
一种体现发展趋势的自-互激励型多阶段信息集结方法
2022-12-15 08:07梁媛媛易平涛李伟伟
运筹与管理 2022年11期
刘 军, 梁媛媛, 易平涛, 李伟伟
(东北大学 工商管理学院,辽宁 沈阳 110169)
0 引言
综合评价是指通过建立一套指标体系,利用一定的方法或模型,对被评价对象做出定量化的总体判断,是决策分析领域的重要组成部分[1~5]。传统综合评价一般聚焦于被评价对象的静态特征,考察其在某个时间点的表现。但在现实管理决策中,评价环境复杂多变,通常需要考虑被评价对象在不同阶段的总体表现。已有学者在评价过程中融入时间因素,提出动态综合评价,目前已取得丰硕成果[6~8]。
针对以往研究中决策意图不突出这一局限性,众多学者基于动态综合评价中的多阶段信息集结问题,提出了带激励特征的集结方法,即在集结过程中融入奖惩因素。文献[9]通过引入正负两条激励线,实现对被评价对象的奖惩。为细化发展状况,文献[10]提出分层激励控制线模型,通过分层实现逐步激励,从而促使个体或组织的突破式发展。在分层激励的基础上,文献[11]提出了三种改进的分层激励集结方法,以更深入地分析隐含信息。文献[12]考虑“进步”或“退步”的变动趋势,提出一种基于增益水平激励的动态评价方法。但以往研究大多仅考虑“状态激励”,为突破这一局限,文献[13]将线性激励控制线拓展为泛激励控制线,在方法中融入“趋势激励”因素。文献[14]在“显性激励”中引入“隐性激励”内容,构建了基于双重激励模型的动态评价方法。为实现逐层激励,拉大整体差距,文献[15]以不同时段的增益为基点,提出一种基于时序增益激励的集结方法。
上述激励方法虽有不同特点,但仍存在以下3点不足:(1)设置激励控制线时,所有对象给定相同的正、负激励线,忽略了个体的差异,使低起点对象长期处于负激励状态,打消了发展积极性,高起点对象长期处于正激励状态,缺乏危机意识。(2)现有的基于激励控制线或发展增益的评价方法,均依据所有对象在全部时刻的变化幅度确定斜率或增益水平,致使每加入新对象或新时期数据,整体状态需重新计算,无法实现动态化。(3)考虑变化幅度时,现有方法默认被评价对象增长相同幅度的难度相同,然而在现实评价问题中,由于个体所处的发展阶段不同,其增长难度也不同。
针对上述3点不足,本文沿用激励控制线思想,将离散的多时点评价值集结问题拓展为时段区域连续的评价值集结问题[9],拟提出一种体现发展趋势的自-互激励型多阶段信息集结方法。具体而言,首先根据被评价对象过去的发展趋势引入预测线,对处于预测线上、下部分分别进行奖、惩,以此进行状态上的自激励;其次以静态评价值衡量发展难度,以增长速度衡量发展好坏,将其结合进行增长水平上的互激励;最后在集结评价信息时兼顾自、互激励结果,根据最终集结值比较被评价对象之间的优劣。
1 基本问题描述
就某一动态评价问题,设有n个被评价对象,m个指标,按时间顺序t1,t2,…,tT收集原始数据。yi(tk)为第i(i=1,2,…,n)个对象在tk(k=1,2,…,T)时刻的评价值,则时序信息矩阵为:
问题:如何在尊重个体发展差异的情况下对被评价对象进行科学的激励评价?本文从以下几个方面进行探索。
2 “自激励”动态评价模型
现有的“状态激励”依据所有对象的整体发展,设置相同的激励控制线,但这种统一的标准不能体现个体差异。“自激励”根据被评价对象过去的发展趋势确定预测点,将预测点的连线称为预测线(作用相当于传统的激励控制线[9~11]),决策者以预测线为基准划分被评价对象发展状态的好坏,对优于预测线部分进行适当奖励,反之进行相应惩罚。
2.1 预测点的确定
本文按各对象过去的发展趋势在不同时刻设置不同预测点,给出以下2种确定预测点的方法。
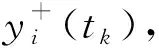
(1)
(2)
式中,vi(tj)为对象si在[tj-1,tj]内评价值的线性增长速率(初始时刻vi(t1)=0)。
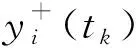
方法2根据上一时段的增益定义下一时刻的预测点,则被评价对象si在tk时刻的预测点为
(3)
式中,ρ为调整因子,通常设ρ∈(0,2],ρ=1表示不调整预测点。yi(tk-1)>yi(tk-2)时,ρ>1表示决策者希望下一时刻设置较高的预测点;ρ<1表示设置较低的预测点。yi(tk-1)
2.2 激励评价值的确定
自-互激励型多阶段信息集结示意图见图1。对分割后的某一单位阶段而言,一般可认为被评价对象的状态是均匀变动的,两点之间的连线表示发展轨迹,tkyi(tk)tk+1yi(tk+1)与横轴包围的面积反映各对象在[tk,tk+1]内的总体状况[9]。
定义1被评价对象在[tk,tk+1]内的动态综合评价值为
(4)
由预测点的设置可知,前期发展的好坏会对后期的预测点产生累积影响。如果被评价对象前期发展较好,则后期会出现较大的预测点。在这种情况下,若发展仍超过预测,应受较大的奖励,若发展未超过预测,应受较小的惩罚。相反,如果前期发展较差,后期出现了较小的预测点。这种情况下,若发展仍低于预测,应受更大的惩罚,若发展超过预测,应受较小的奖励。
定义2被评价对象在[tk,tk+1]内带“自激励”的动态综合评价值为

(5)

评价[tk,tk+1]时段的正负激励量时,若前k-1个时段的增长速率(方法1)或前一时段增长速率(方法2)不小于0,则对正激励部分实行一级正激励,负激励部分实行二级负激励。增长速率小于0时,对正激励部分实行二级正激励,负激励部分实行一级负激励。
3 “互激励”动态评价模型
“自激励”根据各对象的发展趋势得到正负激励量,尊重个体差异。但存在以下2点不足:(1)各对象不仅需要与过去的发展趋势比,了解自身的发展状况,还需与其他对象比,看到发展的差距。(2)预测线的设置受过去发展趋势的影响,可能会出现这种情况,即被评价对象过去的发展趋势不好,导致预测线较低,自激励表现为正激励,但在这段时间内,被评价对象的评价值是下降的,因此仅通过与预测线的差距来确定各对象的发展水平是不全面的。为使激励方式更合理,有必要对变化幅度进行激励。然而现有的“趋势激励”仅依据增长率来衡量发展的好坏程度[13,14],未考虑不同对象增长难度的差异。
基于以上思考,本文在“自激励”基础上加入“互激励”。一般来说,随着评价值的增长,取得相同增长幅度需付出的努力也在增长。同时对个体的激励,不仅受自身增长率的影响,还受其余对象的综合影响。因此“互激励”以静态评价值作为衡量发展难度的依据,将“趋势激励”从仅考虑增长率拓展为考虑增长率和评价值的联合作用。
定义3设ρi(tk)为互激励系数,则被评价对象si在[tk,tk+1]内带“互激励”的动态综合评价值为
(6)
(7)
(8)
(9)
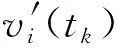
4 “自-互激励”动态评价模型
“自激励”实质上是状态激励,是对发展现状的奖惩,“互激励”为趋势激励,是对相邻时期相对增长水平(包括发展的方向和大小)的奖惩。集结多阶段信息时,需要同时考虑被评价对象在某段时间内发展的状态和在相邻时期间发展的方向和大小。因此融合“自激励”、“互激励”模型,构成具有双重激励的“自-互激励”模型。
“自激励”包含4种情况,“±”表示正负激励,“→”表示无激励,“+”表示全正激励,“-”表示全负激励。“互激励”包含3种情况,“↑”表示向上发展,“→”表示发展平稳,“↓”表示向下发展。符号之间共有12种组合,见表1和图1。
定义4被评价对象si在[tk,tk+1]内带“自-互激励”的动态综合评价值为

(10)

表1 自-互激励类型表

注:图中s,s+,s-分别表示总面积、正激励面积及负激励面积。图1 动态评价信息自-互激励类型示意图
式中有四个待定参数,本文通过以下四个规则进行确定[9~14]。
规则1激励适度规则。要求“自激励”激励系数和为1,即有
μ++μ-=1
(11)
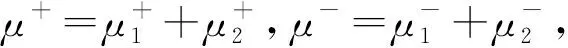
规则2激励守恒规则。要求优激励总量等于劣激励总量,即有

(12)
规则3伸缩临界规则。要求不对保持不变的阶段进行互激励,即有
(13)
规则4两级比较规则。给定系数γ(γ>1),使得
(14)
式中,参数γ为决策者对所有对象全时段内最优与最劣增长水平在互激励上的比值偏好。
综合各时刻,容易得到第i个被评价对象在[t1,tT]内带激励特征的总动态综合评价值为
(15)
式中,τk为时间因子,为体现“厚今薄古”思想,通常取{τk}为递增型序列,如令τk=ek/2T,若无特殊要求可以不考虑时间偏好,即令τk=1。
5 应用实例
为验证本方法的有效性,并与其他方法对比,这里引用文献[10]的算例进行分析。10名员工近6年的绩效成绩如表2所示,分别运用自-互激励模型、双激励控制线模型对其进行计算,并将结果与文献[10]的分层激励和文献[11]的比例分层、一维聚类分层对比。
具体计算过程如下:

表2 绩效成绩表
(1)求各员工在不同年份的预测点(使用方法1),连接为预测线,计算其与实际评价值连线的交点(见表3)。根据类型及交点求不同时段各对象的正、负激励面积(见表4)。

表3 各阶段自-互激励模型类型及自激励模型动态交点演化情况
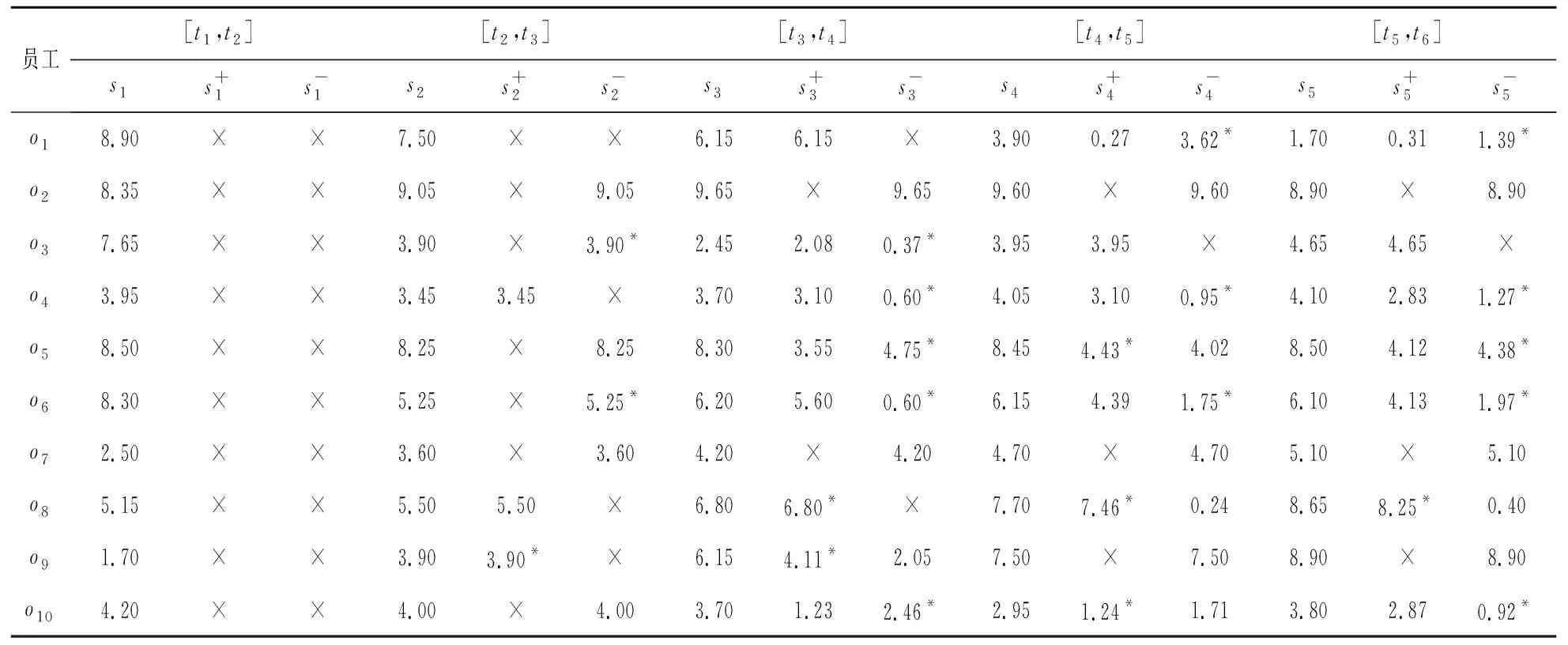
表4 自激励模型各阶段正、负激励信息
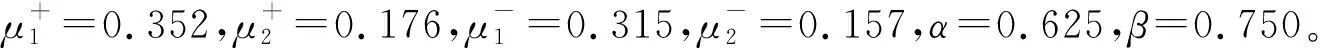
(3)加总各对象的总面积及正负激励面积,并集结T个时点的信息(取时间因子为1),从而求得自激励、互激励以及自-互激励评价结果,根据值的大小排序,结果见表5。

表5 综合评价结果及排序
(4)为验证自-互激励模型结果的有效性,本文计算了双激励控制线模型的结果,并与已有文献中三种分层激励模型的评价结果对比,详见表6和表7。

表6 双激励控制线模型各阶段正、负激励信息

表7 不同方法评价结果对比
由结果对比可知,自-互激励评价方法与其他四种方法得到的结果有一定变动。
自激励模型是对双激励控制线模型的改进,两者本质上都是状态激励。对比分析员工2与员工8,双激励模型中,员工8位于第5位,员工2位于第1位,而在自激励模型中,员工8升到第1位,员工2降到第3位。原因在于员工8的个体发展趋势比员工2好。由表4可知,自激励模型中,员工8的正激励面积高于员工2,且大部分为一级正激励,员工2在全过程皆受负激励。由表6可知,双激励控制线模型中,员工2在前4个时期受正激励,员工8在前2个时期受负激励,因此员工2的最终评价结果接近员工8的2倍。本文的双激励控制线如图2所示,可以看出同样的绩效成绩在初期比末期更有价值,高绩效得分初期受到的正激励比末期高很多,相反,低绩效得分受到的负激励初期比末期大很多。这样的设定对一开始发展较好的对象有利,不利于低起点对象。因此自激励模型以预测线替代双激励线,对不同起点的被评价对象设置不同的预测线,避免了双激励线的弊端。

图2 双激励控制线
无激励时员工1和9的综合评价值相同,员工1的绩效成绩不断下降,员工9不断上升,而双激励控制线中,员工1以较大幅度超过员工9,不符合客观现实。员工9在自激励中超过了员工1,评价结果更客观公正,体现了方法的先进性。自激励模型仅关注发展状态,但发展方向是上升或下降对最终结果同样重要。因此本文在“自激励”基础上,融入“互激励”。在互激励模型中,员工9以较大幅度超过员工1,体现了决策者奖励不断进步的员工,惩罚退步的员工。将互激励结果与同样考虑被评价对象发展方向的分层激励、比例分层和一维聚类分层进行对比,排序仅有略微差别,证明了方法的有效性。
自-互激励模型是将自激励模型与互激励模型融合,两者一静一动,在方法中兼顾了发展现状和增长水平,使结果更加全面、合理。
6 结语
由于被评价对象的发展状态、所处阶段、增长难度均不同,给予统一的激励控制线或激励临界值,无法充分尊重个体差异。基于此,本文提出自-互激励型多阶段信息集结方法,其特点在于:(1)根据各对象的发展趋势设置预测点,尊重个体差异,同时使用调整因子,以在评价中融入决策者的偏好。(2)基于往期数据计算下一时刻的预测点,加入新时期数据或新的对象时,无需对前期数据重新计算,体现了动态性。(3)衡量变化幅度时,考虑增长难度,对仅以增长率确定趋势激励量的方法进行了拓展。
本方法应用空间广泛,首先其适用于各对象更加关注自身发展趋势或各对象之间发展差距较大的情形。例如在评价经济发展时,我国东中西部经济形式呈阶梯递减趋势,发展不均衡。在这种情况下,使用本方法可尊重不同地区的发展差异,提高低起点对象的发展积极性,增强高起点对象的危机意识。其次,本方法充分利用时序数据,考虑被评价对象的动态水平,方法中预测点和激励系数的设置能够体现决策者的决策意图,因此适用那些需在评价中融入主体偏好,并对各对象进行公正评价和精确引导的情形,例如企业绩效考核、人才管理及选拔等问题。
本文根据单一数据(实数)对多时段信息进行集结,但是随着大数据、物联网、云计算等信息技术的迅猛发展,产生了大规模、多样性的数据。因此进一步的研究可以将单一数据扩展为多源数据(如实数、序数、模糊数、随机数、二元语义信息等),以在评价中融入更多信息。
猜你喜欢
河北地质(2021年3期)2021-11-05
湖南税务高等专科学校学报(2021年4期)2021-08-30
军事文摘(2020年18期)2020-10-27
资源导刊(信息化测绘)(2019年11期)2019-01-03
动漫星空(兴趣百科)(2018年4期)2018-10-26
意林(2018年3期)2018-03-02
中学生数理化·八年级物理人教版(2017年3期)2017-11-09
汽车电器(2017年8期)2017-09-07
厦门理工学院学报(2016年1期)2016-12-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
