
基于特征优选的航空发动机剩余寿命预测
2022-12-14 03:53黄培炜杜艺博
中国测试 2022年11期
李 鹏, 丁 瀛, 黄培炜, 杜艺博
(华东交通大学机电与车辆工程学院,江西 南昌 330013)
0 引 言
航空发动机剩余寿命(remaining useful life,RUL)预测是航空发动机PΗM(prediction and health management)的核心技术,是连接飞机系统机载状态监测、飞机设备故障诊断、地面运行规划和维修保障的重要纽带。
对于航空发动机PΗM系统中的设备退化建模和RUL预测,现有文献大多集中在单个特征信号在单个运行条件下的分析。但随着系统和设备结构的日趋复杂,再加上服役工况的恶劣多变,依赖单一类特征信号通常不足以准确描述设备的潜在退化机制,从而导致RUL预测结果的不准确。而另一方面,多个特征数据包含更为丰富的信息,采用多个特征监测数据用于发动机剩余寿命预测可以显著提高发动机健康监测的效果[1]。但用于航空发动机PΗM系统的特征也并非越多越好,过量特征监测数据的处理将会导致算法的计算复杂性增加,并且冗余特征数据的引入将导致分析模型过拟合,反而降低模型的预测能力[2]。
因此,若对特征数据特征进行挑选,只挑选出于设备退化机制较相关的特征监测数据,利用这些合适特征监测数据进行融合并进行建模分析,将会提高RUL预测的精确度和鲁棒性。
对于RUL预测中的特征数据的选择问题,国内外学者也进行了大量的研究,Wang[3]等采用分析传感器信噪比的方法对用于RUL预测的传感器特征数据进行选择,但只是考虑了单个特征信号噪声的特点,未考虑到特征数据变化趋势和不同类型特征数据间的相关性。Liu[4]等研究了集成数据融合方法以改进寿命预测的方法,并以模型拟合误差、失效阈值方差为最小目标函数来确定融合系数。
王金杰[5]等将互信息作为特征贡献度评价指标结合粒子群算法进行冗余特征剔除;Rao[6]等人采用梯度增强决策树作为特征贡献度评价方法,并利用人工蜂群算法进行特征优选。巫红霞[7]等以Pearson相关系数对特征进行评估,再利用人工蚁群算法对评价后的特征子集进行特征优选。但以上方法都未直接建立不同特征选择结果与发动机RUL预测效果的联系,只评价了单一次特征选择的预测结果,采用这样的特征数据进行RUL预测时可能导致不合理的结果。并且随着现代传感器技术的发展,实际应用中采用越来越多的传感器同时对一个设备进行状态监测,从而出现了大量与设备的退化机理不相关或冗余的传感器监测数据。
针对以上问题,研究提出了一种基于特征优选的航空发动机剩余寿命预测方法,首先,基于长短时记忆网络建立监测数据预测模型,预测不同工况下发动机测试样本的数据集。其次,基于特征融合与相似性匹配法,计算预测数据集剩余寿命值的均方根误差,定义剩余寿命预测评价指标,并分别基于非劣分层遗传算法(non-dominated sorting genetic algorithm II, NSGA-II)进行特征优选。最后,对基于特征优选的发动机剩余寿命预测效果进行验证,以证明所提出方法的有效性。
1 基于LSTM的监测数据预测
研究以航空发动机为对象,基于NASA公布的航空涡轮发动机性能退化数据展开研究,研究中所采用的数据为C-PASS数据库中的FD001数据集,包括训练样本集:100个不同工况下航空发动机的全寿命周期数据;测试样本集:100个与训练样本集对应工况下的航空发动机部分退化数据;RUL真实值:包含测试样本集100个不同工况下发动机的剩余寿命值,分别为测试样本集中每个发动机最后时间周期的剩余寿命。上述训练样本集和测试样本集中每组监测数据都包含了24个特征。
研究中以FD001数据集的前50个工况中的训练样本 T1-50和测试样本 C1-50进行监测数据的预测和剩余寿命预测的特征优选,剩余50个工况中的训练样本 T51-100和测试样本 C51-100用于特征优选结果的发动机剩余寿命预测效果验证。
1.1 数据预处理
1)数据滤波。发动机的原始特征监测数据中伴随着大量随机噪声,而且所有发动机存在一定的初始磨损。研究采用FIR数字滤波器对发动机的原始特征监测数据进行异常值和工作噪声的去除。
2)数据去量纲。由于不同类型特征获取的监测数据数量级和量纲都不同,因此采用归一化的方法将数据滤波后的特征监测数据进行去量纲化,具体计算公式为:

式中: xi,j(t)——第i个工况中第j类特征在t时间周期时的原始特征监测数据;
min(xi,j)和——第j类特征在所有工
况下所有时间周期数据的最小值和最大值;
xi′,j(t)—— xi,j(t)经归一化处理后的归一化值。
对所有特征监测数据进行滤波和归一化预处理,获得处理后的训练样本集 xT1-50和测试样本集 xC1-50。
1.2 基于LSTM的监测模型的搭建
为通过监测数据提取出航空发动机的性能退化内在趋势,并以此预测未来一段时间内的性能退化趋势,在设备故障失效前及时预警,需要通过预测模型获取监测数据的时间序列预测结果,并充分利用时间序列信息进行RUL预测。常见的序列学习模型有递归神经网络(recurrent neural network,RNN)、隐马尔可夫模型(hidden Markov model,ΗMM)和前馈神经网络等。其中,RNN网络其内部循环结构允许信息从上一个网络直接传递到下一个网络,与序列型数据建模非常契合,在智能语音识别、图像字幕、机器翻译等领域得到广泛应用。但由于梯度爆炸或梯度弥散现象的存在,导致RNN应用中“记忆能力”受限[8],通常只能学习到短时间步长的依赖关系。而LSTM网络作为特殊的RNN网络,通过引入了门限机制来控制信息的累积速度,使得其能够学习长期的依赖信息[9],其结构如图1所示。

图1 LSTM网络结构
一个LSTM网络单位模块主要包括长期状态Ct和短期状态ht,输入门、遗忘门、输出门门控机制来对进行信息调节[10]。通过遗忘旧信息,添加新信息和控制信息传递来实现LSTM网络状态更新,LSTM网络计算t时刻输入xt到输出ht的实现公式为:

式中:σ——sigmoid函数;
i、f、O和C——输入门、遗忘门、输出门和单元状态;
W——权值矩阵;
b——阈值矩阵;
tanh函数——激活函数;
LSTM监测数据预测模型结构图如图2所示。
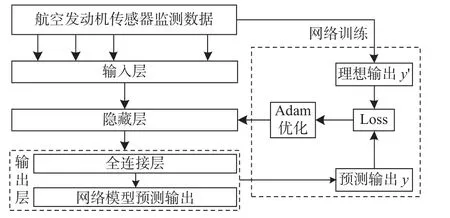
图2 LSTM单序列预测模型结构图
LSTM监测数据预测模型利用特征全周期寿命监测数据中前mi个时间周期的监测数据值来预测第mi+1次时间周期时的特征监测数据y,故在训练网络模型时将第mi+1次时间周期点的xi的真实值y'作为模型的理想输出。在完成所有LSTM监测数据预测模型训练后,将对应的测试样本集输入网络模型,进行测试样本集后续l个时间周期的特征监测数据的预测。
2 基于特征优选的剩余寿命预测
特征优选的目标是获取在特征数量尽可能少的情况保证对不同工况下的航空发动机的剩余寿命预测效果,研究据此设计双目标优化函数f1和f2。
2.1 目标函数I:特征数量f1
特征数量在本研究中指的是基于数据驱动进行航空发动机剩余寿命预测所采用的数据的特征总数量,有效地减少特征数量,不仅能选择出包含信息量丰富、能有效反映航空发动机性能变化且冗余小的特征数据集,并且有利于提高RUL的数据处理速度,提升RUL预测的精准度和鲁棒性。因此将特征数量设为优化目标函数I。
研究中特征的组合方式为二进制编码,特征共24种,则特征的组合的向量可表示为S=[s1,s2,···,s24]T。向量中数字1的个数代表了选择的特征数量。1代表选择中该类特征数据,0代表不选择该类特征数据。因此,优化目标函数I:特征数量fT1即为向量S中的非零元素个数:

2.2 目标函数II:剩余寿命预测评价指标f2
在航空发动机剩余寿命预测过程中,对于相同的数据特征数量,基于不同的特征类型数据组成的特征数据进行的剩余寿命预测结果也大为不同。在某一组特征类型的组合中,如果其剩余寿命预测的预测结果与真实值越接近,即发动机所有工况下的预测剩余寿命与真实剩余寿命的误差值越小,则剩余寿命预测的效果越好,将该误差值定义为目标函数II。
2.2.1 基于特征融合的相似性匹配
研究采用一种基于特征融合的相似性匹配方法来确定预测数据集在对应工况下的发动机RUL预测结果,具体流程如图3所示。

图3 基于特征融合的相似性匹配流程
1)特征融合。为尽可能在特征融合过程中保留全周期寿命数据和预测数据集的退化特性,减少给后续的相似性匹配结果带来的误差,研究中采用最为简单和有效的特征融合方法,即基于串联的特征融合方法。对全周期寿命数据第t个时间周期起始、长度与预测数据集长度l相同的全周期寿命数据片段以及预测数据集进行串联特征融合。
2)相似性匹配。采用Pearson相关系数来计算经过特征融合后的全周期寿命数据片段和预测数据集这两个时间序列之间的相关程度,以此进行相似性匹配。Pearson相关系数的计算公式为:
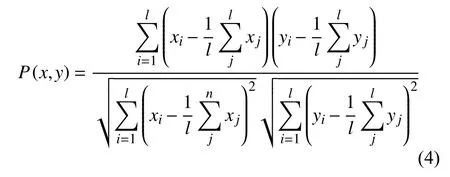
其中,x和y在本研究中为待定的全周期寿命数据片段和预测数据集这两个时间序列。
2.2.2 剩余寿命标定
在进行发动机RUL预测时,由于待测的测试样本集,即待预测的系统性能状态未知,在预测评估其RUL并生成其寿命标签的过程中,通常采用分段标定的策略来实现[11]。定义RUL标定策略函数为 f (RUL),设定上边界为U,则函数 f (RUL)可以表示为:

上边界U值选取大小与航空发动机的退化性能密切相关,通常上边界U的范围在120~130之间。通过分段RUL的标定策略,将全周期寿命数据和预测数据集的剩余寿命标签设置为分段的线性函数,当其RUL值超过125时统一修正为125。
2.2.3 获取剩余寿命预测评价指标
在某一组特征类型的组合中,如果其剩余寿命预测的预测结果与真实值越接近,即发动机所有工况下的预测剩余寿命与真实剩余寿命的误差值越小,则剩余寿命预测的效果越好。均方根误差(root mean square error, RMSE)能够反映出预测结果与真实值之间的偏差,所以将其作为评价目标函数I(f1)选择的特征数据进行发动机剩余寿命预测效果的评价指标,即目标函数 II(f2)。

RULp——预测的剩余寿命值;
RULt——真实的剩余寿命值。
RMSE指的是所有工况下预测的剩余寿命与真实剩余寿命的均方根误差值,得分越高,代表平均预测误差越大。最终,确定剩余寿命预测中进行特征优选的两个目标函数为:
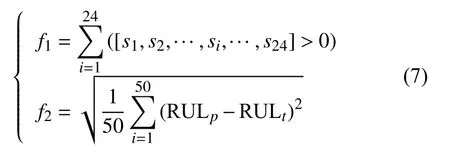
2.3 基于改进非劣分层遗传算法的特征优选
NSGA-II是一种基于最优保存策略的随机寻优算法[13],其本质是模拟自然中生物进化的过程,遵循物竞天择的原则,个体优势基因将有更大机会传递下去,同时加入一定的变异概率,从而可以避免陷入局部最优解,找到全局最优解[14]。流程图如图4所示,具体步骤如下。
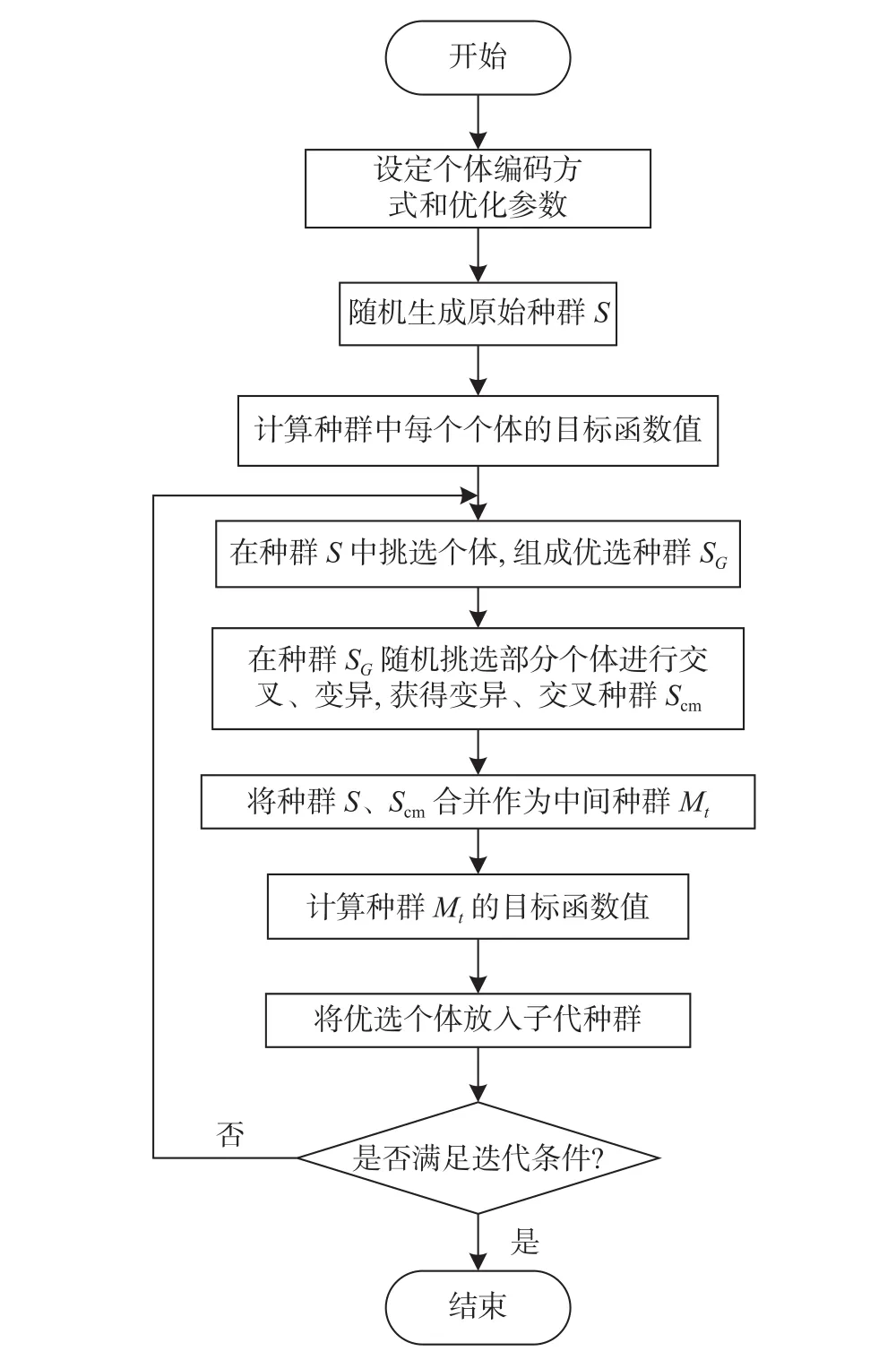
图4 改进的非劣分层遗传算法程序流程图
步骤1:设定个体编码方式。特征选择方案采用A维列向量表示,中元素取值1(或0)表示是否选择第i类特征。
步骤3:创建初始种群。随机生成规模为n的初始种群:

式中:i——0时表示初始种群;
T——迭代终止次数;
j——种群中个体的编号。
步骤4:建立优选池。由公式(7)计算种群中所有个体的目标函数和目标函数的值,据此对所有个体进行非劣层级划分,并采用轮盘赌从父代中挑选n个个体放入优选池。
步骤7:生成子代。将优选池、交叉种群和变异种群合并,并根据目标函数和目标函数的值对合并后的种群进行非劣层级划分,将非劣层级最前和拥挤距离最大的n个个体放入子代。
步骤8:迭代终止条件
2)迭代次数达到10 000次,迭代结束。
2.4 特征优选结果
将数据代入NAGA-II算法,特征数量阈值设定为14,经过优化后,获得的特征优选结果如表1所示。由表1可知,特征优选结果中:

表1 采用NAGA-II优化获得的特征优选结果
1)特征数量少的特征优选结果大都包含在特征数量多的特征优选结果里,说明优化后的特征优选结果具有一定可靠性。
2)在第一非劣层中,随着特征数量从1增加到9,剩余寿命预测评价指标从41.85降低至33.38,以特征数量多的数据进行发动机RUL预测效果好于特征数量少的。
3)特征数量小于特征数量设计阈值14,而优选结果中的最大特征数量小于14,说明过多的特征数量并没有使预测结果更接近真值,即部分冗余特征的数据加入导致了发动机RUL预测效果变得更差,证明了采用特征优选对发动机RUL预测的必要性。
3 基于特征优选的剩余寿命预测验证
将后50个工况中的训练样本 T51-100和测试样本C51-100用于特征优选结果的发动机剩余寿命预测效果验证。对于训练样本 T51-100和测试样本C51-100,采用与前50个工况的训练样本 T1-50和测试样本C1-50相同的数据处理方法和监测数据预测方法,利用2.4中获得的特征优选结果,可以计算得到测试样本剩余寿命预测效果如表2和图5所示。

图5 测试样本C 51-100剩余寿命预测效果

表2 测试样本C 51-100剩余寿命预测效果
由表2和图5可以得知,测试样本 C51-100的剩余寿命预测效果与特征优选结果相似:
1)以特征优选结果第一非劣层的特征组合进行剩余寿命预测和以第二非劣层的特征组合进行剩余寿命预测时,第一非劣层的f2值整体趋势上小于第二非劣层的f2值,说明通过MOPSO算法获得的最优特征组合(第一非劣层),相较于次优的特征组合(第二非劣层),能够获得更好的剩余寿命预测效果,证明论文所提的基于特征优选的航空发动机剩余寿命预测方法的正确性。
2)当特征数量为3时,测试样本 C51-100以最优特征组合(第一非劣层)获得的剩余寿命预测评价指标值反而小于以次优的特征组合(第二非劣层)获得的值,以及当特征数量为3、4和6时,剩余寿命预测评价指标值不降反升,这是由于训练样本T51-100的50个工况和训练样本 T1-50的50个工况存在差异,导致进行特征优选时,优化会尽可能朝着对于训练样本 T1-50的50个工况剩余寿命预测效果更好的方向进行,使得对于训练样本的50个工况而言并非是最优的。
3)随着特征数量的增加,测试样本 C51-100的剩余寿命预测评价指标值整体呈现逐渐下降的趋势。说明以训练样本 T1-50的50个工况数据进行特征优选的结果适用于另外完全不同的训练样本 T51-100的50个工况。
以第一非劣层中2、9个特征数量的特征优选结果进行RUL预测的结果以及第二非劣层中2个特征数量的特征优选结果进行RUL预测的结果如图6所示。

图6 不同特征优选结果下的剩余寿命预测效果
由图6可知:对于进行特征优选的测试样本C1-50的50个工况和进行剩余寿命预测的测试样本C51-100的50个工况,都出现了相同的趋势,以2个特征数量第一非劣层特征优选结果进行RUL预测的结果优于以2个特征数量第二非劣层特征优选结果进行RUL预测的结果,预测误差均值从49.9降低至34.98;以9个特征数量第一非劣层特征优选结果进行RUL预测的结果优于同为第一非劣层中以2个特征数量第一非劣层特征优选结果进行RUL预测的结果,预测误差均值从34.98降低至30.66,证明通过特征优选,可以有效提高航空发动机剩余寿命预测效果;第一非劣层中2个特征的的预测误差均值相差8.47%,9个特征的的预测误差均值相差15.07%,它们都小于16%,则可得到在第一非劣层不同特征数量下,的预测误差均值相差都小于16%,证明了论文所提方法的鲁棒性。
4 结束语
研究针对航空发动机剩余寿命预测中单一特征数据的剩余寿命预测方法数据利用率低及预测精度不高,而多特征数据的剩余寿命预测方法存在信息冗余及时间序列信息考虑不充分的问题,提出了一种基于特征优选的航空发动机剩余寿命预测方法,结果表明:
1)特征优选结果中:①特征数量少的特征优选结果大都包含在特征数量多的特征优选结果里,说明优化后的特征优选结果具有一定可靠性;②随着特征数量从1增加到9,剩余寿命预测评价指标从41.85降低至33.38,以特征数量多的数据进行发动机RUL预测效果好于特征数量少的;③特征数量小于特征数量设计阈值14,说明部分冗余特征的数据加入导致了发动机RUL预测效果变得更差,证明了采用特征优选对发动机RUL预测的必要性。
2)以训练工况样本进行特征优选的结果适用于另外完全不同的测试工况样本,预测误差均值相差小于16%,证明了论文所提方法的正确性和鲁棒性。
猜你喜欢
煤气与热力(2022年4期)2022-05-23
中老年保健(2021年8期)2021-12-02
防爆电机(2021年5期)2021-11-04
舰船科学技术(2021年12期)2021-03-29
铁道通信信号(2020年1期)2020-09-21
作文评点报·低幼版(2020年3期)2020-02-12
铁道通信信号(2019年11期)2019-05-21
华人时刊(2018年17期)2018-12-07
奥秘(2017年12期)2017-07-04
中国资源综合利用(2016年11期)2016-01-22
