
基于PaddleFL联邦学习框架的学生学习数据隐私计算模型构建
2022-12-21 05:52陈桂芳
河北软件职业技术学院学报 2022年4期
雷 莹,纪 娟,陈桂芳
(1.四川华新现代职业学院 信息工程学院,成都 610107;2.四川开放大学 高职院,成都 610073)
0 引言
目前,混合教学模式是高职院校普遍采用的一种教学模式,该模式结合了传统面授课和在线教学的优势,切实提高了教学效率[1]。依托超星学习通平台等进行教学改革,创建了丰富的在线教学资源,经过一段时间的教学积累,平台上也形成了学生的学习数据,结合线下学习情况,描绘出了学生的学习行为画像。随着人工智能和深度学习的发展,基于大数据的分析和运用可以发挥巨大的价值,但是仅仅使用本校的数据存在数据量不足的问题,预测结果不够准确。然而,不同学校的数据融合应用存在一定的难度,出于对学生隐私数据的保护,也增加了校际数据共享的难度。如何在保护好隐私的基础上,安全、可靠地融合多方教育数据,进行联合建模,发挥其蕴藏的价值是一个值得研究的问题。
1 多方数据协作与隐私计算
1.1 隐私计算的概念和现状
隐私计算是指在提供隐私保护的前提下对数据的价值进行充分挖掘的技术体系,多个参与方在不泄露各自数据的前提下,通过联合计算技术对所拥有的数据进行联合机器学习和联合分析。隐私计算的参与方既可以是同一机构的不同部门,也可以是不同的机构。在隐私计算框架下,参与方的数据明文不出本地,在保护数据安全的同时实现多源数据跨域合作,可以破解数据保护与融合应用难题[2]。隐私计算体系架构如图1所示。

图1 隐私计算体系架构
1.2 隐私计算的主要作用
1.2.1 防范数据泄露
随着云计算、物联网与大数据等技术的快速发展,各种平台及服务基于用户的操作习惯和行为偏好对数据进行收集与分析,并提供个性化服务。在提供了便利的同时,个人信息遭泄露的事件也频频发生。
由于数据存在分散性,数据通过各种途径在不同的组织机构和信息系统中产生,同时,数据的可复制性也使得数据一旦分享出去就失去了对数据的所有权和控制权。因此,数据的拥有方往往无法、也不能够通过安全可信的方式进行分享,造成数据难以共享应用,存在“数据孤岛”的问题。隐私计算在很多应用场景,通过密码学算法、明文不出本地等手段,可以有效地提升信息的保护水平,降低个人信息在应用过程中泄露的风险。
1.2.2 提高数据协作的效率
借助隐私计算技术,能够有效保护自身的数据,实现数据可用不可见,从而促进行业企业的跨界数据合作。隐私计算在无需共享明文数据的前提下,能够帮助不同企业和机构进行联合分析,实现数据融合应用,同时在数据协作的过程中履行数据安全和合规义务,实现生态系统内的数据融合,推动企业自身、产业层面的数据价值最大化。
1.3 隐私计算技术与联邦学习框架
隐私计算技术体系分为差分隐私、同态加密、多方安全计算、零知识证明、可信执行环境、联邦学习等技术。各方向技术特点不同,适用于不同场景,其中联邦学习更适用于保密性要求不高但数据量大的模型训练。在本课题中,将对学生学习数据及毕业后的就业数据进行分析,要求的数据量较大,因此选择联邦学习技术。
联邦学习的本质是一种机器学习技术与框架,它是以一个中央服务器为中心节点,在数据不出本地的情况下,联合多方数据源建模,提供人工智能模型推理、更新及服务(如图2所示)。中央服务器首先生成一个通用神经网络模型,各参与方将这个通用模型下载至本地,并利用本地数据训练模型,将训练后的模型更新上传到中央服务器,通过将多个参与方的更新内容进行融合来优化初始通用模型,再由各个参与方下载更新后的通用模型进行上述处理,这个过程不断重复直至达到某一个既定的标准。

图2 联邦学习框架
根据参与方之间数据分布的不同,联邦学习可分为三类:横向联邦学习、纵向联邦学习和联邦迁移学习[3]。
1.3.1 横向联邦学习
横向联邦学习的本质是样本的联合,适合各参与方的业务逻辑相同或相似,但用户重叠较少的场景,即样本数据的特征重合较多而数据量较少。例如,银行行业与保险行业中,同企业或不同地区的同行业的业务是相同的,但是用户不重合。故横向联邦学习是以样本联合为基本思想来进行模型训练的,如图3所示。
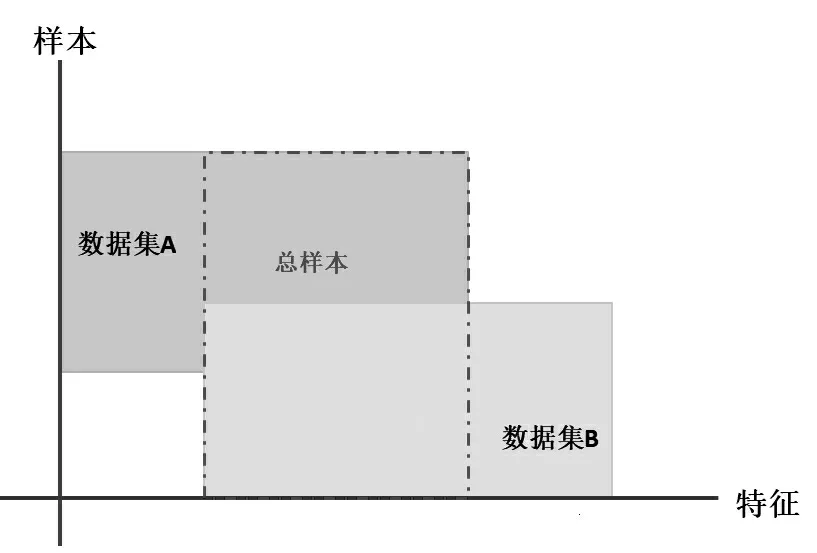
图3 横向联邦学习
1.3.2 纵向联邦学习
纵向联邦学习的本质是特征的联合,适合各参与方的样本数据重叠多,但是特征重叠较少的场景,即各个参与方的用户相似而业务逻辑不同。例如,同一地区的银行行业和零售行业,本质上各自的用户都是该地区的居民,但他们的业务逻辑不同。故纵向联邦学习是以重叠用户在不同业务逻辑下的特征联合为基本思想来进行训练的,如图4所示。

图4 纵向联邦学习
1.3.3 联邦迁移学习
联邦迁移学习适合各参与方的样本数据和样本数据特征重叠都较少的场景,即各个参与方的用户重叠较少,业务逻辑也不同的情况,主要适用于以深度神经网络为基模型的场景。
联邦迁移学习要求各参与方在样本加密对齐的基础上对各自的梯度、权重及损失进行计算,通过加密上传至中心服务器,中心服务器基于上传的数据进行聚合并调整通用训练模型,各参与方下载并解密进行训练,如图5所示。

图5 联邦迁移学习
2 PaddleFL联邦学习框架
2.1 PaddleFL概述
PaddleFL是一个百度开发的基于PaddlePaddle的开源联邦学习框架。研究人员可以很轻松地用PaddleFL复制和比较不同的联邦学习算法。PaddleFL可提供很多联邦学习策略及其在计算机视觉、自然语言处理、推荐算法等领域的应用。此外,PaddleFL还将提供传统机器学习训练策略的应用,如多任务学习、联邦学习环境下的迁移学习。
2.2 PaddleFL框架设计
2.2.1 PaddleFL解决方案
PaddleFL主要提供两种解决方案:Data Parallel和Federated Learning with MPC(PFM)。通过Data Parallel,各数据方可以基于经典的横向联邦学习策略(如FedAvg,DPSGD等)完成模型训练。PFM是基于多方安全计算(MPC)实现的联邦学习方案。作为PaddleFL的一个重要组成部分,PFM可以很好地支持联邦学习,包括横向、纵向及联邦迁移学习等多个场景[4]。既提供了可靠的安全性,也拥有可观的性能。
2.2.2 PFM训练和推理任务
(1)编译时
确定MPC环境:指定MPC协议,并配置网络环境。这里使用的是ABY3[5]协议。
用户定义训练任务:根据PFM提供的安全接口,定义集齐学习网络以及训练策略。
(2)运行时
运算节点:计算节点是与计算方相对应的实体。在实际部署中,它可以是裸机、云虚拟机、docker甚至进程。PFM在每次运行中只需要3个计算节点,这由底层ABY3协议决定。Paddle Encrypted程序将在所有3个计算节点上并行部署和运行。
基于MPC的算子:PFM为操作加密数据提供了特殊的算子,这些算子在PaddlePaddle框架中实现,基于像ABY3一样的MPC协议,在运行时PFM的算子将被创建并按照顺序执行。
3 构建隐私计算模型
3.1 研究方案设计
本课题选取了2021年参加实习的高职院校计算机专业群的3个专业,15个教学班,共679名学生作为研究对象,共两个学期的数据(如表1所示),主要根据学生的学习数据对毕业后的情况进行预测,从而在学习过程中对学生的学习行为进行预警与干预。。

表1 在校学习数据
所选取数据中,学习通数据包括课程视频、章节测验、章节学习次数、讨论、作业、考试、签到、课堂互动、分组任务等,其中章节测验、作业、考试等反映学生“知识输出”能力,占比为50%,在一定程度上反映了学生的专业技能素养;课堂互动、分组任务、讨论等反映“互动交流”的能力,与毕业后学生的沟通协调能力有较大的关系,属于企业所需要的软素质,占比为35%;而课程视频、章节学习次数、签到等反映学生“知识输入”的指标所占比重较小,仅为15%。
期末成绩为学生总成绩的平均分,其中既包括“职业英语”“大学体育”等公共基础课,也包括素质拓展选修课,以及专业通识课、专业技能必修课、专业技能选修课等,反应了学生在本学期的整体学习情况。
素质学分在学生的学习过程中进行统计,包括学生技能竞赛得分、社会实践、集体活动等,每项根据等级名次确定分值,从学校的素质学分统计表中获得。
就业数据主要包括入职公司类型、公司规模、生产类岗位、薪资等,因为数据集数量较少,本文仅对毕业后的薪资进行预测,其余指标可在获取更多的数据后再进行训练。
由于学生数据一般以学校为单位进行留存,单个学校的数据量有限,且每年的就业环境不同,不适合收集多年的数据进行分析。结合上述场景的特点,学生的数据特征较为固定,即样本特征重合度较高,但是用户不重合。综合考虑联邦学习的三种分类及特点,应选用横向联邦学习模型进行学习。
3.2 数据准备
3.2.1 数据集划分
将数据分为训练数据集和测试数据集,其中训练数据占80%,测试数据占20%。
3.2.2 多方计算party划分
本例模拟多机运行,参与方可分为输入方、计算方和结果方,输入方为训练数据及模型的持有方,负责加密数据和模型,并将其发送到计算方。计算方为训练的执行方,基于特定的多方安全计算协议完成训练任务。计算方只能得到加密后的数据及模型,以保证数据隐私。在本例中每个节点充当两个角色,既是数据拥有方,也作为计算方参与训练,节点配置如表2所示。

表2 节点配置
3.2.3 私有数据对齐
在不泄露自身数据的情况下,数据方找到各方共有的样本集合进行训练前的数据对齐,这里使用的是本校的数据,将其划分为几部分以模拟不同的数据方,因此无需进行对齐,只需先删除无用的数据,如准备参加专升本、入伍等学生的数据,将其他数据进行整理,保留学习通数据、期末成绩、技能竞赛、社会实践、集体活动、薪资等字段。
3.2.4 数据加密及分发
运行Paddle Encrypted程序对数据进行加密,产生加密训练数据和测试数据,并运行python process_data.py在指定目录下生成对应于3个计算party的feature和label的加密数据文件,以后缀名区分属于不同party的数据,如第一个feature.party0表示属于party0的feature数据。
按照后缀名,使用scp命令生成的feature和label的加密文件分别发送到对应的计算party,比如,将后缀为Part0的加密数据发送到Party0的./mpc_data/目录下。
将加密后的数据和模型传送给计算方。每个计算方只会拿到数据的一部分,因此计算方无法还原真实的数据,不用担心数据隐私的问题。
3.3 训练及推理
3.3.1 定义MPC协议
使用多方计算协议ABY3,并根据各计算party的机器环境,将localhost修改为三个节点各自的IP地址:
pfl_mpc.init("aby3",int(role),"localhost",server,int(port))
3.3.2 搭建网络
使用自己的数据搭建网络,定义损失函数,这里使用均方误差(MSE),MSE通常用作回归问题的损失函数。

MSE用来计算模型的预测值Y^和Y真实标签的接近程度。
定义优化算法,这里使用随机梯度下降算法SGD,学习率设置为0.0.1。SGD是一种简单而有效的方法,多用于支持向量机、逻辑回归等凸损失函数下的线性分类器的学习。通过优化算法对损失函数进行优化,以便寻找到最优的参数,使得损失函数的值最小。
3.3.3 模型训练
完成配置后进行模型训练,通过迭代器将数据集分batch进行预测值和实际值比较,以求得到最小的loss。
每个迭代中都需要进行前向计算损失函数计算和梯度反向传播,执行梯度反向传播函数将从后向前逐层计算每一层的梯度,并根据设置的优化算法更新参数。最后,使用克隆出的主程序进行预测。
3.4 解密及结果重构
3.4.1 解密预测数据
计算party并将loss.party和prediction.part文件发送到数据方的目录下,数据方使用load_decrypt_data()解密恢复出loss数据和prediction数据。
3.4.2 结果重构
训练和推理工作完成后,模型(或预测结果)由计算方以加密形式输出。结果方收集加密的结果,使用PFM中的工具对其进行解密,并将明文结果传递给用户。
得到明文模型后,使用明文模型进行再训练/预测。
预测结束后,使用process_data.py脚本中的decrypt_data_to_file(),将保存的密文预测结果进行解密,并将解密得到的明文预测结果保存到指定文件中。然后,再调用脚本evaluate_metrics.py中的evaluate_accuracy接口统计预测的准确率。
4 结语
本文将学生学习过程数据使用联邦学习框架进行训练和预测,各个参与方只共享模型的更新参数而无需共享本地的实际数据,达到数据不出本地进行联合训练的目的。将数据集中20%的测试数据与实际数据进行比较,存在一定的误差,但是总体曲线和实际值保持较大的相关性。
将基于横向联邦学习的多方测试数据与普通的集中预测结果进行比较,发现预测精度与集中测试基本相符,说明使用横向联邦学习进行训练及预测,在预测精度上没有明显损失,但很好地保护了用户的隐私数据,可以促进数据联合使用。
猜你喜欢
计算机研究与发展(2022年10期)2022-10-14
家庭影院技术(2020年10期)2020-12-14
家庭影院技术(2019年7期)2019-08-27
太原科技大学学报(2019年3期)2019-08-05
中国房地产·学术版(2016年7期)2016-10-21
专利代理(2016年1期)2016-05-17
项目管理技术(2016年10期)2016-05-17
信息安全研究(2016年10期)2016-02-28
电子设计工程(2015年17期)2015-02-27
华东师范大学学报(自然科学版)(2014年1期)2014-04-16
