
面向在线教育的同伴互评技术综述
2022-12-18 08:11杨攀原
计算机应用 2022年12期
许 嘉,刘 静,于 戈,吕 品*,杨攀原
(1.广西大学 计算机与电子信息学院,南宁 530004;2.广西多媒体通信与网络技术重点实验室(广西大学),南宁 530004;3.东北大学 计算机科学与工程学院,沈阳 110169)
0 引言
近年来,随着大数据、人工智能和互联网技术的不断发展,以中国大学MOOC(Massive Open Online Courses)[1]、学堂在线[2]、Coursera[3]和edX[4]等为代表的在线教育平台让人们能够随时随地访问优质的教育资源,极大促进了在线教育的发展。在线教育的兴起同时也给平台上的任课教师带来了严峻的教学挑战。一门热门的在线课程的选课学习者人数可高达上万人,因此批改大规模学习者提交的主观题作业(例如写作题、程序设计题、简答题等)是平台教师所面临的最大教学挑战,这是因为主观题没有唯一的标准答案,很难基于计算机技术实现自动批改[5]。考虑到主观题比客观题(例如选择题、填空题、判断题等)更能考察学习者的语言表达能力、思辨能力和创新能力[6],因此如何有效进行在线教育平台上大规模主观题作业的批改是当下需要研究和解决的重要问题。
同伴互评(peer grading/peer assessment/peer review),又被称为“同伴评估”[7-8]“同行互评”[8-10]和“同侪互评”[11-12],是指学习者以教师制定的统一评估标准为指导对同一学习环境中其他同伴的学习成果进行评价,即学习者彼此之间评估与被评估的过程[11,13-14]。同伴互评是当下应对大规模主观题作业批改问题的主流技术,已被成功运用到国内外多个代表性的在线教育平台中,例如中国大学MOOC、学堂在线、Coursera 和edX。同伴互评的实施不但能够减轻平台任课教师的主观题作业批改负担,而且还给参与互评学习者带来了诸多益处,具体表现在以下几个方面。
1)让学习者评判同伴的主观题作业,不但能够帮助他们巩固作业涉及的知识点,还能使他们学习到不同的解题思路,提高他们的课程参与度[13,15-17]。
2)同伴互评过程一般要求学习者参与批判性思考、监控和反思等一系列认知活动[14],因此有助于提升学习者的学习动机,增强学习者的社会存在感,发展学习者的高阶思维能力、元认知能力以及提升学习者的反思与批判性思考能力等[18-19]。
3)鉴于任课教师教学精力有限,学习者从同伴处获得反馈往往比从教师处获得反馈更及时[20]。
4)学习者在同伴互评中同时扮演了教师和学习者两种角色,不但有利于促进他们进行评价与反思,还有利于培养他们的责任意识[21]。
鉴于此,本文总结了面向在线教育的同伴互评技术的研究进展,以期为正在从事或打算从事同伴互评研究的人们提供借鉴与参考。本文各个章节之间逻辑关系的文章结构如图1 所示。
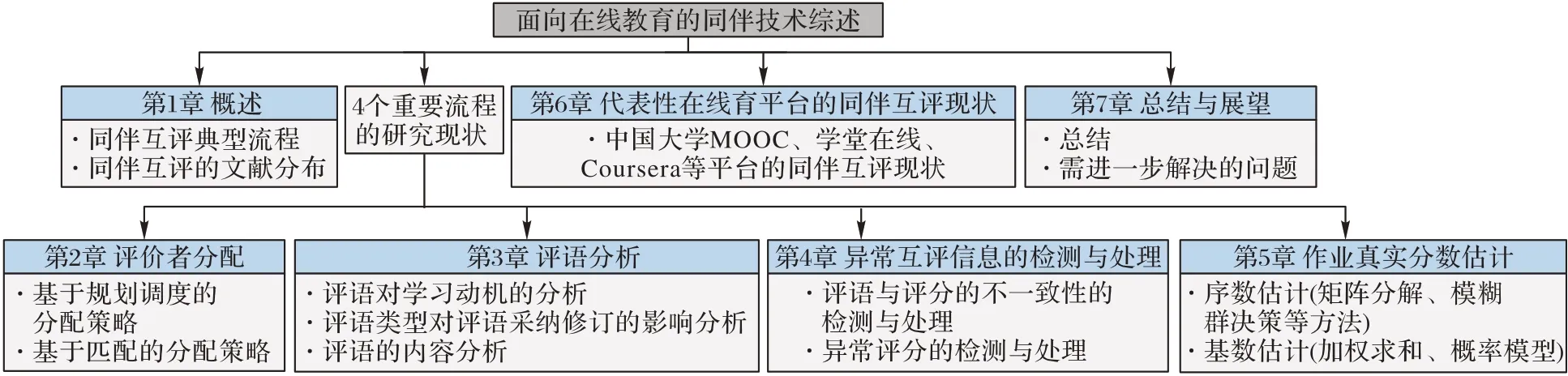
图1 文章结构Fig.1 Article structure
1 概述
1.1 同伴互评典型流程
基于对同伴互评领域大量研究工作的调研,同伴互评的实施流程如图2 所示,包括10 项活动。
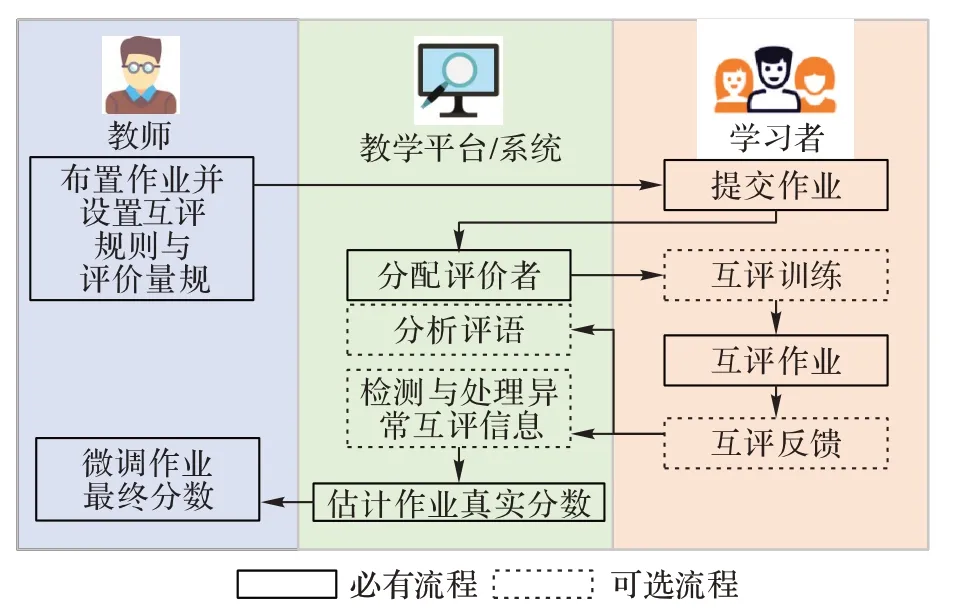
图2 同伴互评的流程Fig.2 Process of peer grading
1)教师布置作业并设置互评规则与评价量规。教师通过教学平台或系统布置主观题作业并设置供学习者互评时参考的互评规则和评价量规。
2)学习者提交作业。学习者需在教师设定的时间内提交主观题作业的答案。
3)系统分配评价者。教学平台或系统按照一定的分配算法为学习者提交的主观题作业分配教师预设数目的评价者。随机分配是最常用的分配算法。系统为每份作业分派的评价者数目通常为不小于3 的奇数[22]。
4)学习者完成互评训练(可选流程)。在正式开始互评作业之前,学习者需要按照教师在活动1)中预设的评价量规对不同质量等级的作业样例进行评价。教学平台或系统根据学习者评分与教师评分之间的吻合程度判定学习者是否具有评价资格,只有通过互评训练的评价者才能参与接下来的互评作业活动。
5)学习者(评价者)互评作业。学习者按照教师发布的评价量规评阅系统分配给他的主观题作业。在评阅过程中,学习者需要给出同伴主观题作业的评分反馈和评语反馈。根据形式的不同,评分可分为基数(cardinal)评分和序数(ordinal)评分,前者为单个作业的数值型分数,后者则是多个作业间基于质量的高低排序。两种评分反馈各具优势:一方面基数评分比序数评分更能准确地量化作业间的质量差距[23-24];另一方面序数评分比基数评分对非专家的评价者更为友好,因为非专家的评价者更容易对作业进行相对排序而不是直接给出每份作业的分数[25-26]。
6)学习者(被评价者)互评反馈(可选流程)。在学习者互评作业活动结束后,一些教学平台或系统设置了作业申诉期。在作业申诉期内,被评价者可针对其所收到的同伴针对其作业给出的评价分数和评语进行反馈,若被评价者对同伴给出的评价结果有异议,可以在平台或系统中提交异议内容并申请由教师对其主观题作业进行评价。
7)系统分析评语(可选流程)。评价者给出的评语中包含评价者对被评价作业的总结、分析和建议等信息,是对其所给评分的进一步解释。因此,分析评语能够探索评语类型与学习者采纳之间的关系,挖掘评语中隐含的学习者学习情绪,检测评语中包含的问题性或建议性信息等,这对主观题作业评估具有重要指导意义。
8)检测与处理异常互评信息(可选流程)。在互评过程中,存在由于评价者的恶意或不当行为导致的异常互评信息,包括异常评分或异常评语,因此需要及时对这类异常互评信息进行检测与处理,以保证同伴互评的质量。
9)估计作业真实分数。即基于收集到的评分数据和评语数据估计每个学习者提交的主观题作业的真实分数。取多个评价分数的平均数或中位数是常用的估计一份作业真实分数的方法。除此之外,其他估计方式还包括贝叶斯概率建模、因子分解以及加权求和等。
10)教师微调作业分数。获得对作业真实分数的估计值之后,教师可以着重关注那些多个同伴给出的评价分数中偏差较大的作业、学习者申请申述的作业或者已检测出存在反馈信息异常的作业,通过人工微调的方式为这些作业确定最终分数。
由于评价者分配、评语分析、异常互评信息的检测与处理以及作业真实分数估计4 个流程所涉及的研究成果丰富,本文将在第2~5 章分别进行分析总结;而其他流程的研究工作侧重于互评模式的研究,比如关注评价细则设置、互评前是否需要互评训练、学习者是否是匿名互评等,本文仅在此简略阐述。对于评分细则的设置,研究发现良好的评价量规不仅可以为学习者完成互评任务提供针对性的指导,还有助于学习者更好地理解学习目标,从而降低评价的主观随意性[27-29]。对于互评训练,研究人员指出它不仅帮助学习者熟悉评估流程和评价量规,还有助于提高评分准确性的外在介入因素[30-32]。Li 等[33]还发现采用游戏式的互评训练比传统的互评训练更能提高学习者参与同伴互评活动的内在动机。另外,评价者与被评价者双方匿名能够减少学习者评价作业的压力和其评价不被对方认可的恐惧感,增加互评双方的舒适感和提升双方参与互评的积极性[34-38],同时使评价者更愿意针对作业提出批评性反馈[35],从而进一步保证互评活动结果的客观性和有效性。
1.2 同伴互评的文献分布
本文对2010 年以来同伴互评领域的研究成果进行了统计分析。在Elsevier ScienceDirect、ACM Digital Library、IEEE Xplore Digital Library、Springer Link Online Library、Wiley Online Library、中国知网等文献数据库中进行搜索,统计公开发表在计算机领域或计算机教育领域的国内外相关会议、期刊中的高水平文献。其中,英文检索关键字为“peer assessment”“peer review”“peer grading”,中文关键字为“同伴互评”“同行互评”“同侪互评”和“同伴评估”。涉及的会议期刊主要包括SIGCSE、WWW、L@S、SIGKDD、Computers &Education 等。经过仔细阅读筛选,最终确定了54 篇研究文献(截至2021 年5 月)。
图3(a)统计了面向在线教育的同伴互评领域从2010 年1 月至2021 年5 月每年的文献发表数量。由图3(a)可知,随着Coursera[3]、edX[4]等慕课平台的成立,自2013 年来面向在线教育的同伴互评领域的文献数目呈稳步上升的趋势。将相关文献按图2 所示的同伴互评流程中的活动进行分类并统计每个活动对应的文献数量,详见图3(b)所示。图3(b)显示作业真实分数估计的相关工作占比最多,为35%;评语分析、异常互评信息检测与处理和评价者分配的研究工作分别占17%、15%和11%,还有22%的文献关注于探索互评训练或在互评作业时是否需要匿名等问题。后文将对重要流程中的主要研究成果进行阐释和分析。
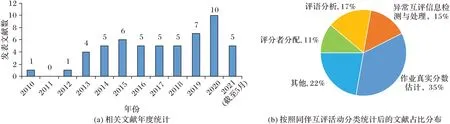
图3 面向在线教育的同伴互评相关文献统计结果Fig.3 Statistics of peer grading related literatures for online education
2 评价者分配
在同伴互评流程中,分配评价者是极其重要的环节。现有的教学平台或系统通常采用随机分配的方式为待评估的作业答案分配评价者。虽然随机分配能一定程度上保证分配的公平,但是考虑到不同学习者的知识水平、评估能力、评估态度等存在差异,随机分配并不能完全保证每份待评作业都能得到合理的评判以及互评结果的准确性和有效性。鉴于此,研究学者对评价者分配进行了深入探究,相关研究可以分为基于规划调度[39-41]和基于匹配两种分配策略[42-44]。
基于规划调度的分配策略依据评价者的知识能力水平进行评价者分配,以减少不可靠评价者给同伴互评带来的影响。Han 等[39]考虑不同学习者间知识水平的差异性,基于并行系统中常用的最长处理时间(Longest Processing Time,LPT)算法,提出了一种改进的最长处理时间(Modified Longest Processing Time,MLPT)方法,将不同知识水平的学习者平均分配到各个评分小组中,使各组间平均知识水平差异最小,从而提高了评价者分配的有效性。Capuano 等[40]基于图挖掘技术平衡知识水平能力高的优秀评价者的分配,以避免不可靠评价者带来的影响。Ohashi 等[41]则提出了一种新颖的自适应评价者分配算法及其扩展算法,这两种算法都能保证只有在评价者需要时才分配评价任务给评价者,而不是强制给评价者分配评价任务;此外,扩展算法考虑了评价者评价能力,避免了只为同一个作业分配评价能力高(或低)的评价者。
基于匹配的分配策略是同时基于评价者特性以及互评双方的作业相似度来为每份作业匹配合适的评价者。文献[42]中整合了评价者的知识背景、互评经验(互评次数与训练次数)和作业相似度等信息实现作业评价者的推荐。文献[43]中则在综合考虑评价者的评阅意愿、评阅能力和评阅双方作业相似度等多种因素的基础上,建立了评价者的推荐模型;同时利用二部图匹配理论求解评价者间的匹配问题,设计了最优均衡匹配算法。此外,Anaya 等[44]考虑了学习者受欢迎程度、主动性和亲密性等社会因素对其在同伴互评参与度的影响,提出了一种新的分配方法。
3 评语分析
同伴互评中评价者给出的作业评语蕴含着评价者对作业答案的总结、分析和建议等丰富信息,能够体现学习者的认知体系;因此,评语分析对于主观题作业评估有重要指导意义。目前学者对评语分析的工作主要涉及探索评语对学习者的学习动机的影响[45-48]、分析评语类型对学习者理解评语与实施修订的影响[49-51]和自动检测评语中是否包含问题性或建议性信息[52-53]。
由于计算机无法直接对文本评语进行计算,目前将评语转换为数值型数据的处理方式主要有两种:内容分析编码和自然语言处理技术。内容分析编码依据评语的内容从不同维度对其进行分类后映射数值编码,不同文献采用不同维度构建评语内容分析框架,并且每个维度下的类型也略有差异。例如文献[46]中主要分为情感、认知和元认知维度,情感维度细分为支持赞扬和反对批评类型,认知维度则分为直接修改、个人观点和指导建议类型,元认知维度则分为评估和反思类型。自然语言技术则有One Hot、TF-IDF(Term Frequency-Inverse Document Frequency)和Word2vec 等方法。除此之外,评语长度、是否含有表情符号也是评语分析中常考虑的因素。
Lu 等[45]对评语从认知和情感维度进行编码,研究了评语对评价者和被评价者的影响;他们发现评价者提供建议性评语有助于促进自身对知识的认知,提供积极情感评语则有助于提高被评价者的学习动机。Cheng 等[46]探索了三类评语(即情感、认知与元认知)对写作学习的作用;他们研究发现认知类评语(如直接纠正)比情感类评语(如表扬)和元认知类评语(如评价知识技能)更利于写作学习。然而随着同伴互评活动的进行,学习者更倾向于提供情感类评语,而不是提供认知类评语。Zong 等[47]则发现评语长度与互评质量显著相关,包含观点的长评论不仅能够帮助同伴,还能帮助评价者在提供评论过程中强化对内容的理解。另外,Moffitt等[48]发现在评语中使用表情符号能够增强互评乐趣,为学习者带来良好的情感体验,进一步提高学习者的参与积极性。
文献[49-51]采用对评语内容分析编码的方法探索了不同评语内容对学习者理解及采纳评语的影响;其次分析了在该影响下学习者根据评语进行作业修订的情况。具体而言,文献[49]中将评语内容分为表扬、问题解释、解决方案、本地化(系统是否支持在待批改处进行评语注释)和关注点类型进行编码,然后利用逻辑回归模型分析特征的重要性,其中,关注点包括低阶关注点(例如语法或拼写)、高阶关注点(例如过渡或论证)以及实质关注点(即内容准确性);文献[49]发现只有表扬和本地化这两个特征对学习者基于评语实施作业修订有效,且学习者一般不会修订评语中指出的高阶关注点方面的内容。文献[50]中分析发现直接明确的评语比含蓄性的评语更容易让被评者接受,并且评语中包含明确性变更和重复被指出(多个评价者对同一个作业相同或相似的评语)等特征更有助于学习者基于评语实施作业修订。文献[51]则认为评语特征包括四个认知特征(即问题识别、问题解释、解决方案、建议性意见)和两个情感特征(减轻表扬、模糊限制语),其中,减轻表扬(mitigating praise)是指通过将正面反馈添加到负面反馈中来弱化批评;模糊限制语则是指评价者在评语中添加了“可能”“或许”等词对评语进行了模糊限制。作者基于逻辑回归分析发现:学习者对评语的理解和认同能够预测学习者是否根据评语实施修订;具备问题详细解释、解决方案和模糊限制语等特征的评语更有助于学习者基于评语实施作业修订。
此外,Xiao 等[52]采用自然语言处理技术将文本评语进行编码,对评语中建议性表述的自动检测问题开展了研究,构建了逻辑回归、随机森林、朴素贝叶斯、支持向量机等分类器并取得了良好的分类效果,能够自动判别出包含建议性表述的评语。同时,还利用多种机器学习模型对评语中是否指出了作业存在的问题进行了深入研究[53]。
总之,通过对互评评语进行分析,能够更好地辅助教师有针对性地调整教学方案和优化互评效果,从而有助于学习者提高学习积极性、提升情绪体验、改善学习成效和改进认知方式,最终达到以评促教和以评促学的双重目的。
4 异常互评信息检测与处理
同伴互评过程中由于评价者的恶意或不当行为所导致的一些异常的互评信息直接影响互评结果的准确性和有效性。文献[54]中提出了利用机器学习方法检测评语与互评分数之间的不一致性,保证评语及评分数据的有效性。这种方式使教师不必逐一监控和检查每一份作业的互评信息,从而让教师只需聚焦处理被检测出的评语与分数不一致的作业,极大减轻了教师的作业评判负担。具体而言,他们尝试使用多种文本表示方式对评语进行编码表征,并利用k近邻、支持向量机、决策树、随机森林、长短期记忆(Long Short-Term Memory,LSTM)网络等算法构建回归模型预估与评语相匹配的分数;之后比较基于作业评语预估的分数与作业真实互评分数之间的差异,差异越大则说明评语与互评分数越不一致。
另外,一些研究者从其他角度检测和处理异常互评分数。例如,Rico-Juan 等[55]利用基于箱型图的统计方法分析发现可能与作业真实分数存在偏差的异常互评分数,此时教师只需对被视为异常互评分数的作业进行判定即可。赵鸣铭等[56]提出了利用哨兵机制的评价者信誉度生成算法过滤异常的恶意评分。该方法以少量教师预评分的作业作为哨兵,并利用评价者信誉度算法基于评价者对哨兵的评分情况量化评价者的信誉值,再利用阈值挑选出高信誉度评价者的评分和评语估计作业的真实分数,从而实现对恶意的高评分或低评分的隔离。Han 等[25]提出了一种人机混合评估框架检测和处理异常的互评信息。该框架首先以学习者提交的作业文本为输入,基于卷积神经网络的自动评分器预测作业得分;其次,比较评分器所得分值与互评分数,从而过滤那些两种分值间存在较大差异的异常互评分数;随后以合理的互评分数为输入并利用贝叶斯同伴评分模型[57-58]推断作业的最终真实分数,同时提示教师评价那些互评分数异常的作业。此外,Xiong 等[59]基于评价者、作业和评阅这3 个层次的特征检测评价者在评分过程中是否存在打分过于严厉或打分过于宽容的问题;通过实验发现不同层次的特征对发现互评分数的过于严厉或过于宽容的情况具有不同程度的作用,为教学平台或系统自动识别同伴互评中不准确的评分以及激励和干预不准确评价者提供了思路。
以上介绍的关于检测和处理异常反馈信息的方法在教学实践中取得了良好效果,然而这些方法均需要设定阈值识别异常信息;因而,如何根据应用的上下文设计阈值进而自适应地调整策略是需要进一步研究的问题。除此之外,James 等[60]提出了用于评估评价者可靠性的多个指标,并且通过在模拟数据集上的实验验证了估计评价者可靠性指标的有效性。Lin 等[61]提取了有助于评估评价者可信度的相关特征,并基于这些特征构建C5.0 决策树分类器自动判别同伴互评记录是否可信。Stelmakh 等[62]设计了一个测试规则用于检测评价者在序数同伴互评中是否采取了有利于提高自己作品排序的战略行为。
5 作业真实分数估计
同伴互评的核心问题是依据评价者反馈的评分和评语信息估计每份主观题作业的分数。目前在同伴互评领域已有许多估计主观题作业真实分数的研究工作,根据评价者反馈的评分内容的不同,可将它们分为序数(Ordinal)估计方法和基数(Cardinal)估计方法。
5.1 序数估计
序数估计方法要求每名评价者对分配给其的作业答案给出作业质量高低的排名,然后基于所有评价者给出的作业间的偏序排名信息推断所有作业的最终排名。现有的序数估计方法主要利用矩阵分解[63-64]、模糊决策[65-66]、贝叶斯[67]、基于配对比较[23,68-69]等方法估计主观题作业的质量。
Díez 等[63]基于矩阵分解方法学习了一个效用函数,这个函数估计所有作业的共识排序,并且这个排序很容易转换为每个作业的绝对分数。Luaces 等[64]则基于矩阵分解方法在基数估计和序数估计之间寻求一种折中的方法。该方法在评估过程中考虑了作业或学习者的特征,并且能够以较快速度处理大量作业互评数据。
Capuano 等[65]提出了一种基于模糊群决策原理的有序同侪评估模型FOPA(Fuzzy Ordinal Peer Assessment),来降低不可靠性评价者带来的影响。在该模型中,评价者对作业的排序被转换成模糊偏好关系,并通过有序加权几何平均算子对其进行聚合;然后使用聚合关系生成作业之间的全局排名,并估计其绝对分数。在后续研究中,他们引入了多重评价准则对FOPA 模型进行扩展以提高模型可靠性[66]。在扩展模型中,评价者不仅参与根据定义的评价准则对同伴提交的作业答案进行排名,而且还参与对标准本身的重要性进行排名。
Waters 等[67]提出了基于贝叶斯方法的BayesRank 模型解决以往同伴互评序数估计工作未对评价者可靠性建模的问题,并提出了一种新的马尔可夫链蒙特卡罗方法简化推断ByaseRank 中的变量。该方法不仅能够推断学习者的作业质量,还能显式推断每个评价者评分的可靠性。
基于配对比较方法指评价者对需评判的作业进行两两比较来估计全局排名和评价者的可靠性。Shah 等[23]基于经典配对比较模型BTL(Bradley-Terry-Luce)[70-71]引入同伴评价者评估能力得到扩展的序数估计模型RBTL(Refereed Bradley-Terry-Luce),从有序的配对比较中推断评价者潜在的作业评估能力和其完成的作业的质量。Raman 等[68]引入评价者的可靠性扩展了一些不同概率分布的经典排名聚合模型,包括MAL(MALlows)[72]、BT(Bradley-Terry)[70]、THUR(THURstone)[73]和PL(Plackett-Luce)[74],并使用迭代交叉最大似然估计策略估计作业真实分数和评价者的评分可靠性。Lin 等[69]则提出了一种新颖的基于配对比较的排名聚合方法,该方法利用谱算法(Spectral algorithm)来估计每份作业的真实分数以及每位评价者的评分可靠性。
5.2 基数估计
与序数估计方法不同,基数估计方法要求每名评价者对被分配的每份主观题作业给出一个数值型评价分数,然后利用不同评价者给出的评价分数估计作业的真实分数。目前主流的基数估计方法有两种:基于加权求和的估计方法和基于概率图模型的估计方法。
基于加权求和的估计方法的思想是根据评价者的准确性和信任度的差异赋予不同的权重,然后加权求和评价者对同一主观题作业答案的评分,估计该作业答案的真实分数;并且,随着同伴互评的开展,可以根据评价者在新作业的评判表现迭代更新其准确性和信任度的权重信息。De Alfaro等[75]提出了Voncouver 算法,该算法通过比较不同评判者对同一份作业答案的评分衡量每个评价者的评分准确性,并赋予准确性更高的评价者评分更高的权重,然后加权求和得到该作业答案的一致分数。对比直接将互评评分求平均,该方法可取得更高的准确度。Walsh[76]提出了另一种迭代加权算法PeerRank,该算法的设计受到Google 的网页排序PageRank算法[77]的启发。他们假设一个评价者的作业分数反映了其评价能力,基于评价者的作业分数对每一份提交作业的多个同伴评价者的评判分数进行加权求和。García-Martínez 等[78]则基于评价者的学习参与度(例如是否观看学习视频、是否完成相关章节测验)提升估计作业真实分数的准确性。Darvishi 等[79]提出了一种基于图的信任传播方法,该方法将评价者(包括学生和教师)和作业作为图中的节点,评价者的评分可靠性设置为评价者节点的权重、作业的质量设置为作业节点的权重、评价关系作为连接两种不同类型节点之间的边;其后提出了基于图结构的作业分数更新策略以及评价者可靠性的传播策略,从而可以推断作业真实分数以及评价者的评分可靠性。此外,Li 等[80]基于评价者在完成作业过程中的行为特性(例如答题时间)和评价者给出的评语信息对评价者的评分可靠性进行建模,然后以量化得到的评分者的评分可靠性为权值对他们给出的评分进行加权求和,从而得到对目标作业真实分数的估计值。Yuan 等[81]则提出了一种结合评语文本信息的半自动同伴评分方法SABTXT(Semi-Automated peer Bias grading approach with TeXTual reviews)。该方法通过两种机制提升了估计主观题真实分数的准确性,首先基于教师与评价者对以往主观题作业的评分差异对评价者的偏见进行建模和纠正;其次基于评语文本内容对评价者的评价仔细度进行建模。评价者的评价仔细度越高,其给出的评分越值得信赖,则给该评价者所打的评分赋予更高的权重以期提升对主观题作业真实分数估计的准确性。
基于概率图模型的估计方法通过构建概率图模型来估计主观题作业的真实分数。这类方法将待估作业的真实分数(Su隐含变量)、互评分数(观测变量)、评价者的可靠性及偏见(τv,bv隐含变量)都建模为服从一定概率分布(设N 表示正态分布,Γ 表示伽马分布)的随机变量,并且变量之间存在一定的关联关系,然后基于可观测评价者的互评分数推断隐含随机变量的值。Piech 等[57]首次提出了3 个概率图模型(PG1、PG2和PG3)估计作业真实分数,其中:PG1建模时考虑了评价者当前的可靠性和偏见这两个因素;PG2在PG1的基础上考虑了评价者的历史偏见;PG3则在PG1的基础上将评价者当前可靠性设定为依赖于评价者当前作业真实分数的线性函数的随机变量,详见图4(a)所示的PG3模型的数学定义的第2 行。Mi 等[58]也认为评价者的可靠性与其自身真实分数相关,但是认为PG3中两者之间的线性关系过于严格,因此弱化了此线性关系。他们将评价者的可靠性建模为满足形状参数为其真实分数的伽马分布或均值为其真实分数的高斯分布,分别得到了PG4模型(图4(b))和PG5模型(图4(c))。考虑到一名同伴评价者的评分偏见会受到其朋友的评分偏见的影响[82],Chan 等[83]利用学堂在线平台上收集到的学习者间的社交关系信息提高对评价者偏见建模的准确性,扩展了PG1、PG4和PG5这三个概率图模型。然而上述概率图模型均认为评价者给不同主观题作业的评分之间是相互独立的,存在局限性。因此,Wang 等[84]引入评价者的相对分数信息(为观测变量,即同一个评价者对不同作业评分之间的差值),基于PG4和PG5模型分别构建了PG6模型(图4(d))和PG7模型(图4(e))。这两个概率图模型有效解决了因数据稀疏性带来的参数估计问题,提高了对主观题真实分数的估计准确性。在此基础上,Xu 等[85]还考虑了评价者对主观题作业中的掌握程度对评价者可靠性的影响。他们利用评价者的历史答题信息,基于DINA(Deterministic Inputs,Noisy “And”gate model)认知诊断模型[86]计算得到评价者对主观题作业的掌握程度信息,基于该掌握程度信息优化建模PG6和PG7模型中的可靠性,分别提出了CD-PG1(Cognitive Diagnosis-Peer Grading)和CD-PG2模型,进一步提升了估计作业真实分数的准确性。表1 中对现有的概率图模型进行了对比分析。表2 则对现有主观题作业真实分数的估计方法进行了比较,√表示模型在设计时考虑了该因素。

表1 不同概率图模型的比较Tab.1 Comparison of different probability graph models

表2 主观题作业真实分数估计方法或策略比较Tab.2 Comparison of methods or strategies of true grade estimation for subjective assignments

图4 典型的概率图模型Fig.4 Typical probability graph models
6 代表性在线教育平台的同伴互评现状
近年来,得益于大数据、云计算、人工智能等技术的发展,新兴在线教育平台的功能更加全面和智能化。目前,虽然大多数平台都已支持基于同伴互评的主观题作业批改模式,但它们在同伴互评的流程与功能方面略有差异。表3 详细对比分析了当下国内外具有代表性的在线教育平台或系统,包括中国大学慕课iCourse[1]、学堂在线XuetangX[2]、好大学在线 CNMOOC[87]、Coursera[3]、edX[4]、Moodle[88]、CrowdGrader[89]和Peerceptiv[90]等。因上述所有教学平台或系统均支持教师布置作业、学习者提交作业、学习者互评作业、教师调整互评分数等功能,本章主要比较不同教学平台或系统的评分者分配、互评活动设置和作业真实分数估计这几个维度的差异性。值得一提的是,在国际上流行的三大MOOC平台(即Coursera、edX 和Udacity[91])中,Coursera 是最早引入同伴互评功能的MOOC 平台;而截至目前,Udacity 仍未引入同伴互评功能。

表3 代表性在线教育平台或系统的同伴互评模块的对比Tab.3 Comparison of peer grading modules of representative online education platforms or systems
7 结语
同伴互评作为一种解决大规模主观题作业评价问题的重要方式具有重要的实用价值与研究意义,受到来自计算机界、教育界、心理学界等不同学科领域研究者的共同关注。本文对近10 年来面向在线教育的同伴互评技术进行了深入调研并总结了该领域的研究进展,希望能够为正在从事或打算从事该领域研究的人员提供借鉴与参考。目前,面向在线教育的同伴互评领域已经取得了一定的进展,但仍存在以下需要进一步解决的问题。
1)缺乏高质量的公开数据集。
由于可能涉及个人隐私信息,目前面向在线教育的同伴互评领域只有少量的公开数据集[92-94]。Vozniuk 等[92]公开的同伴互评数据集包含60 名硕士研究生参与同伴互评后得到的评分数据以及4 名教师对学习者作业的评分数据。Tenório 等[93]组织30 名高中生参与游戏化的同伴互评活动并公开了其收集的同伴互评数据集。Ashenafi[94]公开的同伴互评数据集则涉及五门计算机课程,包含800 多名学习者参与互评活动后所收集到的与5 000 多份作业答案相关的互评信息,然而该数据集不包含教师针对作业给出的评分信息。虽然以上公开数据集为同伴互评技术的研究提供了一定的支持保障,但是这些公开数据集存在数据量较少、数据有缺失、或采集的信息不够丰富等问题。因此,为推动面向在线教育的同伴互评技术的进一步发展,急需相关学校、研究机构提供公开的、高质量的同伴互评数据集。
2)缺乏评价者的激励机制。
在多次同伴互评活动实施之后评价者可能会进入互评疲惫期,即不再愿意付出过多努力提供高质量的个人观点、指导建议、能力评估等认知型的评语[12],而认知型评语对于被评价者往往更有帮助。为解决上述问题,研究人员在设计同伴互评技术时应该结合恰当的外在或内在激励机制[95],从而激励评价者以较高的热情继续参与到同伴互评的活动中来。
3)缺乏对学习者在同伴互评过程中认知水平的追踪。
在同伴互评过程中,学习者认知能力可能在同伴评估之前、期间或之后发生变化,而追踪学习者在不同互评阶段的认知状态变化可以有效评估其学习成效以及预测其未来学习表现,这无疑有助于教师确定需特殊监督的学习者和划分出合理的学习小组[94,96-97];然而,目前鲜有对学习者在同伴互评过程中认知能力变化进行跟踪建模的研究工作。因此可以借鉴流行的知识追踪模型,例如贝叶斯知识追踪(Bayesian Knowledgeable Tracing,BKT)模型[98],深度知识追踪(Deep Knowledge Tracing,DKT)模型[99]和动态键值记忆网络(Dynamic Key-Value Memory Network,DKVMN)[100]等对同伴互评过程中学习者认知水平的追踪。
4)同伴互评活动的智能化程度还需进一步加强。
同伴互评领域目前已在评价者分配、评语分析、异常互评信息检测处理和作业真实分数估计这4 个方面取得了较大研究进展,所发表的研究工作通过在计算机上构建和运行智能化模型简化了同伴互评的实施过程,优化了同伴互评的实施质量。然而,为了使同伴互评能在更多场景下得到推广和应用,其实施过程的智能化程度还需进一步加强。例如,可以针对“布置作业并设置互评规则与评价量规”流程研究互评规则与评价量规的自动生成方法,以期进一步降低同伴互评活动中教师的参与工作量,从而让教师将更多精力用于教学内容的设计和改进。又如,可以针对“互评作业”流程研究如何为学生提供有效的评价建议和评价模板,以期提升学生的同伴互评质量和收获感。
5)同伴互评平台和系统还需进一步优化。
目前同伴互评活动的开展主要依托于在线教育平台或系统,因此如何进一步优化在线教育平台或系统的同伴互评功能非常重要。一方面,平台和系统可以进一步提高同伴互评活动在设置以及数据收集和统计方面的易用性,例如可尝试引入简短、可定制且能够直接勾选的评语词条,提高评价者对作业的评判效率和用语规范性;另一方面,平台和系统需要提供比中位数、均值和加权求和方法精度更高的基于概率图模型[57-58,83-85]的作业真实分数估计功能,从而提高基于同伴评分估计作业真实分数的准确性。
猜你喜欢
井冈教育(2022年2期)2022-10-14
中学生数理化·高三版(2022年6期)2022-07-08
甘肃教育(2021年10期)2021-11-02
四川文学(2020年11期)2020-02-06
四川文学(2020年10期)2020-02-06
统计与决策(2019年2期)2019-03-05
作文与考试·小学低年级版(2019年2期)2019-01-31
中学课程辅导·教师教育(上、下)(2017年3期)2017-03-31
散文百家(2014年11期)2014-08-21
商业经济研究(2009年30期)2009-12-23
