
理想信息系统及粗糙集模型的统一
2022-12-27 01:07:56邓大勇唐雨朋杜巧连
浙江师范大学学报(自然科学版) 2022年1期
邓大勇, 唐雨朋, 杜巧连
(1.浙江师范大学 行知学院,浙江 兰溪 321100;2.浙江师范大学 数学与计算机科学学院,浙江 金华 321004)
0 引 言
粒计算理论[1-2]自被提出二十多年以来,取得了丰硕的研究成果,它已经成为人工智能的重要研究方向.在粒计算基本的组成理论中,粗糙集理论[3-4]是其基础和出发点.近四十年的粗糙集理论研究和发展中,产生了可变精度粗糙集[5-6]、邻域粗糙集[7-9]、覆盖粗糙集[10-11]、三支决策[12-14]、F-粗糙集[15-17]等众多粗糙集模型,这些粗糙集模型大部分从关系角度对粗糙集进行扩展.例如:邻域粗糙集用邻域关系代替等价关系,覆盖粗糙集用一般关系代替等价关系等;三支决策的关注点从经典粗糙集模型重点考虑的正区域扩大为正区域、负区域和边界区域,并给出了它们新的语义解释;F-粗糙集把粗糙集模型动态化,以方便处理动态变化的数据和大数据.
但是粒计算本身是一个直观的概念,缺乏严格的数学定义,很多粒计算的基本问题没有得到解决,比如:什么是信息粒?各种粗糙集模型是否可以统一?
针对这些问题,从传统集合论和离散数学出发,探索信息粒的基本含义,在信息系统中定义了信息粒基和最小信息粒基等概念,提出了理想信息系统假设,探讨了信息粒基的表示能力及它们之间的关系.初步回答了“什么是信息粒?”“各种粗糙集模型是否可以统一?”等问题.本研究结果为粒计算的进一步发展奠定了一定的数学基础.
1 相关基本概念
假设读者对离散数学知识和粗糙集知识比较熟悉,下面仅简单介绍粗糙集[3-4]的基本知识.
设IS=(U,A)是一个信息系统,U为论域,A为属性或关系,X⊆U是一个概念,记
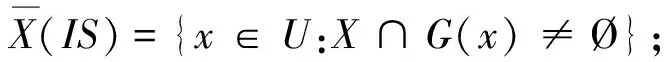
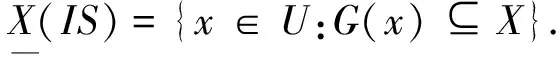

定义1[3-4]设DS=(U,A,d)是一个决策系统,U为论域,A为属性或关系,d为决策属性,称B⊆A为属性约简当且仅当它满足以下条件:
1)POS(U,B,d)=POS(U,A,d);
2)对于任意的S⊂B,都有
POS(U,S,d)≠POS(U,A,d).
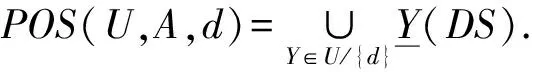
2 信息粒和理想信息系统
下面探讨信息粒定义,提出理想信息系统假设.
定义2信息粒是某种关系下对论域的分类或聚类.
在论域U下,U的任何子集都是一个信息粒,即信息粒的本质是论域中个体的集合.但信息粒与集合有一定的区别,集合强调个体元素的组成,而信息粒强调集合中个体所包含的共同信息.此外,信息粒具有一定的动态性和不确定性.例如,集合{1,-1}和集合{x:x2-1=0∧x∈R}从集合论的角度来看完全相等,但是从信息粒的角度来看就有些不同,前者仅仅表示2个数组成了一个集合;后者带有更丰富的信息,表示一元二次方程的2个根组成一个集合.2个集合所包含的信息并不相等,也就是说,从信息粒的角度看,集合{1,-1}和集合{x:x2-1=0∧x∈R}并不完全相等.所以,所谓信息粒就是带有特定信息的集合,换句话说,信息粒=集合+信息.如果忽略信息或者不特别考虑信息,那么信息粒就是集合.
Ø和U是平凡信息粒.空集Ø是一个特殊的信息粒,它是不包含任何个体的信息粒.U是包含所有个体的信息粒,它包含U中全体个体的特质信息.
概念是与信息粒的意义最接近的一个词.每一个概念都是一个信息粒,粒计算的研究者往往把概念和信息粒混用,但信息粒与概念有一定的区别.主要区别在于:信息粒比概念意义更广,信息粒不一定能够明确表示,更不一定具有标签.例如,“好人”这个词,人们往往把它看成一个概念,但是它具有太强的不确定性,没有明显的外延和内涵,具有很强的动态性和不稳定性.如果把它当成一个信息粒,理解起来更容易些.不同的人、不同的时间、不同的空间,甚至同一个人在不同的条件下,“好人”这个词表示的意义都有可能不同,它的内涵和外延都有可能发生变化.
所有表示集合的方法都可以用来表示信息粒,包括:枚举法、谓词法、文氏图等.
理想信息系统假设:设U为论域,则关于论域U的理想信息系统为IS=P(U)(U的幂集).
理想信息系统IS=P(U)中的每个元素都是一个信息粒,P(U)包含关于论域U的所有的信息粒,这是一种理想的情况.实际的信息系统往往仅包括P(U)的部分元素.
容易得到下列关于理想信息系统的结论:
命题1理想信息系统IS=P(U)关于∪运算构成幺半群.
命题2理想信息系统IS=P(U)关于∩运算构成幺半群.
命题3理想信息系统IS=P(U)中信息粒的个数为2|U|,其中|U|表示U的势.
命题4〈P(U),∪,∩,,Ø,U〉是一个布尔代数,其中偏序关系为⊆,为补集运算.
3 信息粒之间的关系及相互表示
文献[18]从邻域角度定义了信息粒向量,粗糙集[3-4]从等价关系角度定义了粗糙集意义下的基本知识.本节将从更广泛意义上定义信息粒向量、信息粒基,并探讨它们的性质.
定义3设X1,X2∈P(U)是2个信息粒,若X1⊆X2,则称X1是X2的细化,X2是X1的粗化.
∩运算是信息粒细化操作符,∪运算是一种信息粒粗化操作符.当2个信息粒X1=X2时,可以看成信息粒特殊的细化或粗化.
定义4称〈X1,X2,…,Xk〉为信息粒向量,其中Xi∈P(U)(i=1,2,…,k).当不考虑信息粒的顺序时,信息粒向量〈X1,X2,…,Xk〉可用标量形式表示,即E={X1,X2,…,Xk}.
对信息粒向量E1,E2,若任意X∈E1都存在X′∈E2,使得X⊆X′,且对于任意X′∈E2,存在X∈E1,使得X⊆X′,则称E1是E2的细化,E2是E1的粗化.
定义5设E⊆P(U)是一个信息粒向量,X∈P(U)是一个信息粒,X被E表示分为2种情况:确定性表示和不确定性表示.
1)确定性表示:存在N⊆E,使得X=∪N.
2)不确定性表示:X关于E的上、下近似是不确定性表示,即

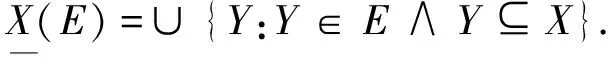
一般情况下表示的信息粒向量E相对于被表示的信息粒X∈P(U)来说比较细,所以人们习惯于用∪运算定义信息粒之间的表示关系.根据需要∩运算也可用于定义信息粒之间的表示关系.∪运算或∩运算在表示信息粒之间的关系时不需要额外的信息.例如, 在一个决策系统中,用条件属性的信息粒表示决策属性的信息粒,前者往往比后者更细,而且条件属性的信息粒之间往往通过∩运算进行细化.在表示决策属性信息粒时,无论是确定性表示还是不确定性表示都是通过∪运算实现的.
定义6设E⊆P(U)是一个信息粒向量,若E中任何信息粒都不能由信息粒向量E中其他信息粒表示,则称信息粒向量E内部独立.
注1信息粒内部表示都是∪运算下的确定性表示.
定义7称能够被信息粒向量E表示的信息粒的个数为信息粒向量的信息表示量.称信息粒向量的表示量与所有理想信息系统信息粒的量之比为信息粒向量的表示率.
信息粒向量的表示量和信息粒向量的表示率都能表示信息粒向量的表示能力.信息系统IS中信息粒的个数是信息系统中包含的信息量的一种表示.信息系统IS中包含的信息粒越多,它所包含的信息量就越大.信息系统IS的信息量第2种表示方法是信息粒向量的表示率,即IS中信息粒的个数与理想信息系统中信息粒的个数之比,
其中,|G(IS)|表示信息系统IS包含信息粒的个数.用γINF(IS)表示信息系统IS的信息量可以方便地比较不同论域信息系统中的信息量.
例1如表1所示,若
G(IS)={Ø,{x1,x2},{x3,x4},{x1,x2,x3},{x3},{x4},{x1,x2,x4},U},
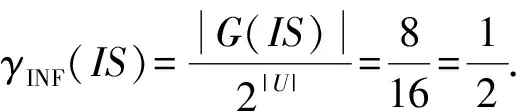

表1 信息系统IS
信息粒向量的表示量表示了信息粒向量表示的信息粒的多少,意义直观,但不方便比较不同系统中的信息粒向量的表示能力,信息粒向量的表示率刚好弥补了这个缺陷.
定义8在论域U中,称满足以下2个条件的信息粒向量E为信息粒基:
1)E内部独立;
2)∪E=U.
定义9当信息粒基满足“任何2个信息粒要么相等,要么相交为空”时,就称其为信息粒划分基.称最细的信息粒划分基为最小信息粒基.
信息粒划分基对应着一个等价关系,而信息粒基对应任意关系,所以信息粒划分基是一种特殊的信息粒基.
定理1任何信息粒基通过∩运算和运算可以转化为信息粒划分基,也可转化为最小信息粒基.
证明结果显然成立.证略.
例2如表1所示,设
={{x3,x4},{x1,x2,x3},{x1,x2,x4}}
′={{x1,x2},{x3},{x4}}.
定理1表明,在论域U上通过任意关系形成的信息粒基都可以通过∩运算和运算转化为等价关系形成的最小信息粒基.例如,邻域粗糙集中邻域关系形成的信息粒基和优势粗糙集中优势关系形成的信息粒基都可以转化为基于等价关系的最小信息粒基.由此,可得下面结论:
推论1任何粗糙集模型都可以转化为Pawlak粗糙集模型.
Pawlak粗糙集模型是粗糙集的起源,是所有粗糙集模型的出发点,根据这个推论,其他粗糙集模型都可以回归到这个出发点.
定义10信息粒基的信息粒表示能力等于相应的最小信息粒基的表示能力.
命题5在论域为U的信息系统IS中,设为最小信息粒基,则可以表示的信息粒个数等于2,信息表示率为
推论2信息粒基越细,则其表示能力越强.
例如,基因可以准确区分每一个个体,它比指纹、足印等能更好地表示和区分人,也能更好地区分人类群体.
4 结论及进一步研究
本研究定义了信息粒、信息粒向量、信息粒基等概念,提出了理想信息系统假设,给出了一种信息系统信息表示能力的计算方法,探讨了信息粒向量之间的相互表示,得出了“任何粗糙集模型都可以转化为Pawlak粗糙集”等有趣结论.
接下来可进一步对本研究方法和结论展开深入的理论及应用研究,比如:用粗糙集模型优化计算,用信息粒向量的表示率进行概念漂移探测等.
猜你喜欢
哈尔滨轴承(2022年1期)2022-05-23 13:13:18
科教导刊·电子版(2021年6期)2021-05-06 05:05:10
成都信息工程大学学报(2021年6期)2021-02-12 03:00:52
测控技术(2018年10期)2018-11-25 09:35:52
电子制作(2018年11期)2018-08-04 03:25:54
消费导刊(2017年20期)2018-01-03 06:26:40
厦门理工学院学报(2016年3期)2016-11-10 09:39:14
现代工业经济和信息化(2016年12期)2016-05-17 05:37:57
广东石油化工学院学报(2016年3期)2016-05-17 05:17:10
电源技术(2016年2期)2016-02-27 09:04:56
