
增强型高阶注意力因子分解机点击率预测模型
2022-12-22 11:46陈育康龙慧云
计算机工程与应用 2022年24期
陈育康,龙慧云,吴 云,林 建
贵州大学 计算机科学与技术学院,贵阳 550025
预测用户对某广告或项目的点击率(click-through rate,CTR)是推荐系统中的关键问题[1],通过预测用户对项目的点击率,对候选项目进行排序,将项目推送给其可能的潜在客户。一方面为公司带来巨大的商业价值,另一方面提高了用户使用满意度,用户可以更容易地找到其想要的内容。点击率预测的好坏直接关系到公司的收益,由于其重要性,近年来学术界和工业界对点击率预测展开了广泛的研究。
特征组合对于预测用户点击率至关重要,例如,向一位女士推荐化妆品时合理的,在此情况下,<性别=女,商品类别=化妆品>是一组非常有用的二阶特征组合。再比如向一个9岁大的男孩推荐游戏机也是合理的,其中<性别=男,年龄=9,商品类别=游戏机>是一组重要的三阶特征组合。在推荐场景中,存在巨量这样有效的特征组合,然而找寻这些高阶特征组合在很大程度上依赖于领域专家,由于庞大的特征数量以及高的阶数,人工挑选所有有效的特征组合几乎是不可能的。因此,对特征交互进行自动建模对提高CTR预测准确度非常重要,近年来许多学者使用机器学习和深度学习方法对自动化特征工程展开了研究。
在自动化特征工程CTR预测模型研究上,经历了从浅层到深层的演变。最初人们利用LR[2-3]模型进行CTR预测,具有可解释性强的特点,但其无法进行特征交叉,表达能力不强。对此Rendle等人[4]提出了因子分解机(factorization machine,FM),将成对特征的交互建模为两两嵌入向量的内积,能同时处理不同类别的特征,并大大降低了模型参数。由于不同特征交互对最终预测的贡献是不同的,为了让模型关注到重要的特征交互,Xiao等人[5]在FM的基础上提出了AFM,利用注意力机制学习不同二阶特征组合的重要性。然而在这类浅层模型中,只利用到了低阶特征交互,无法提取特征间的高阶复杂关系,表达能力不足。
随着深度学习的兴起[6-7],近年来许多研究利用深度神经网络挖掘特征之间的隐式高阶非线性交互,其具有学习能力强的优点。Cheng等人[8]提出的Wide&deep和Guo等人提出的DeepFM[9]采用了并行的方式,分别将一阶特征、二阶特征与DNN部分进行联合,使得网络同时具备记忆能力和泛化能力。为了利用神经网络进一步挖掘低阶特征的信息,蒋兴渝等人[10]提出的APNN模型将一阶特征重要性信息、二阶特征重要性信息以及Product交互信息三个部分的输出融合,并以串联的方式输入多个全连接层进行学习。为了对DNN部分进行优化,Wang等人[11]提出了AdnFM,其利用注意力机制对DNN中不同层的重要性进行学习。在这类基于神经网络的CTR预测模型中,由于神经网络黑盒的特点,以一种隐式的方式建模高阶特征交互,难以保证特征交互的有效性。
为了有效建模高阶特征交互,人们对显式高阶特征交互方法展开了研究。深度交叉网络(DCN)[12]和极深因子分解机(xDeepFM)[13]提出了Cross网络与CIN网络的特征交互方式,分别在元素级与向量级对特征交互进行建模,将显式交互部分拓展到了高阶。为了结合DNN、Cross、FM三种模型的优势,陈彬等人[14]提出了DCFM模型,其在Embedding层上将对三部分并行计算,得到的输出拼接后输入全连接神经网络进行预测,由于组件过多,使得参数量过大。然而在这类高阶特征交互模型中,没有考虑到不同特征交互的重要性,无用的特征交互将对预测产生干扰。
为了区分高阶特征交互的重要性,Song等人[15]提出的AutoInt使用自注意力机制更新特征表示,但其拓展到高阶时特征交互较为隐式,并且只将最后一层结果作为输出拓展到高阶时可能会损失部分信息。Tao等人[16]提出了HoAFM,利用元素级注意力机制对特征交互进行建模,并可拓展到高阶,但由于特征表示维度受限于Embedding维度,限制了模型的表达能力,并且模型在拓展到高阶时容易过拟合。
为了解决以上模型中存在的问题,本文提出了一种新的CTR预测模型,称为增强型高阶注意力因子分解机EHAFM,其主要创新点如下:(1)针对神经网络建模高阶特征交互不可控的缺陷,设计了一种新的显式特征交互层,通过聚合其他特征的表示来更新特征的表示,改变其层数可将特征表示拓展到高阶;(2)针对无用特征交互对预测产生干扰的问题,提出了增强型元素级注意力机制,其利用投影矩阵拓展特征表示维度,扩大特征表示空间的同时,使得新的特征表示具有全局特征信息,增强了模型挖掘特征交互重要性的能力,减少无用特征交互干扰;(3)通过融合多个增强型元素级注意力头的信息,提高了模型的泛化能力。
1 相关工作
本文的工作与以下两项工作有关:(1)特征的编码与嵌入;(2)基于注意力机制的显式特征交互模型。
1.1 特征编码
在点击率预测任务中,数据通常包含类别特征和数值特征,对于数值特征来说可以直接输入网络。但对于类别特征来说,必须先将其编码,目前常用的操作是独热编码(one-hot encoder)[17]。例如对性别特征进行编码,性别特征字段中有性别=男,性别=女两个类别,独热编码可以分别将其表示为[1,0]和[0,1]两个向量,向量维度与类别数对应。
独热编码解决了类别型特征表示问题,但在Web级规模推荐系统中,由于同一个特征字段中有多个类别,将其进行独热编码后会出现两个问题:(1)维度较大,独热向量维度需对应特征字段类别数;(2)向量稀疏,维度庞大的独热向量中仅有一位代表某个特征,其余全为零。若将其直接输入神经网络,由于第一层参数量庞大,会产生极大的计算开销,不利于网络训练。因此,通常在独热向量输入网络前,将其进行Embedding[18-20]嵌入。将高维稀疏的独热编码映射到一个低维稠密的空间中,大幅减少了网络计算量。例如颜色特征字段中有红、黄、蓝、绿四个类别,独热编码分别为[1,0,0,0]、[0,1,0,0]、[0,0,1,0]、[0,0,0,1],其Embedding表示可以为红[0.9,0.1]、黄[0.8,0.2]、蓝[0.7,0.3]、绿[0.6,0.4],大大压缩了向量维度。
1.2 注意力特征交互模型
1.2.1 AFM模型
Xiao等人[5]的研究表明,不同特征交互对最终预测的贡献是不同的,为了区分不同特征组合的重要性,AFM通过在交互层后添加一个加权池化层来实现注意力机制。在注意力权重的计算方法上,AFM采用的是软注意力机制[21],引入了多层感知机(MLP),利用单隐层的神经网络学习特征交互重要性,注意力机制形式化定义如下:其中,W、h、b分别为权重矩阵、权重向量和偏置向量,a'ij为特征组合ij的注意力分数,aij为特征组合ij的注意力权重,⊙为向量间哈达玛积,计算方法为向量对应元素相乘。

利用得到的注意力权重对交互向量进行池化,得到二阶注意力特征表示。其形式化为:

但AFM模型的缺陷是只局限于二阶特征交互,而未考虑高阶特征交互。
1.2.2 HoAFM模型
为将AFM拓展到高阶,最新的研究中Tao等人[16]提出了高阶注意力因子分解机HoAFM,探讨了如何显式建模高阶特征交互,以及不同注意力机制对模型效果的影响,包括元素级注意力机制、软注意力机制、稀疏注意力机制[22],实验表明元素级注意力机制有更优的效果,其形式化定义如下:

其中,e1i为第i个特征的一阶嵌入向量,eli为第i个特征的l阶表示向量,μ(·)为激活函数。wij为论文提出的注意力权重向量,用于在元素级粒度上建模注意力机制。
但由于特征高阶表示向量维度始终固定,与Embed‐ding维度一致,缺少维度可伸缩性,限制了模型的表达能力。
2 EHAFM模型
针对以上问题,本文提出了EHAFM模型,该模型主要由特征Embedding嵌入层、显式特征交互层、输出层构成,模型整体框架如图1所示。首先将输入模型的特征向量通过Embedding层,统一编码为维度相同的Embedding向量,接着将特征Embedding向量分别输入一阶线性部分和显式特征交互部分进行学习,提取线性特征信息和高阶特征交互信息,最后将两部分的输出联合进行点击率预测。

图1 EHAFM模型整体框架Fig.1 Overall framework of EHAFM model
通过改变显式特征交互层的层数可以将特征交互拓展到任意高阶,提取高阶特征信息,并与线性部分结合,使得模型兼具泛化能力和记忆能力。
2.1 Embedding层
在点击率预测任务中,输入模型的特征分为数值特征(0,0.5,7…)和类别特征(性别、城市…),为了使数值特征与类别特征进行交互,构造数值特征与类别特征之间的特征组合,模型将数值特征与类别特征统一嵌入为相同的维度d。
对于类别特征:类别特征是以one-hot形式输入Embedding层,将其高维稀疏的形式嵌入到低维稠密的Embedding特征向量,如图2所示,其形式化为:
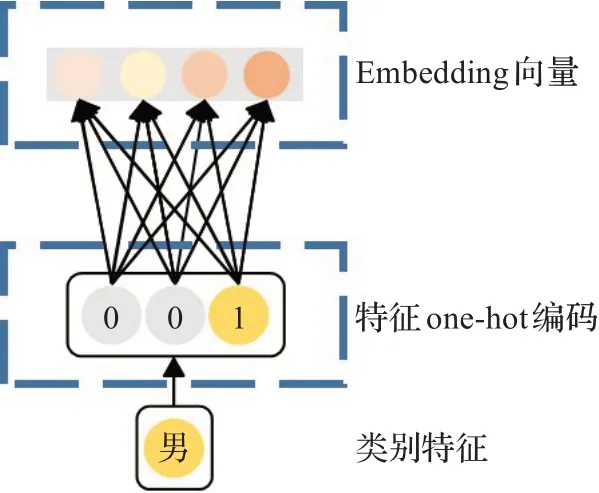
图2 类别特征嵌入Fig.2 Category feature embedding

其中,ei为特征i的特征向量,Vi为特征域i的嵌入矩阵,xonehot为特征i的one-hot向量。
类别特征可以是多值的,即xmultihot是一个multi-hot向量。例如一部电影,它的类型可以既是喜剧片也是爱情片,它的multi-hot编码如[1,0,1,0,0]这样的形式。为了使模型兼容多值特征输入,将multi-hot特征的Embed‐ding向量除以多值个数,具体来说:

其中,q为第i个特征域中多值个数,即multi-hot向量中1的个数,xmultihot为特征i的multi-hot向量。
对于数值特征:将特征为数值类型的每个特征域分别用一个可训练的Embedding向量进行表示,对于每个数值特征来说,其嵌入表示为特征域的Embedding向量乘以特征标量值,如图3所示,其形式化为:

图3 数值特征嵌入Fig.3 Numerical feature embedding

其中,vi为第i个特征域的嵌入向量,xNum为特征i的数值标量。
2.2 显式特征交互层
不同特征组合对于最终预测的贡献是不同的,引入注意力机制区分特征组合的重要性是有必要的。Tao等人的研究表明,向量级注意力机制相比元素级注意力机制具有次优的表示能力,因此本文在元素级上建模注意力机制。相比HoAFM固定的特征表示维度,本文提出的显式特征交互层拓展了特征表示维度,提高了特征向量的表达能力,同时增强了注意力矩阵的学习能力。显式特征交互层计算方法如图4所示。
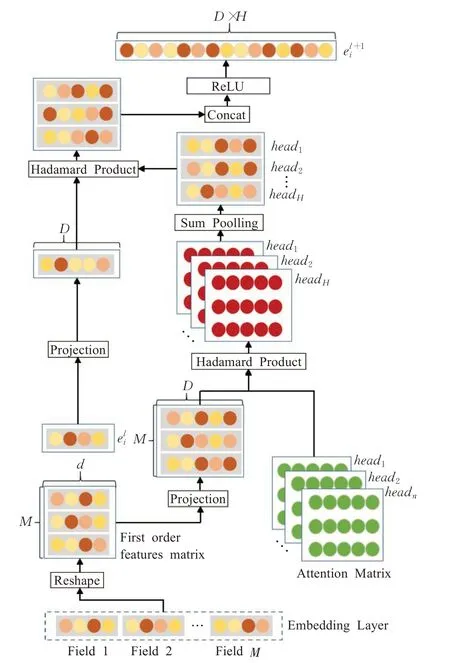
图4 显式特征交互层示意图Fig.4 Schematic diagram of explicit feature interaction layer
2.2.1 增强型元素级注意力机制
为了改变特征向量维度,模型利用可训练的投影权重矩阵将特征向量映射到高维空间,以增加特征表示信息量。定义d为原始特征嵌入维度,D为投影变换后的向量维度,eli∈RD×H为特征i的l阶表示向量,e1i∈Rd为特征i的一阶嵌入向量。将一阶特征向量与l阶特征向量分别投影到D维空间中:

其中,WlProject∈RD×d为特征i的l阶投影矩阵,将维度为d的特征向量投影到D维。
为每个高阶特征创建一个可训练权重矩阵wli,用于在元素级建模注意力机制,以区分不同特征组合的重要性。特征i的l+1阶表示可公式化为:
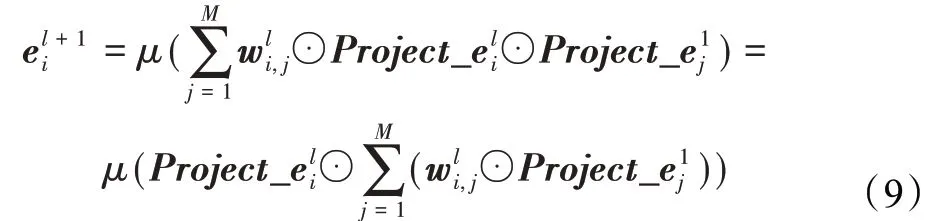
其中,wli,j∈RD为特征i的l阶表示与特征j交互的注意力权重向量,μ(·)为激活函数,本文选用ReLU激活函数,ReLU(z)=max(0,z)。
2.2.2 多头注意力机制
为了避免过拟合,创建多个不共享参数的注意力头[23-24]对特征交互重要性学习,分别在不同的表示子空间中学习特征交互重要性,最后对多个注意力头的输出进行集成,每个注意力头公式化如下:其中,⊕为拼接操作,按照嵌入向量所在维度进行拼接,H为注意力头的总数,对于每个注意力头,注意力权重参数是相互独立的。

因此,结合了多个注意力头后特征i的l阶表示可公式化为:

通过叠加多个这样的特征交互层,从而将特征i更新到其高阶表示el+1i,利用设计的交互层,可以显式建模特征的任意阶交互。
将各个特征的l阶表示堆叠,得到l阶交互矩阵El:

对交互矩阵进行池化,采用的是求和池化,公式化为:
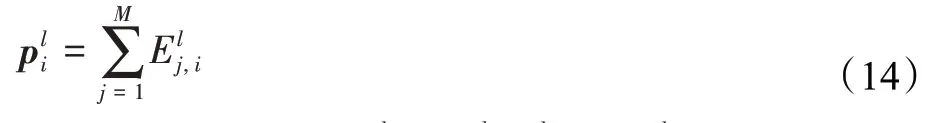
因此,l阶池化向量pl=[pl1,pl1,…,plm],将各阶池化向量拼接,得到显式高阶交互部分的输出p+=p1⊕p2⊕…⊕pl。
2.3 输出层
输出层由一阶线性部分和显式高阶交互两部分构成,将两部分的输出结合起来预测点击率,使得两部分相互互补,同时考虑到特征的低阶和高阶信息。模型的输出可公式化为:
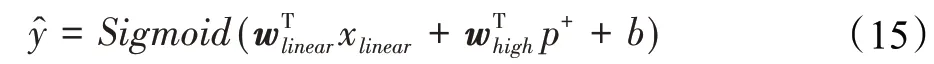

点击率预测任务属于二分类任务(点击、未点击),因此本模型损失函数采用的是Log损失:

其中,N为训练样本的总数,y为样本真实标签(1或0)。
2.4 复杂度分析
2.4.1 空间复杂度分析
模型参数来自于嵌入层、一阶线性部分、显式特征交互部分三个方面。对于嵌入层,其参数量为ndm,其中n为输入特征的稀疏表示维数,d为嵌入维数,m为特征个数。一阶线性部分的参数量来自于权重向量,其参数量为md。显式特征交互部分的参数量来自于注意力机制,首先投影矩阵的参数量dD+HDL,其中D为投影后的向量维度,L为显式特征交互层层数,H为注意力头数量,注意力矩阵的参数量为m(m-1)HDL。加上显式特征交互部分的权重向量,EHAFM模型的总参数量为ndm+md+dD+HDL+m(m-1)HDL+mL,空间复杂度为O(m2HDL)。xDeepFM的空间复杂度为O(mF2L),其中F为过滤器数量,由于F的设置通常远大于m,因此本文模型相比xDeepFM空间复杂度要好。HoAFM的空间复杂度为O(m2dL),本文模型拓展了特征表示,并增加了注意力头,因此空间复杂度略大于HoAFM。
2.4.2 时间复杂度分析
模型时间消耗主要来自于显式特征交互层,计算一个注意力头需要O(m2DL)的时间,本文的模型有H个注意力头,因此模型的时间复杂度为O(m2HDL)。而xDeepFM的时间复杂度为O(mF2dL),由于H的取值较小,md≫HD,并且F≫m,因此本文模型在时间复杂度上比xDeepFM要好得多。对于HoAFM,其时间复杂度为O(m2dL),比本文模型略低。但是,在本文模型注意力机制实现上,采用了矩阵乘法的方式,在GPU上进行批量计算以代替for循环,本文模型的时间成本是可以接受的。
3 实验
3.1 数据集及预处理
本实验所用数据集为公开数据集Criteo和Movielens-1M。Criteo数据集是CTR预测任务的基准数据集,其中包含了在Kaggle竞赛中,Criteo广告公司提供的约4 500万条用户广告行为记录,其中包含26个类别特征和13个数值特征。Movielens-1M数据集是GroupLens Research采集的一组从20世纪90年末到21世纪初由MovieLens用户提供的电影评分数据。数据集中包含了用户对电影的评分、用户性别、年龄、职业以及电影风格、年代等数据。
在数据预处理方面:对于数值特征,空值以0填充。由于数值特征变动范围较大,会对训练造成不利影响,因此需将其进行标准化,当z>2时,z=lb z。对于类别特征,空值以-1填充。将Movielens-1数据集中用户评分大于3分的样本视作正样本(label=1),小于3的样本视作负样本(label=0),去除评分为3的中立样本。将数据集随机打乱后按照9∶1分割训练集和测试集,经预处理后的数据集信息如表1所示。

表1 数据集信息Table 1 Dataset information
3.2 评价指标
AUC(area under curve):AUC为ROC曲线下面积,其衡量了模型预测的正例排在负例前面的概率,其值越接近于1,二分类性能越好,并且指标对于样本类别是否均衡不敏感,在样本不平衡的情况下,依然能做出合理的预测,是点击率预测任务中最重要的评价指标。
Logloss:对数损失同样是二分类任务中广泛使用的评价标准,其可以衡量预估CTR与实际CTR的拟合程度,计算方法为公式(17),Logloss越低拟合能力越强。
3.3 基准模型
在基准模型选择方面,本文将所提出的模型与两类模型进行比较:(1)基于多层全连接神经网络的CTR预测模型;(2)显式特征交互CTR预测模型。
DNN:由多层全连接前馈神经网络构成,直接将特征嵌入向量平铺后输入网络进行训练。
AFM[5]:用注意力机制区别FM中二阶特征交互的重要性。
DCN[12]:在元素级上显式建模特征向量间的高阶交互,并与DNN进行结合。
DeepFM[9]:将DNN与FM二阶特征交互融合,使模型同时具备高阶特征和二阶特征信息。
xDeepFM[13]:利用卷积神经网络对特征交互张量进行压缩,能在向量级显式建模高阶交互。
AutoInt[15]:利用多头自注意力机制更新特征交互表示。
DCFM[14]:将DNN、Cross、FM三个组件结合的混合模型。
APNN[10]:将一阶特征重要性信息、二阶特征重要性信息以及Product交互信息融合,并通过多个全连接层获取更多潜在高阶信息
AdnFM[11]:在DeepFM的基础上,在DNN部分加入层级注意力机制。
HoAFM[16]:基于元素级注意力机制显式建模特征高阶交互。
3.4 参数设置
所有模型使用Tensorflow2.0框架进行实现。在超参数设置方面,本文不探讨Embedding维度对模型的影响,将Embedding嵌入维度统一设置为8,batch-size大小统一设置为1 024。对于含有DNN部分的网络,将其隐藏层数设置为3,每个隐藏层神经元个数为200,dropout比率设置为0.5,以防止过拟合。对于DCN、xDeepFM、AutoInt、DCFM、HoAFM,将其显式特征交互层设置为3层,与本文提出模型保持一致,其中CIN过滤器数量设置为200。对于AFM,将其注意力隐层神经元个数设置为8,与嵌入向量维度一致。最后,所有模型使用Adam[25]来优化所有模型,学习率统一设置为0.000 1。
3.5 实验结果及分析
在四个方面对模型性能进行实验,并对实验结果展开讨论。实验1为本文提出模型与基线模型的性能比较;实验2~实验4是为了探讨不同超参数对于本文提出模型的影响,其中对于Criteo数据集,超参数搜索取前60万条数据作为实验数据。
3.5.1 与基准模型性能对比
实验1为验证模型的有效性,分别在两个数据集上对所有模型进行实验,表2为实验结果。
从表2中可以看出,在Criteo与Movielens-1M数据集上,本文提出的模型在AUC与Logloss指标上明显优于基准模型。相较于最先进的模型,在Criteo与Movielens-1M数据集上分别有0.21%和0.92%的AUC提升,验证了模型在大数据集与小数据集上同样具有优异的性能。此外,在实际业务中,认为0.1%的AUC提升也是颇具意义的,若用户基数庞大,这将为公司带来巨额的收入增长[15]。
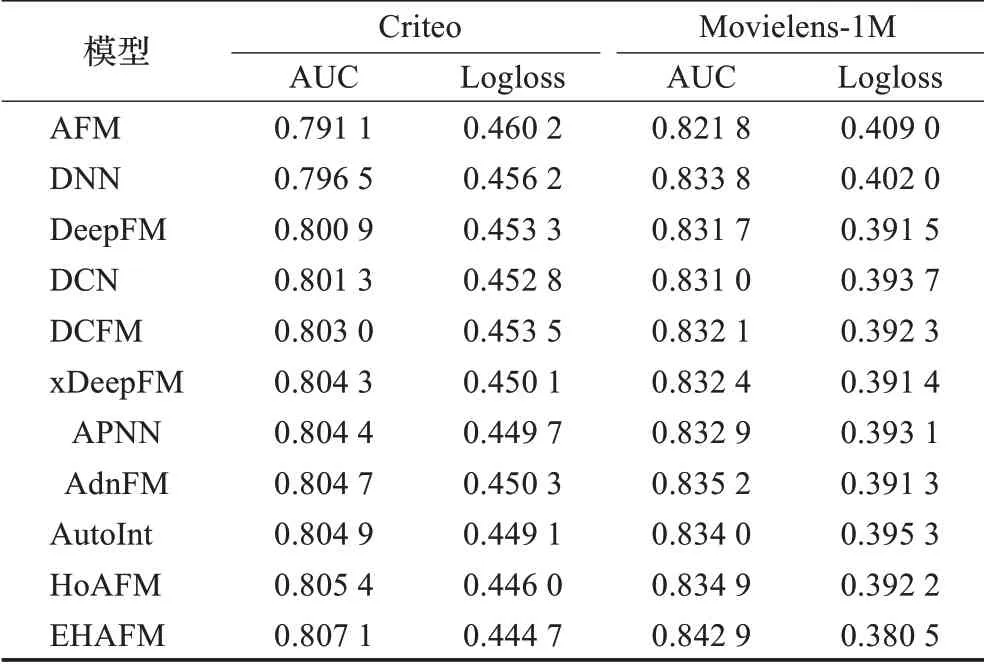
表2 模型表现Table 2 Models performance
3.5.2 显式特征交互层层数对性能的影响
显式交互层层数直接关系到建模特征交互的阶数,因此该实验的目的是为了选取最优显式交互层层数,实验结果如图5所示。
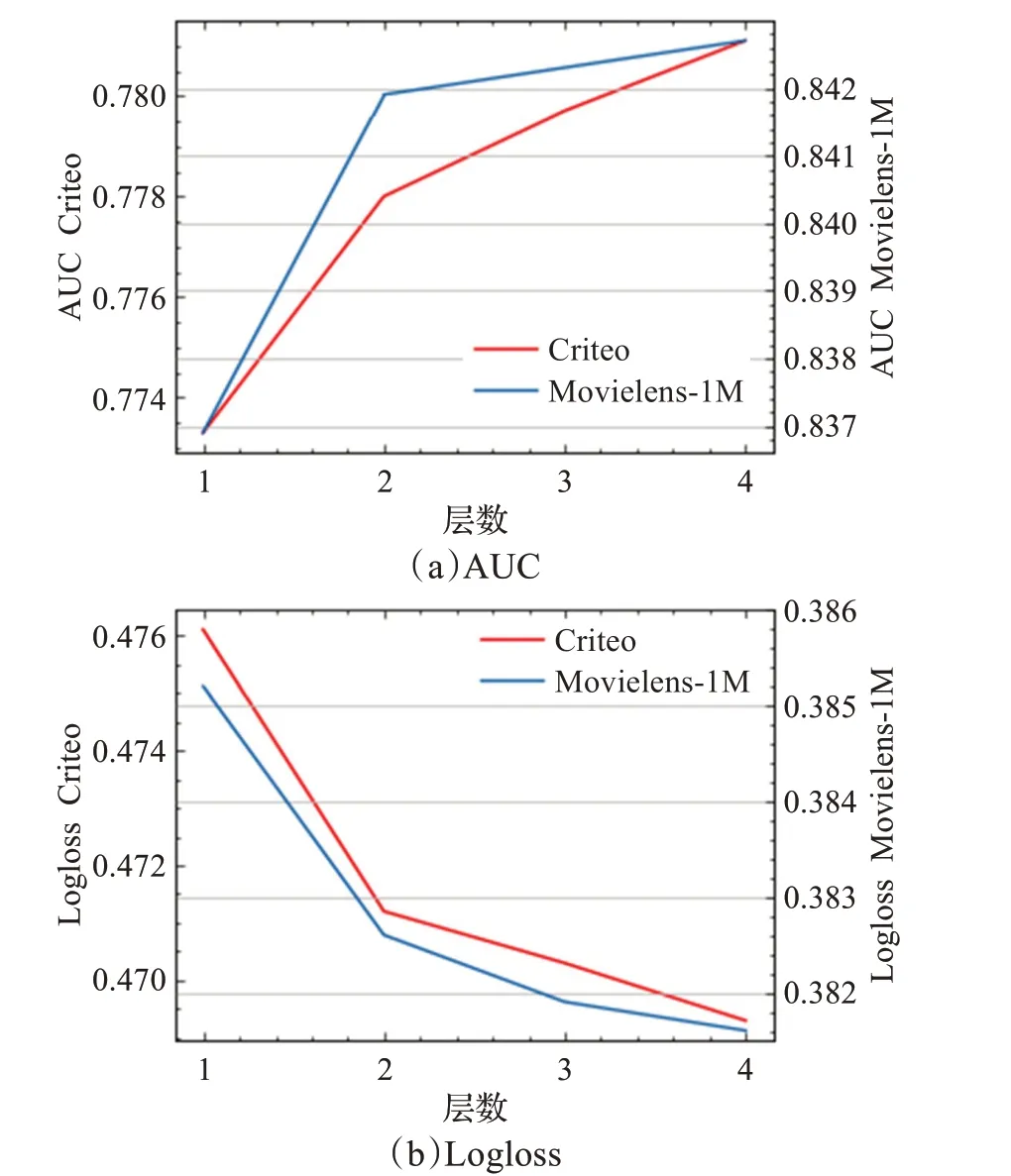
图5 显式特征交互层数与模型表现Fig.5 Influence of explicit feature interaction levels on model performance
由此可见,当显式特征交互层从1层(2阶特征)拓展到2层(3阶特征)时,获得了较大的提升,当拓展到3层以上时,模型提升逐渐放缓。对于Movielens-1M数据集来说,由于其只有7个特征字段,因此显式特征交互层2层以上时提升非常小,将2层显式特征交互层作为最优参数。对于Criteo数据集来说,由于其特征字段数量较多,较高阶的特征交互中也含有有用的信息,将3层作为最优参数。
3.5.3 特征增强对性能的影响
本文提出的算法在进行特征交互前,对特征向量进行了增强,利用投影矩阵将特征向量映射到更高维度的空间,得到特征向量的高维表示,不但拓展了维度,并且所有特征字段共享投影矩阵使得新的特征表示融合了全局特征信息。通过特征增强提高特征向量的表达能力,进而增加注意力矩阵的学习能力。如图6所示,通过消融实验对比了特征增强前后模型在两个数据集上的效果,结果表明特征增强后模型在Criteo与Movielens-1M数据集上分别获得了0.97%和0.85%的AUC提升。
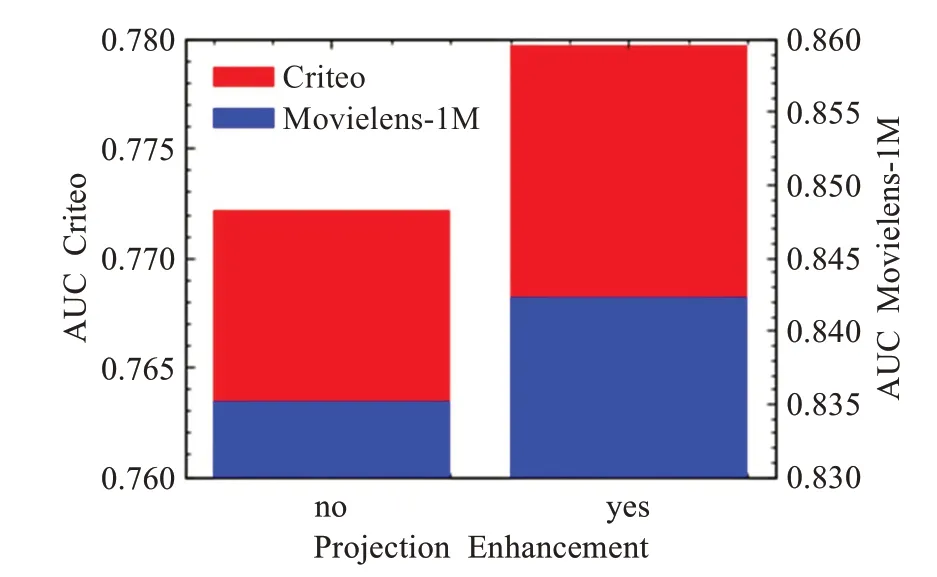
图6 特征增强与模型表现Fig.6 Feature enhancement and model representation
此外,为了探讨投影向量维度对模型性能的影响,在不同投影向量维度下对模型进行了实验。从图7中可以看出,在两个数据集上AUC随着投影向量维度增加而提升,但到达峰值后,再增加投影向量维度收效甚微,并且会带来更高计算成本。

图7 投影向量维度与模型表现Fig.7 Influence of projection vector dimension on model performance
3.5.4 注意力头数量对性能的影响
为了验证多个注意力头对缓解过拟合问题的作用,本实验设计了在不同注意力头数量时模型的表现。
实验结果如图8所示,当注意力头数量为2时,相较单个注意力头有明显提升,这是由于不同注意力头可能观察到不同的特征交互重要性,结合多个注意力头提取到的特征交互信息可缓解过拟合,提高模型的泛化能力。当注意力头数量为3时,AUC与Logloss趋于平稳,再增加注意力头数量模型效果的提升不明显。这可能是因为随着注意力头增加,每个注意力头为预测点击率提供的信息逐渐减少,无法获取更多有效信息。
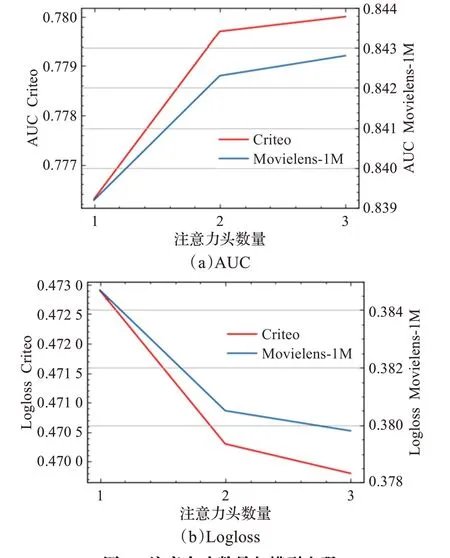
图8 注意力头数量与模型表现Fig.8 Influence of number of attention heads on model performance
4 结束语
为提高点击率预测的准确性,本文提出了一种新的点击率预测模型,称为增强型高阶注意力因子分解机(EHAFM)。模型考虑到不同特征交互对于预测具有不同的重要性,设计了一种增强型元素级注意力机制,其在元素级上区分不同特征交互的重要性,减少了无用特征交互的干扰。并针对模型容易过拟合的问题,融合多个增强型元素级注意力头的信息,增强模型的泛化能力。随着堆叠显式交互层,特征表示可以拓展到任意阶数,最后将高阶特征交互部分与一阶线性部分结合,使模型同时具有记忆能力和泛化能力。通过在两个数据集上的实验,结果表明模型在预测准确性上相较基准模型有明显的提升,验证了模型的有效性。
此外,在工业级推荐系统中,图片、文本等形式的数据广泛存在于用户、项目特征中,并对预测用户偏好产生影响,在接下来的工作中,将考虑多模态特征间的交互,进一步提升模型性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
哈尔滨轴承(2020年1期)2020-11-03
少儿画王(3-6岁)(2020年4期)2020-09-13
甘肃教育(2020年22期)2020-04-13
福建基础教育研究(2019年7期)2019-05-28
北京航空航天大学学报(2016年7期)2016-11-16
第二课堂(课外活动版)(2016年2期)2016-10-21
浙江大学学报(工学版)(2015年1期)2015-03-01
中央民族大学学报(自然科学版)(2014年3期)2014-06-09
微型计算机(2009年4期)2009-12-23
