
CEEMDAN-ARIMA-GARCH模型及其在国际原油价格预测中的应用
2022-12-16 03:47王星惠杨梦梦
西安石油大学学报(社会科学版) 2022年6期
赵 兴 王星惠 杨梦梦
(安徽大学 经济学院,安徽 合肥 230601)
0 引言
随着经济全球化进程不断加速,国际原油期货市场的风险逐步加大,一些极端的情况时有发生。近年来,国际原油价格震荡频繁,新冠疫情暴发导致国际原油价格暴跌为负数。国家经济发展需要原油作为支撑,我国经济处于上升期,能够准确把握国际原油价格波动对经济稳定发展有重要意义。
1 文献综述
许多学者对原油价格的预测研究通常使用ARIMA模型与GARCH模型等计量经济学模型。如丁静之,闵骐等[1]156-159使用ARIMA模型直接对原油价格预测;魏蓉蓉、叶圣伟[2]68-69用ARIMA模型对原油价格的波动进行了分析;姚小剑和吴文洁[3]1-4使用GARCH族模型分析了原油价格波动特征。近年来,LSTM(长短期记忆网络)、SVR(支持向量回归)和KNN(最邻近规则分类)等机器学习的方法也都被广泛地运用在原油价格的预测上,如潘少伟、李辉等[4]180-185使用LSTM模型对原油价格进行了预测;慕晓茜、何佳等[5]4585-4589使用SVR模型对原油期货价格进行了短期预测;楚新元、卢爱珍等[6]15-22等使用KNN模型对原油价格进行了研究。然而,各种模型都有一定的局限性,直接对原始序列应用某种单一的预测模型时,所得到的预测结果都会存在改良空间。因此,近些年来越来越多的学者将组合模型的预测方法应用到该领域。如许南、廖施煜等[7]234-236使用混合型PSO-BP模型对原油期货价格进行了预测;曹新悦、贺春林等[8]418-425使用X12-ARIMA和LSTM组合模型对城市蔬菜价格波动规律进行了研究。然而,组合模型虽然较好地将各模型的优缺点进行了中和,但直接将模型应用于原始序列的分析方法仍然不能完全提取原始序列中的特征,而经验模态分解方法则可以在一定程度上解决这个问题。如杨云飞、鲍玉昆等[9]1884-1889使用EMD-SVMs的组合模型对原油价格进行了预测;姚洪刚和沐年国[10]239-244使用EMD-LSTM模型对金融时间序列进行了分析;Wu Y X,Wu Q B[11]114-124等使用EEMD-LSTM的组合模型对原油价格进行了预测;李政毓[12]1-67使用EEMD-ARIMA-LSTM组合模型对原油价格进行了预测;崔金鑫和邹辉文[13]28-39使用CEEMDAN-PSO-ELM模型对原油期货价格进行了预测;邸浩、赵学军等[14]72-76将EEMD模型和LSTM-Adaboost模型结合对商品价格进行了预测。经验模态分解方法是先将原始序列进行分解后再进行预测,并将预测结果再进行加和重构,有效提高了模型预测的效率,也是近年来预测研究的热点之一。
经验模态分解(EMD)模型由Huang,Shen等[15]903-995创造性地提出,可以将原始信号分解为不同频率的若干个模态分量(IMF)和残差分量(即趋势项)。EMD模型的特点在于可以完全按照自身的特征对原始序列进行分解,具有自适应性。然而,EMD模型却有着容易出现模态混淆的缺点。Wu,Huang[16]1-41提出了集合经验模态分解(EEMD)模型,有效解决了模态混淆的问题。通过向原始序列添加噪声来避免模态混淆的发生,但因为存在噪声残余导致重构误差的问题。在预测过程中,模态分解的重构误差会影响最终的预测结果。María,Marcelo等[17]4144-4147提出的适应白噪声的完全集合经验模态分解(CEEMDAN)模型则可以在模态分量不含残余噪声的同时避免模态混淆的发生,有效地解决了上述的两个问题。因此,CEEMDAN模型在重构预测的过程中显现出一定优势。
本文基于原油价格预测,期间引入了CEEMDAN模型,使用CEEMDAN模型将原始序列分解为不同频率的模态分量和残差分量,再用ARIMA模型分别对各个分量和趋势项进行拟合预测并在最后加和重构。由于分解所得的高频分量波动非常频繁,ARIMA模型并不能很好地捕捉其特征,因而可以使用GARCH模型对高频分量的拟合残差平方序列进行进一步拟合,即用GARCH模型对残差的预测值来对高频分量的ARIMA预测值进行修正。因此,建立了CEEMDAN-ARIMA-GARCH模型。在CEEMDAN-ARIMA模型基础之上,提出了对高频分量有必要检验其残差序列是否具有ARCH效应的原则,使用ARIMA-GARCH模型将分量中所含的信息尽可能提取出来,实现更好的预测效果。
2 模型介绍
2.1 模型设定
2.1.1 EMD分解原理
EMD模型又称经验模态分解,是由Huang,Shen等[15]903-905提出的一种根据时间序列的局部时变特征,将序列分解为若干个模态分量(IMF)和残差分量(即趋势项)的模型。所获得的IMF需要满足以下2个基本原则:任意IMF的极值点与零点的个数之差小于等于1;任意IMF的局部极大值和局部极小值的包络线之和均值为0。
EMD分解步骤如下:
第一步,三次样条插值法对原始序列x(t)中所有的局部极大值和极小值进行拟合,形成上下包络线,记做u(t)与i(t);
第二步,计算上下包络线u(t)与i(t)的均值o(t),见(1)式:
(1)
第三步,将原序列x(t)与o(t)相减得到新序列p(t),见(2)式:
p(t)=x(t)-o(t)
(2)
第四步,若p(t)满足IMF的2个基本条件,则将p(t)作为EMD分解的第一个模态分量IMF1;若p(t)不满足IMF的2个基本条件,则将p(t)定义为原序列,重复第一至第三步直到其满足IMF的基本条件,得到第一个模态分量IMF1;
第五步,将原始序列x(t)减去IMF1,得到r1(t),见(3)式:
r1(t)=x(t)-IMF1
(3)
第六步,将r1(t)作为下一个要分解的原始序列,重复第一至第五步,直至得到残余分量rn(t)小于预先设定值,或为单调函数、常数时,分解完毕。在分解完成之后,原始序列x(t)见(4)式:
(4)
然而EMD模型在实际的应用过程中会有模态混淆的情况发生。下文中的EEMD模型则可以解决模态混淆的问题。
2.1.2 EEMD模型分解原理
EEMD模型又称集合经验模态分解,由Wu和Huang[16]1-41提出,利用多重白噪声均值为0的特点,通过加入白噪声的原始序列进行EMD分解,再将得到的模态分量取均值以达到控制噪声对分解结果的影响。
EEMD分解步骤如下:
第一步,预先确定添加白噪声次数Nε和白噪声振幅系数ε;
第二步,在原始序列x(t)中加入白噪声序列,得到Nε个染噪序列见(5)式:
xj(t)=x(t)+εnj(t)
(5)
其中nj(t)为第j次添加的白噪声序列,xj(t)表示第j个染噪序列;
第三步,对得到的染噪序列进行EMD分解,得到Nε组模态分量IMFij,和Nε个残余分量rj(t);
第四步,对第三步中获得的Nε组模态分量中的第i个分量和Nε个残余分量分别进行平均,见(6)、(7)式:
(6)
(7)
第五步,最终分解结果x(t)见(8)式:
(8)
在EEMD模型中,虽然解决了EMD模型的模态混淆的问题,但其分解所得到的各个模态分量却会存在残留的噪声,进而带来重构误差的问题,会在一定程度上影响最终的分析结果。
2.1.3 CEEMDAN模型
CEEMDAN模型又称具有自适应白噪声的完全集合经验模态分解,由María,Marcelo等[17]4144-4147提出,是EEMD模型的改进版算法,该模型在解决模态混淆问题的同时还解决了噪声残余的问题。分解步骤如下。
第一步,预先确定添加白噪声次数Nε和第i次添加的白噪声振幅系数εi;
第二步,在原始序列x(t)中加入白噪声序列,得到Nε个染噪序列,见(9)式:
xj(t)=x(t)+ε1nj(t)
(9)
其中nj(t)为向原始序列中添加的第j个白噪声序列,xj(t)表示第j个染噪序列;
第三步,对得到的Nε个染噪序列进行EMD分解,将得到的Nε个第1个IMF分量加总平均即为CEEMDAN分解的第一个分量cIMF1,见(10)式:
(10)
第四步,进一步得到残余分量r1(t)=x(t)-cIMF1,将r1(t)当作x(t)重复第二至第三步直至残余分量rn(t)不能进行EMD分解而得到n个模态分量cIMFi;
第五步,最终分解结果x(t)见(11)式
(11)
2.1.4 ARIMA模型
ARIMA模型全称为回归移动平均模型[18]94,是一种在时间序列预测中较为常见的模型。ARIMA模型有三种基本类型:自回归(AR)模型、移动平均模型(MA)、自回归移动平均模型(ARMA),见(12)式:
xt=φ0+φ1xt-1+φ2xt-2+…+φpxt-p+at+θ1at-1+θ2at-2+…+θqat-q
(12)
其中at为残差序列,p表示自回归项数,q表示移动平均项数,φ0,φ1,φ2,…,φp表示需要估计的自回归系数,θ0,θ1,θ2,…,θp表示需要估计的移动平均系数。当q=0或p=0时,其可转化为AR模型或MA模型。由于ARMA模型只能处理过程平稳的时间序列,因此,如果要分析非平稳的时间序列,则需要对原始序列进行d次差分,将其转化为平稳序列,然后再用ARMA模型进行分析。
2.1.5 GARCH模型
GARCH模型全称为广义自回归条件异方差模型,由Bollerslev[19]307-327在ARCH模型的基础上提出。在ARCH的模型的基础上,将滞后阶段引入条件方差,得到广义ARCH模型,见(13)式。
(13)
2.1.6 CEEMDAN-ARIMA-GARCH模型
ARIMA-GARCH模型即在用ARIMA模型对原始序列进行拟合建模后,将得到的残差序列进行ARCH效应检验,若存在ARCH效应,则再用GARCH模型对其进行拟合,尽可能提取出残差序列中的残余信息,将其预测结果用于对ARIMA的预测结果进行修正,见(14)式。
(14)
文中涉及的记号与术语可参见[1,10-11]。若X是拓扑空间,F⊆X,F在X中的闭包记为clF,在涉及多个空间时,为区分起见也记作clXF。空间X的全体开集与全体闭集分别记为Ο(x)与Γ(x)。
进一步,根据模态分量的实际情况将ARIMA-GARCH模型或ARIMA模型应用于CEEMDAN模型分解所得的高频分量与低频分量进行预测,并将预测结果加和得到最终的预测值,CEEMDAN-ARIMA-GARCH模型的预测流程见图1。
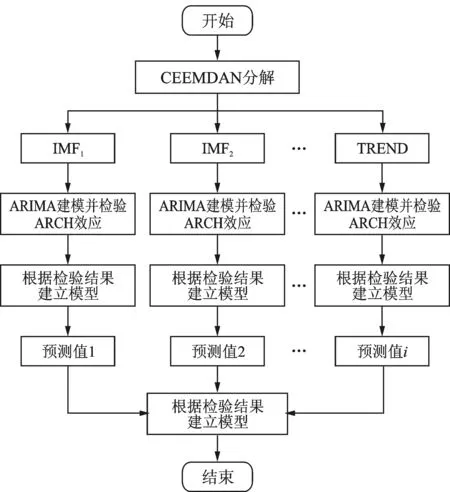
图1 CEEMDAN-ARIMA-GARCH模型的预测流程
3 实证分析
3.1 数据描述
为更加准确地分析国际原油价格波动的特征并进行预测,本文选择使用WTI原油期货价格作为分析对象。WTI原油期货在保持其价格高度透明的同时还有着优良的流动性,是世界原油市场上的三大基准价格之一。所有与美国有贸易往来的原油产品在计价时都以WTI的价格作为基准。
本文选取2020年8月26日至2021年8月25日的WTI原油收盘价作为原始数据。由上述模型介绍可知,CEEMDAN模型对原始序列的数据并没有特殊的要求,而ARIMA模型则要求数据具有平稳性。然而,仅仅是原始数据本身具有平稳性是不够的,为了使CEEMDAN模型分解所得的IMF分量可以拟合ARIMA模型,还要求原始数据通过CEEMDAN分解所得的IMF分量也具有平稳性。若存在部分分量不符合平稳性要求,则进行相应的平稳性转换。因此,本文使用ADF检验对WTI原油收盘价及其IMF分量进行平稳性检验,各序列的平稳性检验结果见表1。

表1 各序列的平稳性检验结果
由表1检验结果可知,选用的WTI原油收盘价的数据从特征上是适合本文模型的。在预测方法上,选取滚动预测的方法,文中使用的原始数据共有262个样本单位,选择将前232个样本单位(2020年8月26日至2021年7月13日)作为初始样本。初始样本中数据在原始数据中的占比超过了85%,可以为模型提供足够的先验信息,很好地拟合原始序列的特征。在此基础上,将用初始样本模拟的模型向前预测一步,得到2021年7月13日的预测值,之后再将2021年7月13日的真实值加入初始样本重新拟合模型,重复以上步骤直至得到了2021年8月25日的预测值。这样就保证了在选取的原始数据范围内,获得的每一个预测值都充分利用了原始数据中的信息,确保了预测结果的准确性。
3.2 模型拟合
将WTI原油收盘价数据进行CEEMDAN分解,得到4个IMF分量以及一个趋势项,原始序列CEEMDAN分解结果见图2。对分解的4个IMF分量以及趋势项在2020年8月26日至2021年7月13日期间的数据拟合ARIMA模型,IMF分量与趋势项的ARIMA拟合参数见表2。
随着分量序列的频率降低,ARIMA模型拟合的效果也越来越好,IMF分量与趋势项的ARIMA拟合结果见图3。因此进一步计算各IMF分量及趋势项与原始序列的相关系数,将序列区分为高频与低频。根据计算,IMF1、IMF2、IMF3、IMF4、趋势项与原始序列之间的相关系数分别为0.0670、-0.0679、-0.0064、0.4426、0.9751。因此IMF1、IMF2、IMF3被判定为高频分量,有必要检验其中的ARCH效应,尝试进一步从中提取信息。
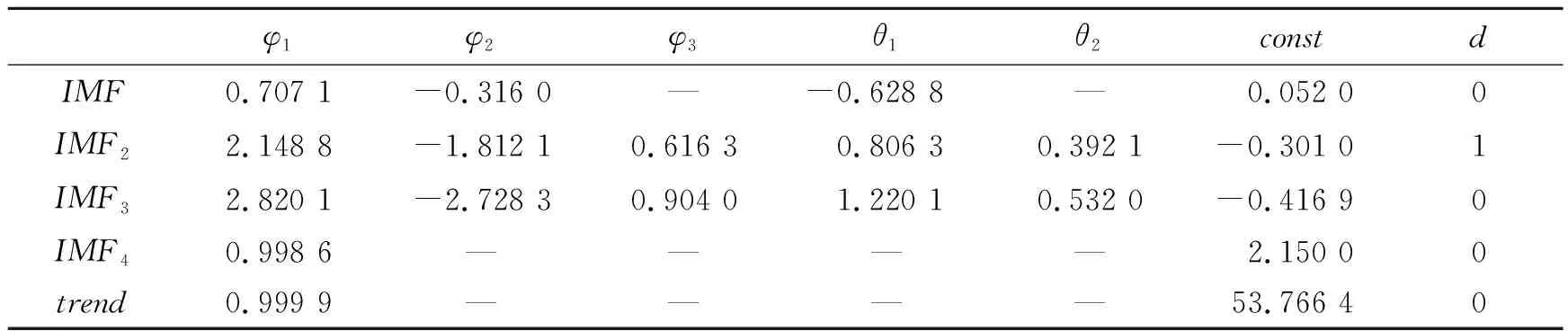
表2 IMF分量与趋势项的ARIMA拟合参数
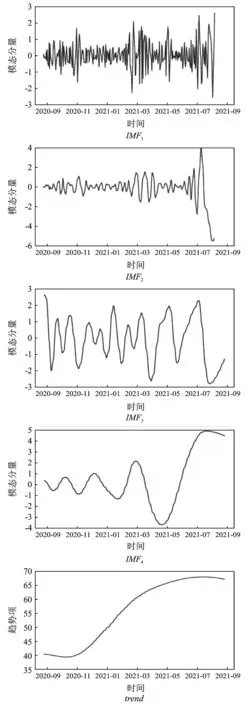
图2 原始序列CEEMDAN分解结果
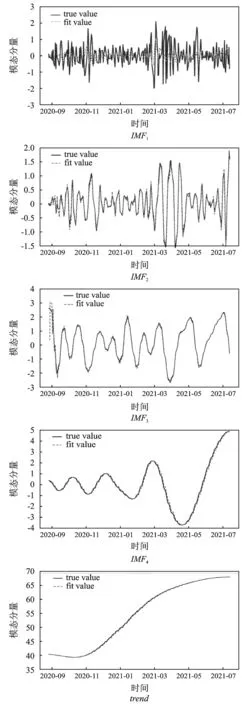
图3 IMF分量与趋势项的ARIMA拟合结果
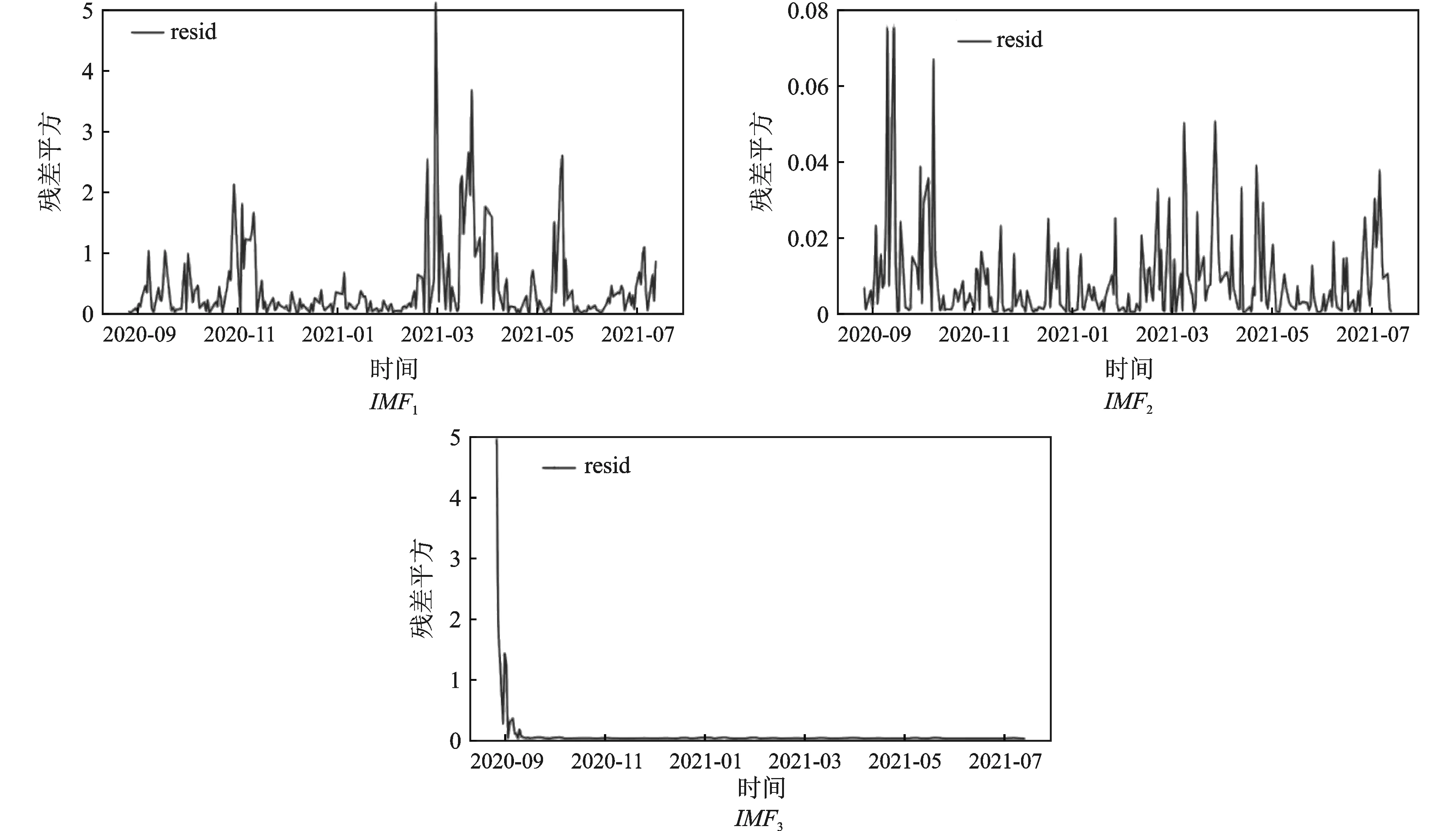
图4 高频IMF的拟合残差平方序列分布图
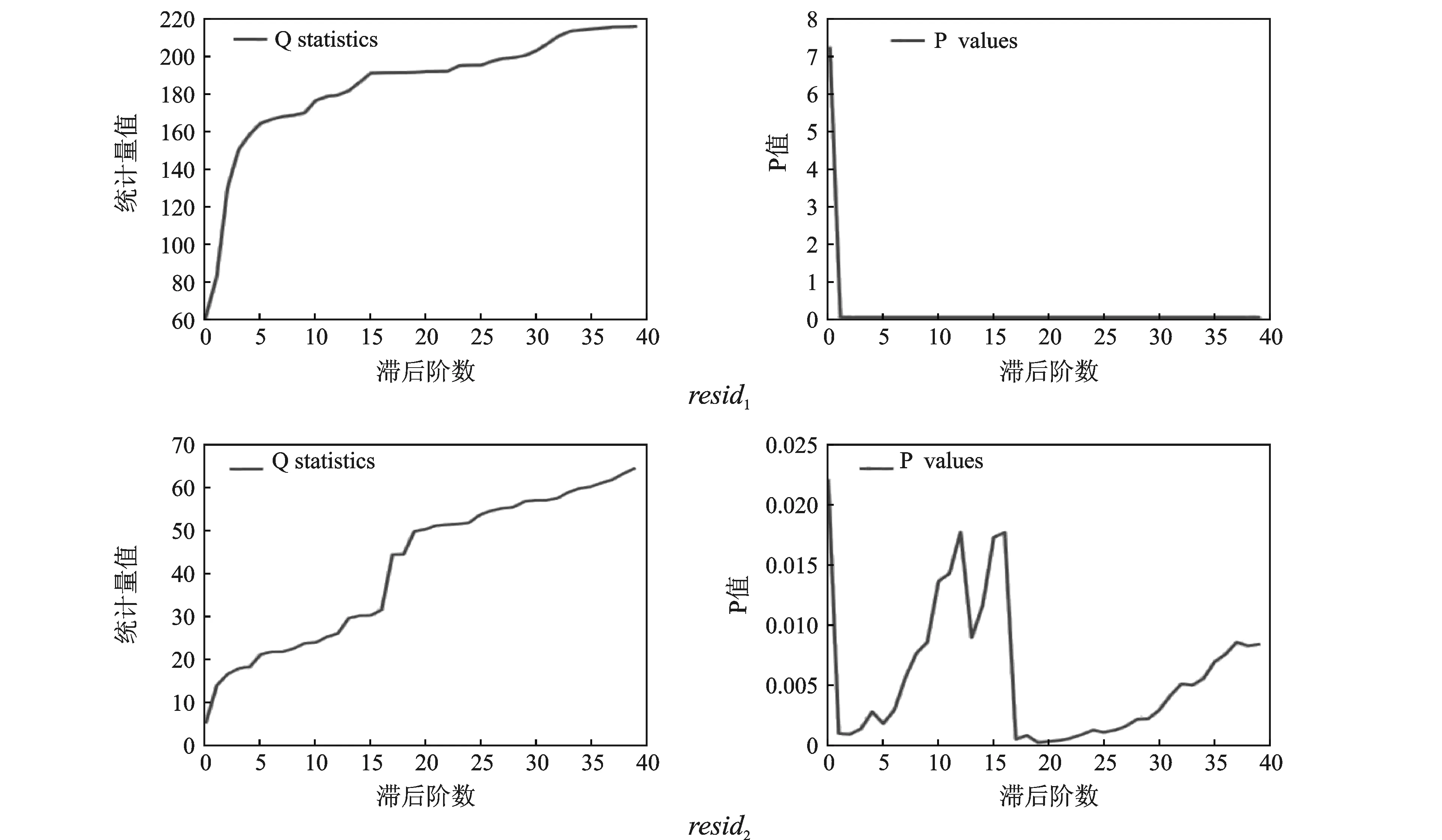
图5 IMF1、IMF2的残差平方序列Ljung-Box检验结果
IMF1、IMF2的残差平方序列Ljung-Box检验结果见图5。从图5可以看出,IMF1、IMF2的残差平方序列检验得到的Q统计量的p值均小于0.05,即以上2个残差平方序列都显著地表现出了ARCH效应,可以进一步进行GARCH模型的拟合,从中提取有效信息。在GARCH模型的拟合中,本文对IMF1、IMF2拟合GARCH(1,1)模型,分别得到(15)式、(16)式:
(15)
(16)
3.3 价格预测
首先对2020年8月26日至2021年7月13日期间的数据用表2中的ARIMA模型对各分量与趋势项进行动态预测,分别得到5个预测样本,再用(14)式对IMF1、IMF2的预测结果进行修正,修正结果见表3。
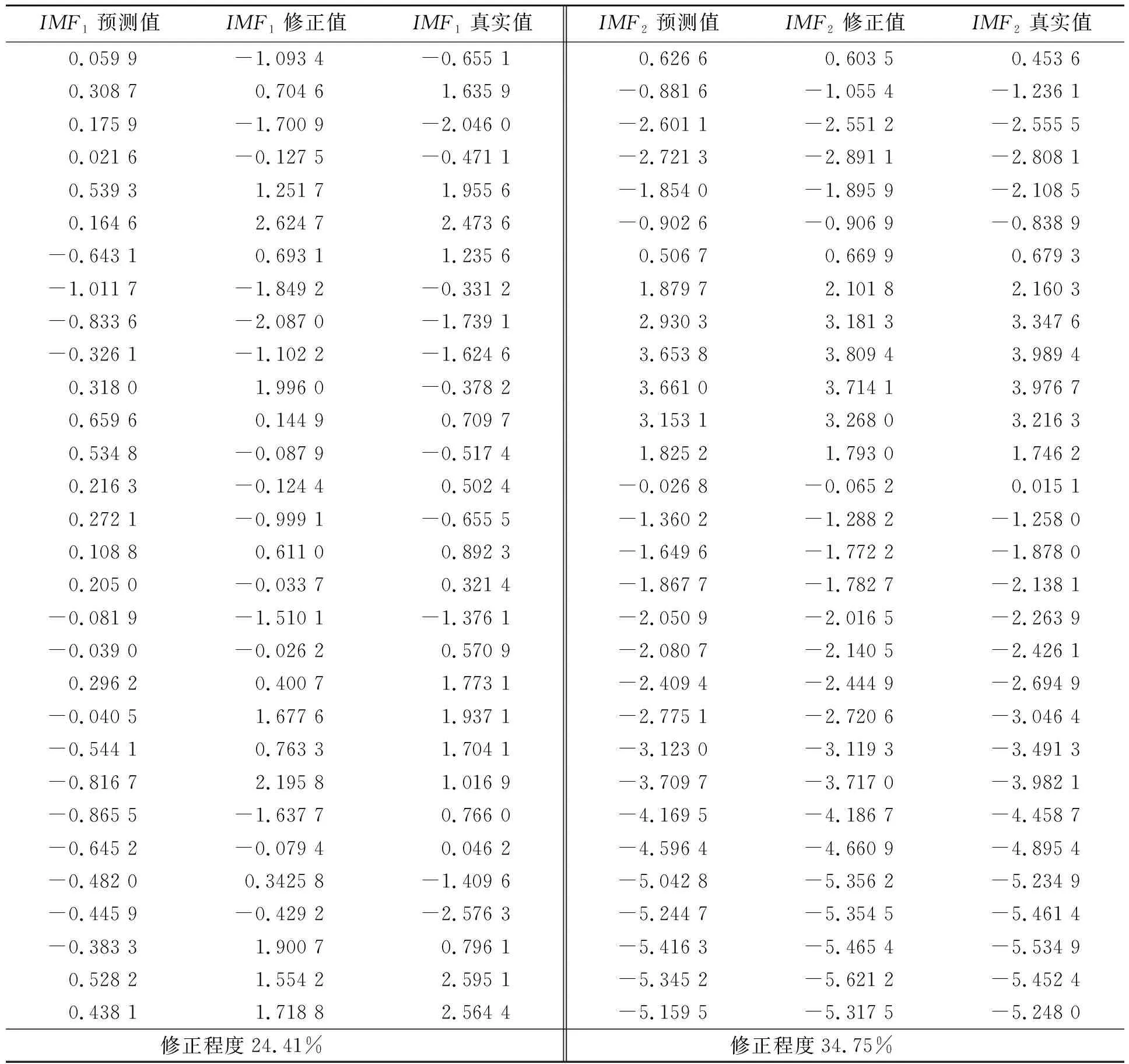
表3 IMF1、IMF2的预测值、修正值、真实值对比
根据表3可以看到,拟合的GARCH(1,1)模型有效修正了原预测值,使IMF1、IMF2的预测值更为准确,从而进一步提高了整体预测的准确度。将得到的IMF1、IMF2的修正预测值与IMF3、IMF4、trend的预测值进行加和,得到最终的预测结果,4种模型预测结果对比见图6。
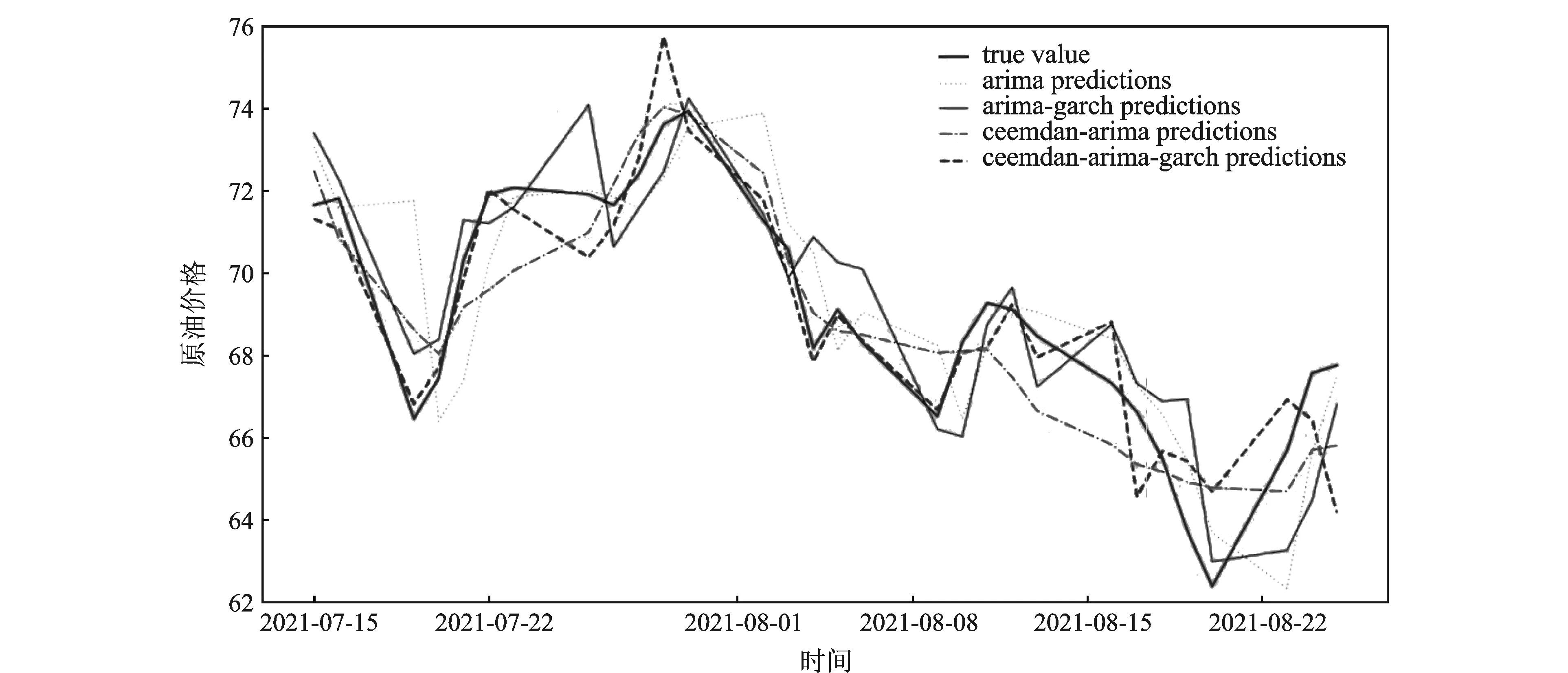
图6 4种模型预测结果对比
从图6可以看出,CEEMDAN-ARIMA-GARCH模型的预测值比其他模型的预测值更为精准。模型的预测数据在整体更加贴近原始数据的同时,对原始数据的趋势与波动的反应也更为准确,相比CEEMDAN-ARIMA-GARCH模型,其他的模型则表现出了滞后性,也不能准确捕捉原始数据趋势的缺陷。为了有效评估模型预测的效果,本文选用均方根误差(RMSE)和对称平均绝对百分比误差(SMAPE)来对模型的预测效果进行评估。
RMSE与SMAPE计算方法见(17)、(18)式:
(17)
(18)
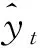
进一步使用RMSE与SMAPE2个指标来评价以上的4个预测模型的预测效果。指标值越小则表明预测误差越小,模型的预测效果越好。
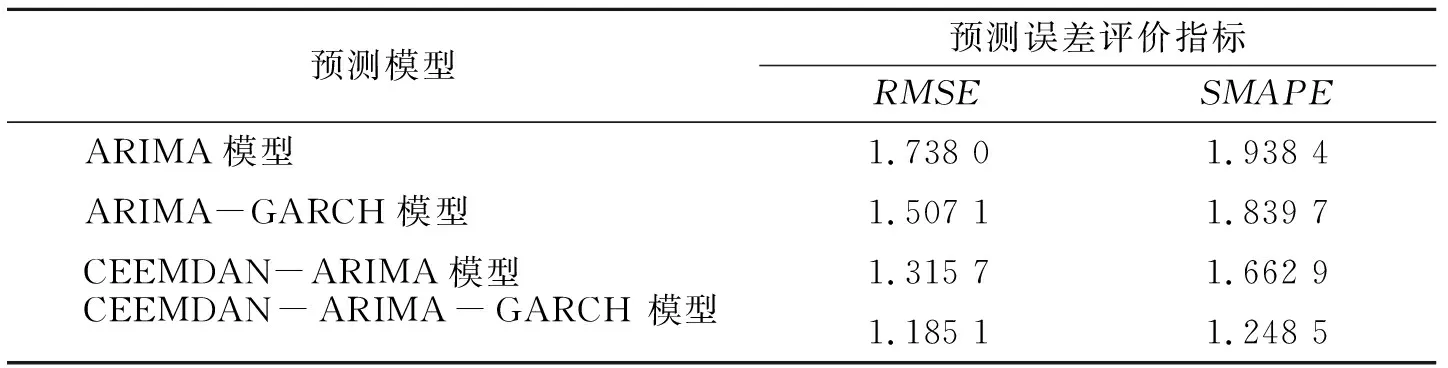
表4 4种模型预测效果评价
从表4可以看出,由于GARCH模型可以将残差序列中的有效信息进一步提取出来,GARCH模型与ARIMA模型和CEEMDAN-ARIMA模型的结合都在一定程度上优于ARIMA模型和CEEMDAN-ARIMA模型,实现了更高的预测精度。另一方面,CEEMDAN-ARIMA模型的预测效果也显著优于ARIMA模型,即后者可以通过分解重构的方法使ARIMA模型可以更加精细地捕捉原始序列中的信息,从而提高了预测的精度。然而,ARIMA模型并不能很好地拟合CEEMDAN模型分解所得高频分量,这时则会导致对高频分量的预测效率低下,从而在重构预测值时影响最终的结果。因此,在使用CEEMDAN-ARIMA-GARCH模型时,可以补齐ARIMA模型难以拟合高频序列的缺陷,使有效信息被更为充分地利用。理论和实证的分析也显示,CEEMDAN-ARIMA-GARCH模型在预测原油价格的研究中具有明显的优势。
4 结 语
本文提出了一种新的预测模型——CEEMDAN-ARIMA-GARCH模型。该模型通过选用无模态混淆和重构误差的CEEMDAN模型,提高了对分量进行拟合预测后重构预测值的精度。另一方面,对各个分量初步拟合ARIMA模型并对拟合的残差序列进行分析,发现高频分量在拟合ARIMA模型后的残差平方序列中存在ARCH效应的问题。即以CEEMDAN-ARIMA模型为基础,提出了通过对高频序列的残差平方序列拟合GARCH模型,以修正原有的ARIMA模型预测值,达到更高的预测精度的预测方法。
实证中,将2020年8月26日至2021年7月13日期间的国际原油价格作为原始数据并分为训练集与测试集,预测测试集最后30天的国际原油价格。实证结果表明,在对比预测模型中,CEEMDAN-ARIMA-GARCH模型的预测精度最高。在面对原油价格波动时的表现也显著优于其他的模型。如在2021年7月中下旬原油价格的锐降与反弹以及2021年8月上旬的波动中,CEEMDAN-ARIMA-GARCH模型的预测值都与真实值非常接近,没有表现出任何的滞后性。可见,在国际原油价格的预测中,CEEMDAN-ARIMA-GARCH模型可以更及时、更准确地对价格的波动做出反应,这对在国际原油市场中规避风险以及寻求获利机会都有着相当重要的现实意义。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
中国化肥信息(2022年2期)2022-04-19
今日农业(2021年19期)2022-01-12
环境保护与循环经济(2021年7期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
国外核新闻(2020年8期)2020-03-14
自动化学报(2019年6期)2019-07-23
能源(2016年2期)2016-12-01
中国惯性技术学报(2015年1期)2015-12-19
中国石油企业(2015年10期)2015-09-24
