
分类任务中标签噪声的研究综述
2022-12-19 11:28佟强刁恩虎李丹谌彤童刘旭红刘秀磊
科学技术与工程 2022年31期
佟强, 刁恩虎, 李丹, 谌彤童, 刘旭红, 刘秀磊*
(1北京材料基因工程高精尖创新中心(北京信息科技大学), 北京 100101; 2 北京信息科技大学, 数据与科学情报分析研究所, 北京 100101; 3 北京跟踪与通信技术研究所, 北京 100094; 4.北京信息科技大学, 网络文化与数字传播北京市重点实验室, 北京 100192)
随着机器学习的发展,计算机能够从经验中学习。机器学习在许多领域都取得了显著的进步,如图像分类[1]、目标检测[2-3]、语义分割[4-5]等。近年来,分类任务在机器学习中得到广泛发展,即从标注数据集中学习得到分类模型,用来预测新样本的类别。一般来说,机器学习模型是模仿人类大脑处理决策数据的工作方式,模型是否具有良好的决策能力取决于数据集的好坏[6]。模型训练过程多采用有监督的学习,其特点是需要大量带标签数据,因此需要大规模的数据集收集和烦琐的标注过程[7]。尽可能减少数据集中的噪声是提高训练模型分类准确率的重要保障。数据中存在两种噪声:特征噪声和标签噪声[8]。特征噪声影响特征的观测值,其产生原因为数据所观察到的特征被破坏,对应着模型的输入。标签噪声则是由于标签与数据真实类别的偏差所导致,对应着模型的输出[9]。两种噪声都会使模型性能显著下降,其中标签噪声危害更大,严重影响模型的泛化性能[10-11]。数据集中噪声的存在模糊了对象特征和其类别之间的关系,这就增加了数据分类的复杂性,许多研究表明有噪声的标签会对分类器的分类精度产生不利影响。标签噪声作为数据集收集和数据标注的自然结果,使处理标签噪声成为高效计算机分类系统发展的一个重要课题[7]。
1 标签噪声的来源
标签噪声是数据集收集过程的自然结果,普遍存在于各种领域,如医学成像[12-13]、语义分割[14]、众包[1,15]、社交网络标签[16]、金融分析[17]等。现重点关注解决标签噪声的各种方法,为了更好地理解这一现象,先要调查标签噪声的原因。
首先,随着网络和社交媒体的发展,人们可以获得海量的数据,分类系统可以很好地利用这些数据进行训练[18-19]。但是,这些数据的标签来自杂乱的用户标签和搜索引擎使用的自动化系统。众所周知,获得数据集的这些过程必然会产生噪声标签。
其次,标签噪声还可能来自于领域专家,因为有时数据过于复杂,即使对该领域的专家来说也有可能无法正确标注,如医学成像。数据还可能由多个专家进行标注,从而形成多标注的数据集。每个标注数据的专家专业水平不同,他们的意见甚至可能会相互冲突,这就导致了标签噪声问题[20]。举例来说,为了收集视网膜图像的最标准验证数据,通常会从6~8个不同的专家那里收集注释[21-22]。考虑到疾病诊断这种至关重要的领域,克服标签噪声是非常有意义的。
另外,通过MTurk (Amazon mechanical turk)[15]和CrowdFlowers[1]等平台,数据标注过程可以进行众包。用自动化系统代替人工来标注数据也是一种广泛使用的方法。虽然这些数据标注方法节约了成本,但从非专家那里获得的标签通常含有大量噪声。由这些数据标注方法导致的噪声称为非专家标签噪声。最后,数据编码和通信问题也可能导致标签噪声[23]。例如,在垃圾邮件过滤中,标签噪声的来源包括对反馈机制的错误解读和意外点击[24]。
2 标签噪声的影响
在实际应用中,标签噪声主要带来负面影响,但不可否认,人工标签噪声也有其潜在作用。例如,可以在统计研究中添加标签噪声以保护人们的隐私[25]。本文主要关注标签噪声的负面影响。
首先,标签噪声会降低预测的性能,这一点在线性分类器[26]、二次分类器[27]和K最邻近(K-nearest neighbor, KNN)分类器[28]等简单模型中已经得到了证明。许多学者在其他分类器中也证实了这一问题,如由C4.5[29]和支持向量机[30]诱导的决策树等。除此之外,Boosting等集成方法也极易受到标签噪声的影响。例如,AdaBoost算法倾向于给错误标记的实例赋予较大的权重[31]。
其次,在机器学习过程中为了减小标签噪声的影响需要增加训练数据集,最终导致训练的模型复杂度增加,容易导致过拟合从而影响预测效果[32]。在概率近似正确(probably approximately correct, PAC)[33]框架中,标签噪声的存在会增加PAC识别所需的必要样本数量;在决策树和支持向量机中,标签噪声会使决策树的节点数量和支持向量机中支持向量的数量增加[23]。
此外,标签噪声可能会导致观测频率的失真[34]。在医学应用中,经常需要通过医学测试来进行疾病诊断,估计一种疾病在人群中的患病率,或者估计不同人群中的患病率,标签噪声会影响医学检测结果的观测频率,从而可能导致错误的结论[35]。
3 标签噪声的解决方案
3.1 标签噪声鲁棒模型
本小节介绍一些对标签噪声具有鲁棒性的模型。当训练数据包含少量的标签噪声时,即使标签噪声没有被净化,这样的模型也相对有效。不过,就目前大多数分类系统而言,都不具备完全的标签噪声鲁棒性。
3.1.1 集成学习方法
集成学习是机器学习分类任务中的常用算法,经典的集成学习方法有:Bagging和Boosting。Bagging每次训练随机抽取训练集的某个子集,同时生成多个分类器,最终的训练结果由多个分类器综合投票给出,从而使分类模型对噪声具有一定的鲁棒性,代表算法如随机森林。Hamsa等[36]使用随机森林(random forest, RF)分类器和小波包变换(wavelet packet transform, WPT)相结合,设计了一个从语音信号中进行情感识别的系统,系统框架如图1所示。该系统由时频分解(time-frequency decomposition)、语音分离(speech segregation)、特征提取(feature extraction)和分类模块组成,其中分类模块采用随机森林分类器。Boosting是将几个弱分类器组合在一起,形成一个强分类器,根据每次基分类器的错误率来调整训练数据集的权重,即给错误标注的样本更高的权重,代表算法如Adaboost。由于Boosting给错分样本更高的权重,容易导致分类模型对噪声过拟合[37]。王友卫等[38]提出基于合群度-隶属度噪声检测和特征选择来改进AdaBoost,综合考虑样本与周围样本的相似度以及与不同类别样本的隶属关系,即合群度和隶属度,再与动态特征选择方法相结合,最终在分类性能上较传统算法得到提升。Pakrashi等[39]提出一个Kalman Tune框架,将优化训练得到的集成模型作为一个可以用卡尔曼滤波(Kalman filtering, KF)解决的静态状态估计问题,利用KF的融合能力来减少标签噪声对集成模型的影响。当训练数据内有标签噪声时,Kalman Tune可以显著提高Boosting训练集成模型的性能。
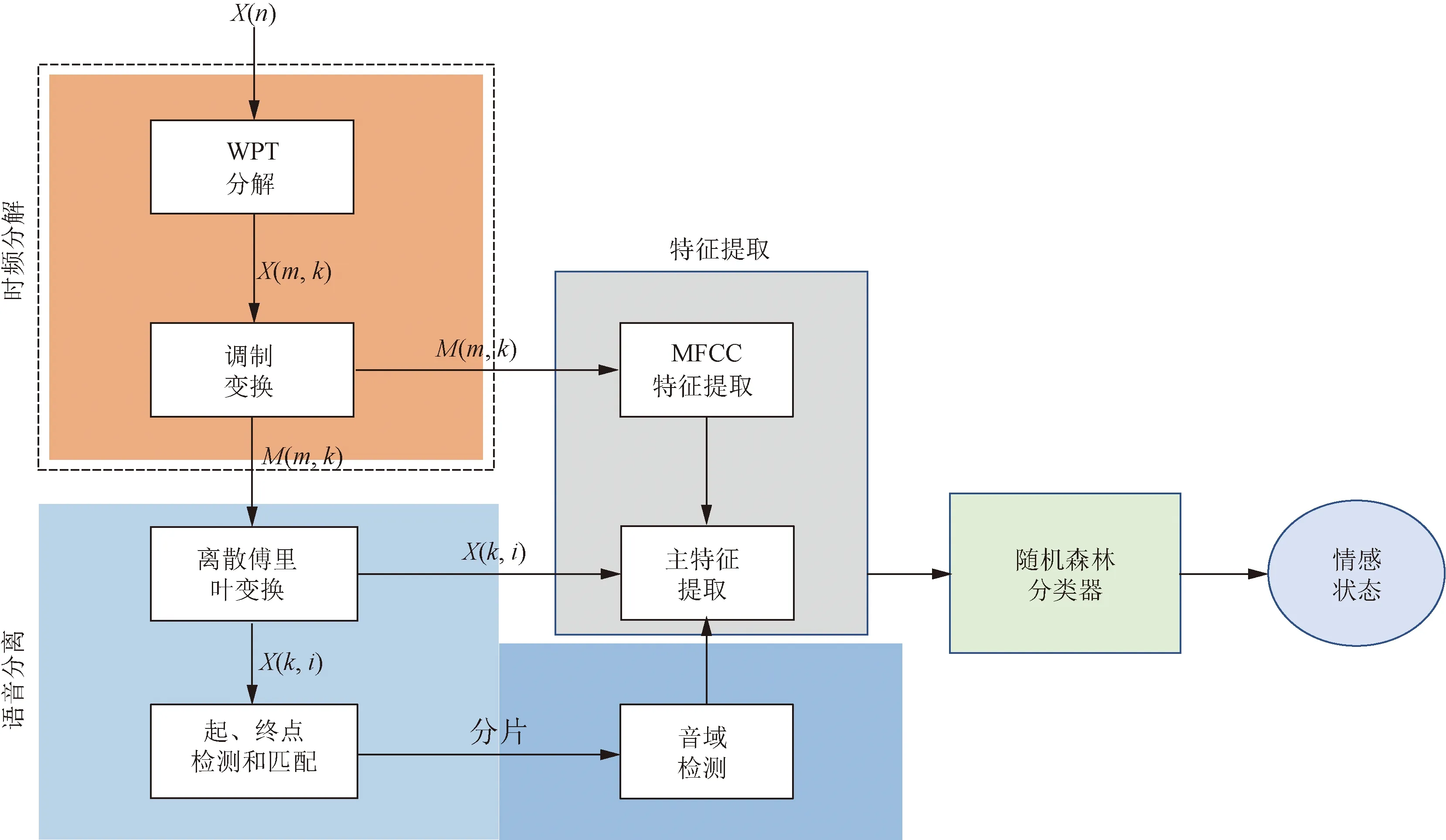
图1 情感识别系统框架[36]Fig.1 Framework of emotion recognition system[36]
动态集成选择 (dynamic ensemble selection, DES)策略是机器学习中处理分类问题最常见和最有效的技术之一。DES 系统目的是构建一个集合,根据单个分类器的能力水平从候选分类器池中选择的最合适的分类器组成该集合。Zhang等[40]提出一个动态加权框架(dynamic weighting framework, DWF),用于在获取DES系统最后输出期间进行分类融合,该方法在准确性和Kappa系数上都优于原始DES框架。
3.1.2 决策树
决策树涉及准确性和简单性之间的权衡,好的决策树需要同时兼顾这两个条件。但是,在存在标签噪声的情况下平衡这种权衡,会使过拟合问题变得更加严重。事实上,决策树的不稳定性使得它非常适合于集成方法。
医学图像去噪是医学图像处理中的关键预处理步骤,Kumarasamy等[41]提出集成朴素贝叶斯、支持向量机、决策树和随机森林方法用于查找医学图像中损坏像素,最终分类的结果由分类器的输出结果投票决定,其分类准确率能达到99.87%。
Credal决策树(Credal decision trees, CDT)已广泛用于不精确分类,即ICDT (imprecise Credal decision trees)。Moral等[42]提出将ICDT与Bagging相结合,以CDT作为基分类器,最大限度地提高Bagging分类器的精度,最终分类器的性能明显优于单个ICDT。
3.1.3 其他方法
在图像去噪任务中,Zhou等[43]提出了一个在AWGN-RVIN (additive white gaussian noise and random value impulse noise)噪声模型上训练的图像盲和非盲去噪网络,该网络由多通道噪声评估器和自适应条件降噪器组成。然后采用PD (pixel-shuffle down-sampling)策略,使训练后的模型适应真实噪声。该方法在Spatially-Variant去噪和细节保护方面效果显著。同样针对图像降噪任务,Byun等[44]提出一种新的去噪方法FC-AIDE (fully convolutional adaptive image denoiser)。该方法设计了一种新颖的全卷积架构,以增强基础监督模型,同时为自适应微调(adaptive fine-tuning)引入正则化方法,以提高其鲁棒性。该方法在基准数据集上的效果优于目前基于卷积神经网络(convolutional neural networks,CNN)的其他方法。
在图像超分辨率任务中,现有的超分辨率方法基本都假设输入的图像是无噪声的,当输入的图像被噪声污染时,它们的性能会急剧下降。针对这种情况,Xin等[45]受胶囊网络(capsule networks)的启发,提出一种面部信息的综合表示模型,称为面部属性胶囊(facial attribute capsule, FAC)。为了有效提高FAC对噪声的鲁棒性,采用集成学习策略,通过语义表示、概率分布对面部属性进行编码生成FAC,由此设计出一个面部属性胶囊网络(facial attribute capsule network, FACN),在噪声图像的超分辨率重建方面效果显著。
为应对训练数据中存在标签噪声的问题,Luo等[46]提出一种双层学习范式方法SCD (spectral cluster discovery)。通过真实标签矩阵的低秩逼近来学习一个强分类器(学习阶段),同时得到一个Affinity图(聚类阶段),两个阶段相互补充,最终提高了模型的分类精度。
许多研究表明特征提取有助于减少标签噪声的影响。受该思想启发,刘望舒等[47]基于聚类分析,提出了一种具有噪声容忍能力的特征选择框架(feature clustering with selection strategies, FECS)。
3.2 数据清洗
处理数据中的标签噪声,最直接的方法是数据清洗,即识别错误标签并将其更正为对应的真实标签或者直接删除错误标注的样本,在关于标签噪声的文献中有很多这样的清洗方法。如Feng等[48]提出一种称为ENDM (ensemble method based on the noise detection metric)的数据清洗方法。该方法首先从带噪训练集中学习得到一个集成分类器,用其导出四个指标来评估样本被错误标记可能性。对于每个指标,在使用三种不同的集成分类器(Bagging、AdaBoost和KNN)时,设置三个阈值用于识别、删除或更正损坏的样本,以最大化带噪验证集上的分类性能。
更正错误标签的过程首先要将数据中的错误标签移除,这一过程会产生有标注和无标注的数据集,可以用半监督学习方法训练这个新的数据集或者对未标注数据重新标注[49]。为了更好地利用半监督学习,标签移除的过程可以通过每次迭代来完成,从而动态地更新数据集。直接删除错误标注的实例,其思想类似于离群值检测[26]和异常检测[27]。例如,可以简单地使用基于异常的测量方法,移除高于给定阈值的样本。还可以删除不成比例地增加模型复杂度的样本[28-29]。在这些删除错误标注实例的方法中,存在移除过多数据的风险。因此,为了防止不必要的数据丢失,应尽可能少地删除样本。
数据清洗的一种思想是识别错误标签并将其更正。如果干净的样本足够多,多到可以训练一个模型时,可以通过该模型的预测来重新标注损坏样本[50]。基于这种思想,Jaehwan等[51]提出用给定噪声标签和预测标签的Alpha混合来重新标注样本。Lee 等[52]提出一种名为CleanNet的联合神经嵌入网络。该方法从小部分人工验证的类别中总结出标签噪声的知识,然后进行迁移学习,将知识转移到其他类别以处理标签噪声。Yuan等[53]提出一种迭代交叉学习策略(iterative cross learning, ICL)来处理深度学习训练数据中的标签噪声问题。该方法将含噪数据集随机划分成多个单独的子集,每个子集用于训练独立的网络,用这些独立的网络预测原始数据的标签,如果它们得出预测结果一致,则将标签更改为预测标签,否则将标签设置为随机标签。与保留噪声标签不同,设置成随机标签有助于打破噪声中的结构,使噪声在标签空间中的分布更加均匀。类似地,Jiang等[49]提出一种随机标签传播算法(random label propagation algorithm, RLPA)来清除噪声。具体来说,随机选择一些训练样本作为“干净”样本,将其余样本设置为未标记样本,用SSPTM (spectral-spatial probability transform matrix)将标签信息从“干净”样本传播到未标记样本。重复此过程,为每个样本生成多个标签,最后采用多数投票算法确定最终标签。Nguyen 等[54]提出使用给定标签和模型预测的移动平均值之间的一致性来评估给定标签是否有噪声,在下一次迭代中用干净的样本训练模型,这个过程一直持续到模型收敛到最佳估计量;基于同样的方法,在另一项研究中稍作调整,不是将预测的移动平均值与给定的标签进行比较,而是与当前epoch中的预测标签进行比较[55]。
数据清洗的另一种思想是直接删除错误标注的样本。如通过概率分类器可以把训练数据分为干净样本集和噪声样本集,根据这些子集的大小估计噪声概率[50],之后根据基网络对数据的输出置信度和估计噪声率去除大部分不可信数据。虽然这样会导致信息丢失,但在减轻噪声带来的负面影响方面会取得更好的性能。Koh等[56]提出用一个影响函数来判断哪些样本对模型训练是有害的。由于该方法需要计算每个训练样本对所有验证样本的影响,因此不易在工业实践中应用。Huang等[57]提出了O2U-Net标签噪声探测方法,该方法通过周期性地调整学习率,使网络的状态周期地在欠拟合和过拟合之间转变,如图2所示。记录下每个样本的平均损失值,循环训练结束后,实验者将所有样本的平均损失降序排列,把前k%的样本作为含有标签噪声的数据从原始数据中删除,其中k的取值取决于数据集的先验知识。最终实验结果表明,删除这些数据之后,网络的性能得到显著提高。当数据中含有大量噪声时,直接删除带噪样本可能使训练集变得过小,影响最终模型的效果。针对该问题,Zhu等[58]提出了CORES2(confidence regularized sample sieve),与前几种方法不同的是,在区分出干净样本和噪声样本之后,该方法删除噪声样本的标签而保留其特征,使用筛选过的数据训练DNN。

图2 情感识别系统框架[57]Fig.2 O2U-Net cyclical training[57]
3.3 神经网络训练策略
神经网络已经在各领域取得很大进展,但常出现对数据集中的噪声标签过拟合现象,在训练过程中通过不同学习策略提高整个过程的鲁棒性一直是近几年的研究热点,主要包括以下几个角度。
(1) 损失函数。Patrini等[59]先用ERM (empirical risk minimization) 训练神经网络,然后估计噪声转移矩阵,用该矩阵构建的修正损失函数来重新训练模型。Xu等[60]提出了一种新的基于信息论的损失函数LDMI(determinant based mutual information),该损失函数可直接应用于任何分类神经网络,且对instance-independent标签噪声具有鲁棒性。
(2) 数据集。与4.2节不同,此处并没有对数据集的标签做任何处理。Zhang等[61]提出利用少量可信数据检测离群点样本和复杂训练集bug的方法DUTI (debugging using trusted items)。但该方法需要对目标函数作一个强凸假设,而这样的假设一般情况下很难成立,所以该方法并不能适用于大多数深层神经网络。Guo等[62]提出了CurriculumNet,通过分布密度对训练数据的复杂度进行排序,将训练数据划分为多个子集。每个子集作为一个curriculum逐步让模型理解标签噪声。Mirzasoleiman等[63]提出一种利用深度神经网络训练带噪数据的新方法CRUST,该方法的核心思想是选择干净数据点的加权子集组成coresets,这些coreset可以使网络参数矩阵的雅可比矩阵低秩。具体为步骤为:①利用近似低秩雅可比矩阵提取干净子集;②进一步减少子集中的错误;③迭代降噪。为了获得良好的泛化性能并避免过拟合,CRUST 迭代地选择提供近似低秩雅可比矩阵的干净数据点子集。
(3) 双网络。从双网络角度出发的代表性方法是Decoupling[64]和MentorNet[65]。Decoupling方法用两个网络预测结果不同的样本来更新模型,但噪声标签仍均匀分布在样本的整个空间中,disagreement区域存在大量噪声标签,因此Decoupling方法不能很有效地处理噪声标签。MentorNet方法先预训练一个的网络,用该网络选择干净的数据来指导训练。当无法得到干净数据用来验证时,MentorNet必须使用预定义的curriculum,比如self-paced curriculum,但存在因样本选择偏差导致误差积累的缺点。MentorNet与上一段提到的CurriculumNet,以及O2U-Net都基于以下假设:在网络欠拟合时,梯度计算由干净样本主导。因此,标签噪声的比例和分布会对这些工作产生很大的影响。Han等[66]对上述问题进行了改进,每个网络选择干净的数据(损失率小的样本)并让另一个网络在其选定的干净子集上进行训练,三种网络的对比如图3所示。

图3 MentorNet, Decoupling和 Co-teaching的误差流向对比[66]Fig.3 Comparison of error flow among MentorNet, Decoupling and Co-teaching[66]
中国也有很多从双网络的角度克服标签噪声的研究,其中具有代表性的是周彧聪等[67]通过结合简单样本挖掘和迁移学习的思想提出的互补学习方法。该方法同时训练一主一辅两个深度神经网络模型,将辅模型的知识迁移给主模型,从而减少标签噪声的影响。
(4) 噪声转移矩阵。在标签噪声学习中,噪声转移矩阵表示干净标签转为噪声标签的概率。Xia等[68]设计了一个基于深度学习的风险一致估计器(risk-consistent estimator)来准确地调整转移矩阵。Chen等[69]将交叉验证用于估计噪声转移矩阵,之后采用Co-teaching策略充分利用识别出的样本来训练DNN。
3.4 小结
将处理标签噪声的方法分为标签噪声鲁棒模型、数据清洗、深度神经网络鲁棒训练三种。标签噪声鲁棒模型旨在对传统方法进行改进以提高其鲁棒性,数据清洗主要用于神经网络训练的预处理阶段,深度神经网络的鲁棒训练是在不改变数据标签的情况下,通过改变训练策略来提高训练鲁棒性的方法。图4所示为所讨论的处理标签噪声的所有前沿算法。
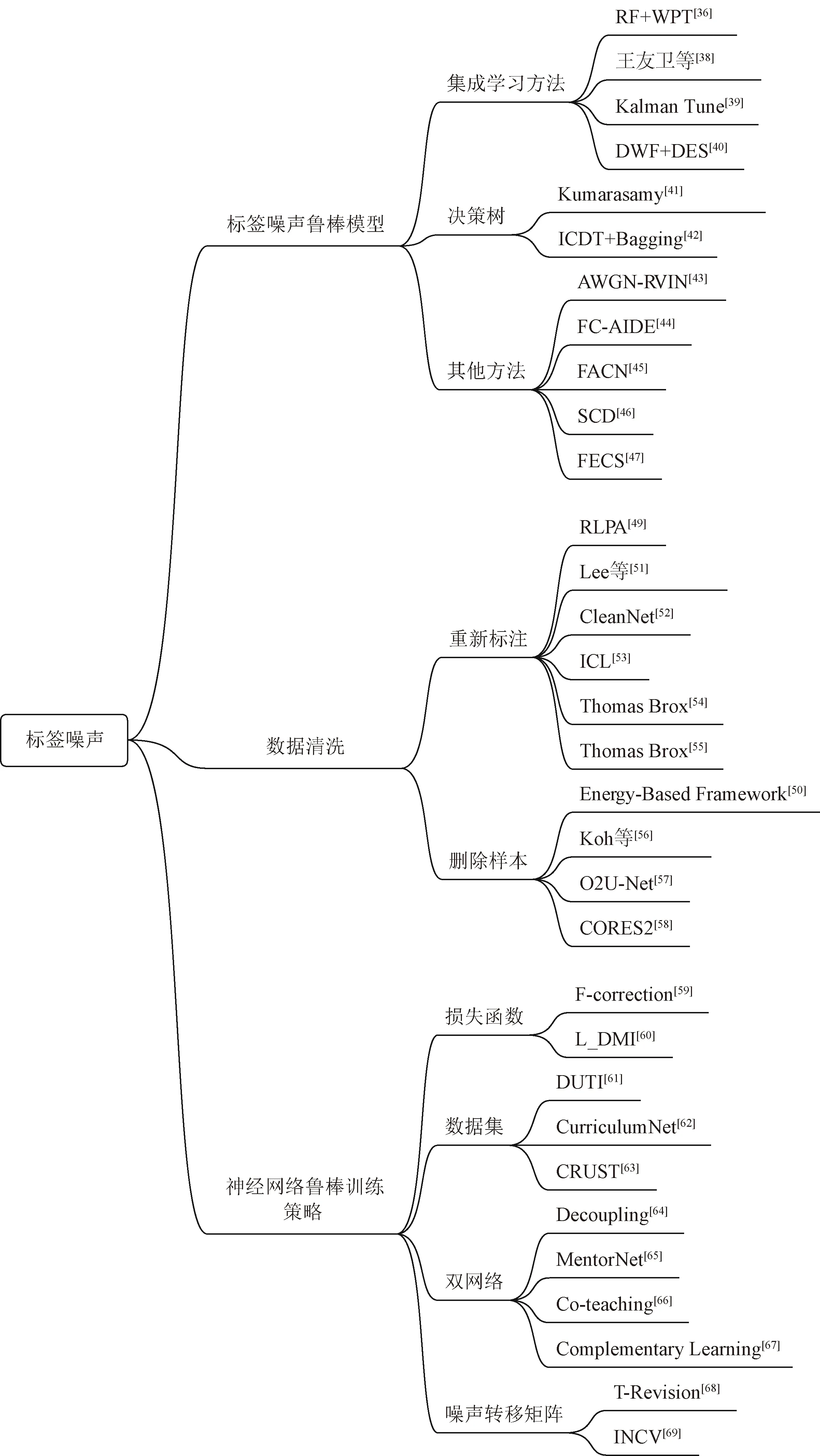
图4 处理标签噪声前沿算法小结Fig.4 Summary of algorithms for processing label noise
4 研究现状分析
对标签噪声的研究可以追溯到三十多年前[70],在最近几年仍然活跃。为研究标签噪声的发展趋势,调研了2016—2020年发表在机器学习与人工智能相关的五大顶级会议AAAI、ICML、NeurIPS、CVPR、IJCAI上的论文,对研究标签噪声的相关论文进行统计分析,统计结果如表1所示。
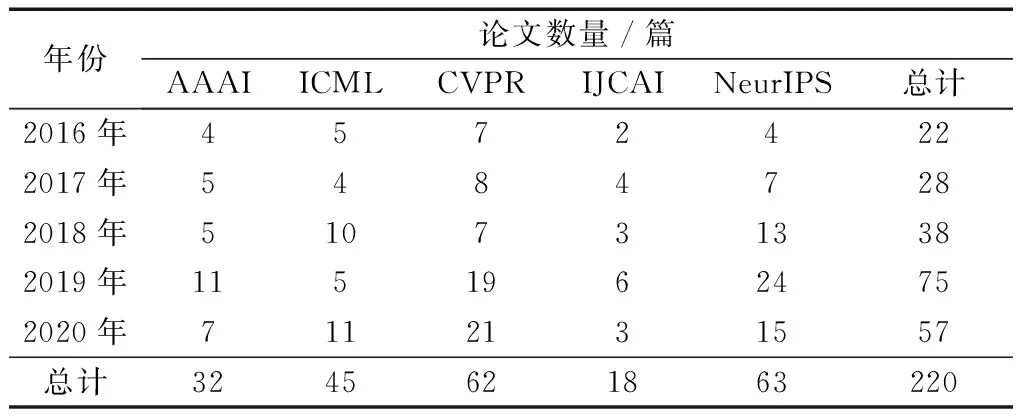
表1 2016—2020 年五大顶级会议上关于标签噪声学习的论文统计Table 1 Papers focusing on label noise published on the top five conferences from 2016 to 2020
自2016年以来,共有220篇关于标签噪声学习的论文发表在上述五大顶级国际会议中,统计调查后得到如下结论。
(1)从论文的数量上可以看出,标签噪声的研究在2019年达到了一个小高潮。同2019年相比,2020年关于标签噪声的论文数量虽略有减少,但仍领先于前几年,可以看出标签噪声学习在机器学习以及人工智能领域的热度仍居高不下。
(2)从论文的内容上来说,关于标签噪声的这220篇论文中既包括理论的研究,又包括应用的研究,且在数量上分布比较均匀,可以看出标签噪声研究在机器学习以及人工智能领域具有非常可观的理论研究价值和实际应用价值。 2020年中对解决标签噪声问题的贡献颇多,在此列举几项突出的贡献。针对严重标签噪声问题,利用小的低成本、高价值可信集合来估计样本权重和标签,再以有监督的方式训练模型,可提高对标签噪声超过90%的鲁棒性[71]。针对噪声标签和真实标签通常难以区分的问题,LDCE (label distribution based confidence estimation)可以用来估计观察标签的置信度[72],不过仍需要更有效的方法估计和利用标签置信度。
5 结论与展望
分类系统无论是在理论方面,还是在应用方面都获得了巨大的成就。但是,取得这些成就离不开强监督信息的支持。目前,存在许多不同的技术来处理标签噪声,虽然这些方法在一定程度上取得了较好的效果,但仍有许多问题亟待解决。
(1)在实际的工作场景中,数据标签的质量决定了最终分类结果的上限,通过算法的调优可以向该上限逼近。文中所提及的多数方法只在数据受标签噪声污染程度较小情况下效率高,当带噪数据的规模接近或大于干净数据规模时,算法的效率会显著下降。在工业实践中,样本数据中标签噪声往往规模巨大且结构复杂。因此,解决极端情况下的标签噪声问题是该研究课题的重点,也是难点所在。
(2)实际数据中的标签噪声可能会更加复杂。一方面,标签噪声的来源可能并不唯一。另一方面,基于网络爬虫等技术的标签生成方法存在开集问题[7],即部分训练样本的真实标签可能不在给定的标签空间内。此外,实际数据集中可能同时存在特征噪声和标签噪声,有效利用这种低质量数据集进行训练也是该研究课题的重点和难点所在。
(3)将监督学习同无监督学习进行结合处理标签噪声是该课题的研究思路。在这种框架中,无监督学习学习出的可信赖表示不受噪声影响,可以提供好的度量关系并且可以对监督学习下的表示进行修正[73]。由于需要额外的进行无监督的计算,所以该方法会受到无监督学习的瓶颈,且在大型数据集上适用度不高。随着自监督学习的兴起,为这个问题指明了方向,将这种框架应用于大型数据集提高分类任务的精度是未来该研究课题的一个方向。
(4)对标签噪声的研究存在更广阔的应用场景值得探索。在计算化学领域,由于外部条件和实验成本的限制,很多数据集中含有噪声,如何克服噪声高效地利用这些数据进行分类(例如判断化学反应的方向)和回归(如分子的属性值预测)任务是该研究课题的一个比较新颖的方向。多标签分类是分类问题中的常见任务,其在医学、文本中的应用较为广泛,例如合并症预测[74]、灾情信息检测[75]等。将效果较好的多标签分类模型应用于一些公开的分子数据集,为药物研制提供帮助也是一个较为新颖的研究方向。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
劳动保护(2019年3期)2019-05-16
计算机测量与控制(2019年4期)2019-05-08
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
Coco薇(2015年11期)2015-11-09
科技视界(2015年24期)2015-08-22
少儿科学周刊·少年版(2015年2期)2015-07-07
