改进U-Net3+与跨模态注意力块的医学图像融合
2022-12-21 03:23王丽芳米嘉秦品乐蔺素珍高媛刘阳
中国图象图形学报 2022年12期
王丽芳,米嘉,秦品乐,蔺素珍,高媛,刘阳
中北大学大数据学院山西省生物医学成像与影像大数据重点实验室,太原 030051
0 引 言
随着现代医学成像技术的发展,出现了不同模态的成像方式,单一模态的医学图像对于细节的表征具有局限性。针对单模态图像的局限性,临床上将多种模态的医学图像进行融合,可以在保留原始图像特征的同时(Gai等,2019),弥补单模态医学图像的缺陷,展示丰富的细节信息(Veshki等,2021),利于医生对疾病准确地诊断和治疗。医学图像中含有大量能反映病灶情况(Nour等,2020)的深层特征和细节信息,然而这些深层特征却难以捕捉,而且从单模态图像提取特征后再融合,容易丢失融合图像信息完整性(蔺素珍和韩泽,2017),因此,利用当前模态和其他模态特征之间的关系来提取融合所需的深层特征(Mbilinyi和Schuldt,2020),对于多模态医学图像融合来说非常重要。
传统的图像融合方法很难表征融合图像中病变区域的深层特征。例如,基于空间域的融合方法会引起融合图像的光谱和空间失真(Maqsood和Javed,2020);基于变换域融合方法会使图像具有块效应(Yan等,2021)。深度学习在图像融合领域发展迅速,卷积神经网络(convolutional neural network,CNN)作为其重要分支,具有强大的提取特征能力(Jung等,2020;Zhang等,2020b;Nikolaev等,2021)。Liu等人(2017)利用卷积神经网络对聚焦区域进行分类后,生成多聚焦融合图像。但存在融合图像部分信息丢失的问题。Zhang等人(2020a)为避免信息丢失提出了全卷积神经网络的图像融合框架(image fusion based on convolutional ceural cetwork,IFCNN),引入了级联的边界感知卷积网络,但因其卷积核设置单一,导致了深层特征提取困难。Pan等人(2021)提出密集连接网络结构(DenseNetFuse),编码部分采用残差密集连接的方式连接密集块,但此结构仅能提取单一尺度上的特征。
生成对抗网络(generative adversarial network,GAN)作为深度学习的另一分支,广泛应用于图像融合领域(Kurakin等,2018;Liu等,2018;Wang等,2021)。Ma等人(2019)提出基于GAN的红外与可见光图像融合框架FusionGAN(fusion generative adversarial network),通过红外热辐射信息和可见光纹理信息之间的博弈,突出了图像关键信息。然而,FusionGAN仅有一个鉴别器,所以融合结果存在过于关注可见光图像信息而红外图像信息部分丢失的问题。Ma等人(2020)为避免融合图像对源图像关注度分配不均,提出了基于双鉴别器的生成对抗网络框架DDcGAN(dual discriminator generation adversative network),利用双鉴别器分别对两幅源图像训练,但其损失函数仅计算了像素损失,不利于充分提取图像的深层特征。Yang等人(2021)提出的GANFuse在DDcGAN的基础上引入梯度损失,将两种损失的加权求和作为损失函数,进一步提升了融合性能。然而,上述方法对于图像深层特征的提取及表征方面依然有所欠缺。
综上,针对目前多模态医学图像融合方法深层特征提取能力不足,部分模态特征被忽略的问题,本文提出了基于改进的U-Net3+与跨模态注意力块的双鉴别器生成对抗网络(U-Net3+ and cross-modal attention block dual-discriminator generative adversal network,UC-DDGAN),其生成器利用5层的U-Net3+实现了全尺度的特征提取,仅用很少的参数提取得到深层特征,提升了深层特征提取能力;跨模态注意力块嵌入到U-Net3+的各层下采样路径上,将深层特征的提取扩展到不同模态之间,保留了各模态丰富的细节信息,有效防止关键信息被忽略。双鉴别器将梯度损失引入到损失函数的计算中,提升了融合性能。训练后,UC-DDGAN可生成包含丰富深层特征的融合图像。
1 相关工作
1.1 U-Net3+
U-Net3+(Huang等,2020)是一种由U-Net(Ronneberger等,2015;Qin等,2020)和U-Net++(Zhou等,2018)改进得到的可以有效提取深层特征的网络框架(Xiao等,2021;Xiong等,2021),其将特征提取的范围扩展到全尺度,捕获了全尺度下的粗细粒度语义。
1.2 跨模态注意力机制
Song等人(2021)针对双模态图像融合和配准时两模态复合特征提取困难的问题,基于非局部注意力机制(Wang等,2017)提出了跨模态注意力机制。不同于非局部注意力机制只在单一图像上计算自我注意力,跨模态注意力机制将注意力的计算扩展到了两个模态,保留了融合图像信息的完整性,使更多的源图像细节特征得到表征,跨模态注意力(cross-modal attention)机制原理如图1所示。

图1 跨模态注意力机制原理Fig.1 Principle of cross-modal attention mechanism
跨模态输入特征图C经过线性映射函数θ(·)处理得到特征θ(C),主输入特征图P分别经过线性映射φ(·)和g(·)处理得到特征φ(P)和g(P);转置后的θ(C)和φ(P)进行矩阵点乘,得到两输入的特征相关性矩阵R,即P局部位置特征与C全局位置特征的关系矩阵;对R进行归一化操作,得到0-1权重,用做跨模态注意力系数;最后将跨模态注意力系数对应与特征矩阵g(P)进行矩阵点乘,得到跨模态注意力特征图F。
1.3 DDcGAN
DDcGAN针对不同分布的源图像设置了两个鉴别器,进行针对性鉴别,如图2所示。

图2 DDcGAN网络结构Fig.2 DDcGAN network structure
DDcGAN包含一个生成器(G)和两个鉴别器(D1、D2),生成器由编码、融合和解码3部分组成,其中编码部分的任务是特征提取、融合,解码部分的任务是特征融合;鉴别器的任务是分别鉴别对应源图像,以此训练生成器。DDcGAN的输入是源图像1和源图像2,编码部分首先采用包含3×3滤波器的卷积层提取同一尺度的粗糙特征,然后采用3个包含同一尺度卷积层的DenseBlock(Cai等,2021)来保留两幅源图像同一尺度的具体特征;融合部分利用注意力机制对提取到的两幅特征图进行融合,融合部分的输出将作为解码部分的输入;解码部分采用4个包含3×3滤波器的卷积层对拼接后的特征图进行解码。两个鉴别器结构相同,先经过卷积操作和激活函数,再经全连接层扁平化数据和激活函数tanh计算概率,得到鉴别结果。DDcGAN的训练过程与GAN类似,生成器的性能在生成器和鉴别器的对抗中不断提升。DDcGAN的特征融合部分采用注意力机制,可以保留更多两模态关键信息,但其特征融合部分也存在仅可在单尺度上提取特征以及深层特征提取能力弱的问题。
2 基于UC-DDGAN的医学图像融合
UC-DDGAN包含一个生成器G和两个鉴别器(Dc、Dm),网络结构如图3所示。生成器负责生成融合图像,鉴别器用来区分源图像和融合图像。生成器生成融合图像分两阶段进行:特征提取和特征融合。以CT(computed tomography)和MR(magnetic resonance imaging)的融合为例,特征提取部分提取CT与MR图像的深层特征,特征融合部分融合提取到的深层特征,经过通道降维和卷积操作后,生成融合图像。在鉴别器区分源图像和融合图像时,将梯度损失引入到损失函数中,提升生成器生成图像的性能。
2.1 特征提取
鉴于GAN的生成器未提取到足够多包含两模态信息的深层细节,UC-DDGAN引入了U-Net3+网络和跨模态注意力块进行深层特征提取。U-Net3+可以在单模态上对深层特征进行全尺度范围的提取和融合;跨模态注意力块可以根据当前模态图像特征和待融合的另一模态图像特征之间的相关性,生成具有两模态信息的复合特征图。
2.1.1 基于U-Net3+的深层特征提取
U-Net3+分为两个阶段:编码阶段和解码阶段,如图4所示。编码阶段对输入图像进行4次逐层下采样提取特征,解码阶段对各层解码结果进行整合并上采样,最后经过1×1的卷积进行通道降维,完成特征提取,输出特征图。图4中,同一虚线框中的两个卷积模块为同一层卷积模块,其中前一个表示编码器,后一个表示解码器(Conv5既为编码器又为解码器),每一层编码器和解码器的结构都一样,其参数设置与在ImageNet上训练的ResNet50(He等,2016)一致。

图3 UC-DDGAN网络结构Fig.3 UC-DDGAN network structure

图4 U-Net3+网络结构Fig.4 U-Net3+ network structure
U-Net3+中的Conv4解码器构建输出特征图的过程如图5所示,其他尺度解码器构建输出特征图的过程与其类似。
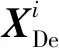
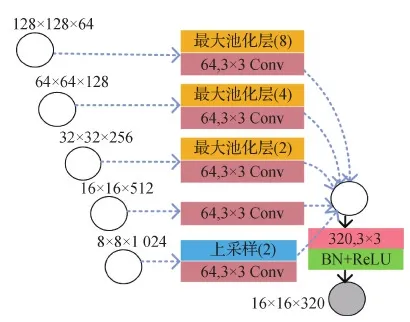
图5 U-Net3+中Conv4解码器输出特征图的构建过程Fig.5 Construction process of Conv4 in U-Net3+ decoder output feature map at all scales
(1)
式(1)表示当编码器和解码器来自同一尺度时(即Conv5,该层的编码器也可作为解码器使用),解码器的输出特征图等于编码器的输入特征图;当编码器和解码器来自不同尺度时,编码器的输出特征图等于编码器输入特征图的叠加,但这些特征图在叠加前需要分别经过上下采样及卷积操作。i表示不同尺度的层数,XEn表示经过编码器得到的特征图,C(·)表示卷积运算,D(·)和U(·)分别表示下采样和上采样操作,H(·)表示通道叠加的函数,[·]表示串联操作,Scale表示特征图的尺度。最后,Conv1的输出特征图再经过64个1×1的滤波器进行通道降维,输出全尺度特征图。
2.1.2 基于跨模态注意力块的特征相关性增强
UC-DDGAN的特征提取部分将跨模态注意力块嵌入U-Net3+提取源图像CT和MR的深层特征。生成器特征提取部分如图6所示。

图6 UC-DDGAN生成器内部结构Fig.6 UC-DDGAN generator internal structure
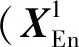

xi=Z([P(ci),C(mi)]),i≤4
(2)
yi=Z([P(mi),C(ci)]),i≤4
(3)
式中,ci、mi分别表示CT、MR路径第i层编码器的输出特征,P(·)表示主模态输入的运算函数,C(·)表示跨模态输入的运算函数,Z(·)表示跨模态注意力块内部先矩阵点乘再将对应元素逐个相乘的函数,[,]表示串联操作。

图7 跨模态注意力块在U-Net3+中的连接方式Fig.7 Cross-modal attention block connection in U-Net3+
跨模态注意力块的内部结构如图8所示。C、P分别表示跨模态路径和主模态路径输入的特征图(C∈RT×W×H×64、P∈RT×W×H×64),T、H和W分别表示特征图的批量数、高度和宽度,64是特征图通道数。首先,C、P经过通道降维及线性变换函数θ(·)、φ(·)处理,得到θ(C)、φ(P)两种特征表示(θ(C)∈RT×W×H×32、φ(P)∈RT×W×H×32),然后对θ(C)、φ(P)进行reshape操作,合并T、H和W维度(θ(C)∈RT×W×H×32、φ(P)∈RT×W×H×32)。再将θ(C)的转置与φ(P)进行矩阵点乘,得到包含主模态各像素与跨模态各像素相关性的特征图F(F∈RT×W×H×32),然后对F进行softmax操作,实现相关性的归一化。P除了经过线性变换函数θ(·)处理,还经过线性变换g(·),得到特征表示g(P)∈RT×W×H×32),对得到的g(P)进行reshape操作,合并T、H以及W维度(g(P)∈RT×W×H×32)。F经过归一化操作后与合并T、H和W维度的g(P)进行矩阵点乘,得到Q∈RT×W×H×32,Q表示经跨模态注意力机制调整后的残差矩阵。然后Q经过1×1×1卷积,恢复T、H和W维度,表示为Y∈RT×W×H×64。最后,Y与P做残差运算,得到跨模态注意力块的输出Z∈RT×W×H×64。跨模态注意力块得到的特征图计算式为
(4)
式中,ci是跨模态输入特征图中i位置的特征,pj是主模态输入特征图中所有与ci有关的特征,j表示特征pj在跨模态输入中的位置。θ(ci)、φ(pj)分别是ci、pj在经过Embedded Gaussian(Benet等,2001)中的两个嵌入权重变换Wθ、Wφ之后得到的特征图,g(pj)是pj经过线性变换得到的特征图,f(·)是用于计算ci、pj相关性的函数。yi是累加了跨模态输入中所有与主输入i位置上特征相关的特征后得到的复合特征图i位置的特征。

图8 跨模态注意力块内部结构Fig.8 Internal structure of cross-modal attention block
跨模态注意力块嵌入U-Net3+构成UC-DDGAN生成器特征提取部分,可以增加CT图像和MR图像的信息交互,使CT图像的骨骼信息和MR图像的软组织初步融合。该特征提取方式能促进特征学习、改善梯度流动和增加隐式深度监督。各层编码器、解码器卷积参数如表1所示。

表1 U-Net3+各层编码器、解码器卷积参数Table 1 Convolution parameters of U-Net3+ encoders and decoders at each layer
2.2 特征融合
特征融合分为融合和解码两部分,如图9所示。融合部分由一个Concat层构成(Song等,2018),解码部分由5个卷积模块组成,该卷积模块利用若干个3×3的滤波器来压缩通道数(各层滤波器数如图中n所示),通过批量归一化层(batch normaligation,BN)来缓解梯度爆炸,ReLU激活函数加快训练速度。特征提取部分得到尺寸为128×128×320的CT、MR深层特征图,依次经过Concat层拼接,再经过滤波器分别为128、64、32、16、1这5个卷积模块逐层进行通道降维,将尺寸为128×128×320的CT、MR深层特征图压缩成尺寸为128×128×1深层细节丰富且充分表征两模态关键特征的融合图像。

图9 特征融合部分网络结构Fig.9 Partial network structure of feature fusion
2.3 双鉴别器网络结构
UC-DDGAN设计了具有相同网络结构的两个鉴别器,其结构如图10所示。真实图像与融合图像依次经过4个卷积模块:由16个3×3的滤波器和ReLU激活函数层构成的第1层卷积模块;32个3×3的滤波器、批量归一化层、ReLU激活函数层构成的第2层卷积模块;64个3×3的滤波器、批量归一化层、ReLU激活函数层构成的第3层卷积模块(步幅为2,填充为0);最后经过全连接层(fully connected,FC)将数据扁平化,在最后一层,利用tanh激活函数作为评估器,得出输入图像是真实图像的概率。
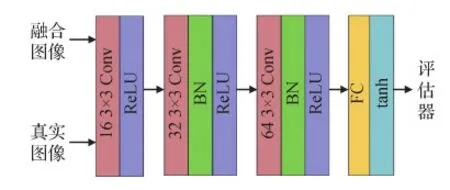
图10 鉴别器网络结构Fig.10 Discriminator network structure
2.4 基于梯度损失加权的损失函数设计
UC-DDGAN是基于双鉴别器的生成对抗网络,因此要用损失函数分别优化一个生成器、两个鉴别器,通过对各部分损失加权来提升融合性能,保留更多源图像特征。为进一步保留源图像的深层特征,UC-DDGAN的损失函数在前人基础上引入了梯度损失,并通过加权的方式将二者结合起来用于生成器的训练。
UC-DDGAN的损失函数由生成器损失LG和两个鉴别器损失LDc、LDm组成。生成器的损失函数LG由CT图像的损失LC和MR图像的损失LM加权相加,计算为
LG=LC+δLM
(5)

(6)

(7)

(8)
式中,Dc(|If-Ic|)代表Dc的正确率,因此在Dc(|If-Ic|)前面设置一个负号,表示减去判定正确的部分。
LG的第2项LM表示MR图像的损失,定义与LC类似,计算式分别为
(9)
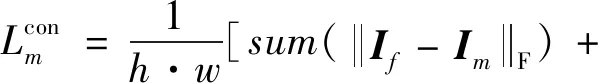
(10)
(11)
Dc和Dm的损失函数LDc、LDm计算式为

(12)

(13)
式中,Dc(|If-Im|)和Dm(|If-Ic|)分别代表Dc和Dm的错误率。因为鉴别器损失表示鉴别失败的概率,所以LDc、LDm用Dc和Dm的错误率分别减去其正确率来表示。随着G与Dc和Dm的对抗训练不断进行,G与Dc和Dm达到纳什平衡(Ratliff等,2013),LDc、LDm和LG达到最优值,训练完成。
2.5 算法步骤
在训练阶段,利用训练集数据分别对生成器G和鉴别器Dc、Dm进行对抗训练。首先固定G训练Dc、Dm,之后再固定Dc、Dm训练G,接着循环训练,来提高G生成融合图像的能力以及Dc、Dm鉴别出G生成的图像与真实CT、MR图像差别的能力,直至G生成的图像足以通过Dc、Dm的鉴别即可停止。此时,将测试集数据输入到G中,得到最终融合结果。在测试阶段,使用经过训练的生成器来生成融合图像。UC-DDGAN算法的详细训练步骤为:
参数描述:IG、IDc和IDm分别表示训练G、Dc和Dm的训练次数,Imax是训练UC-DDGAN的最大次数,在本实验中,Imax=20;Lmax、Lmin和LGmax表示生成器训练完成时的损失范围;Lmax和Lmin用于G、Dc和Dm的对抗损失的优化,LGmax用于G总体损失的优化;
在实验的第1批次中,Lmax=0.065,Lmin=0.055,LGmax=0.2;Dc和Dm的初始化参数为θDc和θDm,G的初始化参数为θG,在每次的训练迭代中:
1)训练鉴别器Dc和Dm。
s个CT图像样本{c1,…,cs}和s个MR图像样本{m1,…,ms};
生成器获取到待生成数据{G(c1,m1),…,G(cs,ms)};
在Adam优化器优化LDc(式(12))更新θDc;
在Adam优化器优化LDm(式(13))更新θDm;
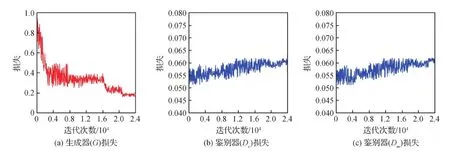
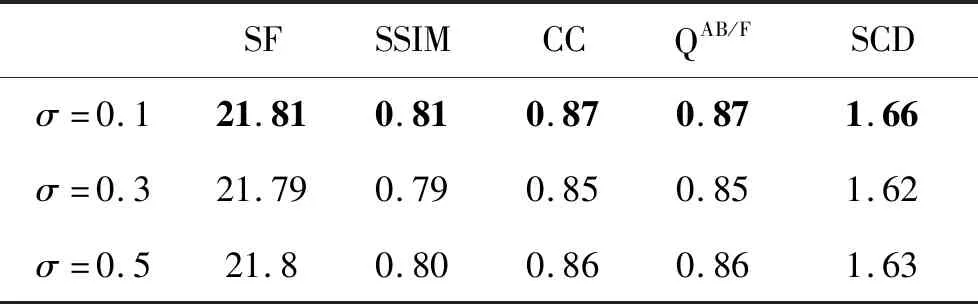
如果LDc>Lmax并且LDm IDc=IDc+1; 如果LDm>Lmax并且LDc IDm=IDm+1。 2)训练生成器G。 s个CT图像样本{c1,…,cs}和s个MR图像样本{m1、…、ms}; 生成器获取到待生成数据{G(c1,m1),…,G(cs,ms)}; 在SGD(stochastic gradient descent)优化器优化LG(式(5))的过程中更新θG; IG=IG+1; IG=IG+1; 如果LDc>Lmax并且LDm IG=IG+1。 实验数据集来自美国哈佛医学院(http:// www.med.harvard.edu)、山西省生物医学成像与影像大数据重点实验室。实验从其开源的常见脑部疾病图像数据集中选取了500对具有清晰脑部纹理、丰富细节特征的高质量CT和MR图像作为数据集。数据集分为训练集和测试集,其中包括400对用于网络训练的训练集图像和100对用于测试网络泛化性能的测试集图像。为避免因数据集较小而导致的网络模型过拟合,采用Albumentations(Buslaev等,2020)对训练集数据进行扩充,将MR和对应CT图像调整到256×256像素,进行0°旋转、90°旋转、180°旋转、270°旋转、水平翻转、垂直翻转,再在上述6种变换的基础上分别进行随机亮度、弹性变换 2种操作,获得6×2=12倍的数据,即4 800对图像进行训练。 实验的硬件平台:CPU为i7-11700,内存16 GB;GPU为RTX 3060Ti 8 GB GDR6;软件平台:操作系统为64位的Windows10;环境框架为PyTorch;Python版本为3.6.0。 在训练过程中,UC-DDGAN分别采用Adam优化算法(Kingma和Ba,2017)和SGD(Cherry等,1998)促使鉴别损失和生成损失函数趋向最小来更新网络的参数。本文网络的参数设置为:初始学习率2E-4,动量参数为0.9,权重衰减为5E-2。为降低GPU显存对训练的影响,训练采用mini-batch的方式进行(王丽芳 等,2020),batch-size设置为40,epoch设置为200,迭代次数为4 800/40×200=24 000次(训练样本数4 800,batch-size为40,epoch为200)。随着迭代次数的增加,生成器损失LG和两个鉴别器损失LDc、LDm的变化趋势如图11所示。图11(a) 中,LG曲折下降后趋于平稳,在0.2附近小幅波动;图11(b)(c)中,LDc,LDm整体缓慢上升后稳定在0.06附近。此外,由图11可以看出,LG和LDc,LDm无较大波动,说明UC-DDGAN在训练过程中较为稳定。 图11 损失折线图Fig.11 Loss line diagram((a) generator G loss;(b) discriminator Dc loss;(c) discriminator Dm loss) 为验证UC-DDGAN的融合性能,实验选取基于拉普拉斯金字塔(Laplasian pyramid,LAP)的方法(黄福升和蔺素珍,2019)、基于脉冲耦合神经网络(pulse-coupled neural network,PCNN)的方法(Indhumathi等,2021)、基于卷积神经网络(CNN)的方法、基于融合生成对抗网络(FusionGAN)的方法以及基于双鉴别器生成对抗网络(DDcGAN)的方法作为对比方法。 3.3.1 定性结果分析 首先对脑梗、脑中风、脑瘤和脑血管4种脑部疾病的图像进行了定性比较实验。融合结果的定性比较如图12所示。图中显示LAP方法得到的融合结果边缘模糊,不利于医生观察病灶轮廓;PCNN方法得到的融合结果亮度过低,损失掉大量细节信息;CNN方法得到的融合结果深层细节表征不够,观察不到其内部细节;FusionGAN方法得到的融合结果过分关注MR模态的图像,损失了CT图像的骨骼信息;DDcGAN方法得到的融合结果边缘不够平滑;UC-DDGAN方法得到的脑梗疾病融合结果脑部沟壑清晰可见、脑中风疾病融合结果脑组织颜色层次分明、脑瘤疾病融合结果脑髓质及骨骼信息得以充分保留、脑血管疾病融合结果包含有脑叶的深层细节。综上,UC-DDGAN的融合效果优于其他5种用于对比的融合方法。 3.3.2 客观评价指标及定量结果分析 为客观地评价融合效果,实验选取了5个客观评价指标:空间频率(spatial frequency,SF)、结构相似性(structural similarity,SSIM)、边缘信息传递因子(edge information transfer factor,QAB/F)、相关系数(correlation coefficient,CC)以及差异相关性的和(the sum of the correlations of differences,SCD)评价UC-DDGAN在脑部医学图像数据集上的性能。 图12 本文算法与5种对比算法在CT和MR图像对上的定性比较结果图Fig.12 Qualitative comparison results((a)CT resource images;(b) MR resource images; (c) LAP;(d)PCNN; (e) CNN; (f) FusionGAN; (g) DDcGAN;(h) UC-DDGAN(ours)) 其中,SF与融合图像分辨率成正比,SF指标越高表明融合图像细节表征越明显;SSIM从图像亮度、对比度和结构方面衡量融合图像与CT/MR两幅源图像的相似性,SSIM值越大,图像结构完整度越高;边缘评价因子用于评价边缘或梯度质量,QAB/F的值越大,融合图像边缘信息损失越小;CC测量融合图像与CT/MR两幅源图像之间的相关性,CC值为正且越大,表示融合图像与两幅源图像的相关性越高;SCD利用另一源图像和融合图像之间的差异来描述当前源图像在融合图像中的信息,两幅源图像在融合图像中的信息相加得到SCD值。SCD值为正且越大,表示融合图像与源图像A的相关性越高。SF、SSIM和QAB/F主要用于评价UC-DDGAN深层特征提取能力;CC、SCD主要用于评价UC-DDGAN保留两模态信息的能力。实验利用上述5个客观评价指标测试了30对脑部CT和MR图像,UC-DDGAN的表现均优于对比的5种融合方法,UC-DDGAN及5种对比融合方法在SF、SSIM、QAB/F、CC和SCD的测试结果折线图分别如图13所示,其中红色折线表示UC-DDGAN的客观评价结果,评价结果平均值如表2所示。由表2可知,利用UC-DDGAN进行融合可以获得各项指标的最大均值。 为了验证UC-DDGAN中U-Net3+与跨模态注意力块保留两模态信息及提取深层特征的效果,进行了两组消融实验。 实验1表示不添加U-Net3+和跨模态注意力块的图像融合网络得到的结果,即DDcGAN;实验2表示仅添加U-Net3+得到的结果;实验3表示仅添加跨模态注意力块得到的结果;实验4表示损失函数中不引入梯度损失的UC-DDGAN效果。定性结果如图14所示,对比实验评价结果如表3所示。由表3可知,UC-DDGAN达到了保留两模态信息且提取更多深度特征的目的。此外,本实验还对损失函数中的梯度损失和像素损失的权重σ的参数进行了研究。UC-DDGAN的损失函数权重σ设置为 0.1。实验5和实验6的权重σ分别为0.3和0.5,定量结果如表4所示。 表5显示,当权重σ设置为0.1时获得的定量结果最优,因此,实验权重σ设置为0.1是合理的。 图13 UC-DDGAN及5种对比融合方法的定量结果Fig.13 Quantitative results of UC-DDGAN and five comparative fusion methods((a)SF;(b)SSIM; (c)QAB/F; (d)CC; (e)SCD) 表2 客观评价指标平均值Table 2 Average value of objective evaluation indexes 本文提出基于U-Net3+与跨模态注意力块的双鉴别器生成对抗网络(UC-DDGAN)的医学图像融合方法,解决了目前多模态医学图像融合方法深层特征提取能力不足、部分模态特征被忽略的问题。从实验结果可知,UC-DDGAN在主观视觉观察和客观指标评价方面都有较好的表现,将UC-DDGAN应用于多模态医学图像融合,可以辅助医生对病灶部位做出准确地诊断与治疗。UC-DDGAN具有以下特点:1)利用U-Net3+网络,提取到了图像深层特征,其融合图像病灶细节完整且深层特征丰富;2)利用跨模态注意力块将深层特征的提取扩展到了不同模态之间,保留了各模态丰富的细节信息;3)双鉴别器通过在损失函数中引入梯度损失,更好地训练生成器生成融合图像,保留更多源图像特征。 图14 UC-DDGAN消融实验的定性比较结果Fig.14 Qualitative comparison results of UC-DDGAN ablation experiment((a)CT resource images;(b) MR resource images; (c)UC-DDGAN;(d) experiment 1;(e)experiment 2;(f)experiment 3;(g)experiment 4) 表3 对比实验客观评价指标Table 3 Objective evaluation indexes of compartive experiments 表4 不同权重对比实验客观评价指标Table 4 Objective evaluation indexes of compartive experiments with different weights 但本文算法也存在局限性,仍有较大提升空间,具体表现在:1)生成器网络较为复杂,存在训练时间长的问题,后续工作将致力于降低计算复杂度;2)本文所做改进主要针对的是特征提取部分,针对融合部分设计能够保留两模态信息的网络模型是今后研究的重点。 下一步工作是改进融合部分网络结构,提升模型泛化性,可用于其他图像融合,例如红外与可见光图像融合。
3 实验结果与分析
3.1 数据集与实验环境
3.2 训练细节
3.3 对比实验及分析

3.4 消融实验


4 结 论


 猜你喜欢
通信学报(2022年10期)2023-01-09北京工业大学学报(2022年9期)2022-09-15水利规划与设计(2020年1期)2020-05-25电子制作(2019年15期)2019-08-27电子制作(2018年19期)2018-11-14铁道通信信号(2018年1期)2018-06-06自动化学报(2017年11期)2017-04-04系统工程与电子技术(2016年5期)2016-11-02中国卫生(2015年1期)2015-11-16噪声与振动控制(2015年4期)2015-01-01
猜你喜欢
通信学报(2022年10期)2023-01-09北京工业大学学报(2022年9期)2022-09-15水利规划与设计(2020年1期)2020-05-25电子制作(2019年15期)2019-08-27电子制作(2018年19期)2018-11-14铁道通信信号(2018年1期)2018-06-06自动化学报(2017年11期)2017-04-04系统工程与电子技术(2016年5期)2016-11-02中国卫生(2015年1期)2015-11-16噪声与振动控制(2015年4期)2015-01-01