
基于OpenVX并行处理器的微程序控制*
2022-12-22 11:32邢立冬
计算机工程与科学 2022年3期
张 珂,李 涛,,邢立冬
(1.西安邮电大学计算机学院,陕西 西安 710121;2.西安邮电大学电子工程学院,陕西 西安 710121)
1 引言
在数字系统中,微程序控制可以简化控制逻辑,具有控制电路规整、功能灵活可变和可升级维护的特点,甚至在相近的系统之间具有可配置复用等优点。微程序控制器作为整个系统控制逻辑的核心部件,制约着整个系统的性能,因此对其结构进行探讨和优化有着重要意义。基于OpenGL图形标准的Khronos组织制订了机器视觉处理的基本层标准OpenVX 1.3[1],设计了一款能够实现OpenVX 1.3中Kernel函数的通用并行可编程处理器,本文主要研究微控制器在OpenVX处理器上的应用。
目前研究人员针对微控制器模块设计问题已做了大量研究。文献[2]采用分组直接控制方法设计微程序控制器,减少了存储容量,降低了微处理芯片的成本。文献[3]提出页式微程序ROM设计,减少了微程序中ROM的位宽。文献[4]通过隐含下址编码、流水和预译码等设计技术,提高了微码的执行效率。文献[5]提出了“内部计算机”采用电路逻辑,“外部计算机”采用程序逻辑观点。文献[6]提出了一个简单的“微程序化计算机”,给出了总体结构和微指令格式,最后给出了“执行机器语言指令的微程序”。文献[7]采用了微指令预取的设计,对微指令的执行过程进行了加速处理。
本文针对文献[4]中微控制器解析命令过程导致内部存储量大的问题和文献[2,5-7]中转移步骤复杂且功能不是很完善的问题,首先基于相联逻辑原理[8]设计了一种相联存储器,提高了控制存储器CS(Control Storage)的利用率,减少了存储器面积;然后基于判断条件分组匹配的方法设计了转移地址产生模块,提高了转移地址产生速度;最后基于OpenVX处理器映射标准Kernel算法,进而优化微指令。
2 OpenVX处理器
本文设计的OpenVX处理器包含4×4个处理单元PE(Processing Element)、路由和微控制器MCU(Micro-program Controller Unit)。控制器的主要功能是通过操作字段和顺序控制字段产生控制信号,实现对数据通路的控制。处理器总体结构如图1所示。
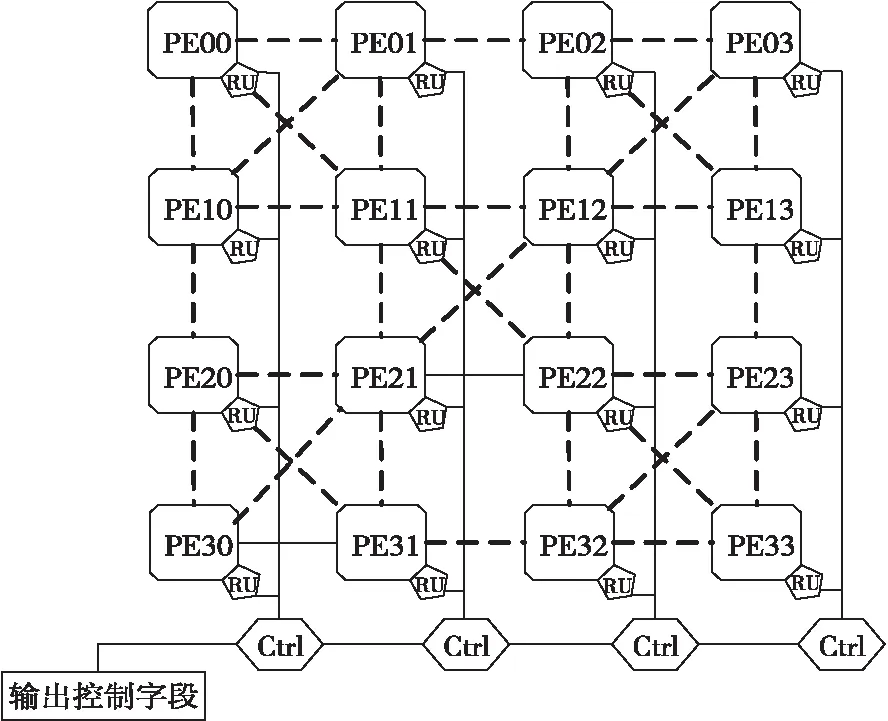
Figure 1 Overall architecture of processor OpenVX
处理图像时,MCU向PE发送指令,每个PE包含8个ALU、2个定点乘法器、2个浮点乘法器、1个定点除法器、1个浮点除法器、1个内部交叉开关、8个32×16的寄存器堆和寄存器堆的访存模块。PE之间的数据交互由控制信号和路由完成。其中,控制器发出控制指令从寄存器堆中读取需要处理的像素信息,将数据发送给PE中的运算单元进行计算。通过控制运算单元中逻辑运算器的数据流向,完成在固定的硬件资源上实现复杂图像处理的功能。
3 OpenVX处理器的微控制器
3.1 微控制器整体结构
在数字系统中,相比于硬布线控制,微程序控制可以简化有规律的控制逻辑,便于检查设计中的错误,即使出现错误,也易于增加和修改指令功能,灵活性较强。其基本思想是把操作控制信号编写成微指令,存放到一个只读存储器中,依次读出这些微指令,从而产生整个处理器所需要的各种控制信号,使相应的部件执行规定的操作[9,10]。
本文自主设计了OpenVX并行处理器微控制器,其结构如图2所示,主要包括:起始地址产生模块、转移地址生成模块、转移信号分组和微程序存储器(包含数据通路控制信号)。
相比于传统的微控制器,本文设计的微控制器具有以下3个特点:可编程程度高、模块化程度高和适用性程度高。微程序提前存储在控制存储器CS中,机器启动后,给出控制存储器的首地址。第1条微指令是取指微指令,当取出一条指令时,首先通过相联存储器得到该指令的微程序的起始地址,输入给下地址选择器,得到控制存储器中相应的微指令。接着根据条件组中条件信息选取转移类型字段中地址编号,选择一个地址做为下一条微指令的地址。最后将操作信号送往数据通路,从而控制整个系统。
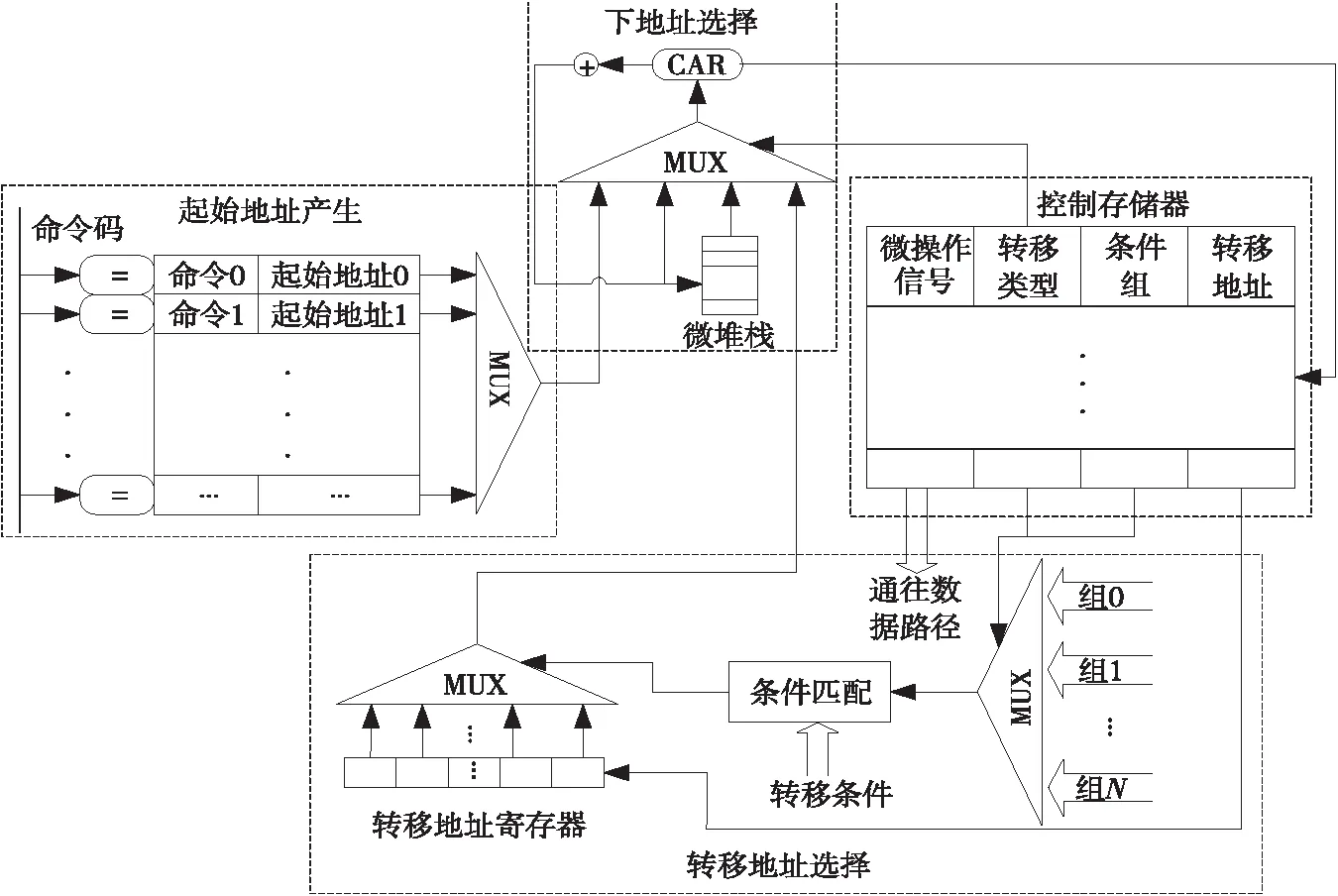
Figure 2 Structure of MCU

Figure 3 Group field direct coding
3.2 微指令格式
微程序控制器除了结构的设计和优化,微指令的设计也是至关重要的,OpenVX处理器中微操作命令数在300个以内。因此,尽可能地缩短控制字段长度能有效减少控存容量,提高指令执行效率。
本文遵循以下原则进行微指令格式设计:
(1)微指令字宁短勿长;
(2)微程序长度宁短勿长;
(3)意义明确,便于修改;
(4)执行速度快。
具体采用分组直接控制法中的分组思想与字段直接编码法相结合的方式,格式如图3所示。
假设将微指令分为5组,每组有10条微指令。在操作控制字段中,组选择字段中用A~E表示5组不同的微指令位,1~10表示10个微命令位,A1~A10,B1~B10,…,E1~E10表示输出的微操作。除了组选择字段外,其余控制字段采用字段直接编码方式。例如共有24个微命令,构成了8个互斥类,即分为8段。每段中间有一个空位表示不做任何操作。条件组字段决定下一步执行哪条微指令,以及要采取的操作,操作与微指令本身相关;转移类型字段是当微程序出现分支(即出现条件转移)时,通过条件判断和状态返回的信息修改微地址内容;下地址字段给出了当满足转移条件时,接下来应执行的微指令地址,否则顺序执行。
4 函数的微程序设计方法
4.1 操作指令格式
本文根据OpenVX像素处理的5类函数:点函数、局部处理函数、全局参数抽象处理函数、迭代处理和跟踪处理函数,设计的操作操作指令格式。设计指令格式共18位,即5种类型(3位)、31个函数(5位)和起始地址(10位)。在外部设置一个17×26的寄存器堆,用来存放储操作码及其对应的起始地址。操作指令格式如图4所示。

1715141090OpcodeTypeMainAddress
图4中,OpcodeType表示5种函数类型;Main表示具体的函数操作码,比如Gaussian、Sobel和Canny等,Address表示对应该指令的地址。
4.2 函数的微程序具体设计
将函数映射到微程序的主要挑战是微指令的设计,总体的设计格式已在3.2节中进行了说明,本节详细介绍每条微指令中各字段所代表的控制信号,并通过设计举例进行验证。微指令字长336位,具体意义如图5所示。

309位21位4位2位操作控制字段条件控制字段转移类型字段下地址字段
操作控制字段包括GS、输出配置OC(Output Configuration)、指令编码IC(Instruction Coding)、寄存器堆编号RHN(Register Heap Number)、PE编号PE_NUM(PE Number)和移位信号SS(Shift Signal)。每个PE中设计了8个运算单元,所以微指令设计8组操作控制信号。下面以操作控制字段为例,详细介绍每个字段的定义,具体如表1所示。
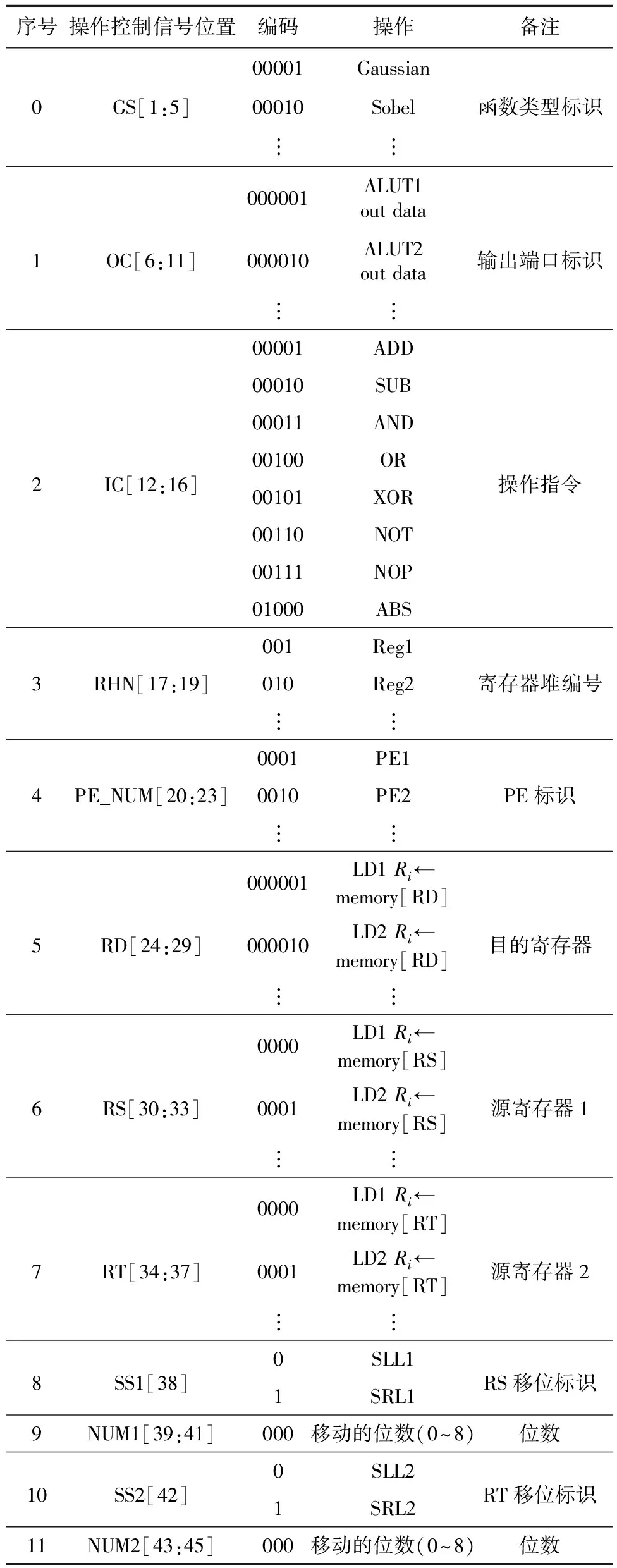
Table 1 Format of operation control field
下面以Canny算法为例进行分析,其流程如图6所示。
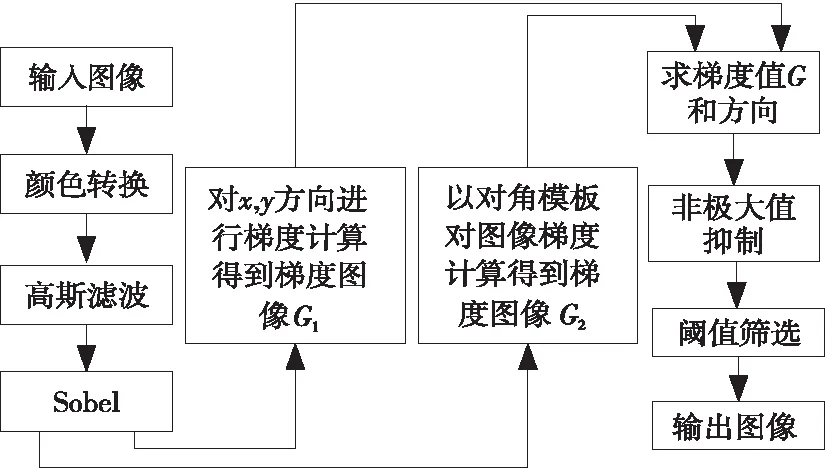
Figure 6 Flow chart of Canny algorithm

Figure 7 Take number instruction types
接着采用Gaussian 5×5进行滤波,以第1次取的数据为例,说明Gaussian滤波处理流程。具体控制流如图8所示。假设Xi(i=1,2,3,…)代表从寄存器堆中取出的像素数据。将数据发送至PE1进行运算,X1和X5由ALU1进行加法运算,处理完的中间结果写回1号寄存器堆中的地址,此操作的微命令格式为:ADD(00011)RHN(001)PE_NUM(0001)R3(0011)R1(0001)R5(0101)。中间结果继续发送到PE1中进行运算,其他像素处理方式相同。一组25个像素需要5行微指令,深度为16,则需要5×16=80条微指令。然后使用Sobel 5×5进行边缘检测,得到G1和G2。因都属于卷积操作,控制流程相同,不再进行说明。

Figure 8 Control flow using Gaussian 5×5 filter
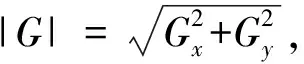
通过条件控制字段,当且仅当某一像素梯度大小大于或等于其垂直于边缘处的像素梯度时,将其保留为潜在的边缘像素。例如,如果像素的方向是0度,只有当它的梯度大小大于与它成90度和270度的像素的梯度大小时,才会被保留。如果一个像素通过这个条件被抑制,那么它在最终的输出图像中一定不能作为边缘像素出现,即在最终的输出图像中它的值必须为0。
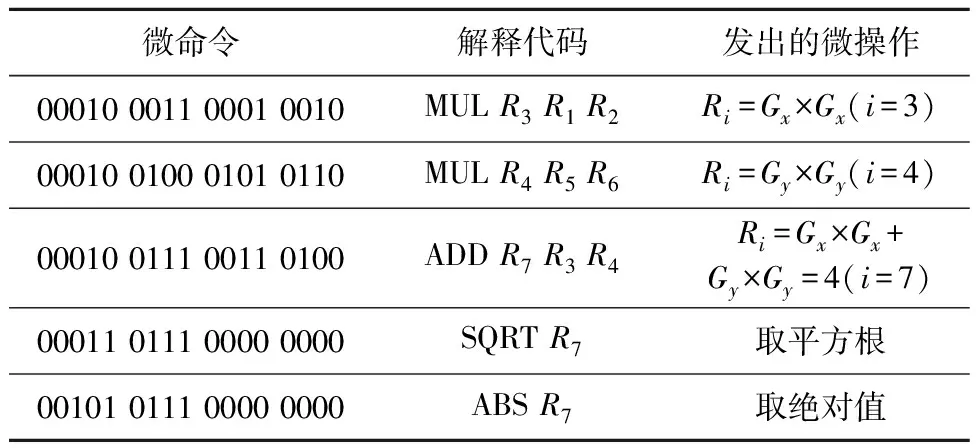
Table 2 Gradient size microcommands
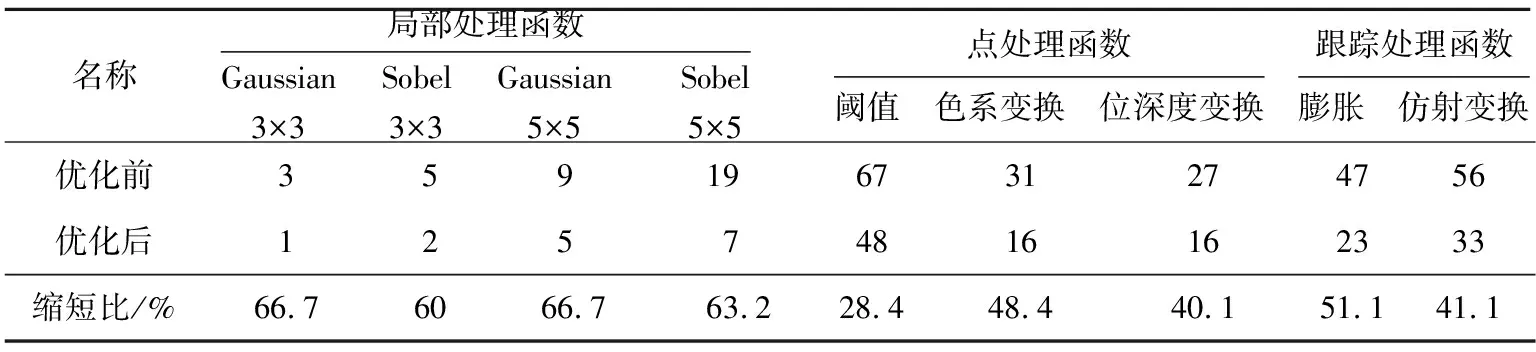
Table 3 Comparison of microprogram optimization results
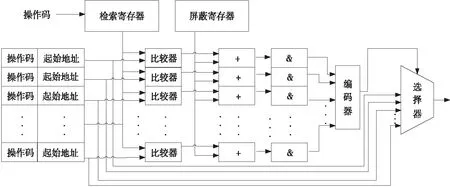
Figure 10 Structure of starting address generation module
输出图像中的最终边缘像素通过双阈值迟滞过程进行识别。所有大于高阈值的保留像素在最终输出图像中被标记为已知边缘像素(值为非零),所有小于或等于低阈值的像素都不能在最终输出图像中标记为边缘像素。
5 硬件结构和指令优化
OpenVX1.3中函数类型较多,对像素的处理也不尽相同,比如卷积操作、逐像素操作等等。微程序的编写具有一定的复杂性,本文主要从硬件资源和指令优化2方面进行优化,硬件资源优化主要体现在起始地址产生模块和转移地址模块,指令优化从数据相关性、增加辅助操作字段和子程序设计等3方面进行,如图9所示。
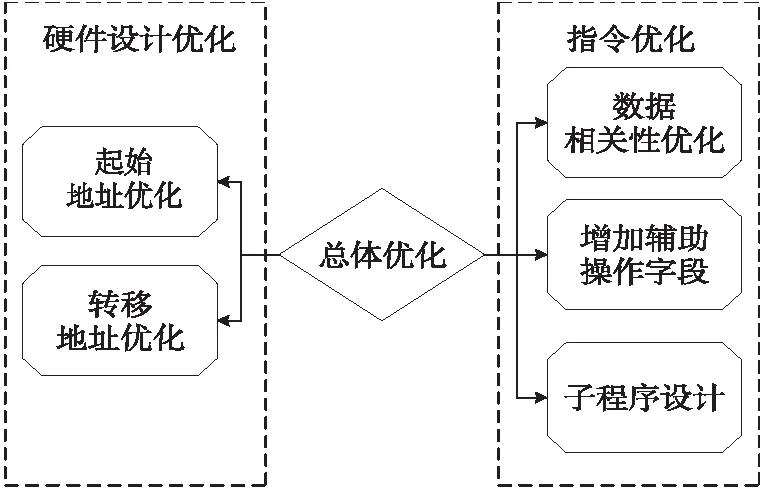
Figure 9 Optimization contents
5.1 起始地址产生模块优化
起始地址产生模块优化采用相联存储器加辅助电路设计,如图10所示。与指令码嵌入方式相比,除了具有存储功能外,还具有信息处理功能,它能根据内容的特征并行查找存储单元,显著提高查找速度。
综上所述,现如今,国民经济正在持续不断的发展着,人们对于自己居住环境的要求也是更加严格了,特别是极为重视对建筑中的水电安装这一工程。在对建筑工程进行建设的过程中,水电安装这一工程是非常重要的,在建筑工程中水电安装这项技术决定着人们在居住环境上舒适的程度。本文对建筑水电安装工程技术创新措施加以分析,指出工程技术之中存在着的问题,然后并指出相应创新的措施。使工程的质量得到提升,使居民在生活上的水平得到有效的提升。
存储体由寄存器堆构成,检索寄存器存储输入的操作码,将寄存器的内容和存储体中每一单元的内容进行比较,将比较结果中的不关心位屏蔽掉,屏蔽之后的结果进行按位与运算。此时,如果比较结果相同,那么按位与后的结果是1,否则是0。然后,对所有结果进行编码,编码结果作为选择器的选择信号,选择器的输入为存储体每一个单元的内容。最后对选择器的输出进行截位,得到最终的微程序起始地址。
通过列举Gaussian 3×3、Sobel 3×3、Gaussian 5×5、Sobel 5×5、阈值、色系变换、位深度变换、膨胀和仿射变换等函数分析控制存储器利用率。9条指令分别对应的微指令条数为1,1,5,5,48,16,16,23和33。公共操作的空指令和停机指令各需要1条微指令,取数指令需要64条微指令,间接地址判断微程序需要2条微指令,取命令微程序需要3条微指令。
通过采用指令码嵌入方式进行测试,控制存储器需要占用的大小为112 221 bits,由所有机器指令微程序与公共操作微程序组成。而起始地址产生模块采用相联存储器设计,12条指令,操作码5 bits,微指令地址7 bits,则相联存储器所用的存储体宽度为12 bits,深度为22,其占用空间大小为(5+7)×12=144 bits。此时微程序占用控制存储器的大小为(1+1+5+5+48+16+16+23+33+1+64+2+3)×331=72158 bits,相比指令码嵌入方式控制存储器利用率提高了35.7%。
5.2 转移地址产生模块优化
一般微程序控制器一次只能判断一个条件,当所有的条件判断完成后发出控制信号。如果要产生正确的地址就需要一步一步进行判断,转移速度很慢。本文采用条件分组的方式快速匹配出转移地址,如图11所示。具体做法是:在复杂数字系统的命令解析中,一个操作需要判断的条件有很多,将所有的条件分为若干组,每组可分配2~6个条件,条件可分在同一组的原则是这几个条件互斥;通过组选择字段选择出一个条件组,再与来自数据路径的状态寄存器进行匹配,看条件是否满足,选择出2~6个地址中的一个,使得在一条微指令里完成2~6个条件的判断,减少转移地址产生步数。
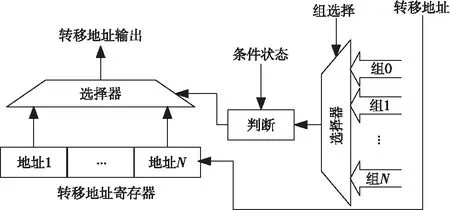
Figure 11 Logic of transition address generation module
采用上述方法,以公共微指令为例,接收到指令的可能是5种函数类型,首先需要判断当前输入的参数Cmd_In[14:10]代表的函数类型。当满足Cmd_In==点函数(001),选择微指令下地址字段中的地址AD1送往控制地址寄存器CAR,作为下一条微指令的地址,执行相应操作。如果都不满足,则选择顺序取微指令,CAR+1作为下一条微指令的地址,该微指令执行完后,就返回到取命令操作微程序,该命令的解析工作完成。该命令有5个操作,可以分为4个条件,采用传统的微程序控制器,最多需要判断4次才能转到相应的操作上,采用上述描述的条件分组方式,每组内并行判断,只需要1条微指令。
5.3 指令优化
从数据依赖性方向进行分析,微指令中发出的微命令可能同时对存储在同一个寄存器中的数进行操作,产生时延,减缓指令执行速度。为了减少指令条数,缩短微指令长度,首先根据数据相关性,对指令进行排序,提升运算速率。以在高斯滤波函数设计为例,部分汇编程序指令如下所示:
1.ADDR26,R1,R5
2.ADDR32,R32,R33
3.ADDR27,R21,R25
4.ADDR26,R26,R27
5.ADDR28,R2,R4
6.ADDR2,R28,R29
7.ADDR29,R6,R10
8.ADDR28,R30,R32
9.ADDR30,R16,R20
10.ADDR29,R32,R33
11.ADDR31,R22,R24
12.ADDR30,R26,R27
13.ADDR33,R31,R32
14.ADDR31,R28,R30
15.ADDR32,R3,R3;SLLR3,2;SLLR3,1
16.ADDR33,R11,R11;SLLR11,2;SLLR11,1
上述指令按照序号顺序执行,每行微指令可以执行8个操作指令,但是数据之间存在相关性,其中,第8条指令和第9条指令中都存在R30,只有第9条指令完成后才能执行第8条。假设在t1和t2时刻完成上述指令运行,根据本文设计的微指令格式,可对上述16条指令进行排序,分为2组:(1,3,5,7,9,11,13,15),(2,4,6,8,10,12,14,16),分别在t1和t2时刻执行,这样减少了指令条数,提高了执行速率。
微指令格式的优化方面,在微指令的基本功能外,增加辅助操作字段,采用组合型微指令,可进一步提高微指令执行的并行度,缩短微程序长度。比如:原本每条微指令需要增加5位移位操作字段,本文设计将移位操作嵌入到加法操作中,使用1位就可完成移位操作。
最后运用子程序设计方法对微指令进行优化。OpenVX函数中存在许多重复的操作,如从寄存器堆中取数操作、模板操作等,通过子程序设计方法实现这些函数。以Gaussian函数中取数操作为例,每条指令执行完后,都有取数操作的微命令。通过设置取数操作子程序,使Gaussian 5×5函数微指令条数从9条优化到5条。优化前后对比结果如表3所示,微程序总体缩短31.7%。
6 仿真结果与性能分析
6.1 仿真结果
本文采用XILINX公司的20 nm XCVU440芯片搭建FPGA板级验证平台进行验证,实验结果如图12所示。

Figure 12 Comparison of image results
图12a是原图,图12b为高斯处理处理后的图像,图12c为Sobel函数处理后的图像,图12d为Canny函数处理后的图像。分别统计出部分函数每秒处理的图像帧数,可以达到像素快速刷新的效果,具体结果如表4所示。

Table 4 Number of image frames processed per second at different resolutions
6.2 性能分析
对Gaussian 3×3、Sobel 3×3、Gaussian 5×5、Sobel 5×5、阈值、色系变换、位深度变换和仿射变换等函数的微程序转移步数进行统计,结果如表5所示。与传统的转移地址产生模块即单组判断条件进行对比,使用本文设计的转移地址产生模块,可以减少50%转移步数。
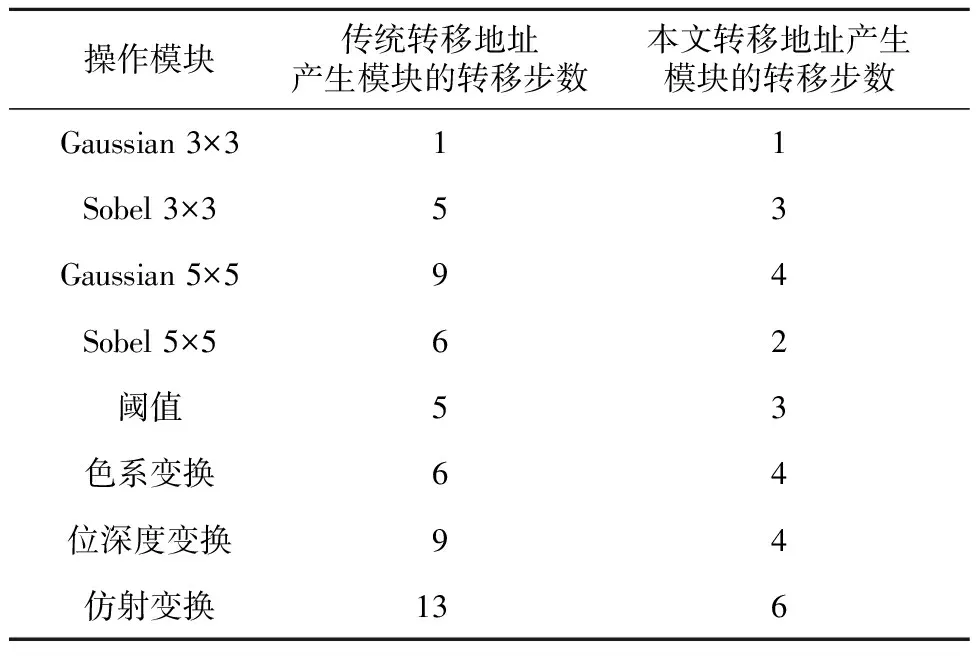
Table 5 Comparison of transfer steps
通过优化微指令,提高控制存储器利用率,减少转移步数等,使处理器整体性能得到了提高。以下对OpenVX并行处理器处理速度进行分析,通过与文献[11-13]设计的Sobel函数专用图形处理器进行对比,本文处理器所用时间较短,处理速度较快。对比结果如表6所示。

Table 6 Comparison of processing time
7 结束语
本文设计了OpenVX并行处理器的微程序控制器,基于传统的微程序控制器,对起始地址和转移地址产生模块进行优化,使控制存储器利用率提高了38.7%,平均转移步数减少了50%。最后通过数据依赖性关系、增加辅助字段和设计子程序等对指令进行优化,提高了执行效率。另外,通过手动优化微指令,出错率较高,今后的研究将重点考虑自动优化微指令工具设计,以进一步进行指令优化。
猜你喜欢
电脑爱好者(2021年23期)2021-12-08
北京航空航天大学学报(2021年6期)2021-07-20
数码世界(2020年12期)2021-01-20
学校教育研究(2020年11期)2020-06-08
办公室业务(2019年13期)2019-08-01
科技传播(2015年20期)2015-03-25
新世纪图书馆(2014年7期)2014-09-19
新世纪图书馆(2014年7期)2014-09-19
环球时报(2014-06-18)2014-06-18
汽车零部件(2014年2期)2014-03-11
