
多注意力集成的图像检索
2022-12-22 11:47曾爱博陈优广
计算机工程与应用 2022年24期
曾爱博,陈优广
1.华东师范大学 计算机科学与技术学院,上海 200062
2.华东师范大学 数据科学与工程学院,上海 200062
长期以来,基于内容的图像检索(content based image retrieval,CBIR)一直是计算机视觉领域的热门研究话题。基于内容的图像检索方法通常利用特定的特征提取方法提取图像特征,进而计算特征之间的相似度并排序,从而返回与待检索图像相似度最高的多张图像作为结果。其中,图像特征是影响图像检索效果的主要因素。
在传统CBIR方法中,SIFT方法[1]及其变种[2]被广泛用于提取图像的局部特征,而VLAD[3]与Fisher Vector[4]等方法被用于进一步聚合以产生效率更高的全局特征。近年来,由于深度卷积神经网络(deep convolutional nerual network,DCNN)可以利用大量训练数据学习到更具语义信息的特征,许多利用深度特征进行检索的方法被不断提出,并展示出优于传统特征的效果,如Babenko等人[5]利用CNN中全连接层的输出作为图像特征进行检索。然而,相比于全连接层的输出,CNN中卷积层输出的特征图(feature map)保留了更丰富的空间信息并能取得更高的检索精度[6-8]。此外,相比于来自低层的特征,CNN中高层产生的特征具有更丰富的语义信息。因此,大多数基于CNN的图像检索方法利用最后一层卷积层输出的特征图生成图像特征进行检索。
进一步地,卷积层输出的特征图常需通过特定的特征聚合方法产生压缩性的图像特征以实现高效检索,如最大值池化[8]、平均值池化[6]。此外,R-MAC方法[8]先以网格化方式产生不同尺度的众多区域,并在各区域上分别进行最大值池化,进而对所有区域特征进行聚合得到最终的图像特征。R-MAC方法在区域层次上进行最大值池化并进一步聚合,使得最终图像特征之间的匹配实际上是不同区域特征之间的匹配。与以上所提的非参数化方法不同,GeM池化方法(generalized mean pooling)[9]存在可训练参数,可通过训练取得更高的检索精度。当这些可训练参数的值等于某些特殊值时,GeM池化实际上等同于最大值池化或平均值池化。因此,GeM池化是对最大值池化及平均值池化的泛化,并能取得更好的表现。受R-MAC方法启发,RGMP方法[10]先在多个区域上进行GeM池化得到区域特征,进而对区域特征进行聚合得到最终的图像特征。然而,RGMP方法通过额外的RPN网络(region proposal network)产生区域信息,需要使用带有标注框信息的数据集进行训练,影响了方法的适用性。
一些基于CNN的图像检索方法[8]使用经过了ImageNet数据集[11]预训练的CNN模型直接提取图像的特征,并被归为off-the-shelf方法。与off-the-shelf方法相比,一些方法利用目标数据集对经过了ImageNet数据集预训练的CNN模型进行进一步微调训练[9],产生更适应目标数据集的图像特征。在微调训练的过程中,损失函数是影响最终检索精度的主要因素。与早期工作使用的图像分类损失相比,排序损失(ranking loss)[9,12-14]可直接以图像检索任务为目标进行优化,能生成更适应图像检索任务的图像特征。排序损失通常利用一些训练样本构成一个集合,如二元图像组(pair)[9]、三元组(triplet)[12]、四元组(quadruplet)[13]、N元组(N-pair)[14]等,使集合内具有相同标签的图像在高维向量空间中距离相近而具有不同标签的图像之间距离较远。进一步地,最近工作[15-16]表明,在排序损失的基础上加入图像分类损失,可以有效增大图像的类间距离,使训练过程能更快收敛并取得更高的检索精度。
为进一步提高检索精度,一些工作在模型中引入了注意力机制以进行信息筛选,从而产生更具辨别性的图像特征。对于CNN最后一层卷积层输出的特征图,DELF方法[17]通过一个注意力模块产生特征图中各特征的重要性,其中该注意力模块由两个卷积核大小为1×1的卷积层以及softplus激活层组成。而ABIR方法[18]提出的注意力模块使用两个不同卷积层输出的特征图作为输入,通过特征图之间的信息融合实现信息筛选。AGeM方法[19]则通过以三个不同卷积层输出的特征图作为输入的旁路注意力模块,结合GeM池化方法产生高效高质量的图像特征。此外,衡量特征图中不同特征在特征聚合方法中的权重同样能实现对特征的信息筛选。例如,CroW[7]方法通过非参数化的权重方法衡量特征图中空间维度和通道维度上不同特征的重要性,从而突出重要特征并抑制无关特征。GeM池化方法对特征图中同一通道的不同特征赋予了同等的权重,以进行特征聚合。而wGeM方法[20]则在GeM方法的基础上,通过一个卷积核大小为3×3的卷积层及softmax层,预测不同特征的权重。然而,以上注意力机制或权重方法都是通过计算不同特征的重要性实现信息筛选,从而产生更高质量的特征,却没有考虑不同特征之间存在的联系。最近,SOLAR[21]方法将在自然语言处理及许多计算机视觉任务上表现优秀的二阶注意力模块(second-order attention,SOA)应用在图像检索中,并取得了成功。SOA模块考虑任一特征与所有特征之间的联系,并通过特征之间的信息融合产生相应位置上的新特征。然而,任一特征与所有特征都进行信息融合将导致极大的信息冗余,不利于压缩性特征的生成。此外,目标物体一般只存在于图像的某部分区域。与目标物体更相关的某些特征与所有特征进行交互时,将与许多与目标物体相关性不高的特征进行信息融合,影响了信息筛选的效果。与SOA相比,在图像分类任务中表现良好的独立自注意力模块(stand-alone self-attention,SASA)[22]只考虑任一特征与相邻的局部特征之间的联系。因此,本文将SASA应用在图像检索中,有效利用局部特征之间的联系生成更高质量的特征,从而改善以上所述问题。
除此之外,集成机制[23-24]也可以有效提升图像检索的精度。例如,ABE[23]方法在模型中引入多个结构相同的注意力模块,构成多个注意力分支,并通过连接不同分支产生的图像特征得到最终的图像特征。为使得各注意力模块聚焦于图像的不同方面以实现功能互补,ABE在排序损失的基础上引入了各分支之间的差异损失(divergence loss),从而提高检索精度。然而,ABE方法没有考虑图像分类损失对训练各注意力分支的作用。此外,ABE不能有效利用各分支特征产生最终图像特征,检索精度不够高。因此,本文提出了一个新的多注意力集成框架(multi-attention ensemble framework,MAE),有效地利用不同注意力分支产生的特征产生最终图像特征,并同时利用排序损失、各注意力分支之间的差异损失及各分支的图像分类损失对模型联合训练,以提高模型训练效果。
综合以上所述,本文的贡献主要有以下三点:
第一,本文将独立自注意力模块SASA应用于图像检索任务中,使各特征仅与相邻的局部特征进行交互,以改善利用SOA模块的图像检索方法中存在的问题。
第二,本文提出了新的多注意力集成框架MAE,在模型中集成多个注意力分支以提高检索精度。框架中的差异损失可以使各注意力分支之间实现互补,图像分类损失可以增大图像特征的类间距离,从而加快各注意力分支的训练并提升训练效果。
第三,本文通过在CARS-196[25]及CUB-200-2011[26]图像检索数据集上的大量实验验证了所提方法的有效性。
1 基于多注意力的图像检索方法
1.1 独立自注意力模块
与SOA计算任一特征与所有特征之间的联系不同,独立自注意力模块(stand-alone self-attention,SASA)[22]仅考虑任一特征与相邻局部特征之间的联系。记注意力模块的输入张量为X∈RC×H×W,其中C是通道数量。对于X的某像素特征Xi,j∈RC,定义其相邻局部特征的位置集合为Xi,j:
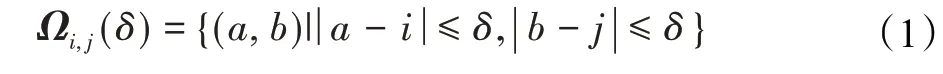
其中,δ表示相邻特征的最大空间距离。集合Ωi,j(δ)中任一元素(a,b)所对应的特征Xa,b属于与相邻的特征,SASA将考虑两者之间的联系。
对于Xi,j,本文所使用的SASA模块通过以下方式计算其与相邻的局部特征之间的联系,并得到相应的新特征:
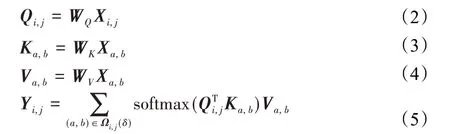
其中,WQ,WK,WV∈RC×(C/E)分别为三个全连接层的参数。WQ、WK、WV可通过调整参数E实现降维,以减少SASA的参数数量从而降低模型的收敛难度。随后,特征Yi,j通过参数为WU∈R(C/E)×C的全连接层进行升维,从而通过跳跃连接(skip-connection)的方式与输入特征Xi,j结合使训练过程更加稳定,并得到最终的输出特征Zi,j∈RC:

以上过程将在输入张量X∈RC×H×W的任一像素特征Xi,j∈RC中进行,从而得到SASA模块对应的输出Z∈RC×H×W。
1.2 多注意力集成框架
多注意力集成框架(下面简称框架)可集成多个注意力分支。受篇幅限制,图1展示了仅存在两个注意力分支的框架。框架可以选择任意CNN作为主干,如VGG[27]、ResNet[28]等。对于某输入图像I,CNN主干的对 应输出是一个三维张量X∈RC×H×W。在 框架中,CNN主干可以连接多个注意力分支。而在每一注意力分支中,X将分别输入各自的SASA模块进行信息筛选,结果记为Zt∈RC×H×W,其中t是分支序号。随后,GeM池化方法将用于对Zt实现特征压缩,产生向量Ft∈RC。对于Zt的第c个通道Ztc∈RH×W,对应的GeM池化结果Ftc为:
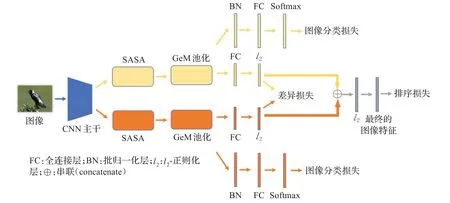
图1 多注意力集成框架Fig.1 Multi-attention ensemble framework

其中,当pc=1时,GeM池化相当于平均池化;当pc→∞时,GeM池化相当于最大值池化。此外,pc可以通过人工设置或通过训练学习,而在本框架中pc将被设置为3。
进一步地,各分支产生的图像特征Ft通过一个全连接层及l2-正则化层进行降维得到向量:

其中,Wt与bt分别是第t个分支中用于降维的全连接层的权重与偏置值。最后,各分支降维后的特征Φt通过串联及l2-正则化层得到最终的图像特征:
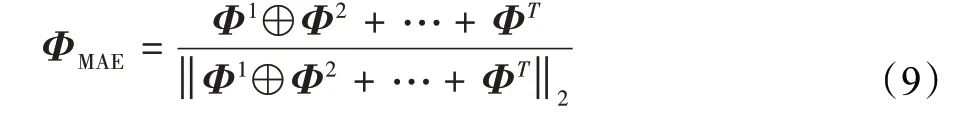
T是注意力分支的数量,⊕表示特征之间的串联(concatenate)。在检索阶段,ΦMAE将用于表示图像并通过向量内积计算图像之间的余弦相似度。在训练阶段,ΦMAE可灵活地使用任意排序损失函数进行训练。在本文的实验部分,框架采用精度高且易于实现的batchhard triplet loss[29]作为排序损失函数,相应的损失记为Lrank。
为了使各注意力分支聚焦图像的不同方面,增大不同分支产生的图像特征之间的差异以实现互补,各分支产生的图像特征利用ABE提出的差异损失[23]Ldiv进行训练:
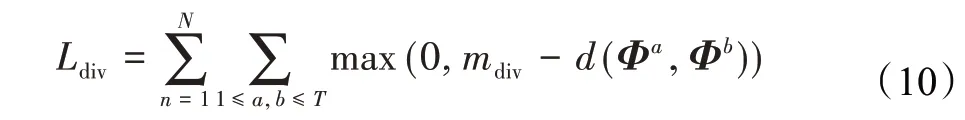
其中,N是训练集样本数量,mdiv是控制损失的超参数,d是余弦相似度函数。通过增大不同分支图像特征之间的距离,差异损失可以有效促进不同注意力分支之间的多样化,从而提高检索精度。
进一步地,受CGD方法[16]所启发,框架将对各分支进行图像分类训练,从而增大各分支图像特征的类间距离,加快训练速度并提高训练效果。与CGD方法中仅有一个分支进行图像分类训练不同,本框架中各分支都将参与图像分类训练。各分支图像特征Ft分别经过一个批归一化层及权重为Wctlass且偏置值为btclass的全连接层,得到一个维度为目标数据集样本类别M的向量Ψt:

随后,各分支Ψt分别输入Softmax层并计算交叉熵损失(cross-entropy loss)作为相应分支的图像分类损失。在这一阶段,框架使用temperature scaling[30]及标签平滑(label smoothing)[31]技术,有效减少类内距离并增大类间距离:
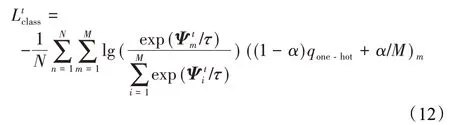
temperature scaling的相关参数τ用于对Softmax层的输入进行放缩。qone-hot是样本真实标签的独热编码,标签平滑的超参数α用于qone-hot进行平滑,生成分布更加平滑的样本训练标签。
综合考虑最终图像特征的排序损失、各分支间的差异损失及各分支的分类损失,框架的总损失函数为:
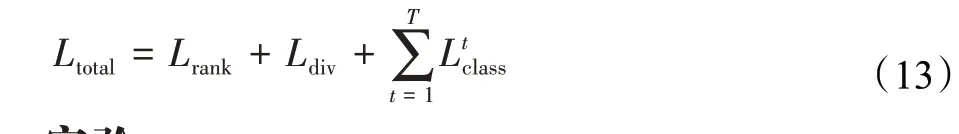
2 实验
2.1 数据集与评价指标
通过图像检索数据集CUB200-2011[26]及CARS196[25]验证了所提方法的有效性。其中CUB200-2011数据集的图像都是关于鸟的图像而CARS196的图像都是关于车的图像。各数据集中训练集与测试集的划分与其他工作相一致[16],如表1所示,其中各数据集的训练集与测试集之间不存在相同类别。此外,本文仅在原始图像上进行实验,不使用CUB200-2011及CARS196数据集提供的标注框信息对图像进行裁剪。为了与其他工作进行比较,本文使用Recall@K指标对图像检索精度进行评估。
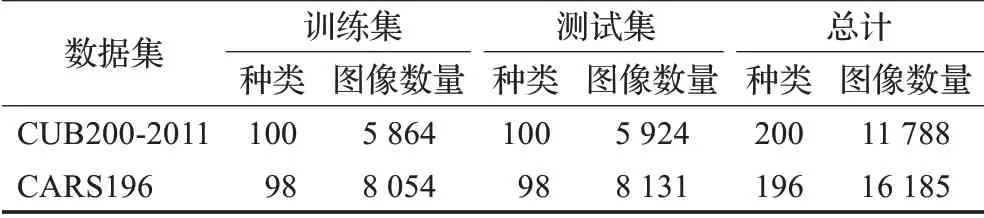
表1 各数据集的训练集与测试集划分Table 1 Train-test split on each dataset
2.2 实现
所有实验通过Pytorch实现并在NVIDIA TITANRTX GPU上运行。本文选择ResNet50[28]作为所提框架的CNN主干,其中ResNet50使用已通过ImageNet数据集进行预训练的模型进行参数初始化。在训练阶段,输入图像首先被调整为252×252大小并随机裁剪为224×224,最后进行随机水平翻转。在测试阶段,输入图像仅被调整为224×224大小。为了使ResNet50产生的特征图能保存更多信息,本文移除了ResNet50中Conv_3模块的下采样操作[16],使224×224大小的输入图像由CNN主干输出的特征图为14×14大小。Adam方法[32]用于对模型进行优化,其中每批数据包含128张图像,初始学习率为0.000 1。在各数据集上完成第12、24轮训练后学习率分别衰减10倍。框架的总损失函数中,排序损失(batch-hard triplet loss[29])的margin参数为0.1,差异损失的mdiv为1,各注意力分支的图像分类损失中的τ与α都分别设置为0.5与0.1。在所有实验中,最终用于检索的图像特征都是512维向量,而各分支产生的图像特征是512/T维向量,其中T是注意力分支数量。
2.3 消融实验
2.3.1 独立自注意力模块
为验证SASA模块的效果,与SOA模块在CUB200-2011数据集上进行对比,并将不使用任何注意力模块的模型作为基准。其中,参数E是SASA模块对输入特征进行降维的倍数,E越大,SASA模块的参数数量越少。SASA模块的δ值设置为1。除注意力模块外,其他设置都保持一致。此外,为避免框架中分支数量T的影响,本部分实验中分支数量T设置为1。
如表2所示,SASA模块在E=2时取得了最高的检索精度。与不使用任何注意力模块及使用SOA模块作为框架中的注意力模块相比,SASA模块能取得更高的检索精度,说明了SASA模块在图像检索任务中的有效性。
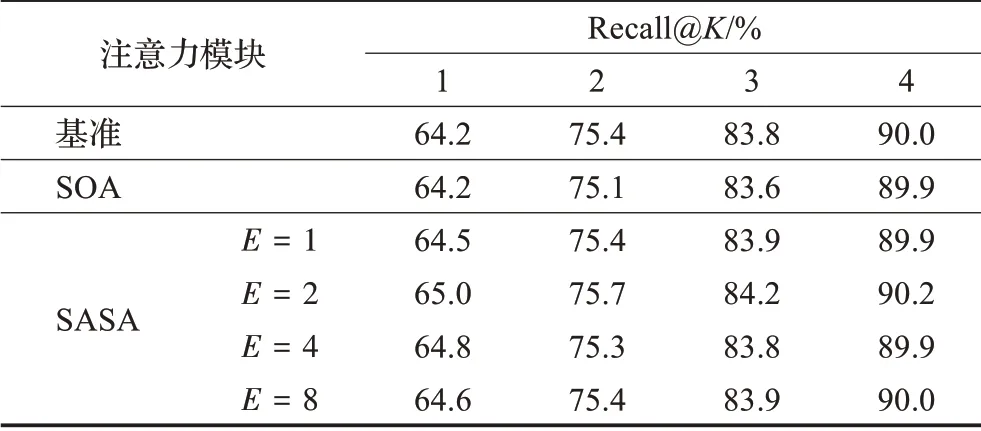
表2 CUB200-2011数据集上不同注意力设置的精度Table 2 Performance of attention with different configurations on CUB200-2011
本文进一步探索了SASA模块中不同δ值对检索精度的影响。同样地,分支数量T设置为1以避免分支数量的影响,E设置为2以取得最高的精度。图2展示了在CUB200-2011数据集上不同δ值对Recall@1精度的影响,其中SASA模块在δ值为1时达到了最高的Recall@1精度,这与δ=4的SASA模块能在图像分类任务中取得最高精度[22]有所不同。
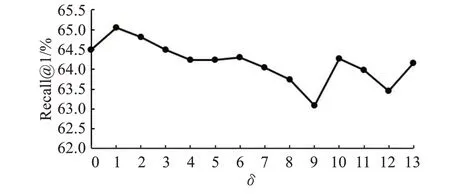
图2 CUB200-2011数据集上不同δ值的Recall@1结果Fig.2 Recall@1 on CUB200-2011 with different value of δ
2.3.2 多注意力集成框架
多注意力集成框架利用最终图像特征的排序损失、各分支之间的差异损失及各分支的图像分类损失对模型进行联合训练。为验证所提框架的有效性,本文在CUB200-2011数据集上对不同损失函数的组合进行探索,其中SASA模块中δ=1而G=2,结果如表3所示。为排除SASA模块的特殊性对损失函数效果的影响,本文进一步将SOA作为框架的注意力模块对不同损失函数的效果进行探索。
表3显示,当使用SOA模块作为框架的注意力模块时,相比于仅使用排序损失,在排序损失上加入差异损失仅提升了0.1%的Recall@1精度。而当使用SASA时,Recall@1精度反而有所降低。其次,无论是使用SOA还是SASA作为框架的注意力模块,仅在排序损失上加入各注意力分支的图像分类损失,各分支不能形成良好的互补,因此同样不能取得最高的检索精度。而本文框架使用差异损失促进各注意力分支间的互补,同时使用各分支的图像分类损失以更有效地训练各注意力分支。在使用SOA作为注意力模块时取得了最高的Recall@1精度65.0%,而在使用SASA时也达到了最高的Recall@1精度65.8%。这说明了框架所用的总损失函数的有效性。
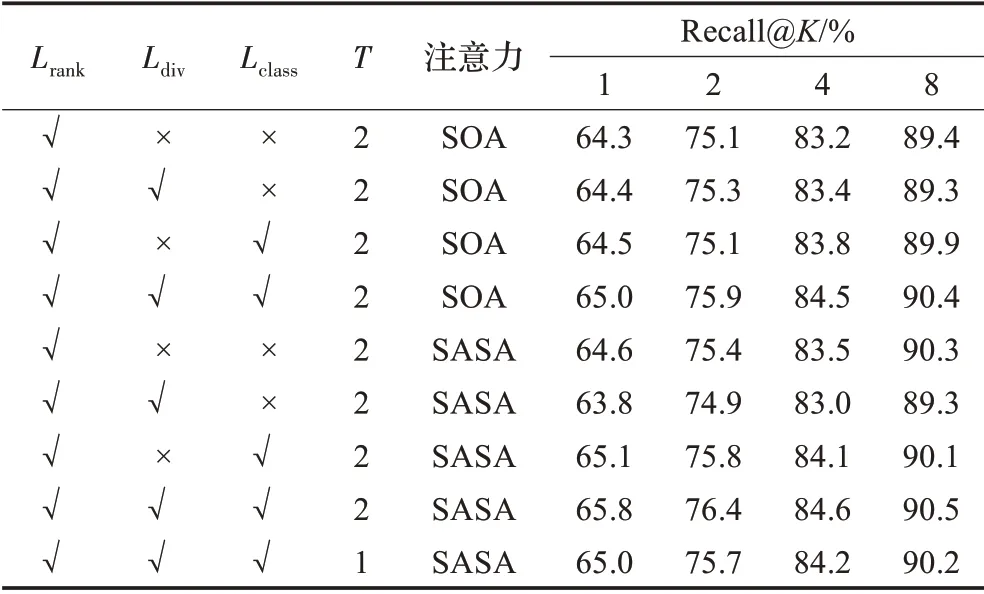
表3 CUB200-2011上不同多注意力框架设置的精度Table 3 Performance of MSE with different settings on CUB200-2011
当使用本文框架的总损失函数对模型进行训练时,与使用SOA作为框架的注意力模块相比,使用SASA作为注意力模块在Recall@1精度上提升了0.8%。这表明框架所用的注意力模块极大地影响了模型的检索精度,同时进一步表明本文所提框架使用SASA作为注意力模块的有效性。此外,当使用SASA作为框架的注意力模块时,注意力分支数量T=2的模型取得了比T=1的模型更高的检索精度,说明本文所提框架可以有效集成多注意力分支以取得更好的检索效果。
2.4 对比实验
最后,本文在CUB200-2011及CARS196数据集上将所提方法与目前表现较好的图像检索方法进行比较,结果如表4、表5所示。
为了公平比较,所有方法用于检索的图像特征都是512维。其中,本文方法的结果采用δ=1,G=2,T=2的结果。特别地,CGD的相关工作[16]利用标注框信息对CUB200-2011及CARS196原始图像进行裁剪并实验。为了公平地比较,本文谨慎地对CGD方法进行复现,并在两数据集的原始图像上进行实验得到该方法的检索精度,其中CNN主干为ResNet50,其余设置使用相关工作[16]中的最优设置。除CGD方法外,其他方法采用相关工作中展示的检索精度[23-24,33-35]。如表4、表5所示,本文方法在CUB200-2011及CARS196两数据集上的检索精度都远高于其他方法,充分说明了本文方法的有效性。
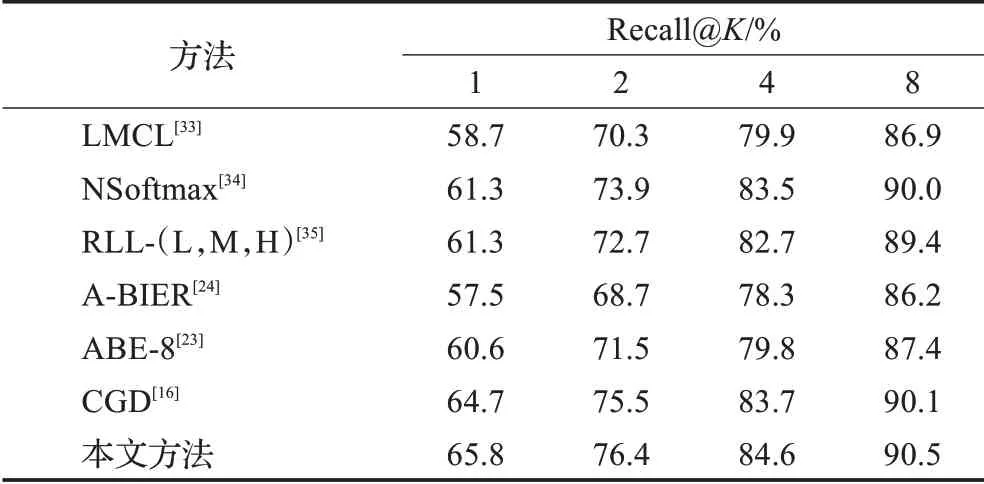
表4 本文方法与其他方法在CUB200-2011数据集上的精度Table 4 Performance of proposed method and others on CUB200-2011
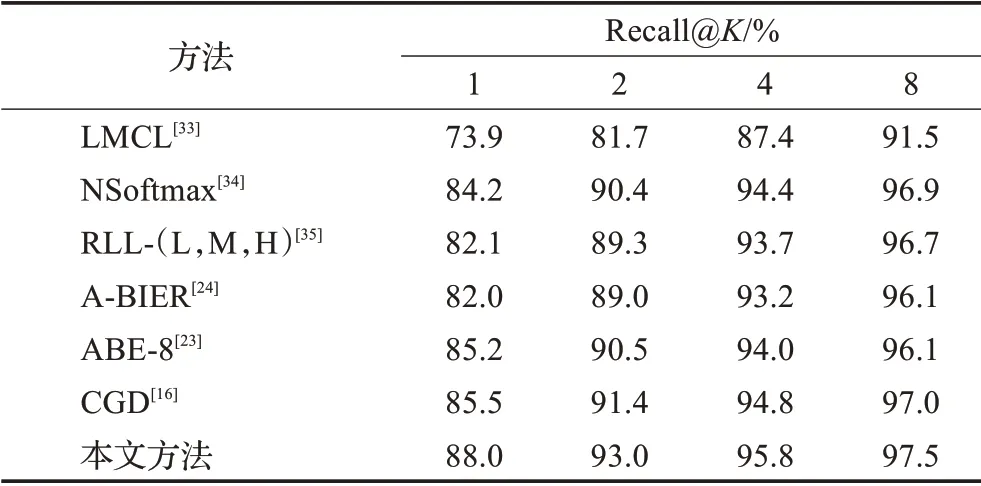
表5 本文方法与其他方法在CARS196数据集上的精度Table 5 Performance of proposed method and others on CARS196
3 结束语
在图像检索任务中表现良好的二阶注意力模块考虑任一特征与所有特征之间的联系,进而产生新特征,但新特征中存在大量冗余信息。针对该问题,本文将独立自注意力模块应用于图像检索任务,对任一特征仅考虑与相邻特征之间的联系,从而改善上述问题。此外,针对目前图像检索的集成方法中存在的不足,本文提出了多注意力集成框架。框架中各注意力分支分别使用独立自注意力模块产生高质量图像特征,并通过有效结合产生最终的图像特征。特别地,多注意力集成框架在最终图像特征的排序损失的基础上,加入各分支特征之间的差异损失使得各注意力分支产生的图像特征多样化,并在各注意力分支中加入图像分类损失使得各分支训练更高效而稳定,从而更充分地训练模型。在CUB200-2011及CARS196上的大量实验表明,本文方法可以有效提高检索精度。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机系统应用(2021年10期)2022-01-06
甘肃教育(2020年22期)2020-04-13
科学与财富(2019年27期)2019-10-25
学生天地(2019年28期)2019-08-25
电子制作(2019年14期)2019-08-20
专利代理(2017年1期)2017-07-21
第二课堂(课外活动版)(2016年2期)2016-10-21
疯狂英语·口语版(2013年1期)2013-01-31
