过的数据标记为历史数据,不能清洗的数据标记为异常数据。具体数据清洗日志管理表如表7所示。
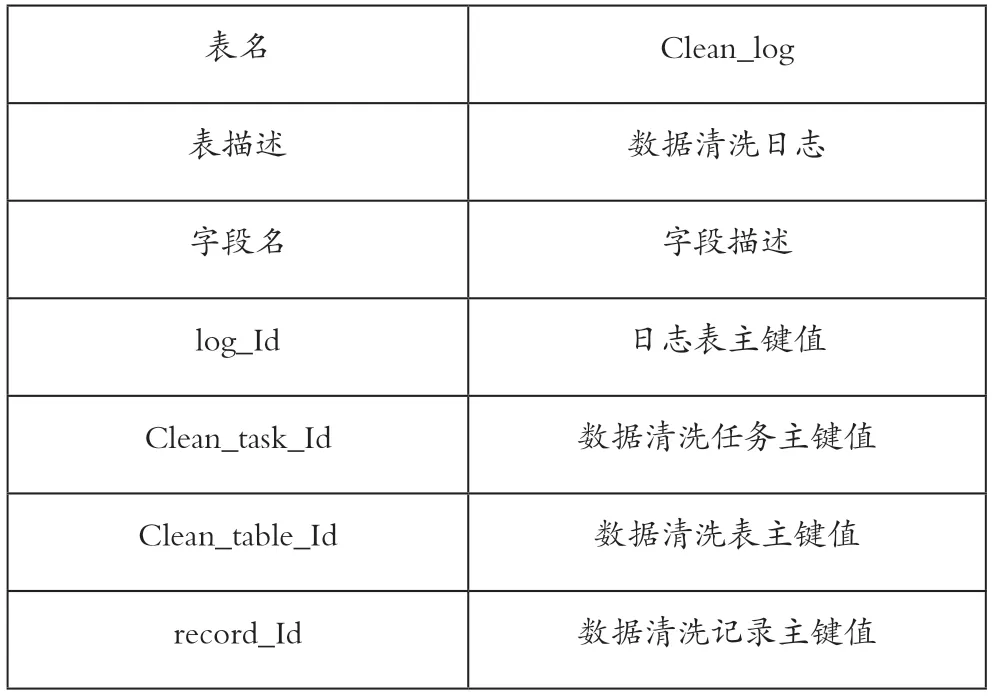
表7 数据清洗日志管理表
2.3.2.5 数据清洗结果
本研究对2021年10月—12月入库的1456.86 万条新闻数据进行数据清洗,清洗结果及各轮耗时统计如表8所示。能够看出,经过数据清洗后,数据量由1456.86 万条降低至8233 条,清洗时间逐步降低,涉及报道的媒体来源也降低至19 家。通过数据清洗后,有效缩减了海量新闻数据采集的时间,大大提高了新闻采编人员的工作效率,为整个集团工作流程高效运转奠定了基础。

表8 数据清洗结果
总结
本研究结合深圳新闻网实际采编工作,利用基于模糊综合评判的数据清洗方法对1456.86 万条新闻数据进行了操作,具体步骤包括了数据标准化处理、匹配消重处理、补全缺失数据以及对相关工具管理。通过本次数据清洗,有效摒弃了无效信息、消除了信息噪声,合理筛选出了质量较高、具有较高研究价值的新闻源,同时优化了新闻数据清洗和采集流程,提高了采编人员的工作效率。
猜你喜欢
中国伤残医学(2022年14期)2022-12-27
政法论丛(2022年5期)2022-09-29
政法论丛(2022年4期)2022-08-16
政法论丛(2022年1期)2022-02-22
疯狂英语·新悦读(2020年1期)2020-02-20
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
自动化学报(2019年6期)2019-07-23
小学生学习指导(低年级)(2018年11期)2018-12-03
现代防御技术(2016年1期)2016-06-01
