
基于位置与信誉感知深度神经网络的云服务质量预测*
2022-12-12 08:22张园园韦贵香
通信技术 2022年10期
朵 琳,张园园,韦贵香
(昆明理工大学 信息工程与自动化学院,云南 昆明 650504)
0 引言
随着大数据和云计算的出现,万物即服务的理念已被广泛接受,互联网上具有类似功能的服务激增[1]。因此,快速发现和选择优质的服务已成为服务推荐领域的研究热点[2]。服务推荐系统由于可以主动向用户推荐高质量的服务,因此备受欢迎[3]。然而,由于服务通常在动态网络上运行,一些服务质量(Quality of Service,QoS)属性的值,例如响应时间、吞吐量等,会受到不同用户的上下文(例如地理位置和网络条件)的影响[4]。因此,预测与用户相关的QoS 值对于有效地云服务推荐非常重要[5]。然而,如何获得具有相似功能的QoS 值是服务推荐领域面临的最大挑战之一。一方面,实际的QoS 值通常取决于调用服务的用户的物理位置和网络状况,也就是说,用户从服务提供者那里获得服务的实际QoS 值是不现实的[6]。另一方面,大多数传统方法直接使用用户提供的历史QoS 值来预测未知的QoS 值,而不考虑QoS 值是否可靠,如果数据是由不可信的用户提供的,那么预测性能会受到很大影响[7]。因此,QoS 预测被认为是获得QoS 值的有效方法[8]。
协同过滤(Collaborative Filtering,CF)是最广泛使用的QoS 预测方法之一[9]。协同过滤根据其实现原理可分为基于内存(或邻域)的方法和基于模型的方法两类。基于内存的CF 方法[10]的关键步骤是计算用户(或服务)之间的相似度,然后根据相似用户(或服务)提供的历史QoS 值来预测未知的QoS。基于模型的CF 方法[11]需要基于训练数据和机器学习算法构建一个有能力的模型,整合来自相关客户的历史数据来预测目标服务的质量。最近,在基于模型的预测方法研究领域中,关于矩阵分解技术[12]的研究热度明显上升。Zhu 等人[13]通过数据转换、在线学习和自适应权重等新技术扩展了传统的矩阵分解模型。Ryu 等人[14]提出了一种使用偏好传播方法的基于位置的矩阵分解,它将调用相似性和邻域相似性整合到偏好传播过程中以应对数据稀缺性。
然而,基于CF 的方法的预测精度依赖于邻居选择效率,在数据稀少的情况下,由于与QoS 相关的数据可用性较低,邻居选择效率会受到限制。另外,由于相似度计算依赖于历史QoS 数据,因此历史数据的质量对预测结果也有很大的影响,如果数据是由不可信的用户提供的,那么预测性能会受到很大影响。因此,解决数据稀疏和用户可信度问题,是提高预测准确度的其中一个手段。Wang 等人[7]提出了一种基于信誉感知网络嵌入学习的改进的QoS 预测方法。该方法首先过滤不可信用户,其次利用信誉感知网络嵌入来学习用户的隐藏表示,最后用基于用户的CF 来预测未知的QoS 值。Seyyed等人[15]结合用户的位置信息和他们的声誉来获得区域声誉,然后与矩阵分解相结合,提高了预测准确度。基于模型的CF 方法不依赖于邻居选择,它们直接从服务调用中学习潜在特征;因此,在较高的数据稀疏度的条件下,基于模型的方法比基于内存的方法能够实现更高的预测精度。然而随着数据集大小的增加,这种方法的预测精度会下降。
近年来,深度学习在图像处理、计算机视觉以及语音识别等领域产生了巨大影响[16]。深度学习比传统方法更适合服务推荐系统的原因是,深度学习具有非线性变换、表示学习、序列建模、灵活性高[17]等特点。此外,深度学习可以学习多个实体之间的许多复杂关联。服务用户的行为可能非线性地依赖于其他用户,因此可以使用深度学习模型有效地学习。深度学习的自动特征设计使其可扩展且轻松,并且支持一些流行的框架。Zou 等人[18]提出了一种基于深度学习的方法,通过特征集成来执行时间感知服务QoS 预测的任务。He 等人[19]提出了一种基于多层感知器(Multilayer Perceptron,MLP)的神经协同过滤(Neural Collaborative Filtering,NCF)框架。Zhang 等人[20]提出了一种基于CF和MLP 相结合的服务推荐的位置感知深度协作过滤(Location-aware Deep Collaborative Filtering for Fervice Recommendation,LDCF)方 法。NCF 和LDCF 都利用MLP 挖掘调用服务的用户行为的潜在特征,以提高QoS 预测的准确性。然而,NCF 忽略了用户和服务的位置所起的重要作用,LDCF 也没有很好地应对由CF 引起的性能波动。Yang 等人[6]不仅利用用户和服务的QoS 信息,还利用用户和服务邻居的信息,并将这些地理数据组合到分解机器中进行预测。基于深度学习的方法具有整合复杂关系的能力和强大的高维挖掘潜在特征的学习能力,并且优于该领域最先进的方法,因此深度学习成为服务推荐应用的更好选择。
通过综合考虑用户信誉问题与地理位置因素的影响,本文提出了一种基于位置与信誉感知深度神经网络(Cloud Service Quality Prediction Based on Location and Reputation Aware Depth Neural Network,RADNN)的云服务质量预测方法。具体来说,本文的主要贡献如下:
(1)解决可信度问题并提供准确的预测结果。结合地理位置利用K-means 聚类将用户信誉考虑进深度神经网络模型中,解决了可信度问题,并帮助目标用户识别更可信和相似的邻居。
(2)为了提取合适的邻域信息,采用网络嵌入方法来挖掘更多相似的邻域,并利用用户特征网络和服务特征网络,有效解决数据稀疏的问题。
(3)在公共的QoS 数据集上进行了多次实验,结果表明,本文提出的RADNN 模型在不同的用户服务矩阵密度下始终表现良好,并且在QoS 预测的准确性方面表现优于现有的先进方法。
1 基于位置与信誉感知的云服务质量预测
1.1 地理位置因素影响
图1 展示了现实中云服务调用的场景。上面是用户所在的位置,下面是服务所在的位置,两部分之间的虚线表示调用记录。底部的表格显示用户u1调用了服务s1、s2和s4,用户u2调用了服务s1和s3。其余QoS 值未知,例如用户u1调用s3的值和用户u2调用s2和s4的值。为了在这4 种服务中为用户u1和u2找到最合适、最高效的服务,需要预测未知的QoS 值,这就是本文要解决的问题。图1 中显示用户u1和用户u2处于具有相似位置信息的相同用户区域中,并且它们调用的QoS 值也相似。s1和s2都位于相同服务区域,也具有类似的QoS 值。在现实场景中,地理位置相邻的用户具有相似的网络环境和质量,这对不同用户的QoS 预测起着重要作用。矩阵中不同用户或服务之间的相似度可以通过位置信息来计算。位置信息包括用户或服务的国家、自治区和经纬度等。本文提出的方法可以充分利用用户和服务的位置信息以获得更好的预测精度。
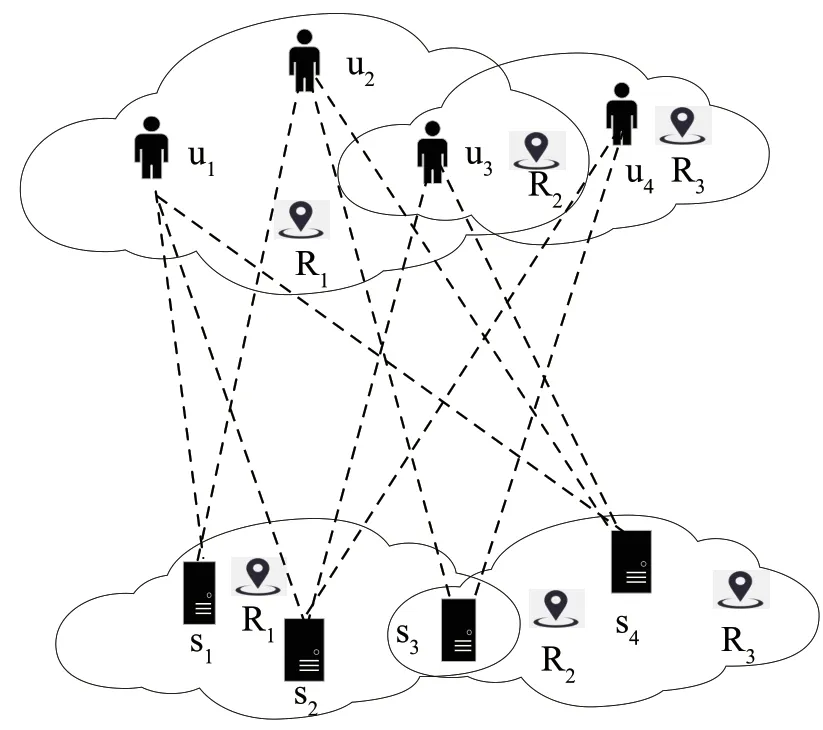
图1 地理位置影响
1.2 用户信誉影响
在用户可以对项目进行评分的评分系统中,用户可能会出于各种原因给出错误的评分,因此在这类系统中,区分可靠用户和不可靠用户非常重要。识别受信任用户的一种方法是根据使用用户的信誉来判定。用户信誉代表了用户在评分系统中的行为,决定了用户评分的准确性。文献[21]对用户信誉作了如下解释:在评级系统中,用户信誉评估用户提供可靠、公平和值得信赖的评级的能力。它是根据用户评分接近服务“真实”分数的程度来衡量的。为了解决可信度问题并获得准确的云服务质量预测,本文采用K-means 聚类来识别不可信用户,并排除这些用户提供的数据。

表1 地理位置影响
2 RADNN 模型框架
本文结合用户位置信息,如国家和经纬度等,来建模涉及位置属性的深度神经网络,并使用网络嵌入学习,提出一种基于位置与信誉感知深度神经网络云服务质量的预测方法。首先采用K-means 聚类来识别不可信用户;其次在考虑用户信誉的同时,在可信用户和服务之间构建一个深度神经网络模型,采用信誉感知网络嵌入来学习用户的潜在表示,深度神经网络又分为用户特征网络和服务特征网络,两个子网络通过全连接层输出用户特征向量和服务特征向量;再次通过矩阵点乘求和对两者进行融合;最后输出预测值。其主要框架如图2 所示。RADNN 架构是一个多层前馈神经网络,包括三个特定的功能层,即输入层、中间层和输出层。在其前向传播过程中,每一层的输出都作为下一层的输入。中间层用于集中训练以获得高维和非线性特征。

图2 RADNN 总体模型框架
2.1 输入层
输入层主要用于处理原始输入。为了让神经网络学习额外的数据特征,将用户ID、用户位置信息、服务ID 和服务位置信息输入嵌入层,并可以将其视为一个特殊的无偏差项的完全连接层。通过该操作,将类别特征映射到高维密集嵌入向量。映射过程如下:


式中:iu和is分别为用户和服务的ID 标识符;gu和gs为用户和服务位置的原始输入;P1为用户的嵌入权重矩阵;Q1为服务的嵌入权重矩阵;b1为初始化为零的偏差项;f1为该层的激活函数;分别为k维用户的ID 嵌入向量和位置嵌入向量;和分别为k维服务的标识符嵌入向量和位置嵌入向量。
然后,将标识符特征向量和相应的位置特征向量相结合,分别得到用户特征向量和服务特征向量。最后,将这两个特征向量连接起来,得到中间层所需的输入向量。具体的计算公式为:

式中:Φ表示合并操作;U和S为用户和服务的嵌入向量;x为输入向量。
2.2 中间层
中间层用于处理输入层的输入向量,以捕获非线性特征。采用全连接MLP 结构来学习用户与服务之间的高维非线性关系。为了让神经网络学习更多的特征,网络架构为底部神经元多、顶层神经少的结构[19]。最后,对权重使用L2 正则化来防止过拟合。中间层中输入向量的正向传播过程定义为:
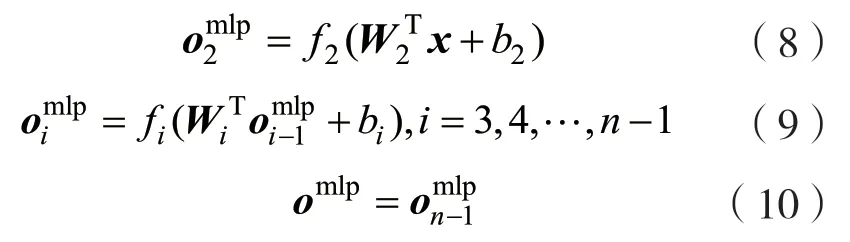
2.3 输出层
输出层主要用于生成最终预测结果。RADNN通过构建用户特征网络和服务特征网络为用户和服务进行建模,两个子网络通过全连接层输出用户特征向量和服务特征向量,然后通过矩阵点乘求和对两者进行融合,最后通过单层神经网络生成最终预测。本文将相似性输出oAC与omlp相结合,构造了一个新的输出向量。该层的参数初始化使用高斯分布,计算方式为:

式中:Q^u,s为调用服务s 的用户u 的预测QoS 值;fn为该层最后一层的激活函数的标准标识函数。
3 实验
3.1 数据集
本文实验使用的数据集为Zheng 等人[2]收集的公共真实世界web 服务QoS 数据集WSDream,包含调用5 825 个web 服务的339 个用户的QoS 信息。该数据集包括web 服务的响应时间(Response Time,RT)和吞吐量(Throughput,TP)记录。用户响应时间的范围是0~20 s,吞吐量的范围是0~1 000 kbit/s。此外,用户信息包括用户ID、IP 地址、IP 号码、国家、自治系统、纬度和经度。对于每一个web 服务,除了上述信息,还有web 服务的提供者名称和网络服务描述语言(Web Services Description Language,WSDL)地址。
3.2 实验设置
本文实验的软硬件环境:操作系统为基于x64的处理器的Windows 11,CPU 为11th Gen Intel(R)Core(TM) i5-11320H @ 3.20 GHz,内存为16.0 GB,处理软件为Pycharm 2018 和Python 3.8。
3.3 评价指标
本文中采用平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Square Error,RMSE)来衡量预测性能。MAE 不仅根据等待预测的值的数量确定平均差异,还计算真实值与预测值之间的绝对差异。RMSE 对异常值非常敏感,并赋予它们相对较高的权重。因此,采用MAE 和RMSE来评估RADNN 的QoS 预测性能。直观地说,MAE和RMSE的值越小,RADNN 模型对QoS 预测的准确度就越高。MAE和RMSE的定义如下:
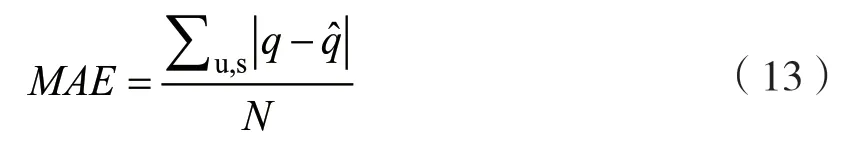

式中:q为实际的QoS 值;q^ 为QoS 的预测值;N为预测的QoS 值的数量。
3.4 基线模型
为了验证所提模型的效果,本实验在预测任务上选择了10种先进模型作为本文方法的基线模型。这10 种先进模型的介绍如下:
(1)用户平均值(User Mean,UMEAN):此方法使用用户对所用web 服务的平均QoS 值来推荐web 服务。
(2)服务平均值(Item Mean,IMEAN):此方法使用其他服务用户观察到的web 服务的平均QoS 值来进行服务推荐。
(3)通过协同过滤对web 服务进行个性化QoS 预测(Personalized QoS prediction for web services via collaborative filtering,UPCC)[22]:该方法通过皮尔逊相关系数(Pearson Correlation Coefficient,PCC)计算不同用户之间的相似性,并利用相似用户的历史调用经验预测未知的QoS 值。
(4)基于项目的协同过滤推荐算法(Item-based collaborative filtering recommendation algorithms,IPCC)[23]:通过挖掘服务之间的相似性来预测QoS缺失值。
(5)通过协同过滤提供QoS 感知的web 服务推荐(QoS-aware web service recommendation by collaborative filtering,UIPCC)[2]:结 合UPCC 和IPCC 中分别采用的相似用户和相似web 服务进行QoS 预测的一种混合协同过滤方法。
(6)基于QoS 服务推荐的位置感知协同过滤(Location-Aware Collaborative Filtering for QoSbased service recommendation,LACF)[24]:该方法同时使用用户和服务的位置进行服务推荐,这是最先进的位置感知方法。
(7)用于个性化服务质量预测的位置和信誉感知矩阵分解方法(A location and reputation aware matrix factorization approach for personalized quality of service prediction,LRMF)[25]:该方法是一种基于矩阵分解(Matrix Factorization,MF)的方法,它利用用户的信誉和位置信息进行QoS 预测。
(8)基于区域信誉矩阵分解的web 服务质量预测(web service quality of service prediction via regional reputation-based matrix factorization,RRMF)[26]:该方法定义了一个区域矩阵分解的概念,先结合用户的位置信息和他们的声誉,再与矩阵分解相结合,提高预测的准确性,并对不可靠用户提供的数据更加持久。
(9)神经协同过滤(Neural Collaborative Filtering,NCF)[20]:作为一种新颖的神经网络方法,NCF 结合了MLP 和矩阵分解进行服务推荐。
(10)概率矩阵分解(Probabilistic Matrix Factorization,PMF)[11]:该方法是一种基于模型的方法,使用概率MF 来预测web 服务的QoS 值。
3.5 实验结果与分析
在现实世界的场景中,实际观察到的QoS 值非常稀疏。为了使实验更加真实,将调用矩阵QoS 数据随机去除掉一定密度作为训练矩阵,然后将去除的数据作为期望值或测试矩阵来研究预测性能。实验研究了6 种不同的基质密度,范围从0.05 到0.30,步长为0.05。对11 种方法的响应时间的实验比较结果如表2 所示。实验比较充分地证明了本文所提模型RADNN 不仅在稀疏数据上表现得非常好,而且与其他10 种方法相比实现了更好的QoS 预测精度。

表2 RADNN 与其他方法在RT 上的比较
如表2 所示,随着矩阵密度降低,11 种方法的QoS 预测精度均逐渐降低。随着密度值从0.05 增加到0.30,11 种方法的响应时间的MAE和RMSE的值呈现下降趋势。这是因为,与低密度的用户服务矩阵相比,高密度的矩阵意味着相应的训练集包含更多有用的信息、更多可用的数据和更多可以提取的潜在特征,说明当收集到的QoS 数据越多时,神经网络可以学习的特征就越多,就可以实现更高的预测精度。在相同稀疏度条件下,与其他方法相比,所提的方法获得了更小的MAE和RMSE,表明所提的方法具有更高的QoS 预测精度。
3.5.1 性能比较
如图3 所示,为了比较各种方法的性能高低,为它们设置相同的矩阵密度0.1 进行比较。通过观察图3(a)发现传统的CF 方法在稀疏度较大时推荐准确率较差,而基于深度学习的方法表现良好。这是因为传统的CF方法只能学习低维和线性特征,因此其特征学习能力受到很大限制,而深度学习可以捕捉高维非线性特征,有效弥补数据稀疏性对CF 特征学习的限制。
通过观察图3(b),当数据稀疏时,RRMF 表现相对较好,但它只使用用户位置信息,不能很好地学习用户和服务的潜在特征。NCF 表现也不错,但它只使用标识符信息。本文方法不仅可以学习用户和服务的非线性特征,还可以结合位置信息来弥补CF 方法和NCF 方法的缺陷。因此在相同密度下,所提方法的RMSE都优于其他方法。综上,与现有的推荐方法相比,RADNN 可以有效地处理数据稀疏性,获得更好的推荐性能。
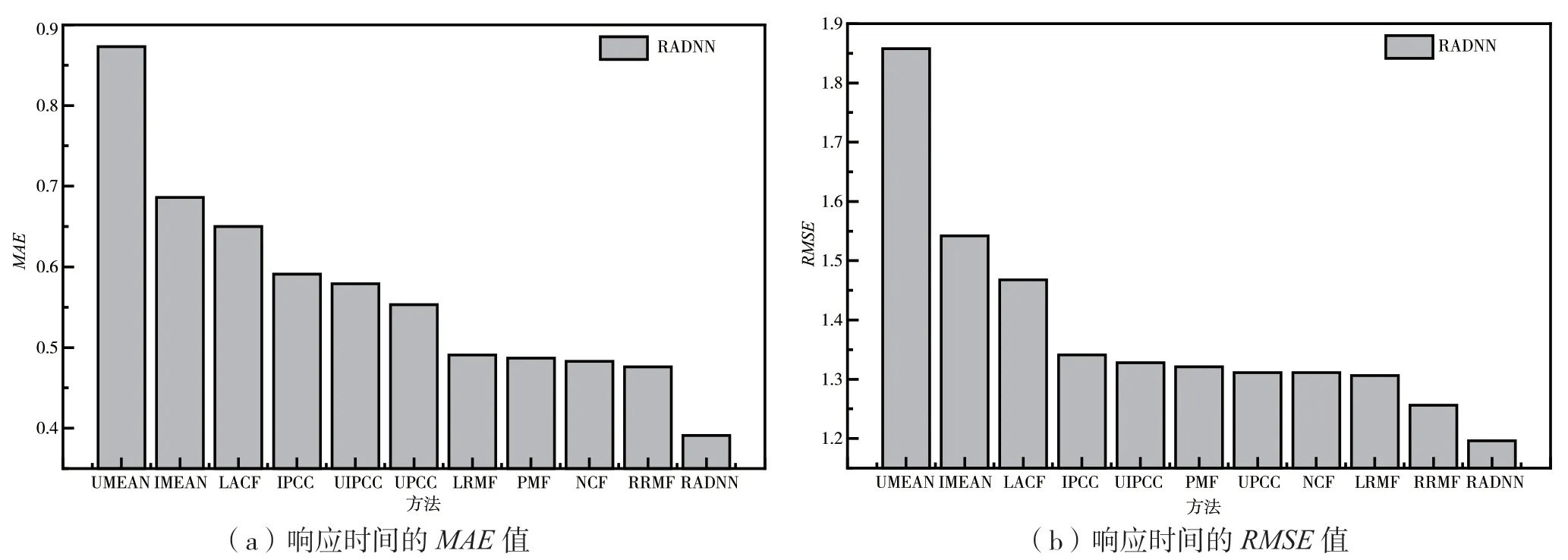
图3 同一密度下的性能对比
3.5.2 基质密度影响
矩阵密度表示训练数据的稀疏性。本文方法在不同稀疏度下的响应时间变化如图4 所示。实验发现MAE和RMSE随着矩阵密度的增加而降低。本文实验将密度矩阵从0.05 改为0.30,步长为0.05。当训练矩阵的密度从0.05 增加到0.30 时,MAE和RMSE都迅速下降,这意味着预测结果有很大提高。随着密度的进一步增加,MAE开始缓慢下降。这表明随着矩阵密度的增加,训练集包含的项目越多,预测准确率会越高。

图4 RADNN 在不同稀疏度下的响应时间变化
3.5.3 维度的影响
模型中利用神经网络时,主要超参数是嵌入层的维度。维度决定了潜在因素的数量,为了清楚地观察维度对QoS 预测的影响,本文比较了RADNN方法在不同潜在因子矩阵维度下的预测精度。实验设置维度范围从8 到128 每次乘以2,比较0.05,0.1和0.15 这3 种密度下随不同维度变化的响应时间的MAE和RMSE值。比较结果如图5 所示,当维数接近32 时,MAE和RMSE的值最小,随着维度增大,MAE和RMSE的值增大。此外,对于不同密度的MAE和RMSE,它们的值随着维度的增加而下降。

图5 RADNN 在不同嵌入维度下的响应时间变化
4 结语
本文提出了一种基于位置与信誉感知深度神经网络的云服务质量的预测方法,首先结合地理位置利用K-means 聚类将用户信誉考虑进深度神经网络模型中,解决了可信度问题,帮助目标用户识别更可信和相似的邻居;其次采用网络嵌入方法来挖掘更多相似的邻域,利用用户特征网络和服务特征网络,有效解决数据稀疏的问题;再次两个子网络通过全连接层输出用户特征向量和服务特征向量,通过矩阵点乘求和对两者进行融合;最后通过单层神经网络生成最终预测。实验表明,本文所提的方法比其他方法更准确、更可靠。未来,将考虑使用更新的深度学习模型,结合除用户服务位置信息外的其他用户服务的更多辅助信息,进一步考虑时间因素对预测的影响。
猜你喜欢
公民与法治(2022年12期)2023-01-07
计算机应用文摘·触控(2022年8期)2022-05-25
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
华人时刊(2019年13期)2019-11-26
电子制作(2019年19期)2019-11-23
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
华人时刊(2016年19期)2016-04-05
重型机械(2016年1期)2016-03-01
