融合时序特征约束与联合优化的点云3维人体姿态序列估计
2022-12-21 03:23廖联军钟重阳张智恒胡磊张子豪夏时洪
中国图象图形学报 2022年12期
廖联军,钟重阳,张智恒,胡磊,张子豪,夏时洪*
1. 中国科学院计算技术研究所, 北京 100190; 2. 中国科学院大学,计算机科学与技术学院, 北京 100049;3. 北方工业大学信息学院, 北京 100144
0 引 言
3维人体姿态估计是计算机视觉中的一个基本问题和重要任务之一,有着非常广泛的应用。在游戏互动领域,人体姿态估计进一步提升了人机交互的可能,为体感游戏等提供了技术基础;在数字娱乐领域,人体姿态估计通过赋能电商行业,在虚拟试衣、数字主播等新兴领域发挥着不可或缺的作用。
一般方法采用RGB图像作为3维人体姿态估计的输入。与RGB图像相比,深度图或点云作为3维人体姿态估计的输入具有以下优势:1)深度图作为一种2D数据,能够有效地表示3D的空间信息,从而使人体姿态估计结果具有尺度正确性;2)点云质量一般不随环境光照的变化而变化,使点云具有更广泛的应用前景,例如在不同光照条件下的室内增强现实;3)点云不包含人体纹理信息,可以在有效捕获人体运动的同时保护个人隐私。
虽然3维人体姿态估计已经取得很大进展,但仍然存在一些挑战。由于遮挡和自遮挡引起的模糊性,以及深度相机生成的点云带有噪声,使得3维人体姿态估计任务比较困难。现有的基于深度图像的方法主要集中在单幅图像的姿态估计。由于缺乏时域平滑度的强制约束,现有方法在连续点云序列上可能会产生抖动伪影。
为解决上述问题,观察到使用点云序列作为输入有助于增强人体姿态预测的时间一致性,本文利用了点云序列的时序先验知识可以得到更好的人体姿态估计结果。针对遮挡和自遮挡引起的模糊性造成的困难,考虑到遮挡及自遮挡在实际情况中一般不会一直存在,本文方法利用输入点云序列提取供时序上的约束,可以使生成的结果更加合理。
时序的约束主要体现在两方面。1)使用长短期记忆网络(long short-term memory,LSTM),在特征层面上构建当前帧的特征与前序特征的关联;2)引入一致性损失函数,约束各关节的速度变化,以缓解遮挡及自遮挡造成的估计困难。
人体姿态估计与运动预测密切相关,然而关于3维人体姿态估计与运动预测是否能相互促进,目前还鲜有研究。本文提出一种从点云序列估计3维人体姿态的方法,如图1所示。该方法以深度图序列中的点云作为输入,估计3维人体姿态和预测后续人体运动。受基于单帧深度图的算法框架(Zhang等,2020)的启发,本文设计了一个以点云序列为输入的两阶段人体姿态估计算法。首先,从深度图中提取2维姿态信息,从而剔除背景和抽取姿态相关点云。然后,通过层次化网络PointNet++(Qi 等,2017b)和长短期记忆(LSTM)层对姿态相关点云序列的时空特征进行编码,并采用多任务网络联合求解人体姿态估计和运动预测问题。为了利用大量的更容易获取的带2D人体姿态标注的数据集,本文采用弱监督学习的方法,以点云序列作为输入,由2维关节监督以减少模糊性。实验结果表明,本文方法是有效的,在ITOP(invariant-top view dataset)和NTU-RGBD数据集上都能有效地达到先进的性能。
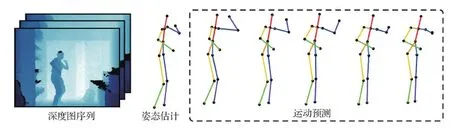
图1 本文方法示意图Fig.1 An illustration of our method
本文工作的主要贡献如下:1)提出一种从序列点云估计3维人体姿态的方法。这是首次利用时间信息构建卷积神经网络(convolutional neural networks,CNN)求解基于深度信息的3维人体姿态估计问题。与现有的先进方法相比,该方法能获得更好、更平滑的人体姿态估计结果。2)对人体姿态估计任务和运动预测任务采用联合训练策略,并验证了两个任务之间可以相互促进。3)本文方法在ITOP和NTU-RGBD数据集上取得了先进的3维人体姿态估计性能,实验从定性和定量两方面验证了这一点。
1 相关工作
1.1 3维人体姿态估计
当前方法主要采用生成式方法,先估计2维人体姿态,然后利用它估计3维人体姿态。具有代表性的工作(Martinez等,2017)使用高效的堆叠沙漏模型(Newell等,2016)估计2维人体姿态,然后用一组线性层将2维姿态提升到3维人体姿态。然而,该方法的性能依赖于2维姿态估计的鲁棒性。基于深度图的3维人体姿态估计,最新的方法大多基于深度图的表示方式(Chang等,2018;Zhang等,2020)。Chang等人(2018)将深度图视为点云,并将其转换为3维体素网格,然后使用3维CNN估计3维人体姿态。然而,这种方法需要事先剔除背景点云。Zhang等人(2020)提出使用一种混合的2D/3D深度图表示方法,并采用类生成式方法。首先估计2维人体姿态,利用它进行点云采样,然后用神经网络PointNet提取姿态内嵌特征,进而估计3维人体姿态。该方法对背景的变化具有很强的鲁棒性,但其基于连续帧生成的结果可能会有抖动现象。Wang等人(2021)提出一个生成式深度学习网络,工作重点在于通过循环神经网络(recurrent neural network,RNN)生成不同的人体运动,同时可以对生成运动的轨迹、速度等进行控制。Li等人(2019)也采用两阶段方法进行3D人体姿态求解,与本文工作不同,该工作主要解决从彩色图像估计3D人体姿态问题,其两阶段方法重点在于预估计和估计优化。Zhou等人(2020)提出一种用于3维姿态估计的深度人体姿态网络,以单个深度图的点云数据作为输入,主要通过阈值的方式,从场景点云中获取人体相关的点云,该方法存在的问题是适用的场景较为固定,一旦场景发生改变,设定的阈值往往不再有用。与本文方法相比,该方法在相同数据集上的平均准确率和均关节误差等关键指标上的结果明显较低。
基于视频的3维人体姿态估计方法可以分为两类。第1类(Dabral等,2017;Lee等,2018;Lin等,2017;Hossain和Little,2018)利用后续若干帧的时序信息使估计结果更加平滑。Lin等人(2017)提出一种多阶段序列细化网络估计3维人体姿态序列,先逐帧估计3维姿态,然后使用多级递归网络对结果进行细化。Dabral等人(2017)使用全连接网络优化粗略的输入姿态。Hossain和Little(2018)使用时序一致的2D姿态估计3D姿态序列,网络由带有LSTM单元的序列到序列网络(sequence-to-sequence network)组成,在训练过程中利用时间约束对训练结果进行平滑处理。Lee等人(2018)也使用LSTM单元,在第1个LSTM单元中创建3D人体姿态的种子关节,在其余LSTM单元中重建3D人体姿态。第2类(Dabral等,2017;Kanazawa等,2019;Pavllo等,2019;Hossain和Little,2018)是向前查看若干帧的方式使用时序信息,并从序列中提取时间相关特征。Kanazawa等人(2019)设计了一个半监督算法流程,从视频中学习3D人体运动,利用2维人体姿态估计方法提取每帧特征,并将其与时间编码器相结合,预测3维人体姿态和体形参数,但这种方法难于处理遮挡和多人交互问题。Pavllo等人(2019)提出一种有效的全卷积结构,利用时间卷积估计视频中的3维人体姿态。
1.2 3维人体姿态预测
早期的研究使用传统的机器学习方法如高斯混合模型(Min等,2009)和双线性时空基模型(Akhter等,2012)来建模人体运动序列中当前时刻的前序运动和后序运动之间的关系。随着深度神经网络的发展,利用循环神经网络(RNN)和LSTM等神经网络的研究取得了进展(Bütepage等,2017;Fragkiadaki等,2015;Zhou等,2018)。Zhou等人(2018)提出一种称为自动调节RNN的训练机制,使用网络输出的结果和真值序列作为下一阶段的输入。Bütepage等人(2017)利用一个具有瓶颈的全连接网络,基于给定的帧窗口预测未来姿态。
Zhang等人(2019)提出一种直接使用人体运动视频作为输入并预测人体未来运动的方法,逐帧提取姿态相关特征,并使用与Kanazawa等人(2019)的工作类似的时序编码器。为了预测未来运动,在中间的隐空间上使用了自回归模型。与Kanazawa等人(2019)的工作相比,本文在隐空间中也使用LSTM单元,不同的是本文方法使用深度图序列代替彩色图像序列进行姿态估计。
1.3 3维深度学习
近年来,对点云、网格模型等3维物体处理的3维深度学习的研究取得了很大进展,尤其是点云表示出了较高的效率和卓越性能。
基于点云的3维深度学习方法主要以点云作为输入,可以从输入点云坐标和其他如表面法向等信息中提取特征。这些方法最初是为点云分割或分类任务设计的(Li等,2018;Qi等,2017a,b),另有一些工作使用点云学习方法来完成目标检测任务(Qi 等,2019;Zhou和Tuzel,2018)。Qi等人(2017b)提出一种端到端网络PointNet,使用点坐标和曲面法向作为输入,并使用多层感知机将其映射到更高维空间。但是,PointNet不能捕获局部结构。其后续工作PointNet++(Qi等,2017b)中,进一步使用分区采样模块,并递归地将输出反馈给该模块。另外,Qi等人(2018)提出利用2维信息加速基于混合相机的3维检测,通过减少网络处理的点云量,获得了较好的时间效率。
本文方法与现有方法的主要区别体现在两方面。1)提出一个新的从点云序列估计3维人体姿态的方法,并提出姿态一致性损失函数来约束姿态估计结果更平滑;2)本文网络遵循多任务框架,并使用联合训练策略来估计当前人体姿态和预测未来人体运动。
2 算法框架
本文提出一种两阶段的算法,求解从深度图像或点云序列估计3维人体姿态的问题,如图2所示。第1阶段为点云提取阶段,目的是从输入的深度图序列中提取姿态相关点云序列,通过2D关节获得下采样的姿态相关点云;第2阶段为姿态编码阶段,进一步对时空信息进行编码,提取姿态相关点云序列的时空特征,联合学习3维人体姿态估计和运动预测任务,估计3维人体姿态序列。

图2 3维人体姿态估计网络Fig.2 Our 3D human pose estimation network
2.1 点云提取阶段
点云提取阶段主要目的是对网络关注的点云进行重采样。众所周知,原始深度图中含有大量的冗余点,这可能会增加计算量、降低估计精度。点云提取阶段大致可分为两部分,即2维姿态检测和姿态相关点云抽取及其归一化。
1)2维姿态估计。本文采用Zhang等人(2020)的方法获得2维人体姿态。在训练过程中,使用堆叠沙漏模型(Newell等,2016)作为2维姿态估计的网络结构。损失函数定义为预测热力图与2维姿态生成的真值热力图之间的L2距离。
2)姿态相关点云提取及其规范化。估计的2维姿态可以用来指导姿态相关采样点云的提取以恢复3维人体姿态。为了确保规范化后的序列点云尺度相同,所有点云必须基于固定边界框执行点云规范化。逐帧处理深度图检测2维关节,裁剪检测到的2维关节的边界框,以2维根关节为中心提取N个局部块。通过在2维边界框内简单地乘以深度相机的内参矩阵,获得点云。然后,本文使用平均3维边界框来规范点云序列。此过程具体为
(1)
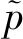
2.2 姿态编码阶段
姿态编码阶段的目标是对姿态相关点云序列进行编码,学习3维人体姿态。图3显示了姿态编码阶段的网络结构,主要由姿态相关特征提取和时间信息编码的LSTM单元两部分组成。首先,将每一帧的采样点云送入层次化网络PointNet++提取姿态相关特征。然后,利用长短期记忆(LSTM)网络对姿态相关特征进行时间特征建模、3维人体姿态估计和3维运动预测。图3中展示了不同任务的损失函数,L3D、L2D、Lc和Lp分别表示3维关节损失、2维关节损失、一致性损失和运动预测损失。
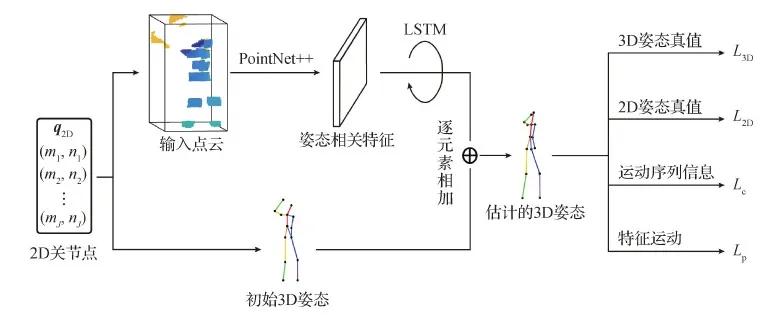
图3 姿态编码阶段的网络架构Fig.3 The network architecture of our pose encode stage
2.2.1 网络结构
2)时序信息处理。本文使用长短期记忆网络(LSTM)在特征层面上构建当前帧的特征与前序特征的关联。得到姿态相关特征后,在相邻帧的特征之间加入递归连接,训练LSTM模块Fe:(φt-r,…,φt,…,φt+r)→qt学习高阶时间依赖,其中,r是时间感受野的长度。由于本文的研究重点是姿态估计和姿态预测,所以使用t帧之前的序列数据来保证一致性。如图3所示,提取连续帧的特征并将其反馈送入LSTM模块。对于第1级LSTM,本文使用随机生成的向量作为输入状态,对于后续LSTM模块,传递当前特征作为下一级的隐藏状态。为了预测最终的3维姿态,首先利用深度图像对应的内参矩阵将所估计的2维关节q2d反投影到3维空间,计算出初始的3维姿态。然后在LSTM模块的输出端使用一个全连接层来学习初始姿态的偏移量,将其与初始3维姿态相加,得到最终的3维姿态。
具体的时序处理如图4所示,采用LSTM模块,利用短时隐变量和长时隐变量,在特征层面上构建当前帧的特征与前序特征的关联。对于输入的深度图像序列,首先利用上文姿态相关特征提取阶段所用的PointNet++网络对深度图像逐一进行特征提取,得到姿态相关的点云特征ft后,将其输入到时序处理网络LSTM中,LSTM可以看做是循环神经网络RNN的改进版本,不仅可以提取序列的短时间关系,还能综合序列的长时间依赖对输出进行预测。以往的工作表明,LSTM网络能够处理网络训练时梯度消失的问题,从而更加便于模型的收敛。因此,对于基于深度图的人体姿态序列估计及运动预测问题,LSTM网络十分适合。如图4所示,LSTM网络模块具有两个隐变量ht和ct,其中,ht用来传递短时间的依赖,而ct则刻画长时间的时序联系。针对时刻t,通过PointNet++提取姿态相关点云特征将会穿越几个“门”来计算出当前时刻的隐变量ht和ct,图4中LSTM内部(绿色圆角矩形)带有符号δ的3个操作从左至右分别表示输入门、遗忘门和输出门,各门的输出分别用符号it、jt和ot表示,其计算为
(2)
式中,W表示网络中待学习的参数矩阵,δ表示sigmoid激活函数。可以发现,输入门、遗忘门和输出门的值都是结合了当前的点云特征ft以及前一帧的短时隐变量ht-1生成的。除了3个门值以外,还有一个用tanh函数来激活的记忆细胞gt,其计算方式类似,具体为
gt=tanh(Wigft+Whght-1)
(3)
有了这4个变量便可以计算出当前帧的隐状态ht和ct。首先,长时特征ct计算为
ct=jt⊙ct-1+it⊙gt
(4)
式中,⊙表示哈达玛积,即矩阵对应元素相乘。式(4)表示当前的长时隐变量是通过遗忘门值jt来遗忘一部分的过去特征ct-1,然后加上当前输入的部分特征it得到的,同时输入特征通过gt来选择记忆。
得到当前时刻长时隐变量ct之后,便可计算当前的短时特征,同时也是输出特征ht,具体为
ht=ot⊙tanh(ct)
(5)
当前时刻的LSTM隐变量ht和ct会传递给下一帧来维持时序上的关联,以此保证所估计的姿态具有时序性,从而提升估计和预测的精度,而ht同时也作为当前帧的LSTM输出特征来回归当前的姿态,如图4顶部所示。

图4 时序处理模块的网络结构Fig.4 The network structure of timing processing module
2.2.2 损失函数
本文使用完全标记数据(ITOP数据集中的有效数据)和弱标记数据(ITOP数据集中的无效数据)训练网络模型。对于完全标记的数据,即具有3维姿态标签的数据,使用3维关节损失L3D约束网络生成的姿态与真值姿态保持一致,使用2D关节损失L2D约束生成的3D姿态的投影2D姿态逼近真值2D姿态。对于弱标记数据,仅使用2D关节损失L2D约束生成的3D姿态的投影2D姿态与真值2D姿态一致。除了这些单帧姿态约束外,使用了一致性损失Lc,使生成的运动序列连续、平滑。一致性损失项作用于完全标记数据和弱标记数据。总的网络损失函数为
L=Iλ3DL3D+λ2DL2D+λcLc
(6)
式中,I是激活3D关节损失项L3D的指示函数,常数λ3D、λ2D和λc为权值。
1)3D关节损失。3维关节损失L3D根据估计的关节位置与真值关节位置之间的欧氏距离来计算,具体为
(7)
式中,q*是真值3维人体姿态,q0是预测的初始姿态,Δq是初始姿态与当前姿态之间的预测偏移量。
2)2D关节损失。利用预测关节位置的2维投影位置与真值2维关节位置之间的欧氏距离计算2维关节损失L2D,定义为
(8)

3)一致性损失。一致性损失的核心思想是变化速度和加速度在短时间内有保持不变的倾向。因此,可以对一阶和二阶导数施加约束。一致性损失Lc由预测姿态与真值姿态的一阶和二阶导数之差计算,具体为
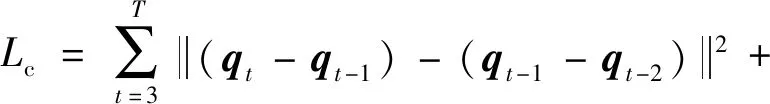
(9)
式中,第1项表示速度损失,第2项表示加速度。
2.3 运动预测
本文利用估计的人体姿态序列,通过学习预测模型来生成将来运动。可以将这个问题描述为一个序列建模问题,利用先前的姿态序列{qt-m,…,qt}估计将来人体运动{qt+1,…,qt+n}。
在实践中,本文构建了从现有的时间感受野提取的特征{φt-m,…,φt}与隐藏空间中未来运动的特征Φt之间的映射,Φt是采用LSTM模块Fp:(φt-m,…,φt)→Φt。然后,将特征向量Φt映射到运动偏移量ΔQt,n={δqt+1,…,δqt+n},ΔQ1,n是n个未来帧相对于初始姿态qt,0的运动偏移量,初始姿态qt,0是最近的具有全连接层的可用帧的姿态。预测的未来运动可通过叠加偏移量ΔQt,n到初始姿态qt,0获得。
运动预测损失Lp可以通过预测关节位置和未来帧的真值关节位置之间的欧氏距离来计算,具体为
(10)
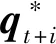
2.4 实现细节
本文采用两阶段训练策略。第1阶段只训练2维姿态估计模型;第2阶段联合训练姿态估计模型和运动预测模型。在第2阶段,冻结预先训练好的2维姿态估计模型的参数,只更新姿态估计模型和运动预测模型的网络参数。为了保证当前估计姿态与未来人体运动之间的相关性和一致性,姿态估计模型和运动预测模型的LSTM模块共享相同的参数。
观察到本文使用的数据集中,人体姿态序列在相邻帧中可以连续5帧以上保持稳定。基于这一观察,根据每个数据集的姿态稳定情况选择时间感受野。在实验中,将ITOP数据集中的时间感受野设置为13,并在5帧内预测未来运动。对于NTU-RGBD数据集,将时间感受野设置为13,并在25帧内预测未来运动。
3 实 验
3.1 数据集和评估指标
实验在ITOP数据集(Haque等,2016)和NTU-RGBD数据集(Liu等,2020;Shahroudy等,2016)上进行,本文工作在训练中只使用了这两种数据集。ITOP数据集构建目的就是用于基于深度图的3维人体姿态估计问题,有超过40 000个训练样本和10 000个测试样本,涵盖15个日常动作。NTU-RGBD数据集主要用于动作识别问题,但包含基于深度图和关节坐标的真值数据。NTU-RGBD数据集由800多万幅深度图组成,涵盖120多种日常活动。然而,其3维姿态真值数据是由微软的Kinect软件开发工具包(Kinect software development kit)生成的,存在许多误标记的人体关节。因此,本文手动选择64 529个样本进行训练,17 383个样本进行测试。与ITOP数据集相比,NTU-RGBD数据集多6个关节(包含几个手部关节),并且由于骨骼的复杂性和动作的多样性,在姿态估计和运动预测任务中带来更大的挑战性。
为了评估人体姿态估计方法的性能,实验同时采用定性和定量的评价方法。定量评价主要参考Zhang等人(2020)的工作,采用两类评价指标。第1类是姿态估计方法的总体精度,包括关键点正确率(percentage of correct keypoints, PCK)和平均精度均值(mean average precision, mAP)。PCK值是指在给定阈值条件下检测到的关键点的百分比。mAP是所有关节PCK的平均值。第2类是平均关节误差,即估计结果与真值之间的平均误差。定性评价采用用户调研的方法。具体来说,要求受试者比较本文预测的未来姿态和其他方法估计的连续姿态的质量。受试者根据预测姿态的质量,按1-5的等级打分,然后比较这些分数的平均值和标准差。
3.2 消融实验与自我比较
为了研究网络不同组成部分的影响,在ITOP数据集上对模型进行消融实验,结果如图5和表1所示。

图5 消融实验结果Fig.5 The results of ablation study((a) PCK by removing different terms in our method; (b) PCK result over different sequential length)
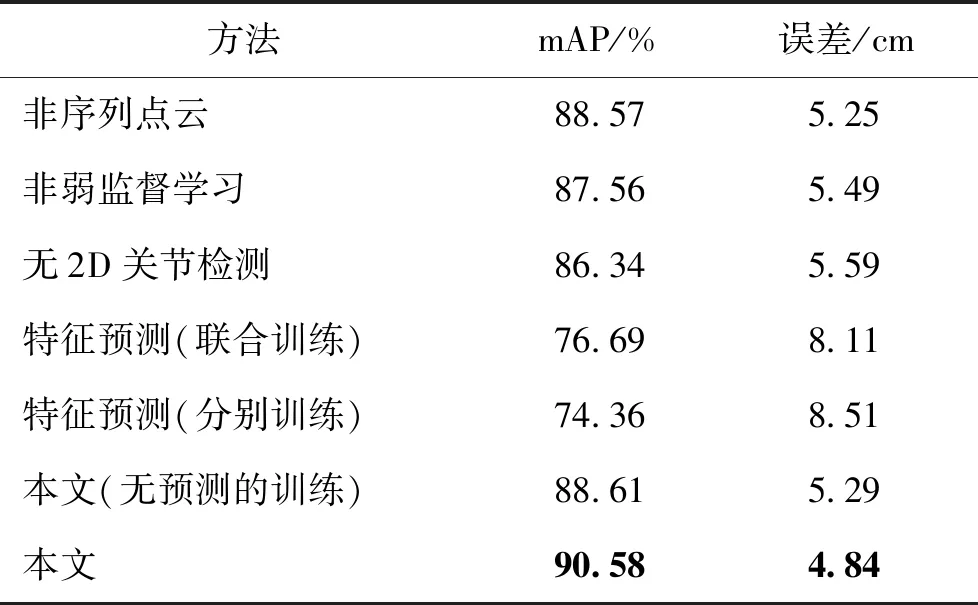
表1 消融实验结果Table 1 The results of ablation study
1)弱监督学习的影响。为了评估弱监督学习对模型的影响,比较了用全标记数据训练的模型(全监督学习)以及用全标记和弱标记数据训练的模型(弱监督学习)的结果。结果如图5(a)所示,全监督学习训练的模型PCK值为87.55%,而弱监督学习训练的模型PCK值为90.58%。弱监督学习方法将模型的性能提高了约3.03%。
此外,使用不同数量的完全标记数据和固定数量的弱标记数据训练模型。如表2所示,用1/3全标记数据(约6 000个)和所有弱标记数据训练的模型mAP值为90.04%,用一半全标记数据和所有弱标记数据训练的模型mAP值为90.16%。实验表明,弱监督学习方法利用少量的全标记数据也能取得很好的效果。
2)2D关节检测的效果。为了评估2D关节检测步骤的效果,移除网络中2D检测步骤,并在整个人体的粗略边界盒上而不是各个关节的边界盒上进行点云采样和规范化。如图5(a)所示,无2D关节检测的PCK值比带2D关节检测的PCK值低4.24%。这些结果可以解释为这样一个事实,即估计的2D姿态可以引导网络关注姿态信息更多的点云(Yao和Li,2010)。

表2 不同数量的完全标记数据和弱标记数据下的mAPTable 2 The mAP of our method with different amount of the fully labeled data and weakly labeled data
3)输入3维点云序列的作用。为了验证输入点云序列的作用,设计了不同时间感受野大小的输入点云序列实验。如果将感受野设为1,就可得非序列点云的估计结果。如图5(b)所示,当感受野设置为1时,PCK结果下降到88.57%的最低值,随着感受野从1增加到5,PCK值增加,感受野大于13时,PCK值逐渐稳定。因此,实验中感受野选为13,以在模型质量与模型大小之间取得平衡。
4)一致性损失的影响。为了评估一致性损失的影响,比较了去除一致性损失后的实验结果。从实验结果可以观察到一致性损失提高了预测的人体姿态序列的平滑度。
5)未来运动预测的结果。进行实验验证本文预测方法的鲁棒性。如表1所示,在10 cm阈值下,平均精度均值mAP为76.69%,达到了高质量的运动预测性能。定性实验结果如图6所示。
6)人体姿态估计和运动预测的多任务训练。
图6 运动预测的定性结果Fig.6 The qualitative results of our motion prediction((a) ground truth human pose sequences;(b) our predicted motion sequences)
为了验证联合训练方法的有效性,针对姿态估计和运动预测进行单任务模型训练实验。如表1所示,联合训练法的平均精度均值mAP值高于单任务训练方法。因此,联合训练策略有助于提高整体性能。
3.3 与现有方法的比较
在ITOP和NTU-RGBD数据集上,将本文方法与其他最新方法如V2V-PoseNet(voxel-to-voxel prediction network)(Chang等,2018)、视点不变方法(viewpoint invariant method,VI)(Haque等,2016)、推理嵌入(inference embedded)方法(Wang等,2016)和弱监督对抗学习方法(weakly supervised adversarial learning methods,WSM)(Zhang等,2020)进行比较,结果如表3、表4和图7所示。

表3 不同方法在ITOP数据集上的mAP值比较Table 3 Comparison of joint mAP of different methods on ITOP dataset /%

表4 不同方法在NTU-RGBD数据集上的mAP值比较Table 4 Comparison of joint mAP of different methods on NTU-RGBD dataset /%
在ITOP数据集上,设阈值为10 cm,本文方法的mAP值比WSM、VI和推理嵌入方法分别高0.99%、13.18%和17.96%,平均关节误差比VI、推断嵌入方法、V2VPoseNet和WSM分别低3.33 cm、5.17 cm、1.67 cm和0.67 cm。实验结果表明,本文方法优于其他最新方法。性能提高可能是由于序列数据作为输入和运动参数(如速度和加速度)的约束。首先,通过LSTM单元对序列数据进行编码,使模型预测也能有效对序列数据进行建模,得到更平滑的预测,提高估计性能。其次,运动参数可以消除随机采样引起的抖动,对关节坐标进行直接监督。
在NTU-RGBD数据集上,阈值设为10 cm,本文方法的mAP值比Zhang等人(2020)的WSM高7.03%。
图7为实验结果的定量比较。从图7(a)可以看出,本文方法的PCK值高于其他方法。图7(b)为不同方法的关节误差对比,显然,本文方法各关节误差明显低于其他方法。图8为关节轨迹的定性比较,给出了关节轨迹真值、本文方法和WSM方法的实验结果。可以看出,本文方法可以获得更稳定的关节轨迹,比WSM方法更接近真值。图9为本文方法在ITOP和NTU-RGBD数据集上的定性评估结果。

图7 不同方法实验结果的定量比较Fig.7 Comparison of quantitative results of different methods((a) PCK value of different methods; (b) joint error of different methods)
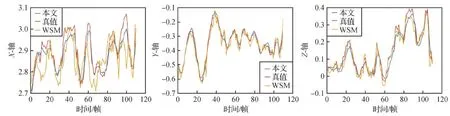
图8 运动序列中左肘关节轨迹的比较Fig.8 Comparison of trajectories of the left elbow joint in a motion sequence

图9 本文方法在ITOP和NTU-RGBD数据集上的定性评估结果Fig.9 Qualitative evaluation results of our method on ITOP dataset and NTU-RGBD dataset((a) ITOP dataset;(b) NTU-RGBD dataset)
3.4 用户调研
为了评估3维人体姿态估计结果和预测结果的质量,特别是结果的逼真度和平滑度,采用用户调研方法。邀请40名不同背景、职业和性别的用户,对本文方法的估计姿态和预测运动结果分别与真值姿态和WSM(Zhang等,2020)生成的结果进行比较。对于每一个用户,随机抽取5个运动序列,对于每个运动序列,以随机顺序显示真值姿态、本文方法的结果和WSM的结果。要求用户提供运动逼真程度的分值。分值从1(表示“最不逼真”)到5(表示“最逼真”)。然后计算各运动序列的平均得分和标准差。用户调研结果如图10所示。用户调研表明,本文方法生成的运动比WSM更逼真。即使真值有伪影,本文方法也可以产生合理的结果。用户调研也验证了序列信息的约束可以提高模型的整体性能。实验要求用户对运动预测结果的逼真度进行评分,如图10所示,本文预测方法能够在给定先前运动序列的情况下产生合理的结果。

图10 用户调研结果Fig.10 Comparison with user study
4 结 论
本文提出了一种从序列点云获得高保真3维人体姿态的有效方法。采用弱监督学习方法,能够使用更易于获得的训练数据,并且该模型对训练数据的不同层级标注具有鲁棒性。实验表明,本文提出的基于人体姿态估计的3维人体运动预测方法在两个真值数据集上都能达到先进的性能。本文方法可以应用于需要高质量人体姿态的场景,如运动重定向和虚拟试衣。本文工作将促进对以序列数据作为输入的相关研究。
本文重点探索了针对相同流形空间上的特征向量,同时进行人体姿态估计与人体运动预测两个任务的可能性。实验表明,两个任务经过联合优化求解,有互相促进的作用。该方法不仅验证了本文的推测,还给后续的人体姿态估计任务,提供了提高模型精度的新思路。
本文工作虽然取得了令人鼓舞的成果,但还有待进一步完善。由于使用数据集的局限性,本文运动预测模块主要集中在站立时的人体运动。所以当预测像跑步这样的快速运动时,性能变化并不是那么明显。如何有效处理各种类型的运动预测是今后的工作。
猜你喜欢
小哥白尼(趣味科学)(2022年1期)2022-04-26
大科技·百科新说(2021年10期)2021-12-31
上海师范大学学报·自然科学版(2021年4期)2021-09-23
学生天地(2020年3期)2020-08-25
小猕猴学习画刊·下半月(2019年6期)2019-08-13
计算机应用(2019年3期)2019-07-31
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
特别健康(2018年3期)2018-07-04
软件导刊(2016年9期)2016-11-07