
面向海量新闻简报的事件演变轨迹构建方法
2022-12-22 11:46邓志宏陈英武
计算机工程与应用 2022年24期
赵 华,邓志宏,陈英武
1.国防科技大学 系统工程学院,长沙 410073
2.国防大学 教育与训练部,北京 100091
当今信息技术的迅猛发展,各大新闻媒体如腾讯、新浪和今日头条等,每天都会产生大量关于热点事件的新闻简报。对于一般读者来说,每天阅读并消化大量新闻简报变得越来越困难。传统的搜索引擎能根据用户输入的关键词从新闻语料库中进行检索,查询读者感兴趣的内容。然而,引擎一般只返回一个排好顺序的新闻报道列表,不提供热点事件的结构摘要,没有为读者提供一种人性化的方式来查看热点事件的内容。
当前无需用户预先指定查询就能对新闻语料库进行可视化组织和呈现的方法主要有:Event Timelines[1-2]、Event Thread[3]、Event Evolution Graphs[4]、Information Maps[5-7]和Story Forest[8]。其中,Story Forest是首个能够有效地将海量中文新闻文章构建成较强逻辑性的故事结构的系统。然而,经过深入研究后,发现Story Forest有以下三个方面可以继续加强和改进:
第一,在新闻文章预处理阶段,Story Forest根据字数对文章进行过滤,这样做对新闻简报效果就没那么好。例如,对于“孟晚舟未能获释,引渡案件将继续审理。”或“华为将向联发科购买更多的芯片。”这些字数极少的新闻简报将会被滤掉,造成重要信息的丢失。另外,Story Forest是根据词语特征(如:是不是命名实体或地理位置),结构化特征(如:TF-IDF)以及语义特征来进行关键词抽取,这样做缺乏了对上下文语义的智能分析和理解,使得关键词的抽取不够准确。
第二,在新闻文章聚类和事件抽取阶段,Story Forest利用关键词构建了关键词图。根据文献[8]的结果表明,系统每天收集的文章数量平均为16 000余份,抽取的关键词也会非常多。而Story Forest在构建关键词图之前没有对关键词作进一步的处理,可能会导致关键词图的结构异常复杂。另外,系统在第二阶段进行聚类所用的SVM分类器,主要考虑的是新闻文章的内容、标题以及首句的TF-IDF和TF向量之间的余弦相似度,同样缺乏对上下文语义内容的智能分析和理解。
第三,Story Forest之所以能够明显优于以往技术的原因就是它利用了事件关键字集合和故事关键字集合之间的Jaccard相似系数来判别与新事件相关的演变结构,并综合考虑事件间的兼容性、演变主线一致性和事件之间的时间间隔三方面的因素,实现了可视化即时新闻系统的实时更新。然而,这样做仍然存在一定的问题,例如:新事件的关键字集合与已有演变结构的关键字集合中的词汇有时即使看起来并不相似,但如果描述的内容与故事树中的内容相似,那么事件与故事树也应该是相关的。此时,使用关键字集合之间的Jaccard相似系数是难以进行准确判定的。因此,对于事件间的兼容性计算要做出相应的改进,并且事件间的时间距离的计算方法也相对简单,应该进行更深入的研究使事件间连接强度的计算更加准确。
针对上述问题,构建了事件演变轨迹模型 来将海量新闻简报数据加工成前后逻辑一致的事件发展结构,模型是在Story Forest的基础上进行改进得来的。主要工作有以下几个方面:
(1)在预处理阶段,事件演变轨迹模型用主题集群创建的步骤替代了Story Forest的新闻文档过滤步骤,在分词时使用了最新的Stanza工具,并在关键词抽取中引入了预训练的BERTBASE[9]模型来替代原来的GBDT+LR。
(2)在构建关键词图时,提出基于频繁项集对关键词价值进行分析来过滤关键词。在第二阶段抽取细粒度事件的过程中,再次引入预训练的BERTBASE替代SVM来判定两个新闻简报是否在讨论同一个事件。
(3)在更新演变轨迹时,用BERTBASE模型替代Jacca‐rd相似系数来判别与新事件相关的演变轨迹,重新定义事件的形心文档,提出了事件时间窗口距离计算方法,改进了事件间连接强度指标中的兼容性计算方法和时间惩罚函数。
(4)基于从中国所有主要互联网新闻提供商(如腾讯、新浪和今日头条)收集的约32 GB中文新闻简报数据,对模型进行评估。从2020年1月1日到2020年5月1日,为期四个月,涵盖开放领域的多个主题。同时,还对新闻简报聚类和事件演变结构的生成进行了详细而广泛的用户试点体验研究,并与几个基准方法对比出哪种更加符合一般读者的习惯。根据用户试点体验研究,本文方法生成的事件演变轨迹的逻辑有效性,以及每个已识别事件和事件演变结构的概念纯度方面,都优于KeyGraph[10]、Story Graph[4]和Story Forest等多个最先进的新闻聚类和事件演变结构生成方法。
1 问题描述和概念定义
首先,在Story Forest的基础上给出了自顶向下层次结构中关键概念的定义:主题➝事件演变轨迹➝热点事件➝新闻简报。
定义1(新闻简报)是指以某个热点事件为核心而触发的新闻报道,时态是突发性或跃进性的。特点是言简意赅、紧扣主题,篇幅长短不一以及写作风格各异。
定义2(热点事件)是指在最近发生并具有重大影响力和极受关注的事件。热点事件E表示一组报道相同事件的一篇或多篇新闻简报。
定义3(事件演变轨迹)是指围绕一个或多个特定的人物或命名实体,在特定的时间发生在特定地点的事件发展结构图。事件E1到E2的有向边缘表示事件E1到E2的时间演变关系或逻辑连接关系。
定义4(主题)是指由一组高度相关或彼此相似的事件演变轨迹集合。
每个主题可能包含一条或多条事件演变轨迹,每条轨迹由多个热点事件组成。将新闻简报作为最小的原子单位。每篇简报被认为只属于一个事件,并且包含关于这个事件的部分或全部信息。
例如,关于“美国海军罗斯福航母”这个主题,“罗斯福航母上出现新冠肺炎确诊病例”就是这个主题中的一条事件演变轨迹,其中“罗斯福号航母上又有5名水兵新冠病毒检测阳性”就是这条演变轨迹中的一个热点事件。而“美国海军的西奥多·罗斯福号航母上又出现了5名检测结果为阳性的水兵。目前感染的8名船员中,已经有4人被送往关岛基地的医院进行治疗,其余4人也将被送下航母。”就是报道这个热点事件的其中一篇新闻简报。给定新闻简报流D={D1,D2,…,Dt},其中Dt为t时段的简报集合,目标是:
(1)将新闻简报流D划分为主题集群T={T1,T2,…,T|T|},其中每篇简报被分配给一个主题集群Tj(1≤j≤|T|)。虽然将简报只分配到一个主题似乎是一种限制,但是如定义1所述,当每篇新闻简报是对某个热点事件进行描述时,这样做是一种合理的解决方案。此外,其他关于主题建模的研究也证明了这种方法是有效的,特别是对于短文本[11]。
(2)使主题Tj中的新闻简报集DTj(1≤j≤|T|)聚集成一组热点事件集合ETj={E1,E2,…,E|ETj|}。
(3)将热点事件连接起来构成一个事件演变轨迹集合Tr={Tr1,Tr2,…,Tr|Tr|},每一条演变轨迹Tr=(E,L)包含一组事件E和一组连接L,其中Lij表示事件Ei到Ej的定向连接,表示时间演变关系或逻辑连接关系。
(4)要以在线或增量的方式提取热点事件并构建事件演变轨迹。也就是说,当t时间段内的新闻简报集合Dt到达时,从集合中提取热点事件,并将新的事件合并到t-1时间段前的现有演变轨迹中。
例 如:图1表示 的 是2020年3月15日至4月10日“美国海军罗斯福航母上出现新冠肺炎确诊病例”的事件演变轨迹。这一事件演变轨迹包含17个节点,其中每个节点代表轨迹中的一个热点事件,每条链接代表了事件之间的时间演变或逻辑关联关系。每个节点上的序号表示时间轴上的序列。在这条轨迹中,主要有3条轨迹路径,其中1➝17描述了罗斯福航母上出现新冠肺炎确诊病例的整体演变过程,2➝15描述了确诊病例人数的事件演变过程,9➝17描述了关于罗斯福航母舰长的事件演变过程。显然,通过将事件的发展和逻辑结构建模成一个有向轨迹路径图,用户可以很容易地快速获取新闻的关键信息。
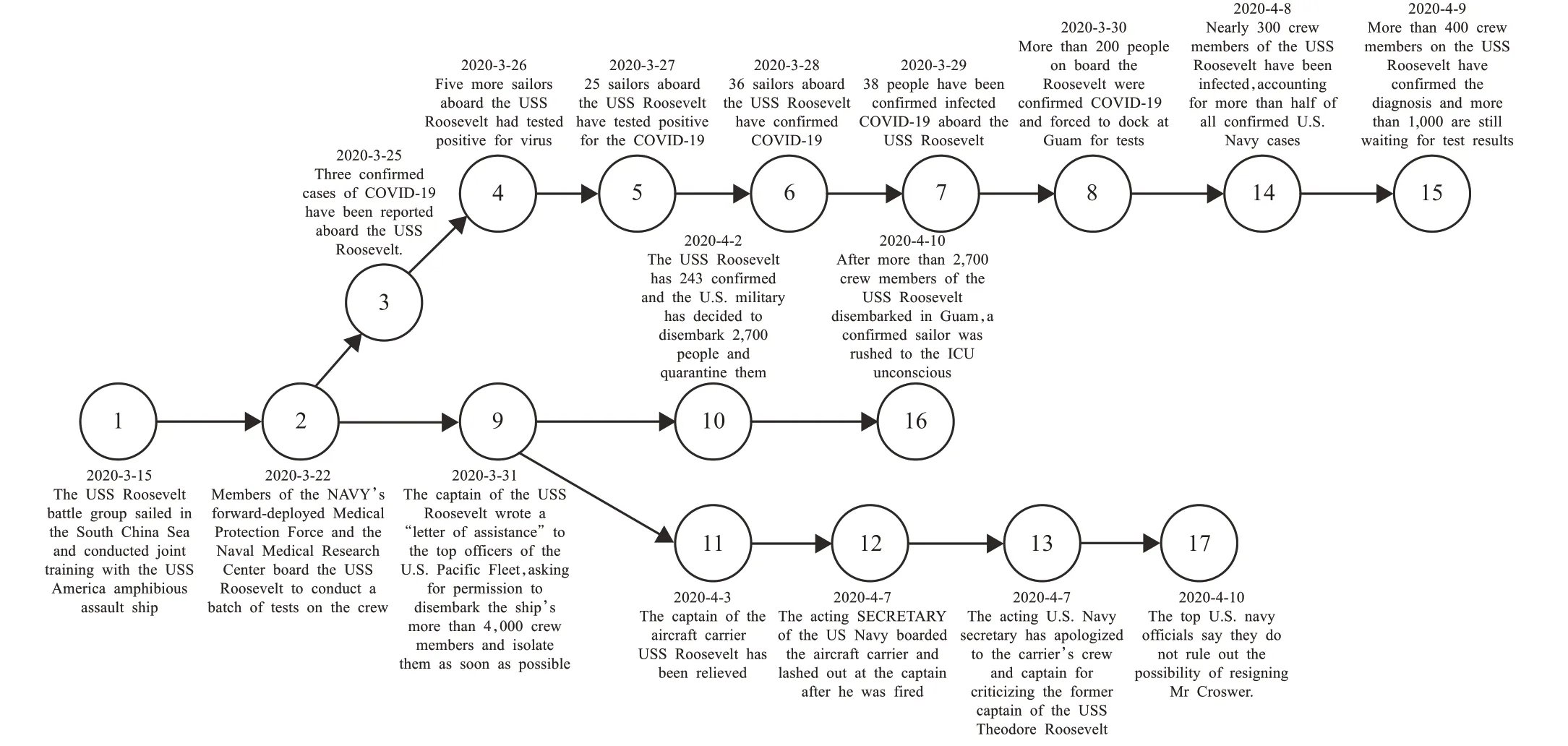
图1 事件演变轨迹示例图Fig.1 Example of event evolution trajectory
2 事件演变轨迹构建方法
构建事件演变轨迹模型的方法概述如图2所示,主要是在Story Forest的基础上改进得来的,由热点事件智能检测和事件演变轨迹实时构建两大部分组成,共分为5个步骤。首先,输入的新闻简报流将通过主题建模方法和各种NLP工具和模型进行处理,与Story Forest不同的是,模型在预处理阶段主要包括的是新闻简报的主题集群创建、分词和关键词提取等。步骤2、3提出一种三阶段的方法将新闻简报分组到热点事件中。与Story Forest的两阶段聚类过程不同,对于每个时间段t的简报语料库Dt,模型会计算关键词的频繁项集,选取重要性高的关键词来构建关键词图[10],再通过社区检测算法从关键词图中提取子图作为子主题。其中,关键词很少的子主题将被剔除。获得子主题后,将找到与该子主题相关的所有新闻简报,并通过一个能分析上下文语义的模型将简报聚类成细粒度的热点事件。该过程由一个预先训练好的新闻简报对关系分类器辅助进行。在步骤4、5中,模型实时构建和更新事件演变轨迹,方法是将每个新事件插入到现有轨迹中的正确位置,或者创建一条新的演变轨迹(前提是新事件不属于任何现有轨迹)。与现有方法不同,判别与事件关联的轨迹时,融入了上下文语义分析,改进了事件间连接强度的计算方法。以下章节将详细阐述每个模块的设计。

图2 事件演变轨迹智能构建方法的体系结构概述Fig.2 Overview of architecture of intelligent construction methods for event trajectory
2.1 热点事件的智能检测
2.1.1 预处理
当新的新闻简报集输入时,模型会创建简报的主题集群,并提取对后续步骤有帮助的特性。模型的预处理模块主要包括三个部分:
第一,使用LDA创建主题集群。应用文献[12]中描述的方法,将每一份简报的标题解析为主题的分布向量θ,如果T=argmaxj(θj),则将该份新闻简报分配给主题集群T,其中包含新闻简报数量小于某一阈值n的主题以及属于该主题下的简报可以被过滤掉,这样做既保留了真实的热点主题,也能够有效避免Story Forest中因字数太少而过滤掉的重要新闻信息。
第二,分词。使用Stanza替代了Story Forest中的Stanford Chinese Word Segmenter Version 3.6.0[13]来对每个简报的标题和正文进行了分割,对于中文新闻简报,Stanza在分词任务中取得了更好的效果。由于上述分词工具都是开源的工具,感兴趣的学者可在相应的数据集上做测试,在此不对工具的性能作详细地比较。
第三,关键词提取。从每个新闻简报中提取关键词来表示简报的主要内容对于热点事件智能检测最终的性能和效率至关重要。传统的关键词提取方法对于真实世界的新闻简报数据来说是不够的[14]。Story Forest利用梯度增强决策树(GBDT)与LR分类器相结合来判断一个词是否是关键词,虽然克服了传统方法的不足,但更多地还是根据词语特征,结构化特征以及语义特征来判别,始终缺乏对上下文语义的智能分析和理解。
为了更高效准确地提取关键词,引入一个微调的BERTBASE模型和单层的神经网络来提取关键词。BERT模型性能强悍,长期霸榜。对于BERTBASE,只需一个额外的输出层,就可以对预训练的BERTBASE模型进行优化,从而为各种任务创建最先进的模型,并且在面对特定任务的情况下无需对模型的体系结构进行大量修改。因此,手工标注了8 000多新闻简报的关键词,包括17 000多正关键词样本和26 000多负关键词样本。表1列出了关键词标注时主要关注的重点特性,当然,更多的是基于专业知识的判别。
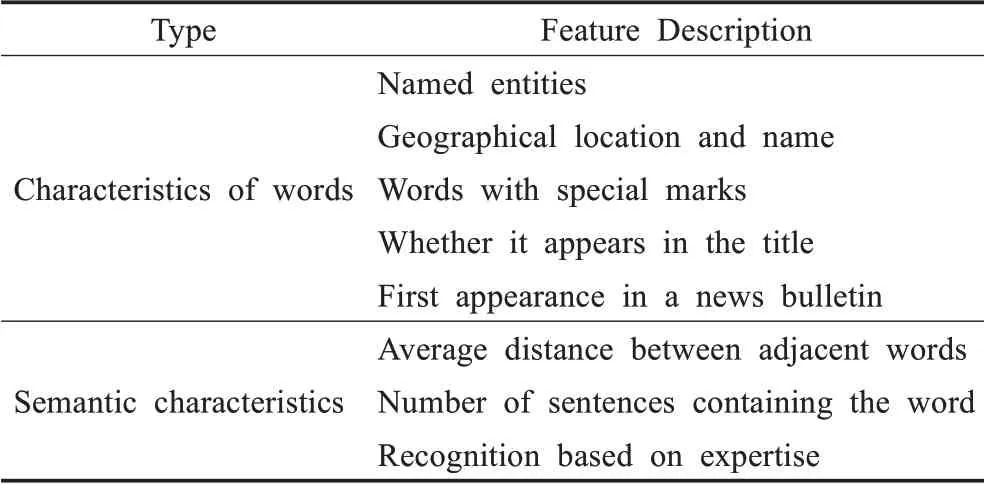
表1 分类器提取关键字的特征Table 1 Features for classifier to extract keywords
BERTBASE模型的功能是判断候选词语wi是不是新闻简报d的关键词。如图3所示,模型将新闻简报作为句子A输入,将候选关键词语作为句子B输入,简报与候选词之间用标记([SEP])分隔。BERTBASE模型输入的最大序列长度为512。因此,将BERTBASE模型应用于关键词判定,会面临如何处理新闻简报和候选词总长度大于510的问题。一般情况下,新闻简报的关键信息在开头和结尾。因此,模型在确保候选词完整的前提下,截断了新闻简报,使简报、候选词和分隔符的连接最大长度为512。设候选词占用wn个字符,则截取简报的前2(510-wn)/3个和后(510-wn)/3个字符作为输入(包括标点符号)。通过使用BERTBASE模型作为二分类模型,将模型中的第一个输入标记([CLS])对应的最终隐藏向量C∈RH作为单层神经网络的输入来获取关键词的识别结果。对于BERTBASE模型的预训练,使用交叉熵损失L将其微调到关键词提取任务:
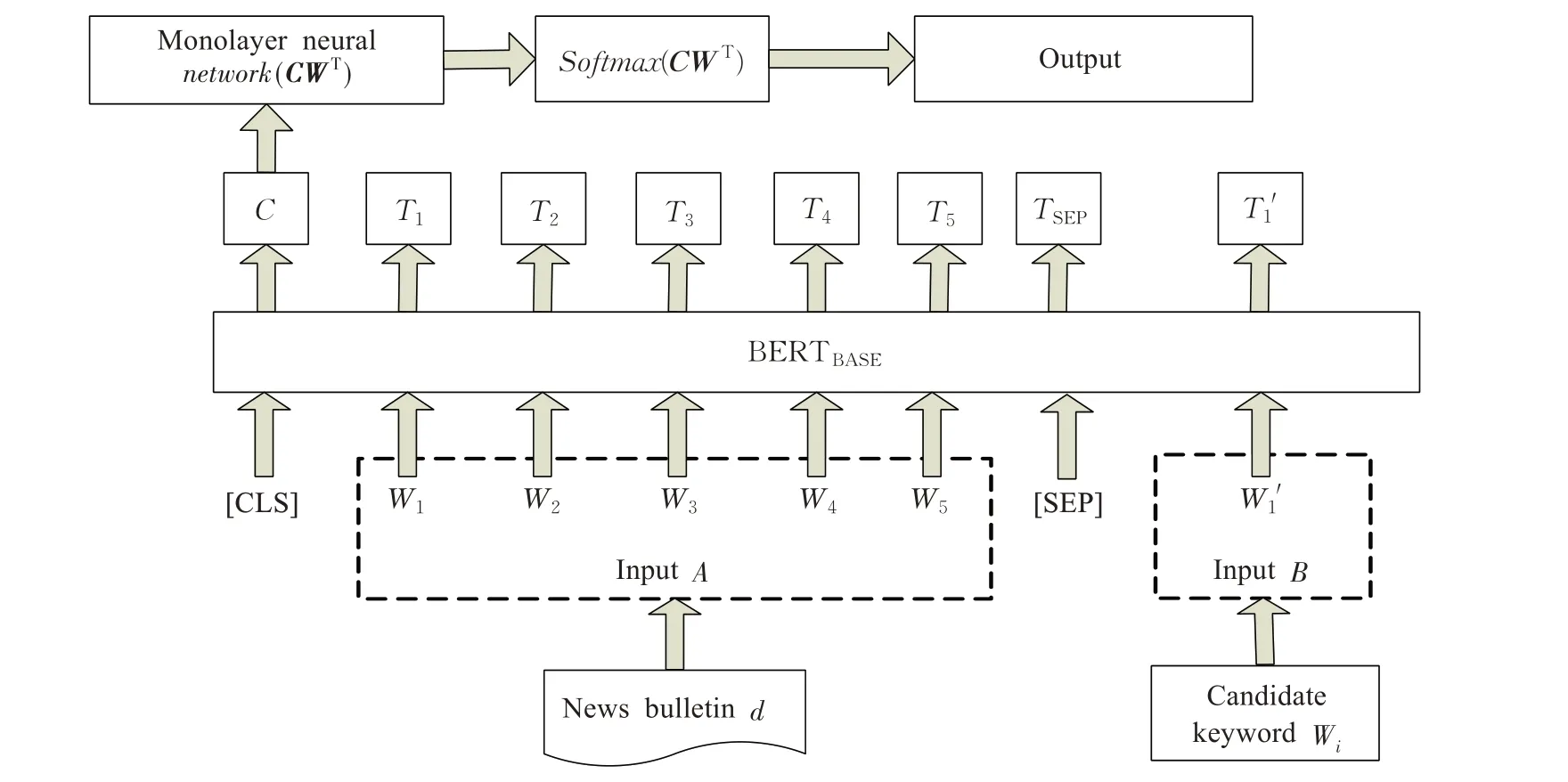
图3 新闻简报关键词判别模型示意图Fig.3 Keyword discrimination model for news bulletin
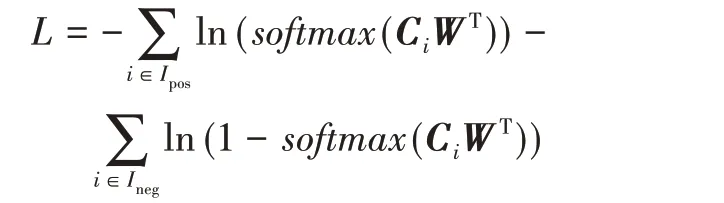
其中,Ipos为手工标注的第i篇新闻简报的关键词集,Ineg为手工标注的第i篇新闻简报的非关键词集。尝试用GBDT+LR作为分类器,并观察两者性能的对比。最终的关键词提取精度和召回率分别为0.90和0.85,如果用GBDT+LR,则分别为0.84和0.78。
2.1.2 新闻简报集群与热点事件抽取
新闻简报预处理结束后,下一步是提取热点事件。与Story Forest类似,这里所说的热点事件提取本质上是一个经过微调的新闻简报聚类过程,用于将主要内容和关键点上类似的简报分组到事件中。针对海量新闻简报聚类的高准确率要求,在新闻简报的二阶段聚类之前,提出了一种基于频繁项集的关键词图构建方法。将两阶段方法改进为三阶段方法。
首先,模型按时间对新闻简报流进行排序,并将其划分为固定大小的时间段(例如:24 h)。将每个时间段中最常见和重要的关键词(例如:重要性排名前10%)保留为事件特征。需要说明的是,这些是可变长度的单词序列(例如:“唐纳德·特朗普”“新型冠状病毒”“口罩”),如果某些关键词在时间段中非常频繁且重要,那么,就使用它们来对热点事件进行语义描述。
然后,为准确获得每个时间段中重要性高的关键词,引入了基于频繁项集的关键词价值分析方法。具体算法和步骤可参考文献[15],在此就不再赘述了。
根据选取出的关键词,模型会构建关键词图G,G中的每个节点表示选取出的关键词w,每条无向边eij表示wi和wj构成了频繁项集。接着,模型在关键词图中也利用边缘的介数中心性评分[10]来度量图中每条边的强度来进行社区检测。目的是将整个关键词图G分成C={C1,C2,…,C|C|},其中每个社区Ci包含了热点事件的关键词。还尝试了另一种基于Bi-LSTM+GloVe的关键词聚类方法。但是,与基于关键词频繁项集的社区检测相比,其性能不够理想。原因主要是使用Bi-LSTM+GloVe,往往会把语义相近的词聚在一起。然而,与专业领域的文章不同,在海量的中文新闻简报中,具有不同语义含义的关键词很可能在同一热点事件中同时出现。
获得关键词社区后,模型将计算每个新闻简报与每个关键词社区之间的余弦相似性。利用BERT-flow模型[16]将简报转换为向量表示。由于关键词社区是一个词袋,可以看作是一篇新闻文章。将每篇简报分配给相似度最高的关键词社区。需要注意的是,这里所说的最高相似度必须高于一个预定义的阈值n1。否则,该简报应该被剔除,因为它的内容与热点事件无关。至此,已经完成了第一阶段的新闻简报聚类,即这些新闻简报是根据筛选后的关键词社区进行聚类的。
模型接着在每个关键词社区中进行第二阶段的新闻简报聚类来获得细粒度的事件。这个过程称为热点事件抽取。事件只包含描述该事件内容且语义相近的新闻简报。为了产生更细粒度的事件,用Story Forest中的SVM作为分类器是不够的,因此采用BERTBASE模型来对该阶段的新闻简报聚类进行引导。具体来说,就是从一个预先训练好的BERTBASE模型开始训练,将其微调为确定一对新闻简报是否在讨论相同的热点事件的任务。首先,假设第i个关键词社区包含v个新闻简报的集合,Di={d1,d2,…,dv},在该集合中有总数为t个事件的集合E={e1,e2,…,et},满足下列条件:
第一个条件表示任意事件ej都是新闻简报集合D的幂集且不为空集。第二个条件确保事件不重叠。第三个条件表示每个新闻简报肯定属于事件集合E中的某个事件。
其次,手工标注了10 000多个新闻简报,包括8 800多个描述同一事件的新闻简报对样本和9 700多个描述不同事件的新闻简报对样本。在手工标注新闻简报对时主要关注的重点包括新闻简报内容的相似度、简报标题相似度、两个简报中首句的内容相似度以及简报发布时间接近程度等。
与上文使用BERTBASE模型的方法类似,模型的任务是获得新闻简报i和新闻简报j在描述同一事件的内容相似程度Sij(Sij=Sji)。将简报对分别作为句子A和句子B输入到模型中。为了保证不超过BERTBASE模型输入的最大序列长度512,选择每个新闻简报的前128个和后127个字符作为输入。同样的,使用[CLS]向量作为单层神经网络的输入,表示简报描述同一事件的内容相似程度。也是从一个预先训练好的BERTBASE模型开始训练,并使用交叉 熵损失将其微调到判断简报对是否描述同一事件的任务中:
其中Dpos为数据集中描述同一事件的新闻简报对集合,Dneg为数据集中描述不同事件的新闻简报对集合。
对于关键词社区中的每一对新闻简报,根据上述模型得出的预测结果来决定是否连接它们。因此,社区中的简报也将形成一幅图。模型应用前文的社区检测算法分割新闻简报图。显然,第二阶段的基于图的聚类会比Story Forest更加高效的,因为在第二阶段新闻简报聚类之前,进行了主题集群和关键词的筛选,因此,每个关键词社区中包含的简报数量要少得多并且概念和内容更一致。
综上所述,提出的基于关键词频繁项集和BERT的聚类方法,首先基于关键词的频繁项集将新闻简报分组到关键词社区,然后利用微调的BERTBASE模型分两阶段将每个社区中的新闻简报分组为细粒度的热点事件。对于每一个热点事件E,还利用BERT-flow模型生成事件中所有的新闻简报的联合词嵌入VE,并记录它所属的关键词社区的关键词集合WE,这将利于后续事件演变轨迹的实时生成。
2.2 事件演变轨迹的实时构建
从前文可得,每个关键词社区可以看作是一个子主题。给定每个社区中提取的热点事件集,以实时在线的方式将这些事件组织到多条事件演变轨迹中。每个热点事件发展的过程都由一个演变轨迹有向图表示,用于描述事件的发展过程。当一个新事件到来并给定一个已有的演变轨迹时,算法主要包括两个步骤:一是识别事件所属的演变轨迹;二是通过将新事件插入到正确的位置来更新演变轨迹。如果这个事件不属于任何现有的演变轨迹,算法将创建一个新事件的演变轨迹。
2.2.1 确定相关的事件演变轨迹
给定一组在t时段新的热点事件Et={e1,e2,…,e|Et|},和一个现有的在之前的t-1时间段内形成的事件演变轨迹集合Ft-1={P1,P2,…,P|Ft-1|}。模型的目标是将每个新的热点事件E∈Et分配给现有的事件演变轨迹P∈Ft-1。如果轨迹集合中没有匹配该事件的轨迹,那么将创建一条新的演变轨迹并将其添加到轨迹集合中。与现有方法不同,虽然也应用一个两步策略来决定一个新事件E是否属于已有的事件演变轨迹P。但是,正如2.1.2小节提到的是,事件E有自己的关键词集WE,也有自己的词嵌入VE。类似地,对于现有的事件演变轨迹P,有一个相关联的关键词集Cp,它是该轨迹中所有事件关键词集的并集,因此,利用BERT-flow模型生成事件演变轨迹的词嵌入Vp。
因此,利用VE和Vp计算热点事件E与事件演变轨迹P之间的余弦相似度,即cos(VE,Vp),从而替代了Story Forest的Jaccard相似系数。如果余弦相似度大于某一个阀值nc,将进一步检测事件E的关键字集与事件演变轨迹P的关键字集是否共享超过60%的关键词。如果两个条件都满足,就将事件E分配给演变轨迹P。否则,就认为事件与演变轨迹无关。如果事件E不属于任何一条轨迹P,那么模型将以事件E为初始事件节点创建一条新事件演变轨迹。需要强调的是,共享关键词的百分比与余弦相似度的阈值可根据实际情况灵活设置。当想识别出更多新事件的演变轨迹,可以将参数值设置高一些,反之则低一些。
2.2.2 更新事件演变轨迹
在确定了新事件E的相关演变轨迹P之后,将执行三种操作中的一种来将事件E更新到演变轨迹中:事件融合、事件扩展和事件演变轨迹新建。事件融合将新事件E合并到演变轨迹中的现有事件节点中。事件扩展是把事件E作为子节点连接到轨迹中的现有事件节点。最后,事件演变轨迹新建是指将事件E作为新的演变轨迹Pnew的根节点。模型会根据以下步骤选择最恰当的操作来处理新事件。
事件融合:如果新事件E与演变轨迹中的已有事件节点描述的是同一个事件,那么就将新事件E融合到已有事件节点当中去。利用2.1.2小节的BERTBASE模型来识别两个事件的形心新闻简报是否在描述同一事件。本文中,事件的形心新闻简报是指在热点事件中连接简报数量最多,并且该简报包含事件关键词集中的关键词数量最多。这与Story Forest定义的形心文档不同,因为在实际情况中,事件中不一定会出现与所有其他新闻简报都有连接关系的新闻简报。
事件扩展:如果新事件E不与任何现有事件相融合,模型将在事件演变轨迹P中找到其父事件节点,并把它加入到轨迹P中。算法根据三个因素计算新事件E与每个现有事件Ej∈P之间的连接强度:一是E与Ej之间的时间距离;二是两个事件之间的相容性;三是如果将E连接到轨迹中的Ej,能否保证事件演变轨迹的逻辑一致性。新事件E与每个事件Ej∈P之间的连接强度定义为:
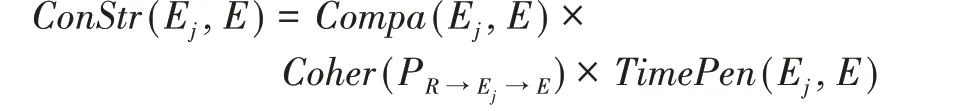
两个事件Ei和Ej之间的兼容性表示为:
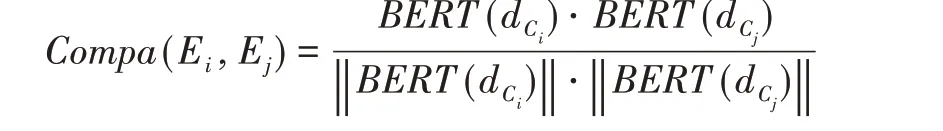
其中,dCi为事件Ei的形心新闻简报。此外,将Ej的事件演变轨迹定义为P中从根节点R开始至Ej本身结束的路径PR➝Ej。同样,添加到Ej的E的事件演变轨迹用PR➝Ej➝Enew表示。对于由路径E0➝…➝E|P|表示的演变轨迹P,其中E0:=R,其一致性衡量的是事件发展过程的主题一致性[7],定义为:
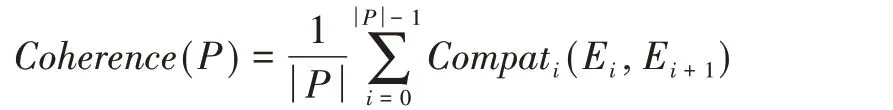
最后,事件Ei到事件Ej的事件演变关系在时间上应该遵循两个条件:一是事件i必须在时间上先于事件j;二是事件之间的时间间隔越大,它们之间发生事件演变关系的可能性就越小。为了更准确地定义时间窗口间的距离,定义了事件之间的时间先后关系,如表2所示。
根据表2所示的7种关系,假设事件i的时间窗口为Ti=[tsi,tei],事件j时间窗口为Tj=[tsj,tej],这两个时间窗口的距离可定义为:

表2 事件间的时间关系Table 2 Temporal relationships between events

另外,使用时间接近度来度量两个事件之间的相对时间距离,定义衰减函数为:
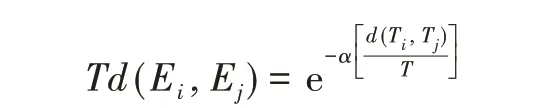
定义Ej与E的时间惩罚函数为:
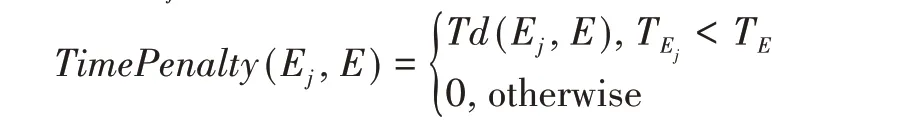
其中,TEj和TE分别是事件Ej和事件E的时间窗口。用式(7)来计算新事件E和每一个事件节点Ej之间的连接强度,并将事件E连接到最大连接强度的Ej中。如果最大连接强度低于阈值,则将E作为根节点新建一条事件演变轨迹,换句话说,新建事件演变轨迹是一种特殊的事件扩展。
3 性能评估
从中国主要互联网新闻提供商(腾讯、新浪和今日头条)收集约32 GB中文新闻简报数据,采用与Story Forest相类似的方法进行评估,从2020年1月3日到2020年5月5日,为期四个月,涵盖不同的主题,平均每天的简报数量为78 286份。在以下的实验中,使用的是前14天的数据进行参数微调,其余的数据作为测试集。
3.1 评估热点事件的提取性能
首先,评估用于热点事件提取的基于关键词频繁项集和BERT的新闻简报聚类过程的性能。手动为一个包含4 600个带有真实事件标签的新闻简报的测试数据集添加了注释,并将算法与LDA+AP[17]、KeyGraph[10]和Story Forest进行了比较,如表3所示。
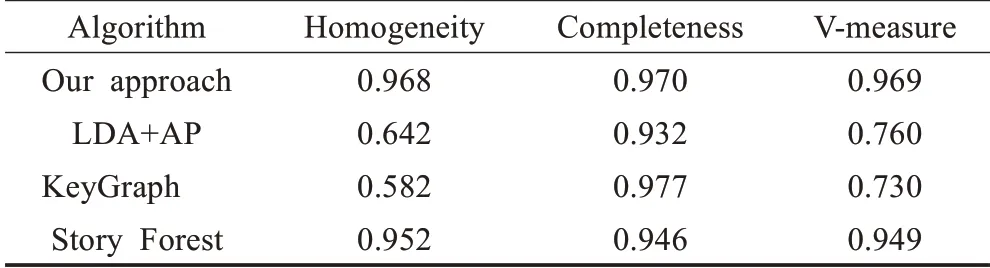
表3 事件聚类方法的比较结果Table 3 Comparison results of event clustering methods
由表3可知,与其他方法相比,本文的方法获得了最好的V-measure[18]值,部分原因是该方法获得了最高的Homogeneity得分,为0.968。这意味着提取的大部分热点事件都是高纯度的:每个事件只包含谈论同一事件的新闻简报。相比之下,LDA+AP和KeyGraph的Homogeneity得分要低得多。原因是采用了基于关键词频繁项集和BERT的聚类方法来将新闻简报分组为具有更合适粒度的热点事件。另外,Story Forest虽然也有较高的Homogeneity得分,但与当前方法相比,它缺少了预处理阶段的主题集群、关键词提取过程中对上下文语义结构的智能分析,以及关键词的过滤。
但是,Completeness比KeyGraph稍小一些,这是因为在使用BERTBASE进行监督的第二阶段基于简报图来抽取热点事件。考虑到Homogeneity的显著提高,Com‐pleteness的损失是可以忽略的。
3.2 与其他事件发展结构描述的对比
通过试点用户评估,评估了新闻数据集中不同的事件时间线和事件演变轨迹的生成算法。为了进行公平的比较,所有方法在生成演变结构之前都采用相同的预处理和事件提取过程,从数据集中检测到146条事件演变轨迹。唯一的区别是如何构造给定一组热点事件节点的事件演变结构。本文的方法与现有的Flat Cluster[19]、Story Timeline[9]、Story Graph[4]、Event Thread[3]以及Sto‐ry Forest进行比较。
首先,邀请了15名专家人员,包括新闻工作者、工科研究生导师和资深新闻读者,对不同方法给出了盲评的结果。每一篇文章都由5位不同的评估人员进行评估。当评估人的意见不同时,他们会讨论并给出最终的结果。评估人针对不同方案产生的5种不同结构分别回答了文献[8]中的5个问题:
(1)在每条事件演变轨迹中所有的新闻简报都与这条演变轨迹密切相关吗(是或否)?如果是的话,继续下一步。
(2)在每个事件节点上所有的新闻简报都真正描述相同的事件(是或否)?如果是的话,继续下去。
(3)对于不同的算法给出的每个事件演变结构,有多少条边正确表示了事件之间的连接?
(4)对于Event Evolution Trajectory、Story Forest、Event Thread和Story Timeline给出的事件演变结构,从根节点到任何子节点有多少条路径存在于图中?有多少这样的路径在逻辑上是连贯的?
(5)哪一种算法生成了最好的事件逻辑结构?
对于问题(3),为了保证评估的公平性,采用只保留n个最高的分数,其中n是代表图中事件的数量。
实验证明,在146条事件演变轨迹中,133条事件演变轨迹是纯演变轨迹(对问题(1)的回答“是”),还有125条事件演变轨迹只包含纯的事件节点(对问题(2)的回答“是”),因此,提取事件的最终精度(对问题(1)和(2)都回答“是”)为87.4%。
接下来,从三方面比较了不同算法输出的事件演变结构:事件之间的正确边缘,路径的逻辑一致性,以及不同事件演变结构的整体可读性。图4显示的是不同算法的错误边缘百分比的CDFs比较结果。正如所看到的,事件演变轨迹明显优于其他5种基线方法。如表4所示,对于62%的事件演变轨迹,每条轨迹的所有边缘都被认为是正确的,所有事件演变轨迹正确边的平均百分比为86.8%,Story Forest的为82.3%。相比之下,故事图算法给出的平均正确边百分比仅为42.4%。
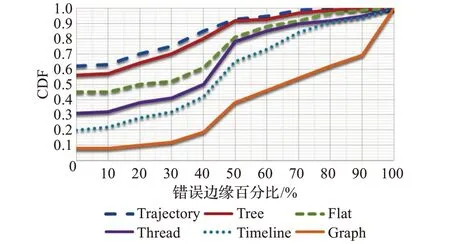
图4 错误边缘的百分比Fig.4 Percentage of incorrect edges

表4 事件演变结构生成算法的比较结果Table 4 Comparison results of event evolution structure generation algorithms
Event Evolution Trajectory综合考虑了新闻简报的上下文语意内容,保留了字数少但内容重要的新闻简报,增加了关键词特征的筛选、深入准确地定义了事件相关性、路径相关性和时间间隔,给出了比其他算法更好的结果,而其他算法只考虑了上述因素的一部分。
对于路径相关性,图5显示的是不同算法下不一致路径百分比的CDFs比较结果。事件演变轨迹提供了更多的连贯路径:提出的算法中,连贯路径的平均百分比为82.3%,Story Forest、Event Threading和Story Timeline的平均百分比分别为78.5%、52.1%和31.6%。需要说明的是,对于平面或图形结构,路径相关性是没有意义的。
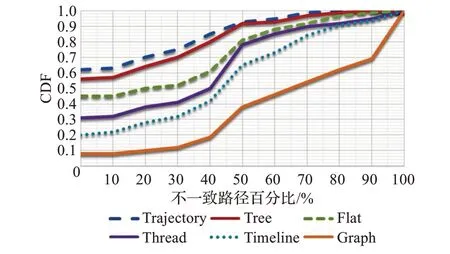
图5 不一致路径的百分比Fig.5 Percentage of inconsistent paths
图6显示的是不同演变结构的整体可读性。在133条事件演变轨迹中,116条事件演变轨迹的可读性最好,这比其他所有方法都要好得多。不同的算法可以生成相同的结构。例如,事件演变轨迹可以生成故事森林、平面结构、时间轴或与事件线程算法相同的结构。因此,不同方法给出的最佳结果的个数之和大于133。值得注意的是,Story Forest、Flat和Timeline算法也给出了112、77和45个最易读的结果,与文献[8]提到实验结果类似,这再次表明,现实世界中大部分 新闻简报描述的事件演变逻辑结构可以用简单的平面或时间轴结构来描述,复杂的图形通常是不必要的。
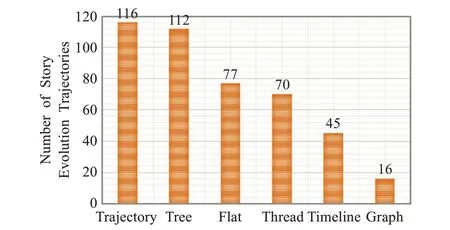
图6 被评为最易读结构的次数Fig.6 Number of times rated as most readable structure
进一步考察了事件演变轨迹生成的图结构。尽管树形结构的事件演变轨迹包含了平面结构和时间轴结构,但是在146个事件演变过程中,事件演变轨迹生成了56个平面结构和15个时间轴结构,而剩下的75个结构仍然是树形结构,如图7所示。虽然这与Story Forest的结构类似,但事件演变轨迹更加强悍,可以称之为Story Forest的加强版,能够为真实世界的热点事件演变生成更多不同的结构,当然,这也取决于事件演变的逻辑复杂性。
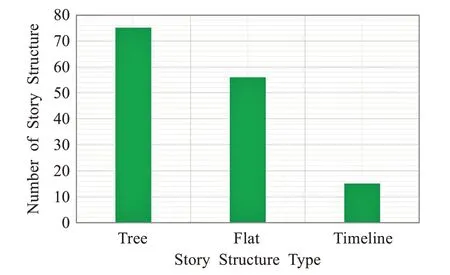
图7 不同表示结构的数量Fig.7 Numbers of different story structures
4 结束语
本文描述了在Story Forest基础上改进得来的新闻简报内容组织模型Event Evolution Trajectory,该模型可以从海量的热门话题和热点新闻中发现热点事件,并以合理的事件演变轨迹实时组织并呈现事件的演变过程。本文的模型是专门为快速处理海量新闻简报数据而设计的,这些数据的结构最终以树形、平面结构或时间轴的结构呈现。提出了一种基于关键词频繁项集和BERT的新闻简报聚类算法,可以从海量新闻简报中提取细粒度的事件。每当新的简报数据到来后,本文的模型能将事件进一步组织到事件演变轨迹中。以32 GB的中文新闻数据为基础进行了详细的试点用户体验研究。另外,提出的模型不局限于某种语言,可以方便地扩展到其他语言。广泛的研究结果表明,本文的聚类过程比现有的算法更有效。通过将事件演变轨迹的结构与更复杂的故事图和Story Forest等相比,证明了该系统生成的事件演变结构对广大读者更具有吸引力。
猜你喜欢
加油站服务指南(2022年6期)2022-07-28
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
铁道通信信号(2019年6期)2019-10-08
车迷(2019年10期)2019-06-24
现代装饰(2018年5期)2018-05-26
快乐语文(2018年7期)2018-05-25
中国三峡(2017年2期)2017-06-09
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
