
基于类别不平衡数据集的图像实例分割方法
2022-12-13 13:52范馨月鲍泓潘卫国
计算机工程 2022年12期
范馨月,鲍泓,潘卫国
(1.北京联合大学 北京市信息服务工程重点实验室,北京 100101;2.北京联合大学 机器人学院,北京 100027)
0 概述
随着深度卷积神经网络的发展,基于深度学习的实例分割算法[1]在类别分布相对均衡的数据集上取得了较大的成功,如数据集COCO(Common Objects in Context)。然而,现实生活中的数据往往呈现长尾分布规律,在自然方式采集的数据集中少数的频繁类数据提供了足够多的图像样本,而大量的稀有类数据在数据集中可能被有限的样本所代表。
早期解决数据不平衡的研究主要使用单阶段模型[2],由于缺乏根本上的策略设计,这种方法没有取得理想的效果。文献[3]采用重采样技术随机添加与删除稀有类与频繁类数据使类别数量实现平衡,然而该方法易丢弃一些有用的潜在信息或增大过拟合的可能性。基于集成学习的方法可以通过修改现有的分类算法使其适用于长尾数据集,具有代表性的方法有:基于Bagging[4]的方法,该方法提升了机器学习算法的稳定性与准确性,但仅在基本分类器效果很好时才有效,否则会进一步降低分割效果;基于Boosting 的方法可以较好地泛化,但是对噪声数据和异常值都很敏感。
研究人员运用数据驱动方法来解决此类问题,文献[5]首先在传统的数据驱动方法基础上提出了自动增强方法,通过对图像中的目标进行几何增强和颜色增强取得了较好的效果,但是其繁重的计算成本与对目标尺寸的忽略导致了其实用性较差与鲁棒性较低。文献[6]在自动增强的基础上增加了目标扩充区域并制定了不同目标下的增强策略,但消耗了大量时间与空间,精确度提升不高。
重采样操作在早期研究中包括稀有类的过采样[4]和频繁类的欠采样[7],但其本质都是根据样本数量对不同类别的图片采样频率进行反向加权。近年来最常使用的策略为类均衡采样[8-9]。文献[8-9]的研究发现,对于任何类别不均衡数据集再平衡的本质都是对分类器的再平衡,即在类别不平衡的情况下学习特征提取的骨干网络,而在数据集类别重新平衡的情况下进行分类器的学习。本质上,稀有类数据的特征依旧会过拟合,而频繁类数据会欠拟合,不能规避特征提取网络提取稀有类数据特征单一性的缺点。
本文提出一种新的图像实例分割方法。通过对各类别中不同尺寸的图像目标进行基于目标级的增广操作,并在训练中使用重采样方法提升稀有类数据的采样频率,增加网络的鲁棒性,从而使神经网络更好地提取目标特征。同时,将目标级数据驱动方法与均等化损失函数方法相结合,以解决实例分割中的长尾分布问题。
1 相关工作
1.1 数据增强方法
随着深度学习的研究与发展,数据增强已被广泛应用于神经网络的优化,而且在实例分割任务中取得了很好的效果。多数用于图像分割任务中的数据增强方法都是通过人工进行设计的,传统的方法分为几何变换[4-5](例如裁剪缩放、移动填充)、色彩空间转换(例如RGB、HSV、Lab)、像素处理(例如模糊锐化、图像混合[10])等方法,但是使用这些方法需要足够的专业知识且耗费时间。Mixup[11]在成对样本及其标签的凸组合上训练神经网络,有效地减少对错误标签的记忆,增加对抗样本的鲁棒性。文献[12]通过采用自动搜索方式改进数据增强策略。文献[13]应用贝叶斯优化来学习数据增强策略并取得了较好的效果。基于上述研究,可以得出多尺度方法[14]能够在图像细节提升中起到关键的作用。Sniper[15]通过缩放特定的上下文区域,在保证裁剪尺度不变性的同时提升了训练速度。Stitcher[16]通过将图像调整为小尺寸的分量而后将这些分量拼接为与常规图像相同的尺寸,避免了小目标所受的损失。
上述数据增强方法都取得了一定的效果,但都是对图像整体进行操作,而不是针对图像中具体的目标进行操作,忽略了图像中目标尺度层次的多样性。
1.2 重加权方法
重加权的基本思想是为不同的训练样本分配权重以解决训练过程中频繁类占据主导的问题。在神经网络中主要体现在分类的损失函数[17]上,其基本计算方法如下:

其中:zi代表网络输出的分类评定模型;β代表重加权的权重。理论上,当f(·)、g(·)是单调递增函数 时,都可以使分类器起到重加权的效果。
文献[2]基于改变新增样本数量带来递减收益的情况,设计一个更优的重加权方法,取得了较好的长尾分类效果。文献[18]对文献[2]方法进行改进,提出一个条件权重用来优化平衡数据集上的结果。文献[19]通过为少数类提供更高的权重分配标签以支持少数类,平衡了频繁类和稀有类间的泛化错误。文献[20]指出在softmax 函数中随机丢弃一些稀有类可以有效地提升网络对于目标识别的鲁棒性,减少频繁类和稀有类之间的混淆。文献[21]基于贝叶斯不确定性修改损失函数。文献[22]提出了两个新的损失函数来平衡梯度流。文献[23]改进了原本交叉熵损失函数使用的二进制类别,运用一种连续型标签判断正负样本。这些方法都帮助模型更好地平衡不同的类别,但都忽略了图像中前景类别不平衡的问题,没有考虑到前景类别均衡的重要性,效果较差。
2 本文方法
2.1 方法框架
本文方法操作流程如图1 所示。首先使用基于目标尺度的数据增广方法对数据集进行处理,以达到扩充训练样本的目的;然后对稀有类数据进行重采样,用以解决稀有类的类别数据量过小的问题,从而提升模型在长尾数据集的鲁棒性;最后将均等化损失函数融入Mask R-CNN 实例分割网络,以降低频繁类的数据特征对稀有类数据特征的抑制性。

图1 数据驱动的实例分割流程Fig.1 Instance splitting procedure of data-driven
2.2 基于目标级的自动增强方法
自动增强方法一般通过设置操作空间、搜索函数、操作评估3 个主要部分实现数据集的自动增强。为解决以往自动增强方法对图像尺寸适应性差与图像目标定位不清晰的问题,本文使用图像增强处理与目标处理实现数据集的自动增强。
图像增强处理首先对图片进行整体的放缩处理,采集放缩后的两张图像及原图的目标像素,将得到的3 组像素进行合成处理后对图像中的目标进行几何变换和色彩空间转换。目标处理通过将高斯映射应用到目标框增广的方法,用以软化边界间隙,同时,设置参数r(Sframe)对目标进行尺寸适应性增广,使增广面积适配于目标的面积。
图像增强处理:为了使神经网络适应不同的图像尺度,通常使用图像金字塔对实例分割模型进行训练。但是由于这些比例的设置及其依赖手工设置的参数,因此本文对图像进行缩放处理来降低网络对参数的依赖性。设置缩放概率Pen、Pre在0.0~0.5范围内,缩放幅度L在0.5~1.5 之间以保证原图存在的概率。为避免大尺寸图像给计算机带来额外的负担,对经过放大函数处理后的图像进行保留原始形状并随机裁剪至原来大小的操作。缩放操作结束后从放大、缩小、原图3 个分辨率中取样。
目标处理:为了避免以前工作中目标级增强方法在整个边界框注释中延伸较多导致增强区域与原始区域间隙较大,以及过大的图像外观变化降低网络对于增强对象的定位,使得训练和验证之间差距较大的问题,本文将高斯映射融入到目标框增广中,通过软化边界间隙解决上述问题。通过混合原始像素与空间高斯映射变化后的像素得到增广区域E,如式(3)所示:

其中:I为输入函数;F为变换函数;E为增广区域。在上述的目标处理中没有考虑到感受野和目标尺度对神经网络的影响。很多研究人员认为神经网络在很大程度上依赖于上下文信息对物体进行识别,然而在研究中发现,它的效果更大程度上随物体尺度的变化而变化,这个可以从Faster R-CNN[24]和RetinaNet[25]得到证明。图像增强与目标处理示意图如图2 所示。

图2 图像增强及目标处理示意图Fig.2 Schematic diagram of image augmentation and object processing
在去掉所有上下文信息的COCO 验证集上进行测试时,发现它对小目标识别的准确率大幅下降,相比之下,对于大目标、中目标识别的准确率有一定幅度的提升。实验结果表明,仅在目标内部/外部进行增强无法处理所有尺度的图像。
为此,本文引入一个用于搜索的参数r(Sframe)对图像目标进行高斯映射,使增广面积适配于对象的面积。增广面积的计算方法为:给出图片尺寸H×W及标注框,标注框(xc,yc,h,w)可以用中心点(xc,yc)以及长宽比h/w表示,可得扩充高斯区域S。
将高斯映射用公式表示为:

增广面积可定义为高斯映射的积分:

最后可得参数面积比r(Sframe),如式(6)所示:

其中:面积比r(Sframe)代表目标面积与目标框面积的比例大小。本文设置P和M分别代表放缩函数的概率和幅度。
在目标处理中,根据参数面积比r(Sframe)对图像中的小目标(r(Sframe)>1)、中目标(r(Sframe)=1)、大目标(r(Sframe)<1)进行搜索,如图3 所示。其中,实线框代表目标框,虚线框代表增广区域。本文对目标处理设置子操作,操作内容如表1 所示。子操作由颜色操作和几何操作组成,每个操作包含两个参数,使用该操作的概率和幅度。概率从一组6 个离散值中采样,范围为0.0~1.0,间隔为0.2。幅度范围映射到一组标准化的6 个离散值,范围为0~10,间隔为2。

图3 不同面积比的目标处理示意图Fig.3 Schematic diagram of target processing with different area ratios
操作效果评估:自动增强方法通常使用的搜索指标不够准确并且时间消耗过大。本文将操作对象精确到每一个目标上,根据每一个目标的尺度获得不同尺度下的具体数据,通过记录不同尺度上的累计损失和精度制定不同尺度的度量。具体方法为:给出一个未经数据驱动训练的普通模型,记录验证平均精度(AP)及不同尺度上的平均精度APj(j∈S),对每个候选操作组m进行微调,记录累计损失Lj,不同尺度的验证平均精度为APm,对整个AP 制定对象函数为:

不同尺度上的平衡优化效果直接影响分割模型的表现力和鲁棒性,为了避免不同尺度上的累计损失Lj有时不是最优的情况,引入了帕累托最优[26]避免这种情况,以使在不损害其他任何尺度精度的情况下达到该尺度最好的优化,并引入一个补偿因子ϕ来补偿使用操作组m进行微调后精度下降的部分所以,操作评估函数可以升级为:

本文使用进化算法作为搜索函数,即在每次迭代中从操作空间抽取m个操作组。在对抽样策略进行评估后选择最优的k个策略作为下一代的父策略,之后通过父策略间的变异和交叉产生子策略,重复迭代此过程至收敛。
2.3 重采样方法
本文使用重采样方法通过对含有稀有类的图像进行重采样,能够在数据驱动方法的基础上进一步对稀有类数据进行扩充,提升了稀有类类别的采样频率,增加了模型的鲁棒性。
对于每个类别c,令fc为至少包含一个实例c的训练图像分数,t为超参数用来控制过采样开始的点,定义每个类的重复因子为:

当fc≤t时,不存在过采样,当fc>t时,过采样通过元素γ<1 来降低某个类别的频率,其重复元素乘以
2.4 均等化处理
本文运用以下函数来进行均等化处理:
1)softmax 交叉熵损失函数。softmax 用在多分类过程中,它将多个神经元的输出映射到(0,1)区间内作为概率值。pi是softmax 输出向量p的第i个值,表示该样本属于第i个类别的概率,c为类别总数,i的范围是1 到类别数c,因此yi是一个1×c的向量,里面有c个值且只有一个值是1,其他c-1 个值都是0,Lsce为最后输出层激活函数的损失函数。

在softmax 交叉熵损失函数中,如果存在前景类别c,那么其可以被视为其他类别i的负样本。因此,类别i就会接收到负梯度pi用于模型更新,这就会导致类别i的网络预测率很低。
当数据集中类别数量分布严重不平衡时,比如在长尾数据集中,频繁类的负梯度效应对稀有类有很大的影响,稀有类的学习总是被抑制。为了解决这一问题,本文引入了均等化损失函数,即对于稀有类别忽略频繁类别的样本梯度使神经网络对不同的类别公平地训练。
2)均等化损失函数。当数据集中图像类别的分布不平衡时,常用的交叉熵损失函数很容易忽略稀有类的学习。为此,本文使用一种均衡化损失函数,即在稀有类数据进行训练时主动忽略频繁类的梯度,以达到各类别数据均衡训练的目的。
在原交叉熵函数的基础上引入一个权重φ,此均衡化损失可表示为:

其中:c为数据集中类别的总数量;pi由sigmoid 交叉熵损失函数得到。为将函数作用于目标级r处理,本文将φi设为:

其中:当r代表图像前景区域时,E(r)为1,当r代表图像背景区域时,E(r)为0;fi代表数据集类别i出现的频率,由类别i的图像数量相比于整个数据集的图像数量计算得到;Tτ(x)是一个阈值函数,当x<τ时为1,否则为0;τ用于区分稀有类和其他类别。
3 实验设置与结果分析
3.1 实验设置
3.1.1 LVIS 数据集
LVIS 数据集是一个大规模细粒度词汇级标记数据集,包含164 000 张图像,并针对超过1 000 类物体进行了约200 万个高质量的实例分割标注。根据每个类别包含图像的数量将这些类别分为3 个大类:稀有类(1~10 个图像),普通类(11~100 个图像)和常见类(大于100 个图像)。该数据集并非在未知类别标记的情况下收集,而是通过在收集图像以后根据图像中目标的自然分布来进行标注。大量的人工标注而非其他数据集的机器自动化标注可以使得数据集图像中自然存在的长尾分布被有效识别。
本文使用LVIS v0.5 训练集进行训练,LVIS v0.5验证集进行测试。
3.1.2 自动增强方法的微调策略
采用RetinaNet 从LVIS 的验证集中随机采样5 000 张图像用于在搜索期间进行评估,训练集中抽取57 000 张图像用于子模型训练,测试集中抽取20 000 张图像用于最后的评估。每个子模型都针对普通模型进行1 000 次迭代微调,普通模型只是一个任意部分训练的基线模型。在进化搜索中,进化过程重复10 次迭代。迭代模型大小为50 个,选取前10 个模型作为后代的父本。
在LVIS 数据集的预训练和微调设计中,使用搜索的增强策略对模型进行训练。调整训练图像的大小,使其较短的尺寸为800 像素,长边不超过1 333 像素。多尺度训练基线通过在训练过程中随机选择范围为640~800 像素的尺寸来增强。
3.1.3 均等化损失函数
使用带有FPN 的标准Mask R-CNN 作为基准模型,对图片进行增强处理。在第1 阶段,RPN 以前景和背景为1∶1 的比例采集256 个锚点;在第2 阶段,以前景和背景为1∶3 的比例采集每幅图像512 个proposals。使用8 个GPU,总共16 个批量用于训练。采用随机梯度下降优化模型,在25 个周期内动量衰减0.9,权值衰减0.000 1,初始学习率为0.02,分别在16 epoch 和22 epoch 衰减到0.004 和0.000 4。虽然特定类别掩码预测的性能较好,但由于大规模类别的巨大内存和计算成本,因此本文采用类别不可知机制。在LVIS 之后,预测分数的阈值从0.05 降低到0.0,保留top300 个边界框作为预测结果。如果它们在正类别中,则均衡化损失函数中的类别将不会忽略该图像的集合或负类别集。对于这些类别,式(14)的权重项将为1。
3.2 实验结果
本文通过LVIS 数据集来分析实验结果,训练阶段使用数据驱动、均等化损失函数及重采样方法。指标APbbox用于对各方法进行综合性评估,APbbox为实例分割框的准确率,下标r、c和f分别代表稀有、常见和频繁类别,结果如表2 所示。实验得出本文方法在测试阶段以ResNet50 为骨干的网络上得到4.9%的精度增益,在以ResNet101 为骨干的网络上得到5%的精度增益。本文还增加了不同模型在测试时的推理时间及最终权重大小,如表2 所示。在使用不同的骨干网络时,本文的推理时间和其他对比模型相当,以ResNet50 为例,本文方法的每张图推理时间为0.264 s,并没有增加过多的推理时间。同时,本文最终的权重大小只比Baseline 增加30×106,在可接受范围内。

表2 总体实验结果Table 2 The overall experimental results
此外,本文对APr指标进行重点比较,通过与Mask R-CNN 基线相比,该指数的大幅提升可以表明该方法应用于长尾数据的有效性,较好地解决了数据集的长尾分布问题。
可视化效果如图4 所示,可以看出,Mask R-CNN和Forest R-CNN 出现了识别错误、掩膜边缘准确率较差的问题,如图4(b)错误地将食物识别为“carrot”类。图4(c)Forest R-CNN 未识别出稀有类“pizza”,Mask R-CNN 将“pizza”识别为“carrot”。本文方法成功地识别出了图4(c)的稀有类“jean”,并且识别出了前两种方法未识别出的“helmet”类。综上所述,本文方法可对稀有类数据进行有效地检测和分割。

图4 可视化实验结果Fig.4 Visualization experimental results
3.3 消融实验
本文对各种方法进行了消融实验,如表3 所示,其中,*表示只用数据增强,**表示只用均等化损失函数,***表示既使用数据增强又使用均等化损失函数。首先,对使用的目标级尺度图像增强进行系统评估。在ResNet50 骨干网络上,本文方法将多尺度训练基线提高了22.6%,APbbox提高了1.8%,APr提高了1.6%;在ResNet101 骨干网络上,APbbox提高了1.7%,APr提高了1.8%。实验结果表明,本文的目标级数据驱动方法有效地提升了长尾实例分割的精度。
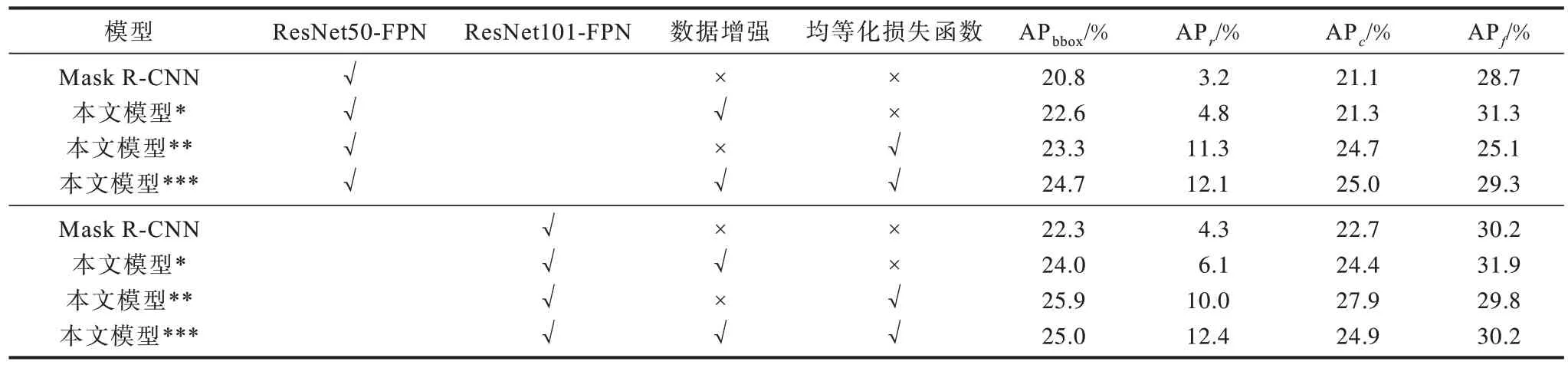
表3 消融实验结果Table 3 Ablation experimental results
其次,对均等化损失函数的作用效果进行评估。表3 展示了均衡损失函数在不同主干和框架上的有效性。可以看出,改进主要来自于稀有和常见的类别,在ResNet50 骨干网络上,APbbox提升了2.5%,APr提升了8.1%,说明了均等化损失函数对长尾分布类别的有效性。
最后,对均等化损失函数和目标级数据驱动方法相结合的有效性进行分析。在ResNet50 骨干网络上,APbbox提升了3.9%,APr提升了8.9%,相较于只使用均等化损失函数分别提升了1.4%及0.8%,充分说明了本文方法的有效性及针对性。而在ResNet101骨干网络上,虽然APbbox降低了0.9%,但是具有针对性的指数APr却提升了2.4%,仍可说明本文方法针对长尾数据的有效性。
4 结束语
本文分析了长尾数据集中存在的类别不平衡问题以及常规神经网络对长尾数据集的不适应性,提出一种目标级的数据驱动方法,并在该方法基础上融入均衡损失函数,以解决稀有类数据匮乏对检测结果造成的影响。同时,在训练中加入了重采样方法,提升检测模型的鲁棒性,以对稀有类数据驱动方法进行补充,实验结果表明了本文方法的有效性。下一步将从神经网络后处理中的置信度角度出发,研究数据的长尾分布在实例分割中的归一化校准方法,在计算量更小的前提下提升稀有类别分割的准确率。
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
民族古籍研究(2018年1期)2018-05-21
西夏学(2016年2期)2016-10-26
中国司法(2016年1期)2016-08-23
太空探索(2016年5期)2016-07-12
中国卫生(2015年1期)2015-11-16
中国领导科学(2015年11期)2015-07-01
浙江大学学报(工学版)(2015年1期)2015-03-01
时代英语·高三(2014年5期)2014-08-26
特区实践与理论(2014年5期)2014-07-24
