
格式化约束的时间戳文字识别网络
2022-12-22 11:46刘洋,陈黎
计算机工程与应用 2022年24期
刘 洋,陈 黎
1.武汉科技大学 计算机科学与技术学院,武汉 430065
2.武汉科技大学 智能信息处理与实时工业系统湖北省重点实验室,武汉 430065
文字识别算法如今已在各行各业得到了广泛的应用,例如书籍扫描[1]、车牌违章处理、自动驾驶识别道路标牌、文本拍照翻译。伴随着深度学习的发展,涌现出了许多先进的识别方法以抵抗复杂多变的文字图像,而为了识别结果更加精准,一些研究选择在特定领域上对算法进行专门优化。如何在时间戳文本识别这一应用方向上对主流文本识别网络进行改进,是本文的主要研究方向。
早期的文字识别算法把识别过程分为检测字符和识别字符两个阶段,Niblack[2]和Smith[3]等人提出使用二值化预处理和启发式的分割方案分割独立字符后,使用分类器进分类,接着使用集束搜索[3]这类优化算法重组字符序列,进而得到概率最高的文本序列。Bissacco[4]和Wang[5]等人则是在检测字符阶段进行改进,提出使用深度学习算法预测独立字符的分割区域,提高了文字分割的鲁棒性。但是早期的这些识别方法把字符当作独立的对象,字符间的信息无法得到很好的传播,导致算法对全局信息的感知能力不强。为了解决这一问题,Jaderberg[6]提出把文字识别看作一个大规模的分类问题,为所有的目标文本预定义词典库作为分类标签,一个标签即对应一段文本,对文本图像整体进行分类,并直接输出该类别的对应的文本。而Almazán[7]和Gordo[8-9]等人采取的方式同样是预定义词典库,不过他们将图像和单词文本通过深度学习网络,嵌入到同一个向量空间[10]中,通过高维空间的向量表达建立图像特征和文本特征之间的关联,向量距离最近的文本对象就是识别结果。此种方法不用分割独立的字符,各个字符之间不再是独立的孤岛,对图片整体进行卷积操作,提高了对图像全局信息的感知能力,然而预定义的文本标签数量是有限的,这导致算法不能识别新词和适应组合排列复杂的语言。
为了解决预定义词典对识别结果存在局限的问题,适应多变的语法和字符组合,Shi[11]和He[12]等人基于循环神经网络RNN提出CRNN网络(CNN+RNN),用CNN提取图像特征,接着使用RNN编解码得到字符序列,最后通过Connectionist Temporal Classication函数[13]计算字符分类的损失,解决了图像文字和文本标签的对齐问题。Lee等人[14]提出基于注意力机制的序列到序列(seq2seq)模型,把图像特征编码为一个全局上下文向量,用这个上下文向量作为RNN的初始状态,逐序列解码输出目标文本,直到输出终结符号。上述方法很好地结合了CNN的图像特征提取能力,以及RNN的序列数据处理能力,十分适合文本识别任务,是目前文本识别的主流选择。在这些工作的基础上,Li[15]和Shi[16]等人针对扭曲文字样本,训练变换网络对图像文本进行矫正,降低识别阶段的难度。这些研究的目标主要集中在光学信息的处理上,但是当输入图像存在模糊、光照干扰等情况时,光学信息被污染,网络的性能就会大打折扣。解决方法之一就是把文本的排列模式和语言规范考虑在内,通过类似自然语言处理任务的方法去感知图像当中的文本内容。
为了进一步挖掘文本图像当中的潜力,仅依赖图像当中光学特征是远远不够的,网络可以借助额外的信息进行学习,例如字符的序列组合所蕴含的语义信息,人类可以通过这些语义信息去猜测被遮挡的字符是什么,那么机器也可以通过类似的方法去解决文字模糊不清晰、字符缺省等问题。原而本文所研究的时间戳文本就具有严格格式规范,这种强相关的模板规范将会更加易于网络去学习。如何融入时间戳的结构化信息对识别结果进行约束修正,是本文要研究的关键问题。在这方面,Qiao等人[17]曾提出使用网络预测图像的语义信息,指导解码模块解码文字,提高模糊图像文本的识别准确度。受到上述研究的启发,本文通过深入研究时间戳的文本特点,提出一种时间戳格式化约束识别网络(time‐stamp formated constrained CRNN,TFC-CRNN),设计专门的一个约束信息预测分支网络,分析图像中的时间戳约束向量,文字解码模块将协同约束信息,学习输出规范化的时间戳文本,解决在光线干扰、背景混淆等情况下,时间戳文本识别精度不高、不符合格式规范的问题。
1 相关工作
1.1 经典的文本识别算法
经典的文字识别方法均采用RNN循环神经网络处理序列数据,并且通过隐藏层的状态捕捉全局信息,非常适合处理文本这类数据。其又分为CRNN和序列到序列(seq2seq)两种模型范式,前者用卷积层CNN提取得到图像的特征图之后,把特征图用作序列进行编解码,输出字符序列后通过CTC函数[13]计算损失代价,CRNN解决了文字序列标签和预测输出序列之前不对齐的问题,使得文字识别算法可以进行端到端的识别,虽然CRNN的文字字符长度可以动态变化,但是最大长度限定在RNN层的输出长度之内,而这个长度和图像的宽度是成正比例的。关于序列到序列模型,把图像特征通过RNN编码成一个紧凑的上下文向量,然后以该向量作为解码层RNN的初始状态,循环解码字符,直到输出终结符号,其文本长度和终结符号的输出位置相关,和CRNN不一样,序列到序列模型的输出文本长度只和终结符号的输出位置有关,因此理论上可以输出无限长的预测序列。不过考虑到时间戳文本的格式固定,长度为18个字符(年、月、日、时、分、秒,以及4个分隔符号),因此本文采用CRNN网络,其优点是能够通过图像宽度对输出序列的长度进行控制。
1.2 多任务信息约束
通过多任务训练目标提升网络的泛化能力是一个有效的优化策略,这需要在主要的训练任务基础上加入一个额外的训练目标,配合主网络,缓解模型的过拟合现象,提高网络的泛化能力,同时也是通过额外的学习目标,提升对图像内容的利用效率。前文提到过的通过卷积网络将图像内容直接映射到语义信息的高维向量空间中[7-9,18],实现了从图像提取上下文信息的功能,其中Patel等人[19]利用社交平台上图像的标签文本训练预测话题的LDA[20]模型,然后对图像数据用卷积网络学习输出这些话题概率分布,让模型能够预测图像的话题,Kang等人[21]进一步将话题的向量表达嵌入到文本检测、文本识别模型中,指导模型输出更加符合图像环境的目标结果,这表明可以让网络学习直接从图像当中获取文本的语义信息,进而提高下游任务的语义敏感度。这些研究涉及的研究对象是全图背景信息,而Qiao等人[17]提出的SEED模型则是在局部区域的文本图像任务上进行优化,设计了词向量预测分支,使用预训练的词向量嵌入模型[22]监督卷积网络预测文本图像的词向量,实现了从图像到词向量的转换。其中的SEED模型将这些词向量输入到文字识别模型ASTER[16]的文字解码模块中,指导模型在低质量文字不清晰的图片上,通过词向量信息补足光学信息缺失的问题,解决模糊、光照不足等问题下文字难以识别的问题。以上研究通过图像中的文字语义预测任务,来提高文本检测和文本识别阶段的模型性能。
在上述研究的启发下,通过分析时间戳文本的特点,本文提出一种约束信息提取模型,从图像信息抽取其中的文本约束向量,结合传统的CRNN网络,解决监控画面中,因为光线干扰、背景复杂、文字半透明模糊不清等原因导致的识别错误问题,并且指导文字解码模块输出更加符合时间戳格式规范的文本结果。这种优化后的模型框架和SEED模型最为接近,区别在于,SEED的研究目标是自然语言文本,需要预训练得到的词向量嵌入模型作为语义信息提取模块,来辅助文本识别模型训练,而本文则是通过时间戳文本的格式特点,利用文本当中的数字字符,简化语义信息特征提取模块,将其转换为一个简洁可控的解析函数,无需大量的参数训练就可以达到提取文本语义信息的功能。
2 时间戳格式约束设计
本文的模型以CRNN[5]网络为基础,针对时间戳文本目标,增加了时间戳约束信息提取模块,并将其融入循环神经网络当中,配合RNN解码模块,约束文字解码输出。
2.1 时间戳的约束信息提取
约束信息学习有两个问题需要解决,一是约束信息的监督标签如何设计,二是使用怎样的预测模型。对于问题一,在传统的自然语言文本上,普遍的方法是采用大量的文本语料训练词向量嵌入模型,使其能够将文本单词对应的one-hot离散向量映射为紧凑连续的高维特征向量,其公式如下:

其中,S表示一个单词字符串,比如“hello”,OneHot函数首先会把这个字符串映射为独一无二的one-hot向量,接着使用We所表示的矩阵乘法,将one-hot向量转换为紧凑的F向量表示。这种嵌入模型需要大量的语料数据去优化学习映射函数We内部的权重,并使得相近语义的文本通过映射之后,也能够得到距离接近的特征向量表示。然而考虑时间戳文本格式固定,具有严谨的结构化特征,本身非常容易解析成连续数值的表示形式,因此,本文利用时间戳文本的这一特点,设计了一个简洁的特征提取函数:
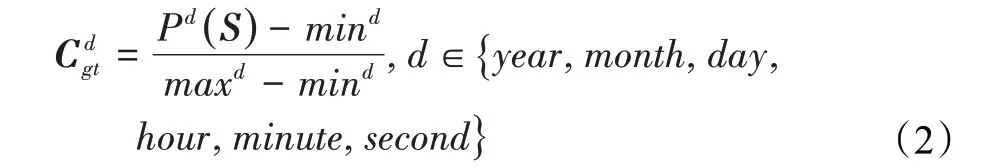
其中,d用于区分时间戳信息中的年、月、日、时、分、秒6个部分,Pd是一个对应时间信息的字符串解析函数,例如Pyear表示将S当中的年份数字提取出来并转换为整数,而mind、maxd表示时间d部分的最小值和最大值(年份取2000—2030),最终特征向量Cgt为这6个归一化数字组成的一维向量。本文将其称作约束向量,一方面是因为其表示范围总是约束在合理的数字范围内,对应0~1的归一化表示范围,另一方面是因为该向量将会被用于解码模块,去约束网络的输出字符概率,让其尽量符合时间戳的格式要求。通过这种方法,利用时间戳文本这一特定领域中的额外文本格式要求,省略词向量嵌入模型训练流程,快速地完成文本语义的向量化映射。
对于问题二,如何设计约束信息预测模型。可以参考常见的图像分类模型,通过在CRNN网络当中的特征提取层之后,串联多层全连接网络,把高维图像特征转换为预测约束向量,其计算公式如下:
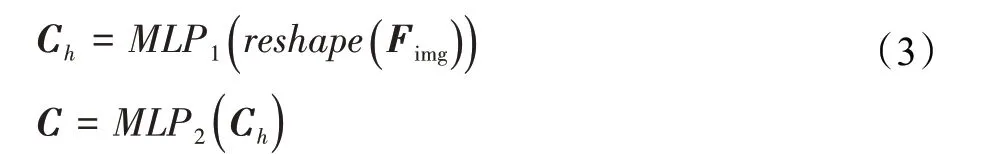
其中,Fimg表示图像特征,reshape把图像特征拉平为一维特征,送入MLP表示的多层感知网络,在MLP1和MLP2的中间,把临时向量Ch用作高维的约束向量表达,它将被用来作为循环神经网络的初始化状态,在解码层中进行约束解码输出的功能,并且由于解码模块的循环神经网络是一个双向LSTM网络,包含前向和后向两个方向的LSTM,因此Ch会被分成两个子向量分给初始化两个方向的LSTM。最后MLP2输出的向量C即最终预测得到的长度为6的约束向量,将其和约束向量Cgt通过均方差损失函数进行线性拟合,监督分支预测模块学习时间戳图像中表达的约束信息。
关于约束向量的选择,一个改进的方案是在训练阶段利用已知的约束向量标签Cgt,通过额外一层线性变换MLP3,把约束向量转换到高维表达,然后作为双向LSTM的初始化状态,而在推理阶段,则使用预测得到C通过MLP3转换得到LSTM的初始状态,这种方案的好处就是训练阶段的约束信息来自真实可靠的标签,理应能够改善训练阶段的约束效果,然而根据SEED[17]文章当中的说明,如果采用训练标签Cgt作为LSTM的初始状态来源,效果要差于当场预测得到的C作为LSTM的初始状态。可能的原因是因为Cgt作为时间戳文本的唯一对应,仍然存在一定的离散性,而实时预测得到的C虽然数值并不一定精确,但是拥有更加丰富的语义表达,更适合作为语义信息对解码模块进行指导。
2.2 时间戳的语义信息提取
本文所用到的网络结构TFC-CRNN如图1所示,它是在CRNN网络的基础上改进而来,原本的CRNN网络,首先是将原本CRNN网络中的两层双向LSTM缩减为单层双向LSTM模块,在图像特征提取模块后面添加了约束信息预测模块,二信息约束模块计算得到的中间向量Ch作均等拆分为两个向量,作为双向LSTM模块的前后两个方向的起始状态,如图1所示。
“回首向来萧瑟处,也有风雨也有晴”。改革开放40年是中国制造业从低端走向中高端的关键发展阶段,在这个伟大的历史变革过程中,我们的制造业通过大浪淘沙涌现了一批有影响力的优秀企业。正是他们的坚守、成就与贡献,推动了行业转型升级,引领了行业发展方向,从而真正促进了中国制造业大踏步从高速度增长向高质量发展迈进。
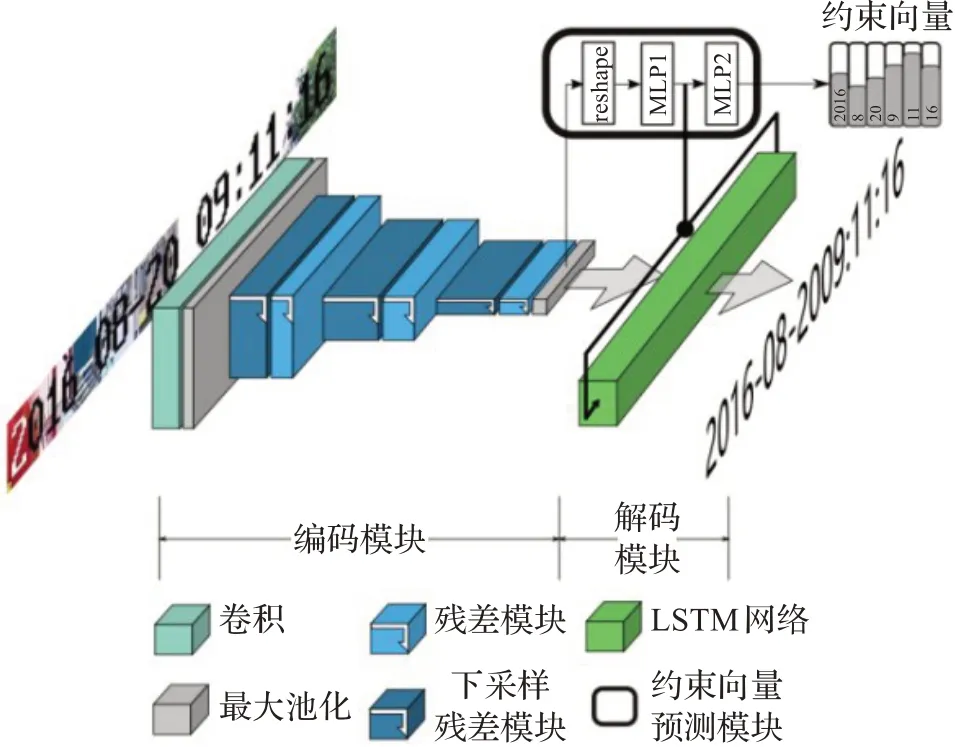
图1 TFC-CRNN模型结构Fig.1 TFC-CRNN framework
在这个框架中,数据的计算流程如下:首先图片需要被预处理为512×32的分辨率,送入特征提取模块,使用多层残差网络提取特征,使用残差网络能够在提取高维图像特征的同时,尽可能保留低维的图像细节信息,在特征提取的最后一个阶段,使用最大化池层将高度方向的特征维度下采样到1,得到编码后的图像特征,维度为64×256,其中宽度64对应解码输出的64个字符,256是每一个字符的特征维度。这里的图像特征将会分别送入约束信息提取模块和文字解码模块,约束信息提取过程中的中间向量C被用来作为解码模块中循环神经网络初始状态向量,起到约束解码的作用。解码模块得到的64个字符概率最后通过CTC损失函数计算损失,而约束模块提取得到的C则与时间戳文字标签对应的约束向量Cgt计算均方差损失。可以看到解码模块只需要MLP1输出的Ch向量,因此在推理阶段,约束信息提取模块的MLP2网络可以被裁剪掉,减少不必要的算力消耗,提高算法的运行速度。
2.3 评价时间戳文本规范性
常见的文本识别测试指标包括全匹配率(ACC)和编辑距离(ED)两个指标,前者检查预测字符串是否完全和目标字符串一致(越大越好),测量所有样本中预测文本和目标文本完全一致的样本比例;后者通过编辑距离衡量预测结果和目标文本的字符级别差异(越小越好),数值越小表示两端文本越相似。考虑到时间戳文本具有格式固定的特点,本文额外提出一种模板编辑距离EDT,用以衡量文本的格式规范程度,在模板编辑距离下,数字字符允许存在误差,衡量的主要标准是数字字符和其他分隔符号的排列模式是否符合目标模板的规定,要求字符串尽可能接近预期的字符串模板。其计算公式如下:
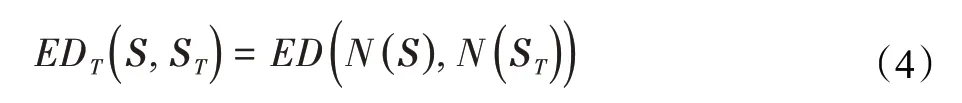
其中,S是被测试的文本,ST是预期的目标模板(例如”2000-01-0100:00:00”),ED代表标准的编辑距离计算函数,而函数N负责对字符串归一化,具体操作就是把字符串当中的数字字符替换为通配符“d”,保留其他非数字符号不变(例如日期分隔符“-”),通过这样的归一化,使得标准编辑函数能够忽略数字的识别精度要求,只考虑字符类型的排列顺序是否符合模板,从而衡量预测文本的模板规范程度。
举例来说,如果将“2019-02-2214:45:12”作为预测文本S,“2020-02-2214:45:12”作为目标模板ST,预测文本和目标模板的差异只在于年份数字不同,在标准编辑距离ED的计算中,年份“2019”转换为“2020”最少需要两步替换字符的操作,因此标准编辑距离结果为2。而模板编辑距离则是将这两个字符串转换为“dddd-dddddd:dd:dd”和“dddd-dd-dddd:dd:dd”之后,再计算标准编辑距离,这种情况下忽略了数字字符的准确性,那么此时的最小编辑步数就可以视作字符串的格式规范指标,数值越小,说明字符串的格式越接近。可以看出来上述的两个字符串格式完全一致,而对应的模板编辑距离计算结果也为0,符合预期的效果。本文通过这种指标计算方法,衡量时间戳识别结果的规范性,数值越小,表明识别出来的文本格式越符合格式规范。本文通过EDT来对比信息约束模块对输出文本模板的约束效果。
3 实验
3.1 数据集
3.1.1 真实数据集,测试集
本实验的测试集来自真实监控摄像头截取的监控画面图像,通过人工裁剪得到只包含时间戳文本的部分,得到总计19 700张样本,按照采样的地点和时间段把这些测试数据分为四个数据集,样张展示可参考表1,这四个数据集的详细特点说明如下:

表1 四种数据集下的样张对比(仅展示年月日)Table 1 Samples on four dataset(only show year/month/day)
NM1数据集:2 000张日间采样样本,文字颜色为不透明的黑白混色,即一行文字中,有的字是黑色,有的是白色,文字字体单一,图像分辨率高,字体清晰,识别难度不大。
NM2数据集:3 500张日间采样样本,黑白混色不透明文字,采样地点不同于A集,由于文字字体单一且清晰规范,分辨率高,文字颜色和背景的区分度高,识别难度最低。
TP2数据集:8 200张夜间采样样本,采样地点同TP1数据集,但是采样的时间改在夜间,夜间背景中的光线干扰较少,时间戳文字更加明显,能够降低识别难度。通过TP1和TP2的对比可以观察背景颜色对文字识别的影响程度。
3.1.2 训练数据集
时间戳图像由监控设备向背景图片上叠加文字生成,可以通过计算机模拟生成,得到大量的时间戳图像样本。实验过程中通过截取真实监控画面的无字区域然后叠加随机的时间戳文字,生成48 000张样本,全部用作训练集。真实时间戳图片的分辨率接近1 024×64,因此模拟程序也以该分辨率从真实的监控画面中截取背景图像,每一张时间戳图片内文字的字体和透明度一致,字体从10种不同的字体随机选取,50%的样本透明度设为1,即不透明文字,其余的50%样本中,透明度的alpha通道值取0.7~0.9之间的随机值,这些半透明样本作为困难样本,主要是为了训练模型应对文字背景混淆、光线干扰等问题。
3.2 实验细节
训练阶段,batch size为64,学习率为1E-3,每10个epoch学习率以0.1的比例衰减,共训练128个epoch。测试阶段,真实时间戳图片的分辨率尺寸各不相同,在输入网络前需要统一缩放到512×32,然而一部分时间戳文字字体太窄,强制在宽度方向上拉伸,会使得这类文字变形严重,拉低识别正确率。因此需要针对此类窄样本,限定拉伸比例,防止拉伸程度过大导致文字失真。通过实验结果的对比发现,当图片的宽高比小于25∶2时,将其拉伸到400×32是一个比较合理的选择,同时向右侧剩余的112像素宽度部分填充灰色,最终把图像填充到512×32,填充灰色是为了避免与时间戳文字的黑白颜色的文字产生混淆,导致文字在真实图像内容和填充的边缘位置误识别成文字字符。此外,这里缩放图片的操作并没有采用等比缩放,而是强制缩放的原因,一方面是因为512×32恰好能够容纳下正常比例的18个字符,强制缩放到这一尺寸之后反而会使得不同字体的文字比例趋近于统一,有利于文字识别;另一个方面的原因则是,CRNN解码字符的序列长度和图片宽度正相关这一特点,对于一些比较紧凑的窄文字样本,强制在宽度方向拉长(拉伸不易过多),可以保证宽度上各个字符之间的像素距离足够远,为解码模块预测有效字符之间的分隔符提供充足的判别空间,避免文字太窄挤到一起导致序列解码模块无法区分独立字符的问题。
3.3 实验效果评估
训练损失函数对比,图2中展示的CRNN网络和TFC-CRNN网络的loss下降曲线,注意为了公平对比,这里只考虑CTC loss部分,TFC-CRNN的信息约束模块的loss并没有考虑在内。
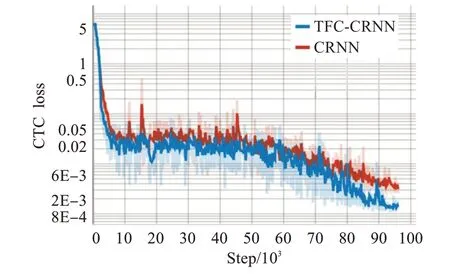
图2 CTC损失下降对比Fig.2 CTC loss descend compare
图2 中可以看到,TFC-CRNN的CTC loss曲线相比CRNN要更低一些,说明信息约束模块所提供的约束向量Ch有效辅助了解码模块的字符序列输出。为了验证这并非是过拟合,在对应每一个epoch之后,测试两种模型在NM1数据集下的完全匹配率,可以得到如图3的测试集曲线。
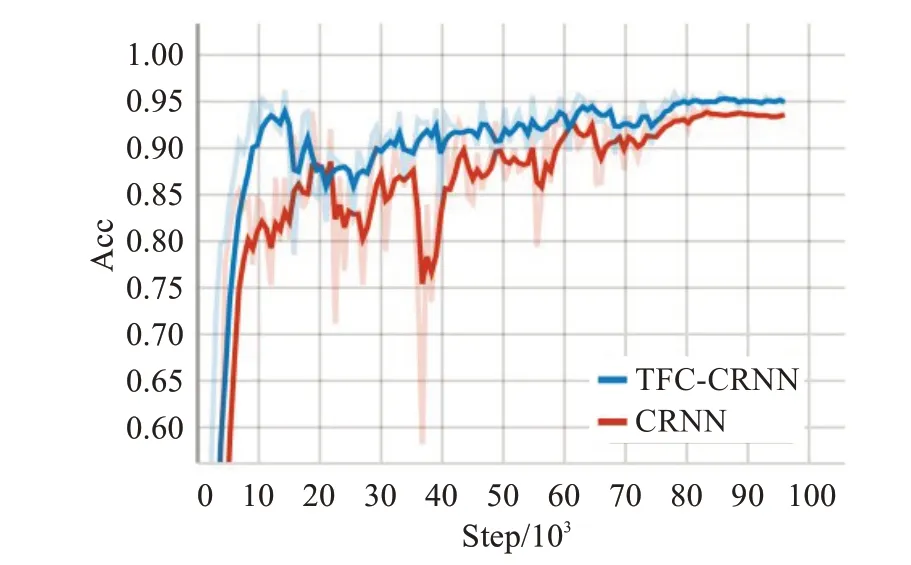
图3 NM1测试集下的完全匹配率变化曲线Fig.3 Exact match rate curve in NM1 dataset
图3 中可以看到,TFC-CRNN相比CRNN更快达到最高点,然后在后续的训练过程中依然保持了对CRNN的优势。除此之外,表2中对比了近年来三种文字识别算法、CRNN算法以及本文提出的算法在NM1、NM2、TP1、TP2四个数据集上的性能表现。
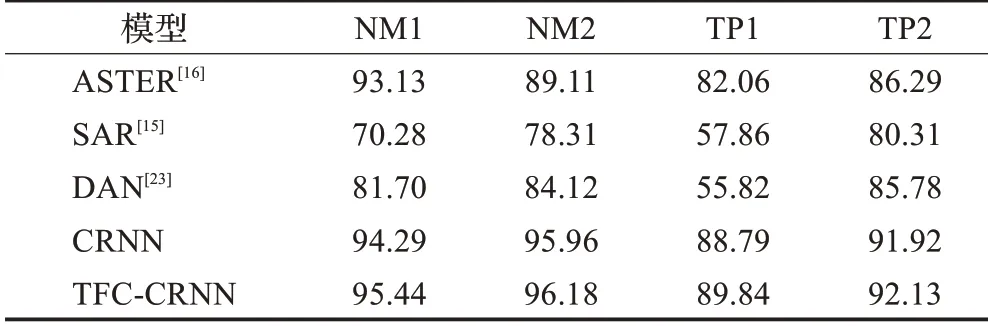
表2 不同模型的完全匹配率Table 2 Exact match rate of different model单位:%
表2中展示了不同测试数据集下的完全匹配率。前三行是以往主流的文本识别算法,第四行是CRNN网络框架下的文字识别算法,第五行的TFC-CRNN是在CRNN的基础上增加信息约束模块之后的效果,可以看出,TFC-CRNN在完全匹配率标准下超过上述所有文本识别模型。其中TFC-CRNN在CRNN的基础上,使得完全匹配率产生0.21~1.15个百分点的提升。同时需要注意TP1和TP2这两个带有半透明文字样本的困难数据集结果,TP2和TP1的差别是采样时间不同,TP2在夜间,背景颜色黯淡,即使是半透明文字也相对容易辨别,而TP1则是在白天采样,背景当中的光线干扰大,加之半透明文字,时间戳非常容易和背景当中的复杂环境混淆在一起,识别难度更高,对应的完全匹配指标相对较低,具体样张可参考表1中的TP1和TP2。这两个数据集在指标上的差异反映了模型对于光线干扰的抵抗能力,在没有信息约束模块的CRNN模型下,两个数据集的完全匹配差距为3.13个百分点,而在增加了约束信息模块后的TFC-CRNN模型测试中,TP1和TP2的性能差距降低到了2.29个百分点,说明TFC-CRNN有效提升了模型在白天抵抗复杂模型的抗干扰能力。
而在输出文本格式的规范性方面,信息约束模块同样起到了积极的作用,在表3中展示的是模板编辑距离的测试结果,其中的数值是数据集中所有样本的平均模板编辑距离。可以看到,加入信息约束模块之后,EDT指标降低了0.002 8~0.012 76,EDT越低说明模型输出的文本越符合目标文字模板,即输出的文字格式越规范,其中在TP1和TP2这两个存在有半透明文字这类困难样本的数据集上的下降幅度,是NM1和NM2这类不透明文字数据集上的4~5倍,说明信息约束模块有效提高了在半透明等文字识别困难的样本上,有效提高了字符串输出的格式规范性,当文本辨别不清时,信息约束模块将会趋向于输出一个符合格式规范的文本,这对于后期应用阶段解析时间戳字符串的结构信息具有积极的意义。
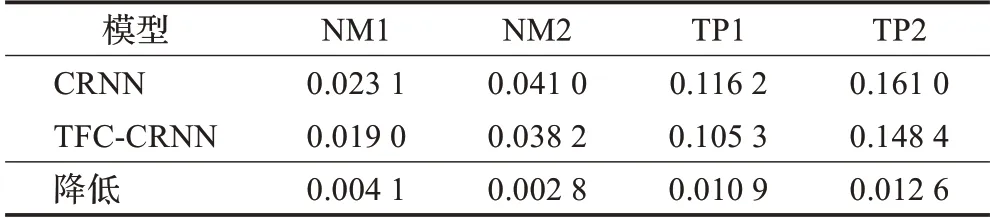
表3 信息约束模块对EDT指标的影响Table 3 Impact of information constrain module on EDT
更进一步,考虑到识别结果中,时间戳文本的数值范围也有较高的要求,对于一个标准的时间戳字符串而言,其字符组合不仅应当满足格式的要求,也应当满足日期时间的数字范围限定,例如月份所在的两位数字需要限定在01~12这12种数字的范围之内,如果文本无法转换为计算机内部的一个标准时间结构体,那么该文本仍然是一个非法的时间戳字符串,为此,本文对比了信息约束模块对数值范围精度的影响,在表4中,记录的是模型输出的时间戳字符串,可以被正常解析为有效时间的样本百分比,括号内表示TFC-CRNN相比CRNN的数值提升,因缺字漏字、超出合理范围、超出闰年限定的结果都会被排除在外。可以从表4当中看出,TP1数据集的困难样本上,指标的提升幅度最为明显,表明信息约束模块在光线干扰、半透明文字等困难样本上,对文本输出结果的数值约束性有较高的收益。
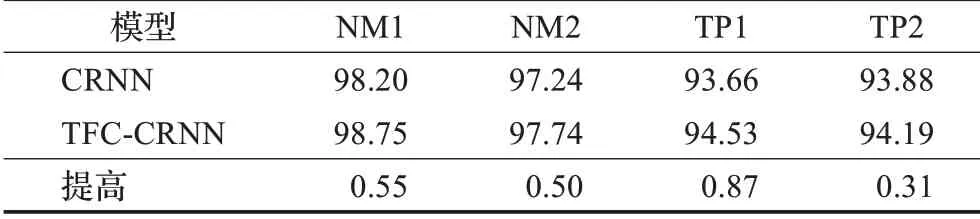
表4 预测数字范围正确的样本所占百分比Table 4 Percentage of samples with correct number interval 单位:%
在表5中展现的是一些具体的时间戳图片识别结果,可以很直观地观察到约束模块对文本格式以及数值范围精度的修正作用。样本1中因为树叶等背景干扰,“2018”中的“0”几乎不可见,传统的文字识别算法会倾向于识别成无字,导致识别结果的格式存在错误,然而在信息约束模块下该处的“0”能够被正确识别出来,生成规范的时间戳格式。样本2则是一个字符干扰问题,在“18:38:22”重叠了一个“Err”文字,这对模型识别产生了严重的干扰,传统的CRNN在这样的干扰下出现分钟数字识别错误的问题,然而在信息约束模块的作用下,TFC-CRNN能够将此处的数值范围修正到00~59的区间内,得出正确的识别结果,同理样本3、4、5。样本6反应的是在极低画质条件下,模型抵抗复杂背景干扰的能力,可以看到传统的CRNN网络对无法有效区分“2018”和“2010”,而TFC-CRNN则依靠多任务的信息约束模块,展现了强大的抗干扰能力,有效区分了“0”和“8”这两个极易混淆的字形。

表5 CRNN和TFC-CRNN的时间戳识别结果对比Table 5 Recognition samples for CRNN and TFC-CRNN
4 总结
本论文就时间戳文字具有固定格式的这一特点,对传统自然语文本识别模型进行专门的优化,从时间戳具有的“年”“月”“日”“时”“分”“秒”六个高度结构化的数字信息这一角度出发,精心设计了约束向量提取网络,将其整合进经典文本识别算法的框架之中,利用监督算法促使网络从图像中提取文本所蕴含的语义信息,并将该信息用于解码阶段的循环神经网络中,使得解码层不仅能够利用图像特征,同时能够学习在约定的规范信息下,对解码输出的文本进行更严格的格式审查和数值范围约束,取得了相比经典文本识别模型更高的准确率和更严谨的文本格式,在后续应用当中,能够为智慧安防系统提供高质量的时间戳文本。
猜你喜欢
中国石油石化(2022年12期)2022-07-16
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
中国外汇(2019年19期)2019-11-26
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
小学阅读指南·低年级版(2017年1期)2017-03-13
人生十六七(2015年6期)2015-02-28
