
基于ARM+FPGA 异构平台的目标检测加速模块设计与实现
2022-12-19 09:23李放曹健李普谢豪赵雄波王源张兴
北京大学学报(自然科学版) 2022年6期
李放 曹健,† 李普 谢豪 赵雄波 王源 张兴,†
1.北京大学软件与微电子学院, 北京 102600; 2.北京航天自动控制研究所, 北京 100070; 3.北京大学集成电路学院,北京 100871; † 通信作者, E-mail: caojian@ss.pku.edu.cn (曹健), wangyuan@pku.edu.cn (王源), zhx@pku.edu.cn (张兴)
卷积神经网络(convolutional neural network,CNN)广泛应用于目标检测和图像分类。由于 CNN的参数多、计算量大, 在处理这类任务时通用处理器效率较低。因此, 基于 GPU (graphics processing unit), FPGA (field programmable gate array)和 ASIC(application specific integrated circuit)的专用神经网络加速器已经成为研究热点[1]。在这些方法中, 基于 FPGA 的加速器获得更多的关注。与 GPU 相比,FPGA 的能效比更高; 与 ASIC 相比, FPGA 的动态可重构性能适应深度学习算法的不断变化[2–3]。
在目标检测领域, YOLO (you only look once) 具有检测速度快、网络较为简单的特点, 适合部署在端侧平台[4]。随着算法的更新, YOLO 的后续版本使用更深的网络来实现更高的检测精度。YOLOv3使用的 Darknet-53 网络共 106 层[5], 难以在终端平台上直接部署。对网络进行适当的剪枝和量化可以有效地减少算法复杂度和存储复杂度, 同时确保推理精度[6–7], 适合硬件的实现。
Zhang 等[8]提出采用 Roofline 模型探索加速器空间, 并对不同卷积层采用统一的循环展开因子来减小设计难度。Qiu 等[9]针对加速器使用定点数计算带来精度损失的问题, 提出动态定点量化的方法。然而, 这种训练后量化的方式使得软件推理的结果与硬件不一致, 造成难以修正的误差。虽然Ahmad 等[10]设计了一种高并行度的硬件架构, 实现 460.8 GOP/s 的系统吞吐率, 但这种架构需要耗费更多的 FPGA 资源, 不适合在资源有限的平台上部署。
本文采用软硬件协同的方式, 设计一种通用的卷积神经网络加速器, 并在 ARM+FPGA 异构平台上成功部署, 实现端侧实时目标检测。在软件层面,在模型训练过程中对数据进行量化, 并将量化因子统一为 2 的幂, 方便硬件推理; 在硬件层面, 通过合理设计硬件架构, 在保证加速器性能的同时, 具备可配置性。
1 研究方案
1.1 系统级设计及软硬件划分
与同构计算相比, 异构计算兼具任务调度和并行计算的优势, 更适合完成实时目标检测任务[11]。本文利用 ARM+FPGA 异构平台来加速 YOLOv3。硬件平台可分为两部分: 可编程逻辑(programmable logic, PL)和处理器系统(processing system, PS)。PL部分是 FPGA 芯片, 是一种适用于高度并行计算的可编程器件。通用处理器进行 CNN 前向推理相对耗时, 因此将推理过程放在 PL 端。本文设计一种基于 FPGA 的 CNN 加速器, 通过增加计算单元的并行度来提高系统的实时性。PS 部分包括通用处理器和外部存储器。CNN 模型所有的参数和指令都存储在外部存储器中。通用处理器按层调度加速器, 并依据算法结果显示检测图像。系统架构如图1 所示。

图1 整体系统架构Fig.1 Overall system architecture
YOLOv3 实现目标检测的步骤如图2 所示。图像预处理的任务是将任意分辨率图片按照网络输入尺寸调整大小, 再进行归一化。此过程可以在 PS端完成。前向推理在 PL 端由硬件加速器完成。后处理过程涉及非极大值抑制等操作, 实际测试时发现耗时较多, 本文将部分移到 PL 端处理。最后由PS端完成检测框绘制。

图2 YOLOv3实现目标检测的步骤Fig.2 Steps to implement object detection using YOLOv3
系统软硬件协同设计分为以下 5个步骤。
1) 首先, 轻量级模型对实时目标检测有重要意义。网络剪枝和数据量化是降低网络复杂度并减少精度损失的有效方法。
2) 得到训练参数后, 将其提取为 ANSI-C 可读的二进制格式。
3) 用 ANSI-C 编写代码, 并验证设计。
4) 使用高层次综合(high-level synthesis, HLS)工具, 生成 RTL 代码, 并导出加速器 IP。这种方式比直接编写 RTL 代码开发效率高。
5) 最后, 将 Xilinx PYNQ 框架作为系统软件环境, 方便PL和PS间通信[12]。
1.2 模型剪枝与数据量化
近年来, 剪枝成为降低网络复杂度的有效方法[13]。针对特定检测目的, 选用轻量级网络, 经过通道和层两个维度剪枝后, 可以得到合适的剪枝模型。为了压缩模型, 并尽量减少操作数, 本文使用网络剪枝。
本文利用训练中量化的方式来提高推理精度。在训练过程中, 先对权重和特征图的浮点数据进行量化, 然后在反量化后开始训练。这样, 在训练过程中就考虑了量化带来的精度损失, 训练后得到的缩放因子可以直接用于 FPGA 上的推理, 确保软硬件的推理结果完全一致。
常见的量化方案有非对称量化、对称量化和随机量化[14]。对称量化是非对称量化的简化版本, 零点约束至0, 适合硬件部署。这种方案使用正负对称的定点区间(-2k–1, 2k–1–1)来表示在区间(xmin,xmax)内的浮点数。缩放因子 scale(Δ)指定量化步长。设浮点数为x, 量化后为xQ, 量化过程如下:
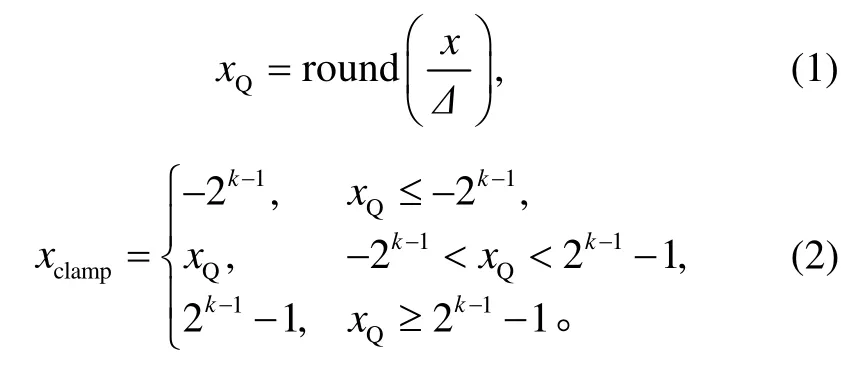
对称量化的缩放因子Δ由式(3)计算得到:

反量化结果可由缩放因子和量化值相乘得到:

以往的量化方法通常使用难以在终端部署的非线性量化函数[15–16]。本文提出一种量化方案, 统一缩放因子为 2 的幂(trainable power-of-2 scale factors quantization, TPSQ)来解决这个问题。这种量化方式在硬件上可以简化为移位操作, 从而方便地实现量化映射, 减少资源消耗, 加快运算速度。
为了获得大小为 2 的幂的缩放因子, 定义函数pow2(x)如下:

对称量化不改变浮点数的数值分布[14], 区间的映射受极值影响, 量化值在有限区间内分布不均,导致量化精度损失。区间截断是解决这个问题的常用方法。通过最小化目标损失函数, 可以找到最佳截断区间。可训练的区间截断量化函数为


其中,γ是可训练的截断区间。
通过将可训练的截断区间与 2 的幂缩放因子相结合, 本文提出的 TPSQ 同时具备二者的优势, 不但可以加速硬件上的量化映射过程, 还可以充分利用数据分布特征来减少精度损失。式(8)展示这种量化方式的前向推理过程:

反向传播过程如式(9):

φ是在反向传播中用于拟合 pow2 的函数。
1.3 硬件加速器的设计与实现
CNN 加速器的工作过程分为数据加载、数据处理和结果输出 3个步骤。在数据加载阶段, 计算所需的所有数据都从片外的动态随机存取存储器(dynamic random access memory, DRAM)传输到片上缓冲区, 包括该层的量化后权重(weight)、偏置(bias)和特征图(feature maps)。CPU 在调用 PL 端的加速器之前, 将这一层的控制信息写入 PL 端的控制寄存器, 加速器根据这些参数处理数据。每一层的输出结果必须在下一层数据加载前写回DRAM。
由于片上资源有限, 必须进行循环分块, 将特征图分割成多个分离的区域, 并尽可能多地复用片上数据, 减少访存外部存储器的次数。数据复用分为输入复用、输出复用和权重复用 3种类型[17]。本文选择输出复用方式。
如图3 所示, 输出复用包括 3个步骤。首先,在输入特征图的同一区域, 不同通道的数据依次加载到片上缓存。然后, 输出缓存的部分和将被一直复用, 直到对应分块的卷积计算全部完成。最后,将该分块存储到 DRAM 中。采用输出复用的方式,从片上缓存到寄存器的通路上, 输入特征图需要传输次, 输出特征图需要传输 0 次, 权重需传输次; 从 DRAM 到片上缓存的通路上,输入特征图需要传输次, 输出特征图需要传输 1 次, 权重需要传输次 。R和C分 别 表示输出特征图的高和宽,Tr和Tc分别表示输出分块的高和宽,Tm表示输出分块的通道数。

图3 输出复用示意图Fig.3 Explanation of output reuse
本文在不同维度间使用循环展开来提高 FPGA的资源利用率。选取输入特征图和输出特征图通道数这两个维度进行展开, 展开度分别用Tm和Tn表示, 伪代码如图4 所示。

图4 循环展开伪代码Fig.4 Pseudo code of loop unrolling
双缓存设计用于实现乒乓操作, 目的是将加载片外数据的传输延迟、计算单元的处理延迟和将数据写回 DRAM 的传输延迟尽可能地重叠。共有 4组缓存, 两组用于输入特征图, 另两组用于输出特征图。图5 展示输入侧计算和传输的时序。加速器在第一拍处理第 0 组输入缓存的数据, 同时把下一拍要处理的数据加载到第 1 组输入缓存。在下一拍,加速器进行相反的操作。此过程就是输入特征图和权重的乒乓缓存策略。在次(N表示输入特征图的总通道数,Tn表示一个输入分块的通道数)计算和数据加载之后, 最终的输出结果写入 DRAM。这样就得到一个分块的输出特征图。输出特征图的乒乓操作与此类似。

图5 双缓冲设计时序图Fig.5 Timing graph of double buffering
2 实验结果分析
2.1 软硬件实验环境
为验证本研究提出的 TPSQ 量化方法, 采用VGG16, VGG19, ResNet18, ResNet50 和 MobileNetv2模型在 ImageNet 图像数据集上进行对比实验。对于所有量化实验, 学习率最初设置为 0.001, 每 10个 epoch 衰减一次, 衰减系数设置为 0.1。将输入图像分辨率调整为 224×224, 并随机水平翻转。
硬件平台选用 Xilinx ZCU102 开发板(4 核 ARM Cortex-A53+FPGA), 其中 FPGA 的 BRAM_18Kb,DSP48E, FF 和 LUT 资源数分别为 1824, 2520,548160 和 274080。加速器使用 Vivado HLS 设计工具, 在 Vivado v2018.3 中完成综合与布局布线。采用 PF9800 高精度功耗测量仪测量板级功耗。
2.2 模型量化实验结果与对比
采用 TPSQ 对主流模型进行量化, 与之前的量化工作 TQT[18], PACT[19]和 SAT[20]进行比较。表1列出几种量化方法在验证集上的准确率。在相同的资源约束下, 与 TQT 相比, 本文方法有一定的优势。

表1 与其他量化研究在ImageNet数据集上的对比Table 1 Comparison with previous works on ImageNet
2.3 硬件部署实验结果
本研究采用 YOLOv3 目标检测算法, 将主干网络替换成轻量级的 MobileNet, 方便硬件部署[21]。以 coco2014 作为测试集的实验结果表明, 替换网络后模型参数量由 59.13 M 减至23.09 M, mAP 仅从0.580 下降为 0.547。在 Oxford Hand 数据集上进行剪枝量化实验。该数据集划分为训练集和验证集,分别包含 9163 和 1856个标注实例。压缩模型的过程中使用层剪枝及通道剪枝[22], 并使用 TPSQ 量化。模型压缩后部署至ZCU102 开发平台上测试加速效果。模型压缩前后的变化情况如表2 和 3 所示。

表2 模型剪枝前后对比Table 2 Model comparison before and after pruning
我们将上述压缩模型部署至ZCU102 平台上,实验结果如表4 所示。可以看出, 与之前的工作相比, 本文的设计在性能和资源消耗方面有一定的优势。陈辰等[23]设计了一个基于 CPU+FPGA 异构平台的YOLOv2 加速器, 本文设计的加速器性能是该设计的 13.3 倍。Yu等[24]提出了一个参数化的 FPGA 定制架构, 其优点是可以在资源有限的平台上加速 YOLOv3-Tiny, 并且具有可扩展性。虽然这种设计可以大幅降低资源消耗和功耗, 但计算性能仅为 19.64 GOP/s。 Ahmad 等[10]为 YOLOv3-tiny 设计一个加速器, 在 200 MHz 工作频率下达到 460.8 GOP/s 的计算性能。但是, 由于该设计方案是在卷积核宽高的尺度上进行并行展开, 所以资源消耗较大, 并且不合适加速有多种卷积核尺寸的网络。本文设计的加速器在 200 MHz 工作频率下, 峰值计算性能达到 425.8 GOP/s, 推测上述压缩模型的速度达到30.3 fps。FPGA 资源消耗和系统功耗如表5 所示。可已看出, 本文的设计消耗了较少的 DSP, LUT和 BRAM硬件资源, 系统功耗低。

表3 模型量化前后对比Table 3 Model comparison before and after quantization

表4 与相关文献在实验条件与结果上的对比Table 4 Comparison of experimental conditions and results in relevant literature

表5 FPGA资源消耗与系统功耗Table 5 FPGA resource and system power consumption
3 结论
本文以 YOLOv3 为例, 利用软硬件协同设计方案, 在 ARM+FPGA 异构平台上设计目标检测加速模块。为加快硬件推理速度同时减少精度损失, 本文使用轻量级的 MobileNet 网络。本文还提出适合硬件部署的 TPSQ 量化方法, 简化硬件加速器的量化映射过程。在 Oxford Hand 数据集上进行剪枝量化实验, 模型参数量减少 82.4%, 8 比特量化模型相对于原模型 mAP 仅下降 1.6%。本文还设计并实现一种在卷积输入和输出特征图数二维展开的CNN 加速器, 利用异构平台上的 ARM 核对加速器进行调度, 最终完成目标检测任务。实验结果表明,在 200 MHz 工作频率下, 加速器的峰值计算性能达到 425.8 GOP/s, 推测压缩模型速度达到 30.3 fps, 模块功耗为 3.56 W。与之前的工作相比, 本文方案从软件层面减少模型参数量, 降低精度损失, 同时方便硬件部署; 从硬件架构层面提高了加速器性能,并减少了 FPGA 资源消耗。通过软硬件协同设计方案得到的加速模块具有可配置性, 适用于不同的网络结构。
猜你喜欢
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
保健医苑(2022年5期)2022-06-10
北京航空航天大学学报(2021年9期)2021-11-02
少先队活动(2021年6期)2021-07-22
成都信息工程大学学报(2021年6期)2021-02-12
计算机应用(2020年5期)2020-06-07
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
