
深浅层表示融合的半监督视频目标分割
2022-12-18 08:11宋慧慧樊佳庆
计算机应用 2022年12期
吕 潇,宋慧慧,樊佳庆
(1.江苏省大数据分析技术重点实验室(南京信息工程大学),南京 210044;2.江苏省大气环境与装备技术协同创新中心(南京信息工程大学),南京 210044)
0 引言
视频目标分割一般指半监督视频目标分割,就是给定视频中第一帧特定物体的精确分割结果,然后在后续帧中准确地对目标进行分割。半监督视频目标分割是计算机视觉中的一项重要任务,在动作识别[1-2]、自动驾驶[3-4]、视频编辑[5]中有着广阔的应用前景。但视频中往往都伴随着目标物体的外观变化,也会含有与目标物体相似的背景物体,因此对视频中目标物体进行准确的分割是一项充满挑战性的任务。而随着深度学习的兴起与发展,半监督视频目标分割领域涌现出大量优秀的算法,推动了半监督视频目标分割的发展。
为了实现对视频中目标的准确分割,多种算法从不同的方面进行了尝试。文献[6-9]中的算法利用第一帧给定的掩膜对分割网络进行微调来学习特定目标的外观特征。文献[10]中的算法则是在此基础上进行了扩展,通过在后续视频帧上进行额外的微调来学习目标外观特征。微调操作使得上述算法在视频目标分割数据集上获得了非常不错的效果,但与此同时微调导致计算成本过高,算法运行时间过长,难以满足实时性的要求。另外,微调导致网络容易过拟合,当目标发生形变或者场景中出现与目标相似的物体时,算法性能就会受到很大的影响。
文献[5,11-13]中的算法通过帧与帧之间的特征关联[5]以及特征匹配[11-13]来设计整个网络,从对应于初始位置目标标签的特征构造外观模型,然后使用经典聚类方法或特征匹配启发的技术对输入帧中的特征进行分类,进一步提高分割精度。这些方法不需要计算成本相当高昂的在线微调,但是由于特征匹配效率并不高,因此虽然精度有所提高,但速度却大打折扣。视频目标跟踪[14]与分割存在一定的联系,视频目标分割实际可以看作目标在像素级别上的跟踪。文献[15]中的算法通过在文献[16]中的算法上添加一个分割分支来缩小跟踪与分割之间的差距,该算法的运行速度相较于之前的算法更快,在DAVIS 数据集[17-18]上取得了不错的结果。文献[19]中利用已有的跟踪器,在视频中先对目标进行跟踪,将跟踪到的物体从视频帧中分离开来进行更加精确的分割操作。这一类的算法在速度方面相较于微调以及特征匹配的算法具有明显的优势,但是,此类算法的分割精度在很大程度上取决于跟踪效果,如果跟踪效果不佳,那么分割结果必然也会受到很大的影响。
学习快速鲁棒目标模型的视频目标分割(learning Fast and Robust Target Models for video object segmentation,FRTM)算法[20]利用预生成的粗糙分割掩膜作为引导信息得到更精确的分割图像。该算法在速度与精度方面均取得了不错的效果,但对粗糙掩膜的利用比较简单,因此也存在较大的提升空间。
针对以上算法存在的不足,本文提出了一种深浅层表示融合的半监督视频目标分割算法。该算法通过所设计的高效高阶注意力(Effective High Order Attention,EHOA)模型,从骨干网络特征中提取出丰富的语义信息。结合粗糙分割掩膜,设计了一种融合分割模块,促使网络学习到更鲁棒的特征,从而在保证分割速度的情况下,提高了分割精度。将本文算法应用于基线算法FRTM 上,并在多个主流数据集上进行评测,结果充分证实了本文算法的有效性。
1 本文算法
FRTM 通过简单的双层线性卷积网络构建目标模型,使用视频首帧图像及标签进行训练,预先生成较为粗糙的掩膜,再通过分割网络对粗糙掩膜及骨干网络特征进行简单融合,在分割精度与速度方面取得了很好的效果。粗糙的掩膜信息带有非常丰富的前景目标轮廓位置信息,对目标的最终分割结果有着重要的引导作用;但是,该算法仅将掩膜特征与骨干特征简单拼接送入分割网络,在分割精度方面仍有待提高。
本文算法基于基线算法FRTM 进行设计,网络整体框架如图1 所示,本文网络主要包含特征提取模块、粗糙掩膜生成模块、特征聚合模块、融合分割模块四个部分。其中,特征提取模块采用ResNet101[21]为其后面三个模块提供特征输入,粗糙掩膜生成模块[20]用于生成粗糙掩膜,特征聚合模块将输入的特征进行聚合,融合分割模块将收集到的各类信息融合,输出最终的精细分割图像。
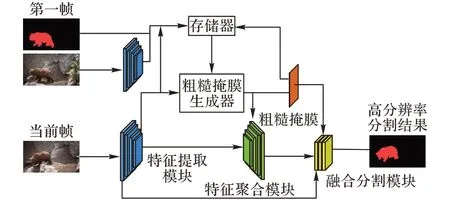
图1 网络整体框架Fig.1 Overall network framework
首先,将图像输入到特征提取模块中进行特征提取,提取到的特征放入存储器中,作为粗糙掩膜生成模块的输入,并且通过高斯牛顿优化方法[22]进行优化,得到粗糙的分割掩膜。在特征聚合模块中,粗糙的分割掩膜与特征提取模块中的各层特征先进行拼接融合,再送入高效高阶注意力模型中。特征聚合模块中的高效高阶注意力模型能够使得特征更加专注于像素级别的变化,因此能够提取出更加精细化的特征。聚合后的特征经由粗糙掩膜提取到的特征进行引导,送入融合分割模块中与处理过的特征提取模块中的第二层特征进行融合分割,最终得到精细的分割结果。
相较于FRTM,本文的不同之处在于特征聚合模块中的EHOA 模型以及所设计的融合分割模块。特征聚合模块中的EHOA 模型提取深层次的语义特征,融合分割模块充分利用了粗糙掩膜,提高了分割效果。
1.1 高效高阶注意力模型
特征聚合模块将特征提取模块输出的各层特征与插值后的粗糙分割掩膜进行拼接,经过卷积滤波后送入通道注意力模块以及高效高阶注意力模型中,输出聚合特征。特征聚合模块结构如图2 所示,其中,粗糙掩膜S和骨干网络各层特征χ(d)循环输入到特征聚合模块中,上一层的输出Z(d)反馈到通道注意力模块[20]中,一共循环输入4 层骨干网络的特征。

图2 特征聚合模块结构Fig.2 Feature aggregation module structure
在行人重识别[23-26]、视频超分[27]等相关领域中,注意力机制[28]被充分证明对视觉特征的提取具有很好的效果,注意力能够将提取出的特征更加偏向于网络所需要的特征。因此,本文在高阶注意力(High Order Attention,HOA)模型[23]的基础上,提出高效高阶注意力(EHOA)模型。
EHOA 结构如图3 所示,输入X经过卷积网络,再与X逐元素相加,经激活函数后输出X0:
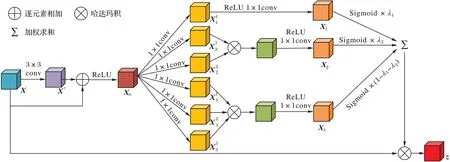
图3 高效高阶注意力模型Fig.3 Efficient high-order attention model


其中:*表示对应元素相乘;f1、f2、f3表示卷积激活操作。通过上述式(2)~(4),由同一特征得到了3 个不同阶次的注意力信息,将3 个不同权重按式(5)进行加权取平均:
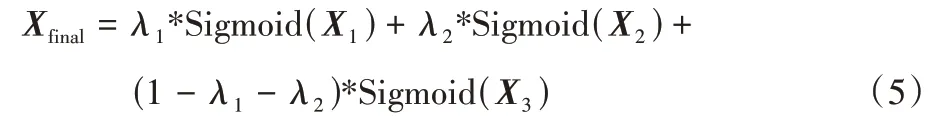
最终按式(6)得到最终输出:

注意力模型通常分为空间注意力模型和通道注意力模型,即在图像空间位置以及通道方向上进行加权。视频目标分割是一项像素级别的分类任务,需要更加精细的注意力机制来提取所需特征。本文所提高效高阶注意力模型,其最终输出为一个与输入特征维度相同的权重矩阵,即对特征在空间以及通道上均进行了加权,相较于单一的通道注意力以及空间注意力机制,能够提取更加精细的特征。
HOA 在后续的特征融合阶段将不同阶次的特征直接相加得到最终的注意力特征。但是这样的操作没有考虑到不同阶次的特征所包含的语义信息存在差异,直接相加会导致部分信息的损失。因此,本文EHOA 模型考虑对特征加入不同的权重减少该部分信息损失,具体地,以粗糙掩膜和骨干网络特征拼接得到的特征作为输入,首先经过一个跳跃连接,利用ReLU 激活函数的单侧抑制性,对特征信息进行初步去噪。根据3 种阶次语义信息的丰富程度设置不同的权重对特征信息进行整合,从而提取最佳的注意力信息,本文权重最终设置为λ1=0.2,λ2=0.3。对于该部分权重的选取将在后续实验中给出。
综上所述,本文高效高阶注意力模型相较于HOA 在引入少量参数的情况下通过设定不同阶次的权重能够更高效地提取网络中的注意力信息,更有效地提升本文算法的分割效果。
1.2 融合分割模块
半监督视频目标分割存在两大难点:1)是否能够区分分割目标与相似物体;2)是否能够准确判别前景与背景之间的边缘位置信息。前者需要网络中有足够丰富并且鲁棒的深度语义信息,后者需要的则是较为浅层的边缘位置信息。因此,本文提出融合分割模块,同时利用网络深层语义信息以及浅层位置信息。
融合分割模块结构如图4 所示。经优化得到的粗糙掩膜带有鲁棒的前背景信息以及纹理信息,因此本文利用带有丰富纹理特征的粗糙掩膜作为引导信息来引导聚合后的深度特征。
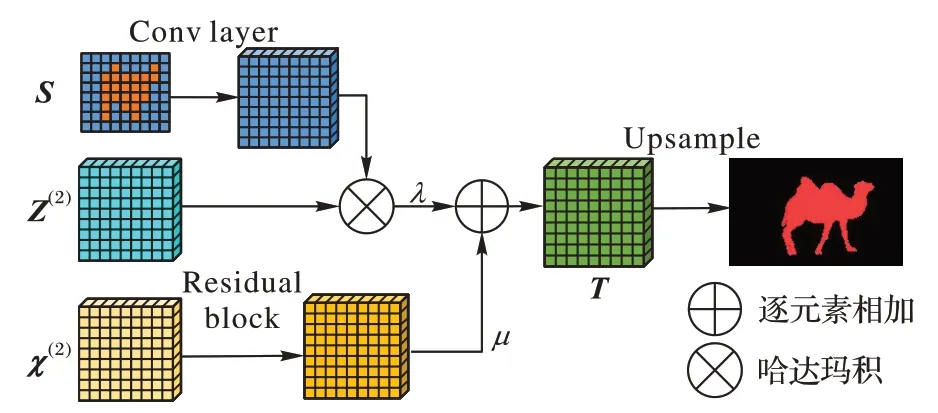
图4 融合分割模块Fig.4 Fusion segmentation module
首先对粗糙掩膜进行插值,再经卷积网络将插值后的掩膜通道数进行扩展,使其与深度特征具有相同的维度,利用扩展通道后的掩膜过滤深度特征中重复的语义信息。
骨干网络中,浅层特征带有更为丰富的边缘纹理信息,而在分割任务中,对前景与背景之间的边缘轮廓的辨别能力是评价分割结果的重要指标,因此,网络浅层特征对提高算法性能有很重要的作用。
基于上述分析,本文将经粗糙掩膜加权后的深度特征与骨干网络浅层特征按式(7)进行融合:
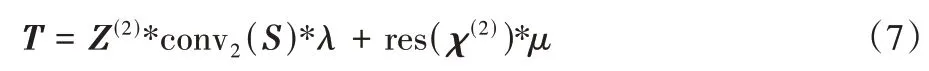
其中:T表示融合后的特征;Z(2)表示特征聚合模块最终输出的特征;S表示粗糙掩膜权重;conv2表示粗糙掩膜的加权网络;χ(2)表示骨干网络第二层输出特征;res 表示残差网络;λ、μ表示超参数,控制加权深层特征与浅层骨干网络特征之间的权重关系,本文方法中的λ和μ设置为1 时,效果最佳。
2 实验与结果分析
2.1 训练设置
本文训练与测试设备均为一张RTX 2080Ti 显卡。特征提取模块采用ResNet101 作为骨干网络,为保证实验的公平性,本文采用与FRTM 相同的训练方法,包括粗糙分割掩膜的优化训练部分以及其他模块的分割训练部分。
1)粗糙掩膜训练。首先将第一帧图片以及第一帧掩膜进行数据增广。特征提取模块所得的特征作为输入,下采样后的首帧掩膜作为标签送入粗糙掩膜生成器[20],粗糙掩膜生成器的结构是两层线性卷积层,通过高斯牛顿法[22]优化参数,接着将后续帧的特征输入到生成器中生成粗糙掩膜,将输入特征与粗糙掩膜放入存储器中构建一个固定容量的数据集来持续优化生成器参数。
2)分割训练。网络中特征聚合模块,融合分割模块的参数通过离线训练的方法学习。
本文将DAVIS 2017 和YouTube-VOS[29]作为训 练数据,采用Adam[30]优化器进行优化,训练260 个周期,初始学习率α设为1E-3,衰减率β1设为0.9,β2设为0.999,权重衰减率设为1E-5。每120 个训练周期,学习率缩减为原来的1/10。
2.2 评价指标
本文主要采用DAVIS 2017 的标准评价指标,包括雅卡尔指标J和F得分。其中,J为标注真值与分割结果的区域相似度,公式表示为:

其中:M表示预测值,G表示标注真值。
F被用来描述预测的分割结果的边界与标注真值的边界之间的吻合程度,公式表示为:

其中:P为查准率,R为查全率。并且,本文还采用J与F的均值J&F作为综合评价指标:

2.3 不同数据集上的结果比较
2.3.1 DAVIS 2016数据集上的结果比较
DAVIS 2016 数据集中每一个视频序列只标注一个目标,是一个单目标视频目标分割数据集,其中包括了30 个用于训练的视频,20 个用于验证的视频。表1 中展示了本文算法与其他先进算法在DAVIS 2016 验证集上的比较结果。为体现实验的公平性,FRTM[20]与本文算法所测数据均在RTX 2080Ti 设备中测得,其余均使用公开数据。与表1 中其他算法不同的是,本文算法以及FRTM 并未使用预训练的分割模型以及额外数据集。从表1 中可以看出,本文算法的雅卡尔指标J=85.5%,相较于FRTM 提高了1.8 个百分点;综合指标J&F=85.9%,相较于FRTM 提高了2.3 个百分点,而速度使用帧率(即每秒传输帧数(Frames Per Second,FPS))衡量,相差不大。在所有运行速度较快的算法中,本文算法是分割效果最好的。相较于其他算法,本文算法在速度与精度的平衡性上更为突出。
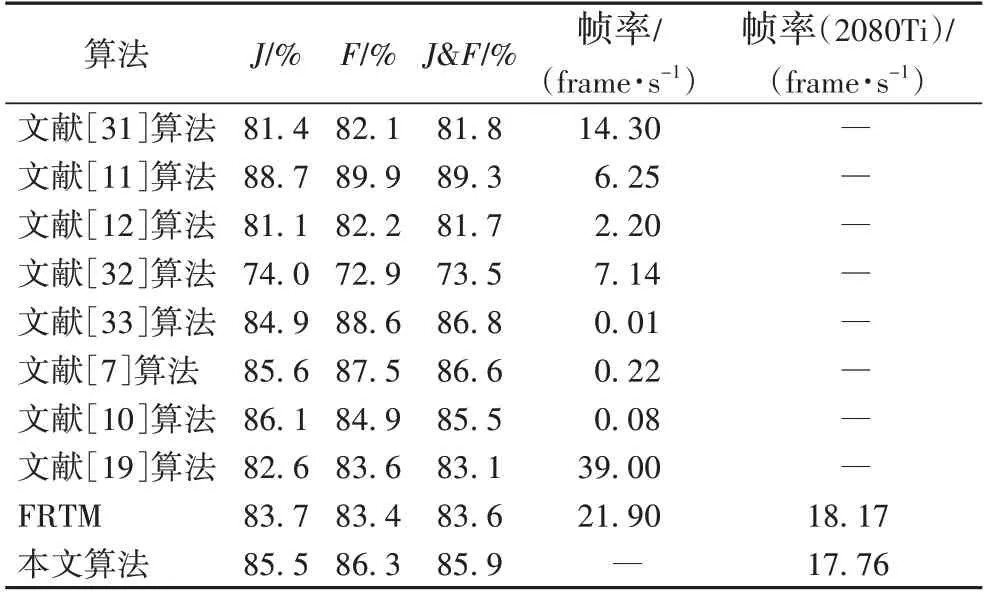
表1 不同算法在DAVIS 2016验证集上的评估结果Tab.1 Evaluation results of different algorithms on DAVIS 2016 validation set
2.3.2 DAVIS 2017数据集上的结果比较
DAVIS 2017 数据集是在DAVIS 2016 数据集上扩展而来的多目标视频目标分割数据集,其中60 段视频用于训练,30段视频用于验证,30 段视频用于测试以及30 段视频用于竞赛。该数据集相较于DAVIS 2016 数据集,数据量明显增加,但同时场景更加复杂,分割难度也显著增加。表2 中展示了不同算法在DAVIS 2017 验证集上的比较结果。在该数据集上,本文算法的雅卡尔指标J=75.0%,相较于FRTM 提高了1.2 个百分点;综合指标J&F=77.8%,相较于FRTM 提高了1.1 个百分点,并且相较于无时序信息的视频目标分割(Video Object Segmentation without Temporal Information,OSVOS-S)算法[7]等在DAVIS 2016 数据集上取得不错效果的算法,本文算法在这个更具挑战性的数据集上体现了良好的优越性。
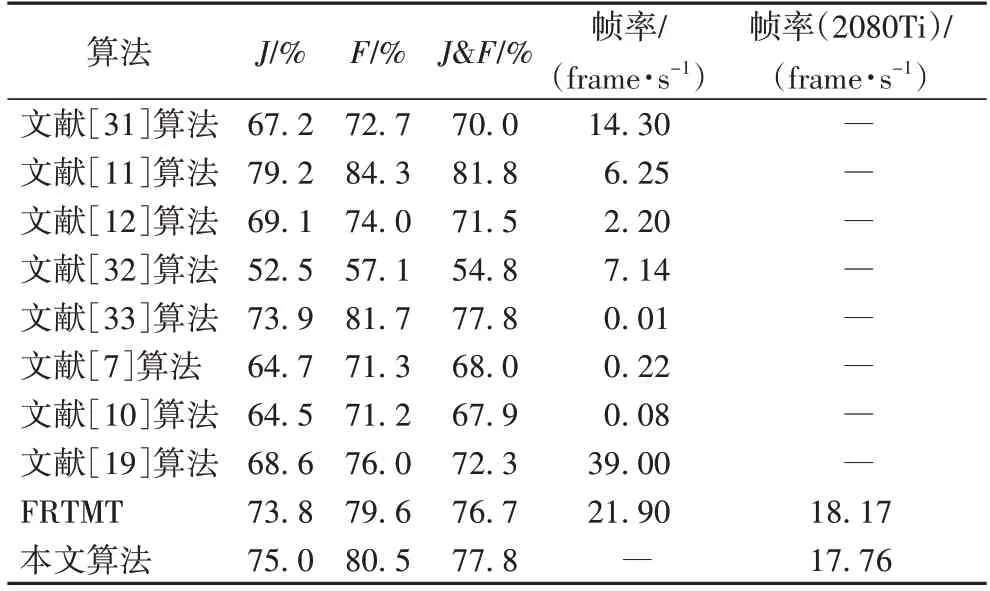
表2 不同算法在DAVIS 2017验证集上的评估结果Tab.2 Evaluation results of different algorithms on DAVIS 2017 validation set
2.3.3 YouTube-VOS数据集上的结果比较
YouTube-VOS 验证集有474 段视频,共有91 个类别,其中有26 个类别为未见类别。分别计算可见与未见类别的J和F作为评估指标,g为4 个单项指标的均值。表3 展示了不同算法在YouTube-VOS 验证集上的结果。由表3 可以看出,本文算法的综合指标g为67.1%,在没有使用额外数据和分割预训练模型的情况下排名第二。尤其,本文算法的F指标在可见与未见类别上取得71.3%和68.4%的出色性能,超越其他对比算法。体现了本文算法区分前景背景边缘位置的出色性能。
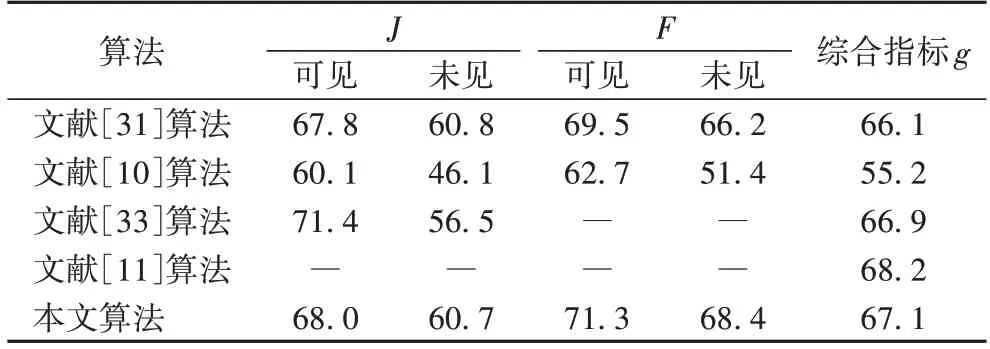
表3 不同算法在YouTube-VOS验证集上的评估结果 单位:%Tab.3 Evaluation results of different algorithms on YouTube-VOS validation set unit:%
2.4 消融实验
表4 展示了本文算法中EHOA 模型、融合分割模块在DAVIS 2016 验证集下的消融实验结果。其中Base 表示本文算法同时去掉EHOA 模型和融合分割模块之后的基础网络,使用Fuse 表示融合分割模块。通过表4 中四种算法变体来验证算法各部分的作用。可以发现,在不考虑EHOA 模型的情况下,J&F达到81.4%。在Base 模型加入EHOA 模型的情况下,算法性能提升了3.2 个百分点;在Base 模型下加入Fuse,算法性能提升了3.8 个百分点。由此可见本文算法中的EHOA 模型以及融合分割模块对网络的整体性能提升均有明显作用,两部分共同作用,最终提升了4.5 个百分点。

表4 消融实验结果 单位:%Tab.4 Ablation experimental results unit:%
表5 展示了EHOA 模型与HOA 模型的实验结果对比,本文所提EHOA 模型的最佳结果(85.9%)相较于HOA 模型的性能提升了0.9 个百分点,证明本文所提模型提取网络注意力信息更为高效。表5 中同时展示了EHOA 模型在不同权重下的算法表现,其中,λ3=1-λ1-λ2。从表5 中可以看出,当各阶特征单独作用时,EHOA 模型的性能均低于HOA 模型;λ1、λ2过小分别为0.1、0.2 时,一阶特征和二阶特征对模型整体影响过小,EHOA 模型的性能相较于最佳结果降低了0.8个百分点;λ1、λ2过大分别为0.6、0.3 时,包含更丰富语义信息的三阶特征信息损失过多,EHOA 模型的性能相较于最佳结果降低了0.9 个百分点;λ1为0.2、λ2为0.3 时,三种阶次特征权重处于相对平衡,EHOA 模型取得最佳性能。充分说明当前模型按特征阶数赋予不同权重的有效性。
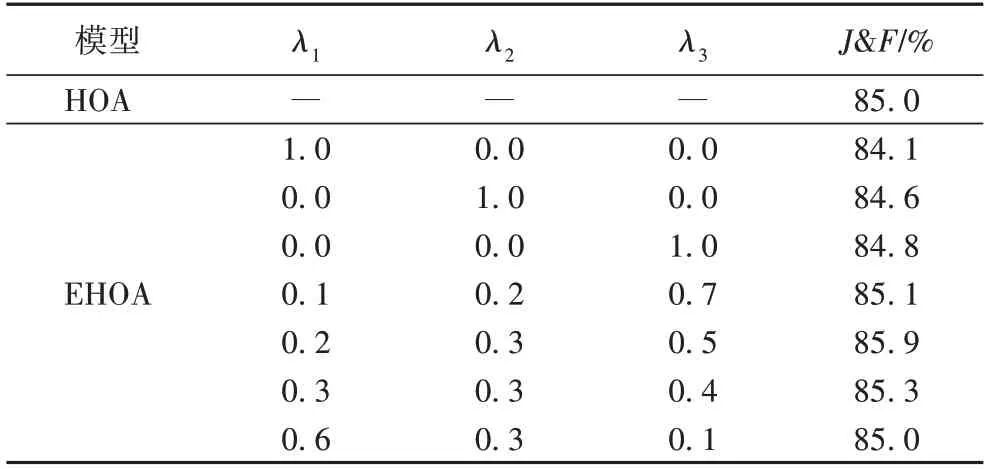
表5 EHOA模型与HOA模型的实验结果对比Tab.5 Comparison of experimental results of EHOA and HOA models
表6 展示了融合分割模块对本文算法在性能方面的影响。将ResNet101 的四层输出分别与加权后的聚合特征进行融合,可以发现,越浅层的特征对算法的性能提升最大,Layer2 的特征相较于Layer5 的特征,算法性能提高了1.1 个百分点,并且越浅层的特征具有的通道数越少,进行融合计算时所需要的计算代价也越小。综上,本文将高效高阶注意力模型与融合分割模块相结合,在没有过多加大计算负担的情况下,取得了较高的精度,在精度与速度上更加平衡。

表6 不同层特征的实验结果对比 单位:%Tab.6 Comparison of experimental results with features of different layers unit:%
2.5 可视化结果
为更直观地展现本文算法的分割效果,对分割结果进行了可视化。
图5 展示的是DAVIS 2016 中一段骆驼视频的分割结果,视频首帧只出现了一只骆驼,根据半监督视频目标分割的任务设定,整个视频中首帧出现的骆驼为需要分割的前景目标,而后续帧中出现的骆驼则为视频中的相似干扰目标。可以看到,在视频中出现另外的属于背景骆驼的情况下,本文算法能够更好地抑制干扰,作出准确的分割,体现了本文算法在区分相似前景背景方面的出色性能。

图5 在DAVIS 2016数据集上的可视化结果对比Fig.5 Comparison of visualized results on DAVIS 2016 dataset
图6 展示的是DAVIS 2017 中一段人与狗的视频。在这段视频中,需要将视频中的3 个物体分割出来。在前几帧,物体的形变与移动距离并不是很大,因此,分割难度不是很大;但是在视频后面几帧,物体发生了比较大的形变与移动,分割难度变大。可以看到,在视频后面几帧,当物体出现比较大的形变和移动的时候,本文算法仍然能够正确分割出物体,表现出了更强大的稳定性。

图6 DAVIS 2017数据集上的可视化结果对比Fig.6 Comparison of visualized results on DAVIS 2017 dataset
3 结语
本文在FRTM 算法的基础上提出了一种深度注意力特征与浅层特征融合的视频目标分割算法。设计了高效高阶注意力模型与融合分割模块。前者在几乎没有增加计算负担的同时显著提高了分割精度;后者加入粗糙掩膜信息,引导深度特征与浅层骨干特征融合,兼顾深层与浅层信息,能够使得特征更加鲁棒,提高了分割效果。本文算法在DAVIS 2016、DAVIS 2017 以及YouTube-VOS 数据集上均取得优异的实验结果,充分验证了其优越性。但本文算法也还存在着一些不足,对于视频中的时序信息没有充分利用,性能还存在较大的提升空间。未来工作应该在保证分割速度不变的前提下有效地提高精度这一方向上进行探索。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
小雪花·成长指南(2022年1期)2022-04-09
四川大学学报(自然科学版)(2021年6期)2021-12-27
电子技术与软件工程(2021年5期)2021-06-16
唐山师范学院学报(2018年6期)2018-12-25
电子技术与软件工程(2018年5期)2018-04-09
制造技术与机床(2017年10期)2017-11-28
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
文苑(2015年9期)2015-09-10
