
基于空洞空间池化金字塔的自动驾驶图像语义分割方法*
2022-12-27 08:25王大方赵文硕
汽车工程 2022年12期
王大方,刘 磊,曹 江,赵 刚,赵文硕,唐 伟
(1.哈尔滨工业大学(威海)汽车工程学院,威海 264200;2.陆军装甲兵学院兵器与控制系,北京 100072)
前言
自动驾驶能够有效降低出行成本,提升车辆利用率。同时可以有效减少交通拥堵,进而提升通行效率。
随着深度学习技术的发展,基于深度学习尤其是基于卷积神经网络的图像语义分割得到了飞速的发展,在很大程度上提高了图像语义分割的精度,与传统的分割算法相比,基于深度学习的语义分割可以自动地学习图像的特征,大大提升了图像分割的精确度,降低了自动驾驶使用语义分割技术的门槛。
自动驾驶车辆必须了解其周围环境,即道路上的各种车辆、行人、车道、交通标志或交通灯等。基于深度学习的语义分割方法是实现这一目标的关键,因为深度神经网络在检测和多类识别任务中具有惊人的准确性。车辆在道路上如果能对摄像头采集的图片或视频进行精确且快速的语义理解,就能在很大程度上对障碍躲避、路径规划等做出指导,这为自动驾驶提供了成本相对较低、部署较简易的信息补充。所以,稳定精确的语义分割结果为自动驾驶提供了丰富可靠的数据支持。综上所述,图像语义分割在自动驾驶领域有着非常重要的应用潜力。
在自动驾驶一些需要低延迟操作的应用中,语义分割方法的计算成本仍然非常有限。因为需要在精确的时间间隔内做出决定。所以,有必要改进分割网路的模型,让其能够以适当的精度实时执行高效的分割任务。本文中从精度和速度性能方面去考虑改进语义分割网络的结构,并通过实验验证算法在自动驾驶技术上应用的可行性。
1 相关研究
图像分割一直以来都是图像研究中的一个重点和难点,之前的图像分割方法多数是利用数学、拓扑学或数字图像处理等方法,深度学习方法对图像分割方法产生了巨大的影响。自动驾驶车辆必须了解其周围环境,现阶段的基于深度学习的图像语义分割结构主要有编码器-解码器结构、多分支结构等,利用金字塔结构提取深层语义信息,能够解决深层语义信息利用率较低的问题,从而对图像进行更加精确有效的分割。
1.1 传统分割方法
传统的图像分割方法主要有基于阈值的分割方法、基于边缘检测的图像分割方法、基于区域的图像分割方法等。基于阈值的分割方法是最为基础的图像分割方法,这类方法最重要的就是怎么去选取合适的阈值,它具有计算效率高、计算速度快和计算简单等优点,但是,也存在分割精度差、出错率高等缺点。比较著名的基于阈值的分割方法有大律法,又称最大类间方差法(OTSU)[1],它是1979年由日本学者大津所提出来的,是一种自适应的阈值确定方法。根据图像的灰度特性将图像目标和背景分为两个部分,目标和背景的类间方差和构成图像的两部分的差别成正比。由于图像的目标和背景在边界处的灰度值变换通常非常剧烈,通过利用图像目标和背景的边缘灰度不连续的这一属性,检测各个目标区域的分界线,就能够将图像的目标区域分割提取出来。基于边缘检测的分割方法通过求解相邻图像像素的1阶导数的极值点或是2阶导数的零点来作为检测目标的边界点。常见的通过求1阶导数的极值点来提取边缘点的方法有Roberts算子、Prewitt算子、梯度算子和Sobel算子法等[2]。基于区域的图像分割方法更加关注目标区域的内部特征相似性,通过利用目标区域和背景区域之间的属性差来对图像进行分割。利用相同目标与背景之间的内部特征具有相似性和不同的目标与背景之间的特征具有不连续性的特点来实现。该方法成功解决了图像在分割过程中不连续的缺点,但同时也存在图像在分割过程中出现过度分割的缺点。常见的基于区域的图像分割方法有区域生长算法、区域分裂合并法和分水岭分割算法等[3]。
1.2 基于深度学习的分割方法
常见的基于深度学习的图像语义分割方法有3种结构,包括基于编码器-解码器结构的语义分割方法、基于多分支结构分语义分割方法和基于金字塔结构的语义分割方法[4]。
第一种语义分割网络基于编码器-解码器体结构的网络,代表性的例子是ENet[5]。其中编码器模块使用卷积层和池化层来执行特征提取,解码器模块从子分辨率特征中恢复空间细节,同时预测对象标签(即语义分割)。编码器模块的标准选择是一个CNN主 干网络,如VGG16[6]、ResNet[7]、GoogleNet[8]等。解码器模块的设计通常包括基于双极插值或转置卷积的上采样层。
为了设计高效且同时精确的模型,人们提出了双分支和多分支网络。与单分支编码器不同,双分支网络使用深分支编码高级语义上下文信息,使用浅分支编码更高分辨率的丰富空间细节。在同一概念下,多分支体系结构集成了处理输入图像不同分辨率(高、低和中)的分支。但是,从不同分支提取的特征必须合并才能进入分割图。为此,两个分支网络引入了一个融合模块来组合编码分支的输出。融合模块可以是通过串联或加法连接输出特征的特征融合模块、聚合层(BiSeNet V2)[9]、双边融合模块(DDRNet)[10]或级联特征融合单元(ICNet)[11]。
为了提高深层语义信息的利用率,获取多尺度的语义信息,又有学者提出了金字塔模块,常见的有两种类型,在PSPNet[12]和PANet[13]中,作者使用不同尺寸和不同步长的卷积核来获取不同分辨率的特征图,在DeepLab[14]系列中,作者通过在各个分支使用不同的卷积来处理特征图从而获得不同分辨率的语义信息,使用不同膨胀率的膨胀卷积来完成相关的操作。DenseASPP[15]使用了更加密集的膨胀率的膨胀卷积来进行操作。这些方法在通过获取图像的多尺度语义信息,一定程度上提高图像语义分割的精度。
2 网络的设计
2.1 整体网络设计
本文中提出了一种多分支的语义分割网络模型,具体网络结果如图1所示,首先利用RseNet18作为网络的特征提取基准网络模块。ResNet18是由1个7×7的卷积层加上8个残差模块堆叠起的模块。随着网络的加深,残差模块能够有效解决深层网络的退化问题。相比于VGG16在性能上能够有较大的提升。
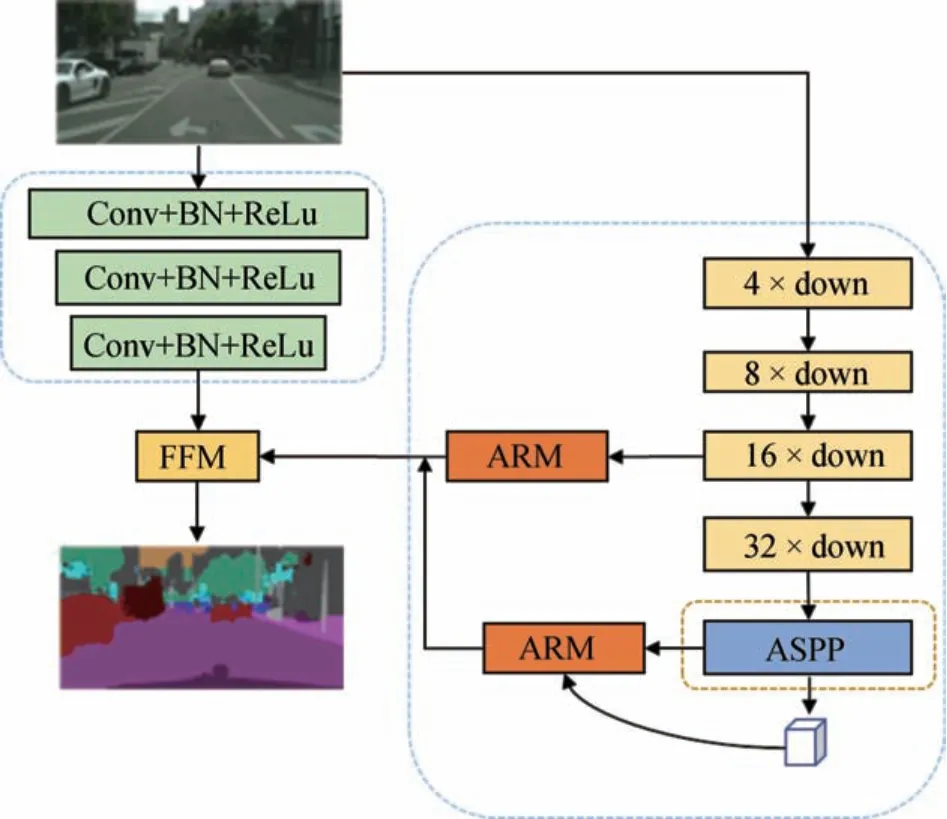
图1 整体网络结构
在ResNet18网络的输出端利用空洞空间池化金字塔改进网络的下采样结构,获取图像多尺度语义信息。网络的其中一个分支是由3个卷积、BN和ReLu层构成,图片经过该模块之后其尺寸缩小为原来的1/8,得到的特征图含有非常丰富的图像空间信息,能够尽可能地保留图片的细节信息。网络的另外一个分支是由改进后的ResNet18和空洞空间池化金字塔模块组成,主要用于图像深层语义信息的提取,空洞空间池化金字塔结构用于获得深层特征的多尺度的图像语义信息。ARM模块的主要作用是用来优化每一个阶段的图像特征,同时他的计算成本也比较小。ARM中使用的全局平均池化能够很好地整合全局空间信息,提高网络的鲁棒性,同时全局池化没有参数,可以降低网络参数,防止网络的过拟合。FFM模块是为了将浅层语义信息和深层语义信息进行融合,能够起到特征选择和特征融合的作用。
2.2 网络模块优化
本文在ASPP和ARM结构的基础上提出了一种新的特征提取结构,该结构有两种类型,本文取名为A_ASPP_1和A_ASPP_2,结构示意图如图2和图3所示。在A_ASPP_1模块中,输入图片通过一个常规的下采样特征提取网络,如ResNet、VGG16等,然后将输出的特征图通过空洞空间池化金字塔ASPP模块获取图像的多尺度语义信息。将下采样的子模块输出后通过注意力细化模块ARM进行优化,再与ASPP的输出特征通过注意力细化模块ARM后的均值进行叠加。ARM模块能够优化每一个阶段的特征,其使用了全局平均池化来获取每一个阶段的全局平均信息并指导特征学习[16]。在16倍下采样阶段的特征图通过ARM得到优化后的特征图后,将优化后的ASPP特征图与优化的16倍下采样特征图进行融合后加和输出。该结构主要对16倍下采样和ASPP的输出特征图的输出结构进行优化。A_ASPP_2的不同点在于将32倍下采样的特征图通过ARM模块优化后与空洞空间池化金字塔模块输出的均值进行加和后,再与优化后的16倍下采样特征进行叠加输出。该结构只对16倍和32倍下采样的输出特征图进行了优化。
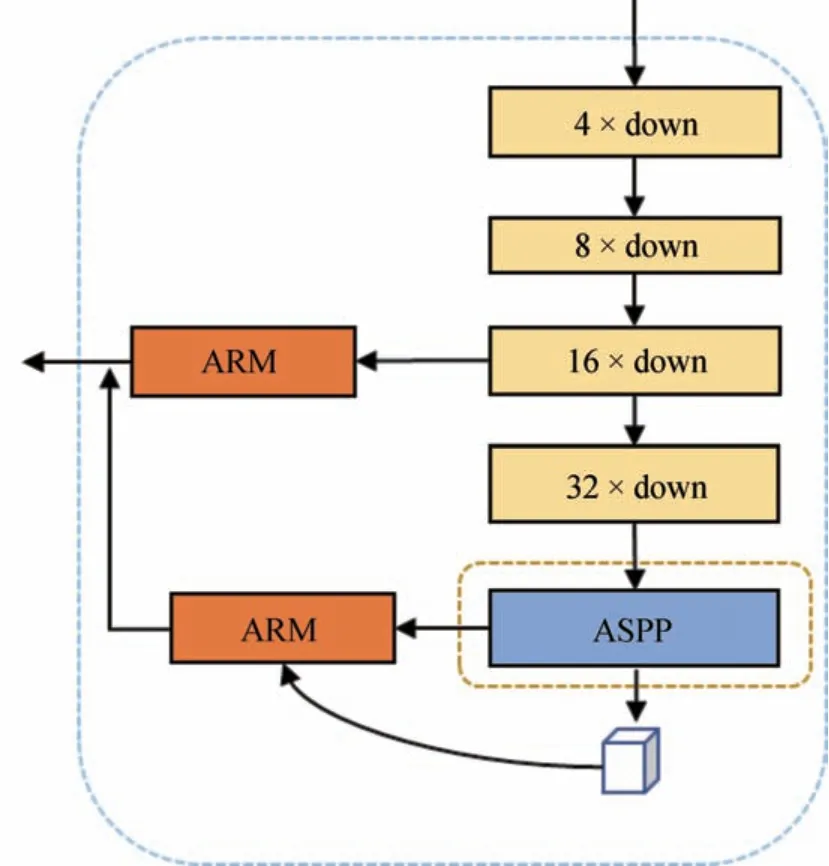
图2 A_ASPP_1结构
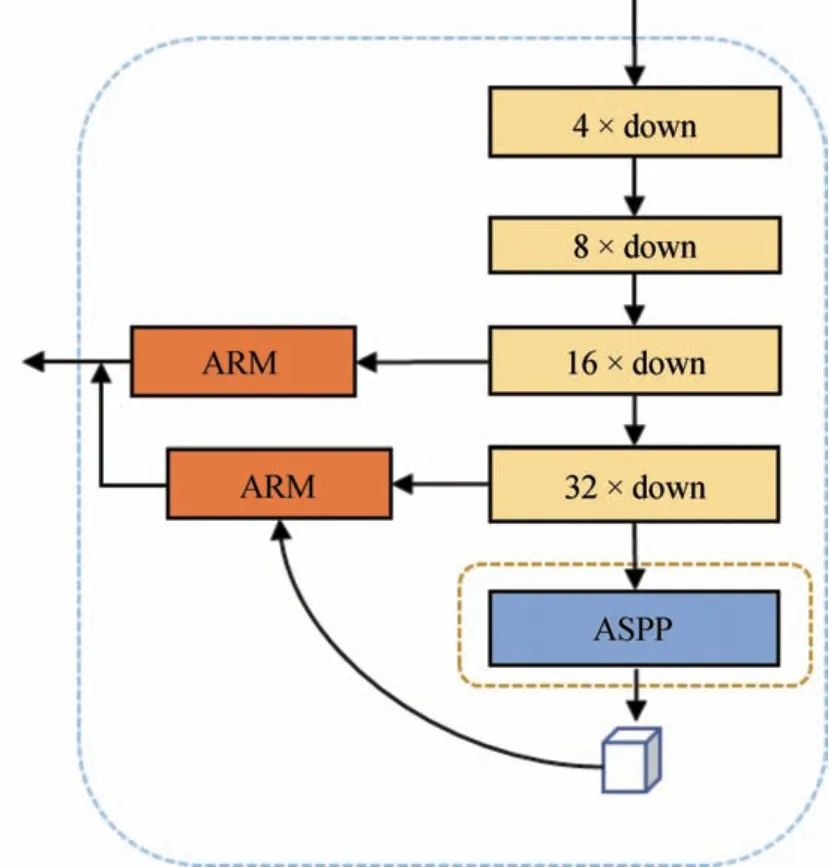
图3 A_ASPP_2结构
图中,4×down、8×down、16×down、32×down分别表示特征提取模块对输入图片的4、8、16、32倍下采样,ASPP表示空洞空间池化金字塔模块,ARM表示特征优化模块。
2.3 空洞空间池化金字塔模块
空洞空间池化金字塔模块示意图如图4所示,该模块是由一个1×1的卷积层、3个膨胀卷积层和一个池化层所组成。因为不同的膨胀率能够获得不用尺度的感受野,所以该结构主要通过使用不同膨胀率的膨胀卷积来提取图像的多尺度语义信息,而最后一个池化层是为了获取图像的全局特征。将获取到的各种特征图在深度方向进行堆叠再进行1×1卷积获取图像的多尺度语义信息。该模块能够有效提升深层语义信息的利用率,获取图像的多尺度语义信息,从而提升语义分割的精度[12]。
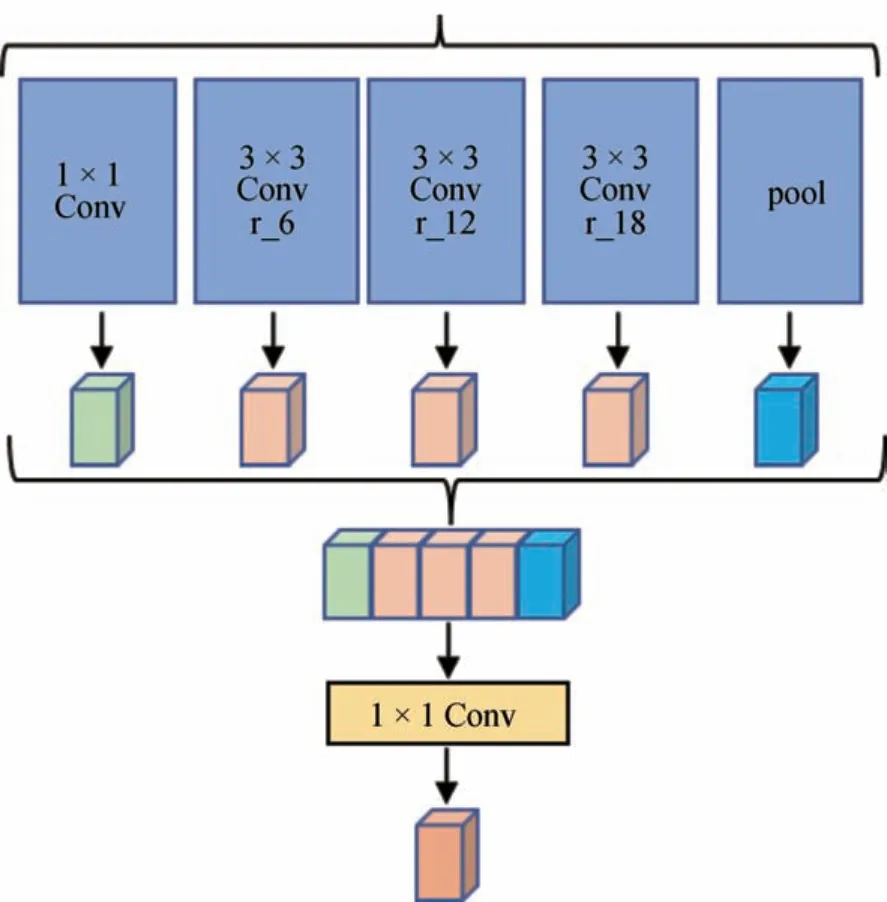
图4 空洞空间池化金字塔模块示意图
2.4 网络结构参数
本文使用ResNet18作为网络的特征提取网络,网络编码器和解码器的具体结构和参数如表1和表2所示。其中conv表示卷积操作,n×down表示n倍下采样操作,其由残差模块堆叠而成实现,上采样的实现为双线性插值算法,ASPP为空洞空间池化金字塔结构,conv_bn_relu分别表示卷积层、批量标准化和池化层,ARM表示注意力优化模块,FFM表示特征融合模块。A_ASPP_1的结构相比A_ASPP_2结构在注意力优化模块ARM的使用处有所不一样,优化的子模块不同,其余都相同。
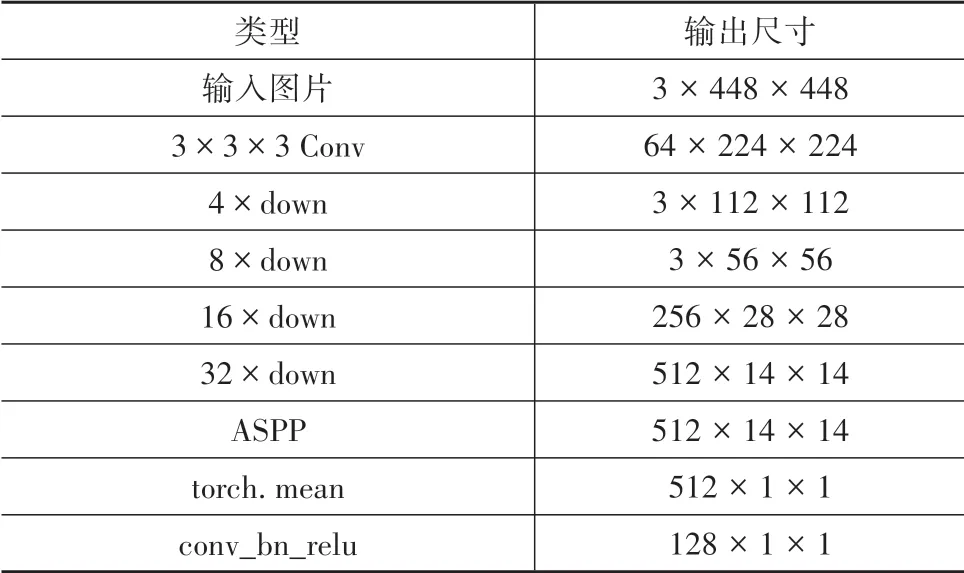
表1 编码器网络结构

表2 解码器网络结构
3 实验验证与结果分析
3.1 数据集简介
本实验所使用的数据集是VOC2012数据集,该数据集共有20个类别,包含行人、动物、自行车、火车、飞机、摩托车、自行车等常见的自动驾驶场景的类别图像。数据集共有17 125张图片,在图像分割任务中,共有训练集约10 582张,同时包含图片的语义标注,验证集1 449张,实验过程中对数据集进行了随机旋转和裁剪增强处理。图片的类别与标签如图5所示。

图5 VOC数据集图像示例(从上到下:原图;标签)
3.2 实验平台与超参数设置
使用该算法网络需要完成对图片的语义分割,其过程需要进行大量的矩阵计算,所以对设备具有较高的要求。本实验在Ubuntu16.04的操作系统下使用当前主流的深度学习框架Pytorch,利用python语言构建网络框架模型。CPU选用的型号为AMD Ryzen9 5950,硬件配置的GPU显卡版本为Nvidia GTX 3090,使用的实验平台的内存为芝奇DDR4 3 200 MHz 64 GB,同时使用了计算构架CUDA11.1和GPU加速库CUDNN进行高性能的并行计算。
在网络训练的过程中,学习率是最重要的超参数之一,网络训练过程中的初始化学习率设置为0.000 1。同时采用Warm Up的训练思想,在模型预训练阶段,先使用较小的学习率训练一些Epochs,再修改为预先设置的学习率进行训练。这样能够使模型的收敛速度更快,提高模型的收敛效果。训练过程中对输入图片先进行预处理,对图片进行随机缩放再进行随机翻转和裁剪,最后进行填充到指定尺寸,同时进行平滑处理。这样处理的作用是能够增强模型的泛化能力,实验最后选定尺寸为448×448。
另外,网络使用当前主流的优化方法SGD优化器对网络的梯度进行更新,采用的损失函数为交叉熵损失。由于随机梯度下降是连续的,且使用小批量,因此不容易并行化。使用更大的批量大小可以在更大程度上并行计算,因为可以在不同的工作节点之间拆分训练示例。这反过来可以显著加快模型训练。然而,较大的Batch Size虽然能够达到与较小的Batch Size相似的训练误差,但往往对测试数据的泛化效果更差,综合考虑本文选用的Batch Size为16。详细的训练超参数如表3所示。
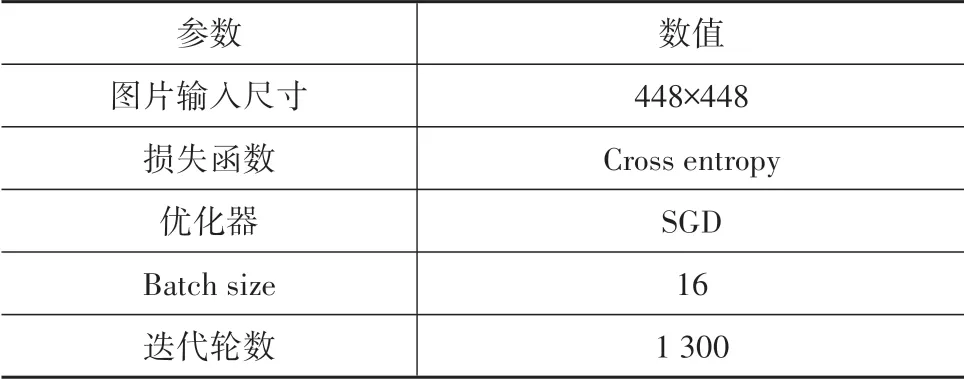
表3 实验参数
3.3 实验结果分析
本文采用的分割评价指标是平均像素精度(mPA)和平均交并比(mIoU)。平均像素精度表示图片中每个类中正确分类像素数的比例,然后再对其求平均,其定义见式(1)。平均交并比是图像分割过程中真实值集合和预测值集合的交集和并集之比。IoU和mIoU的定义如式(2)和式(3)所示。
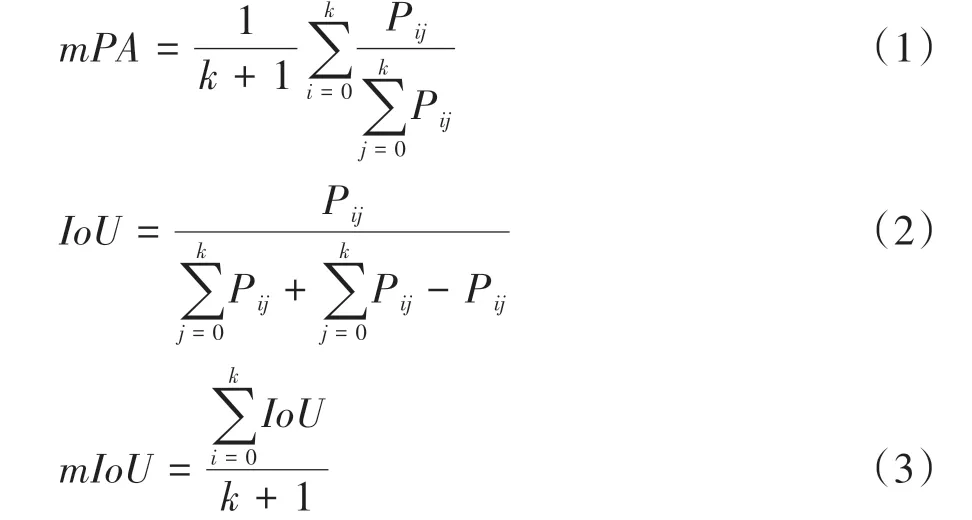
式中:k+1表示包括背景在内的语义类别综述;i表示真实值;j表示预测值;Pij表示将类别i预测为类别j的像素数量。
对于网络速度的评价,本文采用每秒传输帧数(frames per second)作为评价指标用于衡量模型的实时性能,表示网络每秒分割图像的数量。
为了验证本文网络的有效性,设置了模块间的对比实验,实验的参数和环境设置都相同,实验利用VOC2012数据集进行训练。训练集中常见的交通场景图片实验结果如表4所示。

表4 部分交通类别分割结果
从表中可以看出,本文提出的语义分割网络能够对自动驾驶场景中各种位置的行人和常见的自行车、公交车、小汽车、摩托车等进行有效的分割。可以看出行人和车辆的分割结构都能够达到比较好的分割精度。实验中部分人、自行车、公交、小轿车和摩托车等语义场景分割效果如图6所示。

图6 分割结果(从左到右:原图;A_ASPP_1结果;A_ASPP_1结果;标签)
为了进一步说明本文设计的网络有效性,本文在相同的超参数和训练环境下,使用VOC2012数据集训练相同的Epochs,对BiSeNet[16]网络进行了复现处理,对复现结果与本文结果进行了对比实验,实验结果如表5所示。
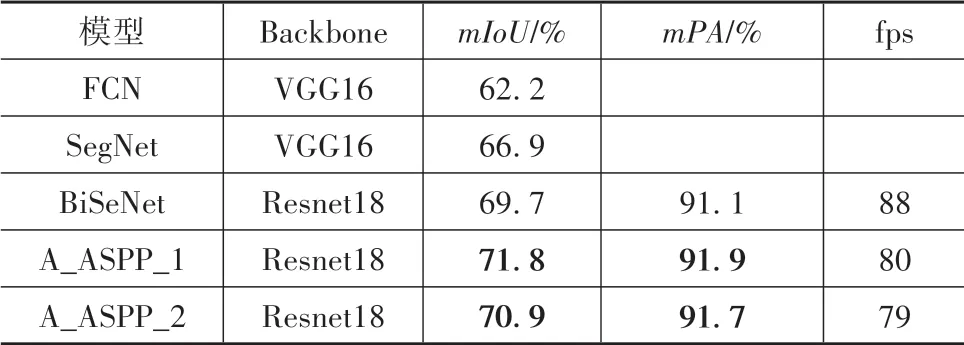
表5 VOC2012数据集训练结果
从表中结果可以看出,本文设计的两个模块A_ASPP_1和A_ASPP_2都能有效提升图像分割的精度,在VOC2012数据集上得到的71.8%和70.9%的平均交并比的训练结果,相对于现有图像语义分割网络BiSeNet,其在平均交并比上分别提升了2.1和1.2个百分点。同时在图像的平均像素精度上也能够达到91.9%和91.7%的结果,相比于现有语义分割网络BiSeNet提升了0.8和0.6个百分点。相比于其他的语义分割算法,也能够有效提升图像的分割精度,实验效果如图7所示。在分割速度方面,A_ASPP_1和A_ASPP_2每秒分别能够识别80和79张图片,相比于BiSeNet有少量减少,分割速度有部分降低。综上所述,改进的算法能够在小范围损失分割速度的基础上,有效提升网络的分割效果,实现语义分割在分割速度和分割精度上的平衡。

图7 分割结果对比(从上到下:原图;标签;BiseNet;A_ASPP_1;A_ASPP_2)
从图中可以看出,本文所提出的算法对于各种交通场景中的行人和各种车辆能够进行有效的分割,同时在相同的Backbone条件下,本文所提出的网络能够获得更好的分割效果,对自动驾驶场景中的车辆和行人场景有着更加精确的分割效果,分割结果更加贴近标签值。
4 结论
本文在现有语义分割网络的基础上,利用空洞空间池化金字塔模块进一步提取图像的多尺度语义信息,然后利用注意力优化模块和特征融合模块对图像的深层语义信息和浅层语义信息进行融合,再进行上采样输出。相比于现有BiSeNet网络而言,本文设计网络能够在损失少量分割速度的基础上,使得图像分割的平均交并比得到有效提升,分别提升了2.1和1.2个百分点,同时网络有着更好的分割效果。
实验结果表明,本文提出的两种语义分割网络模块能够有效地对自动驾驶场景类别的行人、自行车、公交、摩托车、汽车等图像进行有效的分割。如何以更快的分割速度来实现更高的语义分割精度并应用于实时语义分割领域,也是未来的重点研究方向之一。
猜你喜欢
计算机应用(2022年9期)2022-09-25
环球时报(2022-09-19)2022-09-19
软件导刊(2022年3期)2022-03-25
考试与评价·七年级版(2020年4期)2020-10-23
开放教育研究(2020年2期)2020-03-31
少儿美术(快乐历史地理)(2019年2期)2019-06-12
计算机技术与发展(2019年1期)2019-01-21
智能计算机与应用(2018年2期)2018-05-23
小学教学研究·新小读者(2017年9期)2017-10-25
中国修辞(2017年0期)2017-01-31
